机器学习算法原理:详细介绍各种机器学习算法的原理、优缺点和适用场景
目录
引言
二、线性回归
三、逻辑回归
四、支持向量机
五、决策树
六、随机森林
七、K-均值聚类
八、主成分分析(PCA)
九、K近邻算法
十、朴素贝叶斯分类器
十一、神经网络
十二、AdaBoost
十三、梯度提升树(Gradient Boosting Trees)
十四、聚类算法:DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
十四、XGBoost
十五、Lasso回归与Ridge回归
十六、结论
引言
从基础知识到算法原理的过渡
在我们前面的文章中,我们已经介绍了机器学习和深度学习的基本概念、原理以及它们在现实世界中的应用。经过前几篇文章的铺垫,我们已经了解了机器学习的基本原理和常见应用。现在,我们将进入到机器学习的核心部分——算法原理。在本篇文章中,我们将详细探讨各种机器学习算法的原理、优缺点和适用场景。
机器学习算法的重要性
机器学习算法是实现智能应用的基础。正是因为有了这些算法,我们才能够让计算机从数据中学习并预测未知的结果。这些算法有各自的特点和适用场景,了解它们的原理和特性,有助于我们更好地解决实际问题。此外,深入了解这些算法原理,可以为我们后续学习更复杂的深度学习算法奠定基础。
本文目标:详细介绍各种机器学习算法
本文将对各种机器学习算法进行详细介绍,包括线性回归、逻辑回归、支持向量机、决策树、随机森林、K-均值聚类、主成分分析(PCA)、K近邻算法、朴素贝叶斯分类器、神经网络、AdaBoost、梯度提升树(GBM)、XGBoost、Lasso回归与Ridge回归等。我们将逐一探讨它们的原理、优缺点和适用场景。希望通过本文的阅读,能让您对机器学习算法有一个更加深入的了解,并为您的实际应用提供指导。
(欢迎订阅本专栏,后续将会将本专栏设置成付费专栏,现在订阅不需要付费噢)
二、线性回归
- 算法原理
线性回归(Linear Regression)是一种基本的回归算法,它通过拟合一个线性模型来预测连续型目标变量。线性回归模型的基本形式是:y = w1 * x1 + w2 * x2 + ... + wn * xn + b,其中y是目标变量,x1到xn是特征,w1到wn是模型参数(权重),b是截距项。线性回归的目标是找到一组权重和截距,使得预测值与实际值之间的误差最小。为了实现这一目标,线性回归使用了最小二乘法(Least Squares Method)来最小化预测值与实际值之间的平方误差。
2.优缺点
优点:
a) 算法简单,容易理解和实现。
b) 计算复杂度低,训练速度快。
c) 可解释性强,模型参数有直观的物理意义。
d) 可以通过正则化方法(如Lasso和Ridge)来避免过拟合。
缺点:
a) 线性回归假设特征与目标之间存在线性关系,对于非线性关系的数据拟合效果较差。
b) 对异常值(outliers)敏感,异常值可能导致模型拟合效果较差。
c) 对多重共线性问题(特征间高度相关)敏感,可能导致模型不稳定。
3.适用场景
线性回归适用于以下场景:
a) 预测连续型目标变量,如房价、销售额等。
b) 数据特征与目标变量之间存在线性关系或近似线性关系。
c) 数据量较大,需要快速训练模型时。
d) 需要对模型进行解释时,例如分析各个特征对目标变量的贡献程度。
总之,线性回归是一种简单有效的回归算法,在实际应用中具有较广泛的适
用性。然而,当数据之间存在非线性关系或者特征之间存在多重共线性时,线性回归的表现可能会受到影响。在这种情况下,可以考虑使用其他更复杂的回归方法。
三、逻辑回归
- 算法原理
逻辑回归(Logistic Regression)是一种广泛应用于分类问题的线性模型。虽然它的名字中包含“回归”,但实际上它是一种分类算法。逻辑回归通过sigmoid函数(S型函数)将线性模型的输出转换为概率值,用于表示数据属于某一类的概率。sigmoid函数的公式为:f(z) = 1 / (1 + exp(-z))。逻辑回归模型的目标是找到一组权重和截距,使得预测的概率与实际标签之间的误差最小。为了实现这一目标,逻辑回归使用了极大似然估计(Maximum Likelihood Estimation,MLE)来最大化观测数据的对数似然。
2.优缺点
优点:
a) 算法简单,容易理解和实现。
b) 输出结果具有概率意义,方便进行概率估计和置信度分析。
c) 可以通过正则化方法(如L1和L2正则化)来避免过拟合。
d) 可解释性强,模型参数有直观的物理意义。
缺点:
a) 逻辑回归假设特征与目标之间存在线性关系,对于非线性关系的数据分类效果较差。
b) 对异常值敏感,异常值可能导致模型拟合效果较差。
c) 只能处理二分类问题,对于多分类问题需要进行扩展(如one-vs-rest或one-vs-one方法)。
3.适用场景
逻辑回归适用于以下场景:
a) 二分类问题,如垃圾邮件分类、客户流失预测等。
b) 数据特征与目标变量之间存在线性关系或近似线性关系。
c) 需要对模型进行解释时,例如分析各个特征对目标变量的贡献程度。
逻辑回归虽然简单,但在许多实际问题中表现出良好的分类性能。然而,当数据之间存在非线性关系时,可以考虑使用其他更复杂的分类方法。
四、支持向量机
- 算法原理
支持向量机(Support Vector Machine,SVM)是一种广泛应用于分类和回归问题的机器学习算法。在分类问题中,SVM的目标是找到一个超平面,使得两个类别之间的间隔最大化。这个间隔被称为“最大间隔”,而支持向量机的名称来源于构成这个最大间隔边界的数据点,被称为“支持向量”。
为了解决非线性问题,支持向量机引入了核函数(Kernel Function)。核函数可以将原始特征空间映射到一个更高维度的特征空间,使得原本线性不可分的数据在新的特征空间中变得线性可分。常用的核函数包括:线性核、多项式核、高斯径向基核(Radial Basis Function,RBF)等。
2.优缺点
优点:
a) 在高维数据和小样本数据上表现良好。
b) 可以处理非线性问题,通过选择合适的核函数可以提高分类性能。
c) 具有稀疏性,只有支持向量对模型产生影响,降低了计算复杂度。
缺点:
a) 对于大规模数据集和高维数据,训练速度较慢。
b) 需要选择合适的核函数和调整核函数参数,对参数敏感。
c) 对于多分类问题需要进行扩展,如one-vs-rest或one-vs-one方法。
3.适用场景
支持向量机适用于以下场景:
a) 二分类问题,如手写数字识别、人脸识别等。
b) 数据量较小或中等规模的数据集。
c) 数据具有非线性关系或需要在高维空间进行分类。
支持向量机在许多实际问题中表现出良好的分类性能,尤其是在高维数据和小样本数据上。然而,在大规模数据集和高维数据上,训练速度较慢,可能需要考虑使用其他更高效的分类方法。
五、决策树
- 算法原理
决策树(Decision Tree)是一种常见的机器学习算法,用于解决分类和回归问题。决策树以树状结构表示决策过程,通过递归地将数据集划分为不同的子集,每个子集对应于一个树节点。在每个节点上,根据特征值选择一个最佳的划分方式。常用的划分方式包括信息增益、信息增益比、基尼指数等。划分过程一直进行到达到预先设定的停止条件,如节点内的数据数量小于某个阈值或树的深度达到限制等。
2.优缺点
优点:
a) 模型具有良好的可解释性,容易理解和实现。 b) 可以处理缺失值和异常值,对数据的预处理要求较低。 c) 适用于多种数据类型,包括离散型和连续型特征。
缺点:
a) 容易产生过拟合现象,需要采用剪枝策略来防止过拟合。 b) 对于非线性关系的数据建模能力有限。 c) 决策树的构建过程可能受到局部最优解的影响,导致全局最优解无法达到。
3.适用场景
决策树适用于以下场景:
a) 数据具有混合类型的特征,如离散型和连续型。
b) 需要解释模型的决策过程,如信贷审批、医疗诊断等。
c) 数据集中存在缺失值或异常值。
决策树在很多实际应用中表现出较好的性能,尤其是在具有混合数据类型特征的问题中。然而,决策树容易过拟合,需要采用剪枝策略来防止过拟合,同时对非线性关系建模能力有限。在这种情况下,可以考虑使用随机森林等基于决策树的集成方法。
六、随机森林
- 算法原理
随机森林(Random Forest)是一种基于决策树的集成学习方法。它通过构建多个决策树,并将它们的预测结果进行投票(分类问题)或平均(回归问题),以获得最终的预测结果。随机森林的构建过程包括两个关键步骤:自助采样(bootstrap sampling)和特征随机选择。自助采样用于生成不同的训练数据子集,每个子集用于构建一个决策树。特征随机选择则在每个决策树节点上随机选择一部分特征进行划分,以增加决策树的多样性。这两个步骤共同提高了随机森林的泛化能力和鲁棒性。
2.优缺点
优点:
a) 随机森林具有较高的预测准确性,通常比单个决策树的性能要好。
b) 能够有效地处理高维数据和大量特征。
c) 对噪声和异常值具有较强的鲁棒性。
d) 可以进行特征重要性评估,有助于特征选择。
e) 并行化能力强,易于实现并行计算。
缺点:
a) 相比单个决策树,随机森林的模型可解释性较差。
b) 训练和预测时间可能较长,尤其是在大数据集上。
c) 对于某些不平衡的数据集,随机森林的性能可能不尽如人意。
3.适用场景
随机森林适用于以下场景:
a) 需要提高预测准确性的分类和回归问题。
b) 数据集具有高维特征或特征数量较多。
c) 数据集中存在噪声和异常值。
随机森林在许多实际应用中表现出较好的性能,尤其是在提高预测准确性方面。然而,随机森林的可解释性较差,且在大数据集上训练和预测时间可能较长。在面临这些问题时,可以考虑使用其他集成方法,如梯度提升树(Gradient Boosting Trees)等。
七、K-均值聚类
- 算法原理
K-均值聚类(K-means clustering)是一种迭代的无监督学习算法,用于将数据集划分为K个簇。算法的主要思想是最小化各个簇内样本与其质心的距离之和,以达到数据聚类的目的。K-均值聚类的具体步骤如下:
a) 随机选择K个初始质心。
b) 将每个样本分配到距离其最近的质心所在的簇。
c) 更新每个簇的质心,即计算每个簇内所有样本的均值。
d) 重复步骤b和c,直到质心不再发生变化或达到最大迭代次数。
2.优缺点
优点:
a) 算法简单,易于实现和理解。
b) 计算复杂度较低,适用于大数据集。
c) 可以处理数值型数据。
缺点:
a) 需要预先指定K值,且对K值的选择敏感。
b) 对初始质心的选择敏感,可能陷入局部最优解。
c) 对噪声和异常值敏感。
d) 对于非球形簇或簇大小差异较大的情况,效果可能不佳。
e) 仅适用于数值型数据,不能直接处理离散型数据。
3.适用场景
K-均值聚类适用于以下场景:
a) 数据集中存在一定程度的自然分组,且数据分布较为均匀。
b) 数据集中的特征为数值型。
c) 需要一种简单且计算复杂度较低的聚类方法。
K-均值聚类在许多实际应用中表现出较好的性能,如市场细分、文档聚类、图像压缩等。然而,K-均值聚类对K值的选择、初始质心选择以及噪声和异常值敏感。在面临这些问题时,可以考虑使用其他聚类方法,如DBSCAN、谱聚类等。
八、主成分分析(PCA)
- 算法原理
主成分分析(PCA,Principal Component Analysis)是一种常用的无监督线性降维方法,旨在通过线性投影将原始高维特征空间映射到低维空间,同时保留数据集中的最大方差。PCA 的主要步骤如下:
a) 对数据集进行中心化,即使数据的均值为零。
b) 计算数据集的协方差矩阵。
c) 对协方差矩阵进行特征值分解,得到特征值和特征向量。
d) 按照特征值的大小降序排列特征向量,选择前 k 个特征向量组成投影矩阵。
e) 将原始数据集乘以投影矩阵,得到降维后的数据。
2.优缺点
优点:
a) 能够减少数据的维度,降低计算复杂度。
b) 能够消除特征之间的相关性,简化模型。
c) 在降维过程中尽量保留原始数据的信息。
d) 适用于处理连续型特征。
缺点:
a) 假设数据的主要成分是线性组合,对非线性数据降维效果可能不佳。
b) 对异常值敏感,可能影响主成分的计算。
c) 仅考虑方差最大化,可能忽略其他有用的信息。
d) 不能处理离散型特征。
3.适用场景
主成分分析适用于以下场景:
a) 数据集具有较高的维度,需要降低计算复杂度。 b) 特征之间存在较强的相关性。 c) 需要简化模型,减少过拟合风险。 d) 数据集的特征为连续型。
PCA 在许多实际应用中表现出较好的性能,如图像识别、股票市场分析等。然而,PCA 对非线性数据的降维效果可能不佳,此时可以考虑使用其他降维方法,如核主成分分析(KPCA)、t-分布邻域嵌入算法(t-SNE)等。
九、K近邻算法
- 算法原理
K近邻(K-Nearest Neighbors, KNN)算法是一种基于实例的学习方法,用于分类和回归任务。对于一个给定的输入样本,KNN算法首先找到训练集中与之最接近的K个样本(即K个邻居),然后根据这K个邻居的标签(或输出值)来预测输入样本的类别(或输出值)。
对于分类任务,通常采用投票法,将K个邻居中出现次数最多的类别作为预测结果;对于回归任务,通常采用平均法,将K个邻居的输出值求平均作为预测结果。
2.优缺点
优点:
a) 算法简单,易于实现。
b) 无需训练过程,适应性强。
c) 对于非线性数据具有较好的分类性能。
d) 可用于多分类问题。
缺点:
a) 计算量大,特别是当训练集较大时。
b) 对噪声数据和异常值敏感。
c) 需要事先确定合适的K值和距离度量方法。
d) 没有考虑特征权重,可能影响预测性能。
3.适用场景
K近邻算法适用于以下场景:
a) 数据集规模较小,计算资源充足。
b) 数据集的类别边界不规则,呈现非线性分布。
c) 特征之间的相关性较弱。
d) 对实时性要求较高的场景。
KNN在图像识别、文本分类、推荐系统等领域有广泛应用。
十、朴素贝叶斯分类器
- 算法原理
朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理的概率分类器,它假设特征之间相互独立。朴素贝叶斯分类器首先计算给定样本属于每个类别的后验概率,然后将后验概率最大的类别作为预测结果。
2.优缺点
优点:
a) 算法简单,易于实现。
b) 训练速度快,可在线更新模型。
c) 对于特征维度较高的数据具有较好的性能。
d) 可以处理多分类问题。
缺点:
a) 假设特征之间相互独立,实际应用中这个假设可能不成立。
b) 对于连续型特征需要离散化处理。
c) 需要平滑处理来避免概率为0的情况。
d) 当特征关联性较强时,分类性能可能会受到影响。
3.适用场景
朴素贝叶斯分类器适用于以下场景:
a) 数据集特征维度较高,且特征之间关联性较弱。
b) 对训练时间和模型实时更新有较高要求的场景。
c) 数据集中有缺失值的情况。
朴素贝叶斯分类器在自然语言处理、文本分类、垃圾邮件过滤、情感分析等领域有广泛应用。
十一、神经网络
- 算法原理
神经网络是一种模仿生物神经系统的计算模型,由多个相互连接的神经元组成。神经网络的基本结构包括输入层、隐藏层和输出层。神经网络通过前向传播计算预测值,利用反向传播算法调整权重,以最小化损失函数。
2.优缺点
a) 优点: i. 神经网络具有较强的表达能力,能够逼近复杂的非线性函数。 ii. 可以自动学习特征表示,减少特征工程的工作量。 iii. 可以通过多层结构和大量神经元实现深度学习,提高模型性能。
b) 缺点: i. 训练过程可能较慢,需要大量计算资源。 ii. 对超参数的选择敏感,需要进行调优。 iii. 可解释性相对较差。
3.适用场景
神经网络适用于以下场景:
a) 需要学习复杂模式和高维数据表示的问题。
b) 在计算资源充足的情况下,需要较高预测性能的场景。
神经网络在计算机视觉、自然语言处理、语音识别、推荐系统等领域有广泛应用。
十二、AdaBoost
- 算法原理
AdaBoost(Adaptive Boosting)是一种集成学习方法,通过多次迭代训练一系列弱学习器并加权组合,以提高分类性能。在每次迭代过程中,对错误分类的样本增加权重,使得后续的弱学习器更关注这些样本。最后,将所有弱学习器的预测结果进行加权投票,得到最终分类结果。
2.优缺点
a) 优点:
i. 可以提高模型的准确性和泛化能力。
ii. 算法简单易于实现。 iii. 不容易过拟合。
b) 缺点:
i. 对异常值和噪声敏感,可能导致性能下降。
ii. 训练过程需要依次进行,较难并行化。
3.适用场景
AdaBoost适用于以下场景:
a) 当基学习器性能较弱时,可以通过集成提高性能。
b) 适用于二分类问题,尤其是需要提高分类性能的场景。
AdaBoost在人脸检测、文本分类、客户流失预测等领域有广泛应用。
十三、梯度提升树(Gradient Boosting Trees)
- 算法原理
梯度提升树(GBT)是一种集成学习方法,通过多次迭代训练一系列决策树并加权组合,以提高模型性能。GBT的核心思想是在每轮迭代中拟合前一轮模型的残差,并将新拟合的树的预测结果与前一轮的预测结果相加,以逐步减小损失函数。GBT可以用于回归和分类问题。
2.优缺点
a) 优点: i. 模型性能高,可以处理高维度、非线性、复杂关系的数据。
ii. 可以自动处理缺失值,减少数据预处理工作。
iii. 可以通过特征重要性分析进行特征选择。
b) 缺点: i. 训练过程较慢,需要依次进行,较难并行化。
ii. 对超参数的选择敏感,需要进行调优。
iii. 可能产生过拟合,需要使用正则化方法和早停策略。
3.适用场景
梯度提升树适用于以下场景:
a) 需要处理高维度、非线性、复杂关系的数据。
b) 需要较高预测性能的场景。
梯度提升树在金融风控、广告点击率预测、销售预测等领域有广泛应用。
十四、聚类算法:DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
- 算法原理
DBSCAN是一种基于密度的聚类算法,通过计算样本点之间的密度连接关系,将具有相似密度的样本点归为一类。DBSCAN算法可以发现任意形状的聚类,并能够处理噪声数据。
2.优缺点
a) 优点:
i. 可以发现任意形状的聚类。
ii. 对噪声数据具有较强的鲁棒性。
iii. 无需提前指定聚类数量。
b) 缺点:
i.对超参数的选择敏感,需要进行调优。
ii. 对于不同密度的聚类效果较差。
iii. 当数据量较大时,计算复杂度较高,可能导致较慢的计算速度。
3.适用场景
DBSCAN适用于以下场景:
a) 聚类形状不规则且具有噪声的数据。
b) 聚类数量事先未知。
DBSCAN在异常检测、图像处理、社交网络分析等领域有广泛应用。
十四、XGBoost
- 算法原理
XGBoost(eXtreme Gradient Boosting)是基于梯度提升(Gradient Boosting)的决策树集成学习方法。XGBoost通过加入正则化项,降低模型复杂度,提高泛化能力。同时,XGBoost采用了并行计算和近似算法,显著提高了训练速度。
2.优缺点
优点:
i. 高效的训练速度,支持并行计算。
ii. 高准确率,通过正则化降低过拟合风险。
iii. 支持自定义损失函数和评估指标。
iv. 内置特征重要性排序功能。
缺点:
i. 超参数调优较为复杂。
ii. 需要较多的计算资源。
3.适用场景
XGBoost在以下场景表现优异:
a) 大规模数据集。
b) 需要高准确率的分类和回归任务。
c) 特征选择。
XGBoost在Kaggle竞赛中广泛应用,获得了多次胜利。
十五、Lasso回归与Ridge回归
- 算法原理
Lasso回归(Least Absolute Shrinkage and Selection Operator)和Ridge回归(岭回归)都是线性回归的正则化版本。Lasso回归在损失函数中加入了L1正则化项,促使部分系数变为0,实现特征选择;Ridge回归在损失函数中加入了L2正则化项,减小系数的大小,防止过拟合。
2.优缺点
优点:
i. 降低过拟合风险。
ii. Lasso回归可以实现特征选择。
缺点:
i. 对于高度相关的特征,Lasso回归可能选择其中一些而完全忽略其他特征。
ii. Ridge回归不能实现特征选择。
3.适用场景
Lasso回归和Ridge回归适用于以下场景:
a) 存在多重共线性的数据。
b) 需要进行特征选择的场景(Lasso回归)。
Lasso回归和Ridge回归在金融、医疗、生物信息学等领域有广泛应用。
十六、结论
机器学习算法的多样性与实用性
本文介绍了多种机器学习算法,它们各具特点,适用于不同的场景。了解这些算法及其优缺点有助于为特定问题选择合适的方法。
如何选择合适的算法
选择合适的算法取决于具体问题、数据特点和业务需求。以下是一些建议:
a) 充分了解数据:分析数据的分布、特征相关性、样本数量等,有助于选择合适的算法。
b) 尝试不同的算法:在实际应用中,可以尝试多种算法,通过交叉验证和模型评估选择最优模型。
c) 考虑模型的可解释性和复杂度:在某些场景下,可解释性可能比精确度更重要,如金融、医疗等领域。简单的模型可能更易于理解和解释。
d) 考虑计算资源和训练时间:根据可用的计算资源和时间限制,选择适当的算法。
在接下来的文章中,我们将深入探讨深度学习算法的原理,如卷积神经网络、循环神经网络等。此外,我们还将介绍如何将这些算法应用于实际问题,帮助读者在实战中掌握机器学习和深度学习技术。
相关文章:

机器学习算法原理:详细介绍各种机器学习算法的原理、优缺点和适用场景
目录 引言 二、线性回归 三、逻辑回归 四、支持向量机 五、决策树 六、随机森林 七、K-均值聚类 八、主成分分析(PCA) 九、K近邻算法 十、朴素贝叶斯分类器 十一、神经网络 十二、AdaBoost 十三、梯度提升树(Gradient Boosting T…...

Spring Security 6.0系列【32】授权服务器篇之默认过滤器
有道无术,术尚可求,有术无道,止于术。 本系列Spring Boot 版本 3.0.4 本系列Spring Security 版本 6.0.2 本系列Spring Authorization Server 版本 1.0.2 源码地址:https://gitee.com/pearl-organization/study-spring-security-demo 文章目录 前言1. OAuth2Authorizati…...

.NET中比肩System.Text.Json序列化反序列化组件MessagePack
简介 官方定义:MessagePack是一种高效的二进制序列化格式。它允许您像JSON一样在多个语言之间交换数据。但是它更快并且更小。 MessagePack是一种开源的序列化反序列化组件,可支持JAVA,C#等主流语言。在 C# 中使用 MessagePack,…...

Oracle删除列操作:逻辑删除和物理删除
概念 逻辑删除:逻辑删除并不是真正的删除,而是将表中列所对应的状态字段(status)做修改操作,实际上并未删除目标列数据或恢复这些列占用的磁盘空间。比如0是未删除,1是删除。在逻辑上数据是被删除了&#…...

找出字符串中第一个匹配项的下标、求解方程----2023/5/2
找出字符串中第一个匹配项的下标、求解方程----2023/5/2 给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1…...

23:宁以non-member、non-friend替换member函数
想象有个class用来表示网页浏览器。这样的class可能提供的众多函数中,有一些用来清除下载元素高速缓存区、清除访问过的URLs的历史记录、以及移除系统中的所有cookies: class WebBrowser{ public:void clearCache();void clearHistory();void removeCoo…...

Centos7安装Redis
一、安装gcc依赖 由于 redis 是用 C 语言开发,安装之前必先确认是否安装 gcc 环境(gcc -v),如果没有安装,执行以下命令进行安装 [rootlocalhost local]# yum install -y gcc 二、下载并解压安装包 [rootlocalhost l…...

Android 项目必备(四十五)-->2023 年如何构建 Android 应用程序
Android 是什么 Android 是一种基于 Linux 内核并由 Google 开发的开源操作系统。它用于各种设备包括智能手机、平板电脑、电视和智能手表。 目前,Android 是世界上移动设备使用最多的操作系统; 根据 statcounter 的一份最近 12 个月的样本报告;Android 的市场份额…...
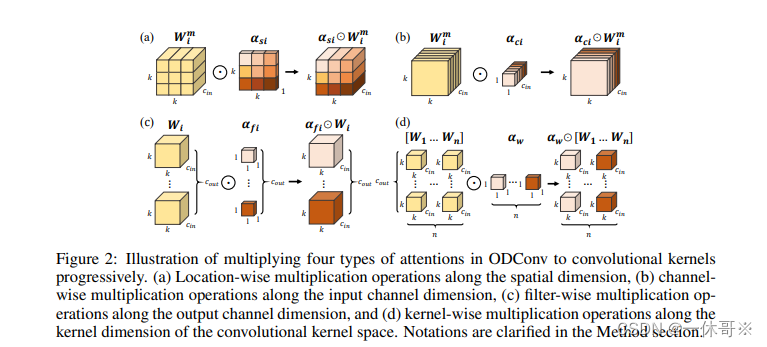
改进YOLOv5: | 涨点神器 | 即插即用| ICLR 2022!Intel提出ODConv:即插即用的动态卷积
OMNI-DIMENSIONAL DYNAMIC CONVOLUTION ODConv实验核心代码ODConv代码yaml文件运行:论文链接: https://openreview.net/forum?id=DmpCfq6Mg39 本文介绍了一篇动态卷积的工作:ODConv,其通过并行策略采用多维注意力机制沿核空间的四个维度学习互补性注意力。作为一种“即插…...
( 数组和矩阵) 485. 最大连续 1 的个数 ——【Leetcode每日一题】
❓485. 最大连续 1 的个数 难度:简单 给定一个二进制数组 nums , 计算其中最大连续 1 的个数。 示例 1: 输入:nums [1,1,0,1,1,1] 输出:3 解释:开头的两位和最后的三位都是连续 1 ,所以最大…...

从0搭建Vue3组件库(十一): 集成项目的编程规范工具链(ESlint+Prettier+Stylelint)
欲先善其事,必先利其器。一个好的项目是必须要有一个统一的规范,比如代码规范,样式规范以及代码提交规范等。统一的代码规范旨在增强团队开发协作、提高代码质量和打造开发基石,所以每个人必须严格遵守。 本篇文章将引入 ESLintPrettierStylelint 来对代码规范化。 ESlint ES…...
Mysql 苞米豆 多数据源 读写分离(小项目可用)
目录 0 课程视频 1 配置 1.1 加依赖 1.2 yml 配置文件 -> druid配置后报错 搞不定 2 代码 2.1 实体类 2.2 mapper -> 调用操作数据库方法 操作数据库 2.3 service -> 指定数据源 -> 用Mapper 接口 -> 操作数据库 2.4 controller -> 用户使用接口 -&…...

OJ练习第90题——删除字符使频率相同
删除字符使频率相同 力扣链接:2423. 删除字符使频率相同 题目描述 给你一个下标从 0 开始的字符串 word ,字符串只包含小写英文字母。你需要选择 一个 下标并 删除 下标处的字符,使得 word 中剩余每个字母出现 频率 相同。 如果删除一个字…...
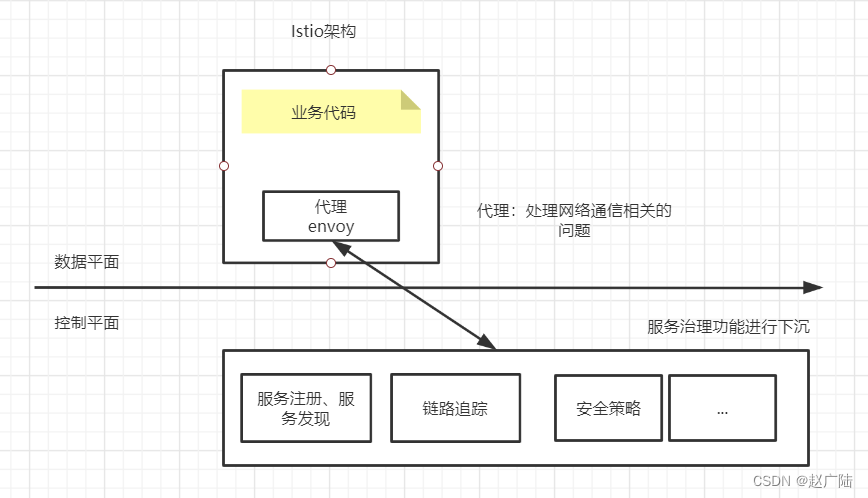
云原生Istio基本介绍
目录 1 什么是Istio2 Istio特征2.1 连接2.2 安全2.3 策略2.4 观察 3 Istio与服务治理3.1服务治理的三种形态 4 Istio与Kubernetes4.1 Kubernetes介绍4.2 Istio是Kubernetes的好帮手4.3 Kubernetes是Istio的好基座 5 Istio与服务网格5.1 时代选择服务网格5.2 服务网格选择Istio …...
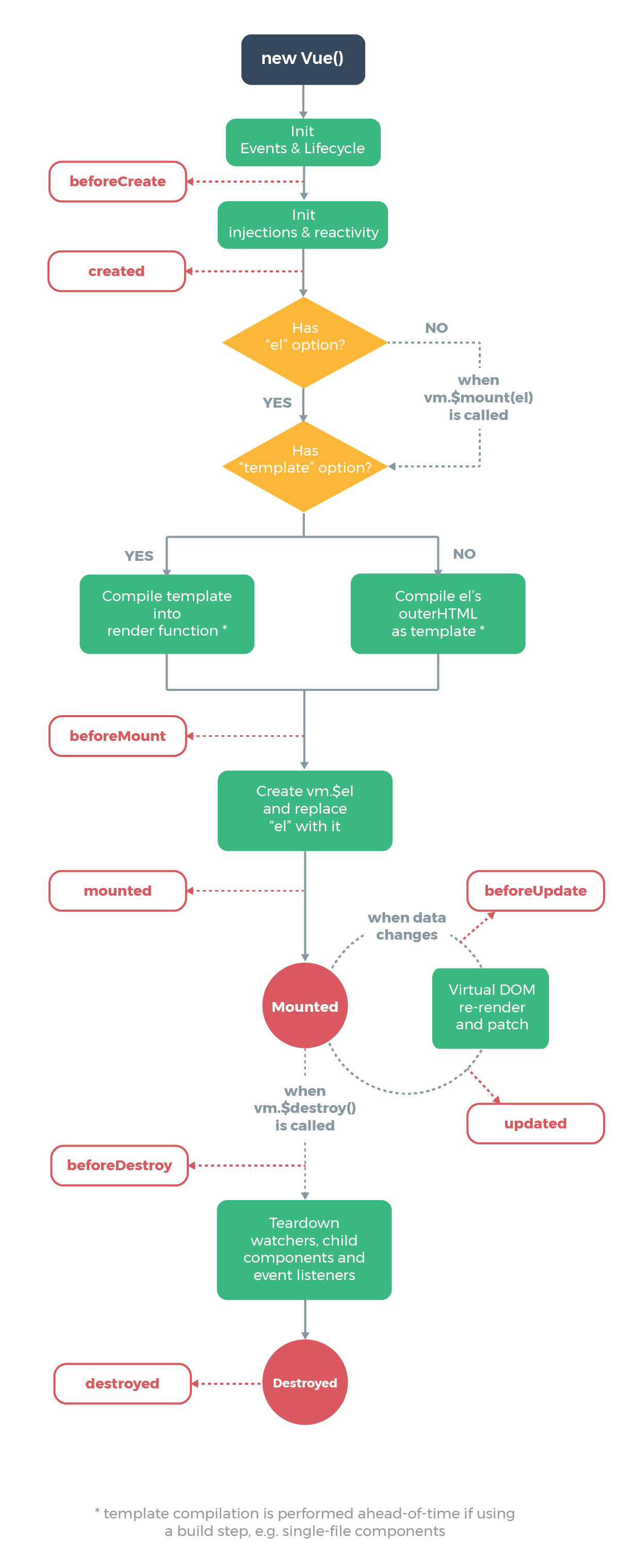
Vue(简单了解Cookie、生命周期)
一、了解Cookie 类似于对象响应携带数据 输入用户名密码跳转到指定页面 点击指定页面中其中一个按钮跳转到另一个指定页面(再不需用输入用户名密码) 例如现在很多浏览器实现七天免密登录 简单理解:就是在网站登录页面之后,服务…...

57.网页设计图标实战
首先我们需要找一个图标库,本次演示采用的是heroicon ● 之后我们根据需求搜索与之想匹配的图标并复制svg代码 ● 之后将我们的代码复制到我们想要放置图标的地方 ● 当然我们需要使用CSS来修饰一下 .features-icon {stroke: #087f5b;width: 32px;height: 3…...

浅析AI视频智能检测技术在城市管理中的场景应用
随着中国的城市建设和发展日益加快,城镇化过程中重建设、轻管理模式带来不少管理难点,传统城管模式存在违法问题多样、缺乏源头治理、业务协同难、取证手段单一等,人员不足问题进一步加剧管理难度。随着移动互联网、物联网、云计算、大数据、…...

unity中的Line Renderer
介绍 unity中的Line Renderer 方法 首先,Line Renderer 是 Unity 引擎中的一个组件,它可以生成直线、曲线等形状,并且在场景中呈现。通常情况下,Line Renderer 被用来实现轨迹、路径、线框渲染以及射线可视化等功能。 在使用 …...
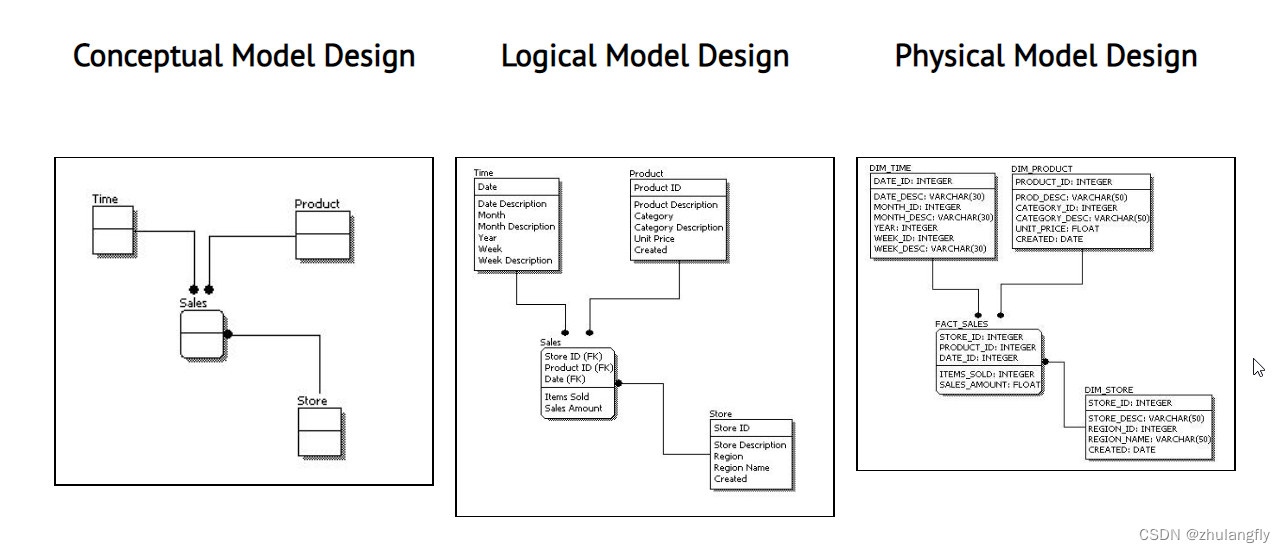
【数据架构系列-06】一文搞懂数据模型的3中类型——概念模型、逻辑模型、物理模型
数据模型就是模拟现实世界的方法论,是通向智慧世界的基石! 从现实世界发展到智慧世界,要数经历现实世界、信息世界、计算机世界、数据世界、智慧世界五个不同的世界,我们天生具有从混沌的世界抽象信息变为信息世界的能力ÿ…...

Java——Java面向对象
该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架。 概述: Java是面向对象的程序…...

ARM Boot Monitor与闪存编程实战指南
1. ARM Boot Monitor核心功能解析Boot Monitor是ARM架构嵌入式系统中的核心启动管理组件,它相当于系统的"第一响应者",负责硬件初始化、启动流程控制和运行时服务提供。这个不足100KB的微型系统却承担着三大关键职责:硬件抽象层&am…...

基于MCP协议构建AI工具服务器:连接Web与AI的标准化适配器
1. 项目概述:一个连接Web与AI的“万能适配器”如果你正在尝试让AI助手(比如ChatGPT、Claude)去访问一个网站、查询实时天气、或者控制你的智能家居,你可能会发现一个核心难题:这些大模型本身是“离线”的,它…...

终极指南:3步彻底解决腾讯游戏ACE-Guard卡顿,免费提升游戏性能
终极指南:3步彻底解决腾讯游戏ACE-Guard卡顿,免费提升游戏性能 【免费下载链接】sguard_limit 限制ACE-Guard Client EXE占用系统资源,支持各种腾讯游戏 项目地址: https://gitcode.com/gh_mirrors/sg/sguard_limit 你是否在玩《英雄联…...

从零到一:uni-app多端应用集成i18n国际化的完整实践指南
1. 为什么需要国际化? 第一次接触国际化需求时,我也以为就是简单的文本翻译。直到实际开发中遇到阿拉伯语从右向左排版、德语超长文本撑破布局、日语敬语体系等复杂场景,才发现国际化远不止翻译这么简单。国际化(i18n)…...
)
一文读懂大模型Agent工作流:小白也能学会的AI新玩法(收藏版)
本文深入解析了AI Agent和Agent工作流的核心概念,阐述了AI代理如何通过工作流实现复杂任务的自动化。文章详细介绍了AI Agent的组成部分,包括推理、工具和记忆,并解释了Agent工作流的组成要素和不同模式。此外,还探讨了Agent工作流…...

GA/T 1400视图库实战:从零部署Easy1400平台到设备级联全流程解析
1. 初识GA/T 1400与Easy1400平台 第一次接触GA/T 1400标准时,我完全被各种专业术语绕晕了。简单来说,这是一套专门针对视频监控领域的行业标准,规定了视频图像信息在采集、传输、存储等环节的技术要求。而Easy1400就是基于这个标准开发的一套…...

Agent OS:AI智能体开发的操作系统级解决方案
1. 项目概述:一个为AI智能体而生的操作系统最近在AI智能体开发圈子里,一个名为“Agent OS”的项目热度持续攀升。它来自Rivet.dev团队,定位非常清晰:一个专为构建、运行和管理AI智能体而设计的操作系统。如果你正在尝试将大语言模…...
)
告别内置ADC的烦恼:用ADS1119搞定STM32/DSP的高精度电压采样(附完整代码)
告别内置ADC的烦恼:用ADS1119搞定STM32/DSP的高精度电压采样(附完整代码) 在嵌入式系统开发中,电压采样是基础却至关重要的环节。许多工程师在使用STM32或DSP内置ADC时,常会遇到精度不足、抗干扰能力差、无法测量差分信…...

FanControl终极指南:免费开源的风扇控制神器,轻松解决Windows散热与噪音问题
FanControl终极指南:免费开源的风扇控制神器,轻松解决Windows散热与噪音问题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https:…...
在Windows下的详细评测与实战技巧)
Kafka运维新选择:Offset Explorer(Kafka Tool)在Windows下的详细评测与实战技巧
Kafka运维新选择:Offset Explorer在Windows下的深度评测与高阶实战 当Kafka集群规模从几个节点扩展到数十甚至上百个Broker时,命令行工具kafka-topics.sh和kafka-console-consumer.sh开始显得力不从心。这时,一个得力的可视化工具就像黑暗中的…...