第 5 章 HBase 优化
5.1 RowKey 设计
一条数据的唯一标识就是 rowkey,那么这条数据存储于哪个分区,取决于 rowkey 处于
哪个一个预分区的区间内,设计 rowkey的主要目的 ,就是让数据均匀的分布于所有的 region
中,在一定程度上防止数据倾斜。接下来我们就谈一谈 rowkey 常用的设计方案。
1)生成随机数、hash、散列值
2)时间戳反转
3)字符串拼接
**需求:**使用 hbase 存储下列数据,要求能够通过 hbase 的 API 读取数据完成两个统计需求。

5.1.1 实现需求 1
为了能够统计张三在 2021 年 12 月份消费的总金额,我们需要用 scan 命令能够得到张三在这个月消费的所有记录,之后在进行累加即可。Scan 需要填写 startRow 和 stopRow:

scan : startRow -> ^A^Azhangsan2021-12 endRow -> ^A^Azhangsan2021-12.
注意点:
(1)避免扫描数据混乱,解决字段长度不一致的问题,可以使用相同阿斯卡码值的符
号进行填充,框架底层填充使用的是阿斯卡码值为 1 的^A。
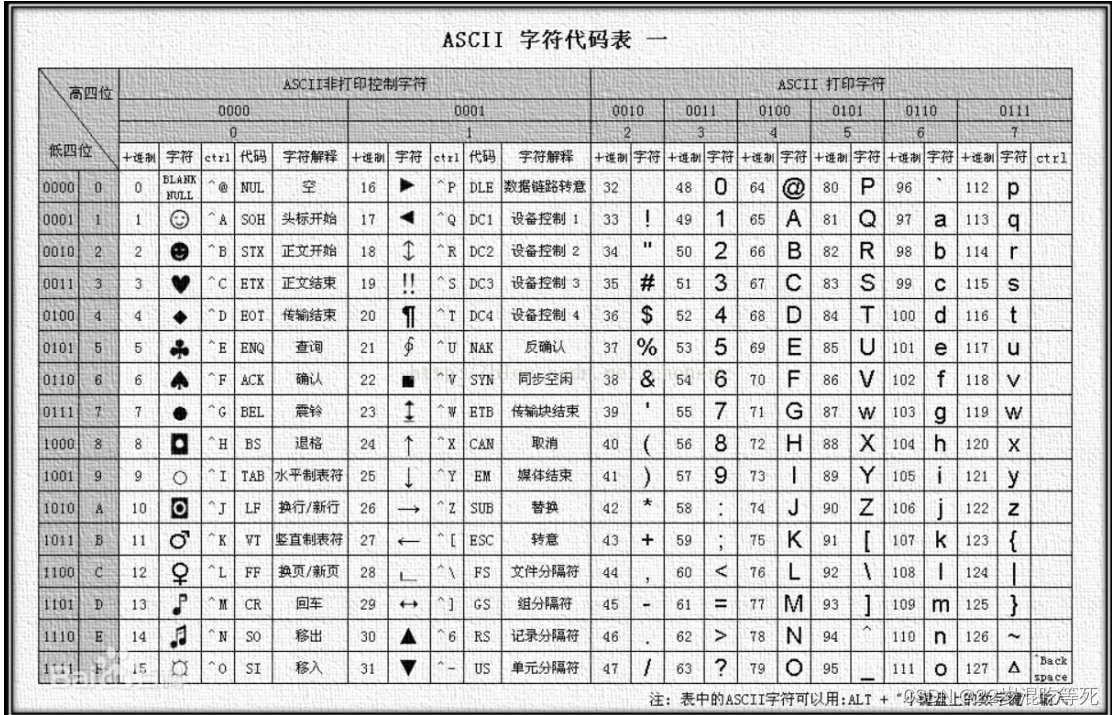
(2)最后的日期结尾处需要使用阿斯卡码略大于’-’的值
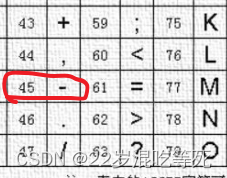
最终得到 rowKey 的设计为:
//注意 rowkey 相同的数据会视为相同数据覆盖掉之前的版本
rowKey: userdate(yyyy-MM-dd HH:mm:SS)
5.1.2 实现需求 2
问题提出:按照需要 1 的 rowKey 设计,会发现对于需求 2,完全没有办法写 rowKey 的
扫描范围。此处能够看出 hbase 设计 rowKey 使用的特点为:
适用性强 泛用性差 能够完美实现一个需求 但是不能同时完美实现多个需要。
如果想要同时完成两个需求,需要对 rowKey 出现字段的顺序进行调整。
调整的原则为:可枚举的放在前面。其中时间是可以枚举的,用户名称无法枚举,所以
必须把时间放在前面。
最终满足 2 个需求的设计
可以穷举的写在前面即可
rowKey 设计格式 => date(yyyy-MM)^A^Auserdate(-dd hh:mm:ss ms)(1)统计张三在 2021 年 12 月份消费的总金额
scan: startRow => 2021-12^A^AzhangsanstopRow => 2021-12^A^Azhangsan.(2)统计所有人在 2021 年 12 月份消费的总金额
scan: startRow => 2021-12stopRow => 2021-12.
5.1.3 添加预分区优化
预分区的分区号同样需要遵守 rowKey 的 scan 原则。所有必须添加在 rowKey 的最前面,前缀为最简单的数字。同时使用 hash 算法将用户名和月份拼接决定分区号。(单独使用用户名会造成单一用户所有数据存储在一个分区)。
添加预分区优化
startKey stopKey
001
001 002
002 003
...
119 120分区号=> hash(user+date(MM)) % 120分区号填充 如果得到 1 => 001rowKey 设计格式 => 分区号 date(yyyy-MM)^A^Auserdate(-dd hh:mm:ss ms)
缺点:实现需求 2 的时候,由于每个分区都有 12 月份的数据,需要扫描 120 个分区。
解决方法:提前将分区号和月份进行对应。
提前将月份和分区号对应一下:
000 到 009 分区 存储的都是 1 月份数据
010 到 019 分区 存储的都是 2 月份数据
…
110 到 119 分区 存储的都是 12 月份数据
是 9 月份的数据
- 分区号=> hash(user+date(MM)) % 10 + 80
- 分区号填充 如果得到 85 => 085
得到 12 月份所有人的数据
- 扫描 10 次
scan: startRow => 1102021-12stopRow => 1102021-12.
...startRow => 1122021-12stopRow => 1122021-12.
..startRow => 1192021-12stopRow => 1192021-12.
5.2 参数优化
1)Zookeeper 会话超时时间
hbase-site.xml
属性:zookeeper.session.timeout解释:默认值为 90000 毫秒(90s)。当某个 RegionServer 挂掉,90s 之后 Master 才能察觉到。
可适当减小此值,尽可能快地检测 regionserver 故障,可调整至 20-30s。看你能有都能忍耐超时,同时可以调整重试时间和重试次数
hbase.client.pause(默认值 100ms)
hbase.client.retries.number(默认 15 次)
2)设置 RPC 监听数量
hbase-site.xml
属性:hbase.regionserver.handler.count
解释:默认值为 30,用于指定 RPC 监听的数量,可以根据客户端的请求数进行调整,读写请求较多时,增加此值。
3)手动控制 Major Compaction
hbase-site.xml
属性:hbase.hregion.majorcompaction
解释:默认值:604800000 秒(7 天), Major Compaction 的周期,若关闭自动 Major
Compaction,可将其设为 0。如果关闭一定记得自己手动合并,因为大合并非常有意义。
4)优化 HStore 文件大小
hbase-site.xml
属性:hbase.hregion.max.filesize解释:默认值 10737418240(10GB),如果需要运行 HBase 的 MR 任务,可以减小此值,
因为一个 region 对应一个 map 任务,如果单个 region 过大,会导致 map 任务执行时间过长。
该值的意思就是,如果 HFile 的大小达到这个数值,则这个 region 会被切分为两个 Hfile。
5)优化 HBase 客户端缓存
hbase-site.xml
属性:hbase.client.write.buffer解释:默认值 2097152bytes(2M)用于指定 HBase 客户端缓存,
增大该值可以减少 RPC调用次数,但是会消耗更多内存,反之则反之。
一般我们需要设定一定的缓存大小,以达到减少 RPC 次数的目的。
6)指定 scan.next 扫描 HBase 所获取的行数
hbase-site.xml
属性:hbase.client.scanner.caching解释:用于指定 scan.next 方法获取的默认行数,值越大,消耗内存越大。
7)BlockCache 占用 RegionServer 堆内存的比例
hbase-site.xml
属性:hfile.block.cache.size
解释:默认 0.4,读请求比较多的情况下,可适当调大
8)MemStore 占用 RegionServer 堆内存的比例
hbase-site.xml
属性:hbase.regionserver.global.memstore.size
解释:默认 0.4,写请求较多的情况下,可适当调大
Lars Hofhansl(拉斯·霍夫汉斯)大神推荐 Region 设置 20G,刷写大小设置 128M,其它默认。
hbase-site.xml文件:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
/** Licensed to the Apache Software Foundation (ASF) under one* or more contributor license agreements. See the NOTICE file* distributed with this work for additional information* regarding copyright ownership. The ASF licenses this file* to you under the Apache License, Version 2.0 (the* "License"); you may not use this file except in compliance* with the License. You may obtain a copy of the License at** http://www.apache.org/licenses/LICENSE-2.0** Unless required by applicable law or agreed to in writing, software* distributed under the License is distributed on an "AS IS" BASIS,* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.* See the License for the specific language governing permissions and* limitations under the License.*/
-->
<configuration><!--The following properties are set for running HBase as a single process on adeveloper workstation. With this configuration, HBase is running in"stand-alone" mode and without a distributed file system. In this mode, andwithout further configuration, HBase and ZooKeeper data are stored on thelocal filesystem, in a path under the value configured for `hbase.tmp.dir`.This value is overridden from its default value of `/tmp` because manysystems clean `/tmp` on a regular basis. Instead, it points to a path withinthis HBase installation directory.Running against the `LocalFileSystem`, as opposed to a distributedfilesystem, runs the risk of data integrity issues and data loss. NormallyHBase will refuse to run in such an environment. Setting`hbase.unsafe.stream.capability.enforce` to `false` overrides this behavior,permitting operation. This configuration is for the developer workstationonly and __should not be used in production!__See also https://hbase.apache.org/book.html#standalone_dist--><property><name>hbase.cluster.distributed</name><value>false</value></property><property><name>hbase.tmp.dir</name><value>./tmp</value></property><property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property>
<property><name>hbase.zookeeper.quorum</name><value>hadoop102,hadoop103,hadoop104</value><description>The directory shared by RegionServers.</description></property>
<property><name>hbase.zookeeper.quorum</name><value>hadoop102,hadoop103,hadoop104</value></property>
<!-**加粗样式**- <property>-->
<!-- <name>hbase.zookeeper.property.dataDir</name>-->
<!-- <value>/export/zookeeper</value>-->
<!-- <description> 记得修改 ZK 的配置文件 -->
<!-- ZK 的信息不能保存到临时文件夹-->
<!-- </description>-->
<!-- </property>--><property><name>hbase.rootdir</name><value>hdfs://hadoop102:8020/hbase</value><description>The directory shared by RegionServers.</description></property><property><name>hbase.cluster.distributed</name><value>true</value></property>
</configuration>5.3 JVM 调优
JVM 调优的思路有两部分:一是内存设置,二是垃圾回收器设置。
垃圾回收的修改是使用并发垃圾回收,默认 PO+PS 是并行垃圾回收,会有大量的暂停。
理由是 HBsae 大量使用内存用于存储数据,容易遭遇数据洪峰造成 OOM,同时写缓存的数
据是不能垃圾回收的,主要回收的就是读缓存,而读缓存垃圾回收不影响性能,所以最终设
置的效果可以总结为:防患于未然,早洗早轻松。
1)设置使用 CMS 收集器:
-XX:+UseConcMarkSweepGC
2)保持新生代尽量小,同时尽早开启 GC,例如:
//在内存占用到 70%的时候开启 GC
-XX:CMSInitiatingOccupancyFraction=70//指定使用 70%,不让 JVM 动态调整
-XX:+UseCMSInitiatingOccupancyOnly//新生代内存设置为 512m
-Xmn512m//并行执行新生代垃圾回收
-XX:+UseParNewGC// 设 置 scanner 扫 描 结 果 占 用 内 存 大 小 , 在 hbase-site.xml 中,设置
hbase.client.scanner.max.result.size(默认值为 2M)为 eden 空间的 1/8
(大概在 64M)// 设置多个与 max.result.size * handler.count 相乘的结果小于 Survivor
Space(新生代经过垃圾回收之后存活的对象)
5.4 HBase 使用经验法则
官方给出了权威的使用法则:

相关文章:
第 5 章 HBase 优化
5.1 RowKey 设计 一条数据的唯一标识就是 rowkey,那么这条数据存储于哪个分区,取决于 rowkey 处于 哪个一个预分区的区间内,设计 rowkey的主要目的 ,就是让数据均匀的分布于所有的 region 中,在一定程度上防止数据倾斜…...
台北房价预测
目录 1.数据理解1.1分析数据集的基本结构,查询并输出数据的前 10 行和 后 10 行1.2识别并输出所有变量 2.数据清洗2.1输出所有变量折线图2.2缺失值处理2.3异常值处理 3.数据分析3.1寻找相关性3.2划分数据集 4.数据整理4.1数据标准化 5.回归预测分析5.1线性回归&…...
9:00进去,9:05就出来了,这问的也太···
从外包出来,没想到死在另一家厂子了。 自从加入这家公司,每天都在加班,钱倒是给的不少,所以也就忍了。没想到8月一纸通知,所有人不许加班,薪资直降30%,顿时有吃不起饭的赶脚。 好在有个兄弟内推…...

debootstrap 构建 RISC-V 64 Ubuntu 根文件系统
debootstrap 构建 Ubuntu RISC-V Linux 根文件系统 flyfish 主机信息 命令 lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 20.04.6 LTS Release: 20.04 Codename: focal制作的根文件系统为 RISC-V 64 Ubuntu 22.04 LTS 1 主机…...
怎么样?)
腾讯云轻量应用服务器(Lighthouse)怎么样?
轻量应用服务器是否好用,小白这么多年的经验来看,跑企业站或博客都没问题,因为小流量站是可以的。但是限制流量的服务器只适合小站。超流量后是要扣费的。简而言之,超过流量是按流量计费的。如果被攻击大概率会欠费。如果是企业用…...

学习 AI 常用的一些专业词汇
学习 AI 常用的一些专业词汇 AI 词汇集 AI 词汇集 神经网络(Neural Network): 由节点(模型参数)和连接(权重)组成的网络结构,用于机器学习与深度学习。 深度学习(Deep Learning): 使用包含多隐藏层神经网络进行表征学习的机器学习方法。 机器学习(Machine Learnin…...

IP协议基础
文章目录 基本概念IP和TCP分别解决什么问题 以下过程都是在网络层完成的网段划分路由路由转发过程路由表 基本概念 主机: 配有IP地址, 但是不进行路由控制的设备。 路由器: 即配有IP地址, 又能进行路由控制。 节点: 主机和路由器的统称。 IP和TCP分别解决什么问题 TCP解决…...

Redis主从复制、哨兵实战
环境:linux centos7.x ,虚拟机3台 版本:redis-6.2.6 1.下载安转redis 下载地址 wget https://download.redis.io/releases/redis-6.2.6.tar.gz解压 tar -zxvf redis-6.2.6.tar.gz移动目录 mv redis-6.2.6 /usr/local/redis编译 cd /usr/…...

README.md编写
一、摘要 项目一般会有个描述文件,对于项目的代码来讲,这个描述就是README.md文件,可以描述各模块功能、目录结构等。该文件可以方便让人快速了解项目的代码结构和功能。当然,若要深层次的了解项目,就得看项目总体的需…...

软件设计证书倒计时28天
从一个月前的果断报考软件设计证书,我没有后悔过。 软件设计证书一个月备考情况: 现在做选择题的正确率可以达到65%。是重复做过两遍历年真题。 接下来是继续做模拟题。 大题的题型基本是都知道, 第一题数据流图,第二题er图&…...

程序员基础的硬件知识(cpu、主板、显卡、内存条等)
一、综合简介 cpu:负责运算数据,就等于你的大脑运算速度。 显卡:本来没有显卡,后来因为大家对图片要求越来越高,视频要求越来越高,啥都让cpu算太累了,于是分出来一个,专门用来计算…...
优化Google Cloud Storage大文件上传和内存溢出
背景 我们的项目每天都会并行上传好几万份文件到下游的GCP Cloud Storage,当文件比较大时,会采用GCP的可续上传方案,通过把文件切分成多个数据块,分多次HTTP请求上传到GCP Bucket,具体可参考https://cloud.google.com…...

chatGPT的prompt技巧
Prompt 公式是 Prompt 的特定格式,通常由三个主要元素组成: 任务:明确而简洁地陈述 Prompt 要求模型生成的内容。指令:模型在生成文本时应遵循的指令。角色:模型在生成文本时应扮演的角色。 指令 Prompt 技术 指令 …...
)
【华为OD机试 2023最新 】统一限载货物数最小值(C语言题解 100%)
文章目录 题目描述输入描述输出描述备注用例题目解析代码思路C语言题目描述 火车站附近的货物中转站负责将到站货物运往仓库,小明在中转站负责调度2K辆中转车(K辆干货中转车,K辆湿货中转车)。 货物由不同供货商从各地发来,各地的货物是依次进站,然后小明按照卸货顺序依…...

ios 在windows chrome 联调
必要条件 1、iOS设备、数据线 2、Node.js 环境 3、Chrome 浏览器 4、电脑登录iTunes 5、手机 Safari 浏览器环境准备 1、安装Node环境参考Node安装的教程,确保终端输入node时可正常使用 2、安装 scoope 以及相关配置为了安装后续需要用的工具 remotedebug-ios-web…...

干翻Mybatis源码系列之第六篇:Mybatis可选缓存概述
前言 一:后续Mybatis我们会研究那些内容? Mybatis核心运行源码分析(前面系列文章已经探讨过) Mybatis中缓存的使用 Mybatis与Spring集成 Mybatis 插件。 Mybatis的插件可以对Mybatis内核功能或者是业务功能进行拓展,…...

如何调教ChatGPT
调教ChatGPT需要进行以下步骤: 收集语料库 首先需要准备一定量的自然语言数据,这些数据可以是文本、对话、新闻等。语料库越大,模型效果通常会越好。 数据预处理 对于收集到的原始语料库需要进行一定的预处理操作,比如去除噪声…...
记一次我的漏洞挖掘实战——某公司的SQL注入漏洞
目录 一、前言 二、挖掘过程 1.谷歌语法随机搜索 2.进入网站 3.注入点检测 3.SQLMAP爆破 (1)爆库 (2)爆表 (3)爆字段 三、总结 一、前言 我是在漏洞盒子上提交的漏洞,上面有一个项目叫…...

代码随想录二刷复习 day1 704二分查找 27 移除元素 977 有序数组的平方
代码如下 func search(nums []int, target int) int { left : 0 right : len(nums)-1 for left < right { middle : (leftright)/2 if target < nums[middle] { //因为上面的判断条件是left < right,所以左右两个边界的值最后都能取到,而此…...

第16章 指令级并行与超标量处理器
处理器体系结构的超标量实现是指常见指令--整数与浮点算术、加载存储和条件分支--可以同时启动,但独立执行。 16.1 概述 超标量方法的本质是能在不同的流水线中独立地并发地执行指令。 在传统的标量组织结构中,其并行性是通过允许许多指令在同一时间处…...

Kohya Trainer 图像生成实战:利用训练好的模型进行高质量创作
Kohya Trainer 图像生成实战:利用训练好的模型进行高质量创作 【免费下载链接】kohya-trainer Adapted from https://note.com/kohya_ss/n/nbf7ce8d80f29 for easier cloning 项目地址: https://gitcode.com/gh_mirrors/ko/kohya-trainer Kohya Trainer 是一…...

CANN/ge算子句柄创建API
aclopCreateHandle 【免费下载链接】ge GE(Graph Engine)是面向昇腾的图编译器和执行器,提供了计算图优化、多流并行、内存复用和模型下沉等技术手段,加速模型执行效率,减少模型内存占用。 GE 提供对 PyTorch、TensorF…...

StofDoctrineExtensionsBundle的IpTraceable扩展:自动记录用户IP地址的简单实现指南 [特殊字符]
StofDoctrineExtensionsBundle的IpTraceable扩展:自动记录用户IP地址的简单实现指南 🚀 【免费下载链接】StofDoctrineExtensionsBundle Integration bundle for DoctrineExtensions by l3pp4rd in Symfony 项目地址: https://gitcode.com/gh_mirrors/…...

工程师如何构建高效个人知识库:从信息管理到生产力提升
1. 项目概述:从信息过载到有序管理,一个工程师的救赎之路作为一名在电子设计自动化(EDA)和嵌入式系统领域摸爬滚打了十几年的工程师,我的日常和原文作者Clive Maxfield描述的几乎一模一样。我的浏览器标签页常年保持在…...
Transformer注意力机制数据流优化与MMEE方法实践
1. 注意力机制数据流优化概述在Transformer架构和大型语言模型(LLM)中,注意力机制的计算开销通常占整体工作负载的60%以上。随着模型处理序列长度的不断增加,注意力计算面临的性能瓶颈日益凸显——其计算复杂度与序列长度呈二次方关系。这种特性使得传统…...

Anthropic研究院议程:不止做AI大模型,更要定义AI时代的全球规则
当大模型竞赛进入白热化,多数科技公司都在比拼参数、速度、模型能力时,OpenAI竞品Anthropic走出了一条完全不同的路。 近期,Anthropic 正式公布 Anthropic Institute(Anthropic研究院)全新研究议程,不再只埋头做模型研发,而是站在行业顶层视角,深度拆解AI对经济、安全、…...

基于Qlearning强化学习和人工势场融合算法的无人机航迹规划matlab仿真
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

【通信】D2D通信中基于Qlearning强化学习算法的联合资源分配与功率控制算法matlab仿真
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

Silvaco TCAD新手必看:迁移率模型到底怎么选?从CONMOB到ANALYTIC的保姆级指南
Silvaco TCAD迁移率模型选择指南:从理论到实践的完整决策框架 半导体器件仿真中,迁移率模型的选择往往让初学者感到无从下手。我第一次接触Silvaco TCAD时,面对CONMOB、ANALYTIC、KLAASSEN等十几种模型选项,花了整整两周时间才弄明…...

Diablo Edit2深度解析:技术架构与安全使用的暗黑2存档编辑完全手册
Diablo Edit2深度解析:技术架构与安全使用的暗黑2存档编辑完全手册 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit Diablo Edit2是一款功能强大的开源暗黑破坏神2存档编辑器࿰…...