双向链表(数据结构)(C语言)
目录
概念
带头双向循环链表的实现
前情提示
双向链表的结构体定义
双向链表的初始化
关于无头单向非循环链表无需初始化函数,顺序表、带头双向循环链表需要的思考
双向链表在pos位置之前插入x
双向链表的打印
双链表删除pos位置的结点
双向链表的尾插
关于单链表的尾插需要用到二级指针,双向链表不需要用到二级指针的思考
双向链表的判空
双向链表的尾删
双向链表的头插
双向链表的头删
双向链表查找值为x的结点
双向链表的销毁
双向链表的修改
双向链表删除值为x的结点
双向链表计算结点总数(不计phead)
双向链表获取第i位置的结点
双向链表的清空
总代码(想直接看结果的可以看这里)
概念
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。我们一般构造双向循环链表。循环链表是一种链式存储结构,它的最后一个结点指向头结点,形成一个环。因此,从循环链表中的任何一个结点出发都能找到任何其它结点。
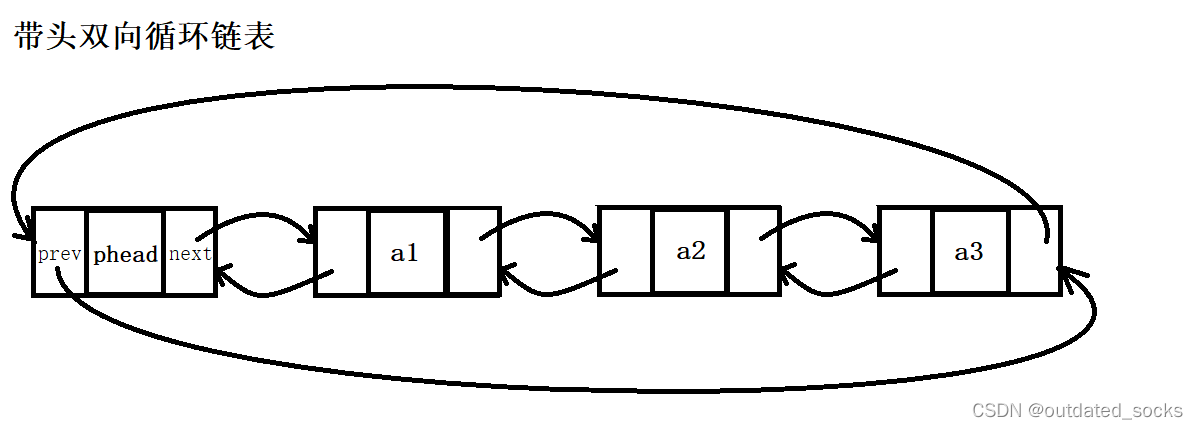
带头双向循环链表的实现
前情提示
List.h 用于 引用的头文件、双向链表的定义、函数的声明。
List.c 用于 函数的定义。
Test.c 用于 双向链表功能的测试。
双向链表的结构体定义
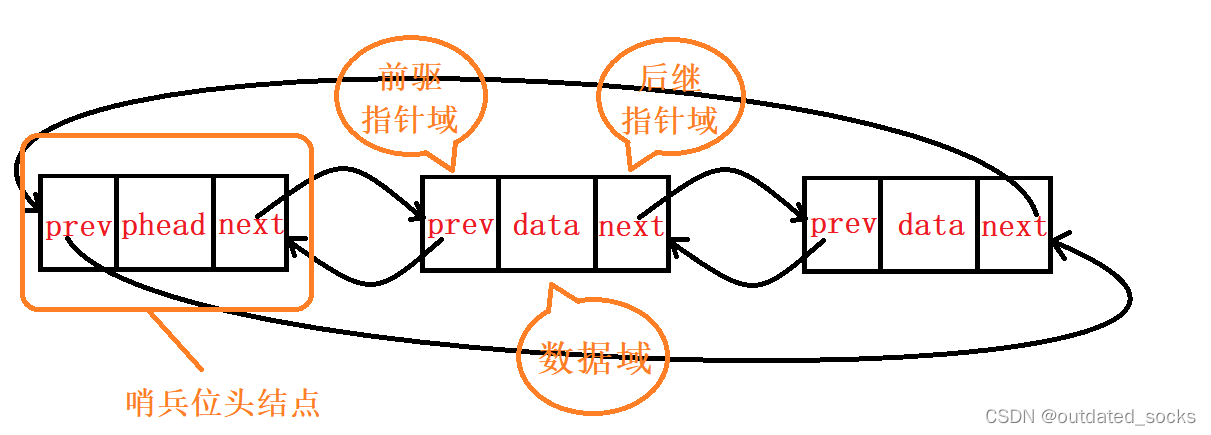
在List.h下
#pragma once//使同一个文件不会被包含(include)多次,不必担心宏名冲突//先将可能使用到的头文件写上
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>typedef int LTDataType;//假设结点的数据域类型为 int
//给变量定义一个易于记忆且意义明确的新名字,并且便于以后存储其它类型时方便改动
//(比如我晚点想存double类型的数据,我就直接将 int 改为 double )// 带哨兵位双向循环链表的结构体定义
typedef struct ListNode
{struct ListNode* prev;//前驱指针域:存放上一个结点的地址struct ListNode* next;//后继指针域:存放下一个结点的地址LTDataType data;//数据域
}LTNode;
//struct 关键字和 ListNode 一起构成了这个结构类型
//typedef 为这个结构起了一个别名,叫 LTNode,即:typedef struct ListNode LTNode
//现在就可以像 int 和 double 那样直接使用 LTNode 来定义变量双向链表的初始化

在List.h下
// 双向链表的初始化// 如果是单链表直接给个空指针就行,不需要单独写一个函数进行初始化
// 即:LTNode* plist = NULL;
// 那为什么顺序表、带头双向循环链表有呢?
// 因为顺序表、带头双向循环链表的结构并不简单,
// 如: 顺序表顺序表为空size要为0,还要看capacity是否要开空间,
// 若不开空间capacity=0,指针要给空,若开空间,还要检查malloc是否成功
// 带头双向循环链表要开个结点,检查malloc是否成功,然后让结点自己指向自己
// 顺序表和双向循环链表的初始化有点复杂,最好构建一个函数
LTNode* LTInit();在List.c下
#include"List.h"//别忘了//动态申请一个结点
LTNode* BuyListNode(LTDataType x)
{LTNode* node = (LTNode*)malloc(sizeof(LTNode));if (node == NULL)//如果malloc失败{perror("malloc fail");return NULL;}//如果malloc成功//初始化一下,防止野指针,如果看到返回的是空指针,那逻辑可能有些错误node->next = NULL;node->prev = NULL;node->data = x;return node;
}// 双向链表的初始化
LTNode* LTInit()
{LTNode* phead = BuyListNode(-1);//创建哨兵位//自己指向自己phead->next = phead;phead->prev = phead;return phead;
}关于无头单向非循环链表无需初始化函数,顺序表、带头双向循环链表需要的思考
无头单向非循环链表结构太简单了,初始化只需直接赋空指针,无需单独写一个函数进行初始化。
即:LTNode* plist = NULL;那为什么顺序表、带头双向循环链表有单独写一个函数进行初始化呢?
因为顺序表、带头双向循环链表的结构并不简单。
如:
顺序表顺序表为空size要为0,还要看capacity是否要开空间,若不开空间capacity=0,指针要给空,若开空间,还要检查malloc是否成功。
带头双向循环链表要开个结点,检查malloc是否成功,然后让结点自己指向自己。
顺序表和双向循环链表的初始化有点复杂,最好构建一个函数。
双向链表在pos位置之前插入x
在List.h下
// 双向链表在pos位置之前进行插入
void LTInsert(LTNode* pos, LTDataType x);在List.c下
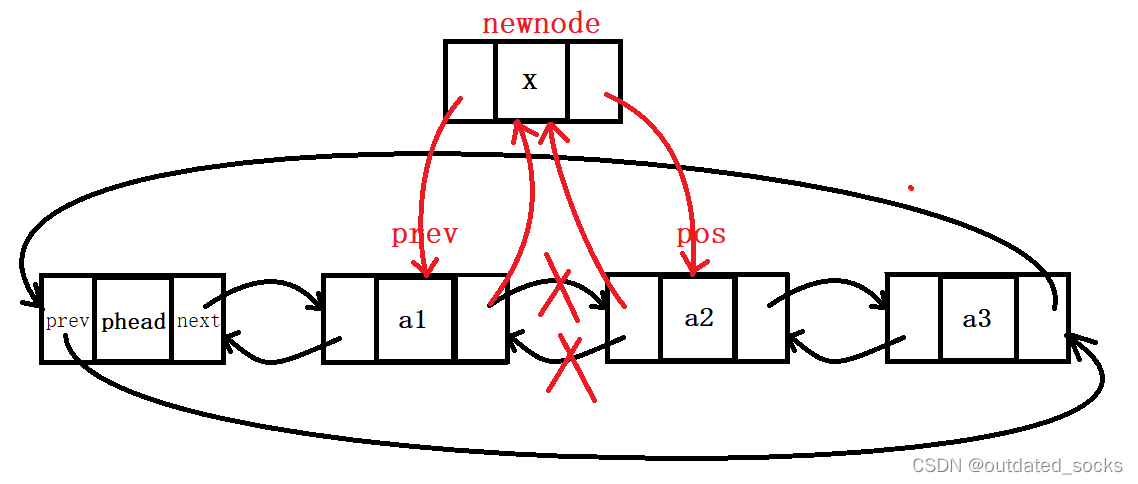
// 双向链表在pos位置之前进行插入
void LTInsert(LTNode* pos, LTDataType x)
{assert(pos);//pos肯定不为空LTNode* prev = pos->prev;LTNode* newnode = BuyListNode(x);//创建一个需要插入的结点prev->next = newnode;newnode->prev = prev;newnode->next = pos;pos->prev = newnode;
}
双向链表的打印
在List.h下
// 双向链表打印
void LTPrint(LTNode* phead);在List.c下
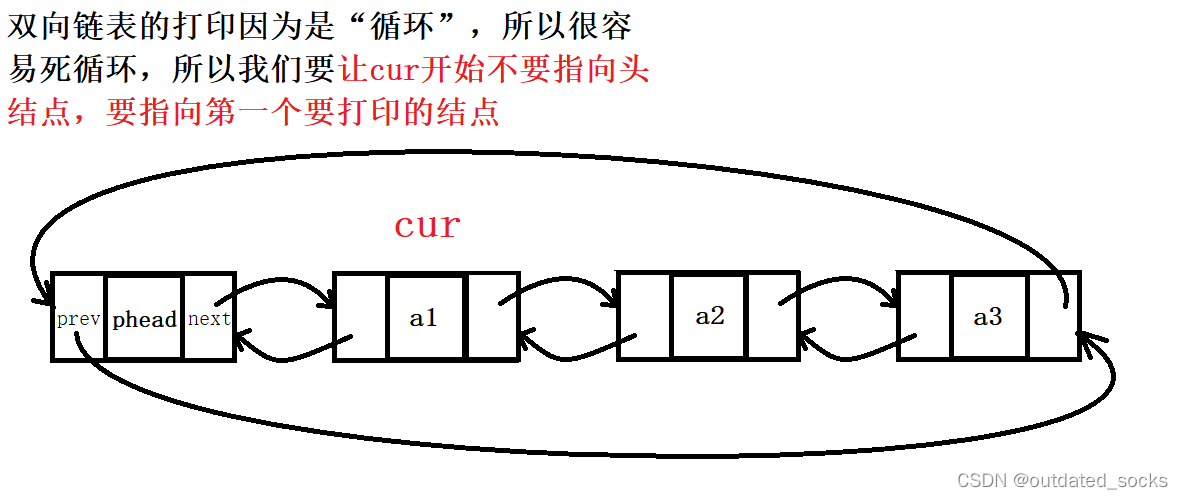
// 双向链表打印
void LTPrint(LTNode* phead)
{assert(phead);//有哨兵位printf("<=>phead<=>");LTNode* cur = phead->next;//cur指向第一个要打印的结点while (cur != phead)//cur等于头结点时打印就结束了{printf("%d<=>", cur->data);cur = cur->next;}printf("\n");
}在Test.c下
#include"List.h"//别忘了//测试函数
void TestList1()
{LTNode* plist = LTInit();LTInsert(plist, 1);LTInsert(plist, 2);LTInsert(plist, 3);LTInsert(plist, 4);LTPrint(plist);
}int main()
{TestList1();return 0;
}
双链表删除pos位置的结点
在List.h下
// 双向链表删除pos位置的结点
void LTErase(LTNode* pos);在List.c下
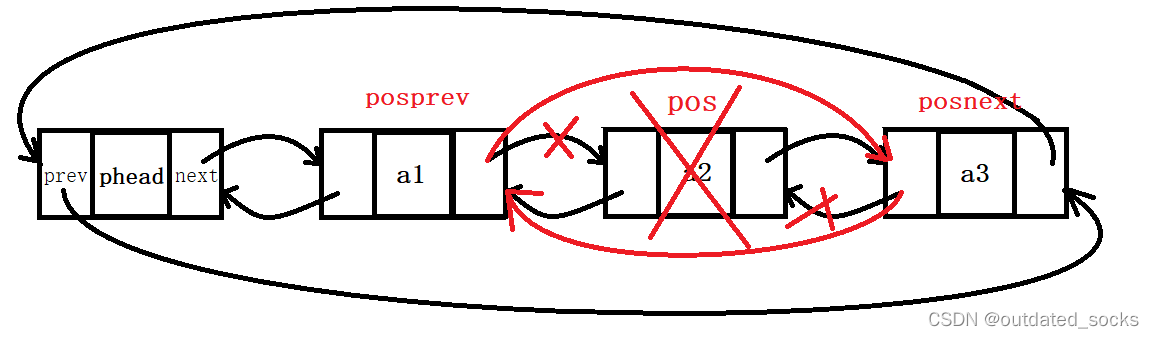
// 双向链表删除pos位置的结点
void LTErase(LTNode* pos)
{assert(pos);//pos肯定不为空LTNode* posprev = pos->prev;LTNode* posnext = pos->next;posprev->next = posnext;posnext->prev = posprev;free(pos);pos = NULL;//这个置空其实已经没有意义了,形参的改变不会改变实参
}在Test.c下
//测试函数
void TestList1()
{LTNode* plist = LTInit();LTInsert(plist, 1);LTInsert(plist, 2);LTInsert(plist, 3);LTInsert(plist, 4);LTPrint(plist);LTErase(plist->next);LTPrint(plist);}int main()
{TestList1();return 0;
}
双向链表的尾插
在List.h下
//双向链表优于单链表的点——不需要找尾、二级指针
//(我们改的不是结构体的指针,改的是结构体的变量)
// 双向链表的尾插
void LTPushBack(LTNode* phead, LTDataType x);在List.c下
法一:(便于新手更好地理解双向链表的尾插)
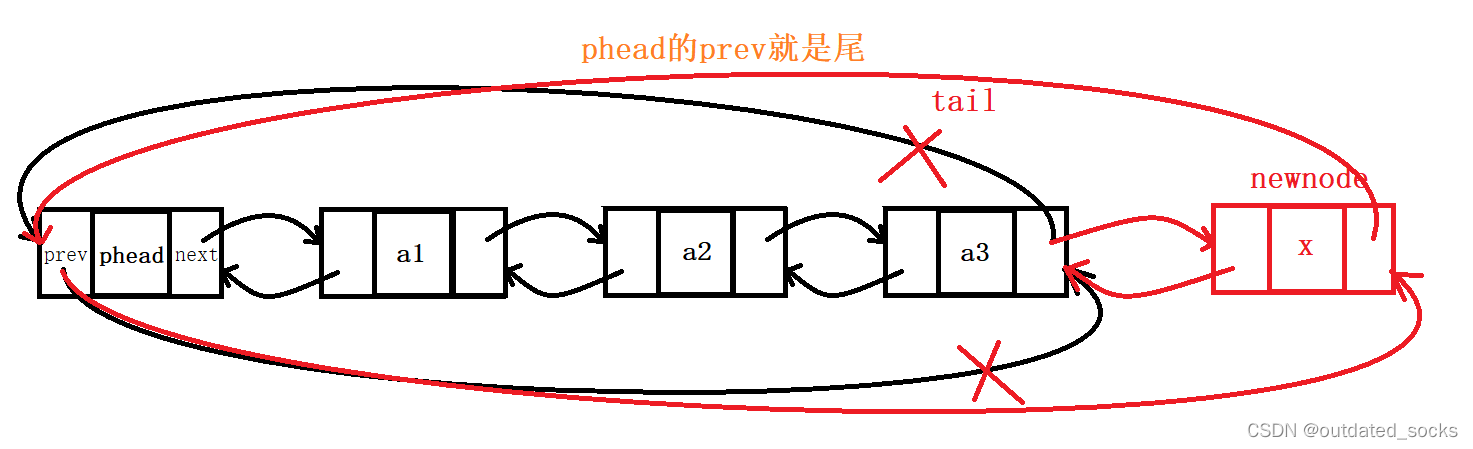

// 双向链表的尾插
void LTPushBack(LTNode* phead, LTDataType x)
{assert(phead);//有哨兵位//法一:(便于新手更好地理解双向链表的尾插)//一步就可完成链表为空/不为空的尾插——因为有哨兵位LTNode* newnode = BuyListNode(x);//创建一个要插入的结点LTNode* tail = phead->prev;tail->next = newnode;newnode->prev = tail;newnode->next = phead;phead->prev = newnode;
}法二:函数复用(简单方便)
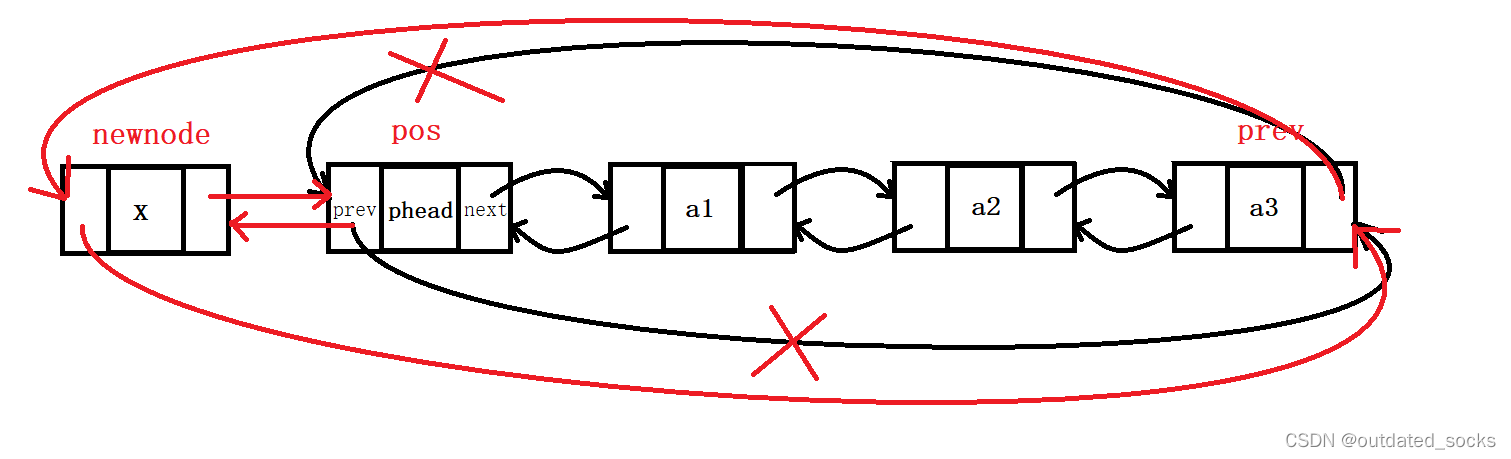
// 双向链表的尾插
void LTPushBack(LTNode* phead, LTDataType x)
{assert(phead);//有哨兵位//法二:函数复用(简单方便)LTInsert(phead, x);
}
关于单链表的尾插需要用到二级指针,双向链表不需要用到二级指针的思考
单链表改变的是结构体的指针,双向链表改变的是结构体的变量
二级指针和一级指针的区别在于指针所指向变量的层级不同,一级指针指向的是结构体的变量,而二级指针指向的是结构体指针的地址。
单链表中,在进行链表结点的删除或插入操作时,需要更新结点之间的指针指向。若使用一级指针,则操作会直接改变指向结点的指针,很难实现目标。因此需要传递二级指针,让函数能够修改指向结点指针的地址,也就是修改之前结点指针变量存放的地址。
而双向链表中,每个结点除了保存指向下一结点的指针外,还有保存指向上一结点的指针,结点之间的双向指针关系使得结点的插入和删除操作更加方便。双向链表不需要传递二级指针,因为在结点的删除和插入操作中,只需要先修改当前结点前后结点的指针,无需直接改变前后结点指针变量存放的地址。
综上所述,单链表只有指向下一结点的指针,通过传递二级指针来修改结点之间的指针关系,使得操作更加灵活;而双向链表的结点之间有双向指针关系,无需直接改变前后结点指针变量存放的地址,因此只需要传递一级指针即可。
单链表(对比):

在Test.c下
//测试函数
void TestList2()
{LTNode* plist = LTInit();LTPushBack(plist, 5);LTPushBack(plist, 6);LTPushBack(plist, 7);LTPushBack(plist, 8);LTPrint(plist);
}int main()
{TestList2();return 0;
}
双向链表的判空
在尾删/头删之前,我们要先判断链表是否为空。
在List.h下
// 双向链表的判空
bool LTEmpty(LTNode* phead);在List.c下
// 双向链表的判空
bool LTEmpty(LTNode* phead)
{assert(phead);return phead->next == phead;//两者相等就是空链表(返回真),两者不相等就不是空链表(返回假)
}双向链表的尾删
在List.h下
// 双向链表的尾删
void LTPopBack(LTNode* phead);在List.c下
法一:(便于新手更好地理解双向链表的尾删)
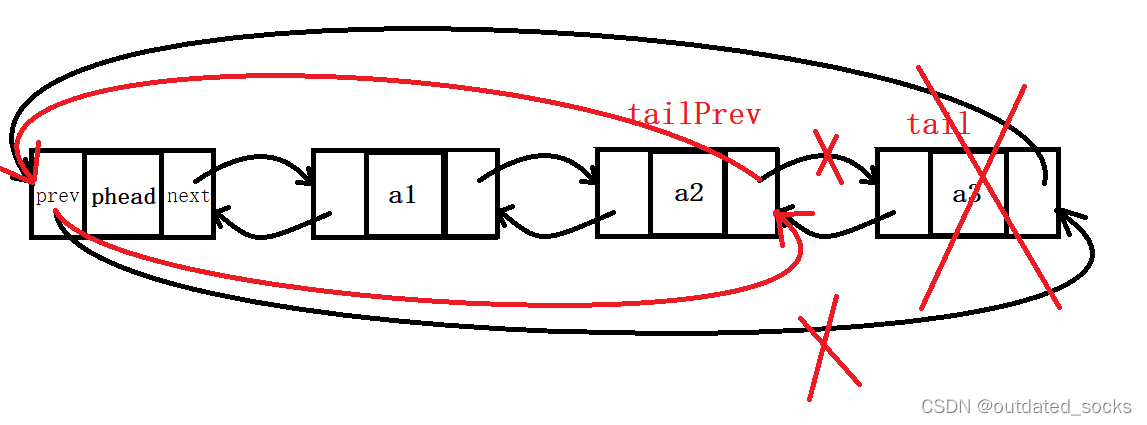
// 双向链表的尾删
void LTPopBack(LTNode* phead)
{assert(phead);//有哨兵位assert(!LTEmpty(phead));//判空//法一:(便于新手更好地理解双向链表的尾删)LTNode* tail = phead->prev;LTNode* tailPrev = tail->prev;tailPrev->next = phead;phead->prev = tailPrev;free(tail);tail = NULL;
}法二:函数复用(简单方便)
// 双向链表的尾删
void LTPopBack(LTNode* phead)
{assert(phead);//有哨兵位assert(!LTEmpty(phead));//判空//法二:函数复用LTErase(phead->prev);
}在Test.c下
//测试函数
void TestList2()
{LTNode* plist = LTInit();LTPushBack(plist, 5);LTPushBack(plist, 6);LTPushBack(plist, 7);LTPushBack(plist, 8);LTPrint(plist);LTPopBack(plist);LTPopBack(plist);LTPrint(plist);
}int main()
{TestList2();return 0;
}
双向链表的头插
在List.h下
// 双向链表头插
void LTPushFront(LTNode* phead, LTDataType x);在List.c下
法一:只用phead和newnode两个指针(便于新手更好地理解双向链表的头插)

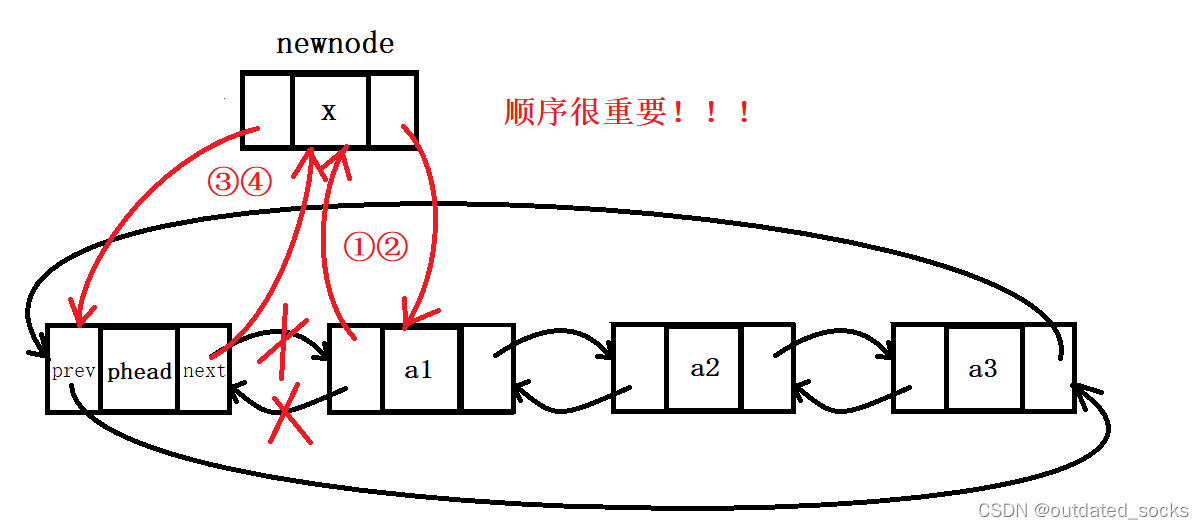
// 双向链表头插
void LTPushFront(LTNode* phead, LTDataType x)
{assert(phead);//有哨兵位LTNode* newnode = BuyListNode(x);//创建一个要插入的结点//法一:只用phead和newnode两个指针(便于新手更好地理解双向链表的头插)//顺序很重要!!!newnode->next = phead->next;phead->next->prev = newnode;phead->next = newnode;newnode->prev = phead;
}法二:多用了first记录第一个结点的位置(便于新手更好地理解双向链表的头插)

// 双向链表头插
void LTPushFront(LTNode* phead, LTDataType x)
{assert(phead);//哨兵位LTNode* newnode = BuyListNode(x);//创建一个要插入的结点//法二:多用了first先记住第一个结点(便于新手更好地理解双向链表的头插)LTNode* first = phead->next;phead->next = newnode;newnode->prev = phead;newnode->next = first;first->prev = newnode;
}法三:函数复用(简单方便)
// 双向链表头插
void LTPushFront(LTNode* phead, LTDataType x)
{assert(phead);//有哨兵位//法三:函数复用(简单方便)LTInsert(phead->next, x);
}在Test.c下
//测试函数
void TestList3()
{LTNode* plist = LTInit();LTPushFront(plist, 1);LTPushFront(plist, 2);LTPushFront(plist, 3);LTPushFront(plist, 4);LTPrint(plist);
}int main()
{TestList3();return 0;
}
双向链表的头删
在List.h下
// 双向链表头删
void LTPopFront(LTNode* phead);在List.c下
法一:(便于新手更好地理解双向链表的头删)
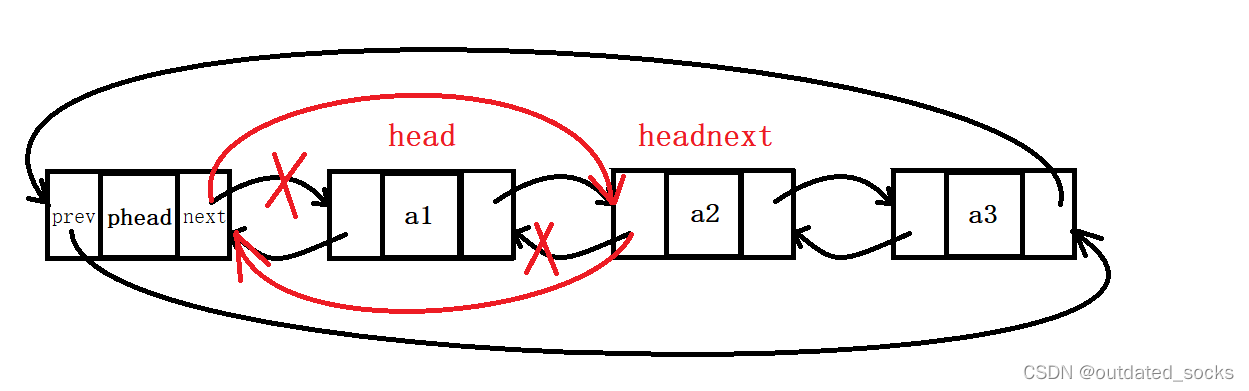
// 双向链表头删
void LTPopFront(LTNode* phead)
{assert(phead);//有哨兵位assert(!LTEmpty(phead));//判空//法一:(便于新手更好地理解双向链表的头删)LTNode* head = phead->next;LTNode* headnext = head->next;phead->next = headnext;headnext->prev = phead;free(head);head = NULL;
}法二:函数复用(简单方便)
// 双向链表头删
void LTPopFront(LTNode* phead)
{assert(phead);//有哨兵位assert(!LTEmpty(phead));//判空//法二:函数复用(简单方便)LTErase(phead->next);
}
在Test.c下
//测试函数
void TestList3()
{LTNode* plist = LTInit();LTPushFront(plist, 1);LTPushFront(plist, 2);LTPushFront(plist, 3);LTPushFront(plist, 4);LTPrint(plist);LTPopFront(plist);LTPopFront(plist);LTPrint(plist);
}int main()
{TestList3();return 0;
}
双向链表查找值为x的结点
在List.h下
// 双向链表查找值为x的结点
LTNode* LTFind(LTNode* phead, LTDataType x);在List.c下
// 双向链表查找值为x的结点
LTNode* LTFind(LTNode* phead, LTDataType x)
{assert(phead);//有哨兵位LTNode* cur = phead->next;while (cur != phead)//让cur去遍历{if (cur->data == x)//如果找到{return cur;}cur = cur->next;}return NULL;//如果没找到
}在Test.c下
//测试函数
TestList4()
{LTNode* plist = LTInit();LTInsert(plist, 1);LTInsert(plist, 2);LTInsert(plist, 3);LTInsert(plist, 4);LTPrint(plist);LTNode* pos = LTFind(plist, 3);if (pos){LTErase(pos);pos = NULL;}LTPrint(plist);
}int main()
{TestList4();return 0;
}
双向链表的销毁
在List.h下
// 双向链表的销毁
void LTDestory(LTNode* phead);在List.c下
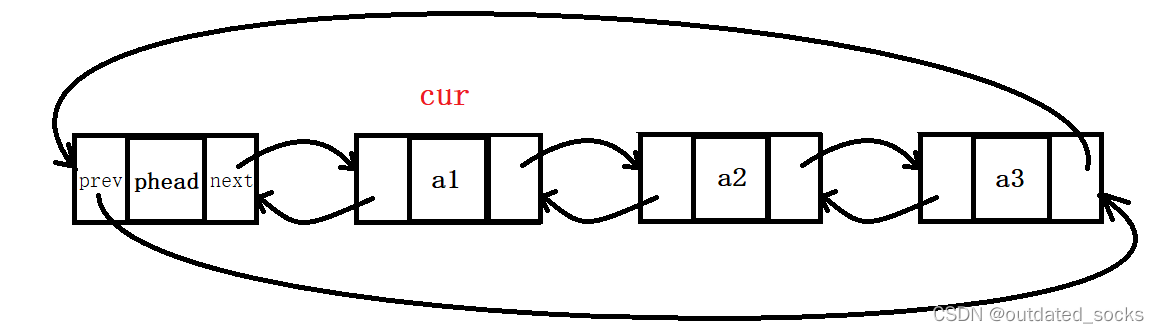
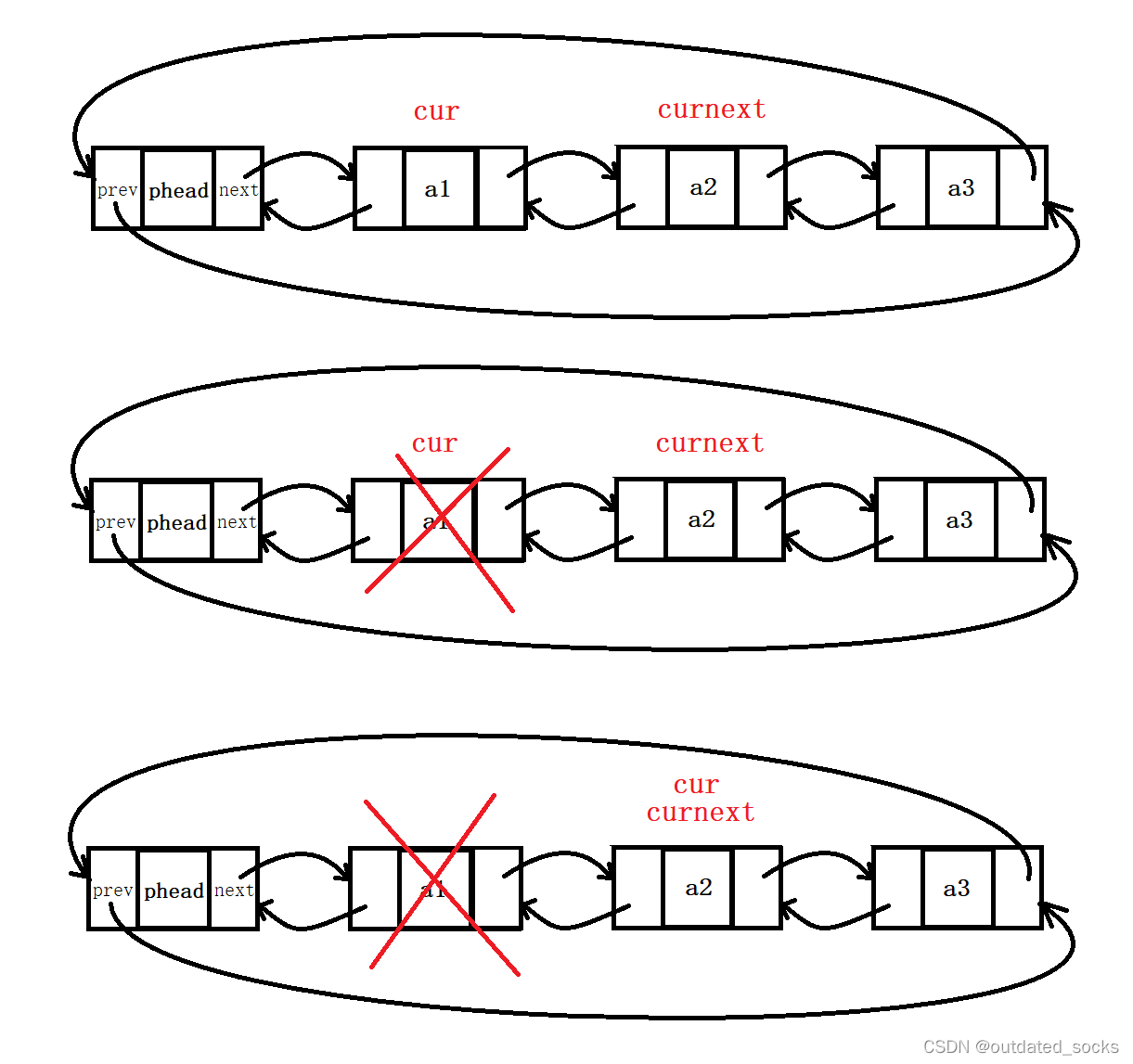

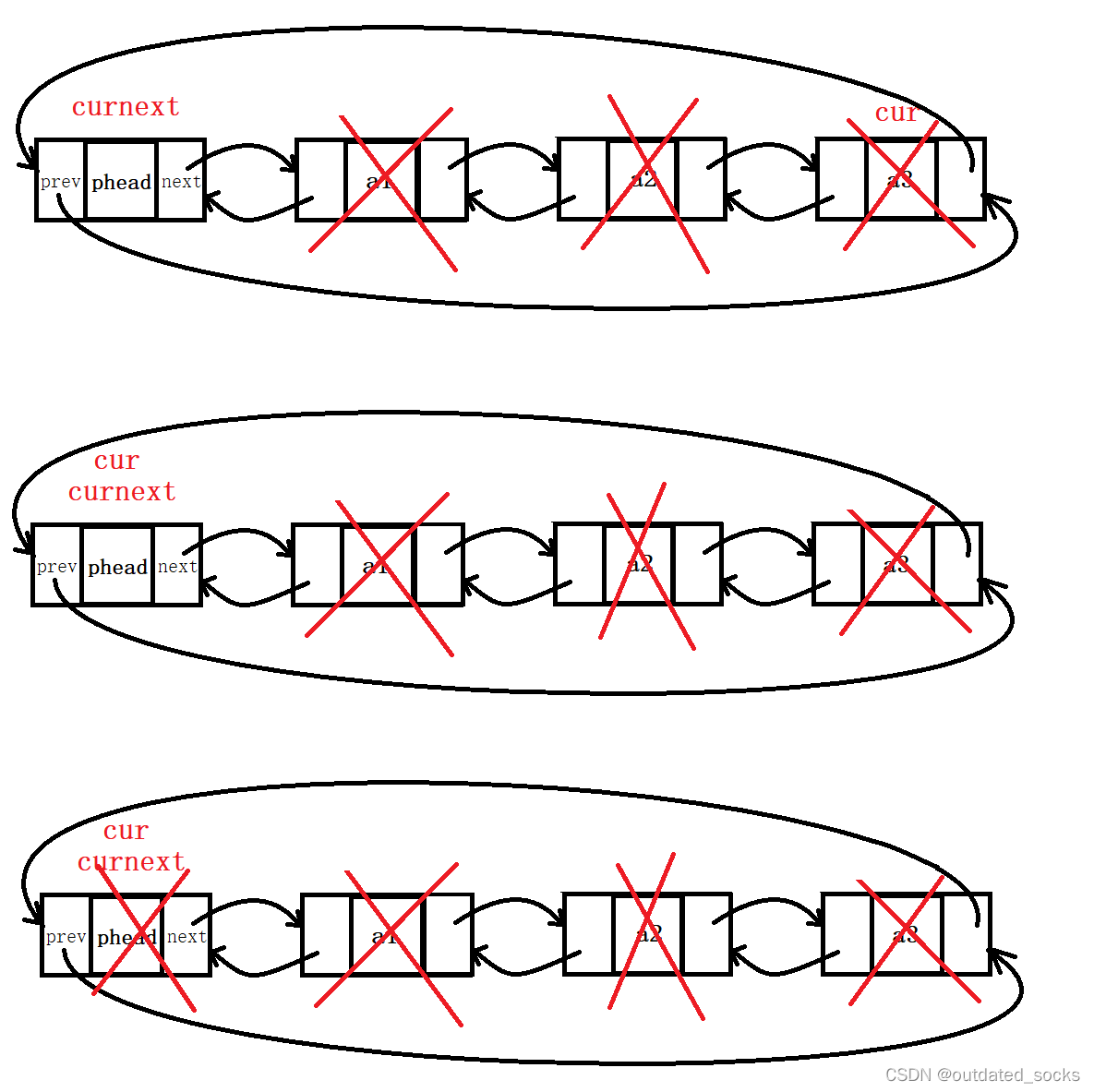
// 双向链表的销毁
void LTDestory(LTNode* phead)
{assert(phead);LTNode* cur = phead->next;//让cur遍历while (cur != phead){LTNode* curnext = cur->next;free(cur);cur = curnext;}free(phead);phead = NULL;//这个置空其实已经没有意义了,形参的改变不会改变实参//我们为了保持接口的一致性,不传二级指针,选择在测试的时候置空
}在Test.c下
//测试函数
TestList4()
{LTNode* plist = LTInit();LTInsert(plist, 1);LTInsert(plist, 2);LTInsert(plist, 3);LTInsert(plist, 4);LTPrint(plist);LTNode* pos = LTFind(plist, 3);if (pos){LTErase(pos);pos = NULL;}LTPrint(plist);LTDestory(plist);plist = NULL;//在这里置空
}双向链表的修改
在List.h下
// 双向链表的修改,修改pos位置的值为x
void LTModify(LTNode* pos, LTDataType x);在List.c下
// 双向链表的修改,修改pos位置的值为x
void LTModify(LTNode* pos, LTDataType x)
{assert(pos);pos->data = x;
}在Test.c下
//测试函数
TestList5()
{LTNode* plist = LTInit();LTInsert(plist, 1);LTInsert(plist, 2);LTInsert(plist, 3);LTInsert(plist, 4);LTPrint(plist);LTModify(plist->next,5);LTPrint(plist);
}int main()
{TestList5();return 0;
}
双向链表删除值为x的结点
在List.h下
// 双向链表删除值为x的结点
void LTRemove(LTNode* phead,LTDataType x);在List.c下
// 双向链表删除值为x的结点
void LTRemove(LTNode* phead, LTDataType x)
{assert(phead);//有哨兵位LTNode* pos = phead->next;while (pos != phead){pos = LTFind(phead, x);if (pos == NULL)//如果遍历完{return NULL;}LTErase(pos);pos = pos->next;}
}在Test.c下
TestList6()
{LTNode* plist = LTInit();LTInsert(plist, 1);LTInsert(plist, 3);LTInsert(plist, 3);LTInsert(plist, 4);LTInsert(plist, 3);LTPrint(plist);LTRemove(plist, 3);LTPrint(plist);
}int main()
{TestList6();return 0;
}
双向链表计算结点总数(不计phead)
在List.h下
// 双向链表计算结点总数(不计phead)
int LTTotal(LTNode* phead);在List.c下
// 双向链表计算结点总数(不计phead)
int LTTotal(LTNode* phead)
{assert(phead);//有哨兵位int count = 0;//count来计数LTNode* cur = phead->next;//让cur去遍历while (cur != phead){count++;cur = cur->next;}return count;
}在Test.c下
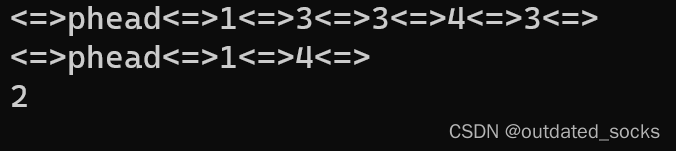
TestList6()
{LTNode* plist = LTInit();LTInsert(plist, 1);LTInsert(plist, 3);LTInsert(plist, 3);LTInsert(plist, 4);LTInsert(plist, 3);LTPrint(plist);LTRemove(plist, 3);LTPrint(plist);printf("%d\n", LTTotal(plist));
}int main()
{TestList6();return 0;
}
双向链表获取第i位置的结点
在List.h下
// 双向链表获取第i位置的结点
LTNode* LTGet(LTNode* phead, int i);在List.c下
// 双向链表获取第i位置的结点
LTNode* LTGet(LTNode* phead, int i)
{assert(phead);//有哨兵位int length = LTTotal(phead);LTNode* cur = phead->next;if (i == 0){return phead;}else if (i<0 || i>length)//位置不合法{return NULL;}else if (i <= (length / 2))//从表头开始遍历{cur = phead->next;for (int count = 1; count < i; count++){cur = cur->next;}}else//从表尾开始遍历{cur = phead->prev;for (int count = 1; count <= length - i; count++){cur = cur->prev;}}return cur;
}在Test.c下
//测试函数
TestList7()
{LTNode* plist = LTInit();LTInsert(plist, 5);LTInsert(plist, 6);LTInsert(plist, 7);LTInsert(plist, 8);LTInsert(plist, 9);LTPrint(plist);LTNode* pos = LTGet(plist,3);if (pos){LTErase(pos);pos = NULL;}LTPrint(plist);
}int main()
{TestList7();return 0;
}双向链表的清空
在List.h下
// 双向链表的清空
void LTClean(LTNode* phead);在List.c下
// 双向链表的清空
void LTClear(LTNode* phead)
{assert(phead);//有哨兵位while (!LTEmpty(phead))//如果不为空就一直头删{LTPopFront(phead);}
}在Test.c下
//测试函数
TestList8()
{LTNode* plist = LTInit();LTInsert(plist, 5);LTInsert(plist, 6);LTInsert(plist, 7);LTInsert(plist, 8);LTInsert(plist, 9);LTPrint(plist);LTClear(plist);LTPrint(plist);
}int main()
{TestList8();return 0;
}总代码(想直接看结果的可以看这里)
在List.h下
#pragma once//使同一个文件不会被包含(include)多次,不必担心宏名冲突//先将可能使用到的头文件写上
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>typedef int LTDataType;//假设结点的数据域类型为 int
//给变量定义一个易于记忆且意义明确的新名字,并且便于以后存储其它类型时方便改动
//(比如我晚点想存double类型的数据,我就直接将 int 改为 double )// 带哨兵位双向循环链表的结构体定义
typedef struct ListNode
{struct ListNode* prev;//前驱指针域:存放上一个结点的地址struct ListNode* next;//后继指针域:存放下一个结点的地址LTDataType data;//数据域
}LTNode;
//struct 关键字和 ListNode 一起构成了这个结构类型
//typedef 为这个结构起了一个别名,叫 LTNode,即:typedef struct ListNode LTNode
//现在就可以像 int 和 double 那样直接使用 LTNode 来定义变量// 双向链表的初始化// 如果是单链表直接给个空指针就行,不需要单独写一个函数进行初始化
// 即:LTNode* plist = NULL;
// 那为什么顺序表、带头双向循环链表有呢?
// 因为顺序表、带头双向循环链表的结构并不简单,
// 如:顺序表顺序表为空size要为0,还要看capacity是否要开空间,
//若不开空间capacity=0,指针要给空,若开空间,还要检查malloc是否成功
// 带头双向循环链表要开个结点,检查malloc是否成功,然后让结点自己指向自己
// 顺序表和双向循环链表的初始化有点复杂,最好构建一个函数
LTNode* LTInit();// 双向链表在pos位置之前进行插入x
void LTInsert(LTNode* pos, LTDataType x);// 双向链表的打印
void LTPrint(LTNode* phead);// 双向链表删除pos位置的结点
void LTErase(LTNode* pos);//双向链表优于单链表的点——不需要找尾、二级指针
// (我们改的不是结构体的指针,改的是结构体的变量)
// 双向链表的尾插
void LTPushBack(LTNode* phead, LTDataType x);// 双向链表的判空
bool LTEmpty(LTNode* phead);// 双向链表的尾删
void LTPopBack(LTNode* phead);// 双向链表头插
void LTPushFront(LTNode* phead, LTDataType x);// 双向链表头删
void LTPopFront(LTNode* phead);// 双向链表查找值为x的结点
LTNode* LTFind(LTNode* phead, LTDataType x);// 双向链表的销毁
void LTDestory(LTNode* phead);// 双向链表的修改,修改pos位置的值为x
void LTModify(LTNode* pos, LTDataType x);// 双向链表删除值为x的结点
void LTRemove(LTNode* phead, LTDataType x);// 双向链表计算结点总数(不计phead)
int LTTotal(LTNode* phead);// 双向链表获取第i位置的结点
LTNode* LTGet(LTNode* phead, int i);// 双向链表的清空
void LTClear(LTNode* phead);在List.c下
#include"List.h"//动态申请一个结点
LTNode* BuyListNode(LTDataType x)
{LTNode* node = (LTNode*)malloc(sizeof(LTNode));if (node == NULL)//如果malloc失败{perror("malloc fail");return NULL;}//如果malloc成功//初始化一下,防止野指针,如果看到返回的是空指针,那逻辑可能有些错误node->next = NULL;node->prev = NULL;node->data = x;return node;
}// 双向链表的初始化
LTNode* LTInit()
{LTNode* phead = BuyListNode(-1);//自己指向自己phead->next = phead;phead->prev = phead;return phead;
}// 双向链表在pos位置之前进行插入x
void LTInsert(LTNode* pos, LTDataType x)
{assert(pos);//pos肯定不为空LTNode* prev = pos->prev;LTNode* newnode = BuyListNode(x);//创建一个需要插入的结点prev->next = newnode;newnode->prev = prev;newnode->next = pos;pos->prev = newnode;
}// 双向链表的打印
void LTPrint(LTNode* phead)
{assert(phead);//有哨兵位printf("<=>phead<=>");LTNode* cur = phead->next;//cur指向第一个要打印的结点while (cur != phead)//cur等于头结点时打印就结束了{printf("%d<=>", cur->data);cur = cur->next;}printf("\n");
}// 双向链表删除pos位置的结点
void LTErase(LTNode* pos)
{assert(pos);//pos肯定不为空LTNode* posprev = pos->prev;LTNode* posnext = pos->next;posprev->next = posnext;posnext->prev = posprev;free(pos);pos = NULL;//这个置空其实已经没有意义了,形参的改变不会改变实参
}// 双向链表的尾插
void LTPushBack(LTNode* phead, LTDataType x)
{assert(phead);//有哨兵位//法一:(便于新手更好地理解双向链表的尾插)//一步就可完成链表为空/不为空的尾插//LTNode* newnode = BuyListNode(x);//LTNode* tail = phead->prev;//tail->next = newnode;//newnode->prev = tail;//newnode->next = phead;//phead->prev = newnode;//法二:函数复用(简单方便)LTInsert(phead, x);
}// 双向链表的判空
bool LTEmpty(LTNode* phead)
{assert(phead);return phead->next == phead;//两者相等就是空链表(返回真),两者不相等就不是空链表(返回假)
}// 双向链表的尾删
void LTPopBack(LTNode* phead)
{assert(phead);//有哨兵位//法一:(便于新手更好地理解双向链表的尾删)//assert(!LTEmpty(phead));//判空//LTNode* tail = phead->prev;//LTNode* tailPrev = tail->prev;//tailPrev->next = phead;//phead->prev = tailPrev;//free(tail);//tail = NULL;//法二:函数复用LTErase(phead->prev);
}// 双向链表头插
void LTPushFront(LTNode* phead, LTDataType x)
{assert(phead);//有哨兵位//LTNode* newnode = BuyListNode(x);//创建一个要插入的结点//法一:只用phead和newnode两个指针(便于新手更好地理解双向链表的头插)//newnode->next = phead->next;//phead->next->prev = newnode;//phead->next = newnode;//newnode->prev = phead;//法二:多用了first先记住第一个结点(便于新手更好地理解双向链表的头插)//LTNode* first = phead->next;//phead->next = newnode;//newnode->prev = phead;//newnode->next = first;//first->prev = newnode;//法三:函数复用(简单方便)LTInsert(phead->next, x);
}// 双向链表头删
void LTPopFront(LTNode* phead)
{assert(phead);//有哨兵位assert(!LTEmpty(phead));//判空//法一:(便于新手更好地理解双向链表的头删)//LTNode* head = phead->next;//LTNode* headnext = head->next;//phead->next = headnext;//headnext->prev = phead;//free(head);//head = NULL;//法二:函数复用(简单方便)LTErase(phead->next);
}// 双向链表查找值为x的结点
LTNode* LTFind(LTNode* phead, LTDataType x)
{assert(phead);//有哨兵位LTNode* cur = phead->next;while (cur != phead)//让cur去遍历{if (cur->data == x){return cur;}cur = cur->next;}return NULL;
}// 双向链表的销毁
void LTDestory(LTNode* phead)
{assert(phead);LTNode* cur = phead->next;while (cur != phead){LTNode* curnext = cur->next;free(cur);cur = curnext;}free(phead);phead = NULL;//这个置空其实已经没有意义了,形参的改变不会改变实参//我们为了保持接口的一致性,不传二级指针,选择在测试的时候置空
}// 双向链表的修改,修改pos位置的值为x
void LTModify(LTNode* pos, LTDataType x)
{assert(pos);//pos肯定不为空pos->data = x;
}// 双向链表删除值为x的结点
void LTRemove(LTNode* phead, LTDataType x)
{assert(phead);//有哨兵位LTNode* pos = phead->next;while (pos != phead){pos = LTFind(phead, x);if (pos == NULL)//如果遍历完{return NULL;}LTErase(pos);pos = pos->next;}
}// 双向链表计算结点总数(不计phead)
int LTTotal(LTNode* phead)
{assert(phead);//有哨兵位int count = 0;//count来计数LTNode* cur = phead->next;//让cur去遍历while (cur != phead){count++;cur = cur->next;}return count;
}// 双向链表获取第i位置的结点
LTNode* LTGet(LTNode* phead, int i)
{assert(phead);//有哨兵位int length = LTTotal(phead);LTNode* cur = phead->next;if (i == 0){return phead;}else if (i<0 || i>length)//位置不合法{return NULL;}else if (i <= (length / 2))//从表头开始遍历{cur = phead->next;for (int count = 1; count < i; count++){cur = cur->next;}}else//从表尾开始遍历{cur = phead->prev;for (int count = 1; count <= length - i; count++){cur = cur->prev;}}return cur;
}// 双向链表的清空
void LTClear(LTNode* phead)
{assert(phead);//有哨兵位while (!LTEmpty(phead))//如果不为空就一直头删{LTPopFront(phead);}
}在Test.c下
#include"List.h"//测试函数
void TestList1()
{LTNode* plist = LTInit();LTInsert(plist, 1);LTInsert(plist, 2);LTInsert(plist, 3);LTInsert(plist, 4);LTPrint(plist);LTErase(plist->next);LTPrint(plist);}//测试函数
void TestList2()
{LTNode* plist = LTInit();LTPushBack(plist, 5);LTPushBack(plist, 6);LTPushBack(plist, 7);LTPushBack(plist, 8);LTPrint(plist);LTPopBack(plist);LTPopBack(plist);LTPrint(plist);}//测试函数
void TestList3()
{LTNode* plist = LTInit();LTPushFront(plist, 1);LTPushFront(plist, 2);LTPushFront(plist, 3);LTPushFront(plist, 4);LTPrint(plist);LTPopFront(plist);LTPopFront(plist);LTPrint(plist);
}//测试函数
TestList4()
{LTNode* plist = LTInit();LTInsert(plist, 1);LTInsert(plist, 2);LTInsert(plist, 3);LTInsert(plist, 4);LTPrint(plist);LTNode* pos = LTFind(plist, 3);if (pos){LTErase(pos);pos = NULL;}LTPrint(plist);LTDestory(plist);plist = NULL;//在这里置空
}//测试函数
TestList5()
{LTNode* plist = LTInit();LTInsert(plist, 1);LTInsert(plist, 2);LTInsert(plist, 3);LTInsert(plist, 4);LTPrint(plist);LTModify(plist->next, 5);LTPrint(plist);}TestList6()
{LTNode* plist = LTInit();LTInsert(plist, 1);LTInsert(plist, 3);LTInsert(plist, 3);LTInsert(plist, 4);LTInsert(plist, 3);LTPrint(plist);LTRemove(plist, 3);LTPrint(plist);printf("%d\n", LTTotal(plist));
}//测试函数
TestList7()
{LTNode* plist = LTInit();LTInsert(plist, 5);LTInsert(plist, 6);LTInsert(plist, 7);LTInsert(plist, 8);LTInsert(plist, 9);LTPrint(plist);LTNode* pos = LTGet(plist, 3);if (pos){LTErase(pos);pos = NULL;}LTPrint(plist);LTClear(plist);LTPrint(plist);
}//测试函数
TestList8()
{LTNode* plist = LTInit();LTInsert(plist, 5);LTInsert(plist, 6);LTInsert(plist, 7);LTInsert(plist, 8);LTInsert(plist, 9);LTPrint(plist);LTClear(plist);LTPrint(plist);
}int main()
{//TestList1();//TestList2();//TestList3();//TestList4();//TestList5();//TestList6();//TestList7();TestList8();return 0;
}欢迎指正❀

相关文章:
双向链表(数据结构)(C语言)
目录 概念 带头双向循环链表的实现 前情提示 双向链表的结构体定义 双向链表的初始化 关于无头单向非循环链表无需初始化函数,顺序表、带头双向循环链表需要的思考 双向链表在pos位置之前插入x 双向链表的打印 双链表删除pos位置的结点 双向链表的尾插 关…...
离线安装Percona
前言 安装还是比较简单,这边简单进行记录一下。 版本差异 一、离线安装Percona 下载percona官网 去下载你需要对应的版本 jemalloc-3.6.0-1.el7.x86_64.rpm 需要单独下载 安装Percona 进入RPM安装文件目录,执行下面的脚本 yum localinstall *.rpm修改…...
界面控件Telerik UI for WinForms使用指南 - 数据绑定 填充(二)
Telerik UI for WinForms拥有适用Windows Forms的110多个令人惊叹的UI控件,所有的UI for WinForms控件都具有完整的主题支持,可以轻松地帮助开发人员在桌面和平板电脑应用程序提供一致美观的下一代用户体验。 Telerik UI for WinForms组件为可视化任何类…...

通过栈/队列/优先级队列/了解容器适配器,仿函数和反向迭代器
文章目录 一.stack二.queue三.deque(双端队列)四.优先级队列优先级队列中的仿函数手搓优先级队列 五.反向迭代器手搓反向迭代器 vector和list我们称为容器,而stack和queue却被称为容器适配器。 这和它们第二个模板参数有关系,可以…...

leetcode 704. 二分查找
题目描述解题思路执行结果 leetcode 704. 二分查找 题目描述 二分查找 给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。 示…...

蓝牙耳机什么牌子好?500内好用的蓝牙耳机推荐
随着蓝牙耳机的受欢迎程度越来越高,近几年来,无蓝牙耳机市场呈爆发式增长,蓝牙耳机品牌也越来越多。那么蓝牙耳机什么牌子好?接下来,我来给大家推荐几款500内好用的蓝牙耳机,一起来看看吧。 一、南卡小音舱…...

设计模式 -- 中介者模式
前言 月是一轮明镜,晶莹剔透,代表着一张白纸(啥也不懂) 央是一片海洋,海乃百川,代表着一块海绵(吸纳万物) 泽是一柄利剑,千锤百炼,代表着千百锤炼(输入输出) 月央泽,学习的一种过程,从白纸->吸收各种知识->不断输入输出变成自己的内容 希望大家一起坚持这个过程,也同…...

人工智能的未来之路:语音识别的应用与挑战
随着人工智能技术的不断发展,语音识别已成为人工智能领域的一个重要应用。语音识别是指通过计算机对语音信号进行处理,将其转换为可以被计算机识别的文本或指令的过程。语音识别技术的应用范围非常广泛,例如智能家居、语音助手、智能客服、智…...

c++ 友元介绍
友元的目的就是让一个函数或类访问另一个函数中的私有成员 友元函数 (1)普通函数作为友元函数 class 类名{friend 函数返回值类型 友元函数名(形参列表);//这个形参一般是此类的对象.... } 经过以上操作后,友元函数就可以访问此类中的私有…...

四维轻云地理空间数据在线管理软件能够在线管理哪些数据?
四维轻云是一款地理空间数据在线管理软件,支持各类地理空间数据的在线管理、浏览及分享,用户可不受时间地点限制,随时随地查看各类地理空间数据。软件还具有项目管理、场景搭建、素材库等功能模块,支持在线协作管理,便…...

学习 GitHub 对我们有什么好处?
学习 GitHub 对我们有什么好处? 为什么要学习 GitHub,或者说学习 GitHub 对我们有什么好处? 理由一:GitHub 上有很多大牛出没,国外的咱先不说,就国内的像百度、腾讯、阿里之类的大公司,里面的很…...

java记录-反射
什么是反射 反射是一种让Java拥有一定动态性的机制,它允许程序在执行期间取得任何类的内部信息,并且直接操作任意对象的内部属性及方法 类加载 类加载后通过堆内存方法区的Class类型对象就能了解该类的结构信息,这个对象就像该类的一面镜子…...

这次彻底不需要账号了,无需魔法永久白嫖GPT
免费GPT 自GPT风靡以来,大家用的是不亦乐乎,你用他去解决过实际问题,你用他去写过代码,你用他去修改过bug,你用他去写过sql,你用他去画过图,你问过他你能想到的任何“刁钻”问题。 你ÿ…...
远程桌面连接是什么?如何开启远程桌面连接详细教程
远程桌面连接是一种非常方便的技术,它允许用户通过互联网在不同的计算机之间共享资源和访问数据。目前这个技术已经广泛地应用于企业、教育、医疗和其他领域,使得人们能够更高效地工作和学习。 这篇文章,我将解释远程桌面连接是什么…...
)
lua实战(2)
目录 值和类型子类型类型字符串type (v) 值和类型 Lua是一种动态类型语言。这意味着变量没有类型;只有价值观才有意义。该语言中没有类型定义。所有值都有自己的类型。 Lua中的所有值都是一等值。这意味着所有的值都可以存储在变量中,作为参数传递给其他函数&…...

UI自动化测试案例——简单的Google搜索测试
以下是一个UI自动化测试的经典案例: import unittest from selenium import webdriverclass GoogleSearchTest(unittest.TestCase):def setUp(self):# 创建Chrome浏览器实例self.driver webdriver.Chrome()self.driver.maximize_window() # 最大化浏览器窗口def t…...
C++之虚函数原理
对象数据和函数的存储方式 注意说的是对象。 C中的对象存储方式是 每个对象占用的存储空间只是该对象的数据部分(虚函数指针和虚基类指针也属于数据部分),函数属于公共部分。 虚函数表 虚函数是通过虚函数表实现的。 C实现虚函数的方法是…...
部署方案)
Windows Information Protection(WIP)部署方案
目录 前言 一、方案准备工作 1、确定哪些数据需要保护 2、选择合适的加密方式...

细说Hibernate的缓存机制
Hibernate 的缓存机制主要包括一级缓存和二级缓存。 1. 一级缓存(Session 缓存): 一级缓存是 Hibernate 的 Session 级别的缓存,与每个 Session 对象相关联。当您通过 Session 对象执行查询、保存或更新操作时,Hibern…...
初识C++之线程库
目录 一、C中的线程使用 二、C的线程安全问题 1. 加锁 2. 变为原子操作 3. 递归里面的锁 4. 定时锁 5. RAII的锁 三、条件变量 1. 为什么需要条件变量 2. 条件变量的使用 2.1 条件变量的相关函数 2.2 wait函数 一、C中的线程使用 线程的概念在linux中的线程栏已经…...

PostgreSQL CASE语句深度解析:性能、类型与NULL安全实战指南
1. 为什么你必须真正吃透 PostgreSQL 的 CASE 语句——它远不止是 SQL 里的“if-else”翻译器在 PostgreSQL 实战中,我见过太多人把CASE当成一个语法糖:写几个WHEN...THEN,加个ELSE,再套个END,就以为搞定了。结果呢&am…...
 —— STM32的SPI外设)
STM32单片机学习(28) —— STM32的SPI外设
文章目录概述SPI通信的移位机制(以bit为单位)SPI外设框图第一部分:数据通路SPI通信的数据帧格式SPI外设移位机制(以字节为单位)第二部分:主机时钟生成器SPI通信时钟频率与传输速率第三部分:主从…...

番茄小说下载器终极指南:三步构建你的离线阅读自由王国
番茄小说下载器终极指南:三步构建你的离线阅读自由王国 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾在地铁里读到精彩章节时突然断网?是否在…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

【DeepSeek事件驱动架构实战指南】:20年架构师亲授5大核心陷阱与避坑清单
更多请点击: https://kaifayun.com 第一章:DeepSeek事件驱动架构全景认知 DeepSeek事件驱动架构(Event-Driven Architecture, EDA)并非单一技术组件的堆叠,而是一种以事件为第一公民、强调松耦合与异步协作的系统设计…...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...

基于MAX78000的医疗紧急呼叫系统:边缘AI与低功耗设计实战
1. 项目概述与核心价值大家好,我是Victor Hugo,一名电子工程师。今天我想和大家分享一个我最近完成并参与设计竞赛的项目:一个基于MAX78000 FTHR开发板的医疗紧急呼叫辅助系统。这个项目的核心,不是从零开始造一个新轮子ÿ…...

基于Arduino与nRF24L01+的无线传感器平台设计与部署指南
1. 项目概述与设计思路如果你和我一样,喜欢在阳台或者小院子里种点蔬菜瓜果,那你肯定也遇到过这样的烦恼:出门几天,心里总惦记着家里的番茄苗是不是缺水了,小温室里的温度会不会太高。传统的温湿度计只能让你在现场读数…...

开源ELM327 OBD-II适配器:从硬件设计到多协议固件实现全解析
1. 项目概述:开源ELM327 OBD适配器如果你对汽车诊断、数据监控或者嵌入式开发感兴趣,那么自己动手做一个OBD-II适配器绝对是个能让你学到很多东西的硬核项目。今天要聊的,就是一个完全开源的、基于NXP LPC1517微控制器的ELM327兼容OBD适配器。…...

3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍
3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在为网易云音乐功能单一而烦恼吗?想要解锁更多个…...