Protobuf: 高效数据传输的秘密武器
当涉及到网络通信和数据存储时,数据序列化一直都是一个重要的话题;特别是现在很多公司都在推行微服务,数据序列化更是重中之重,通常会选择使用 JSON 作为数据交换格式,且 JSON 已经成为业界的主流。但是 Google 这么大的公司使用的却是一种被称为 Protobuf 的数据交换格式,它是有什么优势吗?这篇文章介绍 Protobuf 的相关知识。

GitHub:https://github.com/protocolbuffers/protobuf
官方文档:https://protobuf.dev/overview/
Protobuf 介绍
Protobuf(Protocol Buffers)是由 Google 开发的一种轻量级、高效的数据交换格式,它被用于结构化数据的序列化、反序列化和传输。相比于 XML 和 JSON 等文本格式,Protobuf 具有更小的数据体积、更快的解析速度和更强的可扩展性。
Protobuf 的核心思想是使用协议(Protocol)来定义数据的结构和编码方式。使用 Protobuf,可以先定义数据的结构和各字段的类型、字段等信息,然后使用Protobuf提供的编译器生成对应的代码,用于序列化和反序列化数据。由于 Protobuf 是基于二进制编码的,因此可以在数据传输和存储中实现更高效的数据交换,同时也可以跨语言使用。

相比于 XML 和 JSON,Protobuf 有以下几个优势:
-
更小的数据量:Protobuf 的二进制编码通常比 XML 和 JSON 小 3-10 倍,因此在网络传输和存储数据时可以节省带宽和存储空间。
-
更快的序列化和反序列化速度:由于 Protobuf 使用二进制格式,所以序列化和反序列化速度比 XML 和 JSON 快得多。
-
跨语言:Protobuf 支持多种编程语言,可以使用不同的编程语言来编写客户端和服务端。这种跨语言的特性使得 Protobuf 受到很多开发者的欢迎(JSON 也是如此)。
-
易于维护可扩展:Protobuf 使用 .proto 文件定义数据模型和数据格式,这种文件比 XML 和 JSON 更容易阅读和维护,且可以在不破坏原有协议的基础上,轻松添加或删除字段,实现版本升级和兼容性。
编写 Protobuf
使用 Protobuf 的语言定义文件(.proto)可以定义要传输的信息的数据结构,可以包括各个字段的名称、类型等信息。同时也可以相互嵌套组合,构造出更加复杂的消息结构。
比如想要构造一个地址簿 AddressBook 信息结构。一个 AddressBook 可以包含多个人员 Person 信息,每个 Person 信息可以包含 id、name、email 信息,同时一个 Person 也可以包含多个电话号码信息 PhoneNumber,每个电话号码信息需要指定号码种类,如手机、家庭电话、工作电话等。
如果使用 Protobuf 编写定义文件如下:
// 文件:addressbook.proto
syntax = "proto3";
// 指定 protobuf 包名,防止有相同类名的 message 定义
package com.wdbyte.protobuf;
// 是否生成多个文件
option java_multiple_files = true;
// 生成的文件存放在哪个包下
option java_package = "com.wdbyte.tool.protos";
// 生成的类名,如果没有指定,会根据文件名自动转驼峰来命名
option java_outer_classname = "AddressBookProtos";message Person {// =1,=2 作为序列化后的二进制编码中的字段的唯一标签,也因此,1-15 比 16 会少一个字节,所以尽量使用 1-15 来指定常用字段。optional int32 id = 1;optional string name = 2;optional string email = 3;enum PhoneType {MOBILE = 0;HOME = 1;WORK = 2;}message PhoneNumber {optional string number = 1;optional PhoneType type = 2;}repeated PhoneNumber phones = 4;
}message AddressBook {repeated Person people = 1;
}
Protobuf 文件中的语法解释。
头部全局定义
syntax = "proto3";指定 Protobuf 版本为版本3(最新版本)package com.wdbyte.protobuf;指定 Protobuf 包名,防止有相同类名的message定义,这个包名是生成的类中所用到的一些信息的前缀,并非类所在包。option java_multiple_files = true;是否生成多个文件。若false,则只会生成一个类,其他类以内部类形式提供。option java_package =生成的类所在包。option java_outer_classname生成的类名,若无,自动使用文件名进行驼峰转换来为类命名。
消息结构具体定义
message Person 定一个了一个 Person 类。
Person 类中的字段被 optional 修饰,被 optional 修饰说明字段可以不赋值。
- 修饰符
optional表示可选字段,可以不赋值。 - 修饰符
repeated表示数据重复多个,如数组,如 List。 - 修饰符
required表示必要字段,必须给值,否则会报错RuntimeException,但是在 Protobuf 版本 3 中被移除。即使在版本 2 中也应该慎用,因为一旦定义,很难更改。
字段类型定义
修饰符后面紧跟的是字段类型,如 int32 、string。常用的类型如下:
-
int32、int64、uint32、uint64:整数类型,包括有符号和无符号类型。 -
float、double:浮点数类型。 -
bool:布尔类型,只有两个值,true 和 false。 -
string:字符串类型。 -
bytes:二进制数据类型。 -
enum:枚举类型,枚举值可以是整数或字符串。 -
message:消息类型,可以嵌套其他消息类型,类似于结构体。
字段后面的 =1,=2 是作为序列化后的二进制编码中的字段的对应标签,因为 Protobuf 消息在序列化后是不包含字段信息的,只有对应的字段序号,所以节省了空间。也因此,1-15 比 16 会少一个字节,所以尽量使用 1-15 来指定常用字段。且一旦定义,不要随意更改,否则可能会对不上序列化信息。
编译 Protobuf
使用 Protobuf 提供的编译器,可以将 .proto 文件编译成各种语言的代码文件(如 Java、C++、Python 等)。

下载编译器:https://github.com/protocolbuffers/protobuf/releases/latest
安装完成后可以使用 protoc 命令编译 proto 文件,如编译示例中的 addressbook.proto.
protoc --java_out=./java ./resources/addressbook.proto
# --java_out 指定输出 java 格式文件,输出到 ./java 目录
# ./resources/addressbook.proto 为 proto 文件位置
生成后可以看到生产的类文件。
./
├── java
│ └── com
│ └── wdbyte
│ └── tool
│ ├── protos
│ │ ├── AddressBook.java
│ │ ├── AddressBookOrBuilder.java
│ │ ├── AddressBookProtos.java
│ │ ├── Person.java
│ │ ├── PersonOrBuilder.java
└── resources├── addressbook.proto
使用 Protobuf
使用 Java 语言操作 Protobuf,首先需要引入 Protobuf 依赖。
Maven 依赖:
<dependency><groupId>com.google.protobuf</groupId><artifactId>protobuf-java</artifactId><version>3.22.3</version>
</dependency>
构造消息对象
// 直接构建
PhoneNumber phoneNumber1 = PhoneNumber.newBuilder().setNumber("18388888888").setType(PhoneType.HOME).build();
Person person1 = Person.newBuilder().setId(1).setName("www.wdbyte.com").setEmail("xxx@wdbyte.com").addPhones(phoneNumber1).build();
AddressBook addressBook1 = AddressBook.newBuilder().addPeople(person1).build();
System.out.println(addressBook1);
System.out.println("------------------");// 链式构建
AddressBook addressBook2 = AddressBook.newBuilder().addPeople(Person.newBuilder().setId(2).setName("www.wdbyte.com").setEmail("yyy@126.com").addPhones(PhoneNumber.newBuilder().setNumber("18388888888").setType(PhoneType.HOME))).build();
System.out.println(addressBook2);
输出:
people {id: 1name: "www.wdbyte.com"email: "xxx@wdbyte.com"phones {number: "18388888888"type: HOME}
}------------------
people {id: 2name: "www.wdbyte.com"email: "yyy@126.com"phones {number: "18388888888"type: HOME}
}
序列化、反序列化
序列化:将内存中的数据对象序列化为二进制数据,可以用于网络传输或存储等场景。
反序列化:将二进制数据反序列化成内存中的数据对象,可以用于数据处理和业务逻辑。
下面演示使用 Protobuf 进行字符数组和文件的序列化及反序列化过程。
package com.wdbyte.tool.protos;import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;/*** * @author www.wdbyte.com*/
public class ProtobufTest2 {public static void main(String[] args) throws IOException {PhoneNumber phoneNumber1 = PhoneNumber.newBuilder().setNumber("18388888888").setType(PhoneType.HOME).build();Person person1 = Person.newBuilder().setId(1).setName("www.wdbyte.com").setEmail("xxx@wdbyte.com").addPhones(phoneNumber1).build();AddressBook addressBook1 = AddressBook.newBuilder().addPeople(person1).build();// 序列化成字节数组byte[] byteArray = addressBook1.toByteArray();// 反序列化 - 字节数组转对象AddressBook addressBook2 = AddressBook.parseFrom(byteArray);System.out.println("字节数组反序列化:");System.out.println(addressBook2);// 序列化到文件addressBook1.writeTo(new FileOutputStream("AddressBook1.txt"));// 读取文件反序列化AddressBook addressBook3 = AddressBook.parseFrom(new FileInputStream("AddressBook1.txt"));System.out.println("文件读取反序列化:");System.out.println(addressBook3);}
}
输出:
字节数组反序列化:
people {id: 1name: "www.wdbyte.com"email: "xxx@wdbyte.com"phones {number: "18388888888"type: HOME}
}文件读取反序列化:
people {id: 1name: "www.wdbyte.com"email: "xxx@wdbyte.com"phones {number: "18388888888"type: HOME}
}
Protobuf 为什么高效
在分析 Protobuf 高效之前,我们先确认一下 Protobuf 是否真的高效,下面将 Protobuf 与 JSON 进行对比,分别对比序列化和反序列化速度以及序列化后的存储占用大小。
测试工具:JMH,FastJSON,
测试对象:Protobuf 的 addressbook.proto,JSON 的普通 Java 类。
Maven 依赖:
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>2.0.7</version>
</dependency>
<dependency><groupId>org.openjdk.jmh</groupId><artifactId>jmh-core</artifactId><version>1.33</version>
</dependency>
<dependency><groupId>org.openjdk.jmh</groupId><artifactId>jmh-generator-annprocess</artifactId><version>1.33</version><scope>provided</scope>
</dependency>
先编写与addressbook.proto 结构相同的 Java 类 AddressBookJava.java.
public class AddressBookJava {List<PersonJava> personJavaList;public static class PersonJava {private int id;private String name;private String email;private PhoneNumberJava phones;// get...set...}public static class PhoneNumberJava {private String number;private PhoneTypeJava phoneTypeJava;// get....set....}public enum PhoneTypeJava {MOBILE, HOME, WORK;}public List<PersonJava> getPersonJavaList() {return personJavaList;}public void setPersonJavaList(List<PersonJava> personJavaList) {this.personJavaList = personJavaList;}
}
序列化大小对比
分别在地址簿中添加 1000 个人员信息,输出序列化后的数组大小。
package com.wdbyte.tool.protos;import java.io.IOException;
import java.util.ArrayList;import com.alibaba.fastjson.JSON;import com.wdbyte.tool.protos.AddressBook.Builder;
import com.wdbyte.tool.protos.AddressBookJava.PersonJava;
import com.wdbyte.tool.protos.AddressBookJava.PhoneNumberJava;
import com.wdbyte.tool.protos.AddressBookJava.PhoneTypeJava;
import com.wdbyte.tool.protos.Person.PhoneNumber;
import com.wdbyte.tool.protos.Person.PhoneType;/*** @author https://www.wdbyte.com*/
public class ProtobufTest3 {public static void main(String[] args) throws IOException {AddressBookJava addressBookJava = createAddressBookJava(1000);String jsonString = JSON.toJSONString(addressBookJava);System.out.println("json string size:" + jsonString.length());AddressBook addressBook = createAddressBook(1000);byte[] addressBookByteArray = addressBook.toByteArray();System.out.println("protobuf byte array size:" + addressBookByteArray.length);}public static AddressBook createAddressBook(int personCount) {Builder builder = AddressBook.newBuilder();for (int i = 0; i < personCount; i++) {builder.addPeople(Person.newBuilder().setId(i).setName("www.wdbyte.com").setEmail("xxx@126.com").addPhones(PhoneNumber.newBuilder().setNumber("18333333333").setType(PhoneType.HOME)));}return builder.build();}public static AddressBookJava createAddressBookJava(int personCount) {AddressBookJava addressBookJava = new AddressBookJava();addressBookJava.setPersonJavaList(new ArrayList<>());for (int i = 0; i < personCount; i++) {PersonJava personJava = new PersonJava();personJava.setId(i);personJava.setName("www.wdbyte.com");personJava.setEmail("xxx@126.com");PhoneNumberJava numberJava = new PhoneNumberJava();numberJava.setNumber("18333333333");numberJava.setPhoneTypeJava(PhoneTypeJava.HOME);personJava.setPhones(numberJava);addressBookJava.getPersonJavaList().add(personJava);}return addressBookJava;}
}
输出:
json string size:108910
protobuf byte array size:50872
可见测试中 Protobuf 的序列化结果比 JSON 小了将近一倍左右。
序列化速度对比
使用 JMH 进行性能测试,分别测试 JSON 的序列化和反序列以及 Protobuf 的序列化和反序列化性能情况。每次测试前进行 3 次预热,每次 3 秒。接着进行 5 次测试,每次 3 秒,收集测试情况。
package com.wdbyte.tool.protos;import java.util.ArrayList;
import java.util.concurrent.TimeUnit;import com.alibaba.fastjson.JSON;import com.google.protobuf.InvalidProtocolBufferException;
import com.wdbyte.tool.protos.AddressBook.Builder;
import com.wdbyte.tool.protos.AddressBookJava.PersonJava;
import com.wdbyte.tool.protos.AddressBookJava.PhoneNumberJava;
import com.wdbyte.tool.protos.AddressBookJava.PhoneTypeJava;
import com.wdbyte.tool.protos.Person.PhoneNumber;
import com.wdbyte.tool.protos.Person.PhoneType;
import org.openjdk.jmh.annotations.Benchmark;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.Fork;
import org.openjdk.jmh.annotations.Measurement;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.Setup;
import org.openjdk.jmh.annotations.State;
import org.openjdk.jmh.annotations.Warmup;/*** @author https://www.wdbyte.com*/
@State(Scope.Thread)
@Fork(2)
@Warmup(iterations = 3, time = 3)
@Measurement(iterations = 5, time = 3)
@BenchmarkMode(Mode.Throughput) // Throughput:吞吐量,SampleTime:采样时间
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public class ProtobufTest4 {private AddressBookJava addressBookJava;private AddressBook addressBook;@Setuppublic void init() {addressBookJava = createAddressBookJava(1000);addressBook = createAddressBook(1000);}@Benchmarkpublic AddressBookJava testJSON() {// 转 JSONString jsonString = JSON.toJSONString(addressBookJava);// JSON 转对象return JSON.parseObject(jsonString, AddressBookJava.class);}@Benchmarkpublic AddressBook testProtobuf() throws InvalidProtocolBufferException {// 转 JSONbyte[] addressBookByteArray = addressBook.toByteArray();// JSON 转对象return AddressBook.parseFrom(addressBookByteArray);}public static AddressBook createAddressBook(int personCount) {Builder builder = AddressBook.newBuilder();for (int i = 0; i < personCount; i++) {builder.addPeople(Person.newBuilder().setId(i).setName("www.wdbyte.com").setEmail("xxx@126.com").addPhones(PhoneNumber.newBuilder().setNumber("18333333333").setType(PhoneType.HOME)));}return builder.build();}public static AddressBookJava createAddressBookJava(int personCount) {AddressBookJava addressBookJava = new AddressBookJava();addressBookJava.setPersonJavaList(new ArrayList<>());for (int i = 0; i < personCount; i++) {PersonJava personJava = new PersonJava();personJava.setId(i);personJava.setName("www.wdbyte.com");personJava.setEmail("xxx@126.com");PhoneNumberJava numberJava = new PhoneNumberJava();numberJava.setNumber("18333333333");numberJava.setPhoneTypeJava(PhoneTypeJava.HOME);personJava.setPhones(numberJava);addressBookJava.getPersonJavaList().add(personJava);}return addressBookJava;}
}
JMH 吞吐量测试结果(Score 值越大吞吐量越高,性能越好):
Benchmark Mode Cnt Score Error Units
ProtobufTest3.testJSON thrpt 10 1.877 ± 0.287 ops/ms
ProtobufTest3.testProtobuf thrpt 10 2.813 ± 0.446 ops/ms
JMH 采样时间测试结果(Score 越小,采样时间越小,性能越好):
Benchmark Mode Cnt Score Error Units
ProtobufTest3.testJSON sample 53028 0.565 ± 0.005 ms/op
ProtobufTest3.testProtobuf sample 90413 0.332 ± 0.001 ms/op
从测试结果看,不管是吞吐量测试,还是采样时间测试,Protobuf 都优于 JSON。
为什么高效?
Protobuf 是如何实现这种高效紧凑的数据编码和解码的呢?
首先,Protobuf 使用二进制编码,会提高性能;其次 Protobuf 在将数据转换成二进制时,会对字段和类型重新编码,减少空间占用。它采用 TLV 格式来存储编码后的数据。TLV 也是就是 Tag-Length-Value ,是一种常见的编码方式,因为数据其实都是键值对形式,所以在 TAG 中会存储对应的字段和类型信息,Length 存储内容的长度,Value 存储具体的内容。

还记得上面定义结构体时每个字段都对应一个数字吗?如 =1,=2,=3.
message Person {optional int32 id = 1;optional string name = 2;optional string email = 3;
}
在序列化成二进制时候就是通过这个数字来标记对应的字段的,二进制中只存储这个数字,反序列化时通过这个数字找对应的字段。这也是上面为什么说尽量使用 1-15 范围内的数字,因为一旦超过 15,就需要多一个 bit 位来存储。
那么类型信息呢?比如 int32 怎么标记,因为类型个数有限,所以 Protobuf 规定了每个类型对应的二进制编码,比如 int32 对应二进制 000,string 对应二进制 010,这样就可以只用三个比特位存储类型信息。
这里只是举例描述大概思想,具体还有一些变化。
详情可以参考官方文档:https://protobuf.dev/programming-guides/encoding/
其次,Protobuf 还会采用一种变长编码的方式来存储数据。这种编码方式能够保证数据占用的空间最小化,从而减少了数据传输和存储的开销。具体来说,Protobuf 会将整数和浮点数等类型变换成一个或多个字节的形式,其中每个字节都包含了一部分数据信息和一部分标识符信息。这种编码方式可以在数据值比较小的情况下,只使用一个字节来存储数据,以此来提高编码效率。
最后,Protobuf 还可以通过采用压缩算法来减少数据传输的大小。比如 GZIP 算法能够将原始数据压缩成更小的二进制格式,从而在网络传输中能够节省带宽和传输时间。Protobuf 还提供了一些可选的压缩算法,如 zlib 和 snappy,这些算法在不同的场景下能够适应不同的压缩需求。
综上所述,Protobuf 在实现高效编码和解码的过程中,采用了多种优化方式,从而在实际应用中能够有效地提升数据传输和处理的效率。
总结
ProtoBuf 是一种轻量、高效的数据交换格式,它具有以下优点:
- 语言中立,可以支持多种编程语言;
- 数据结构清晰,易于维护和扩展;
- 二进制编码,数据体积小,传输效率高;
- 自动生成代码,开发效率高。
但是,ProtoBuf 也存在以下缺点:
- 学习成本较高,需要掌握其语法规则和使用方法;
- 需要先定义数据结构,然后才能对数据进行序列化和反序列化,增加了一定的开发成本;
- 由于二进制编码,可读性较差,这点不如 JSON 可以直接阅读。
总体来说,Protobuf 适合用于数据传输和存储等场景,能够提高数据传输效率和减少数据体积。但对于需要人类可读的数据,或需要实时修改的数据,或者对数据的传输效率和体积没那么在意的场景,选择更加通用的 JSON 未尝不是一个好的选择。
参考:https://protobuf.dev/overview/
一如既往,文章代码都存放在 Github.com/niumoo/javaNotes.
文章持续更新,可以微信搜一搜「 程序猿阿朗 」或访问「程序猿阿朗博客 」第一时间阅读。本文 Github.com/niumoo/JavaNotes 已经收录,有很多系列文章,欢迎Star。
相关文章:
Protobuf: 高效数据传输的秘密武器
当涉及到网络通信和数据存储时,数据序列化一直都是一个重要的话题;特别是现在很多公司都在推行微服务,数据序列化更是重中之重,通常会选择使用 JSON 作为数据交换格式,且 JSON 已经成为业界的主流。但是 Google 这么大…...
第五十四章 Unity 移动平台输入(下)
本章节我们介绍一个模拟器插件。这种插件比较多,比如EasyTouch,Lean Touch,Joystick Pack等等。EasyTouch是一个使用非常广泛的插件,支持点击,拖拽,遥感等很多常用功能。不过遗憾的是,该插件已经…...

KD305Y带吸收比极化指数兆欧表
一、概述 KD305Y绝缘电阻测试仪对众多的电力设备如:电缆、电机、发电机、变压器、互感器、高压开关、避雷器等要求做一系列的绝缘性能试验,首先是要做绝缘电阻测试。近年来随着电力事业的飞速发展,大容量设备的使用不断增加,用普通的兆欧表无…...
磁盘空间不足怎么办?释放磁盘空间的4种方法
虽然现在硬盘的空间越来越大,但是在这个数据爆炸的时代中,总是会觉得存储空间不够用,一不注意磁盘就满了,那么除了清空回收站、卸载某些程序外,还能怎么释放磁盘空间呢? 方案一:禁用休眠 休眠是…...
ChatGPT调教指北,技巧就是效率!
技巧就是效率 很多人都知道ChatGPT很火很强,几乎无所不能,但跨越了重重门槛之才有机会使用的时候却有些迷茫,一时间不知道如何使用它。如果你就是把他当作一个普通的智能助手来看待,那与小爱同学有什么区别?甚至还差劲…...
——init进程对子进程的监控)
Android启动流程(五)——init进程对子进程的监控
init进程会读取rc文件,然后孵化很多其他系统服务进程,为防止子进程死亡后称为僵尸进程,init需要监测子进程是否死亡,如果死亡,则清除子进程资源,并重新拉起进程。 system/core/init/init.cpp InstallSigna…...
Python每日一练:蚂蚁家族(详解集合法)
文章目录 前言一、题目二、代码分析总结 前言 这题挺有意思,感觉评简单难度有点低了,如果正经用无向图来做,代码还是有点长的。首先得建立节点,估计除第一个和最后一个每个节点都是一条线连进,一条线连出的。就可以这…...

图神经网络:在KarateClub数据集上动手实现图神经网络
文章说明: 1)参考资料:PYG官方文档。超链。 2)博主水平不高,如有错误还望批评指正。 3)我在百度网盘上传了这篇文章的jupyter notebook。超链。提取码8888。 文章目录 文献阅读:代码实操: 文献阅读: 参考文…...

ArduPilot之开源代码调试技巧
ArduPilot之开源代码调试技巧 1. 源由2. ArduPilot Code Debugging Part13. ArduPilot Code Debugging Part24. 持续更新中。。。5. 参考资料 1. 源由 对于如何调试和验证ArduPilot,对于新手来说,有的时候反而是入门的一个门槛。 其实这个并不难&#…...

Linux网络基础-2
在之前的网络基础博客中,我们对网络的基本概念进行了一个简单的介绍,那么接下来的网络内容中,我们将对网络通信中的典型协议进行详细解释。 我们根据网络协议中的分层来对典型协议进行注意介绍,不过对于物理层的传输我们不做考究…...

软件测试报告模板
目录 2 1 概述... 3 1.1 测试目的... 3 1.2 测试策略... 3 1.3 测试方法... 3 1.4 计划验收标准... 3 1.5 测试用例... 4...
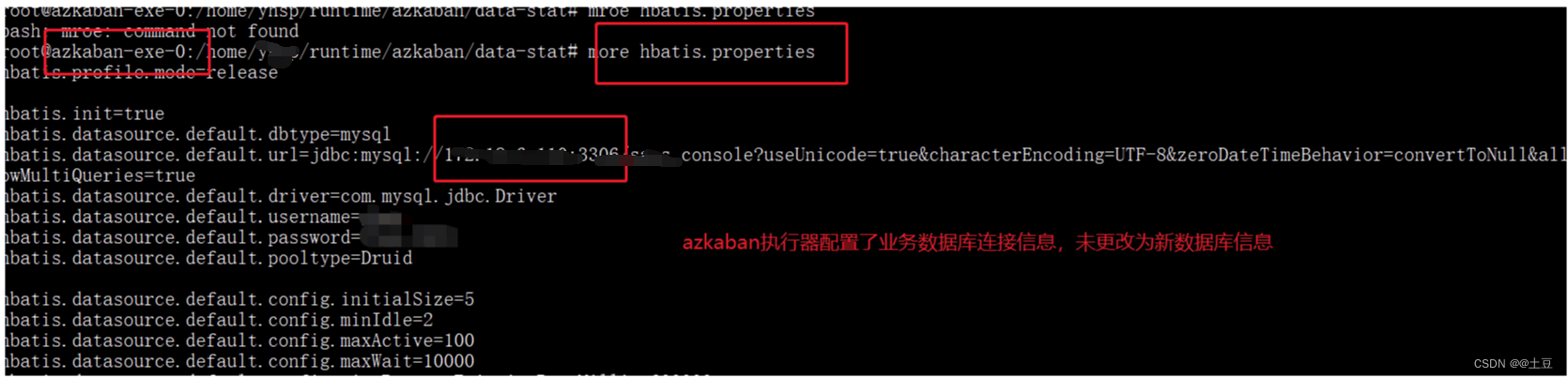
记一次azkaban调度异常处理
一、背景 预发布环境使用的数据库性能比较低,根据业务测试的需求,需要将数据库更换成 稳定高性能的数据库。更换业务数据库后azkaban定时任务失败 二、数据库服务信息 说明:该部分使用代号来代替,非真实信息 该数据库存储了azka…...

开发一个vue自定义指令的npm库-系列三:使用rollup打包npm库并发布
配置 rollup 使用rollup将 TypeScript 代码转换为 JavaScript,然后进行压缩和输出到目标文件。 项目根目录新建rollup.config.js import typescript from "rollup/plugin-typescript"; import terser from "rollup/plugin-terser"; import de…...
C嘎嘎的运算符重载基础教程以及遵守规则【文末赠书三本】
博主名字:阿玥的小东东 大家一起共进步! 目录 基础概念 优先级和结合性 不会改变用法 在全局范围内重载运算符 小结 本期送书:盼了一年的Core Java最新版卷Ⅱ,终于上市了 基础概念 运算符重载是通过函数重载实现的…...
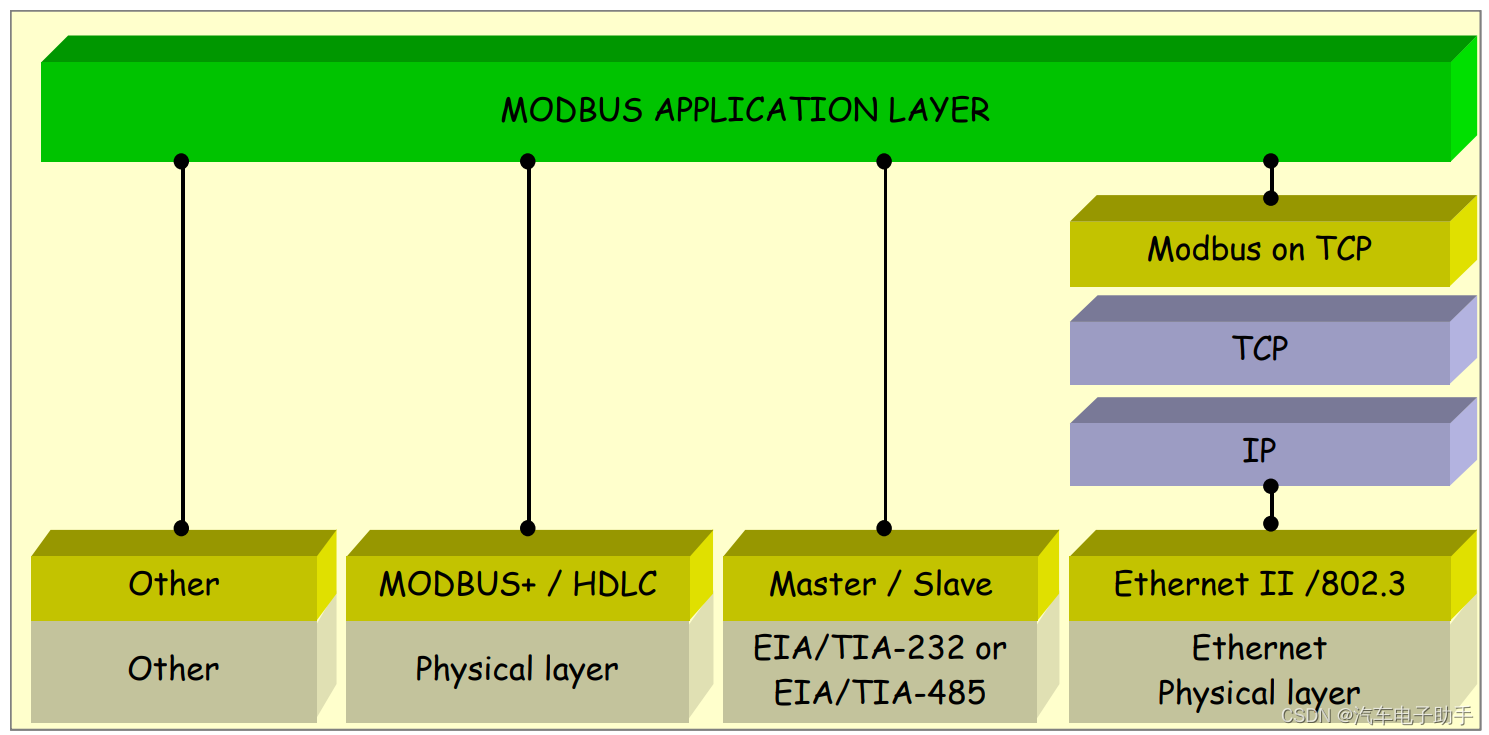
【MCAL_UART】-1.2-图文详解RS232,RS485和MODBUS的关系
目录 1 UART,RS232和RS485通信拓扑 2 什么是RS232 2.1 RS232标准的演变 2.2 RS232标准讲了哪些 2.2.1 RS232通信的电平 2.2.2 RS232通信的带宽 2.2.3 RS232通信距离 2.2.4 RS232通信的机械接口 3 什么是RS485 3.1 RS485标准的演变 3.2 RS485标准讲了哪些…...
——单例模式)
设计模式详解(二)——单例模式
单例模式简介 单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一。这种类型的设计模式属于创建型模式,创建型模式是一类最常用的设计模式,在软件开发中应用非常广泛,它提供了一种创建对象的最佳方式。 单例模…...
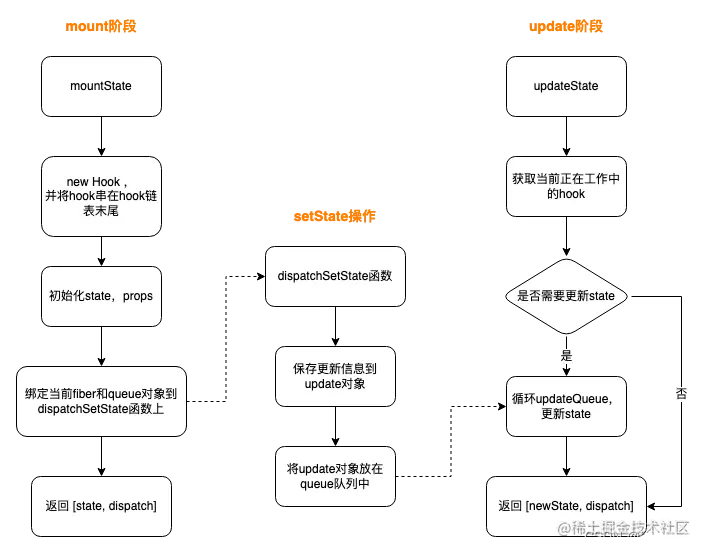
为什么hooks不能在循环、条件或嵌套函数中调用
hooks不能在循环、条件或嵌套函数中调用 为什么? 带着疑问一起去看源码吧~ function App() {const [num, setNum] useState(0);const [count, setCount] useState(0);const handleClick () > {setNum(num > num 1)setCount(2)}return <p …...

互联网赚钱项目有哪些?目前最火的互联网项目
互联网是一个神奇的行业,大门不出二门不迈,一根网线一台电脑,甚至一台手机就可以赚钱。它给我们创造了前所未有的商业机会,让成千上万有梦想,敢想敢干的人通过互联网获得了巨大的成功!正因为如此࿰…...

队列、栈专题
队列、栈专题 LeetCode 20. 有效的括号解题思路代码实现 LeetCode 921. 使括号有效的最少添加解题思路代码实现 LeetCode 1541. 平衡括号字符串的最少插入次数解题思路代码实现 总结 不要纠结,干就完事了,熟练度很重要!!ÿ…...

TensorFlow vs PyTorch:哪一个更适合您的深度学习项目?
在深度学习领域中,TensorFlow 和 PyTorch 都是非常流行的框架。这两个框架都提供了用于开发神经网络模型的工具和库,但它们在设计和实现上有很大的差异。在本文中,我们将比较 TensorFlow 和 PyTorch,并讨论哪个框架更适合您的深度…...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...

零基础轻松拿捏!魔珐星云青少年健康运动教学数字人搭建全流程指南
大家好!本次给大家分享一款面向青少年体育教育的AI创意实践项目——青少年健康运动教学智能数字交互系统。本项目聚焦青少年体质健康痛点,围绕体育教学智能化升级需求,打造集健康知识教学、运动动作陪练、健康知识考核、运动能力评测于一体的…...
)
ROS Noetic实战:从bag包里‘抠’出雷达点云和IMU数据的保姆级教程(Ubuntu 20.04)
ROS Noetic实战:从bag包里提取雷达点云和IMU数据的完整指南(Ubuntu 20.04)在机器人开发中,ROS bag文件就像是一个装满珍贵数据的宝箱,而雷达点云和IMU数据则是其中最闪亮的宝石。作为一名长期与ROS打交道的开发者&…...

PentestGPT实战部署指南:AI驱动的渗透测试工作流落地
1. 这不是另一个“AI安全”的概念玩具,而是一套能真正跑起来的渗透测试辅助工作流“PentestGPT”这个名字刚在GitHub上出现时,我第一反应是点开又关掉——过去三年里,我见过太多打着“AI渗透”旗号的项目:有的只是把ChatGPT API封…...

MongoDB Limit 与 Skip 方法详解
MongoDB Limit 与 Skip 方法详解 引言 MongoDB 是一个高性能、可伸缩的文档存储系统,它提供了强大的数据存储和查询功能。在处理大量数据时,Limit 与 Skip 方法是 MongoDB 中常用的查询优化工具。本文将详细介绍 MongoDB 中的 Limit 与 Skip 方法,包括其基本用法、性能影响…...

别急着扔!12年老ThinkPad X230升级SSD和内存后,Win10流畅得像新电脑
12年老ThinkPad X230重生指南:极简升级打造流畅办公利器每次打开抽屉看到那台积灰的ThinkPad X230,总有种说不出的情感。这款2012年问世的经典商务本,曾陪伴无数人度过加班到凌晨的夜晚。如今性能确实有些力不从心,但直接丢弃又觉…...

告别元素变动导致的报错:探索自动化测试脚本的 AI“自愈”能力
前言:一个所有测试人都经历过的噩梦 周三晚上十一点,CI/CD流水线再次亮起红灯。 你打开日志,满屏的NoSuchElementException扑面而来。仔细一看——前端团队在昨天的版本中重构了登录页面的DOM结构,原本的#login-btn变成了#signin-button-v2,30个测试用例因此全军覆没。 …...

OmenSuperHub:基于WMI BIOS控制的高性能笔记本硬件管理方案
OmenSuperHub:基于WMI BIOS控制的高性能笔记本硬件管理方案 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 在惠…...
)
用Python复现Nature论文:仅需100次循环数据,提前预测锂电池寿命(附完整代码与数据集)
用Python实战预测锂电池寿命:从数据特征到模型部署全解析锂电池作为现代能源存储的核心组件,其寿命预测一直是工业界和学术界关注的焦点。传统方法往往需要等待电池出现明显容量衰减才能进行判断,而最新研究表明,通过分析早期循环…...

Elden Ring帧率解锁终极指南:从60帧到144+的完整教程
Elden Ring帧率解锁终极指南:从60帧到144的完整教程 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/Elden…...