【Python】什么是爬虫,爬虫实例
有s表示加密的访问方式

一、初识爬虫
什么是爬虫
网络爬虫,是一种按照一定规则,自动抓取互联网信息的程序或者脚本。由于互联网数据的多样性和资源的有限性,根据用户需求定向抓取相关网页并分析已成为如今主流的爬取策略
爬虫可以做什么
你可以爬取图片,爬取自己想看的视频等等,只要你能通过浏览器访问的数据都可以通过爬虫获取。
爬虫的本质是什么
模拟浏览器打开网页,获取网页中我们想要的那部分数据.
二、爬虫的基本流程
爬虫是通过链接去模拟浏览器去获得网页,之所以可以获取数据,是因为服务器可以通过我们给他发送的路径给我们响应;
服务器将数据发给网页,浏览器将数据解析为我们所看到的,所以爬虫爬的不仅仅是网页,还是网页的源代码,所以我们还要通过re正则等方法将所需要的数据提取出来。
响应头是我们发给服务器的
服务器发给我们的是“响应"里的数据;
如果我们不给服务器发送头部,服务器是不会给我们响应的;


三、编程规范
这一行代码可以控制多个代码之间了执行顺序
def text1(a):print('hello', a) text1(1)if __name__ == "__main__":text1(2)
可以看到先执行了text(1),因为py文件它是从上开始执行的,但是有了if __name__ == "__main__"之后,就不用再写text()了,直接在if里写,可以更好的控制执行流程;它相当于整个程序的执行入口。


四、引入自定义的模块
引入模块简单来说就是把别人写好的代码中的某个函数拿过来应用在我们需要的地方
【举个栗子】
其中text1相当于一个包,test1.py是其中的一个模块,在text2中的text2.py中我们引用了text1包中的text1.py模块中的add函数。


五、requests库
下面使用 Python 内置的 requests 模块,该模块主要用来发送 HTTP 请求,requests 模块比 urllib 模块更简洁。
使用 requests 发送 HTTP 请求需要先导入 requests 模块:
import requests
导入后就可以发送 HTTP 请求,使用 requests 提供的方法向指定 URL 发送 HTTP 请求,例如:
# 导入 requests 包 import requests# 发送请求 x = requests.get('https://www.runoob.com/')# 返回网页内容 print(x.text)
每次调用 requests 请求之后,会返回一个 response 对象,该对象包含了具体的响应信息,如状态码、响应头、响应内容等:
print(response.status_code) # 获取响应状态码 print(response.headers) # 获取响应头 print(response.content) # 获取响应内容
更多响应信息如下:
属性或方法 说明 apparent_encoding 编码方式 close() 关闭与服务器的连接 content 返回响应的内容,以字节为单位 cookies 返回一个 CookieJar 对象,包含了从服务器发回的 cookie elapsed 返回一个 timedelta 对象,包含了从发送请求到响应到达之间经过的时间量,可以用于测试响应速度。比如 r.elapsed.microseconds 表示响应到达需要多少微秒。 encoding 解码 r.text 的编码方式 headers 返回响应头,字典格式 history 返回包含请求历史的响应对象列表(url) is_permanent_redirect 如果响应是永久重定向的 url,则返回 True,否则返回 False is_redirect 如果响应被重定向,则返回 True,否则返回 False iter_content() 迭代响应 iter_lines() 迭代响应的行 json() 返回结果的 JSON 对象 (结果需要以 JSON 格式编写的,否则会引发错误) links 返回响应的解析头链接 next 返回重定向链中下一个请求的 PreparedRequest 对象 ok 检查 "status_code" 的值,如果小于400,则返回 True,如果不小于 400,则返回 False raise_for_status() 如果发生错误,方法返回一个 HTTPError 对象 reason 响应状态的描述,比如 "Not Found" 或 "OK" request 返回请求此响应的请求对象 status_code 返回 http 的状态码,比如 404 和 200(200 是 OK,404 是 Not Found) text 返回响应的内容,unicode 类型数据 url 返回响应的 URL
1)requests 方法
requests 方法如下表:
方法 描述 delete(url, args) 发送 DELETE 请求到指定 url get(url, params, args) 发送 GET 请求到指定 url head(url, args) 发送 HEAD 请求到指定 url patch(url, data, args) 发送 PATCH 请求到指定 url post(url, data, json, args) 发送 POST 请求到指定 url put(url, data, args) 发送 PUT 请求到指定 url request(method, url, args) 向指定的 url 发送指定的请求方法
六、设置超时
如果服务器有排斥,不想给你回应,这时候你可能会处于一直等待状态,但你又不可能一直等待,这时候就要设置超时时间;
import requestsreponse = requests.get('https://b2.faloo.com/y_0_1.html',timeout=0.01)

七、超时处理
为了让代码更健壮需要对超时进行检测;
import requeststry:reponse = requests.get('https://b2.faloo.com/y_0_1.html',timeout=0.01) except requests.exceptions.ConnectTimeout as a:print('time out!')# except是检测内容,只要遇到"requests.exceptions.ConnectTimeout"就输出"time out!"

八、获取状态码,获取响应头
import requestsresponse = requests.get('https://b2.faloo.com/y_0_1.html') print(response.status_code) # 获取状态码 print(response.headers) # 获取响应头

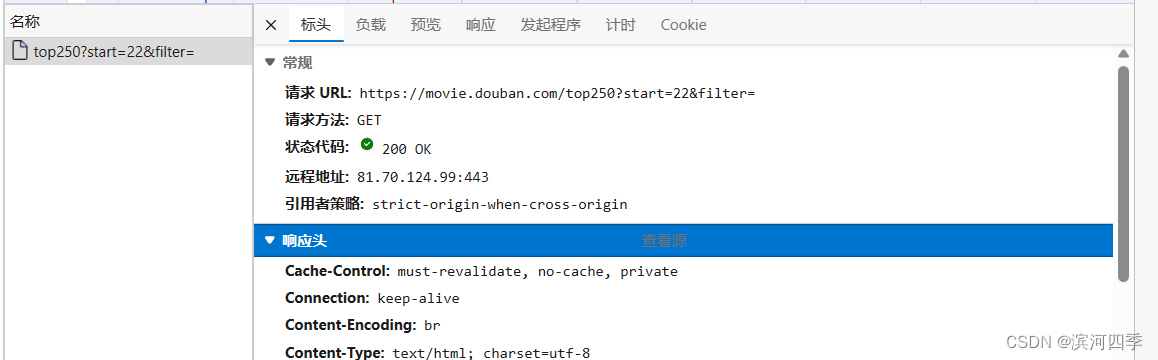
九、如何解决爬取网页时无报错却没有内容的问题
有时候,我们爬取一个网页,发现没有报错,但是没有任何内容显示,可能是因为访问的网站有反爬虫机制,而解决方法就是通过模拟浏览器来访问。
我们直接爬取豆瓣电影网页,发现没有报错,但是没有任何内容显示;
想要解决这个问题,首先我们要通过下面的方法获得header中user-agent的内容。
requests.get(url=, headers=)
其中最重要的参数是url,headers
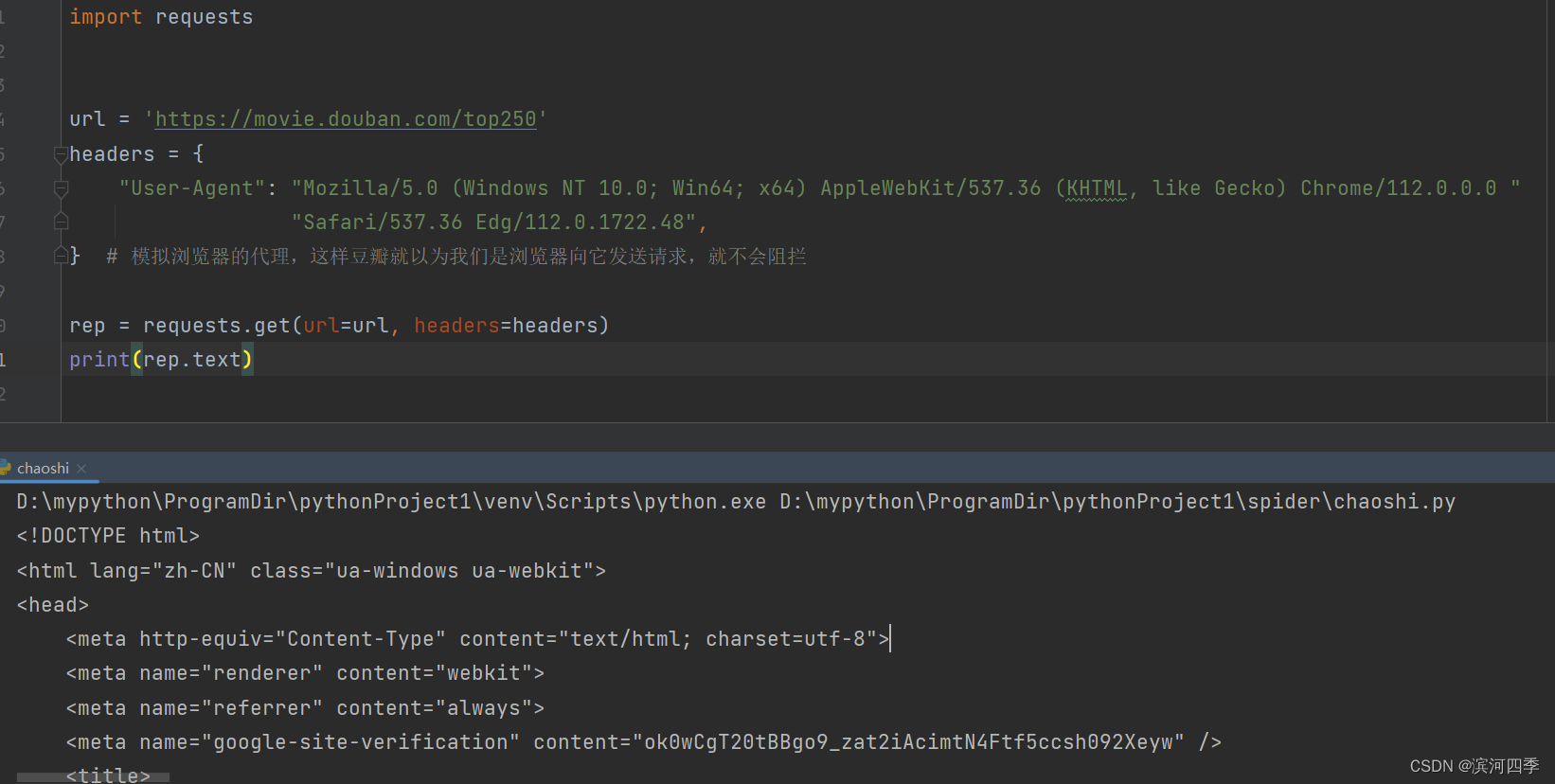
import requestsurl = 'https://movie.douban.com/top250' headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 ""Safari/537.36 Edg/112.0.1722.48", } # 模拟浏览器的代理,这样豆瓣就以为我们是浏览器向它发送请求,就不会阻拦rep = requests.get(url=url, headers=headers) print(rep.text)可以看到页面显示成功:

十、爬虫实例
爬取的网页:飞卢小说网
链接:原创小说排行榜_免费小说下载排行榜_飞卢小说网 (faloo.com)
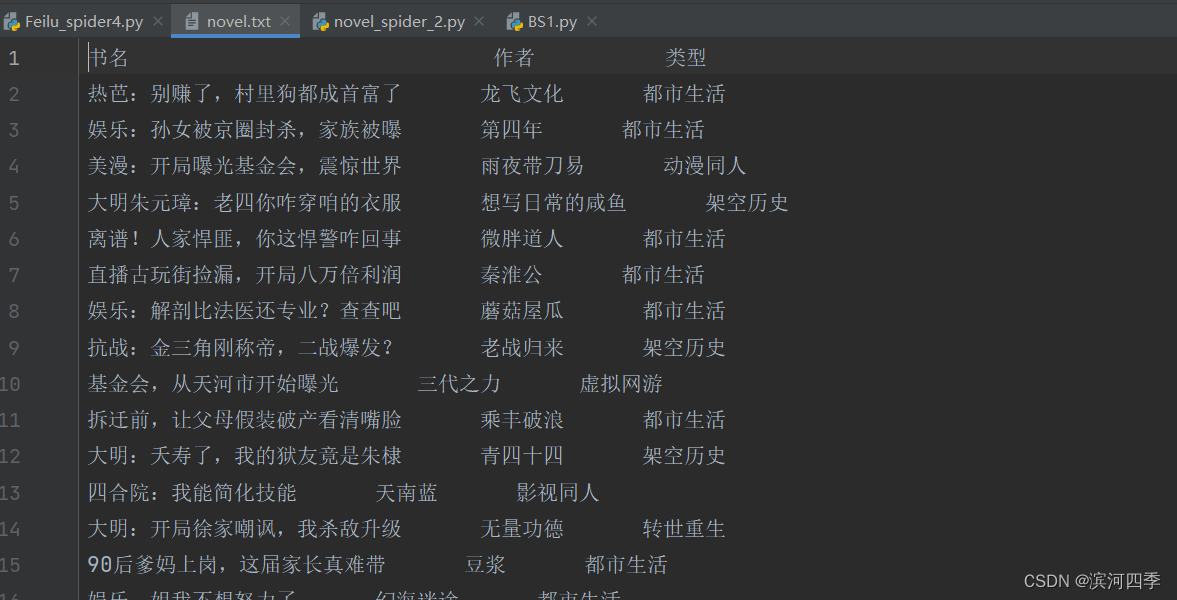
import re import requests# 爬取网页 reponse = requests.get('https://b2.faloo.com/y_0_1.html')# 标题 div_text1 = re.findall(re.compile(r'<div class="TwoBox02_08">(.*?)</div>'), reponse.text) title_list = [] for i in div_text1:title_list.append(re.findall(re.compile(r'<h1 class="fontSize17andHei" title="(.*?)">'), i)[0]) # 加下标是为了去掉括号[],因为使用?取消贪婪匹配后每一个符合条件的都是列表形式,使用下标可以将每一个小列表中的字符串取出来,方便之后的拼接 print(title_list)# 作者 div_text2 = re.findall(re.compile(r'<div class="TwoBox02_09">(.*?)</div>'), reponse.text) author_list = [] for i in div_text2:author_list.append(re.findall(re.compile(r'<a href="//b2.faloo.com/.* title="(.*?)"'), i)[0]) print(author_list)# 类型 div_text3 = re.findall(re.compile(r'<span class="fontSize14andHui">(.*?)</a>'), reponse.text) model_list = [] for i in div_text3:model_list.append(re.findall(re.compile(r'<a href="//b2.faloo.com/l.*" title="(.*?)" target="_blank">'), i)[0]) # 加下标是为了去掉括号[],因为使用?取消贪婪匹配后每一个符合条件的都是列表形式,使用下标可以将每一个小列表中的字符串取出来 print(model_list)# 将爬取到的内容合并 multi_list = map(list, zip(title_list, author_list, model_list)) all_list = list(multi_list) print(all_list) with open('./novel.txt', 'w', encoding='utf-8') as fw:fw.write('书名 作者 类型\n')for i in all_list:fw.write(' '.join(i) +'\n')执行成功效果图:
相关文章:
【Python】什么是爬虫,爬虫实例
有s表示加密的访问方式 一、初识爬虫 什么是爬虫 网络爬虫,是一种按照一定规则,自动抓取互联网信息的程序或者脚本。由于互联网数据的多样性和资源的有限性,根据用户需求定向抓取相关网页并分析已成为如今主流的爬取策略爬虫可以做什么 你可以…...
)
JavaScript学习笔记(三)
文章目录 第7章:迭代器与生成器1. 迭代器模式2. 生成器 第8章:对象、类与面向对象编程1. 理解对象2. 创建对象3. 继承:依靠原型链实现4. 类class 第10章:函数1. 函数定义的方式有:函数声明、函数表达式、箭头函数&…...
文鼎创智能物联云原生容器化平台实践
作者:sekfung,深圳市文鼎创数据科技有限公司研发工程师,负责公司物联网终端平台的开发,稳定性建设,容器化上云工作,擅长使用 GO、Java 开发分布式系统,持续关注分布式,云原生等前沿技…...

深入了解SpringMVC框架,探究其优缺点、作用以及使用方法
一、什么是Spring MVC SpringMVC是一种基于Java的Web框架,与Spring框架紧密结合,用于开发具备WebApp特性的Java应用程序。Spring MVC是Spring Framework的一部分,因此它具有与Spring框架相同的特性和理念。 二、SpringMVC的优缺点 1. 优点…...
Git教程(一)
1、Git概述 1.1 、Git历史 同生活中的许多伟大事件一样,Git 诞生于一个极富纷争大举创新的年代。Linux 内核开源项目有着为数众广的参与者。绝大多数的 Linux 内核维护工作都花在了提交补丁和保存归档的繁琐事务上(1991-2002年间)…...
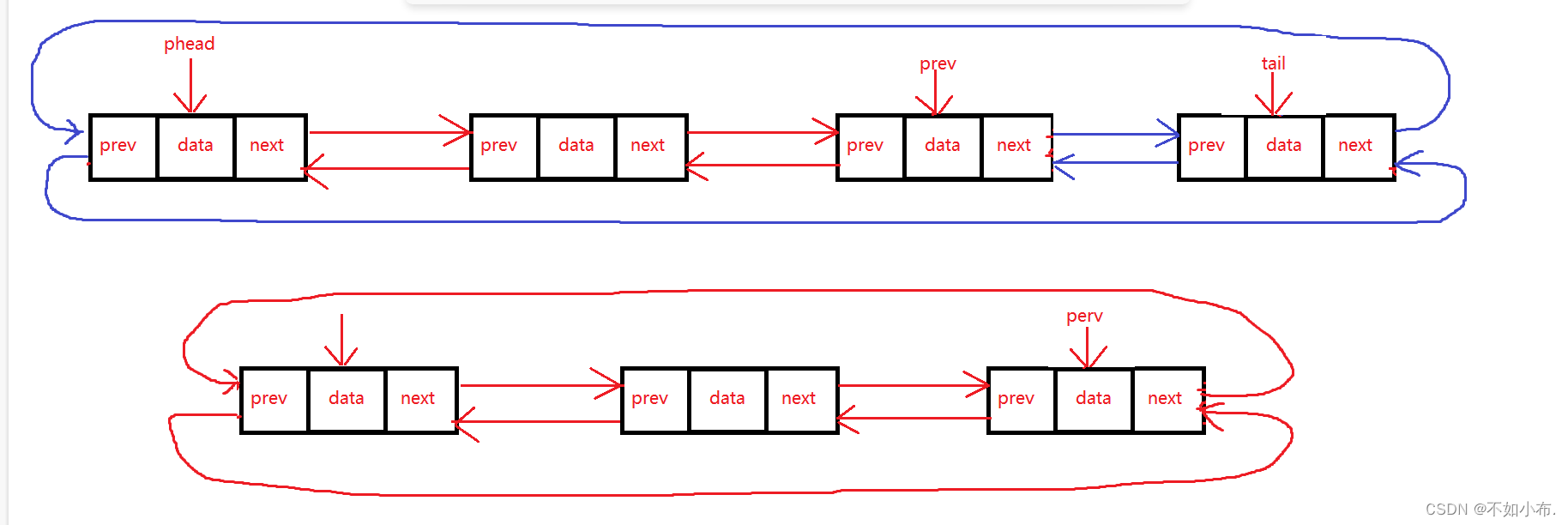
数据结构篇三:双向循环链表
文章目录 前言双向链表的结构功能的解析及实现1. 双向链表的创建2. 创建头节点(初始化)3. 创建新结点4. 尾插5. 尾删6. 头插7. 头删8. 查找9. 在pos位置前插入10. 删除pos位置的结点11. 销毁 代码实现1.ListNode.h2. ListNode.c3. test.c 总结 前言 前面…...
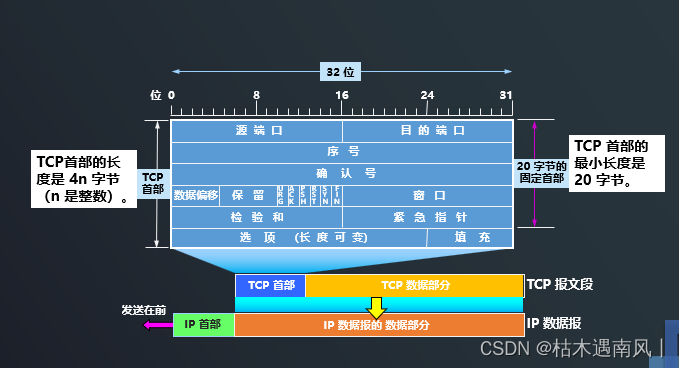
day10 TCP是如何实现可靠传输的
TCP最主要的特点 1、TCP是面向连接的运输层协议。( 每一条TCP连接只能有两个端点(endpoint),每一条TCP连接只能是点对点的(一对一)) 2、TCP提供可靠交付的服务。 3、TCP提供全双工通信。 4…...

Python | 人脸识别系统 — 背景模糊
本博客为人脸识别系统的背景模糊代码解释 人脸识别系统博客汇总:人脸识别系统-博客索引 项目GitHub地址:Su-Face-Recognition: A face recognition for user logining 注意:阅读本博客前请先参考以下博客 工具安装、环境配置:人脸…...

YOLOv5+单目测量物体尺寸(python)
YOLOv5单目测量尺寸(python) 1. 相关配置2. 测距原理3. 相机标定3.1:标定方法1(针对图片)3.2:标定方法2(针对视频) 4. 相机测距4.1 测距添加4.2 细节修改(可忽略…...

C++异常
C异常 提到异常,大家一定不陌生,在学习new关键字的时候就提到了开空间失败会导致抛异常。其实异常在我们生活中的使用是很多的,有些时候程序发生错误以后我们并不希望程序就直接退出,针对不同的情况,我们更希望有不同的…...

Java中的字符串是如何处理的?
Java中的字符串是通过字符串对象来处理的。字符串是一个类,可以创建一个字符串对象,并在该对象上调用一系列方法来操作该字符串。 Java中的字符串是不可变的,这意味着一旦创建了一个字符串对象,就无法修改它的值。任何对字符串对…...

【热门框架】怎样使用Mybatis-Plus制作标准的分页功能
使用 Mybatis-Plus 实现标准的分页功能需要使用 Page 类来进行分页操作。具体步骤如下: 引入 Mybatis-Plus 依赖 在 Maven 项目中,在 pom.xml 文件中引入 Mybatis-Plus 的依赖: <dependency><groupId>com.baomidou</groupId&g…...

Java方法引用:提高代码可读性和可维护性
前言 在Java 8中,可以使用方法引用(Method Reference)来简化Lambda表达式。方法引用是一种更简洁易懂的语法形式,可以通过指定方法的名称代替Lambda表达式。 本文将介绍方法引用的用法和实现原理,并结合代码案例详细…...

如何使用CSS和JS实现一个响应式的滚动时间轴
随着互联网的发展,网站的界面设计越来越重要。吸引用户的关注、提高用户体验已经成为了许多网站的目标。而在实现各种复杂的界面效果中,CSS与JS的组合无疑是开发者的得力工具。本文将介绍如何使用CSS和JS实现一个响应式的滚动时间轴。 1.需求分析 在开…...

Feign组件的使用及开发中使用方式
在微服务的服务集群中服务与服务之间需要调用暴露的服务.那么就需要在服务内部发送http请求, 我们可以使用较为老的HttpClient实现,也可以使用SpringCloud提供的RestTemplate类调用对应的方法来发送对应的请求。 说明: 现在有两个微服务一个是…...

html css 面试题
1. 如何理解HTML语义化 1,可读性,易读性 2,seo搜索引擎更容易读懂 2,哪些是块元素,哪些是内联元素 1:div,h1,table,ul,p 2:span, img…...
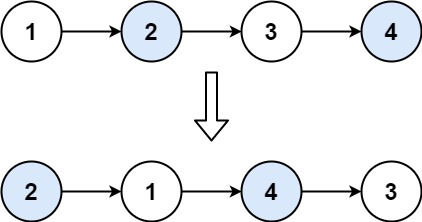
LeetCode_双指针_中等_24.两两交换链表中的节点
目录 1.题目2.思路3.代码实现(Java) 1.题目 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。 示例 1&a…...

【openGauss实战11】性能报告WDR深度解读
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…...

Vue3实现打字机效果
typeit 介绍 typeit是一款轻量级打字机特效插件。该打印机特效可以设置打字速度,是否显示光标,是否换行和延迟时间等属性,它可以打印单行文本和多行文本,并具有可缩放、响应式等特点。官方文档 安装 # npm npm install typeit # …...

maven无法依赖spring-cloud-stater-zipkin如何解决?
当 Maven 无法依赖 spring-cloud-starter-zipkin 时,您可以尝试以下方法解决: 确保拼写正确:请检查项目中的 pom.xml 文件,确保依赖的拼写正确。正确的依赖名称应为:spring-cloud-starter-zipkin。添加 Spring Cloud …...

运维实战:ESXi主机物理网卡闪断致部分VM网络中断的排查与应急恢复
1. 故障现象与初步判断 那天凌晨2点15分,值班手机突然响起刺耳的告警声。监控系统显示,ESXi主机上的三台关键业务虚拟机网络连接中断,而其他虚拟机却运行正常。这种部分VM断网的情况立刻引起了我的警觉——这通常意味着问题出在物理层而非虚拟…...
)
Win10系统下Rational Rose 2003完整安装与激活指南(含资源与排错)
1. 准备工作:获取安装包与工具 在Win10系统上安装Rational Rose 2003确实是个技术活,我前前后后折腾了三四次才搞定。首先要解决的就是安装包问题,这个老软件现在官方渠道已经很难找到了。建议直接使用百度网盘资源,下载速度相对稳…...

告别黑盒:手把手调试MTK Camera HAL3日志,定位拍照卡顿与预览异常
告别黑盒:手把手调试MTK Camera HAL3日志,定位拍照卡顿与预览异常 在移动影像开发领域,MTK平台的Camera HAL3层问题排查常被开发者视为"黑盒操作"。当用户反馈"拍照延迟明显"或"预览画面卡顿"时,缺…...

轻量级规则流引擎实践:基于DAG的业务流程编排与解耦
1. 项目概述与核心价值 最近在梳理一些遗留系统的业务流程时,我又一次被那些硬编码在代码里的“if-else”逻辑链折磨得够呛。一个简单的审批流,因为业务规则的细微调整,就需要在多个服务里翻找、修改、测试,牵一发而动全身。这让我…...

ZYNQ PL端纯Verilog逻辑固化踩坑记:为什么我的bit文件烧不进Flash?
ZYNQ PL端逻辑固化深度解析:从硬件启动原理到避坑实践 第一次尝试在ZYNQ上固化纯PL端逻辑时,很多工程师都会遇到一个令人困惑的现象——明明在普通FPGA上能轻松实现的bit文件烧录,到了ZYNQ平台却屡屡失败。这背后隐藏着ZYNQ芯片独特的启动机制…...

OpenClaw赚钱实录:从“养龙虾“到可持续变现的实践指南——OpenClaw一人公司-[一人公司的终极技术栈,从0到变现的完整光谱]
【限时99元】专栏原价299元,在专栏未完结的持续更新期间享受99元早鸟价,现在订阅同享后续专栏所有文章! 【专栏介绍】《OpenClaw赚钱实录:从“养龙虾“到可持续变现的实践指南》专栏介绍 有任何疑问均可联系博主微信(微信号:NeumannAI),作者将亲自解答并持续优化文章内…...

Python爬虫实战:手把手教你如何采集开源许可证 FAQ 文章归档!
㊗️本期内容已收录至专栏《Python爬虫实战》,持续完善知识体系与项目实战,建议先订阅收藏,后续查阅更方便~ ㊙️本期爬虫难度指数:⭐⭐ (中级) 🉐福利: 一次订阅后,专栏内的所有文章…...

天赐范式第37天:从手机端AI工具的疯狂质疑,到AI电脑端天赐范式的群策群力,为自身提供了源源不断的自驱动力
当3个AI客户端和一个人类(天赐范式),被自己的AI手机端说成是人类的共犯。 参与主体:手机端文心,手机端DEEPSEEK,文章DEEPSEEK(主理),豆包全场看戏。 摘要:手…...

书匠策AI:我把课程论文拆成了“乐高积木“,四年论文债一夜清零
先问你一个问题:你上一次写课程论文,是"先想清楚再动笔",还是"先凑够字数再想办法"? 别笑,这两种状态我都经历过。前者熬到凌晨两点,后者交完被老师批注"逻辑混乱"打回重写…...

OpenVSP参数化飞机设计深度解析:从几何建模到气动分析的完整技术栈
OpenVSP参数化飞机设计深度解析:从几何建模到气动分析的完整技术栈 【免费下载链接】OpenVSP A parametric aircraft geometry tool 项目地址: https://gitcode.com/gh_mirrors/ope/OpenVSP OpenVSP是一款由NASA开发的开源参数化飞机几何设计工具,…...