优化Google Cloud Storage大文件上传和内存溢出
背景
我们的项目每天都会并行上传好几万份文件到下游的GCP Cloud Storage,当文件比较大时,会采用GCP的可续上传方案,通过把文件切分成多个数据块,分多次HTTP请求上传到GCP Bucket,具体可参考https://cloud.google.com/storage/docs/performing-resumable-uploads。 但是在实际应用中,会发现文件比较大时,由于数据包会被分成多次HTTP请求上传,偶尔GCP会返回400错误码导致上传失败,但是查看各个请求参数都属于正常,目前不确定GCP一些网络限制导致还是该 API 存在性能问题。于是我选择使用另一种替代方案,尝试使用以下方式,通过GCP 官方SDK进行文件上传。
GoogleCredentials apiCredentials = GoogleCredentials.fromStream(new FileInputStream(jsonKeyPath)).createScoped(scopes);Storage storage = StorageOptions.newBuilder().setCredentials(apiCredentials).build().getService();BlobId blobId = BlobId.of(bucketName, objectName);BlobInfo blobInfo = BlobInfo.newBuilder(blobId).setContentType("application/json;charset=UTF-8").setMd5(checksum).build();byte[] bytes = Files.readAllBytes(sourceFIle.toPath());storage.create(blobInfo,bytes);
SDK API参考https://cloud.google.com/java/docs/reference/google-cloud-storage/latest/overview。
文件小的时候速度还是比较快,因为它是直接Upload,不做数据分块,但是当文件大点或者数量多点,就会出现如下异常
java.lang.OutOfMemoryError: Required array size too large
原因是这句代码Files.readAllBytes(sourceFIle.toPath())会一次过把文件直接加载到内存,当文件比较大或者文件数量很多的时候,就会直接导致内存溢出。
虽然官方SDK也有针对大文件上传提供了可续上传方案,例如:
String bucketName = "my-unique-bucket";String blobName = "my-blob-name";BlobId blobId = BlobId.of(bucketName, blobName);byte[] content = "Hello, World!".getBytes(UTF_8);BlobInfo blobInfo = BlobInfo.newBuilder(blobId).setContentType("text/plain").build();try (WriteChannel writer = storage.writer(blobInfo)) {writer.write(ByteBuffer.wrap(content, 0, content.length));} catch (IOException ex) {// handle exception}
WriteChannel底层原理也是会在传输的时候会分块上传,并且遇到网络波动导致传输失败会自动基于上一次传输的数据包进行重传,但是这个也只是解决大文件上传性能问题,并没办法解决我们在加载源文件就已经内存溢出。
解决方案
其实解决办法也很简单,我们只需要把每次读书源文件的数据包在可控范围即可,也就是分块读取,分块上传,这样既保证大文件上传效率,也不会因为一次过加载文件太多导致内存溢出。
以下是示范代码:
主程序入口:
以下scope对应的是我们所需要的权限https://cloud.google.com/storage/docs/authentication
public static void main(String[] args) throws IOException {List<String> scopes = new ArrayList<>(Arrays.asList("https://www.googleapis.com/auth/devstorage.full_control","https://www.googleapis.com/auth/devstorage.read_write"));//GCP Json Key PathString jsonKeyPath = "";//File used to be uploadedFile sourceFile = new File("filePath");//Calculate file checksumString checksum = DigestUtils.md5Hex(new FileInputStream(sourceFile));//GCS BucketNameString bucketName = "";//GCS Target ObjectNameString objectName=sourceFile.getName();//Prepare connection details//https://cloud.google.com/storage/docs/authenticationGoogleCredentials apiCredentials = GoogleCredentials.fromStream(new FileInputStream(jsonKeyPath)).createScoped(scopes);Storage storage = StorageOptions.newBuilder().setCredentials(apiCredentials).build().getService();BlobId blobId = BlobId.of(bucketName, objectName);BlobInfo blobInfo = BlobInfo.newBuilder(blobId).setContentType("application/json;charset=UTF-8").setMd5(checksum).build();uploadToBucket(storage, sourceFile, blobInfo);}
上传方法:
这里的文件大小需要根据自己服务器实际的内存和带宽去设置,一般小文件使用直接上传方法效果最好,如果文件比较大,就需要进行数据包拆分。
关于数据块大小设置,以下是GCP的建议:
The chunk size should be a multiple of 256 KiB (256 x 1024 bytes), unless it's the last chunk that completes the upload. Larger chunk sizes typically make uploads faster, but note that there's a tradeoff between speed and memory usage. It's recommended that you use at least 8 MiB for the chunk size.
public static void uploadToBucket(Storage storage, File sourceFIle, BlobInfo blobInfo) throws IOException {//For small files, we can upload the file in one go// less than 10 MBif(sourceFIle.length() < 10000000){byte[] bytes = Files.readAllBytes(sourceFIle.toPath());storage.create(blobInfo,bytes);return;}//For big files , we need to split it into multiple chunkstry(WriteChannel writer = storage.writer(blobInfo)){//Don't read the whole file because it will cause OutOfMemory issuebyte[] buffer = new byte[10240];try(InputStream input = Files.newInputStream(sourceFIle.toPath())){int limit;while((limit = input.read(buffer))>=0){writer.write(ByteBuffer.wrap(buffer,0,limit));}}}}
以下这一句是解决这个问题的关键,每次只读取一部分数据,所以不会导致内存溢出。
while((limit = input.read(buffer))>=0){
测试效果
这里使用了项目用的GCP Storage和账号进行测试,多线程并行去上传4个210MB文件,由于我电脑在中国网络,而对应GCP Bucket部署在欧洲,所以速度不算快。

总结
其实这里解决方案不只适用于谷歌云,以前我们使用阿里云的时候,上传一些大文件也是采用这样的方式,适用于所有的文件传输场景,这里其实就是利用分治思想去解决问题。
完整代码
https://github.com/EvanLeung08/cloud-solutions/tree/main/gcs-largefile-upload
相关文章:
优化Google Cloud Storage大文件上传和内存溢出
背景 我们的项目每天都会并行上传好几万份文件到下游的GCP Cloud Storage,当文件比较大时,会采用GCP的可续上传方案,通过把文件切分成多个数据块,分多次HTTP请求上传到GCP Bucket,具体可参考https://cloud.google.com…...

chatGPT的prompt技巧
Prompt 公式是 Prompt 的特定格式,通常由三个主要元素组成: 任务:明确而简洁地陈述 Prompt 要求模型生成的内容。指令:模型在生成文本时应遵循的指令。角色:模型在生成文本时应扮演的角色。 指令 Prompt 技术 指令 …...
)
【华为OD机试 2023最新 】统一限载货物数最小值(C语言题解 100%)
文章目录 题目描述输入描述输出描述备注用例题目解析代码思路C语言题目描述 火车站附近的货物中转站负责将到站货物运往仓库,小明在中转站负责调度2K辆中转车(K辆干货中转车,K辆湿货中转车)。 货物由不同供货商从各地发来,各地的货物是依次进站,然后小明按照卸货顺序依…...

ios 在windows chrome 联调
必要条件 1、iOS设备、数据线 2、Node.js 环境 3、Chrome 浏览器 4、电脑登录iTunes 5、手机 Safari 浏览器环境准备 1、安装Node环境参考Node安装的教程,确保终端输入node时可正常使用 2、安装 scoope 以及相关配置为了安装后续需要用的工具 remotedebug-ios-web…...

干翻Mybatis源码系列之第六篇:Mybatis可选缓存概述
前言 一:后续Mybatis我们会研究那些内容? Mybatis核心运行源码分析(前面系列文章已经探讨过) Mybatis中缓存的使用 Mybatis与Spring集成 Mybatis 插件。 Mybatis的插件可以对Mybatis内核功能或者是业务功能进行拓展,…...

如何调教ChatGPT
调教ChatGPT需要进行以下步骤: 收集语料库 首先需要准备一定量的自然语言数据,这些数据可以是文本、对话、新闻等。语料库越大,模型效果通常会越好。 数据预处理 对于收集到的原始语料库需要进行一定的预处理操作,比如去除噪声…...
记一次我的漏洞挖掘实战——某公司的SQL注入漏洞
目录 一、前言 二、挖掘过程 1.谷歌语法随机搜索 2.进入网站 3.注入点检测 3.SQLMAP爆破 (1)爆库 (2)爆表 (3)爆字段 三、总结 一、前言 我是在漏洞盒子上提交的漏洞,上面有一个项目叫…...

代码随想录二刷复习 day1 704二分查找 27 移除元素 977 有序数组的平方
代码如下 func search(nums []int, target int) int { left : 0 right : len(nums)-1 for left < right { middle : (leftright)/2 if target < nums[middle] { //因为上面的判断条件是left < right,所以左右两个边界的值最后都能取到,而此…...

第16章 指令级并行与超标量处理器
处理器体系结构的超标量实现是指常见指令--整数与浮点算术、加载存储和条件分支--可以同时启动,但独立执行。 16.1 概述 超标量方法的本质是能在不同的流水线中独立地并发地执行指令。 在传统的标量组织结构中,其并行性是通过允许许多指令在同一时间处…...

JavaWeb ( 三 ) Web Server 服务器
1.5.Web Server服务器 Web Server 服务器是一种安装在服务器主机上的应用程序, 用于处理客户端(Web浏览器)的请求,并返回响应内容。服务器使用HTTP(超文本传输协议)与客户机浏览器进行信息交流。 简单说就是将http协议的信息翻译成对应开发语言可以处理的对象信息。…...

2.6 浮点运算方法和浮点运算器
学习目标: 以下是一些具体的学习目标: 理解浮点数的基本概念和表示方法,包括符号位、指数和尾数。学习浮点数的运算规则和舍入规则,包括加、减、乘、除、开方等。了解浮点数的常见问题和误差,例如舍入误差、溢出、下…...

第一次找实习, 什么项目可以给自己加分(笔记)
什么样的项目能简历加分、对找工作有帮助 基本特征: 一个特征是“硬核基础软件”,另一个为很实用的APP。 硬核基础软件 独立实现一个操作系统的kerne内核(操作系统的内部引擎) 北美计算机名校会让学生用一个学期的时间实现一个…...
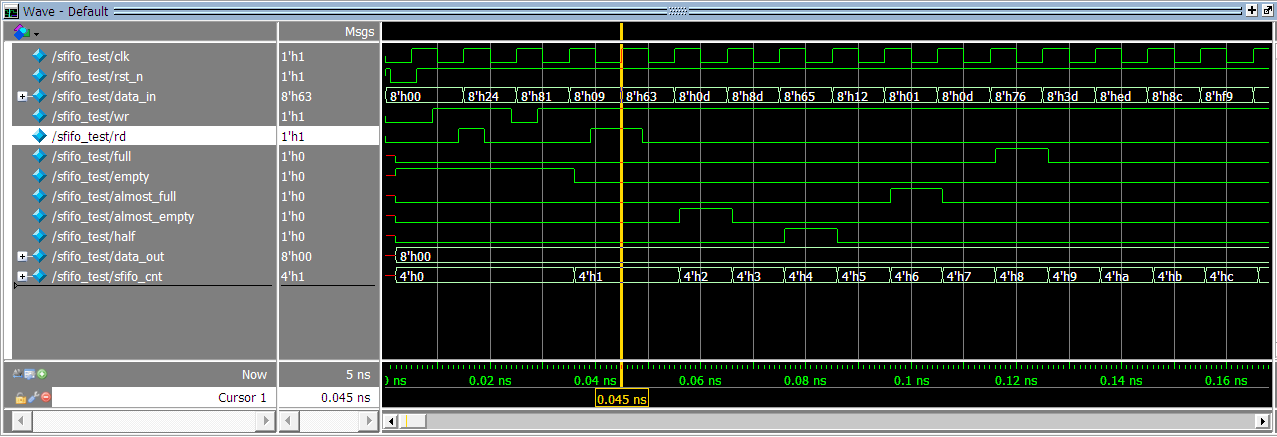
FPGA/Verilog HDL/AC620零基础入门学习——8*8同步FIFO实验
实验要求 该项目主要实现一个深度为8、位宽为8bit的同步FIFO存储单元。模块功能应包括读控制、写控制、同时读写控制、FIFO满状态、FIFO空状态等逻辑部分。 该项目由一个功能模块和一个testbench组成。其中功能模块的端口信号如下表所示。 提示: (1&a…...

shell脚本
shell函数 函数分类: 系统函数 自定义函数 常用系统函数: basename 从指定路径中获取文件名 dirname 从指定路径中获取目录名,去掉文件名 自定义函数 # 函数的定义 函数名 () { 命令 # 使用$n获取函数的参数 [return 返回…...

不部署服务端调用接口,前端接口神器json-server
简介 json-server 是一款小巧的接口模拟工具,一分钟内就能搭建一套 Restful 风格的 API,尤其适合前端接口测试使用。 只需指定一个 json 文件作为 api 的数据源即可,使用起来非常方便,30秒入门,基本上有手就行。 进阶…...
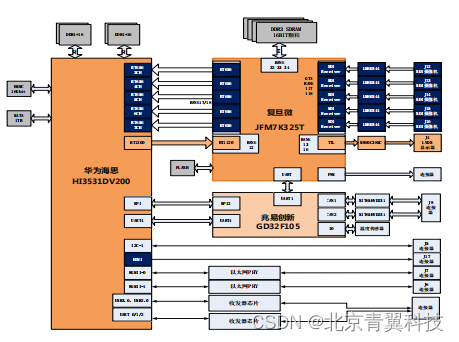
国产化:复旦微JFM7K325T +华为海思 HI3531DV200 的综合视频处理平台
板卡概述 TES714 是自主研制的一款 5 路 HD-SDI 视频采集图像处理平台,该平台采用上海复旦微的高性能 Kintex 系列 FPGA 加上华为海 思的高性能视频处理器 HI3531DV200 来实现。 华为海思的 HI3531DV200 是一款集成了 ARM A53 四核处理 器性能强大的神经网络引擎…...
)
Ceph入门到精通- stderr raise RuntimeError(‘Unable to create a new OSD id‘)
/bin/podman: stderr raise RuntimeError(Unable to create a new OSD id) podman ps |grep osd.0 podman stop osd.0 容器id 重新添加osd.0 集群目录 cd /var/lib/ceph/e8cde810-e4b8-11ed-9ba8-98039b976596/1109 ls1110 rm -rf osd.01111 ceph orch daemon add osd…...

AWSFireLens轻松实现容器日志处理
applog应用程序和fluent-bit共享磁盘,日志内容是json格式数据,输出到S3也是JSON格式 applog应用部分在applog目录: Dockerfile文件内容 FROM alpine RUN mkdir -p /data/logs/ COPY testlog.sh /bin/ RUN chmod 777 /bin/testlog.sh ENTRYP…...
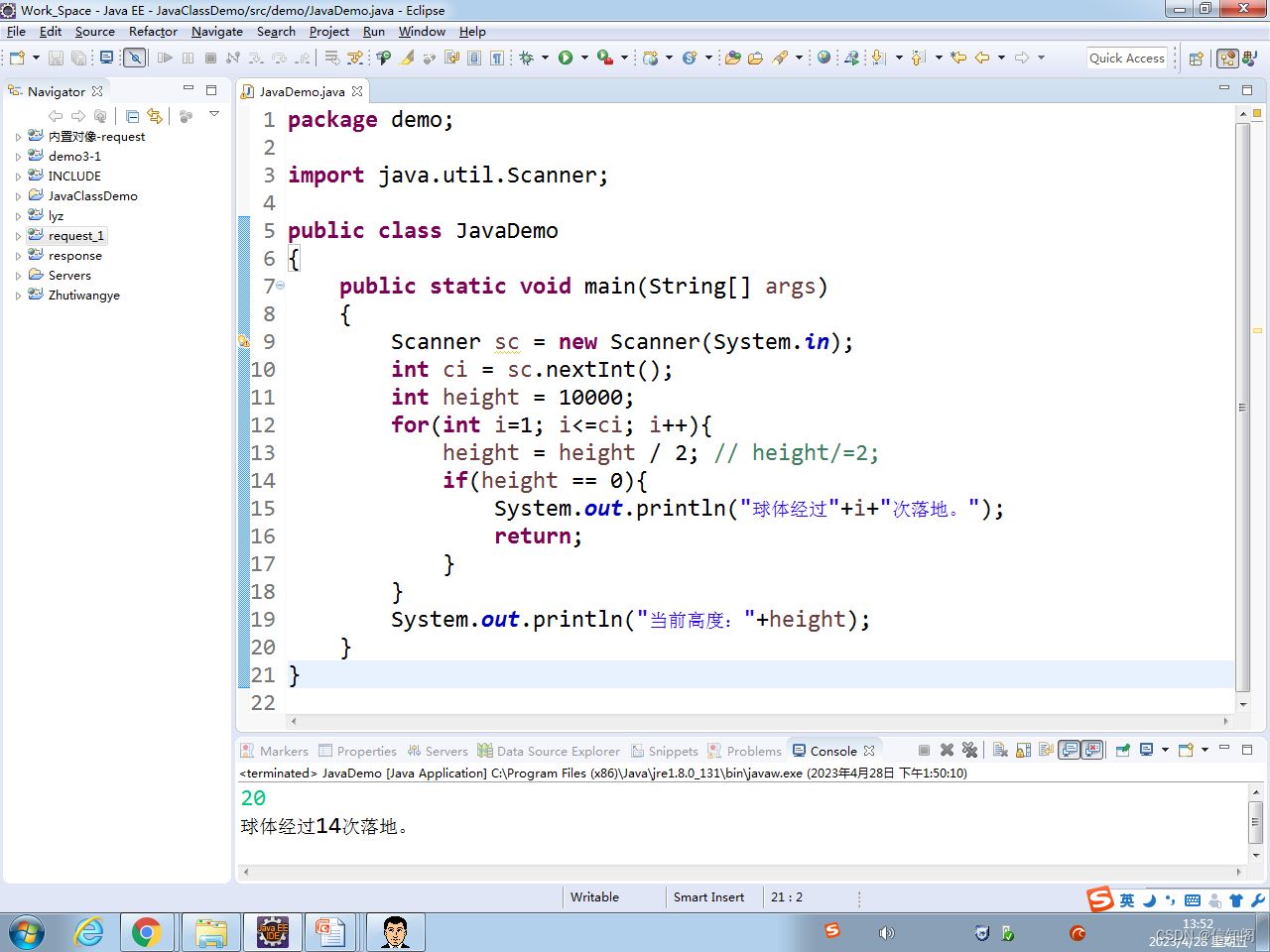
Java程序设计入门教程--案例:自由落体
程序模拟物体从10000米高空掉落后的反弹行为。 球体每落地一次,就会反弹至原高度的一半。按用户输入的弹跳次数,计算球体每次弹跳的高度。 实现过程: 1. 新建项目; 2. 接收 用户输入的弹跳次数: (1&#…...

Qt音视频开发44-本地摄像头推流(支持分辨率/帧率等设置/实时性极高)
一、前言 本地摄像头推流和本地桌面推流类似,无非就是采集的设备源头换成了本地摄像头设备而不是桌面,其他代码完全一样。采集本地摄像头实时视频要注意的是如果设置分辨率和帧率,一定要是设备本身就支持的,如果不支持那就歇菜&a…...

Fasd终极路线图:2025年项目发展方向与社区规划完全指南
Fasd终极路线图:2025年项目发展方向与社区规划完全指南 【免费下载链接】fasd Command-line productivity booster, offers quick access to files and directories, inspired by autojump, z and v. 项目地址: https://gitcode.com/gh_mirrors/fa/fasd Fasd…...

罗斯蒙特RoseMount手操器TREXLFPKL9S1
罗斯蒙特475手操器是一款由艾默生(Emerson)推出的高性能现场通讯设备,广泛应用于工业自动化领域,用于配置、校准和诊断HART及Foundation Fieldbus协议的智能仪表设备。它具备彩色图形界面、蓝牙通信、强大的现场诊断功能和可用户升…...

公开信息整理|2026年3月26日:科学进展、词元活动、食品安全、护理保险与部分国际动态速览
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...

Qwen1.5-1.8B GPTQ生成技术博客大纲与初稿:以“操作系统内存管理”为例
Qwen1.5-1.8B GPTQ生成技术博客大纲与初稿:以“操作系统内存管理”为例 1. 引言:当AI成为技术写作的“副驾驶” 最近在折腾一些技术分享,想写一篇关于操作系统内存管理的文章。这话题吧,说深了容易劝退,说浅了又没意…...

SleeperX:Mac电源管理的智能守护者,让每一次工作都不被打断
SleeperX:Mac电源管理的智能守护者,让每一次工作都不被打断 【免费下载链接】SleeperX MacBook prevent idle/lid sleep! Hackintosh sleep on low battery capacity. 项目地址: https://gitcode.com/gh_mirrors/sl/SleeperX 您是否经历过这样的时…...

Llama-3.2V-11B-cot多轮对话效果展示:复杂技术问题拆解与解答
Llama-3.2V-11B-cot多轮对话效果展示:复杂技术问题拆解与解答 最近在测试各种大模型时,我特意找了一个比较“刁钻”的场景:让模型来解答一个复杂的系统设计问题。这类问题通常不是一两句话能说清的,它需要模型有很强的逻辑推理能…...

【AI视频从0到1系统课】导师全程陪跑、课程持续更新、适合零基础!
在 AI 视频工具日益同质化的当下,课程的核心竞争力已从“教你用什么工具”转向“如何帮你拿到结果”。面对“2026 全新升级”与“陪伴式教育”这类宣传语,阅读的关键在于验证其服务颗粒度与学习转化率。 一、 解构“陪伴式教育”:关注反馈机制…...

Windows系统下安装与配置FreeSWITCH完整指南
本文提供在 Windows 系统上安装 FreeSWITCH 的完整步骤,涵盖下载、安装、配置、启动测试,以及可能遇到问题的解决方案,帮助你顺利完成开发环境的搭建。 一、环境准备与下载 1.1 系统要求 项目要求操作系统Windows 7/8/10/11,Wi…...

智能体架构的创新突破:Agent-S框架的技术解析与实战应用
智能体架构的创新突破:Agent-S框架的技术解析与实战应用 【免费下载链接】Agent-S Agent S: an open agentic framework that uses computers like a human 项目地址: https://gitcode.com/GitHub_Trending/ag/Agent-S Agent-S作为开源的智能体框架ÿ…...

2026年云储存哪个好用?5款免费又便捷的工具深度盘点
在如今这个数字化时代,云储存软件成为了我们存储、管理和共享数据的得力助手。无论是个人用户保存生活照片、工作文档,还是企业团队协作共享资源,都离不开云储存。 然而市场上软件众多,到底哪个才真正好用?为了帮助大…...