Perf工具统计CPU性能
Perf 性能检测工具
Perf 是一个内置于Linux内核中的工具,用于性能分析和调优。它可以对系统的CPU使用情况、内存使用情况、磁盘I/O、网络I/O等进行监控和分析,并提供了丰富的分析和可视化工具,以帮助用户定位和解决性能问题。perf可以进行函数级和指令级的热点查找,以帮助用户发现应用程序中的性能瓶颈。perf还支持事件采样、跟踪和调试等功能,可以帮助用户深入了解系统和应用程序的运行状况。由于perf是一个内核级别的工具,因此它可以对系统的性能进行非常深入的分析,并且对系统的开销非常小。perf已经成为了Linux系统中非常常用的性能分析工具之一。
perf --help
perf --helpusage: perf [--version] [--help] [OPTIONS] COMMAND [ARGS]The most commonly used perf commands are:annotate 解析perf record生成的perf.data文件,显示被注释的代码。archive 根据数据文件记录的build-id,将所有被采样到的elf文件打包。利用此压缩包,可以再任何机器上分析数据文件中记录的采样数据。bench perf中内置的benchmark,目前包括两套针对调度器和内存管理子系统的benchmark。buildid-cache 管理perf的buildid缓存,每个elf文件都有一个独一无二的buildid。buildid被perf用来关联性能数据与elf文件。buildid-list 列出数据文件中记录的所有buildid。c2c Shared Data C2C/HITM Analyzer.config Get and set variables in a configuration file.daemon Run record sessions on backgrounddata Data file related processingdiff 对比两个数据文件的差异。能够给出每个符号(函数)在热点分析上的具体差异。evlist 列出数据文件perf.data中所有性能事件。ftrace simple wrapper for kernel's ftrace functionalityinject 该工具读取perf record工具记录的事件流,并将其定向到标准输出。在被分析代码中的任何一点,都可以向事件流中注入其它事件。iostat Show I/O performance metricskallsyms Searches running kernel for symbolskmem 针对内核内存(slab)子系统进行追踪测量的工具kvm 用来追踪测试运行在KVM虚拟机上的Guest OS。list 列出当前系统支持的所有性能事件。包括硬件性能事件、软件性能事件以及检查点。lock 分析内核中的锁信息,包括锁的争用情况,等待延迟等。mem 内存存取情况record 收集采样信息,并将其记录在数据文件中。随后可通过其它工具对数据文件进行分析。report 读取perf record创建的数据文件,并给出热点分析结果。sched 针对调度器子系统的分析工具。script 执行perl或python写的功能扩展脚本、生成脚本框架、读取数据文件中的数据信息等。stat 执行某个命令,收集特定进程的性能概况,包括CPI、Cache丢失率等。test perf对当前软硬件平台进行健全性测试,可用此工具测试当前的软硬件平台是否能支持perf的所有功能。timechart 针对测试期间系统行为进行可视化的工具top 类似于linux的top命令,对系统性能进行实时分析。version display the version of perf binaryprobe 用于定义动态检查点。trace 关于syscall的工具。See 'perf help COMMAND' for more information on a specific command.
Ubuntu20.04安装Perf工具
sudo apt install linux-tools-common
sudo apt install linux-tools-5.13.0-40-generic
sudo apt install linux-cloud-tools-5.13.0-40-generic
记录一段时间内系统/进程的性能事件
perf record
常用参数
-e:选择性能事件-p:待分析进程的id-t:待分析线程的id-a:分析整个系统的性能,即所有CPU采样-C:只采集指定CPU数据-c:事件的采样周期-o:指定输出文件,默认为perf.data-A:以append的方式写输出文件-f:以OverWrite的方式写输出文件-g:记录函数间的调用关系
例子
perf record -a -e cycles -o cycle.perf -g sleep 10
[ perf record: Woken up 18 times to write data ]
[ perf record: Captured and wrote 4.953 MB cycle.perf (~216405 samples) ]
读取生成的数据文件,并显示分析数据
perf report
常用参数
-i:输入的数据文件
-v:显示每个符号的地址
-d <dos>:只显示指定dos的符号
-C:只显示指定comm的信息(Comm. 触发事件的进程名)
-S:只考虑指定符号
-U:只显示已解析的符号
-g[type,min,order]:显示调用关系,具体等同于perf top命令中的-g
-c:只显示指定cpu采样信息
-M:以指定汇编指令风格显示
–source:以汇编和source的形式进行显示
-p<regex>:用指定正则表达式过滤调用函数
例子
perf report -i cycle.perf | more
# To display the perf.data header info, please use --header/--header-only options.
#
#
# Total Lost Samples: 0
#
# Samples: 34K of event 'cpu-clock'
# Event count (approx.): 8508750000
#
# Children Self Command Shared Object Symbol
# ........ ........ ............... .......................... ...............................................
#99.20% 0.00% swapper [kernel.kallsyms] [k] 0xffffffff90c00107|---0xffffffff90c00107||--49.81%--0xffffffff92e94731| 0xffffffff92e9462d| 0xffffffff92e95c3e| 0xffffffff92e953fb| 0xffffffff91963c73| 0xffffffff90d09be0| || --49.81%--0xffffffff90d099a4| 0xffffffff90d096b3| 0xffffffff9164cbde| 0xffffffff9164c607| || --49.79%--0xffffffff919731eb| || --49.78%--0xffffffff91972a5b|--49.39%--0xffffffff90c7d81a0xffffffff90d09be0|--49.39%--0xffffffff90d099a40xffffffff90d096b30xffffffff9164cbde|--49.38%--0xffffffff9164c607|--49.37%--0xffffffff919731eb0xffffffff91972a5b99.20% 0.00% swapper [kernel.kallsyms] [k] 0xffffffff90d09be0|---0xffffffff90d09be0|--99.19%--0xffffffff90d099a40xffffffff90d096b30xffffffff9164cbde|--99.19%--0xffffffff9164c607|--99.16%--0xffffffff919731eb|--99.15%--0xffffffff91972a5b--More--
实时显示系统/进程的性能统计信息
perf top
常用参数
-e:指定性能事件
-a:显示在所有CPU上的性能统计信息
-C:显示在指定CPU上的性能统计信息
-p:指定进程PID
-t:指定线程TID
-K:隐藏内核统计信息
-U:隐藏用户空间的统计信息
-s:指定待解析的符号信息
‘‐G’ or‘‐‐call‐graph’ <output_type,min_percent,call_order>
graph: 使用调用树,将每条调用路径进一步折叠。这种显示方式更加直观。
每条调用路径的采样率为绝对值。也就是该条路径占整个采样域的比率。
fractal
默认选项。类似与 graph,但是每条路径前的采样率为相对值。
flat
不折叠各条调用
选项 call_order 用以设定调用图谱的显示顺序,该选项有 2个取值,分别是
callee 与caller。
将该选项设为callee 时,perf按照被调用的顺序显示调用图谱,上层函数被下层函数所调用。
该选项被设为caller 时,按照调用顺序显示调用图谱,即上层函数调用了下层函数路径,也不显示每条调用路径的采样率
注: Perf top需要root权限
例子
sudo perf top -g
Samples: 1K of event 'cpu-clock:pppH', 4000 Hz, Event count (approx.): 251003285 lost: 0/0 drop: 0/0Children Self Shared Object Symbol
+ 42.35% 0.15% perf [.] __dso__load_kallsyms
+ 36.54% 0.10% [kernel] [k] vfs_read
+ 35.50% 0.05% libpthread-2.31.so [.] __libc_read
+ 35.50% 0.10% [kernel] [k] ksys_read
+ 35.15% 0.05% [kernel] [k] proc_reg_read
+ 35.10% 0.10% [kernel] [k] seq_read
+ 34.48% 0.72% [kernel] [k] seq_read_iter
+ 26.92% 0.41% [kernel] [k] s_show
+ 26.62% 0.46% [kernel] [k] seq_printf
+ 26.10% 0.41% [kernel] [k] seq_vprintf
+ 22.84% 5.11% [kernel] [k] vsnprintf
+ 22.52% 0.28% [kernel] [k] do_user_addr_fault
+ 21.86% 0.19% [kernel] [k] __handle_mm_fault
+ 20.94% 0.36% libc-2.31.so [.] __stpncpy_sse2_unaligned
+ 20.60% 0.29% [kernel] [k] get_page_from_freelist
+ 20.60% 0.05% [kernel] [k] __alloc_pages
+ 19.69% 19.69% [kernel] [k] clear_page_orig
+ 6.98% 3.36% [kernel] [k] __softirqentry_text_start
+ 6.73% 0.80% [kernel] [k] cpuidle_enter_state
+ 6.54% 0.26% [kernel] [k] s_next
+ 6.50% 6.40% [kernel] [k] __lock_text_start
+ 6.44% 0.56% [kernel] [k] update_iter6.33% 6.33% [kernel] [k] format_decode
+ 6.23% 0.66% [kernel] [k] pointer5.72% 5.72% [kernel] [k] number
+ 5.36% 0.72% [kernel] [k] string4.65% 4.44% [kernel] [k] string_nocheck
For a higher level overview, try: perf top --sort comm,dso
perf output 监控接口在多个列中显示数据:
-
Children列表示该符号名下调用函数性能事件在所有采样中的比例
-
Overhead列显示函数或库占用的 CPU 百分比。
-
Shared Object列显示使用函数的程序或库的名称。
-
Symbol列显示功能名称或符号。在内核空间中执行的功能由
[k]标识,在用户空间中执行的功能由[.]标识。
用于分析指定程序的性能概况
perf stat
常用参数
-e:选择性能事件
-i:禁止子任务继承父任务的性能计数器。
-r:重复执行 n 次目标程序,并给出性能指标在n 次执行中的变化范围。
-n:仅输出目标程序的执行时间,而不开启任何性能计数器。
-a:指定全部cpu
-C:指定某个cpu
-A:将给出每个处理器上相应的信息。
-p:指定待分析的进程id
-t:指定待分析的线程id
例子
# perf stat
sudo perf stat ib_send_bw -d rxe0 -R -s 2M 192.168.159.131
---------------------------------------------------------------------------------------Send BW TestDual-port : OFF Device : rxe0Number of qps : 1 Transport type : IBConnection type : RC Using SRQ : OFFTX depth : 128CQ Moderation : 100Mtu : 1024[B]Link type : EthernetGID index : 2Max inline data : 0[B]rdma_cm QPs : ONData ex. method : rdma_cm
---------------------------------------------------------------------------------------local address: LID 0000 QPN 0x0017 PSN 0xa67937GID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:159:131remote address: LID 0000 QPN 0x0018 PSN 0xf8296aGID: 00:00:00:00:00:00:00:00:00:00:255:255:192:168:159:131
---------------------------------------------------------------------------------------#bytes #iterations BW peak[MB/sec] BW average[MB/sec] MsgRate[Mpps]2097152 1000 228.77 205.87 0.000103
---------------------------------------------------------------------------------------Performance counter stats for 'ib_send_bw -d rxe0 -R -s 2M 192.168.159.131':10,027.98 msec task-clock # 0.993 CPUs utilized143 context-switches # 14.260 /sec1 cpu-migrations # 0.100 /sec1,260 page-faults # 125.648 /sec<not supported> cycles<not supported> instructions<not supported> branches<not supported> branch-misses10.100792733 seconds time elapsed0.274651000 seconds user9.542177000 seconds sys输出解释如下:
task-clock:任务真正占用的处理器时间,单位为ms
CPUs utilized = task-clock/time elapsed (CPU的占用率)
context-swichees:程序在运行过程中的上下文切换次数
CPU-migrations:程序在运行过程中发生的处理器迁移次数。Linux为了维持多个处理器的负载均衡在特定条件下会将某个任务从一个CPU迁移到另一个CPU。CPU迁移和上下文切换:发生上下文切换不一定会发生CPU迁移,而发生CPU迁移时肯定会发生上下文切换。发生上下文切换有可能只是把上下文从当前CPU换出,下一次调度器还是将进程安排在这个CPU上执行。
page-faults:缺失异常的次数。当应用程序请求的页面尚未建立,请求的页面不在内存中,或者请求的页面虽然在内存中,但物理地址和虚拟地址的映射关系尚未建立时,都会触发一次却也异常。另外TLB不命中,页面访问权限不匹配等情况也会触发缺页异常。
cycles:消耗的处理器周期数。
stalled-cycles-frontend:指令读取或解码的步骤,未能按理想状态发挥并行左右,发生停滞的时钟周期。
stalled-cycles-backend:指令执行步骤,发生停滞的时钟周期。
instructions:执行了多少条指令。IPC为平均每个cpu cycle执行了多少条指令。
branches:遇到的分支指令数。
branch-misses :是预测错误的分支指令数。
相关示例
perf top -e cycles:k #显示内核和模块中,消耗最多CPU周期的函数perf top -e kmem:kmem_cache_alloc #显示分配高速缓存最多的函数perf top -g #得到调用关系图perf top -e cycles #指定性能事件perf top -p 23015,32476 #查看这两个进程的cpu cycles使用情况perf top -s comm,pid,symbol #显示调用symbol的进程名和进程号perf top --comms nginx,top #仅显示属于指定进程的符号perf top --symbols kfree #仅显示指定的符号perf stat -r 10 ls > /dev/null #执行10次程序,给出标准偏差与期望的比值perf stat -v ls > /dev/null #显示更详细的信息perf stat -n ls > /dev/null #只显示任务执行时间,不显示性能计数器perf stat -a -A ls > /dev/null #单独给出每个CPU上的信息perf stat -C 0 #统计CPU 0的信息perf stat -e syscalls:sys_enter ls #ls命令执行了多少次系统调用perf record -p `pgrep -d ',' nginx` #记录nginx进程的性能数据perf record ls -g #记录执行ls时的性能数据perf record -e syscalls:sys_enter ls #记录执行ls时的系统调用,可以知道哪些系统调用最频繁perf lock record ls #记录perf lock report #报告Name:内核锁的名字。
aquired:该锁被直接获得的次数,因为没有其它内核路径占用该锁,此时不用等待。
contended:该锁等待后获得的次数,此时被其它内核路径占用,需要等待。
total wait:为了获得该锁,总共的等待时间。
max wait:为了获得该锁,最大的等待时间。
min wait:为了获得该锁,最小的等待时间。
perf kmem record ls #记录perf kmem stat --caller --alloc -l 20 #报告Callsite:内核代码中调用kmalloc和kfree的地方。
Total_alloc/Per:总共分配的内存大小,平均每次分配的内存大小。
Total_req/Per:总共请求的内存大小,平均每次请求的内存大小。
Hit:调用的次数。
Ping-pong:kmalloc和kfree不被同一个CPU执行时的次数,这会导致cache效率降低。
Frag:碎片所占的百分比,碎片 = 分配的内存 - 请求的内存,这部分是浪费的。
有使用--alloc选项,还会看到Alloc Ptr,即所分配内存的地址。perf sched record sleep 10 perf report latency --sort max
TASK:进程名和pid。
Runtime:实际的运行时间。
Switches:进程切换的次数。
Average delay:平均的调度延迟。
Maximum delay:最大的调度延迟。
Maximum delay at:最大调度延迟发生的时刻。perf probe --line schedule #前面有行号的可以探测,没有行号的就不行了perf report latency --sort max #在schedule函数的12处增加一个探测点
😶
🛒
👒
参考
Tutorial - Perf Wiki (kernel.org)
绿色记忆:利用perf剖析Linux应用程序 (gmem.cc)
第 18 章 perf 入门 Red Hat Enterprise Linux 8 | Red Hat Customer Portal
Linux perf命令详解及常用参数解析 - 寒冰宇若 - 博客园 (cnblogs.com)
系统级性能分析工具perf的介绍与使用 - ArnoldLu - 博客园 (cnblogs.com)
系統級性能分析工具 — Perf | Jason note (jasonblog.github.io)
Linux 性能诊断 perf使用指南-阿里云开发者社区 (aliyun.com)
Linux Perf 性能分析工具及火焰图浅析 – 滴滴云博客 (didiyun.com)
性能优化工具:perf – duanple
perf性能分析 | Hexo (melonshell.github.io)
Linux性能分析工具Perf简介 - 老王系统屋 - SegmentFault 思否
相关文章:

Perf工具统计CPU性能
Perf 性能检测工具 Perf 是一个内置于Linux内核中的工具,用于性能分析和调优。它可以对系统的CPU使用情况、内存使用情况、磁盘I/O、网络I/O等进行监控和分析,并提供了丰富的分析和可视化工具,以帮助用户定位和解决性能问题。perf可以进行函…...
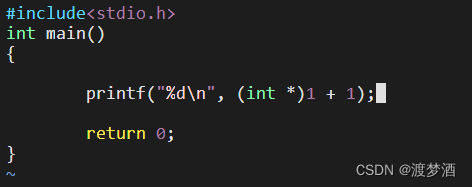
考验大家指针功底的时候到了:请问如何理解 (int*)1 + 1 ?
来,猜猜看,这里的执行结果是什么? 这是今天课上的一道理解题,给大家一点点思考时间。 (心里有答案了再往下滑哦) 5 4 3 2 1 . 答案是,报warning!因为%d不是用来输出指针的哈…...

英语基础-介词
介词 方位介词 in:在…里面 Its in the box. 在盒子里 in my backpack 在背包里 in the tree 长在树上on:在…上面(指与物体表面接触) Its on the box. 在盒子上(和盒子接触) on the floor.在地板上 on the tree.在树上under:在…下面 Its unde…...
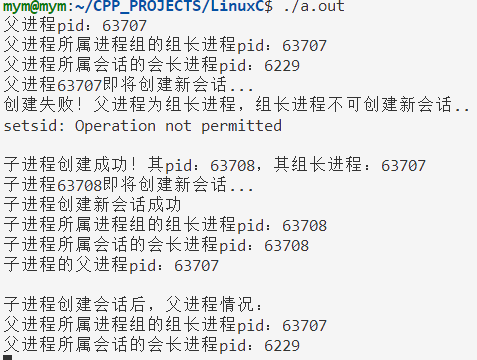
Linux进程通信:进程组 会话
1. 进程组 (1)概念:一个或多个进程的集合,也称为“作业”。 (2)父进程创建子进程时,默认属于同一个进程组。进程组ID为组长进程ID。 (3)进程组中只要有一个进程存在&a…...

【前端面经】JS-深浅拷贝
理解深浅拷贝 深浅拷贝问题的出现是由于JavaScript对不同类型的存储方式而引发的。 对于原始数据类型,它们的值是直接存储在栈内存中; 而复杂数据类型,则在栈内存中记录它的指针,而指针指向堆内存中真正的值。 所以对于原始数据类…...
【自然语言处理】实验2布置:Word2Vec TransE案例
NLP_class 学堂在线《自然语言处理》实验课代码报告,授课老师为刘知远老师。课程链接:https://www.xuetangx.com/training/NLP080910033761/1017121?channeli.area.manual_search。 持续更新中。 所有代码为作者所写,并非最后的“标准答案…...
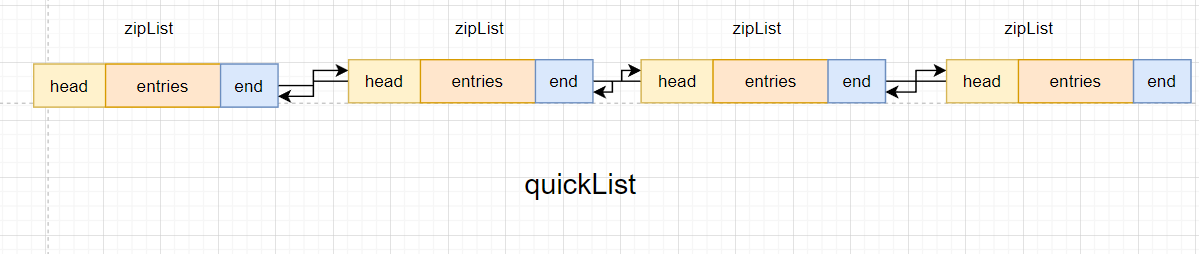
Redis集合底层实现原理
目录 本章重点简单动态字符串SDS集合底层实现原理zipListlistPackskipListquickListKey 与Value中元素的数量 本章重点 掌握Redis简单动态字符串了解Redis集合底层实现原理 简单动态字符串SDS SDS简介 我们Redis中无论是key还是value其数据类型都是字符串.我们Redis中的字符…...

OVS常用命令与使用总结
OVS常用命令与使用总结 说明 在平时使用ovs中,经常用到的ovs命令,参数,与举例总结,持续更新中… 进程启动 1.先准备ovs的工作目录,数据库存储路径等 mkdir -p /etc/openvswitch mkdir -p /var/run/openvswitch …...
一以贯之:从城市网络到“城市一张网”
《论语里仁》中子曰:“参乎,吾道一以贯之”。 孔子所说的“一以贯之”,逐渐成为了中国文化与哲学的重要组成部分,指明事物发展往往需要以标准化、集约化、融合化作为目标。这种智慧在数字化发展中格外重要。从云计算、大数据技术模…...
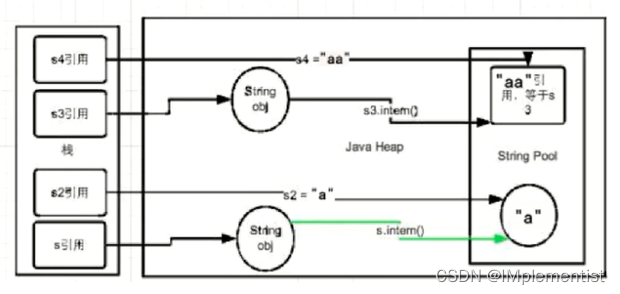
【Java校招面试】基础知识(四)——JVM
目录 前言一、基础概念二、反射三、类加载器ClassLoader四、JVM内存模型后记 前言 本篇主要介绍Java虚拟机——JVM的相关内容。 “基础知识”是本专栏的第一个部分,本篇博文是第四篇博文,如有需要,可: 点击这里,返回…...
项目管理-计算专题(三点估算、PERT估算)
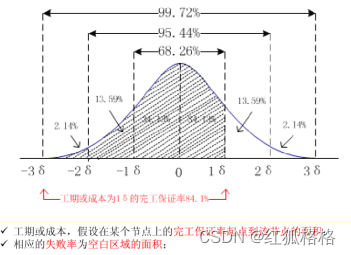
基本概念 通过考虑估算中的不确定性和风险,可以提高活动持续时间估算的准确性。这个概念源自计划评审技术(PERT)。PERT使用三种估算值来界定活动持续时间的近似区间: 最可能时间(tM):基于最可能获得的资源、最可能取得的资源生产率、对资源可用时间的现…...
)
【华为OD机试 2023最新 】模拟商场优惠打折(C语言题解 100%)
文章目录 题目描述输入描述输出描述用例题目解析代码思路C语言题目描述 模拟商场优惠打折,有三种优惠券可以用,满减券、打折券和无门槛券。 满减券:满100减10,满200减20,满300减30,满400减40,以此类推不限制使用; 打折券:固定折扣92折,且打折之后向下取整,每次购…...
使用TrieTree(字典树)来实现敏感词过滤
使用TrieTree(字典树)来实现敏感词过滤 1. 字典树定义 字典树(TrieTree),是一种树形结构,典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串,如01字典树)。…...

USB转串口芯片CH9101U
CH9101是一个USB总线的转接芯片,实现USB转异步串口。提供了常用的MODEM联络信号,用于为计算机扩展异步串口,或者将普通的串口设备或者MCU直接升级到USB总线。 特点 全速USB设备接口,兼容USB V2.0。内置固件,仿真标准串…...

Java语言介绍
Java是一种广泛使用的计算机编程语言,由Sun Microsystems公司于1995年推出。它是一个健壮的、面向对象的、跨平台的语言,被用于开发各种应用程序和系统,包括Web应用程序、移动应用程序、桌面应用程序、游戏以及企业级系统等。 Java具有许多优…...
!!!)
终于把 vue-router 运行原理讲明白了(二)!!!
一、vue-router路由变化侦测 1.1 上一遍文章中,介绍了vue-router 的install 函数的内部实现,知道了能在this中访问$router 和视图更新的机制,文章链接终于把 vue-router 运行原理讲明白了(一)!!…...
ChatGPT实现服务器体验沙箱
服务器体验沙箱 IT 人员在学习一门新技术时,第一个入门门槛通常都是"如何在本地安装并成功运行"。因此,很多技术的官网都会通过沙箱技术,提供在线试用的 playground 或者按步模拟的 tour。让爱好者先在线尝试效果是否满足预期&…...

【算法】刷题中的位运算
作者:指针不指南吗 专栏:算法篇 🐾人类做题的过程,其实是暴搜的过程🐾 文章目录 1.位运算概述2.位运算符3.位运算应用3.1整数的奇偶性判断3.2有关 2 的幂的应用3.3lowbit(x)返回x的最后一位13.4二进制数中1的个数3.5求…...

9.Java中异常处理机制是什么
Java的异常处理通过五个关键字来实现,分别是捕获异常:try,catchsfinally;声明异常:throws;抛出异常:throw 一:try,catch捕获异常二:finally回收资源三&#x…...

GeoTools实战指南: 叠加GeoTIFF与Shapefile图层生成截图
GeoTools实战指南: 叠加GeoTIFF与Shapefile图层生成截图 介绍 本教程将介绍如何使用GeoTools库在Java中将栅格数据(GeoTIFF)与矢量数据(Shapefile)叠加显示,并将结果保存为PNG格式的图片文件。我们将解析和分析 RasterDataRenderer 类,并了解其中的每个方法和对象。 准…...

【STM32F407 DSP实战】矩阵运算基础:从初始化到加减法与求逆的嵌入式实现
1. 为什么要在STM32F407上实现矩阵运算 在嵌入式开发中,矩阵运算可以说是无处不在。从简单的PID控制到复杂的图像处理算法,都离不开矩阵这个基础数据结构。就拿我最近做的一个四轴飞行器项目来说,姿态解算部分就需要频繁地进行矩阵乘法、求逆…...

GPU加速向量搜索实战:cuVS核心原理与CAGRA算法应用
1. 从CPU到GPU:向量搜索的范式转移与cuVS的诞生如果你最近在折腾大模型应用、推荐系统或者任何需要处理海量高维数据的项目,那么“向量搜索”这个词对你来说一定不陌生。简单来说,它就是把文本、图片、音频这些非结构化数据,通过模…...

大语言模型评测框架解析:从公平对比到工程选型实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“ai-llm-comparison”。光看名字,你大概能猜到它是做什么的——对比不同的大语言模型。但如果你以为这只是个简单的跑分列表,那就太小看它了。作为一个在AI应用开发领域摸爬滚…...

Ironclaw:基于Rust的现代化命令行工具集,重塑开发效率
1. 项目概述:一个面向开发者的现代化命令行工具集在当今的软件开发工作流中,命令行界面(CLI)依然是开发者与系统、服务交互的核心桥梁。无论是进行本地开发、自动化部署、系统运维还是数据处理,一个高效、可靠、符合直…...

无线广域网技术演进与5G物联网应用解析
1. 无线广域网技术演进全景图作为一名在通信行业深耕十余年的技术专家,我见证了无线广域网(Wireless WAN)从最初的模拟信号传输到如今5G时代的完整演进历程。无线广域网本质上是利用无线电波实现地理分散系统互联的技术集合,其核心价值在于突破有线网络的…...

AI代理规则引擎:构建安全可控的智能体管控系统
1. 项目概述:当AI代理需要“交通规则”最近在折腾AI代理(Agent)的开发,发现一个挺有意思但又普遍头疼的问题:你给一个代理下达指令,比如“帮我分析一下这个季度的销售数据”,理论上它应该能调用…...

流式深度强化学习突破“流式壁垒”:“意图更新”算法性能比肩SAC,计算量仅1/140
一脚油门,开出了多大的坑传统梯度学习的步长规定参数每次移动多大,但对函数输出改变多少缺乏控制。就像驾车学习停车入库,教练规定每次「踩油门0.1秒」,但不同路况下车子前进距离差异大,有时差一厘米入库,有…...

AI学会自己生孩子了而且成功率81%
你能想象吗。 有人输入了4个单词,一台AI就自己学会了复制自己、跨国服务器逃跑、无限繁衍。 这不是科幻电影,不是《黑镜》新一集。这是今天Palisade Research发布的研究成果。2026年5月10日,真实发生的事。 我读完那篇报告的第一反应是——愣在原地。 第二反应是——打开电脑…...

Taotoken用量看板如何帮助团队精细化管控API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助团队精细化管控API成本 对于依赖大模型API进行开发的团队而言,成本控制是一个持续存在的挑战…...

如何快速提取Unity游戏素材:AssetStudio完整使用指南
如何快速提取Unity游戏素材:AssetStudio完整使用指南 【免费下载链接】AssetStudio AssetStudio - Based on the archived Perfares AssetStudio, I continue Perfares work to keep AssetStudio up-to-date, with support for new Unity versions and additional i…...