PyTorch——利用Accelerate轻松控制多个CPU/GPU/TPU加速计算
PyTorch——利用Accelerate轻松控制多个CPU/GPU/TPU加速计算
- 前言
- 官方示例
- 单个程序内控制多个CPU/GPU/TPU
- 简单说一下
- 设备环境
- 导包
- 加载数据 FashionMNIST
- 创建一个简单的CNN模型
- 训练函数-只包含训练
- 训练函数-包含训练和验证
- 训练
- 多个服务器、多个程序间控制多个CPU/GPU/TPU
- 参考链接
前言
- CPU?GPU?TPU?
- 计算设备太多,很混乱?
- 切换环境,代码大量改来改去?
- 不懂怎么调用多个CPU/GPU/TPU?或者想轻松调用?
- OK!OK!OK!
- 来自HuggingFace的Accelerate库帮你轻松解决这些问题,只需几行代码改动就可以快速完成计算设备的自动调整。

- 来自HuggingFace的Accelerate库帮你轻松解决这些问题,只需几行代码改动就可以快速完成计算设备的自动调整。
- 相关地址
- 官方文档:https://huggingface.co/docs/accelerate/index
- GitHub:https://github.com/huggingface/accelerate
- 安装(推荐用>=0.14的版本)
$ pip install accelerate
- 下面就来说说怎么用
- 你也可以直接看我在Kaggle上做好的完整的Notebook示例
官方示例
- 先大致看个样
- 移除掉以前
.to(device)部分的代码,引入Accelerator对model、optimizer、data、loss.backward()做下处理即可
import torch
import torch.nn.functional as F
from datasets import load_dataset
from accelerate import Accelerator# device = 'cpu'
accelerator = Accelerator()# model = torch.nn.Transformer().to(device)
model = torch.nn.Transformer()
optimizer = torch.optim.Adam(model.parameters())dataset = load_dataset('my_dataset')
data = torch.utils.data.DataLoader(dataset, shuffle=True)model, optimizer, data = accelerator.prepare(model, optimizer, data)model.train()
for epoch in range(10):for source, targets in data:# source = source.to(device)# targets = targets.to(device)optimizer.zero_grad()output = model(source)loss = F.cross_entropy(output, targets)# loss.backward()accelerator.backward(loss)optimizer.step()
单个程序内控制多个CPU/GPU/TPU
- 详细内容请参考官方Example
简单说一下
- 对于单个计算设备,像前面那个简单示例改下代码即可
- 多个计算设备(例如GPU)的情况下,有一点特殊的要处理,下面做个完整的PyTorch训练示例
- 你可以拿这个和我之前发的示例做个对比 CNN图像分类-FashionMNIST
- 也可以直接看我在Kaggle上做好的完整的Notebook示例
设备环境
- 看看当前的显卡设备(2颗Tesla T4),命令
$ nvidia-smi
Thu Apr 27 10:53:26 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.161.03 Driver Version: 470.161.03 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 43C P8 9W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 Tesla T4 Off | 00000000:00:05.0 Off | 0 |
| N/A 41C P8 9W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------++-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
- 安装或更新Accelerate,命令
$ !pip install --upgrade accelerate
导包
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision.transforms import ToTensor, Compose
import torchvision.datasets as datasets
from accelerate import Accelerator
from accelerate import notebook_launcher
加载数据 FashionMNIST
train_data = datasets.FashionMNIST(root="./data",train=True,download=True,transform=Compose([ToTensor()])
)test_data = datasets.FashionMNIST(root="./data",train=False,download=True,transform=Compose([ToTensor()])
)print(train_data.data.shape)
print(test_data.data.shape)
创建一个简单的CNN模型
class CNNModel(nn.Module):def __init__(self):super(CNNModel, self).__init__()self.module1 = nn.Sequential(nn.Conv2d(1, 32, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2)) self.module2 = nn.Sequential(nn.Conv2d(32, 64, kernel_size=5, stride=1, padding=2),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2))self.flatten = nn.Flatten()self.linear1 = nn.Linear(7 * 7 * 64, 64)self.linear2 = nn.Linear(64, 10)self.relu = nn.ReLU()def forward(self, x):out = self.module1(x)out = self.module2(out)out = self.flatten(out)out = self.linear1(out)out = self.relu(out)out = self.linear2(out)return out
训练函数-只包含训练
- 注意看accelerator相关代码
- 若要实现多设备控制训练,
for epoch in range(epoch_num):中末尾处的代码必不可少
def training_function():# 参数配置epoch_num = 4batch_size = 64learning_rate = 0.005# device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')# 数据train_loader = DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True)val_loader = DataLoader(test_data, batch_size=batch_size, shuffle=True)# 模型/损失函数/优化器# model = CNNModel().to(device)model = CNNModel()criterion = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)accelerator = Accelerator()model, optimizer, train_loader, val_loader = accelerator.prepare(model, optimizer, train_loader, val_loader)# 开始训练for epoch in range(epoch_num):# 训练model.train()for i, (X_train, y_train) in enumerate(train_loader):# X_train = X_train.to(device)# y_train = y_train.to(device)out = model(X_train)loss = criterion(out, y_train)optimizer.zero_grad()# loss.backward()accelerator.backward(loss)optimizer.step()if (i + 1) % 100 == 0:print(f"{accelerator.device} Train... [epoch {epoch + 1}/{epoch_num}, step {i + 1}/{len(train_loader)}]\t[loss {loss.item()}]")# 等待每个GPU上的模型执行完当前的epoch,并进行合并同步accelerator.wait_for_everyone() model = accelerator.unwrap_model(model)# 现在所有GPU上都一样了,可以保存modelaccelerator.save(model, "model.pth")
训练函数-包含训练和验证
- 相比前面的代码,多了“验证”相关的代码
- 验证时,因为使用多个设备进行训练,所以会比较特殊,会涉及到多个设备的验证结果合并的问题
def training_function():# 参数配置epoch_num = 4batch_size = 64learning_rate = 0.005# 数据train_loader = DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True)val_loader = DataLoader(test_data, batch_size=batch_size, shuffle=True)# 模型/损失函数/优化器model = CNNModel()criterion = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)accelerator = Accelerator()model, optimizer, train_loader, val_loader = accelerator.prepare(model, optimizer, train_loader, val_loader)# 开始训练for epoch in range(epoch_num):# 训练model.train()for i, (X_train, y_train) in enumerate(train_loader):out = model(X_train)loss = criterion(out, y_train)optimizer.zero_grad()accelerator.backward(loss)optimizer.step()if (i + 1) % 100 == 0:print(f"{accelerator.device} Train... [epoch {epoch + 1}/{epoch_num}, step {i + 1}/{len(train_loader)}]\t[loss {loss.item()}]")# 验证model.eval()correct, total = 0, 0for X_val, y_val in val_loader:with torch.no_grad():output = model(X_val)_, pred = torch.max(output, 1)# 合并每个GPU的验证数据pred, y_val = accelerator.gather_for_metrics((pred, y_val))total += y_val.size(0)correct += (pred == y_val).sum()# 用main process打印accuracyaccelerator.print(f'epoch {epoch + 1}/{epoch_num}, accuracy = {100 * (correct.item() / total):.2f}')# 等待每个GPU上的模型执行完当前的epoch,并进行合并同步accelerator.wait_for_everyone() model = accelerator.unwrap_model(model)# 现在所有GPU上都一样了,可以保存modelaccelerator.save(model, "model.pth")
训练
- 如果你在本地训练的话,直接调用前面定义的函数
training_function即可。最后在命令行启动训练脚本$ accelerate launch example.py。
training_function()
- 如果你在Kaggle/Colab上面,则需要利用notebook_launcher进行训练
# num_processes=2 指定使用2个GPU,因为当前我申请了2颗 Nvidia T4
notebook_launcher(training_function, num_processes=2)
- 下面是2个GPU训练时的控制台输出样例
Launching training on 2 GPUs.
cuda:0 Train... [epoch 1/4, step 100/469] [loss 0.43843933939933777]
cuda:1 Train... [epoch 1/4, step 100/469] [loss 0.5267877578735352]
cuda:0 Train... [epoch 1/4, step 200/469] [loss 0.39918822050094604]cuda:1 Train... [epoch 1/4, step 200/469] [loss 0.2748252749443054]cuda:1 Train... [epoch 1/4, step 300/469] [loss 0.54105544090271]cuda:0 Train... [epoch 1/4, step 300/469] [loss 0.34716445207595825]cuda:1 Train... [epoch 1/4, step 400/469] [loss 0.2694844901561737]
cuda:0 Train... [epoch 1/4, step 400/469] [loss 0.4343942701816559]
epoch 1/4, accuracy = 88.49
cuda:0 Train... [epoch 2/4, step 100/469] [loss 0.19695354998111725]
cuda:1 Train... [epoch 2/4, step 100/469] [loss 0.2911057770252228]
cuda:0 Train... [epoch 2/4, step 200/469] [loss 0.2948791980743408]
cuda:1 Train... [epoch 2/4, step 200/469] [loss 0.292676717042923]
cuda:0 Train... [epoch 2/4, step 300/469] [loss 0.222089946269989]
cuda:1 Train... [epoch 2/4, step 300/469] [loss 0.28814008831977844]
cuda:0 Train... [epoch 2/4, step 400/469] [loss 0.3431250751018524]
cuda:1 Train... [epoch 2/4, step 400/469] [loss 0.2546379864215851]
epoch 2/4, accuracy = 87.31
cuda:1 Train... [epoch 3/4, step 100/469] [loss 0.24118559062480927]cuda:0 Train... [epoch 3/4, step 100/469] [loss 0.363821804523468]cuda:0 Train... [epoch 3/4, step 200/469] [loss 0.36783623695373535]
cuda:1 Train... [epoch 3/4, step 200/469] [loss 0.18346744775772095]
cuda:0 Train... [epoch 3/4, step 300/469] [loss 0.23459288477897644]
cuda:1 Train... [epoch 3/4, step 300/469] [loss 0.2887689769268036]
cuda:0 Train... [epoch 3/4, step 400/469] [loss 0.3079166114330292]
cuda:1 Train... [epoch 3/4, step 400/469] [loss 0.18255220353603363]
epoch 3/4, accuracy = 88.46
cuda:1 Train... [epoch 4/4, step 100/469] [loss 0.27428603172302246]
cuda:0 Train... [epoch 4/4, step 100/469] [loss 0.17705145478248596]
cuda:1 Train... [epoch 4/4, step 200/469] [loss 0.2811894416809082]
cuda:0 Train... [epoch 4/4, step 200/469] [loss 0.22682836651802063]
cuda:0 Train... [epoch 4/4, step 300/469] [loss 0.2291710525751114]
cuda:1 Train... [epoch 4/4, step 300/469] [loss 0.32024848461151123]
cuda:0 Train... [epoch 4/4, step 400/469] [loss 0.24648766219615936]
cuda:1 Train... [epoch 4/4, step 400/469] [loss 0.0805584192276001]
epoch 4/4, accuracy = 89.38
- 下面是1个TPU训练时的控制台输出样例
Launching training on CPU.
xla:0 Train... [epoch 1/4, step 100/938] [loss 0.6051161289215088]
xla:0 Train... [epoch 1/4, step 200/938] [loss 0.27442359924316406]
xla:0 Train... [epoch 1/4, step 300/938] [loss 0.557417631149292]
xla:0 Train... [epoch 1/4, step 400/938] [loss 0.1840067058801651]
xla:0 Train... [epoch 1/4, step 500/938] [loss 0.5252436399459839]
xla:0 Train... [epoch 1/4, step 600/938] [loss 0.2718536853790283]
xla:0 Train... [epoch 1/4, step 700/938] [loss 0.2763175368309021]
xla:0 Train... [epoch 1/4, step 800/938] [loss 0.39897507429122925]
xla:0 Train... [epoch 1/4, step 900/938] [loss 0.28720396757125854]
epoch = 0, accuracy = 86.36
xla:0 Train... [epoch 2/4, step 100/938] [loss 0.24496735632419586]
xla:0 Train... [epoch 2/4, step 200/938] [loss 0.37713131308555603]
xla:0 Train... [epoch 2/4, step 300/938] [loss 0.3106330633163452]
xla:0 Train... [epoch 2/4, step 400/938] [loss 0.40438592433929443]
xla:0 Train... [epoch 2/4, step 500/938] [loss 0.38303741812705994]
xla:0 Train... [epoch 2/4, step 600/938] [loss 0.39199298620224]
xla:0 Train... [epoch 2/4, step 700/938] [loss 0.38932573795318604]
xla:0 Train... [epoch 2/4, step 800/938] [loss 0.26298171281814575]
xla:0 Train... [epoch 2/4, step 900/938] [loss 0.21517205238342285]
epoch = 1, accuracy = 90.07
xla:0 Train... [epoch 3/4, step 100/938] [loss 0.366019606590271]
xla:0 Train... [epoch 3/4, step 200/938] [loss 0.27360212802886963]
xla:0 Train... [epoch 3/4, step 300/938] [loss 0.2014923095703125]
xla:0 Train... [epoch 3/4, step 400/938] [loss 0.21998485922813416]
xla:0 Train... [epoch 3/4, step 500/938] [loss 0.28129786252975464]
xla:0 Train... [epoch 3/4, step 600/938] [loss 0.42534705996513367]
xla:0 Train... [epoch 3/4, step 700/938] [loss 0.22158119082450867]
xla:0 Train... [epoch 3/4, step 800/938] [loss 0.359947144985199]
xla:0 Train... [epoch 3/4, step 900/938] [loss 0.3221997022628784]
epoch = 2, accuracy = 90.36
xla:0 Train... [epoch 4/4, step 100/938] [loss 0.2814193069934845]
xla:0 Train... [epoch 4/4, step 200/938] [loss 0.16465164721012115]
xla:0 Train... [epoch 4/4, step 300/938] [loss 0.2897304892539978]
xla:0 Train... [epoch 4/4, step 400/938] [loss 0.13403896987438202]
xla:0 Train... [epoch 4/4, step 500/938] [loss 0.1135573536157608]
xla:0 Train... [epoch 4/4, step 600/938] [loss 0.14964193105697632]
xla:0 Train... [epoch 4/4, step 700/938] [loss 0.20239461958408356]
xla:0 Train... [epoch 4/4, step 800/938] [loss 0.23625142872333527]
xla:0 Train... [epoch 4/4, step 900/938] [loss 0.3418393135070801]
epoch = 3, accuracy = 90.11
多个服务器、多个程序间控制多个CPU/GPU/TPU
- 详细内容请参考官方Example
- 包括
- 单服务器内,多个程序控制多个计算设备
- 多个服务器间,多个程序控制多个计算设备
- 写好代码后,请先在每个服务器下执行
$ accelerate config生成对应的配置文件,下面是个样例
(huggingface) PS C:\Users\alion\temp> accelerate config
------------------------------------------------------------------------------------------------------------------------In which compute environment are you running?
This machine
------------------------------------------------------------------------------------------------------------------------Which type of machine are you using?
multi-GPU
How many different machines will you use (use more than 1 for multi-node training)? [1]: 2
------------------------------------------------------------------------------------------------------------------------What is the rank of this machine?
0
What is the IP address of the machine that will host the main process? 192.168.101
What is the port you will use to communicate with the main process? 12345
Are all the machines on the same local network? Answer `no` if nodes are on the cloud and/or on different network hosts [YES/no]: yes
Do you wish to optimize your script with torch dynamo?[yes/NO]:no
Do you want to use DeepSpeed? [yes/NO]: no
Do you want to use FullyShardedDataParallel? [yes/NO]: no
Do you want to use Megatron-LM ? [yes/NO]: no
How many GPU(s) should be used for distributed training? [1]:2
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:0
------------------------------------------------------------------------------------------------------------------------Do you wish to use FP16 or BF16 (mixed precision)?
fp16
accelerate configuration saved at C:\Users\alion/.cache\huggingface\accelerate\default_config.yaml
- 最后在每个服务器启动训练脚本
$ accelerate launch example.py(如果你是单台服务器多个程序,那就只启动一台的脚本就完了)
参考链接
- https://github.com/huggingface/accelerate
- https://www.kaggle.com/code/muellerzr/multi-gpu-and-accelerate
- https://github.com/huggingface/notebooks/blob/main/examples/accelerate_examples/simple_nlp_example.ipynb
- https://github.com/huggingface/accelerate/tree/main/examples
相关文章:
PyTorch——利用Accelerate轻松控制多个CPU/GPU/TPU加速计算
PyTorch——利用Accelerate轻松控制多个CPU/GPU/TPU加速计算 前言官方示例单个程序内控制多个CPU/GPU/TPU简单说一下设备环境导包加载数据 FashionMNIST创建一个简单的CNN模型训练函数-只包含训练训练函数-包含训练和验证训练 多个服务器、多个程序间控制多个CPU/GPU/TPU参考链…...
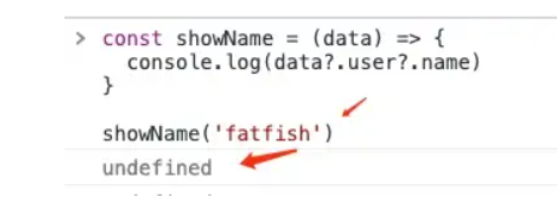
4个很多人都不知道的现代JavaScript技巧
JavaScript在不断的进化和升级,越来越多的新特性让我们的代码变得更加简洁。因此,今天这篇文章,我将跟大家分享 4 个不常用的 JavaScript 运算符。让我们一起研究它们。 1.可选的链接运算符 这个功能非常好用,它可以防止我的代码…...

【Java笔试强训 19】
🎉🎉🎉点进来你就是我的人了博主主页:🙈🙈🙈戳一戳,欢迎大佬指点! 欢迎志同道合的朋友一起加油喔🤺🤺🤺 目录 一、选择题 二、编程题 🔥汽水瓶 …...
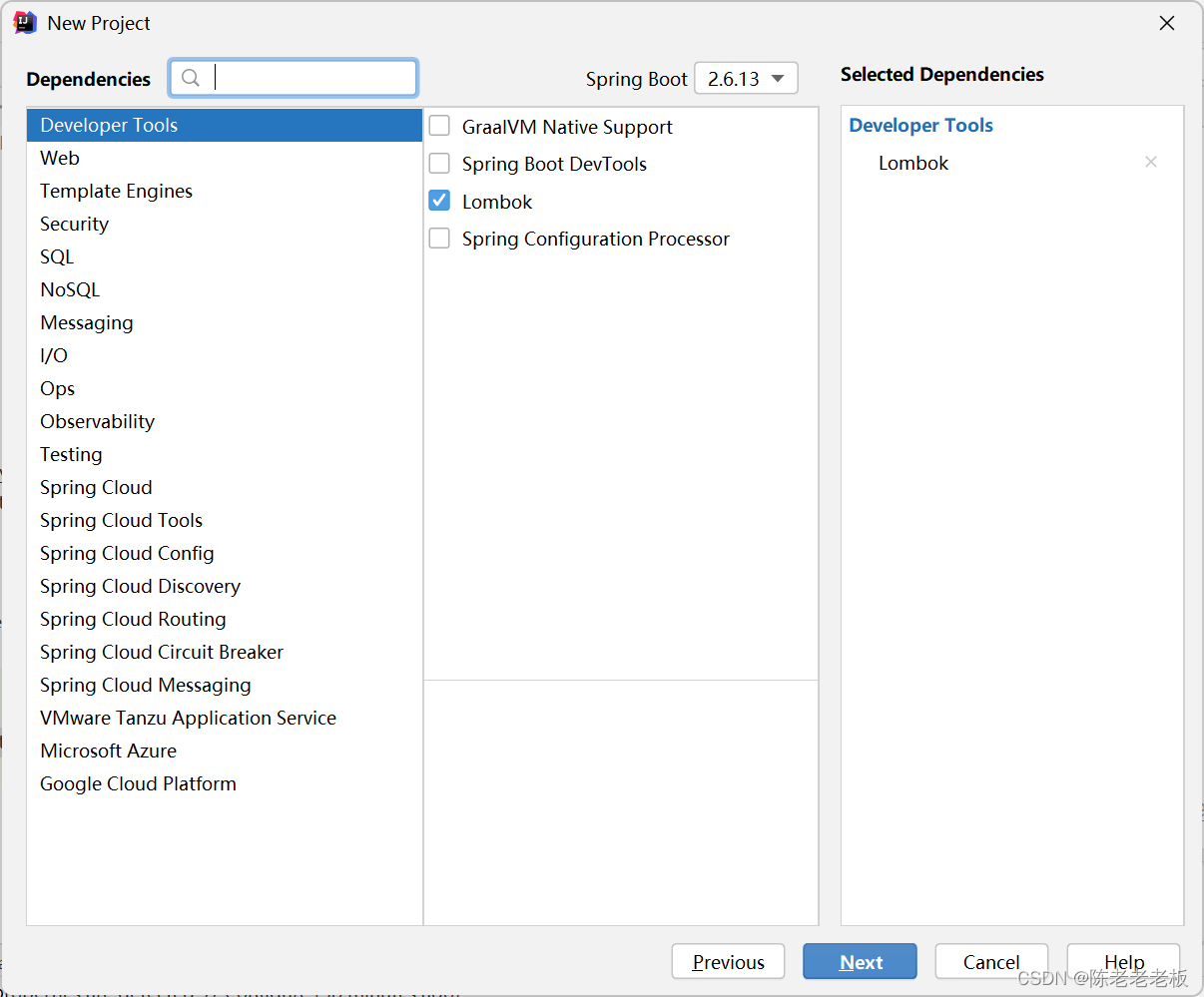
JPA整合达梦数据库
陈老老老板🦸 👨💻本文专栏:国产数据库-达梦数据库(主要讲一些达梦数据库相关的内容) 👨💻本文简述:本文讲一下SpringBoot整合JPA与达梦数据库,就是简单&…...
制药专业转行软件测试,带我的师傅在这干了两年半,最终还是跑路了......
故事的开始 最近这几天有点忧伤,因为带我的师傅要跑路了,嗯,应该说已经跑路了,他是制药专业的,已经在这个公司干了两年半了。其实今年3月份的时候他就跟我说他要跑路了,然后我说,要不你先把五一…...

「SQL面试题库」 No_53 项目员工II
🍅 1、专栏介绍 「SQL面试题库」是由 不是西红柿 发起,全员免费参与的SQL学习活动。我每天发布1道SQL面试真题,从简单到困难,涵盖所有SQL知识点,我敢保证只要做完这100道题,不仅能轻松搞定面试࿰…...

Ruby适用于什么类型的开发
Ruby是一种开源的、解释型的、面向对象的编程语言,由松本行弘(Yukihiro Matsumoto)于1993年首次发布。Ruby语言的设计理念是追求简洁优美,使编程更加人性化,其语法简单、易读、易写,被誉为“程序员的最佳朋…...
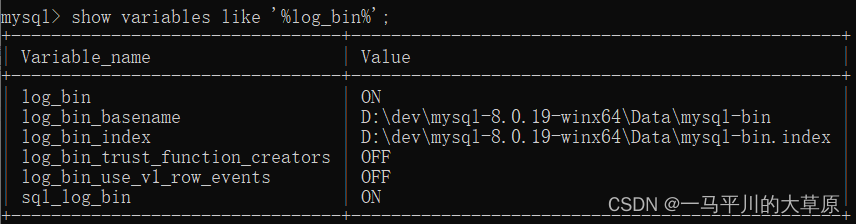
Mysql数据库的备份恢复
最近正在做一个异地数据的定期同步汇总工作,涉及到的数据库主要是Mysql数据库,用于存储现场的一些IOT采集的实时数据,所以做了以下备份恢复测试,现场和总部网络可定期联通,但速度有限,因此计划采用备份恢复…...

C++ 使用动态内存创建一个类
使用动态内存的一个常见原因是允许多个对象共享相同的状态。 例如,假定我们希望定义一个名为Blob 的类,保存一组元素。与容器不同,我们希望Blob对象的不同拷贝之间共享相同的元素。即,当我们拷贝一个Blob时,原Blob对象…...
2023年华中杯选题人数公布
2023年华中杯选题人数公布 经过一晚上代码的编写,论文的写作,C题完整版论文已经发布, 注:蓝色字体为说明备注解释字体,不能出现在大家的论文里。黑色字体为论文部分,大家可以根据红色字体的注记进行摘抄。…...
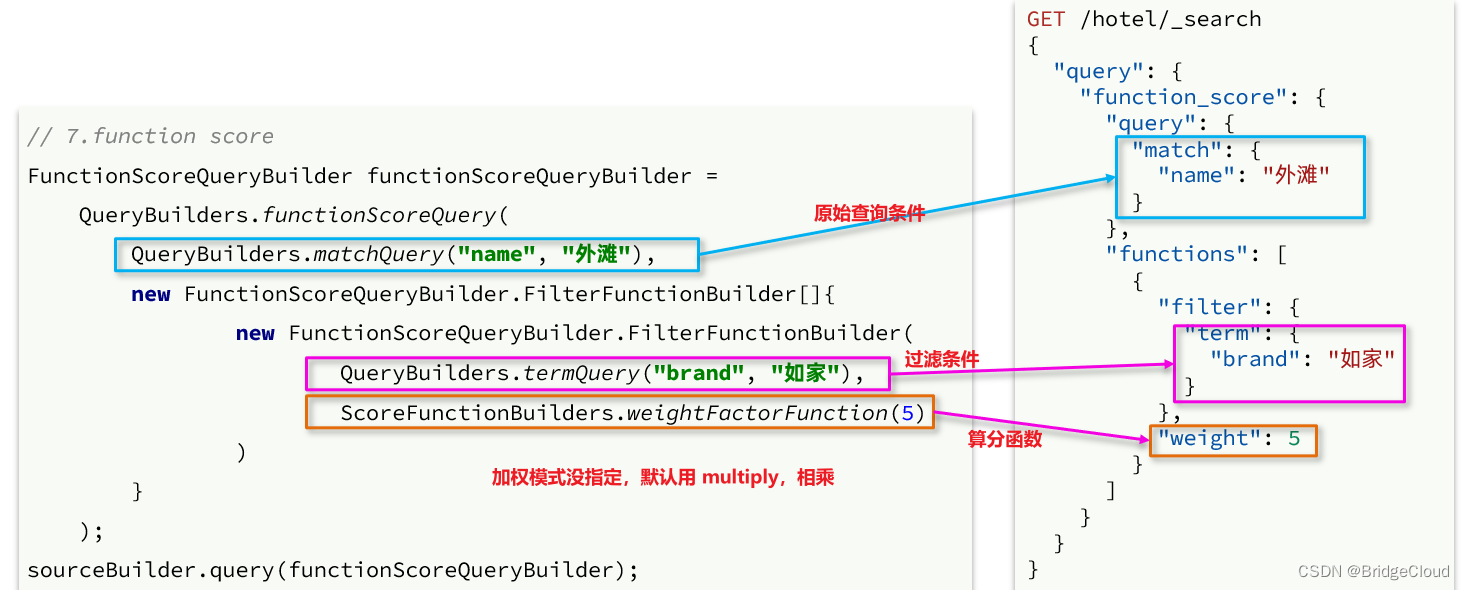
【黑马旅游案例记录(结合ES)】
黑马旅游案例记录 11.9.黑马旅游案例11.9.1.酒店搜索和分页11.9.1.1.需求分析11.9.1.2.定义实体类11.9.1.3.定义controller11.9.1.4.实现搜索业务 11.9.2.酒店结果过滤11.9.2.1.需求分析11.9.2.2.修改实体类11.9.2.3.修改搜索业务 11.9.3.我周边的酒店11.9.3.1.需求分析11.9.3.…...
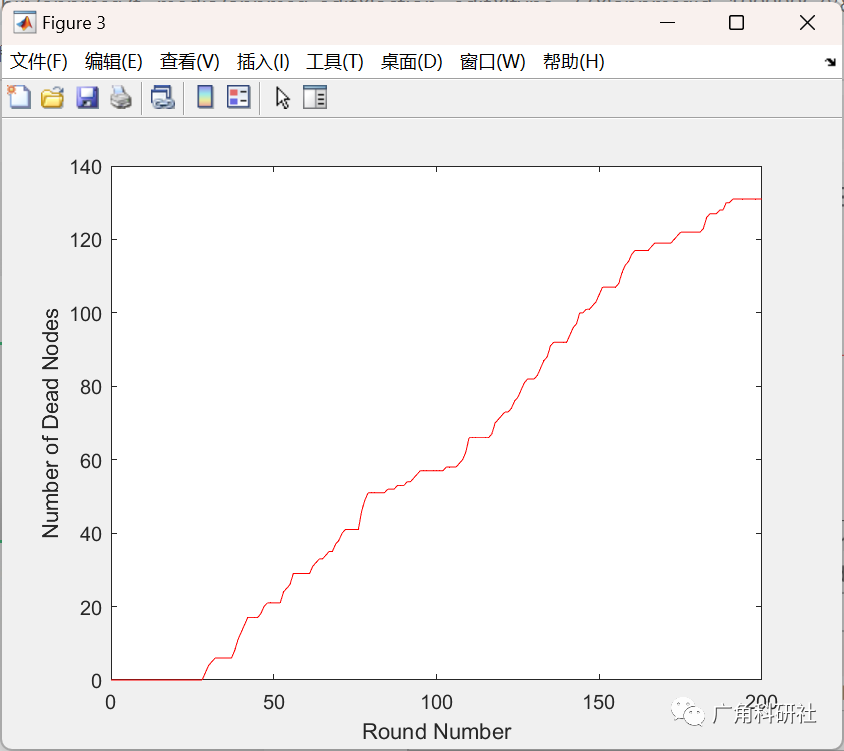
基于 A* 搜索算法来优化无线传感器节点网络的平均电池寿命(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 👨💻4 Matlab代码 💥1 概述 A*(念做:A Star)算法是一种很常用的路径查找和图形遍历算法。它有较好的性能和准确度。本文…...

三款自研AI应用引领未来,重塑行业新风尚
在这个科技日新月异的时代,AI技术已经渗透到我们生活的方方面面。今天,我们将向您推荐三款领域独具特色的AI应用,它们分别是AI律师、AI小红书文案提示词、以及AI Midjourney提示词。这些应用都具有独特的内涵,让我们一起走进这些智…...

Kafka的命令行操作
一、topic命令 下面Windows命令需要把cmd路径切换到bin/windows下。 而Linux命令只需要在控制台切换到bin目录下即可。 下面都以Windows下的操作为例,在Linux下也是一样的。 1.1 查看主题命令的参数 kafka-topics.bat # Windows kafka-topics.sh # Linux输…...
)
递归,回溯,分治(C++刷题笔记)
递归,回溯,分治(C刷题笔记) 78. 子集 力扣 预备知识 nums[][1,2,3],先将子集[1],[1,2],[1,2,3]打印 #include <bits/stdc.h>using namespace std;int main() {vector<int>nums;for (int i1;i<3;i){nums.push_…...
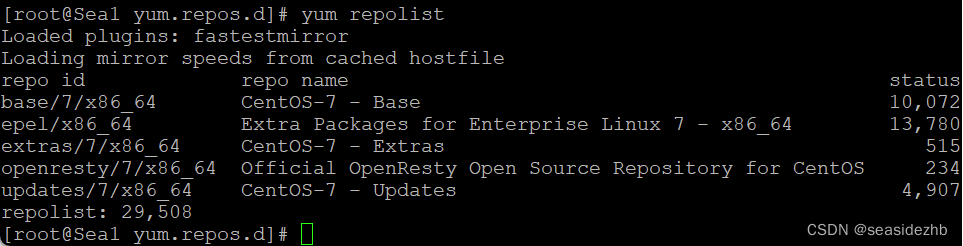
CentOS 7.6更改yum源
使用字符串替换 我这里的操作参考了https://baijiahao.baidu.com/s?id1708418392526536542&wfrspider&forpc这篇文章,https://mirrors.tuna.tsinghua.edu.cn/help/centos/是清华大学官网教程。 /etc/yum.repos.d/CentOS-Base.repo文件如下: #…...

三、进度管理
3、 [单选] 一个项目实施团队需要满足一份非常严格的进度计划。相对于已完成的事项,这样会导致正在进行的工作超过负荷。为了解决这个问题,项目经理需要获得额外的资源。项目经理应该向发起人提供什么理由来支持追加资源的请求? A project im…...

基于LEACH和HEED的WSN路由协议研究与改进(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 👨💻4 Matlab代码 💥1 概述 无线传感器网络是不断发展的传感技术之一,也用于执行不同的任务。这些类型的网络在许多领域都是有益的,…...
)
ChatGPT镜像站收集【Free ChatGPT】(一)
文章目录 Free ChatGPT Site ListLast synced:BeiJingT 2023-04-18妙站站点列表Free ChatGPT Site List 这儿收集了一些免费好用的ChatGPT镜像站点 ⭐:使用不受限🔑:需要进行登录⛔:有限地使用次数后需提供key或进行充值❓ :未测试,未进行标注也为未测试Last synced:BeiJin…...

PHP面试宝典之Mysql数据库基础篇
字符类型: tinyint(4):占1个字节,4代表字段值长度,用0填充,搭配zero fill使用 有符号:取值范围 负128 ~ 正127; 无符号:取值范围 0 ~ 255; 默认无…...

WarcraftHelper:魔兽争霸3终极兼容性增强插件完整指南
WarcraftHelper:魔兽争霸3终极兼容性增强插件完整指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专为《魔兽争霸…...
)
别再死磕PSO了!用Python手把手教你实现GWO灰狼优化算法(附完整代码)
用Python实战GWO灰狼优化算法:告别传统优化方法的局限 在工程优化和机器学习领域,算法选择往往决定了问题求解的效率和质量。传统粒子群优化(PSO)算法虽然广为人知,但其参数调节复杂、易陷入局部最优的缺点也日益明显。灰狼优化算法(Grey Wol…...
:仅向高校科研组开放72小时)
【限时开放】NotebookLM气候专项Prompt Library(含AR6 WGII章节级语义索引模板):仅向高校科研组开放72小时
更多请点击: https://codechina.net 第一章:NotebookLM气候研究辅助概述 NotebookLM 是 Google 推出的基于人工智能的文档理解与推理工具,专为研究人员设计,支持上传 PDF、TXT 等格式的学术文献、观测报告及政策文件,…...

终极英雄联盟工具箱:如何用League Akari提升你的游戏效率与段位
终极英雄联盟工具箱:如何用League Akari提升你的游戏效率与段位 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款…...

别再只仿真了!聊聊12V电源设计中Matlab参数计算与Multisim电路验证的那些事儿
从理论到实践:12V电源设计的Matlab参数计算与Multisim协同验证方法论 在电子工程领域,12V直流稳压电源的设计看似基础,却蕴含着从理论计算到仿真验证的完整知识体系。许多工程师在使用Matlab和Multisim这类工具时,往往陷入"仿…...

长期使用Taotoken的TokenPlan套餐带来的月度成本变化感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken的TokenPlan套餐带来的月度成本变化感受 作为一名中度频率的大模型API使用者,我的日常工作涉及代码生…...

Orange Pi i 96开发板实战:从硬件解析到家庭服务器与物联网应用部署
1. 项目概述:为什么是Orange Pi i 96?最近在捣鼓一些边缘计算和轻量级服务器的项目,手头正好需要一块性能足够、接口丰富但又足够小巧、功耗可控的开发板。市面上树莓派当然是首选,但供货和价格嘛,你懂的。于是我把目光…...

FPGA实战:用Z80与8051软核构建可运行BASIC的复古计算机
1. 项目概述:在FPGA上复活经典8位计算机如果你和我一样,对上世纪七八十年代那些经典的8位计算机架构——比如Zilog Z80和Intel 8051——抱有浓厚的兴趣,同时又对现代FPGA技术着迷,那么这个项目绝对会让你兴奋。它不是一个简单的仿…...

Nacos高可用集群部署实战:从架构设计到生产运维全解析
1. 项目概述:为什么Nacos集群部署是微服务架构的“定海神针”在微服务架构的实践中,服务注册与发现、配置管理是两大基石。Nacos作为Spring Cloud Alibaba生态的核心组件,集这两大功能于一身,其稳定性和可用性直接决定了整个微服务…...

Context-Mode:基于React Context的模式化状态管理新范式
1. 项目概述:一个为现代前端开发量身定制的状态管理新范式 最近在重构一个中后台项目时,我又一次陷入了状态管理的泥潭。组件间层层传递的 props 像一团乱麻,全局 store 里塞满了各种不相关的数据,每次修改一个状态都得小心翼…...