【计算机视觉 | 自然语言处理】BLIP:统一视觉—语言理解和生成任务(论文讲解)
文章目录
- 一、前言
- 二、试玩效果
- 三、研究背景
- 四、模型结构
- 五、Pre-training objectives
- 六、CapFilt架构
- 七、Experiment
- 八、结论
一、前言
今天我们要介绍的论文是 BLIP,论文全名为 Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation。

论文地址为:
https://arxiv.org/pdf/2201.12086.pdf
代码地址为:
https://github.com/salesforce/BLIP
试玩地址为:
https://huggingface.co/spaces/akhaliq/BLIP
在开始正文之前,我们不妨先来试试试玩的效果如何。
二、试玩效果
BLIP 的效果如何呢?用户只需上传一张图像,或单击内置示例加载图像就可完成。
BLIP 模型具有两个功能:
- 图像标注
- 回答问题
BLIP 的 Gradio 演示:用于统一视觉-语言理解和生成的引导语言-图像预训练(Salesforce 研究)。 从 2023 年 3 月 23 日起,现在已禁用图像上传。单击其中一个示例以加载它们:
上传著名油画《星夜》,在图像标注功能下模型输出「caption: a painting with many clouds above the city」。
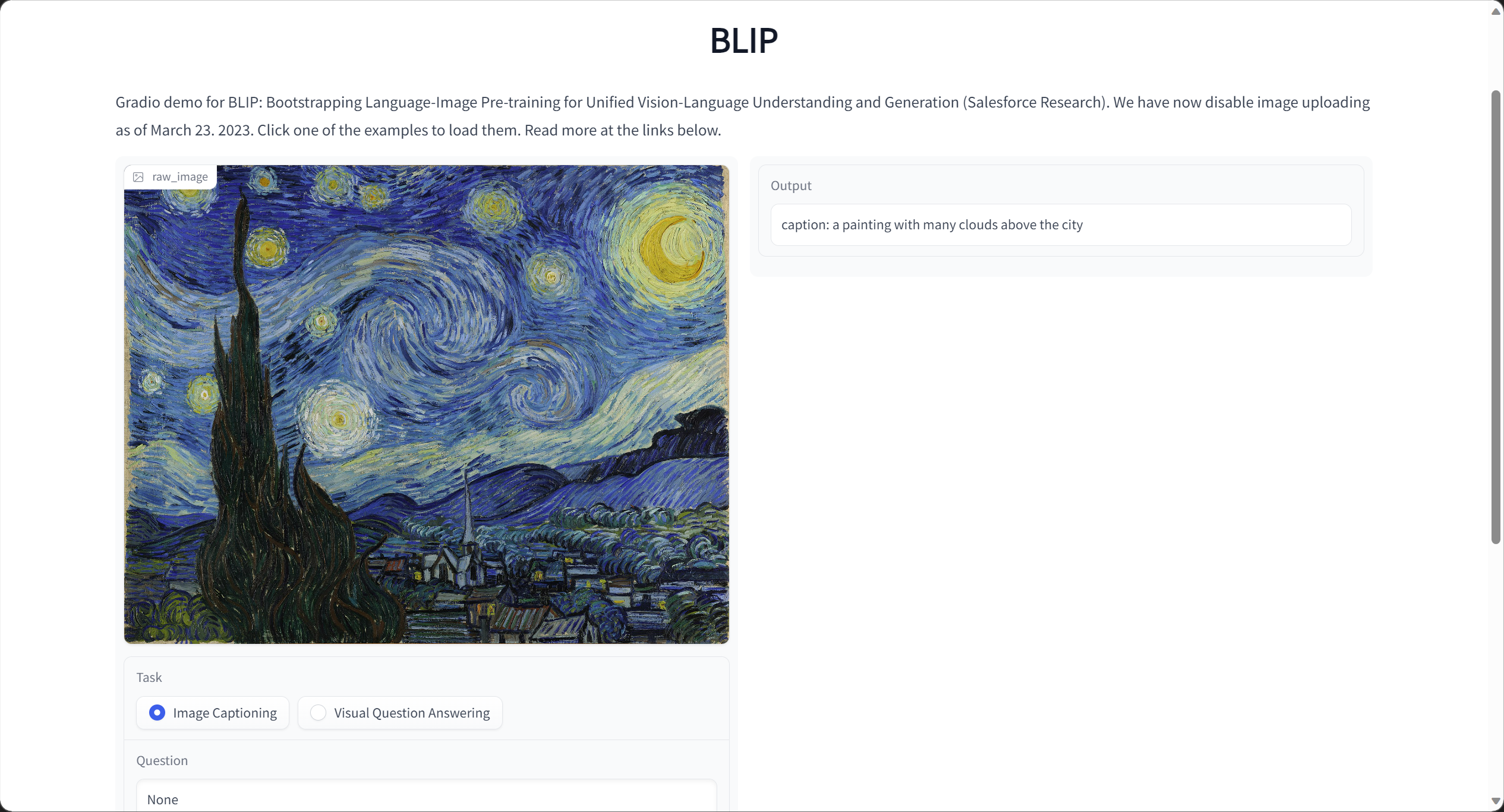
我们看一下之前其他博主测试的一些效果:
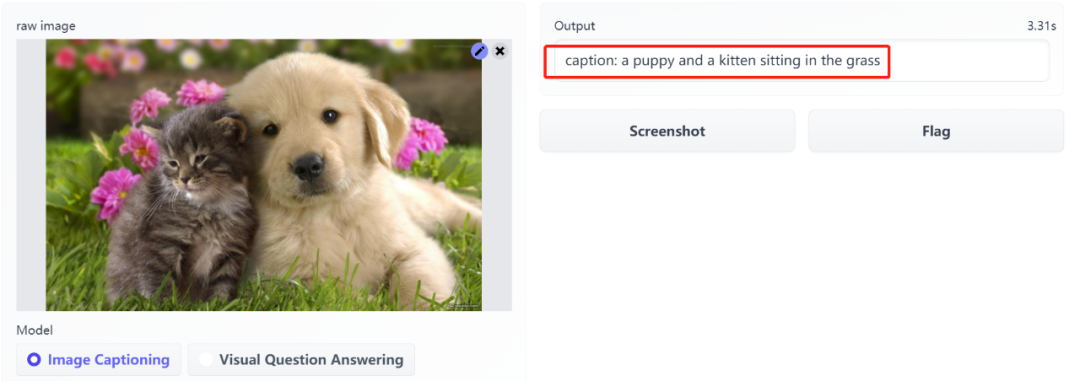

根据试玩效果来看还是不错的。
三、研究背景
视觉 - 语言预训练 (Vision-Language Pre-training,VLP) 提高了许多视觉 - 语言任务的性能。然而,大多数现有的预训练模型只能在基于理解任务(understanding-based tasks)或基于生成任务(generation-based tsaks)中表现出色。
但很少在这两方面都能取得较好的结果。
现有的 VLP 方法主要存在两个局限性:
- 从模型角度来讲,大多数方法采用基于编码器的模型,或者采用基于编码器 - 解码器模型。然而,基于编码器的模型很难直接转换到文本生成任务中,而编码器 - 解码器模型还没有成功地用于图像 - 文本检索任务;
- 从数据角度来讲,像 CLIP、SimVLM 等 SOTA 模型通过在 web 上收集的图像 - 文本对进行预训练,尽管扩大数据集获得了性能提升,但 web 上的文本具有噪声,对 VLP 来说并不是最优。
近日,来自 Salesforce Research 的研究者提出了 BLIP(Bootstrapping Language-Image Pre-training),用于统一视觉 - 语言理解和生成任务。
BLIP 是一个新的 VLP 框架,可以支持比现有方法更广泛的下游任务。
BLIP 通过自展标注(bootstrapping the captions),可以有效地利用带有噪声的 web 数据,其中标注器(captioner)生成标注,过滤器(filter)去除有噪声的标注。
该研究在视觉 - 语言任务上取得了 SOTA 性能,例如在图像 - 文本检索任务上, recall@1 提高 2.7%;在图像标注任务上,CIDEr 提高 2.8%、VQA 提高 +1.6%。
当将 BLIP 以零样本的方式直接迁移到视频 - 语言任务时,BLIP 也表现出很强的泛化能力。
四、模型结构
研究者提出的 BLIP 是一个统一的视觉语言预训练(vision-language pre-training, VLP)框架,从有噪声的图像文本对中学习。
接下来详细解读模型架构 MED(mixture of encoder-decoder)、它的预训练目标以及用于数据集自展的方法 CapFilt。
下图为 BLIP 的预训练模型架构和目标:
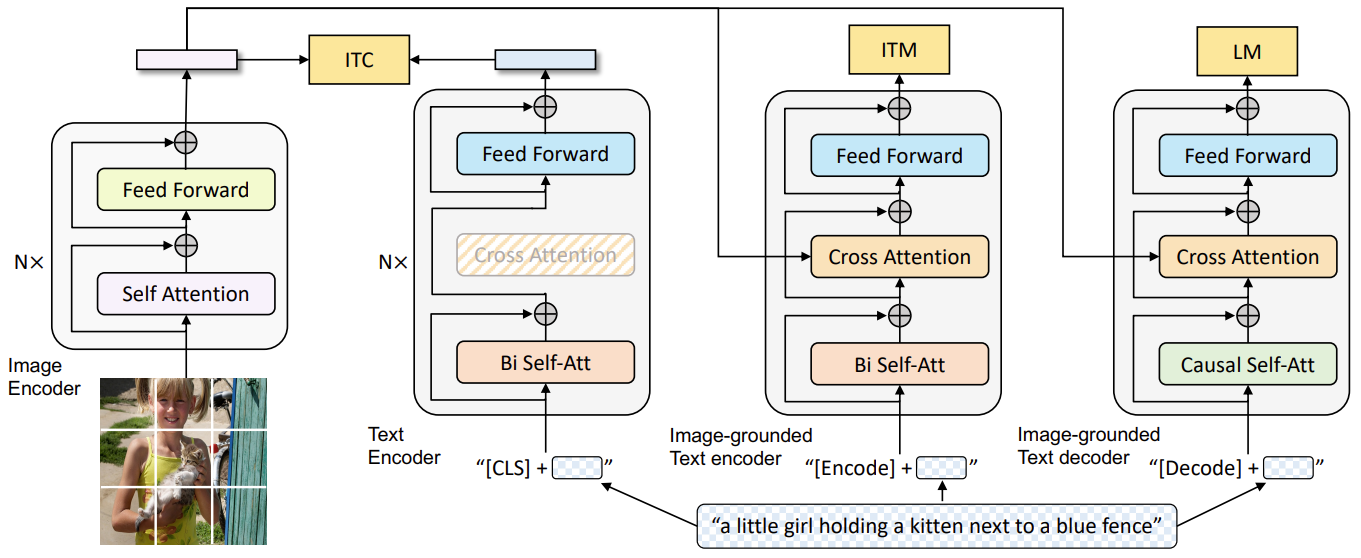
BLIP 采用 Visual Transformer 作为图像编码器,将输入的图像划分为 patch,然后将 patches 编码为一个 embedding 序列,并用一个额外的 [CLS] 标记来代表全局图像特征。与使用预训练的目标检测器进行视觉特征提取相比,使用 ViT 更便于计算,并且已经逐渐成为主流。
为了预训练一个具有理解和生成能力的统一模型,研究人员提出了多模态混合编码器-解码器(MED),能够用于多任务。
- 单模态编码器(Unimodal encoder),对图像和文本分别进行编码。文本编码器(text encoder)与 BERT 相同,在文本输入的开头附加一个 [CLS] 标记,以总结句子。
- 以图像为基础的文本编码器(Image-grounded text encoder),通过在自注意力(SA)层和前馈网络(FFN)之间为文本编码器的每个 Transformer 块插入一个额外的交叉注意力(CA)层来注入视觉信息。一个特定任务的 [Encode] 标记被附加到文本上,[Encode] 的输出 embedding 被用作图像-文本对的多模态表示。
- 以图像为基础的文本解码器(Image-grounded text decoder),用因果自注意力层(causal self-attention layer)替代编码器中的双向自注意力层。用 [Decode] 标记来表示一个序列的开始和结束。
显然,经由上述的三个模块,这个 MED 模型就拥有了同时匹配 generation-based tasks 和 understanding-based tasks 的能力。
五、Pre-training objectives
本文在 pre-training 的时候使用了三个 objectives,分别是两个 understanding-based objectives 和一个 generatin-based objectives。
- Image-Text Contrastive Loss (ITC):通过 contrastive learning 的思想,对齐视觉 transformer 和文本 transformer 的特征空间,目的是为了获得更加优质的 image 和 text 的 representation。
- Image-Text Matching Loss (ITM):旨在学习 image-text multimodal representation,来捕获视觉和语言的细粒度对齐。简单的来啊说就是图文匹配,最后输出一个二分类,positive or negative。
- Image-Text Matching Loss (ITM):三个 tasks 中的生成任务,为给定的图片生成对应的 description。广泛用于 VLP 的 MLM 损失相比,LM 使模型具有将视觉信息转换为连贯字幕的泛化能力。
六、CapFilt架构
由于大规模预训练的文本-图片对通常是从 web 上找出来的,该文本通常无法准确描述图像的视觉内容,从而使它们成为嘈杂的信号,对于学习视觉语言对齐不是最佳的。
由此,作者提出了一个 CapFilt 架构用来提高 image-text pair 的质量。
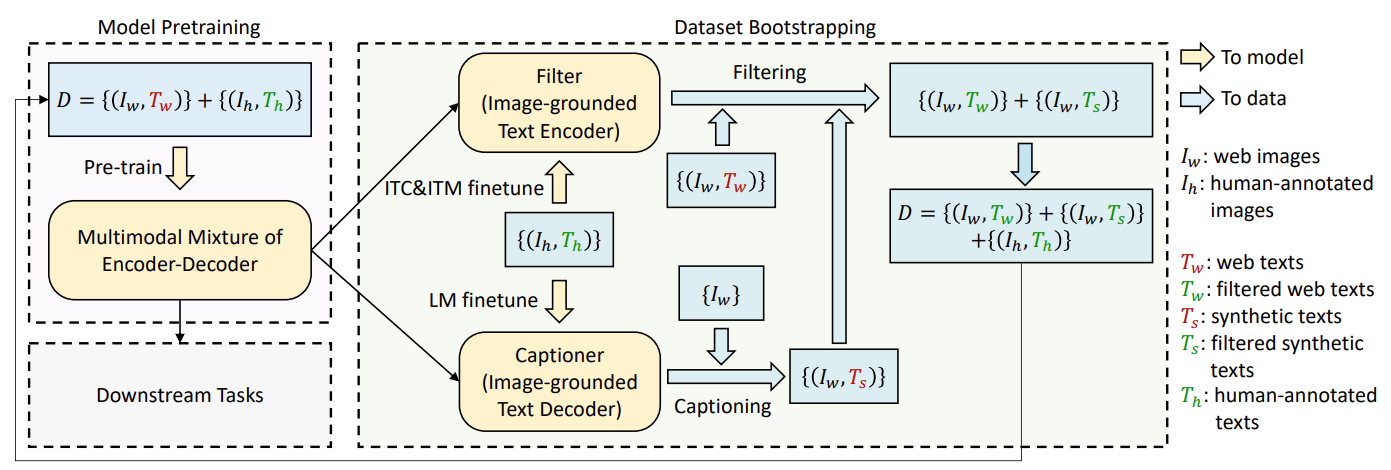
如上图所示,其中 I w I_w Iw和 T w T_w Tw代表 web image-text pair, ( I h , T h ) (I_h, T_h) (Ih,Th)代表高质量的手工标注的 image-text pair。
它引入了两个模块:一个基于 web 图像生成 caption 的 captioner ,以及一个用于去除 image-text pair 噪声的 filter。captioner 和 filter 都是从同一个预训练过的 MED 模型中初始化的,并在 COCO 数据集上单独微调。微调是一个轻量级的过程。
整个过程大概为:先进行 pre_train,之后利用 I h I_h Ih, T h T_h Th分别对 captioner 和 filter 进行 finetune,captioner 给定 web 图片生成对应的 caption,filter 利用ITM判断 web 图片-文字对和 web 图片-生成 caption 对是否 match,如果不 match,则过滤掉,最后将过滤后剩余的图片-文字对和 I h I_h Ih, T h T_h Th合在一起 pre_train 一个新 model。个人理解比较像一个新颖的 online self-knowledge distillation。
七、Experiment
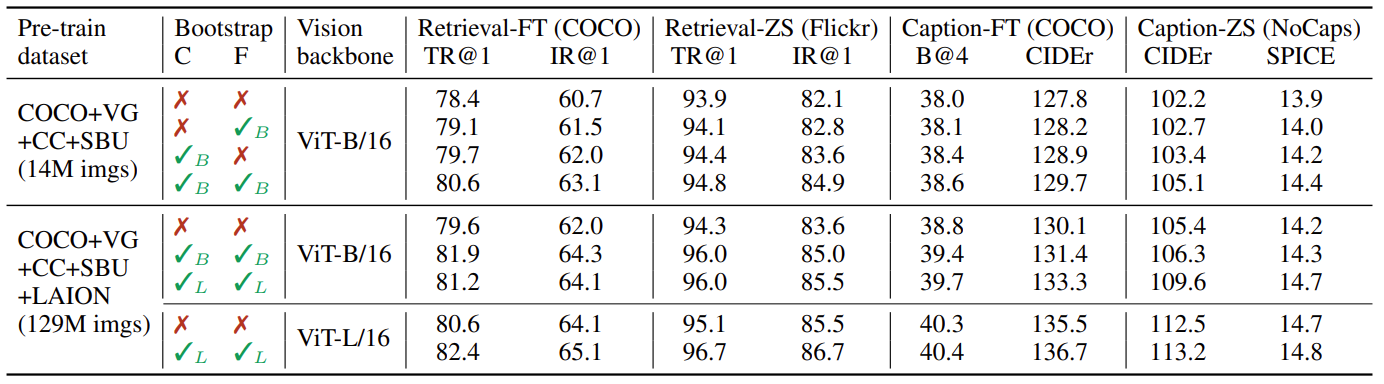
上图是提出的 captioner 和 filter 对最后结果的影响。

上图是 parameters sharing 策略对最后结果的影响。
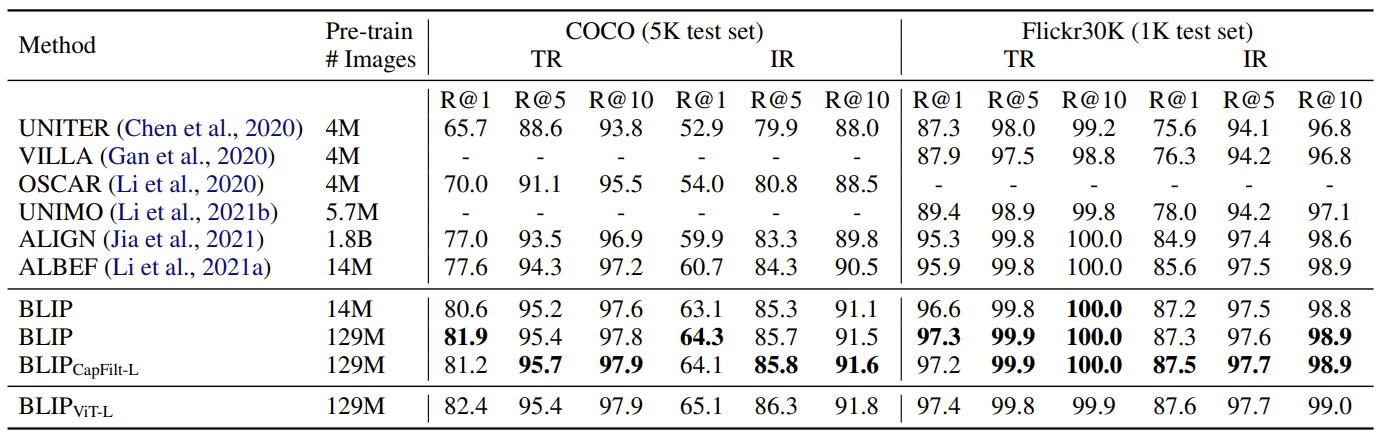
上图是 image-text retirval 中与其他 SOTA 任务的对比,可以看出有较大提升。
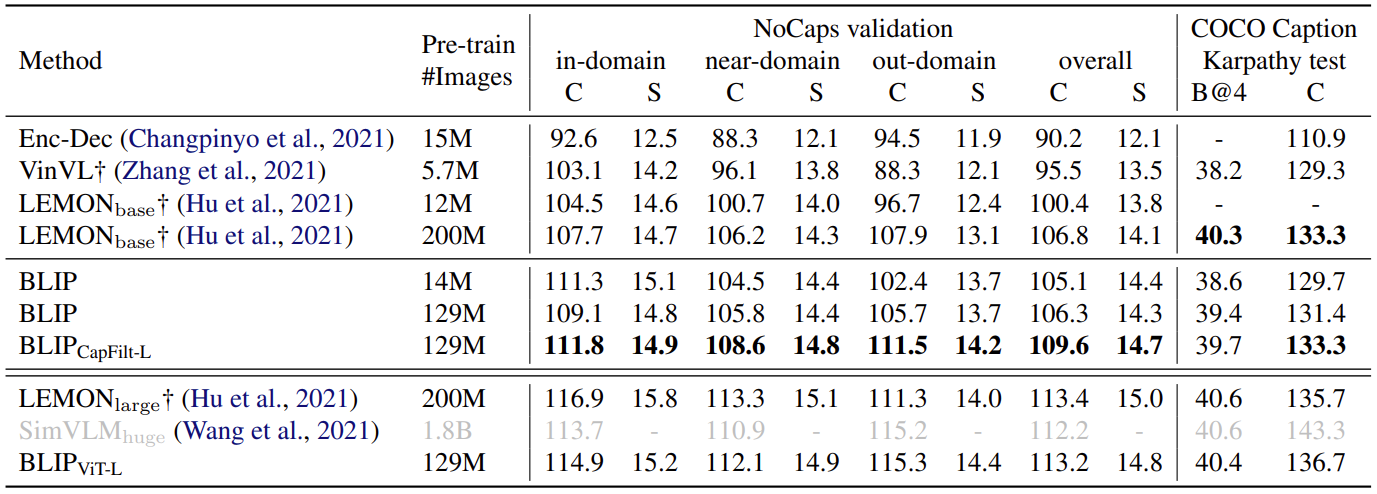
上图是与其他 image caption SOTA 方法的对比。
八、结论
作者提出的 BLIP 架构在大范围的 downstream 任务上达到了 SOTA 的效果,其中包括了 understanding-based tasks 和 generation-based tasks。同时模型使用了一种 dataset bootstrapping 的方法来解决 web 中收集的大量 noisy 数据的问题。
作者还提出有几个潜在的方法可能可以提高BLIP的性能:
- 进行多轮的 dataset bootstrapping
- 为每幅图片生成多个 caption,来扩大语料库
- 训练多个 captioner 和 filter,并进行 model ensemble
相关文章:
【计算机视觉 | 自然语言处理】BLIP:统一视觉—语言理解和生成任务(论文讲解)
文章目录 一、前言二、试玩效果三、研究背景四、模型结构五、Pre-training objectives六、CapFilt架构七、Experiment八、结论 一、前言 今天我们要介绍的论文是 BLIP,论文全名为 Bootstrapping Language-Image Pre-training for Unified Vision-Language Understa…...
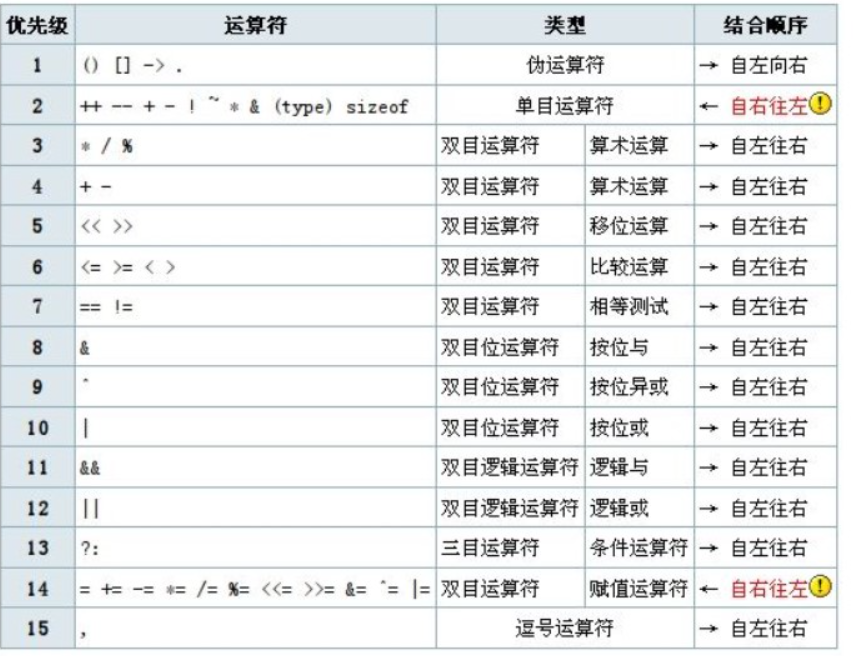
c++基础-运算符
目录 1关系运算符 2运算符优先级 3关系表达式的书写 代码实例: 下面是面试中可能遇到的问题: 1关系运算符 C中有6个关系运算符,用于比较两个值的大小关系,它们分别是: 运算符描述等于!不等于<小于>大于<…...

美术馆c++
题目: 杜老师非常喜欢玩一种叫做“美术馆”的数字游戏,蜗蜗看了之后决定也来试一试,他改编了这个游戏,规则如下: 有一个 n� 行 m� 列的方格,每一个格子中有一个数,数字…...

浅谈MySQL索引以及执行计划
MySQL索引及执行计划 🐪索引的作用🐫索引的分类(算法)🦙BTREE索引算法演变🦒Btree索引功能上的分类4.1 辅助索引4.2 聚集索引4.3 辅助索引和聚集索引的区别 🐘辅助索引分类🦏索引树高…...

在c++项目中使用rapidjson(有具体的步骤,十分详细) windows10系统
具体的步骤: 先下载rapidjson的依赖包 方式1:直接使用git去下载 地址:git clone https://github.com/miloyip/rapidjson.git 方式2:下载我上传的依赖包 将依赖包引入到项目中 1 将解压后的文件放在你c项目中 2 将rapidjson文…...

编译方式汇总:Makefile\configure\autogen.sh\configure.ac、Makefile.am文件
一、前言 文章目的:针对各种开源项目,由于部分项目文档写的不够详细,(或者是我太菜了),没有进行详细的介绍怎么编译该项目,导致花费过多时间在查找如何编译该项目上。因此该篇文章针对目前遇到的…...

explicit关键字
explicit关键字只能用来修饰构造函数。使用explicit可以禁止编译器自动调用拷贝初始化,还可以禁止编译器对拷贝函数的参数进行隐式转换。 那么什么是隐式转换呢? 类 命名 参数; //有参构造类 命名 命名对象; //拷贝构造&#x…...

[优雅的面试] 你了解python的对象吗
前情提要:小编面试,结果面试官着急去吃饭~又约了这次来面,不晓得又会问什么问题呢? 面试官大佬:小伙子来的挺准时的(赞赏的表情~),今天咱们接着聊哈,小伙子,你有对象了没?…...

【hello Linux】线程概念
目录 1. 线程概念的铺设 2. Linux线程概念 2.1 什么是线程 2.2 线程的优点 2.3 线程的缺点 2.4 线程异常 2.5 线程用途 3. Linux进程VS线程 4. Linux线程控制 4.1 POSIX线程库 4.2 创建线程 4.3 进程ID和线程ID 4.4 线程终止 4.5 线程等待 4.6 分离线程 Linux🌷 1…...

JavaWeb07(MVC应用01[家居商城]连接数据库)
目录 一.什么是MVC设计模式? 1.2 MVC设计模式有什么优点? 二.MVC运用(家居商城) 2.1 实现登录 2.2 绑定轮播【随机三个商品】 2.2.1 效果预览 index.jsp 2.3 绑定最新上架&热门家居 2.3.1 效果预览 2.3.2 代码实现 数据…...

如何使用电商API接口API接口如何应用
使用API接口 API(应用程序接口)是现代软件开发中必不可少的一部分,它通常允许软件与其他软件或服务进行交互。使用API可以大大提高软件的灵活性和可扩展性,并允许您轻松添加新的功能和服务,因此,API接口的…...
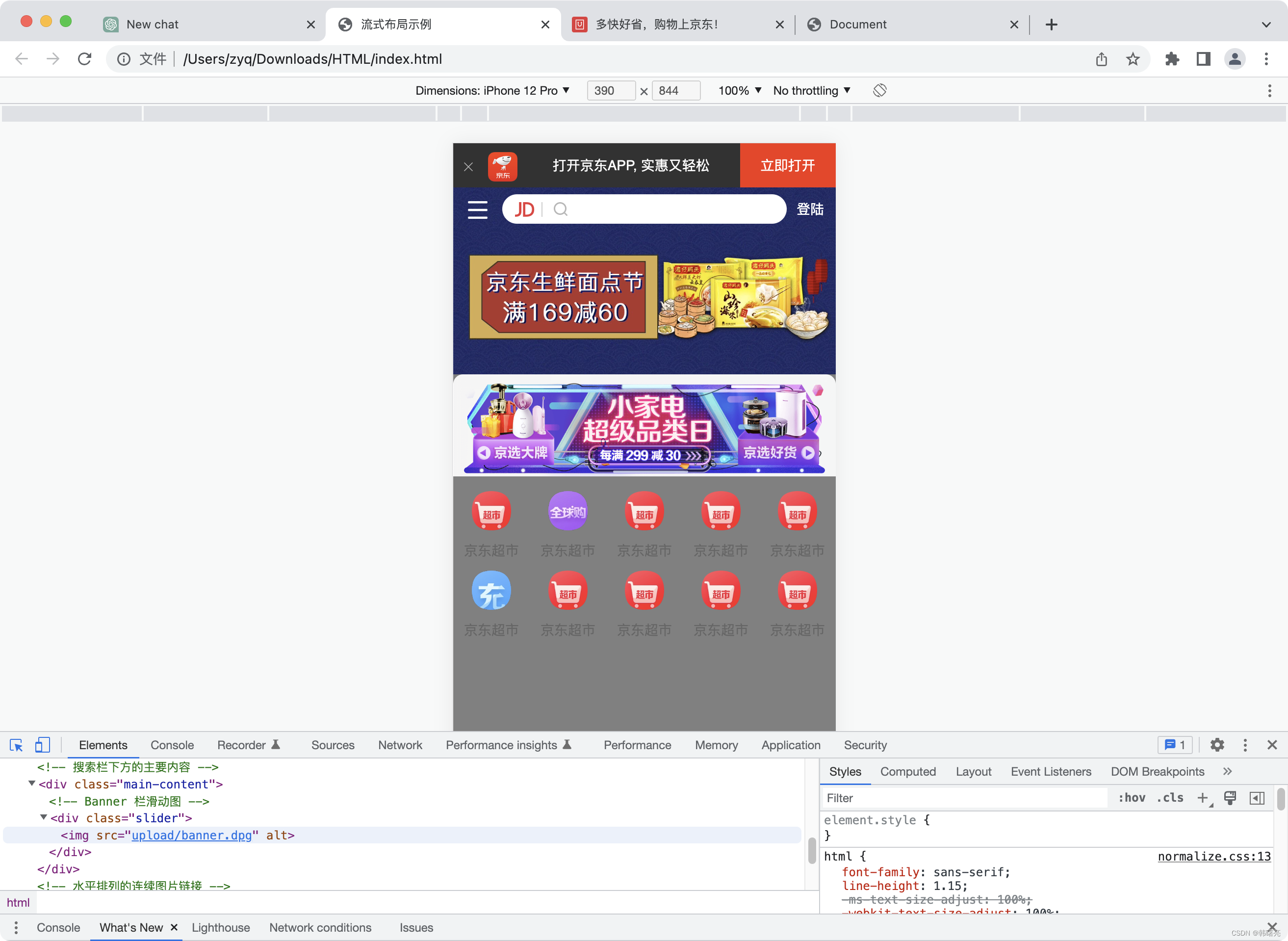
【移动端网页布局】流式布局案例 ⑥ ( 多排按钮导航栏 | 设置浮动及宽度 | 设置图片样式 | 设置文本 )
文章目录 一、多排按钮导航栏样式及核心要点1、实现效果2、总体布局设计3、设置浮动及宽度4、设置图片样式5、设置文本 二、完整代码实例1、HTML 标签结构2、CSS 样式3、展示效果 一、多排按钮导航栏样式及核心要点 1、实现效果 要实现下面的导航栏效果 ; 2、总体布局设计 该导…...

1. 先从云计算讲起
本章讲解知识点 什么是云计算? 为什么要用云计算? 物理服务器与云服务器对比 云计算服务类型 云计算部署类型 1. 什么是云计算? 云计算是一种通过计算机网络以服务的方式提供动态可伸缩的虚拟化资源的计算模式。按照服务层次分为IaaS、…...
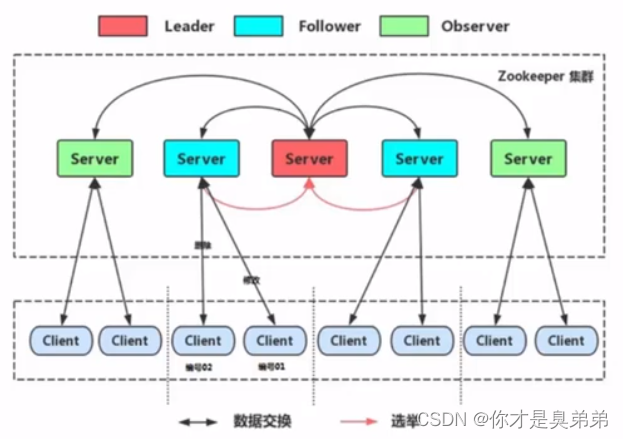
ZooKeeper安装与配置集群
简介: ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,它提供了一个分布式环境中的高可用性、高性能、有序访问的数据存储,可以让分布式应用程…...

浅谈Mysql的RR和RC隔离级别的主要区别
MySQL默认为RR级别 首先默认RR是因为mysql为了保证在主从同步过程中数据的安全的问题(涉及到binlog三种格式)。 就是说两个并发事务数AB,A先开启事物最后提交也是最后,事务B开启和提交都在A内部,由于隔离级别不同&…...

Build生成器模式
设计模式简述 设计模式的核心在于提供了相关问题的解决方案,使得人们可以更加简单方便地复用成功的设计和体系结构。 生成器模式(创建型设计模式) 意图:将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以…...
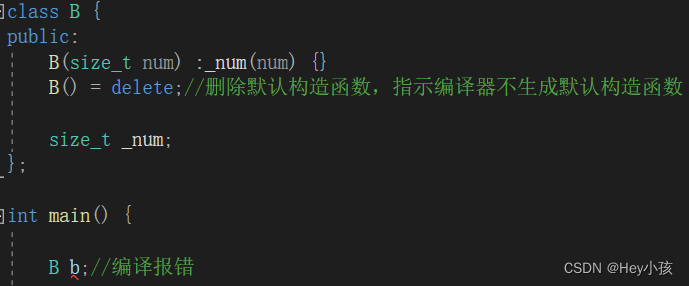
C++程序设计——常见C++11新特性
一、列表初始化 1.C98中{}的初始化问题 在C98中,允许使用花括号{}对数组元素进行统一的列表初始化值设定,比如: 但是对于一些自定义类型,就无法使用这样的方式进行初始化了,比如: 就无法通过编译ÿ…...

Rust main 函数返回值类型不能是 String
是的,Rust 的 main 函数返回值类型不能是 String。 Rust 的 main 函数只能返回以下几种类型之一: ():表示空类型,不返回任何值。i32:表示程序的退出码,通常非零值表示执行失败,0 表示执行成功…...

视频里的音乐怎么转换成mp3格式?
视频里的音乐怎么转换成mp3格式?视频里的音乐转换为mp3的原因有很多,主要是因为mp3格式是一种音频格式,文件大小较小,更易于存储和传输。相比之下,视频格式则是一种视频文件格式,虽然包含音频,但…...

CSS3 grid网格布局
文章目录 CSS3 grid网格布局概述grid属性说明使用grid-template-rows & grid-template-columns 定义行高和列宽grid-auto-flow 定义项目的排列顺序grid-auto-rows & grid-auto-columns 定义多余网格的行高和列宽row-gap & column-gap 设置行间距和列间距gap 简写形…...

为Dify扩展AI图表与文档生成能力:微服务架构实战指南
1. 项目概述:为Dify打造专属的AI图表与文档生成工具箱如果你正在使用Dify构建自己的AI应用,并且希望让AI不仅能生成文字,还能直接输出流程图、思维导图、PPT甚至试卷,那么这个项目就是为你准备的。brightwang/dify-tool-service是…...

Android本地AI智能家居框架:ZeroClaw架构设计与工程实践
1. 项目缘起与核心愿景几年前,我还在为一个智能家居项目焦头烂额,试图让家里的灯光、空调和音箱能听懂人话,而不是只会执行预设的“回家模式”或“睡眠模式”。当时市面上主流的方案,要么是依赖某个封闭的云平台,所有指…...

告别空转!用RT-Thread PM组件给你的IoT设备省电:从投票机制到外设管理的完整指南
告别空转!用RT-Thread PM组件给你的IoT设备省电:从投票机制到外设管理的完整指南 在电池供电的物联网设备开发中,功耗优化往往成为决定产品成败的关键因素。想象一下,一个部署在偏远地区的环境监测节点,如果因为功耗问…...

重温DIRE:走向通用人工智能生成的图像检测
1.摘要生成模型的快速发展提高了图像质量,并使图像合成广泛可用,引起了对内容可信度的关注。为了解决这个问题,我们提出了一种称为通用重建残差分析(UR2EA)的方法来检测合成图像。我们的研究表明,当通过预训练的扩散模型重建GAN和…...

PHP怎么处理Eloquent Attribute Harmonization属性协调_Laravel解决数据冲突【教程】
Eloquent 属性协调失败源于 $casts、访问器、序列化逻辑等机制作用域与执行顺序不一致;应优先用 $casts 处理类型转换,访问器仅用于动态计算,JSON 字段需显式标记 dirty 或拆分为关联模型。PHP 中 Eloquent 的 “Attribute Harmonization” 并…...

3步解锁网易云音乐NCM文件:ncmdump让你的音乐自由播放
3步解锁网易云音乐NCM文件:ncmdump让你的音乐自由播放 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的加密NCM文件无法在其他设备播放而烦恼吗?ncmdump作为一款专业的网易云音乐NCM文件…...

3大核心功能:智能自动化提升英雄联盟游戏体验的终极指南
3大核心功能:智能自动化提升英雄联盟游戏体验的终极指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款基于英…...

Betaflight飞行控制固件:5分钟快速上手指南与完整配置教程
Betaflight飞行控制固件:5分钟快速上手指南与完整配置教程 【免费下载链接】betaflight Open Source Flight Controller Firmware 项目地址: https://gitcode.com/gh_mirrors/be/betaflight 还在为穿越机飞行不稳定而烦恼吗?🤔 想体验…...

CANN/asc-devkit bfloat16转half API
__bfloat162half_ru 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://git…...

深度解析:3种高效的Windows依赖检测完整方案
深度解析:3种高效的Windows依赖检测完整方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist VisualCppRedist AIO项目是一个专业的Microsoft Visual …...