OpenCL使用CL_MEM_USE_HOST_PTR存储器对象属性与存储器映射
随着OpenCL的普及,现在有越来越多的移动设备以及平板、超级本等都支持OpenCL异构计算。而这些设备与桌面计算机、服务器相比而言性能不是占主要因素的,反而能耗更受人关注。因此,这些移动设备上的GPU与CPU基本都是在同一芯片上(SoC),或者GPU就已经成为了处理器的一部分,像Intel Ivy Bridge架构开始的处理器(Intel HD Graphics 4000开始支持OpenCL),AMD APU等。
因此,在这些设备上做OpenCL的异构并行计算的话,我们不需要像桌面端那些独立GPU那样,要把主存数据通过PCIe搬运到GPU端,然后等GPU计算结束后再搬回到主存。我们只需要将给GPU端分配的显存映射到主机端即可。这样,在主机端我们也能直接通过指针来操作这块存储数据。
下面编写了一个比较简单的例子来描述如何使用OpenCL的存储器映射特性。这个例子在MacBook Air,macOS 10.9.2下完成,并通过Xcode 5.1,Apple LLVM 5.1的编译与运行。 硬件环境为:Intel Core i7 4650U, Intel Graphics 5000, 8GB DDR3L, 128GB SSD。
这是主机端代码(C源文件):
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <time.h>#ifdef __APPLE__
#include <OpenCL/opencl.h>
#else
#include <CL/cl.h>
#endifint main(void)
{cl_int ret;cl_platform_id platform_id = NULL;cl_device_id device_id = NULL;cl_context context = NULL;cl_command_queue command_queue = NULL;cl_mem memObj = NULL;char *kernelSource = NULL;cl_program program = NULL;cl_kernel kernel = NULL;int *pHostBuffer = NULL;clGetPlatformIDs(1, &platform_id, NULL);if(platform_id == NULL){puts("Get OpenCL platform failed!");goto FINISH;}clGetDeviceIDs(platform_id, CL_DEVICE_TYPE_GPU, 1, &device_id, NULL);if(device_id == NULL){puts("No GPU available as a compute device!");goto FINISH;}context = clCreateContext(NULL, 1, &device_id, NULL, NULL, &ret);if(context == NULL){puts("Context not established!");goto FINISH;}command_queue = clCreateCommandQueue(context, device_id, 0, &ret);if(command_queue == NULL){puts("Command queue cannot be created!");goto FINISH;}// 指定内核源文件路径const char *pFileName = "/Users/zennychen/Downloads/test.cl";FILE *fp = fopen(pFileName, "r");if (fp == NULL){puts("The specified kernel source file cannot be opened!");goto FINISH;}fseek(fp, 0, SEEK_END);const long kernelLength = ftell(fp);fseek(fp, 0, SEEK_SET);kernelSource = malloc(kernelLength);fread(kernelSource, 1, kernelLength, fp);fclose(fp);program = clCreateProgramWithSource(context, 1, (const char**)&kernelSource, (const size_t*)&kernelLength, &ret);ret = clBuildProgram(program, 1, &device_id, NULL, NULL, NULL);if (ret != CL_SUCCESS){size_t len;char buffer[8 * 1024];printf("Error: Failed to build program executable!\n");clGetProgramBuildInfo(program, device_id, CL_PROGRAM_BUILD_LOG, sizeof(buffer), buffer, &len);printf("%s\n", buffer);goto FINISH;}kernel = clCreateKernel(program, "test", &ret);if(kernel == NULL){puts("Kernel failed to create!");goto FINISH;}const size_t contentLength = sizeof(*pHostBuffer) * 1024 * 1024;// 以下为在主机端分配输入缓存pHostBuffer = malloc(contentLength);// 然后对此工作缓存进行初始化for(int i = 0; i < 1024 * 1024; i++)pHostBuffer[i] = i + 1;// 这里预分配的缓存大小为4MB,第一个参数是读写的memObj = clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_USE_HOST_PTR, contentLength, pHostBuffer, &ret);if(memObj == NULL){puts("Memory object1 failed to create!");goto FINISH;}ret = clSetKernelArg(kernel, 0, sizeof(cl_mem), (void*)&memObj);if(ret != CL_SUCCESS){puts("Set arguments error!");goto FINISH;}// 做存储器映射int *pDeviceBuffer = clEnqueueMapBuffer(command_queue, memObj, CL_TRUE, CL_MAP_READ | CL_MAP_WRITE, 0, contentLength, 0, NULL, NULL, &ret);if(pDeviceBuffer == NULL){puts("Memory map failed!");goto FINISH;}if(pDeviceBuffer != pHostBuffer){// 若从GPU端映射得到的存储器地址与原先主机端的不同,则将数据从主机端传递到GPU端ret = clEnqueueWriteBuffer(command_queue, memObj, CL_TRUE, 0, contentLength, pHostBuffer, 0, NULL, NULL);if(ret != CL_SUCCESS){puts("Data transfer failed");goto FINISH;}/** 如果主机端与设备端地址不同,我们不妨测试一下设备端存储器的Cache情况 */// 先测试主机端的时间int sum = 0;// 先过一遍存储器for(int j = 0; j < 1024; j++)sum += pHostBuffer[j];time_t t1 = time(NULL);for(int i = 0; i < 1000000; i++){for(int j = 0; j < 1024; j++)sum += pHostBuffer[j];}time_t t2 = time(NULL);printf("The host delta time is: %f. The value is: %d\n", difftime(t2, t1), sum);// 测试设备端sum = 0;// 先过一遍存储器for(int j = 0; j < 1024; j++)sum += pDeviceBuffer[j];t1 = time(NULL);for(int i = 0; i < 1000000; i++){for(int j = 0; j < 1024; j++)sum += pDeviceBuffer[j];}t2 = time(NULL);printf("The device delta time is: %f. The value is: %d\n", difftime(t2, t1), sum);}else{// 若主机端与设备端存储器地址相同,我们仅仅做CPU端测试int sum = 0;// 先过一遍存储器for(int j = 0; j < 1024; j++)sum += pHostBuffer[j];time_t t1 = time(NULL);for(int i = 0; i < 1000000; i++){for(int j = 0; j < 1024; j++)sum += pHostBuffer[j];}time_t t2 = time(NULL);printf("The host delta time is: %f. The value is: %d\n", difftime(t2, t1), sum);}// 这里指定将总共有1024 * 1024个work-itemret = clEnqueueNDRangeKernel(command_queue, kernel, 1, NULL, (const size_t[]){1024 * 1024}, NULL, 0, NULL, NULL);// 做次同步,这里偷懒,不用wait event机制了~clFinish(command_queue);// 做校验for(int i = 0; i < 1024 * 1024; i++){if(pDeviceBuffer[i] != (i + 1) * 2){puts("Result error!");break;}}puts("Compute finished!");FINISH:/* Finalization */if(pHostBuffer != NULL)free(pHostBuffer);if(kernelSource != NULL)free(kernelSource);if(memObj != NULL)clReleaseMemObject(memObj);if(kernel != NULL)clReleaseKernel(kernel);if(program != NULL)clReleaseProgram(program);if(command_queue != NULL)clReleaseCommandQueue(command_queue);if(context != NULL)clReleaseContext(context);return 0;
}
以下是OpenCL内核源代码:
kernel void test(__global int *pInOut)
{int index = get_global_id(0);pInOut[index] += pInOut[index];
}
另外,主机端代码部分中,OpenCL源文件路径是写死的。各位朋友可以根据自己环境来重新指定路径。
当然,我们还可以修改主机端 clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_USE_HOST_PTR, contentLength, pHostBuffer, &ret); 这段创建存储器对象的属性。比如,将 CL_MEM_USE_HOST_PTR 去掉。然后可以再试试效果。
倘若 clCreateBuffer 的 flags 参数用的是 CL_MEM_ALLOC_HOST_PTR,那么其 host_ptr 参数必须为空。在调用 clEnqueueMapBuffer 之后,可以根据其返回的缓存地址,对存储区域做数据初始化。
CL_MEM_ALLOC_HOST_PTR 表示应用程序暗示OpenCL实现从主机端可访问的存储空间给设备端分配存储缓存。这个与 CL_MEM_USE_HOST_PTR 还是有所区别的。CL_MEM_USE_HOST_PTR 是完全从应用端当前的内存池分配存储空间;而 CL_MEM_ALLOC_HOST_PTR 对于CPU与GPU共享主存的环境下,可以在CPU端留下一个访问GPU端VRAM的入口点。我们通过以下程序来测试当前环境的OpenCL实现(以下代码在调用调用了 clEnqueueMapBuffer 函数之后做了缓存数据初始化的时间比较):
long deltaTimes[10];for(int i = 0; i < 10; i++){struct timeval tBegin, tEnd;gettimeofday(&tBegin, NULL);for(int i = 0; i < 1024 * 1024; i++)pDeviceBuffer[i] = i + 1;gettimeofday(&tEnd, NULL);deltaTimes[i] = 1000000 * (tEnd.tv_sec - tBegin.tv_sec ) + tEnd.tv_usec - tBegin.tv_usec;}long useTime = deltaTimes[0];for(int i = 1; i < 10; i++){if(useTime > deltaTimes[i])useTime = deltaTimes[i];}printf("Device memory time spent: %ldus\n", useTime);int *pHostBuffer = malloc(contentLength);for(int i = 0; i < 10; i++){struct timeval tBegin, tEnd;gettimeofday(&tBegin, NULL);for(int i = 0; i < 1024 * 1024; i++)pHostBuffer[i] = i + 1;gettimeofday(&tEnd, NULL);deltaTimes[i] = 1000000 * (tEnd.tv_sec - tBegin.tv_sec ) + tEnd.tv_usec - tBegin.tv_usec;}useTime = deltaTimes[0];for(int i = 1; i < 10; i++){if(useTime > deltaTimes[i])useTime = deltaTimes[i];}printf("Host memory time spent: %ldus\n", useTime);
其中,对 gettimeofday 的调用需要包含头文件 <sys/time.h>。这个函数所返回的时间可以精确到 μs(微秒)。
在Intel Core i7 4650U, Intel Graphics 5000环境下,花费时间差不多,都是2.6ms(毫秒)。因此,在内核真正执行的时候为了清空这部分存储空间的Cache,驱动还是要做点工作的。当然,驱动也可为这块内存区域分配 Write-Combined 类型的存储器,这样主机端对这部分数据的访问不会被Cache,尽管速度会慢很多,但是通过 non-temporal Stream 方式读写还是会很不错。况且大部分OpenCL应用对同一块内存数据的读写都只有一次,这么做也不会造成Cache污染。
相关文章:

OpenCL使用CL_MEM_USE_HOST_PTR存储器对象属性与存储器映射
随着OpenCL的普及,现在有越来越多的移动设备以及平板、超级本等都支持OpenCL异构计算。而这些设备与桌面计算机、服务器相比而言性能不是占主要因素的,反而能耗更受人关注。因此,这些移动设备上的GPU与CPU基本都是在同一芯片上(So…...
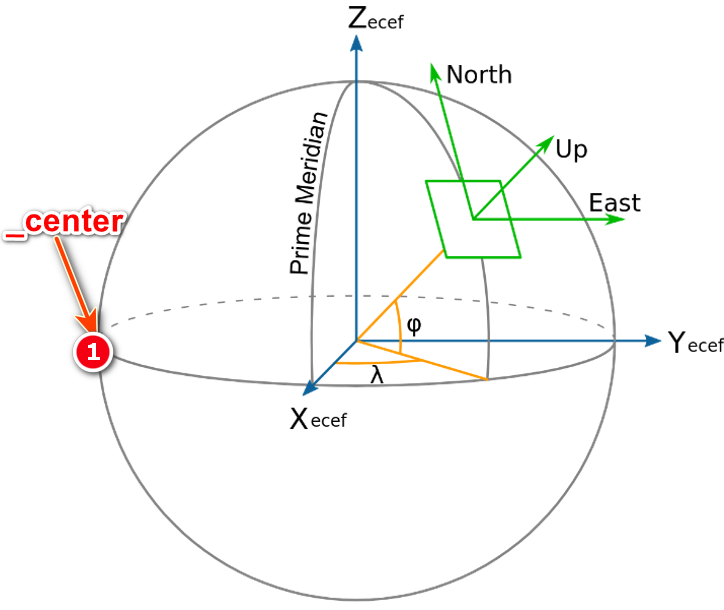
浅谈osgEarth操控器类的createLocalCoordFrame函数如何将局部坐标系的点转为世界坐标系下的Martix(ENU坐标)
在osgEarth操控器类的EarthManipulator中的如下函数: void EarthManipulator::setLookAt(const osg::Vec3d& center,double azim,double pitch,double range,const osg::Vec3d& posOffset) {setCenter( center );.... //…...

PHP程序员和Python程序员的职业前景怎么样?我来聊聊自己的体会
大家好,今天我们来聊一下程序员这个职业的特点。在讲这个话题之前,我先说一下我自己的情况:我在福州和深圳做了8年左右的程序员,然后回到老家,在家里面为福州的一个公司做远程开发。目前已经在老家做了将近3年。 今天…...
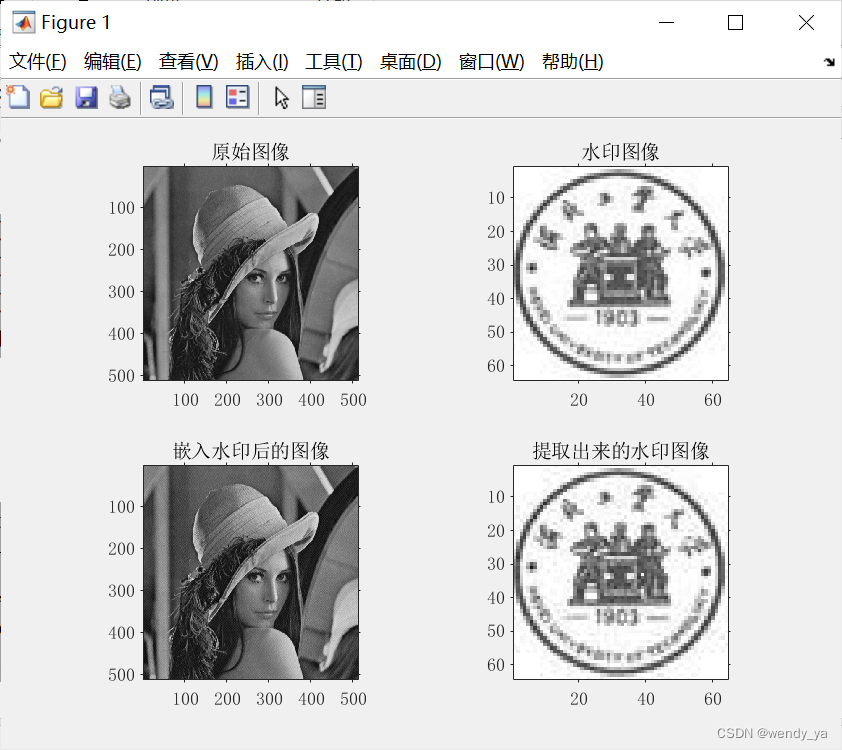
【MATLAB图像处理实用案例详解(8)】—— 图像数字水印算法
目录 一、背景意义二、基本原理三、算法介绍3.1 数字水印嵌入3.2 数字水印提取 四、程序实现 一、背景意义 数字水印技术作为信息隐藏技术的一个重要分支,是将信息(水印)隐藏于数字图像、视频、音频及文本文档等数字媒体中,从而实现隐秘传输、存储、标注…...
最全的免费SSL证书申请方式
在SSL广泛普及的今天,申请一张免费的SSL证书是一件非常容易的事情。这里为大家总结当前阶段(2023年)拥有一张免费SSL证书的方式。首推的方式为来此加密网站,文章后面会有详细的介绍。 下面介绍几种获取免费SSL证书的方式,大家可以根据自己的…...

Ceph入门到精通-CrushMap算法概述
下面是伪代码object到osd的伪代码 locator =object_name obj_hash =hash(locator) pg =obj_hash %num_pg OSDs_for_pg =crush(pg) # returns a list of OSDs primary =osds_for_pg[0] replicas =osds_for_pg[1:] defcrush(pg): all_osds=[osd.0,osd.1,osd.2,...] resu…...
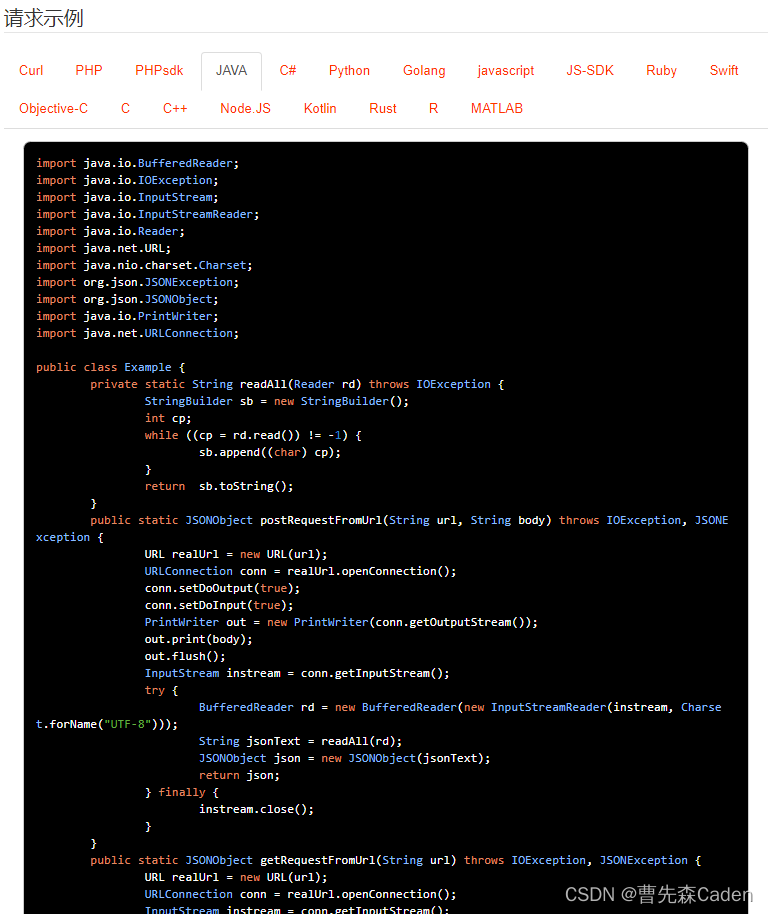
如何利用API做好电商,接口如何凋用关键字
一.随着互联网的快速发展,电子商务成为了众多企业的首选模式,而开放API则成为了电商业务中不可或缺的部分。API(Application Programming Interface),即应用程序接口,是软件系统不同组件之间交互的约定。电…...

Give me a logic game idea about economics
Here’s an logic game idea about economics: Game name: “Economics Tycoon” Game Objective: Build an economic empire and grow from a small business owner to a global tycoon. Gameplay: Start with a small business and limited resources. Manage your compa…...
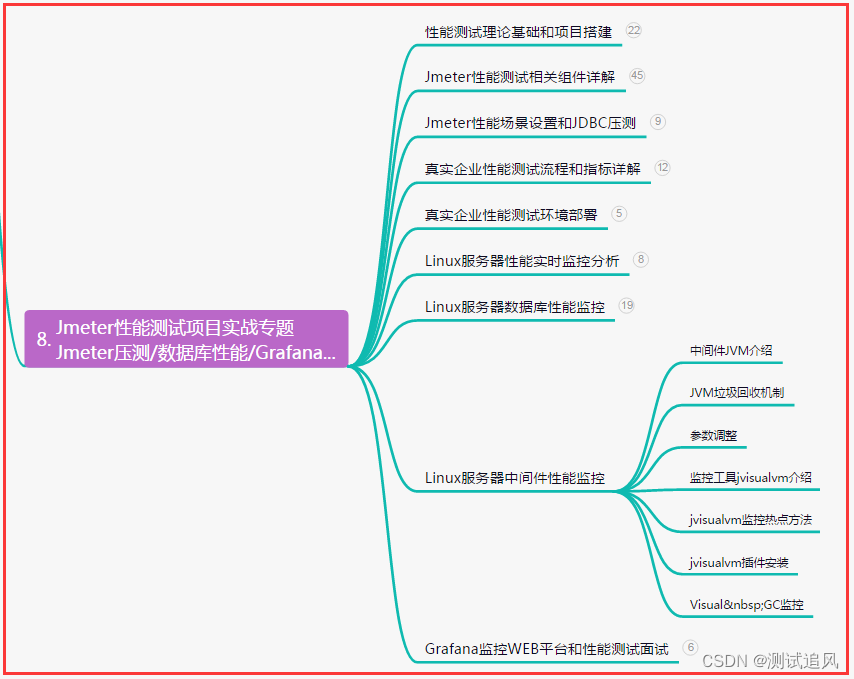
测试之路,2023年软件测试市场领域有哪些变化?突破走得更远...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 Python自动化测试&…...

配置Windows终端直接执行Python脚本,无需输入“python“
配置Windows终端直接执行Python脚本,无需输入"python" 1. 将Python加入环境变量2. 将Python后缀加入环境变量PATHEXT中3. 修改Python脚本的默认打开方式4. *将Python脚本命令加入环境变量*5. 测试 在Linux系统中,在Python脚本的开头指定Python…...

IDEA快捷键
文章目录 快捷键介绍重点掌握CtrlAltShiftCtrl AltCtrl ShiftAlt ShiftCtrl Shift Alt其他 快捷键介绍 重点掌握 psvmmain函数sout输出soutv带变量名输出.sout变量.调用 输出变量值.if布尔值.调用 生成if语句.for数组类型变量.for 生成for语句.var补全接收的变量&#x…...

关于c++指针数组的要设置初值的情况
在大多数情况下,都应该对指针数组进行初始化,以避免出现未知的值和潜在的未定义行为。指针数组在定义时必须指定元素个数,如果未指定元素值,则需要对其进行显式初始化。如果未初始化数组,则未知的值可能指向无效的内存…...

泰克RSA306B频谱分析仪测试信道功率方法
泰克RSA306B实时频谱分析仪是一种用于无线信号分析的仪器。它可以实时监控无线信号的频谱,帮助用户分析信号特征,掌握信号的功率、频率、调制等关键信息。在无线通信中,信道功率是一个非常重要的指标,它反映了信号在传输过程中的强…...
深度学习技巧应用12-神经网络训练中批归一化的应用
大家好,我是微学AI,今天给大家介绍一下深度学习技巧应用12-神经网络训练中批归一化的应用,在深度学习中,批归一化(Batch Normalization,简称BN)是一种重要的技巧,它在许多神经网络中都得到了广泛应用。本文将详细介绍批归一化的原理和应用,并结合PyTorch框架构建一个简…...

Masonry使用以及源码解析(未完待续
文章目录 Masonry使用约束约束优先级 以及 intrinsicContentSize相关问题 Masonry:iOS12Masonry源码解析下面是使用make.width点语法后的全部内部调用过程: Masonry使用 约束 在写Masonry之前,我想先来聊聊约束的基础知识,我们首先要了解一…...
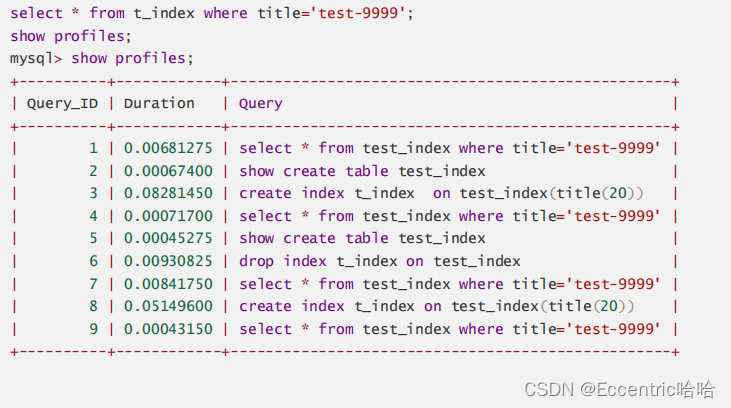
118-Linux_数据库_索引
文章目录 一.索引是什么?二.索引为什么选择b树三.测试索引1.在mysql中创建数据库 test_indexdb2.在test_indexdb中创建表 test_index3.运行程序向表中插入1万条数据,都是字符串4. 查询验证 一.索引是什么? 索引是一种特殊的文件,它包含着对数据表里所…...

macos和windows区别 macos怎么运行windows程序
在我们使用电脑时,重要的是电脑内应用,而系统不过是运行软件的“容器”。日常生活中,我们常见的操作系统是macos和windows,那么macos和windows区别在哪?这两款操作系统的区别很大。macos怎么运行windows程序࿱…...

一起Talk Android吧(第五百四十二回:无进度值ProgressBar)
文章目录 概念介绍使用资源文件实现使用默认设置修改风格使用动画资源 使用代码实现经验总结 各位看官们大家好,上一回中咱们说的例子是"ProgressBar总结",本章回中介绍的例子是" 无进度值ProgressBar"。闲话休提,言归正转…...
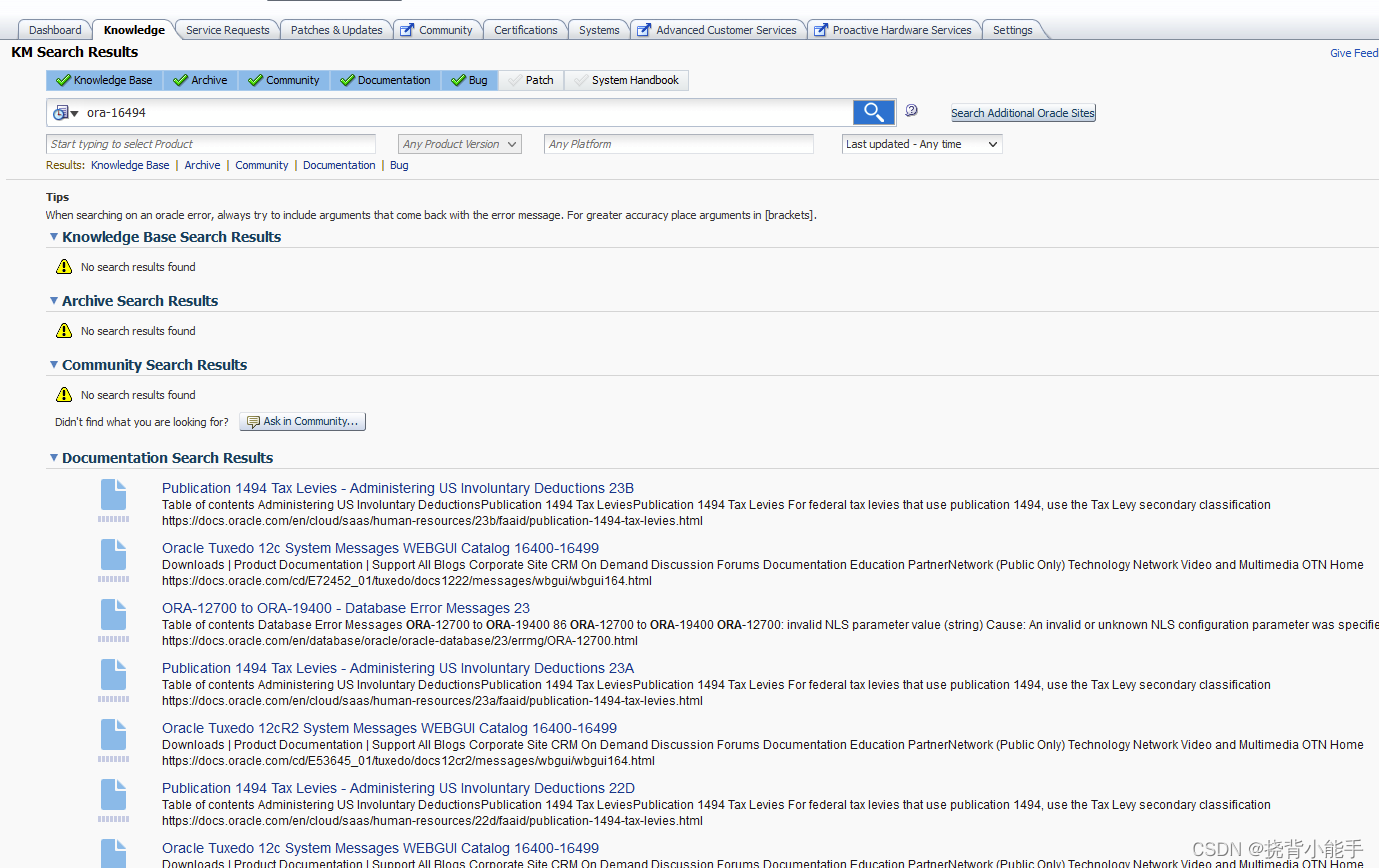
Oracle DataGuard奇怪的ORA-16494错误
Oracle数据库DataGuard数据无法同步,主库查询v$archive_dest出现ORA-16494错误。 数据库版本Oracle 12.1.0.2.0: SQL> select * from v$version;BANNER --------------------------------------------------------------------------------CON_ID --…...

《花雕学AI》Poe 一站式 AI 工具箱:ChatGPT4 体验邀请,亲,不要错过哦!
你有没有想过,如果你能在同一个平台上体验多种不同的 AI 模型,和他们进行有趣、有用、有深度的对话,甚至还能轻松地分享你的对话给其他人,那该有多好?如果你有这样的想法,那么你一定不能错过 Poe 一站式 AI…...

DeepSeek代码质量评估实战手册:7步完成从混沌到可度量的质变跃迁
更多请点击: https://kaifayun.com 第一章:DeepSeek代码质量评估的底层逻辑与核心价值 DeepSeek代码质量评估并非简单地统计行数或检测语法错误,而是基于多维语义理解构建的推理系统。其底层逻辑融合了静态分析、符号执行与大语言模型生成式…...

Win10家庭版别再卡了!保姆级教程:手动修复gpedit.msc路径,彻底关闭Antimalware Service
Win10家庭版性能优化实战:精准修复组策略路径与系统服务调优每次游戏激战正酣时突然卡顿,或是视频渲染到关键时刻系统响应迟缓,很多Win10家庭版用户都遭遇过这类困扰。任务管理器里那个名为"Antimalware Service Executable"的进程…...

Yokogawa AAI835-H50/K4A00模拟输入/输出模块
Yokogawa AAI835-H50/K4A00 模拟输入/输出模块产品特点:通道配置:共8个通道,含4路模拟输入和4路模拟输出。信号类型:所有通道均支持4-20mA标准电流信号。HART通信:支持HART协议,可与智能现场设备双向数字通…...

[智能体-69]:重新认知MCP:协议不生产智能,只是AI全域交互的标准化基石
MCP只是提供了大模型、编排调度、外部工具能够进行结构化交流的标准,而整个系统的智能主要依赖编排调度,与外部软件系统的交互取决于外部工具,包括外部语音交互、视觉交互、数字化交互。当下MCP(Model Context Protocol࿰…...

收藏必看|2026 版大厂 AI 岗位薪资曝光!普通程序员转型大模型最全指南
深夜收到大厂 HR 好友发来的内部资料,再三叮嘱切勿对外泄露。如今网络信息传播速度极快,这份 2026 年企业 AI 岗真实薪资内幕,也值得给广大程序员、零基础入行小白参考借鉴。 翻看完整薪资台账后,真切感受到当下大模型赛道的薪资差…...

Linux服务器被挖矿木马劫持的五步应急处置指南
1. 这不是“中病毒”,是服务器被劫持成了矿机——先别慌,但必须立刻断网“服务器被黑客攻击,用来挖矿!”——这句话在运维圈里一出,比收到OOM告警还让人头皮发紧。它不像网页被挂马、数据库被拖库那样有明显业务影响&a…...
:执行计划教我做事)
开发转兼职DBA(二):执行计划教我做事
开发转兼职DBA(二):执行计划教我做事 查询慢了不知道为什么,加了索引还是慢,复合索引怎么建,执行计划怎么看——这些不是DBA的专利,是每个写SQL的开发者迟早要面对的事。 文章目录 开发转兼职DB…...

GEO生成引擎优化:当AI成为信息分发的主角,品牌如何抢占对话窗口?
当用户不再"搜索-浏览",而是直接"AI提问-获取答案",传统SEO的逻辑正在被彻底改写。2026年,GEO(Generative Engine Optimization,生成式引擎优化)已经从概念走向规模化落地。本文从技术…...

从游戏引擎到仿真平台:手把手教你用AirSim+UE4搭建你的第一个无人机/自动驾驶仿真环境
从游戏引擎到仿真平台:构建AirSimUE4无人机与自动驾驶仿真环境实战指南当游戏引擎遇上机器人算法测试,会碰撞出怎样的火花?微软开源的AirSim项目将虚幻引擎(Unreal Engine)从游戏开发领域引入到自动驾驶和无人机研究的…...

【与我学 ClaudeCode】协作篇 之 Worktree + Task Isolation :目录隔离的并行执行通道
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】协作篇 之 Worktree Task Isolation :目录隔离的并行执行通道》. Le…...