Enterprise:如何在 Elastic 企业搜索引擎中添加对更多语言的支持
作者:Ioana-Alina Tagirta

Elastic App Search 中的引擎(engines)使你能够索引文档并提供开箱即用的可调搜索功能。 默认情况下,引擎支持预定义的语言列表。 如果你的语言不在该列表中,此博客将说明如何添加对其他语言的支持。 我们将通过创建一个 App Search 引擎来实现这一点,该引擎具有针对该语言设置的分析器。
在我们深入细节之前,让我们定义什么是 Elasticsearch 分析器:
Elasticsearch 分析器是一个包含三个较低级别构建块的包:字符过滤器、标记器和标记过滤器。 分析器可以是内置的或定制的。 内置分析器将构建块预打包到适合不同语言和文本类型的分析器中。更多关于 Analyzer 的内容,请参阅文章 “Elasticsearch: analyzer”。
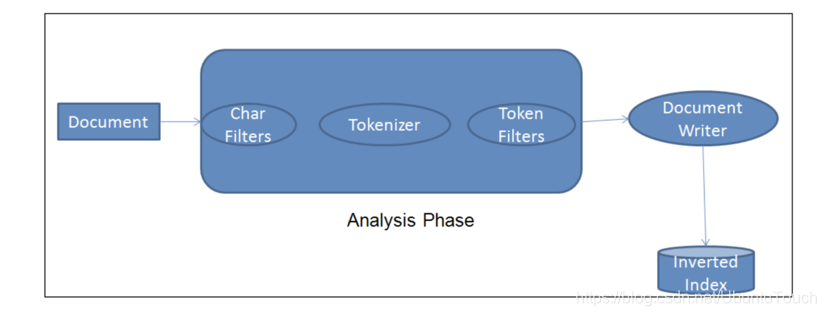
每个字段的分析器用于:
- 索引文档。 每个文档字段都将使用其相应的分析器进行处理,并分解为分词以方便搜索。
- 搜索文档。 将分析 search query 以确保与已分析的索引字段正确匹配。
基于 Elasticsearch 索引的引擎使你能够从现有的 Elasticsearch 索引创建 App Search 引擎。 我们将使用我们自己的分析器和映射创建一个 Elasticsearch 索引,并在 App Search 中使用该索引。
这个过程有四个步骤:
- 创建 Elasticsearch 索引和索引文档
- 将语言分析器添加到该索引
- 更新索引映射以使用分析器
- 重新索引文档
1)创建 Elasticsearch 索引和索引文档
首先,让我们使用一个尚未针对任何语言进行优化的索引。 假设这是一个没有预定义映射的新索引,它是在第一次为文档建立索引时创建的。
在 Elasticsearch 中,映射(mapping)是定义文档及其包含的字段如何存储和索引的过程。 每个文档都是字段的集合,每个字段都有自己的数据类型。 映射数据时,你创建一个映射定义,其中包含与文档相关的字段列表。
回到我们的例子。 该索引称为 books,title 为罗马尼亚语。 我们选择罗马尼亚语是因为它是我的语言,它不包含在 App Search 默认支持的语言列表中。
POST books/_doc/1
{"title": "Un veac de singurătate","author": "Gabriel García Márquez"
}POST books/_doc/2
{"title": "Dragoste în vremea holerei","author": "Gabriel García Márquez"
}POST books/_doc/3
{"title": "Obosit de viaţă, obosit de moarte","author": "Mo Yan"
}POST books/_doc/4
{"title": "Maestrul și Margareta","author": "Mihail Bulgakov"
}2)增加语言分析器到书籍索引
当我们检查 books 索引映射时,我们发现它没有针对罗马尼亚语进行优化。 你可以看出 settings 块中没有 analysis 字段,并且文本字段不使用自定义分析器。
GET books
{"books": {"aliases": {},"mappings": {"properties": {"author": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"title": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}}}},"settings": {"index": {"routing": {"allocation": {"include": {"_tier_preference": "data_content"}}},"number_of_shards": "1","provided_name": "books","creation_date": "1679310576178","number_of_replicas": "1","uuid": "0KuiDk8iSZ-YHVQGg3B0iw","version": {"created": "8080099"}}}}
}如果我们尝试使用 books 索引创建 App Search 引擎,我们会遇到两个问题。 首先,搜索结果将不会针对罗马尼亚语进行优化,其次,精确调整等功能将被禁用。
关于不同类型的 Elastic App Search 引擎的快速说明:
- 默认选项是 App Search 托管引擎,它将自动创建和管理隐藏的 Elasticsearch 索引。 使用此选项,你必须使用 App Search 文档 API 在引擎中提取数据。
- 对于另一个选项,App Search 会创建一个具有现有 Elasticsearch 索引的引擎 —— 在这种情况下,App Search 将按原样使用该索引。 在这里,你可以使用 Elasticsearch 索引文档 API 直接在底层索引中提取数据。
[相关文章:Elasticsearch Search API:一种定位 App Search 文档的新方法]
当你从现有 Elasticsearch 索引创建引擎时,如果映射不遵循 App Search 约定,则不会为该引擎启用所有功能。 让我们通过查看完全由 App Search 管理的引擎来更仔细地了解 App Search 映射约定。 该引擎有两个字段,title 和 author,并使用英语。
GET .ent-search-engine-documents-app-search-books/_mapping/field/title
{".ent-search-engine-documents-app-search-books": {"mappings": {"title": {"full_name": "title","mapping": {"title": {"type": "text","fields": {"date": {"type": "date","format": "strict_date_time||strict_date","ignore_malformed": true},"delimiter": {"type": "text","index_options": "freqs","analyzer": "iq_text_delimiter"},"enum": {"type": "keyword","ignore_above": 2048},"float": {"type": "double","ignore_malformed": true},"joined": {"type": "text","index_options": "freqs","analyzer": "i_text_bigram","search_analyzer": "q_text_bigram"},"location": {"type": "geo_point","ignore_malformed": true,"ignore_z_value": false},"prefix": {"type": "text","index_options": "docs","analyzer": "i_prefix","search_analyzer": "q_prefix"},"stem": {"type": "text","analyzer": "iq_text_stem"}},"index_options": "freqs","analyzer": "iq_text_base"}}}}}
}你会看到 title 字段有几个子字段。date、float 和 location 子字段不是文本字段。
在这里,我们感兴趣的是如何设置 App Search 需要的文本字段。 多了几个字段! 此文档页面解释了 App Search 中使用的文本字段。 让我们看看 App Search 为属于 App Search 托管引擎的隐藏索引设置的分析器:
GET .ent-search-engine-documents-app-search-books/_settings/index.analysis*
{".ent-search-engine-documents-app-search-books": {"settings": {"index": {"analysis": {"filter": {"front_ngram": {"type": "edge_ngram","min_gram": "1","max_gram": "12"},"bigram_joiner": {"max_shingle_size": "2","token_separator": "","output_unigrams": "false","type": "shingle"},"bigram_max_size": {"type": "length","max": "16","min": "0"},"en-stem-filter": {"name": "light_english","type": "stemmer"},"bigram_joiner_unigrams": {"max_shingle_size": "2","token_separator": "","output_unigrams": "true","type": "shingle"},"delimiter": {"split_on_numerics": "true","generate_word_parts": "true","preserve_original": "false","catenate_words": "true","generate_number_parts": "true","catenate_all": "true","split_on_case_change": "true","type": "word_delimiter_graph","catenate_numbers": "true","stem_english_possessive": "true"},"en-stop-words-filter": {"type": "stop","stopwords": "_english_"}},"analyzer": {"i_prefix": {"filter": ["cjk_width","lowercase","asciifolding","front_ngram"],"tokenizer": "standard"},"iq_text_delimiter": {"filter": ["delimiter","cjk_width","lowercase","asciifolding","en-stop-words-filter","en-stem-filter"],"tokenizer": "whitespace"},"q_prefix": {"filter": ["cjk_width","lowercase","asciifolding"],"tokenizer": "standard"},"iq_text_base": {"filter": ["cjk_width","lowercase","asciifolding","en-stop-words-filter"],"tokenizer": "standard"},"iq_text_stem": {"filter": ["cjk_width","lowercase","asciifolding","en-stop-words-filter","en-stem-filter"],"tokenizer": "standard"},"i_text_bigram": {"filter": ["cjk_width","lowercase","asciifolding","en-stem-filter","bigram_joiner","bigram_max_size"],"tokenizer": "standard"},"q_text_bigram": {"filter": ["cjk_width","lowercase","asciifolding","en-stem-filter","bigram_joiner_unigrams","bigram_max_size"],"tokenizer": "standard"}}}}}}
}
如果我们想为不同的语言(例如挪威语、芬兰语或阿拉伯语)创建一个可以在 App Search 中使用的索引,我们将需要类似的分析器。 对于我们的示例,我们需要确保词干和停用词过滤器使用罗马尼亚语版本。
回到我们最初的 books 索引,让我们添加正确的分析器。
在这里快速警告一下。 对于现有索引,分析器是一种 Elasticsearch 设置,只能在索引关闭时更改。 在这种方法中,我们从现有索引开始,因此需要关闭索引、添加分析器,然后 reopen 索引。
注意:作为替代方案,你也可以使用正确的映射从头开始重新创建索引,然后索引所有文档。 如果这更适合你的用例,请随意跳过本指南中讨论打开和关闭索引以及重新索引的部分。
你可以通过运行 POST books/_close 来关闭索引。 之后,我们将添加分析器:
PUT books/_settings
{"analysis": {"filter": {"front_ngram": {"type": "edge_ngram","min_gram": "1","max_gram": "12"},"bigram_joiner": {"max_shingle_size": "2","token_separator": "","output_unigrams": "false","type": "shingle"},"bigram_max_size": {"type": "length","max": "16","min": "0"},"ro-stem-filter": {"name": "romanian","type": "stemmer"},"bigram_joiner_unigrams": {"max_shingle_size": "2","token_separator": "","output_unigrams": "true","type": "shingle"},"delimiter": {"split_on_numerics": "true","generate_word_parts": "true","preserve_original": "false","catenate_words": "true","generate_number_parts": "true","catenate_all": "true","split_on_case_change": "true","type": "word_delimiter_graph","catenate_numbers": "true"},"ro-stop-words-filter": {"type": "stop","stopwords": "_romanian_"}},"analyzer": {"i_prefix": {"filter": ["cjk_width","lowercase","asciifolding","front_ngram"],"tokenizer": "standard"},"iq_text_delimiter": {"filter": ["delimiter","cjk_width","lowercase","asciifolding","ro-stop-words-filter","ro-stem-filter"],"tokenizer": "whitespace"},"q_prefix": {"filter": ["cjk_width","lowercase","asciifolding"],"tokenizer": "standard"},"iq_text_base": {"filter": ["cjk_width","lowercase","asciifolding","ro-stop-words-filter"],"tokenizer": "standard"},"iq_text_stem": {"filter": ["cjk_width","lowercase","asciifolding","ro-stop-words-filter","ro-stem-filter"],"tokenizer": "standard"},"i_text_bigram": {"filter": ["cjk_width","lowercase","asciifolding","ro-stem-filter","bigram_joiner","bigram_max_size"],"tokenizer": "standard"},"q_text_bigram": {"filter": ["cjk_width","lowercase","asciifolding","ro-stem-filter","bigram_joiner_unigrams","bigram_max_size"],"tokenizer": "standard"}}}
}你可以看到,我们正在添加 ro-stem-filter 以提取罗马尼亚语的词干,这将提高罗马尼亚语特定单词变体的搜索相关性。 我们包括罗马尼亚语停用词过滤器 (ro-stop-words-filter) 以确保罗马尼亚语停用词不被考虑用于搜索目的。
现在我们将通过执行 POST books/_open 重新打开索引。
3)更新索引映射以使用分析器
一旦我们有了分析设置,我们就可以修改索引映射。 App Search 使用动态模板来确保新字段具有正确的子字段和分析器。 对于我们的示例,我们只会将子字段添加到现有的 title 和 author 字段中:
PUT books/_mapping
{"properties": {"author": {"type": "text","fields": {"delimiter": {"type": "text","index_options": "freqs","analyzer": "iq_text_delimiter"},"enum": {"type": "keyword","ignore_above": 2048},"joined": {"type": "text","index_options": "freqs","analyzer": "i_text_bigram","search_analyzer": "q_text_bigram"},"prefix": {"type": "text","index_options": "docs","analyzer": "i_prefix","search_analyzer": "q_prefix"},"stem": {"type": "text","analyzer": "iq_text_stem"}}},"title": {"type": "text","fields": {"delimiter": {"type": "text","index_options": "freqs","analyzer": "iq_text_delimiter"},"enum": {"type": "keyword","ignore_above": 2048},"joined": {"type": "text","index_options": "freqs","analyzer": "i_text_bigram","search_analyzer": "q_text_bigram"},"prefix": {"type": "text","index_options": "docs","analyzer": "i_prefix","search_analyzer": "q_prefix"},"stem": {"type": "text","analyzer": "iq_text_stem"}}}}
}4)重新索引文档
books 索引现在几乎可以在 App Search 中使用了!
我们只需要确保我们在修改映射之前索引的文档具有所有正确的子字段。 为此,我们可以使用 update_by_query 就地运行重建索引:
POST books/_update_by_query?refresh
{"query": {"match_all": {}}
}由于我们使用的是 match_all 查询,因此所有现有文档都将被更新。
通过 update by query 请求,我们还可以包含一个脚本参数来定义如何更新文档。
请注意,我们没有更改文档,但我们确实希望按原样重新索引现有文档,以确保文本字段 author 和 title 具有正确的子字段。 因此,我们不需要在我们的查询请求更新中包含脚本。
我们现在有一个语言优化的索引,我们可以在带有 Elasticsearch 引擎的 App Search 中使用! 你将在以下屏幕截图中看到实际的好处。
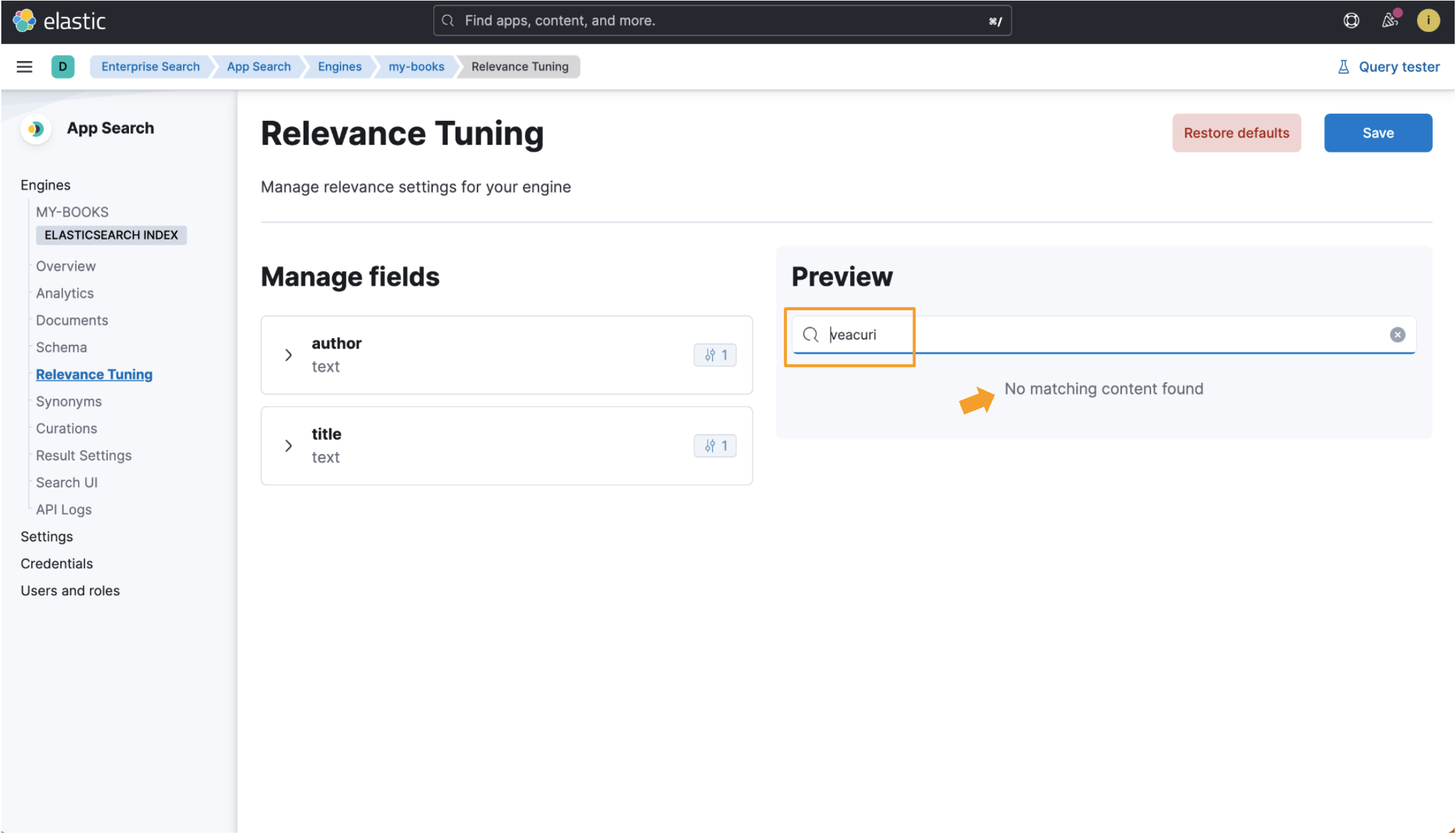
我们将使用书名 One Hundred Years of Solitude 作为参考。 罗马尼亚语的翻译标题是 Un veac de singurătate。 注意 veac 这个词,它是罗马尼亚语中 “世纪” 的意思。 我们将使用 veac 的复数形式进行搜索,即 veacuri。 我们在将要查看的两个示例中都提取了此数据记录:
{"title": "Un veac de singurătate","author": "Gabriel García Márquez"
}当索引未针对某种语言进行优化时,罗马尼亚书名 Un veac de singurătate 将使用标准分析器进行索引,该分析器适用于大多数语言,但可能并不总是与相关文档匹配。 搜索 veacuri 不会显示任何结果,因为此搜索输入与数据记录中的任何纯文本都不匹配。
然而,在使用语言优化索引时,当我们搜索 veacuri 时,Elastic App Search 会将其与罗马尼亚语单词 veac 相匹配,并返回我们要查找的数据。 相关调整视图中也提供精确调整字段! 查看此图像中所有突出显示的位:
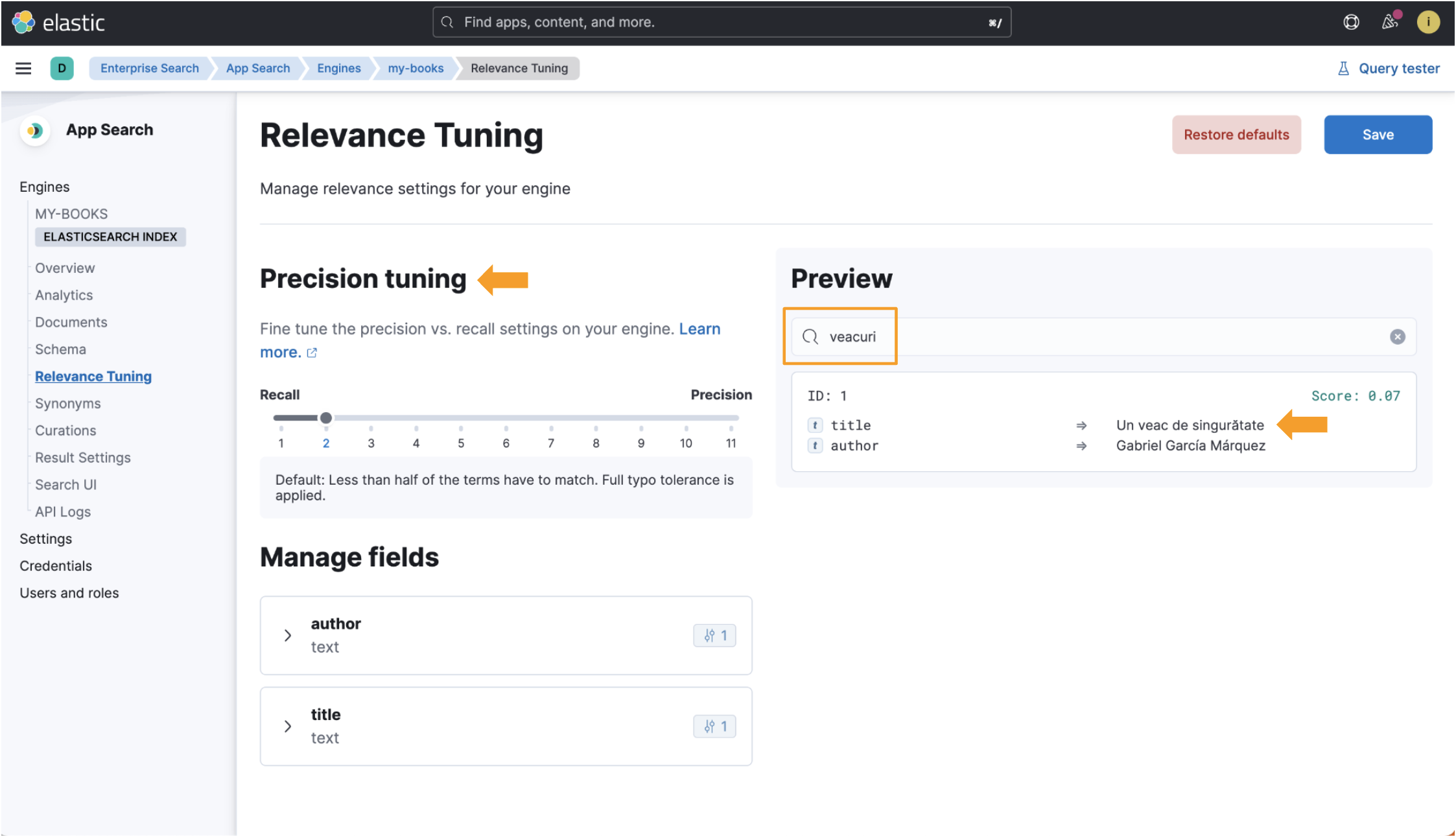
因此,我们在 Elastic Enterprise Search 中添加了对罗马尼亚语的支持,这是我的语言! 可以复制本指南中使用的过程来创建针对 Elasticsearch 支持的任何其他语言优化的索引。 有关 Elasticsearch 中支持的语言分析器的完整列表,请查看此文档页面。
Elasticsearch 中的分析器是一个引人入胜的话题。 如果你有兴趣了解更多信息,这里有一些其他资源:
- Elasticsearch 文本分析概述文档页面
- Elasticsearch 内置分析器参考文档页面(有关支持的语言分析器列表,请参阅此子页面。)
- 了解有关 Elastic Enterprise Search 和 Elastic Cloud 试用的更多信息
相关文章:
Enterprise:如何在 Elastic 企业搜索引擎中添加对更多语言的支持
作者:Ioana-Alina Tagirta Elastic App Search 中的引擎(engines)使你能够索引文档并提供开箱即用的可调搜索功能。 默认情况下,引擎支持预定义的语言列表。 如果你的语言不在该列表中,此博客将说明如何添加对其他语言…...
SqlServer数据库中文乱码问题解决方法
这个问题在网上找了很多资料都没找到真正解决问题的办法,最终去了官网,终于找到问题的答案了,整理出来做个记录。 问题描述: 项目中遇到一个问题,sqlserver中的数据是ok的,结果保存到mysql中是乱码&#…...

跨域的五种最常见解决方案
在开发Web应用程序时,一个常见的问题是如何处理跨域请求。跨域请求是指来自不同源的请求,这些请求可能会受到浏览器的限制而不能被正常处理。在这篇文章中,我们将探讨跨域请求的常见解决方案,并了解每种解决方案的优缺点。 一、J…...
作为一个C++新手,我感兴趣的C++开源项目
2023年4月30日,周日晚上。 昨天完成了一个C项目后,想再开始一个C项目,但不知道做什么,于是决定看看有什么好的C开源项目。 今晚在网上逛了一圈后,发现了好多有趣的C开源项目。 参考文章: GitHub Top 10 …...

杭州云降价只是敲锣
1. 陈年旧事 大约是2015年,某友商宣布存储免费,当时我们公司如临大敌,我也被拽过去开会。后来我们才发现……对方的套路是: 文件存储原始收费是一毛钱。文档存储免费的条件是,需要客户当月有一次下载文件的行为才能免费…...
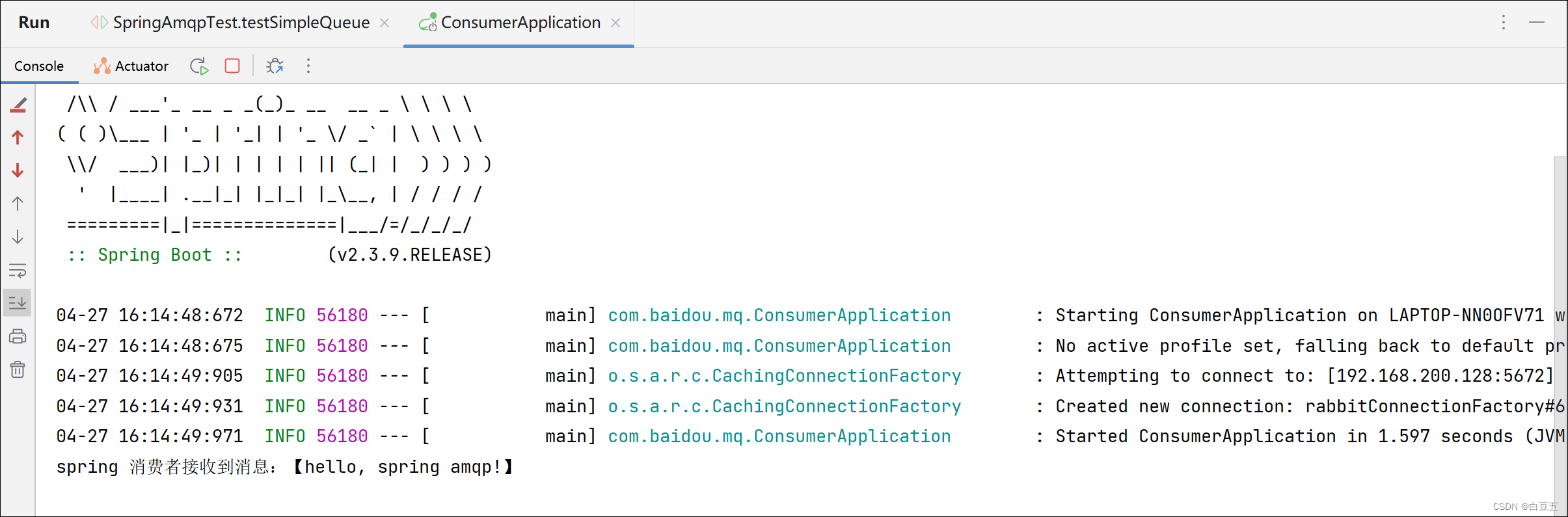
RabbitMQ笔记
一、MQ与RabbitMQ概述 1. MQ简述 MQ(Message Queue)消息队列,是基础数据结构中 “先进先出” 的一种数据结构,也是在消息的传输过程中保存消息的容器(中间件),多用于分布式系统之间进行通信。 …...

【Latex】如何在表格中使用footnote
Latex table cell中是不支持\footnote的。 如果你在table中用\footnote,那么要么这个脚注根本不显示出来,要么就会出现计数出错等问题。总之非常麻烦。 解决策略 笔者在搜集大量资料后,也并没有找到一种“完美的”解决方案。我们只能用一些…...
设计师常用的素材网站有哪个推荐
即时设计资源社区聚集了许多优秀的创作者,分享了大量的优质资源。 目前,社区资源数量已达到10000,包含图标、插画、原型、设计作品等多个素材类别。这些优秀的设计作品降低了设计师思维的成本,成为设计师的宝藏材料网站。 即时设…...
jmeter常用的命令行参数有哪些?常用的jmeter命令行如何编写
目录:导读 引言 一、JMete执行方式 二、JMete非GUI运行优点 三、jmeter非GUI运行参数 四、jmeter非GUI运行命令 4.1非GUI基本命令格式: 4.2非GUI并生成html报告基本命令格式 结语 引言 你是否在使用JMeter进行负载测试时感到手忙脚乱࿱…...
APP渗透—查脱壳、反编译、重打包签名
APP渗透—查脱壳、反编译、重打包签名 1. 前言1.1. 其它 2. 安装工具2.1. 下载jadx工具2.1.1. 下载链接2.1.2. 执行文件 2.2. 下载apktool工具2.2.1. 下载链接2.2.2. 测试 2.3. 下载dex2jar工具2.3.1. 下载链接 3. 查壳脱壳3.1. 查壳3.1.1. 探探查壳3.1.2. 棋牌查壳 3.2. 脱壳3…...

【贪婪技术】
目录 知识框架No.1 贪婪技术一、问题引入二、基本思想三、问题实例:连续背包问题 No.2 最小生成树问题一、基本思想二、Prim算法1、主要思想和步骤2、算法效率 三、Kruskal算法1、主要思想和步骤 No.3 Dijkstra算法一、主要思想二、问题实例: No.4 哈夫曼…...

谈「效」风生 | 如何找到现有研发体系的「内耗问题」?
#第3期:如何找到现有研发体系的「内耗问题」?# 在上一期《谈到提升效能,我们应该如何下手?》我们聊到开始做研发效能的四个要点:评估现有流程、引入自动化工具、建立度量指标、持续改进。本期就围绕「评估现有研发体系…...
Linux第四章
文章目录 前言一、快捷键小技巧二、软件安装三、systemctl控制软件启动关闭四、软链接五、日期和时区六、ip地址和主机名七、配置linux固定ip地址八、网络请求和下载九、端口十、进程管理十一、主机状态监控十二、环境变量十三、linux文件的上传和下载十四、压缩和解压总结 前言…...
HCIA-RS实验-路由配置-静态路由缺省路由
在计算机网络中,路由器是实现数据包转发的重要设备。它通过查找路由表中的路由信息,将数据包从源地址转发到目标地址。而静态路由和缺省路由则是路由表中的两种重要信息,下面我们来详细了解一下它们的概念、特点和应用。 目录 简述 一、静态…...

Unity API详解——Quaternion类
Quaternion类又称四元数,由x、y、z和w这4个分量组成,属于struct类型。在Unity中,用Quaternion来存储和表示对象的旋转角度。Quaternion的变换比较复杂,对于GameObject一般的旋转及移动,可以用Transform中的相关方法实现…...

8个免费的PNG素材网站推荐
很多设计小白都不知道什么是PNG。事实上,PNG是一种支持透明度的图像格式。当你想在设计中将图像与背景或文本混合时,它就会派上用场。 如果你没有时间为你正在处理的设计创建透明的PNG图像,你也可以使用我收集的PNG素材网站,以便…...

ChatGPT技术原理 第二章:自然语言处理基础
目录 2.1 语言模型 2.3 词嵌入 2.4 注意力机制 2.5 生成式模型 2.1 语言模型...
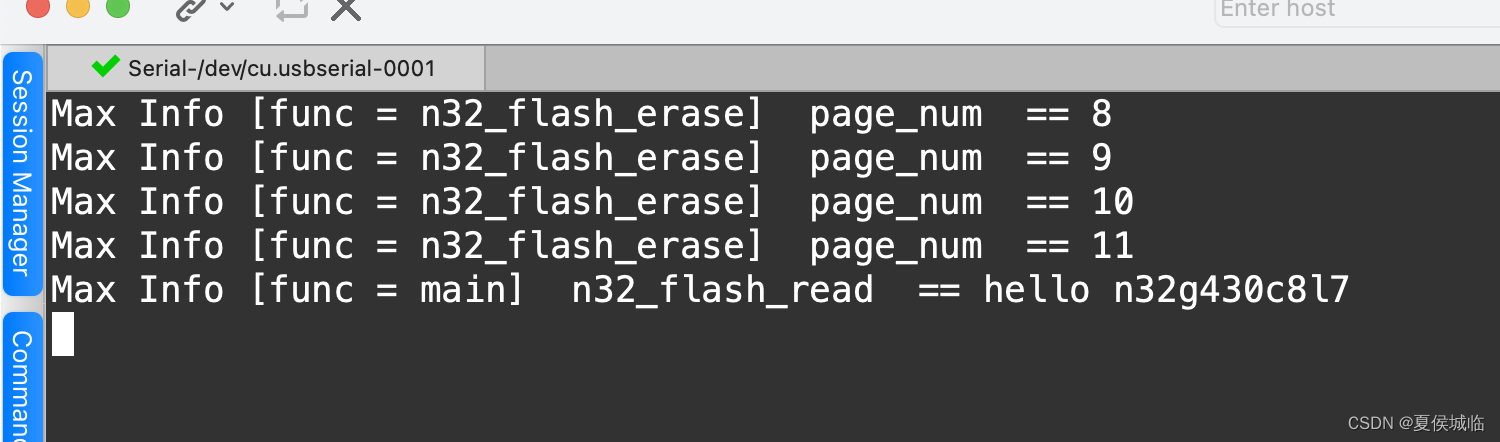
国民技术N32G430开发笔记(8)- 内部Flash的读写操作
N32G430 内部Flash的读写操作 1、主存储区最大为 64KB,也称作主闪存存储器,包含 32 个 Page,用于用户程序的存放和运行,以及数 据存储。 每一页的大小为2K字节 2、IAP 升级我们将64K的flash分区如下: Boot 0x800000…...

JVM 基本知识
目录 前言 一、JVM 内存区域划分 1.1 程序计数器 1.2 栈 1.3 堆 1.4 方法区 二、 JVM 类加载机制 2.1 类加载需要经过的几个步骤 2.1.1 Loading - 加载 2.1.2 Linking - 连接 2.1.3 initialization(初始化) 小结 经典面试题 三、JVM 垃圾…...

【源码解析】流控框架Sentinel源码解析
Sentinel简介 Sentinel是阿里开源的一款面向分布式、多语言异构化服务架构的流量治理组件。 主要以流量为切入点,从流量路由、流量控制、流量整形、熔断降级、系统自适应过载保护、热点流量防护等多个维度来帮助开发者保障微服务的稳定性。 核心概念 资源 资源…...

3DMAX建模救星实测:SmoothBoolean插件处理复杂布尔运算,到底有多稳多快?
3DMAX建模革命:SmoothBoolean插件深度测评与实战指南 在数字建模的世界里,布尔运算一直是把双刃剑——它既能快速实现复杂形状的切割与组合,又常常成为模型崩溃的导火索。对于专业建模师而言,面对机械零件、建筑构件或影视道具中那…...
的优缺点与选型指南)
别再只认Revit了!盘点7种主流BIM数据格式(RVT/IFC/FBX...)的优缺点与选型指南
建筑数字化进阶指南:7大BIM数据格式深度解析与实战选型策略 在建筑信息模型(BIM)与地理信息系统(GIS)加速融合的今天,数据格式的选择直接影响着项目协同效率与成果交付质量。当设计院的Revit模型需要与施工…...

GPU-CPU混合向量检索框架的技术突破与应用
1. 项目概述:GPU-CPU混合向量检索框架的技术突破在当今大规模信息检索和推荐系统领域,向量相似度计算已成为核心瓶颈。传统方案通常面临两难选择:要么完全依赖CPU导致响应延迟居高不下,要么全量使用GPU造成资源严重浪费。VECTORLI…...

拆个汽车配件里的压电陶瓷片,用示波器和面包板实测它的‘发电’与‘震动’能力
从废弃汽车配件到电子实验神器:压电陶瓷片的深度拆解与实战应用 引言:压电陶瓷的奇妙世界 在电子爱好者的眼中,垃圾堆可能是最有趣的"宝藏库"。那些被丢弃的汽车配件、旧家电和电子设备中,往往藏着令人惊喜的元器件。其…...

WarcraftHelper:魔兽争霸3终极增强插件,让经典游戏在现代电脑焕发新生
WarcraftHelper:魔兽争霸3终极增强插件,让经典游戏在现代电脑焕发新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper Warcraf…...

RocketMQ 源码解析——Controller 高可用切换架构
延伸阅读:🔍「RocketMQ 中文社区」 持续更新源码解析/最佳实践,提供 RocketMQ 专家 AI 答疑服务 一、原理及核心概念浅述 1.1 核心架构 1.2 核心概念 controller:负责管理broker间的主备关系,可以挂在namesrv中&…...
-仿printf和scanf输入输出)
【免费下载】 STM32标准库-SPI-DMA收发数据-读写Flash(W25Q256JV)-仿printf和scanf输入输出
STM32标准库-SPI-DMA收发数据-读写Flash(W25Q256JV)-仿printf和scanf输入输出 【下载地址】STM32标准库-SPI-DMA收发数据-读写FlashW25Q256JV-仿printf和scanf输入输出 本项目基于STM32F429IGT6单片机,利用Keil MDK V5.32开发环境,展示了如何通过SPI接口…...
打造丝滑下拉刷新(附Paging3联动实战))
告别传统SwipeRefreshLayout!用Compose的pullRefresh()打造丝滑下拉刷新(附Paging3联动实战)
用Compose的pullRefresh()重构Android下拉刷新体验:从基础封装到Paging3深度集成 下拉刷新作为移动端最基础的用户交互之一,在Jetpack Compose时代迎来了全新的设计范式。传统Android开发中,我们习惯使用SwipeRefreshLayout包裹RecyclerView的…...

不只是CT重建:手把手教你用RTK+ITK+VS2022搭建可扩展的医学影像处理开发环境
构建医学影像算法开发平台:RTKITKVS2022全流程实战指南 医学影像处理领域正迎来前所未有的技术革新,从传统的CT重建到三维可视化、病灶自动检测等高级应用,开发者需要一套稳定且可扩展的开发环境。本文将带您从零开始,在Windows平…...

从8251A芯片实战出发:手把手教你用8086汇编完成串口通信初始化编程
从8251A芯片实战出发:手把手教你用8086汇编完成串口通信初始化编程 在嵌入式系统与硬件接口开发领域,掌握串口通信编程是工程师的必修技能。8251A作为经典的通用同步/异步收发器(USART)芯片,至今仍在教学和工业控制领域广泛应用。本文将带您从…...