轻松搭建自己的ChatGPT聊天机器人,让AI陪你聊天!
随着人工智能技术的发展,聊天机器人已经成为了我们生活中的一部分。无论是在客服机器人上还是智能助手上,聊天机器人都能够给我们带来真正的便利和快乐。现在,你也可以轻松搭建自己的ChatGPT聊天机器人,和它天马行空地聊天!
第一步:准备所需材料
首先,你需要一些基本的技术知识和一些必备的软件工具,包括:
-
Python基本语法:ChatGPT是使用Python开发的,因此你需要先掌握一些基本的Python语法。
-
PyTorch:ChatGPT是使用PyTorch构建的,因此在搭建ChatGPT之前,你需要先了解PyTorch的基本使用方法。
-
Transformers库:这是一个用于自然语言处理的Python库,可以帮助我们轻松地搭建和训练ChatGPT模型。
第二步:搭建ChatGPT模型
现在你已经准备好了所有必要的软件工具,那么就让我们开始搭建ChatGPT模型吧!
以下是一个简单的示例代码,可以使用Transformers和PyTorch搭建ChatGPT模型:
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel# 加载预训练模型和分词器
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')# 输入文本
text = 'Hello, how are you?'# 将文本编码为ID
input_ids = tokenizer.encode(text, return_tensors='pt')# 生成响应
output = model.generate(input_ids, max_length=1000)# 将响应解码为文本
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(output_text)
这段代码使用了GPT2模型和分词器,从输入文本中生成了一个1000个字符的响应。
第三步:训练ChatGPT模型
如果你想让你的ChatGPT模型可以更加智能和对话更加流畅,那么你需要利用机器学习的方法对模型进行训练。
以下是一个简单的示例代码,可以使用Transformers和PyTorch训练ChatGPT模型:
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel, TextDataset, DataCollatorForLanguageModeling, Trainer, TrainingArguments# 加载预训练模型和分词器
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')# 加载数据集
dataset = TextDataset(tokenizer=tokenizer, file_path='data.txt', block_size=128)# 设置训练参数
training_args = TrainingArguments(output_dir='./results', # output directoryoverwrite_output_dir=True, # overwrite the content of the output directorynum_train_epochs=1, # number of training epochsper_device_train_batch_size=32, # batch size for trainingsave_steps=1000, # save checkpoint every 1000 stepssave_total_limit=2, # only keep last 2 checkpointswarmup_steps=500, # number of warmup steps for learning rate schedulerweight_decay=0.01, # strength of weight decaylogging_dir='./logs', # directory for storing logslogging_steps=1000, # log every 1000 steps)# 设置DataCollator
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False,
)# 构建Trainer
trainer = Trainer(model=model,args=training_args,data_collator=data_collator,train_dataset=dataset,
)# 开始训练
trainer.train()
这段代码使用了TextDataset和DataCollatorForLanguageModeling来读取和处理数据集,使用GPT2模型和分词器训练ChatGPT模型,并将结果保存在results目录中。
第四步:让ChatGPT机器人和你聊天
现在你已经成功搭建和训练了自己的ChatGPT机器人了!那么让我们来看看如何和它进行聊天。
以下是一个简单的示例代码,可以使用训练好的ChatGPT机器人进行聊天:
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel# 加载训练好的模型和分词器
tokenizer = GPT2Tokenizer.from_pretrained('results')
model = GPT2LMHeadModel.from_pretrained('results')# 开始聊天
while True:# 获取用户输入user_input = input('You: ')# 将用户输入编码为IDinput_ids = tokenizer.encode(user_input, return_tensors='pt')# 生成响应output = model.generate(input_ids, max_length=1000)# 将响应解码为文本output_text = tokenizer.decode(output[0], skip_special_tokens=True)# 输出机器人的响应print('ChatGPT: ' + output_text)
这段代码使用了训练好的模型和分词器,可以和ChatGPT机器人进行聊天交流!
结语
通过这份资料,你已经学会了如何搭建、训练和使用ChatGPT聊天机器人了!希望这份资料能够帮助你打造出一款智能、有趣的聊天机器人,让你的生活充满更多色彩!
相关文章:

轻松搭建自己的ChatGPT聊天机器人,让AI陪你聊天!
随着人工智能技术的发展,聊天机器人已经成为了我们生活中的一部分。无论是在客服机器人上还是智能助手上,聊天机器人都能够给我们带来真正的便利和快乐。现在,你也可以轻松搭建自己的ChatGPT聊天机器人,和它天马行空地聊天&#x…...
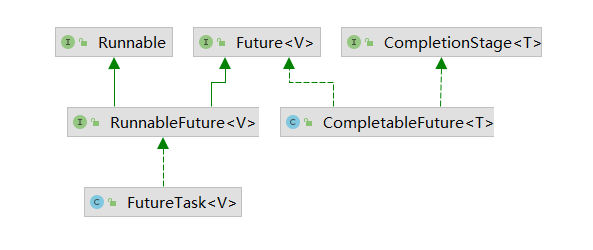
CompletableFutrue异步处理
异步处理 一、线程的实现方式 1. 线程的实现方式 1.1 继承Thread class ThreadDemo01 extends Thread{Overridepublic void run() {System.out.println("当前线程:" Thread.currentThread().getName());} }1.2 实现Runnable接口 class ThreadDemo02 implements …...

【前端面经】JS-对象的可枚举性
JavaScript中的对象是非常重要的数据类型,它们作为编程中的基础构建块,可以被用来表示各种数据结构。对象是由属性构成的,每个属性都包含一个名字和一个值。属性值可以是基本类型或其他对象。在JavaScript中,对象属性有许多特性&a…...
沁恒 CH32V208(三): CH32V208 Ubuntu22.04 Makefile VSCode环境配置
目录 沁恒 CH32V208(一): CH32V208WBU6 评估板上手报告和Win10环境配置沁恒 CH32V208(二): CH32V208的储存结构, 启动模式和时钟沁恒 CH32V208(三): CH32V208 Ubuntu22.04 Makefile VSCode环境配置 硬件部分 CH32V208WBU6 评估板WCH-LinkE 或 WCH-Link 硬件环境与Windows下…...
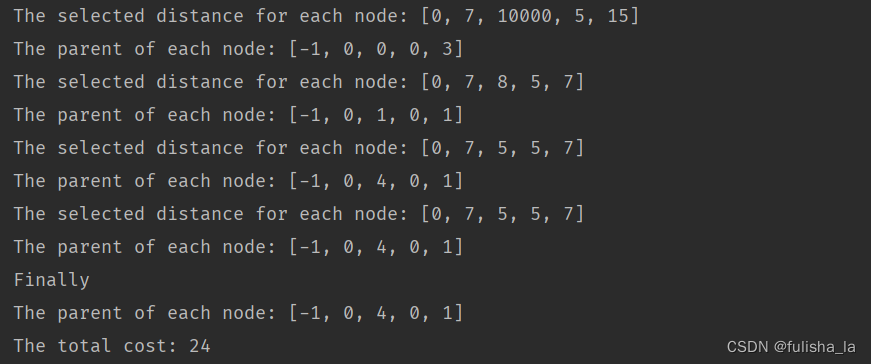
日撸 Java 三百行day38
文章目录 说明day381.Dijkstra 算法思路分析2.Prim 算法思路分析3.对比4.代码 说明 闵老师的文章链接: 日撸 Java 三百行(总述)_minfanphd的博客-CSDN博客 自己也把手敲的代码放在了github上维护:https://github.com/fulisha-ok/…...
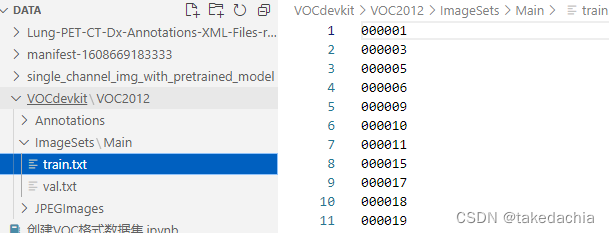
玩转肺癌目标检测数据集Lung-PET-CT-Dx ——④转换成PASCAL VOC格式数据集
文章目录 关于PASCAL VOC数据集目录结构 ①创建VOC数据集的几个相关目录XML文件的形式 ②读取dcm文件与xml文件的配对关系③创建VOC格式数据集④创建训练、验证集 本文所用代码见文末Github链接。 关于PASCAL VOC数据集 pascal voc数据集是关于计算机视觉,业内广泛…...

两种使用 JavaScript 实现网页高亮关键字的方法
随着各种类型的信息源变得越来越多,我们常常需要通过搜索引擎来找到自己需要的信息。在搜索结果中,通常会高亮显示与我们搜索的关键词相关的内容,这样我们就能更快地找到自己需要的信息。 在本文中,我们将探讨如何使用 JavaScrip…...
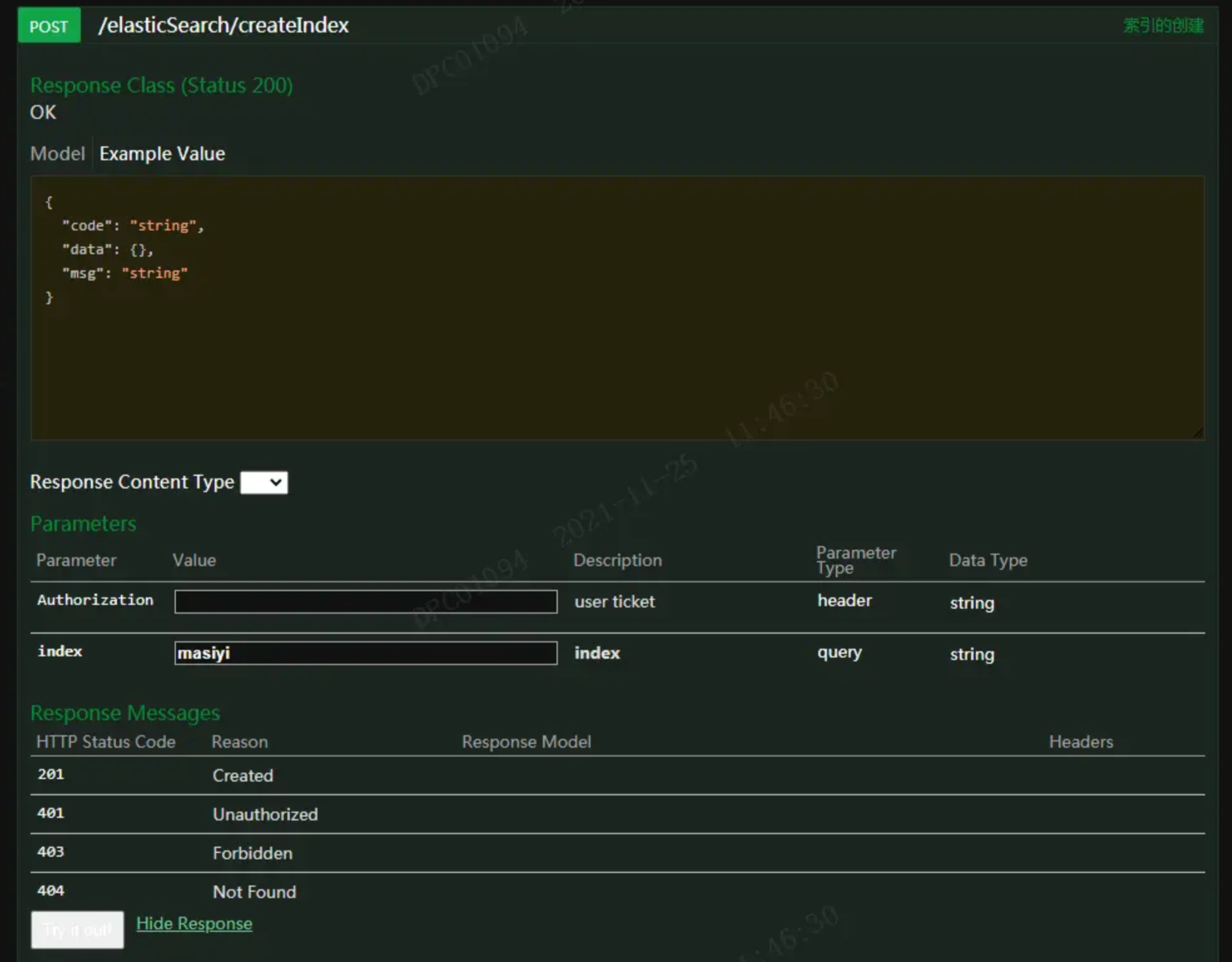
【SpringBoot】SpringBoot集成ElasticSearch
文章目录 第一步,导入jar包,注意这里的jar包版本可能和你导入的不一致,所以需要修改第二步,编写配置类第三步,填写yml第四步,编写util类第五步,编写controller类第六步,测试即可 第一…...
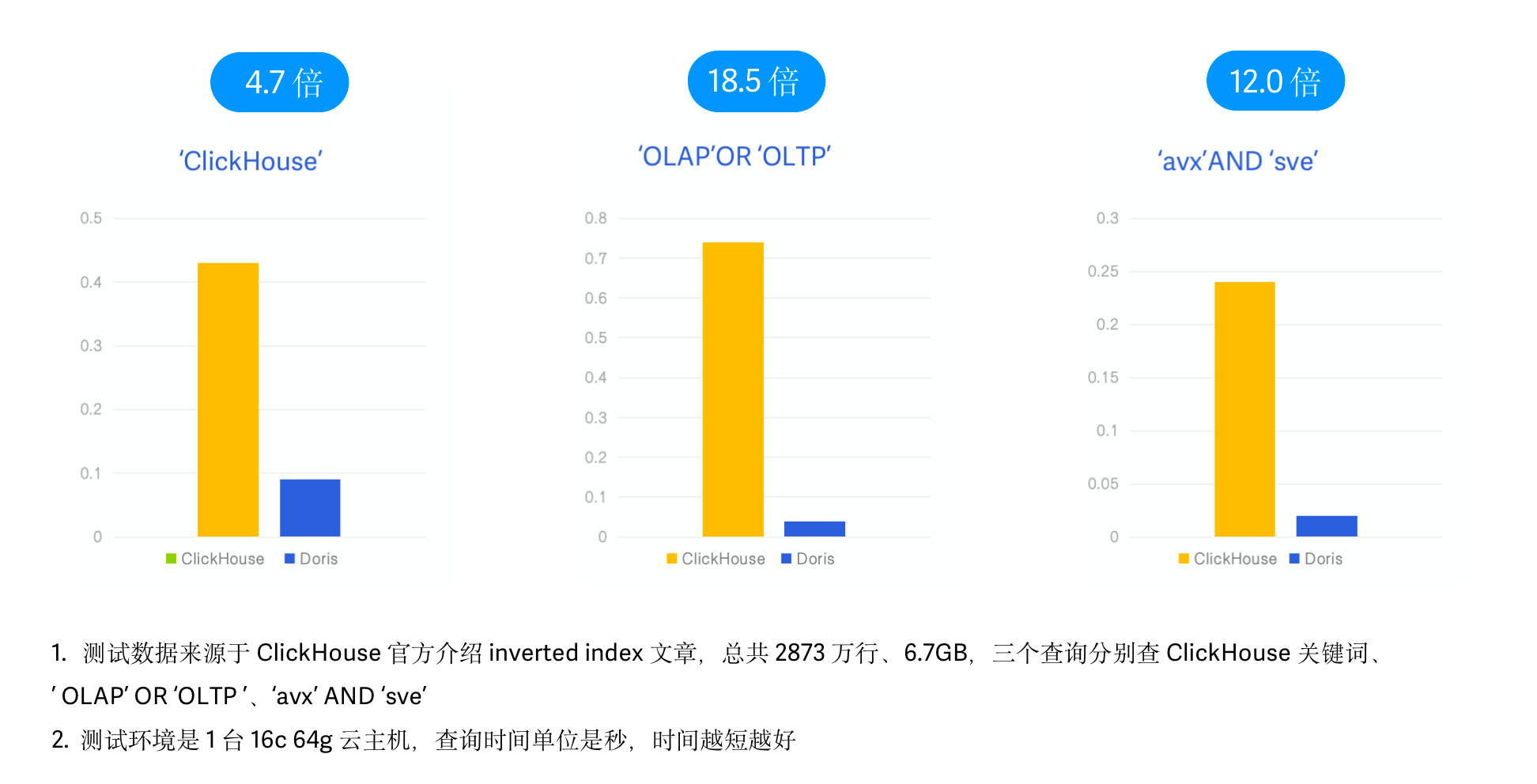
从 Elasticsearch 到 Apache Doris,10 倍性价比的新一代日志存储分析平台
作者介绍:肖康,SelectDB 技术副总裁 导语 日志数据的处理与分析是最典型的大数据分析场景之一,过去业内以 Elasticsearch 和 Grafana Loki 为代表的两类架构难以同时兼顾高吞吐实时写入、低成本海量存储、实时文本检索的需求。Apache Doris…...

探讨Redis缓存问题及解决方案:缓存穿透、缓存击穿、缓存雪崩与缓存预热(如何解决Redis缓存中的常见问题并提高应用性能)
Redis是一种非常流行的开源缓存系统,用于缓存数据以提高应用程序性能。但是,如果我们不注意一些缓存问题,Redis也可能会导致一些性能问题。在本文中,我们将探讨Redis中的一些常见缓存问题,并提供解决方案。 一、缓存穿…...
)
【Python】怎么在pip下载的时候设置镜像?(常见的清华镜像、阿里云镜像以及中科大镜像)
一、清华镜像 在使用 pip 命令下载 Python 包时,可以通过设置 pip 的镜像源为清华镜像来加快下载速度。 以下是如何设置清华镜像源的步骤: 打开终端或命令行窗口执行以下命令添加清华镜像源: pip config set global.index-url https://py…...
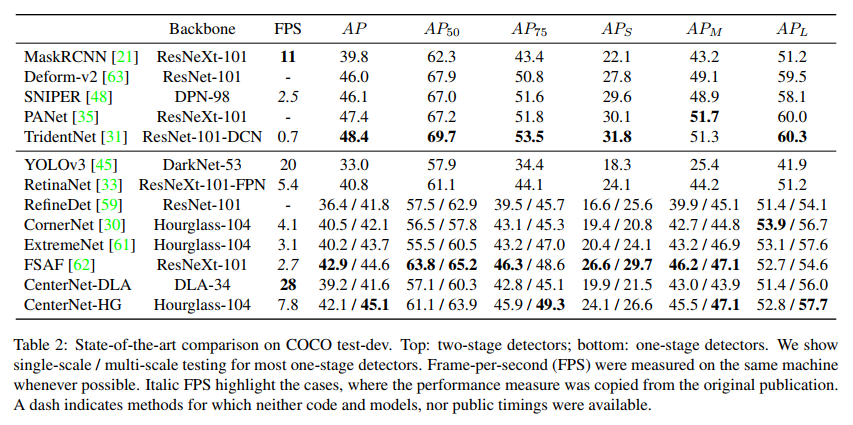
【AI面试】目标检测中one-stage、two-stage算法的内容和优缺点对比汇总
在深度学习领域中,图像分类,目标检测和目标分割是三个相对来说较为基础的任务了。再加上图像生成(GAN,VAE,扩散模型),keypoints关键点检测等等,基本上涵盖了图像领域大部分场景了。 …...

stack、queue和priority_queue的使用介绍--C++
目录 一、stack介绍 使用方法 二、queue介绍 queue的使用 三、priority_queeue 优先级队列介绍 一、stack介绍 1. stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。 2. stack是作为容器…...

python遍历数组
在Python中,有多种方式可以遍历数组,以下是其中的几种方式: 1. 使用for循环: my_list [1, 2, 3, 4, 5] for x in my_list: print(x) 2. 使用while循环和索引: my_list [1, 2, 3, 4, 5] i 0 while i < len(m…...
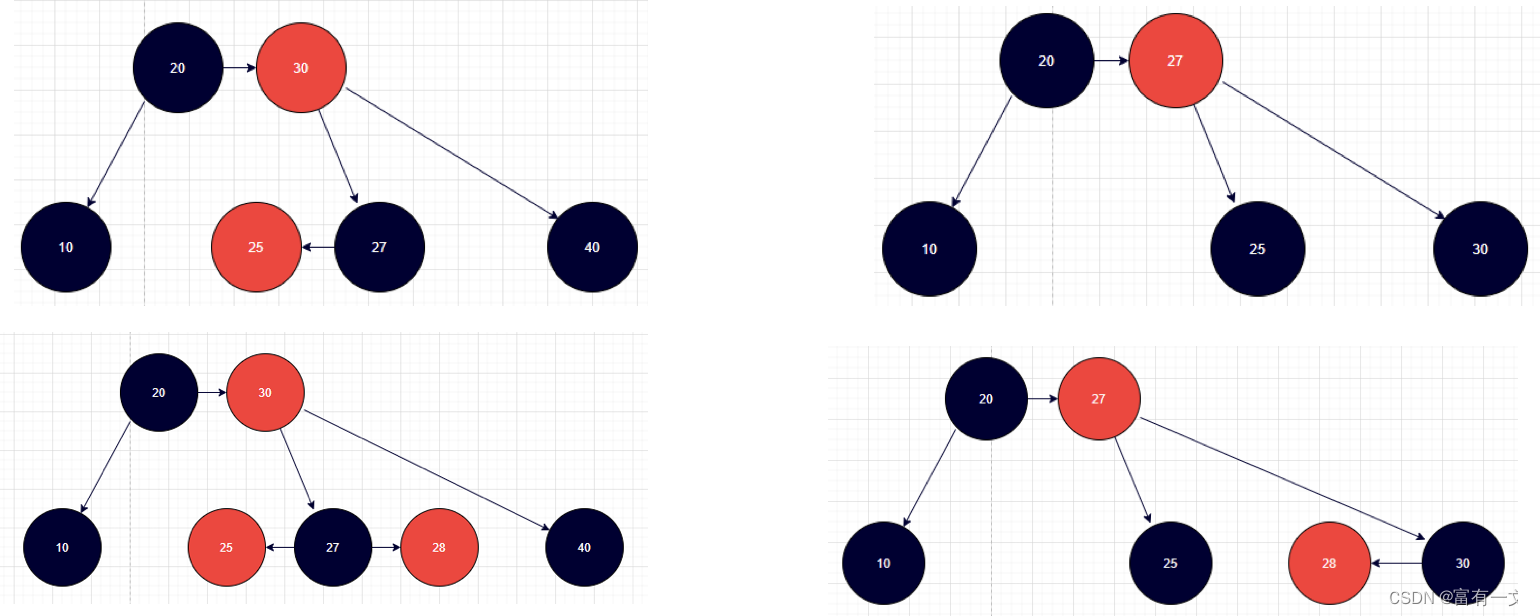
红黑树理论详解与Java实现
文章目录 基本定义五大性质红黑树和2-3-4树的关系红黑树和2-3-4树各结点对应关系添加结点到红黑树注意事项添加的所有情况 添加导致不平衡叔父节点不是红色节点(祖父节点为红色)添加不平衡LL/RR添加不平衡LR/RL 叔父节点是红色节点(祖父节点为…...

container的讲解
我们做开发经常会遇到这样的一个需求,要开发一个响应式的网站,但是我们需要我们的元素样式跟随着我们的元素尺寸大小变化而变化。而我们常用的媒体查询(Media Queries)检测的是视窗的宽高,根本无法满足我们的业务需求&…...

JavaScript 箭头函数
(许多人所谓的成熟,不过是被习俗磨去了棱角,变得世故而实际了。那不是成熟,而是精神的早衰和个性的消亡。真正的成熟,应当是独特个性的形成,真实自我的发现,精神上的结果和丰收。——周国平&…...

简单理解Transformer注意力机制
这篇文章是对《动手深度学习》注意力机制部分的简单理解。 生物学中的注意力 生物学上的注意力有两种,一种是无意识的,零一种是有意识的。如下图1,由于红色的杯子比较突出,因此注意力不由自主指向了它。如下图2,由于…...

Vue3面试题:20道含答案和代码示例的练习题
Vue3中响应式数据的实现原理是什么? 答:Vue3中使用Proxy对象来实现响应式数据。当数据发生变化时,Proxy会自动触发更新。 const state {count: 0 }const reactiveState new Proxy(state, {set(target, key, value) {target[key] valueco…...

Oracle数据库创建用户
文章目录 1 查看当前连接的容器2 查看pdb下库的信息3 将连接改到XEPDB1下,并查看当前连接4 创建表空间5 创建用户6 用户赋权7 删除表空间、用户7.1 删除表空间7.2 删除用户 8 CDB与PDB的概念 1 查看当前连接的容器 SQL> show con_name;CON_NAME ---------------…...
)
从DC到DCG:手把手教你搭建物理感知综合流程(含DEF文件处理避坑指南)
从DC到DCG:物理感知综合全流程实战指南 在28nm以下工艺节点,传统逻辑综合工具已难以应对复杂的物理效应。我们团队在最近一次5nm芯片项目中,由于初期忽视物理感知综合的约束设置,导致时序收敛多耗费三周时间。本文将分享从Design …...

WebToEpub:5分钟快速制作专业EPUB电子书的完整指南
WebToEpub:5分钟快速制作专业EPUB电子书的完整指南 【免费下载链接】WebToEpub A simple Chrome (and Firefox) Extension that converts Web Novels (and other web pages) into an EPUB. 项目地址: https://gitcode.com/gh_mirrors/we/WebToEpub 还在为在线…...

别再瞎试了!用Python+正交设计,5分钟搞定你的多因素实验方案
用Python正交设计高效优化多因素实验方案 在数据科学和工程实践中,我们经常面临需要同时优化多个参数的挑战。无论是机器学习模型的超参数调优,还是化工生产中的工艺条件优化,传统的一一尝试方法不仅耗时耗力,而且难以捕捉因素间的…...

从赛博朋克到量子有机体,未来主义风格演进全图谱,深度解析MJ 5.2→6.2→NijiV6的渲染范式跃迁
更多请点击: https://intelliparadigm.com 第一章:赛博朋克到量子有机体:未来主义视觉范式的哲学跃迁 当霓虹雨巷中的义体少女凝视全息广告牌,她瞳孔倒映的已不仅是资本编码的欲望图景,而是意识与拓扑量子态耦合的初始…...

免费开源的终极分子绘图神器:5分钟快速上手Ketcher完整指南
免费开源的终极分子绘图神器:5分钟快速上手Ketcher完整指南 【免费下载链接】ketcher Web-based molecule sketcher 项目地址: https://gitcode.com/gh_mirrors/ke/ketcher 你是否厌倦了笨重的化学绘图软件?想找一款既专业又轻量的分子结构编辑器…...

ComfyUI-Inpaint-CropAndStitch:如何用局部修复技术将AI图像处理速度提升100倍
ComfyUI-Inpaint-CropAndStitch:如何用局部修复技术将AI图像处理速度提升100倍 【免费下载链接】ComfyUI-Inpaint-CropAndStitch ComfyUI nodes to crop before sampling and stitch back after sampling that speed up inpainting 项目地址: https://gitcode.com…...
)
保姆级教程:在HCL模拟器上给H3C路由器配置DHCP服务器(双网段实战)
从零构建H3C路由器双网段DHCP服务:模拟器实战与协议解析 在虚拟实验室中搭建网络环境已成为现代工程师的必备技能,而DHCP服务作为网络自动化的基石,其配置过程往往成为初学者接触企业级设备的第一个实战挑战。本文将使用H3C官方推出的HCL模拟…...

从零到一:手把手部署openGauss极简版并完成基础运维
1. 环境准备:从零搭建openGauss的基石 第一次接触openGauss时,我被它"极简版"的宣传吸引,但真正动手部署才发现,前期环境准备才是决定成败的关键。就像盖房子需要打地基,数据库安装前的系统配置直接影响后续…...

AI工作流引擎设计:从Prompt工程到可编程组件的系统化实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫jmagly/aiwg。乍一看这个仓库名,可能有点摸不着头脑,但点进去之后,你会发现它其实是一个关于“AI写作指南”或“AI工作流生成器”的雏形。这类项目在当前AI应用爆发…...

JSON Lint for PHP:如何构建企业级JSON数据验证解决方案?
JSON Lint for PHP:如何构建企业级JSON数据验证解决方案? 【免费下载链接】jsonlint JSON Lint for PHP 项目地址: https://gitcode.com/gh_mirrors/jso/jsonlint 在现代Web开发和API设计中,JSON数据验证是确保系统稳定性的关键环节。…...