ChatGLM-LLaMA-chinese-insturct 学习记录(含LoRA的源码理解)
ChatGLM-LLaMA-chinese-insturct
- 前言
- 一、实验记录
- 1.1 环境配置
- 1.2 代码理解
- 1.2.1 LoRA
- 1.4 实验结果
- 二、总结
前言
介绍:探索中文instruct数据在ChatGLM, LLaMA等LLM上微调表现,结合PEFT等方法降低资源需求。
Github: https://github.com/27182812/ChatGLM-LLaMA-chinese-insturct
补充学习:https://kexue.fm/archives/9138
一、实验记录
1.1 环境配置
优雅下载hugging face模型和数据集
conda update -n base -c defaults conda
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash
apt-get install git-lfs
git lfs installgit clone [模型|数据集|地址]
配置conda 环境
conda env create -f env.yml -n bab
conda activate bab
pip install git+https://github.com/huggingface/peft.git
数据集
belle数据集 和 自己收集的中文指令数据集
指令数据集
{"context": Instruction:[举一个使用以下对象的隐喻示例]\nInput:[星星]\nAnswer:, "target": Answer:星星是夜空中闪烁的钻石。
}
1.2 代码理解
函数:gradient_checkpointing_enable
如何理解 gradient_checkpoint, 时间换空间,使得模型显存占用变小,但训练时长增加
PEFT的相关介绍
大模型训练——PEFT与LORA介绍
你也可以动手参数有效微调:LoRA、Prefix Tuning、P-Tuning、Prompt Tuning
1.2.1 LoRA
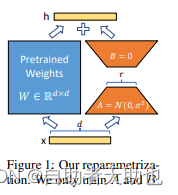
对于左右两个部分,右侧看起来像是左侧原有矩阵W WW的分解,将参数量从d ∗ d 变成了d ∗ r + d ∗ r ,在
r < < d的情况下,参数量就大大地降低了。LORA保留了原来的矩阵W,但是不让W参与训练,所以需要计算梯度的部分就只剩下旁支的A和B两个小矩阵。
蓝色部分的目标函数为:
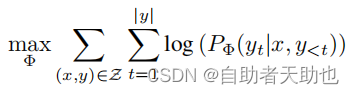
加入LoRA之后:
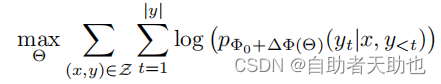
但是相应地,引入LORA部分的参数,并不会在推理阶段加速(不是单纯的橙色部分进行计算),因为在前向计算的时候, 蓝色部分还是需要参与计算的,而Θ部分是凭空增加了的参数,所以理论上,推理阶段应该比原来的计算量增大一点。
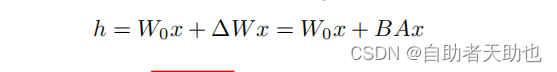
技术细节:

α 可以理解我们在调整lr, α/r 实在缩放蓝色部分的输出,有助于减少训练的超参数
相关参数:

那么如何使用PEFT的LoRA
from peft import get_peft_model, LoraConfig, TaskTypepeft_config = LoraConfig(task_type=TaskType.CAUSAL_LM,inference_mode=False, r=finetune_args.lora_rank,lora_alpha=32,lora_dropout=0.1,)model = get_peft_model(model, peft_config)
其中TaskType可以设置多种任务
class TaskType(str, enum.Enum):SEQ_CLS = "SEQ_CLS" 常规分类任务SEQ_2_SEQ_LM = "SEQ_2_SEQ_LM" seq2seq任务CAUSAL_LM = "CAUSAL_LM" LM任务TOKEN_CLS = "TOKEN_CLS" token的分类任务:序列标注之类的
参数解释:
inference_mode = Whether to use the Peft model in inference mode.
根据苏神的介绍,LST的效果应该是优于LoRA的:
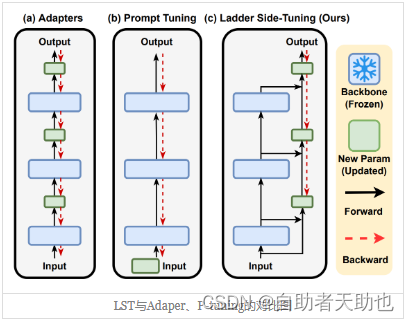
每层当中都有分支,可以理解为LoRA是LST的超简化版本
def __init__(self, model, config, adapter_name):super().__init__()...self.add_adapter(adapter_name, self.peft_config[adapter_name])def add_adapter(self, adapter_name, config=None):...self._find_and_replace(adapter_name)...mark_only_lora_as_trainable(self.model, self.peft_config[adapter_name].bias)if self.peft_config[adapter_name].inference_mode:_freeze_adapter(self.model, adapter_name)
核心类在
def _find_and_replace(self, adapter_name):...# 遍历整个需要训练的模型的名字,这个模型你可以理解为一个字典,拿出所有的keykey_list = [key for key, _ in self.model.named_modules()]for key in key_list:# 找到所有qkv的keyif isinstance(lora_config.target_modules, str):target_module_found = re.fullmatch(lora_config.target_modules, key)else:target_module_found = any(key.endswith(target_key) for target_key in lora_config.target_modules)...# 然后对于每一个找到的目标层,创建一个新的lora层# 注意这里的Linear是在该py中新建的类,不是torch的Linearnew_module = Linear(adapter_name, in_features, out_features, bias=bias, **kwargs)self._replace_module(parent, target_name, new_module, target)
replace_modul把原来的weight和bias赋给新创建的module,然后再分配到指定的设备上
def _replace_module(self, parent_module, child_name, new_module, old_module):setattr(parent_module, child_name, new_module)new_module.weight = old_module.weightif old_module.bias is not None:new_module.bias = old_module.biasif getattr(old_module, "state", None) is not None:new_module.state = old_module.statenew_module.to(old_module.weight.device)# dispatch to correct devicefor name, module in new_module.named_modules():if "lora_" in name:module.to(old_module.weight.device)
merge\ forward部分
def merge(self):if self.active_adapter not in self.lora_A.keys():returnif self.merged:warnings.warn("Already merged. Nothing to do.")returnif self.r[self.active_adapter] > 0:self.weight.data += (transpose(self.lora_B[self.active_adapter].weight @ self.lora_A[self.active_adapter].weight,self.fan_in_fan_out,)* self.scaling[self.active_adapter])self.merged = Truedef forward(self, x: torch.Tensor):previous_dtype = x.dtypeif self.active_adapter not in self.lora_A.keys():return F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)if self.disable_adapters:if self.r[self.active_adapter] > 0 and self.merged:self.unmerge()result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)elif self.r[self.active_adapter] > 0 and not self.merged:result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)x = x.to(self.lora_A[self.active_adapter].weight.dtype)result += (self.lora_B[self.active_adapter](self.lora_A[self.active_adapter](self.lora_dropout[self.active_adapter](x)))* self.scaling[self.active_adapter])else:result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)result = result.to(previous_dtype)return result
评估的过程中,需要将lora部分的weight加到linear层原本的weight中,not self.merged是状态的记录,也就是说,如果设置了需要融合,而当前状态没有融合的话,就把lora部分的参数scale之后加上去,并且更新self.merged状态;
训练的过程中,确保linear本身的weights是没有经过融合过的
1.4 实验结果
chatglm-6b loss的下降不是特别多,3epoch效果也不是特别的明显,最近看到很多人反馈,不管是基于lora还是ptuning对原本的模型效果还是影响很大
二、总结
如果要基于大语言模型的FT,至少需要足够的显存,和语料,最好是将新的语料和原本的语料一起进行SFT
- sft的原理还没有弄明白
- 显存还需要扩充,使用deepspeed框架进行full FT,有资源谁还回去lora,ptuning呢?
- 多轮的数据集还没有
- 这个仓库的数据集还是,单轮的指令数据集,并没有涉及到多轮
- 即使是官方的仓库也只是构造了多轮的训练脚本,数据集并没有提供
- llama不跑了,只是换了一个模型而已
相关文章:
ChatGLM-LLaMA-chinese-insturct 学习记录(含LoRA的源码理解)
ChatGLM-LLaMA-chinese-insturct 前言一、实验记录1.1 环境配置1.2 代码理解1.2.1 LoRA 1.4 实验结果 二、总结 前言 介绍:探索中文instruct数据在ChatGLM, LLaMA等LLM上微调表现,结合PEFT等方法降低资源需求。 Github: https://github.com/27182812/Ch…...

JuiceFS-K8s部署
目录 1、部署JuiceFS-CSI驱动2、创建OBS认证信息Secret3、创建存储类4、创建PVC--PVC创建时会自动创建PV5、创建测试Pod--测试Pod创建容器内是否挂载成功 官网文档地址:https://juicefs.com/docs/zh/csi/introduction/ 1、部署JuiceFS-CSI驱动 部署yaml如下&#x…...

2023最新版本Camtasia电脑录屏软件好不好用?
在当今数字化时代,屏幕录制成为了许多用户制作教学视频、演示文稿、游戏攻略等内容的首选。本文将为您介绍几款常用的电脑录屏软件,包括Camtasia、OBS Studio、Bandicam等,并对其进行功能和用户体验方面的比较,同时给出10款电脑录…...

第三章 Linux 初步
第三章 Linux 初步 一、 基本操作 ①登录: Linux 是多用户系统,必须用正确的用户名和口令登录后才能 进入 Linux Shell 提示符状态。 默认的文本界面 Shell 提示符有两种: •root 用户登录后的提示符: # •普通用户登录后的…...

linux环境安装使用mysql详解
01-安装MySQL并启动 1.1 环境准备 # 1.卸载mariadb,否则安装mysql会出现冲突 (1).执行命令rpm -qa | grep mariadb 会列出所有被安装的mariadb rpm 包; (2).执行命令rpm -e --nodeps mariadb-libs-5.5.56…...
SUNTANS模型学习(9)——学习Tidal forcing算例
学习Tidal forcing算例 简介网格配置与地形定解条件设置初始条件设置边界条件设置开边界处的通量计算(OpenBoundaryFluxes)开边处的速度、水位(BoundaryVelocities) 其它参数配置模拟结果 简介 SUNTANS中 tidal forcing 算例的全…...

力扣解法汇总1010. 总持续时间可被 60 整除的歌曲
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接: 力扣 描述: 在歌曲列表中,第 i 首歌曲的持续时间为 time[i] 秒。 返回其总持…...

利用老毛桃pe启动U盘启动ubuntu.iso,完成ubuntu系统的安装
1.双U盘,一个是老毛桃pe启动盘,可以启动grub4dos,加载了run模块,很好用(尤其是对不熟悉grub的小白) 2.大容量U盘存放ubuntu-desktop-i386.iso,U盘的格式是ntfs格式(其实这个不好&am…...
分享2个教学视频录制的方法!
案例:如何录制教学视频? 【我是一名老师,我想录制一些教学视频发布在网络平台上,但是我不知道如何操作。有没有人知道录制教学视频需要什么工具?如何录制?】 随着在线教育的普及,越来越多的教…...

「SQL面试题库」 No_63 报告的记录 II
🍅 1、专栏介绍 「SQL面试题库」是由 不是西红柿 发起,全员免费参与的SQL学习活动。我每天发布1道SQL面试真题,从简单到困难,涵盖所有SQL知识点,我敢保证只要做完这100道题,不仅能轻松搞定面试࿰…...

【事务】怎么去理解事务?
1、什么是事务? 事务是指作为单个逻辑工作单元执行的一系列操作,这些操作要么全做,要么全不做,是一个不可分割的工作单元。 2、事务具有哪些特性? 一个逻辑工作单元要成为事务,在关系型数据库管理系统中…...

camunda流程变量如何使用
Camunda是一个流程引擎,它支持在流程执行期间存储和操作流程变量。流程变量是一个值或对象,可以与Camunda中的流程实例、任务或执行相关联。 流程变量在Camunda中有很多用途。以下是一些常见的用途: 1、传递数据:流程变量可以用于…...
CMIP6:WRF模式动力降尺度、单点降尺度、统计方法区域降尺度
专题一 CMIP6中的模式比较计划 1.1 GCM介绍 1.2 相关比较计划介绍 专题二数据下载 2.1方法一:手动人工 利用官方网站 2.2方法二:自动 利用Python的命令行工具 2.3方法三:半自动购物车 利用官方网站 2.4 裁剪netCDF文件 …...

2023建筑设计师们有哪些好用的AI设计工具?
目前,建筑师要么单独工作,要么团队合作来完成设计过程,这可能需要数月甚至数年的时间。设计和准备用于开发的建筑物可能需要很长时间,有时甚至数年。一些比较繁琐的步骤可以自动化,但整个过程仍然需要大量的人工和时间…...
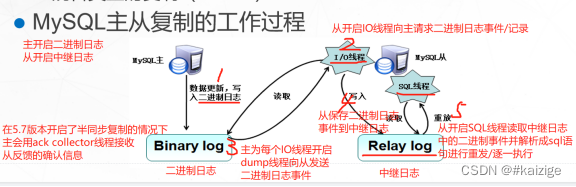
mysql主从复制与读写分离
mysql主从复制与读写分离 MySQL主从复制是一种常见的数据复制技术,用于将一个MySQL数据库服务器的数据复制到其他服务器上。 单台mysql在安全性,高并发方面都无法满足实际需求 配置多台主从数据库服务器以实现读写分离 读写分离,主数据库的…...

技术控,看这里,一款支持断点调试的数据科学工具
数据科学是一门利用统计学、机器学习、数据挖掘、数据可视化等技术和方法,从数据中提取知识和信息的交叉学科。自上世纪60年代,统计学家John W.Tukey首次提出“数据分析”(Data Analysis)的概念起,数据科学已历经了几十…...

论文导读 | 大语言模型上的精调策略
随着预训练语言模型规模的快速增长,在下游任务上精调模型的成本也随之快速增加。这种成本主要体现在两方面上:一,计算开销。以大语言模型作为基座,精调的显存占用和时间成本都成倍增加。随着模型规模扩大到10B以上,几乎…...

进阶自动化测试,这3点你一定要知道的...
自动化测试指软件测试的自动化,在预设状态下运行应用程序或系统,预设条件包括正常和异常,最后评估运行结果。将人为驱动的测试行为转化为机器执行的过程。 自动化测试框架一般可以分为两个层次,上层是管理整个自动化测试的开发&a…...

网络编程套接字API
一. linux平台 1.创建套接字 成功返回文件描述符,失败返回-1 int socket (int __domain, int __type, int __protocol) ;2.套接字绑定IP地址和端口号 成功返回0,失败返回-1 int bind (int __fd, __CONST_SOCKADDR_ARG __addr, socklen_t __len);3.开启…...

数字藏品的价值和意义
2022年以来,数字藏品概念在国内火热起来。从年初的《关于防范 NFT相关金融风险的倡议》到8月份央行数字货币 DCEP的正式面世,从中国香港首个“NFT”艺术品在香港拍卖市场成交到国内多家互联网大厂推出数字藏品平台,越来越多的企业开始试水数字…...
)
从一次生产事故复盘:我们如何优雅地处理用户上传的‘异常’Excel文件(附Apache POI配置详解)
从生产事故到防御体系:构建Excel文件处理的工程化解决方案那天凌晨2点,我被一阵急促的告警声惊醒。监控系统显示,核心文件处理服务的错误率在10分钟内飙升到35%,大量用户上传的Excel文件无法正常解析。更糟糕的是,部分…...

Allegro等长设置翻车实录:拓扑模板法的3个坑与手工PinPair的救赎
Allegro等长设计避坑指南:从拓扑模板到精准PinPair的实战演进在高速PCB设计中,等长匹配如同精密钟表里的齿轮啮合,差之毫厘便可能导致整个系统时序崩塌。当设计从简单的点对点结构升级到多负载复杂拓扑时,Allegro用户常陷入两种典…...

iPaaS 应用场景深度解析:从系统孤岛到数据自由流动的六大实战路径
写在前面 一个企业的数字化程度越高,系统就越多。系统越多,集成问题就越严重。 这不是假设,而是我们在服务客户过程中反复验证的结论——企业数字化转型的瓶颈,往往不在于"造新系统",而在于"连老系统&q…...

打不开JupyterLab
因为安装某些依赖导致JupyterLab的依赖被动升级或降级,从而影响了JupyterLab的运行,此时可以SSH登录到实例,然后输入jupyter-lab命令进行确认,如果执行命令报错则说明是此问题,那么可以通过pip install jupyterlab再次…...

巧用对称性与平均值原理:低成本实现高精度电阻分压器校准
1. 项目概述:用数学思维突破测量设备的精度极限在电子实验室里捣鼓精密电路,尤其是涉及到电压基准、信号调理或者高精度ADC前端时,一个绕不开的坎就是精密分压器。你可能在设计一个需要0.1%甚至更高精度的分压网络,但手头的万用表…...

3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单
3大实战秘籍:揭秘raylib如何让游戏开发像搭积木一样简单 【免费下载链接】raylib A simple and easy-to-use library to enjoy videogames programming 项目地址: https://gitcode.com/GitHub_Trending/ra/raylib 你是否曾经被复杂的游戏引擎配置搞得焦头烂额…...

十年以上经验的建站公司推荐|策划强、落地稳的网站制作公司盘点
互联网时代,企业官网已从单纯的信息展示窗口升级为集品牌价值传递、用户体验连接与业务高效转化于一体的核心数字阵地。行业报告显示,优质官网可帮助企业线上转化率提升35%-60%,而低效官网则可能导致潜在客户大量流失。面对市场上众多的网站建…...

3步快速部署:智能茅台抢购平台的终极自动化解决方案
3步快速部署:智能茅台抢购平台的终极自动化解决方案 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gi…...

原来专业的赛事专用匹克球厂家有这么多门道?
引言在匹克球运动蓬勃发展的当下,专业赛事专用匹克球的选择至关重要。很多人可能不知道,看似普通的赛事专用匹克球背后,其实隐藏着诸多门道。接下来,我们就一起深入探究专业赛事专用匹克球厂家的秘密。核心技术与材料的门道专业赛…...

HarmonyOS DateUtil 日期工具入门:格式化、时间戳与今日信息
文章目录背景一、HarmonyOS 日期处理的痛点二、核心方法:getFormatDate三、时间戳自动补位四、核心方法:getFormatDateStr五、今日信息快速获取六、完整 Demo 演示6.1 刷新当前时间6.2 格式化演示6.3 常用格式展示6.4 基础信息 UI6.5 intl.DateTimeForma…...