深度学习01-tensorflow开发环境搭建
文章目录
- 简介
- 运行硬件
- cuda和cuddn
- tensorflow安装。
- tensorflow版本
- 安装Anaconda
- 创建python环境
- 安装tensorflow-gpu
- pycharm配置
- 配置conda环境
- 配置juypternotebook
- 安装cuda
- 安装cudnn
- 安装blas
- 云服务器运行
- 云服务器选择
- pycharm配置
- 代码自动同步
- 远程interpreter
简介
TensorFlow是一种端到端开源机器学习平台,它提供了一个全面而灵活的生态系统,包含各种工具、库和社区资源,能够助力研究人员推动先进机器学习技术的发展。在TensorFlow机器学习框架下,开发者能够轻松地构建和部署由机器学习提供支持的应用。[2]
Keras是一个高层次神经网络 API,适用于快速构建原型、高级研究和生产。它作为TensorFlow的一个接口,可以兼容多种深度学习框架。Keras 的核心数据结构是 model,一种组织网络层的方式。最简单的模型是 Sequential 顺序模型,它由多个网络层线性堆叠。对于更复杂的结构,你应该使用 Keras 函数式 API,它允许构建任意的神经网络图。 Keras最开始是为研究人员开发的,其目的在于快速实验,具有相同的代码可以在CPU或GPU上无缝切换运行的特点,同时也具有用户友好的API,方便快速地开发深度学习模型的原型。
Keras使用类sklearn的api接口来调用tensorflow,从sklearn机器学习中切换过来,更加容易上手。
Tenforflow2.0后直接内置可keras。
运行硬件
TensorFlow支持在CPU和GPU上运行。GPU(图形处理单元)是一种专门用于加速计算的硬件,它可以大大提高深度学习模型的训练速度。相对而言,CPU(中央处理器)的每个核心具有更强大的处理能力,但它们的数量通常非常有限,因此在处理大数据时它们表现不佳。
TensorFlow GPU和CPU的主要区别在于如何使用硬件来处理计算任务,以及处理速度的差异。在CPU上,TensorFlow利用所有可用的CPU内核并将任务分配给它们,这可能需要几分钟或几小时来完成。在GPU上,TensorFlow使用CUDA(Compute Unified Device Architecture)技术来利用GPU进行并行计算并加速训练过程,因为GPU拥有数百到数千个小型核心,这比CPU的几十个核心要多得多。这使得TensorFlow能够在GPU上实现更快的训练速度和更高的吞吐量,尤其是在处理大规模的深度学习任务时。
另外需要注意的是,如果你的计算机没有安装专门的GPU,则无法使用TensorFlow GPU。在这种情况下,TensorFlow会使用CPU作为默认选项,但是训练过程会比在GPU上慢得多。因此,如果你需要进行大量的深度学习训练任务,建议使用具有至少一张GPU的计算机来加速训练。
总之,TensorFlow GPU和CPU之间的区别在于它们的硬件架构、并行计算能力以及处理速度等方面。当进行大规模的深度学习训练时,使用GPU可以显著提高训练速度和吞吐量,而对于较小的任务或者没有专门GPU的计算机,则应该使用CPU。
cuda和cuddn
CUDA(Compute Unified Device Architecture)是一种由NVIDIA公司开发的并行计算平台和编程模型,它允许开发人员使用标准C/C++语言编写基于GPU的高性能应用程序。CUDA包括一个可编程的内核语言(CUDA C/C++),一个并行计算库(CUDA Toolkit),以及驱动程序和硬件架构,支持对NVIDIA GPU进行高性能并行计算。与CPU相比,GPU在并行处理任务时的性能要高得多,因此CUDA被广泛用于深度学习、科学计算和高性能计算等领域。[2]
cuDNN(CUDA Deep Neural Network library)是NVIDIA CUDA的一个加速库,它提供了一组高度优化的本地函数,用于加速深度神经网络模型的训练和推理。cuDNN主要用于卷积神经网络(CNNs)和递归神经网络(RNNs)等深度学习模型的优化,从而实现更快的训练和推理速度。cuDNN支持多种深度学习框架,包括TensorFlow,PyTorch和Caffe等。[1]
因此,CUDA是一种GPU计算平台和编程模型,cuDNN是其中一个加速库,专门用于加速深度学习模型的训练和推理。这两个技术结合起来,可以实现对GPU的高性能并行计算和深度学习模型的优化,从而提高深度学习任务的整体性能。
不同的tensorflow版本需要不同的cuda和cuddn版本,google官网可查看
https://tensorflow.google.cn/install/source_windows?hl=en
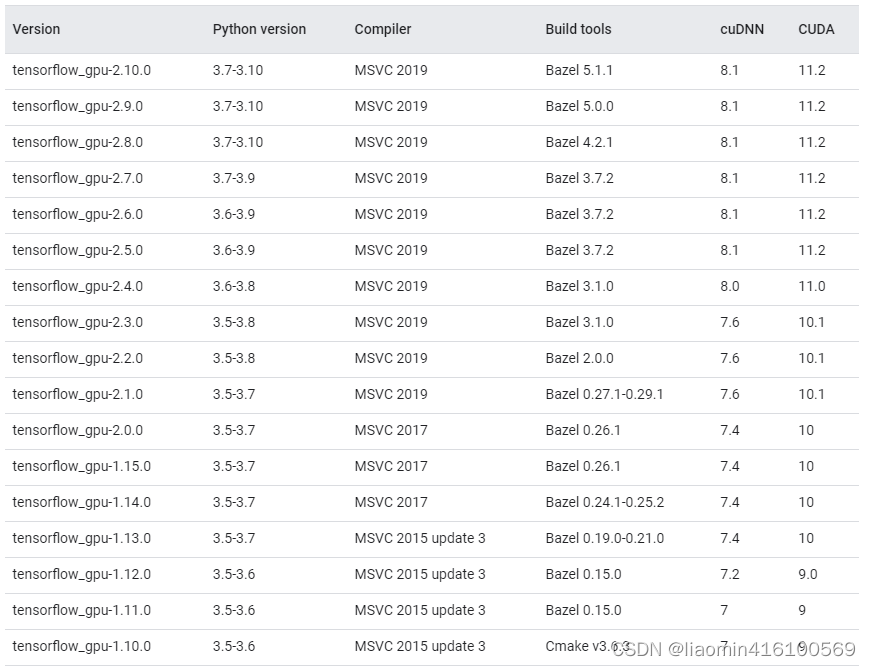
如果电脑有gpu建议安装tensorflow-gpu,如果电脑没有gpu安装性能较差的tensorflow
打开任务管理器-性能,查看你是否支持gpu
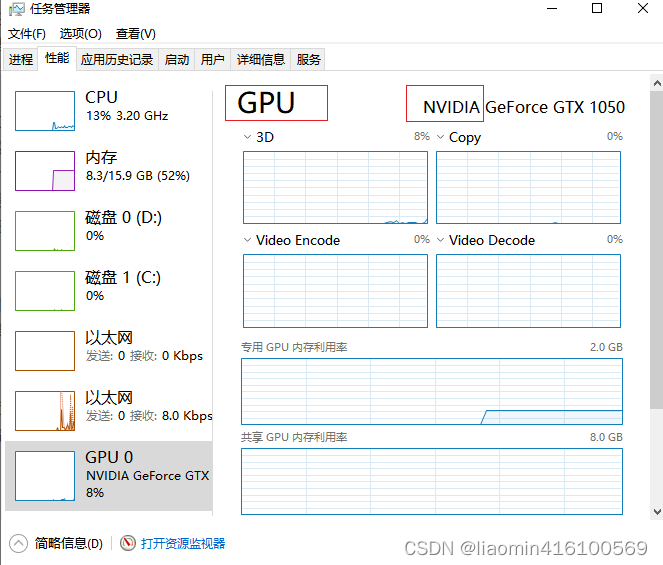
从这里我们可以看到我的cpu是英伟达(nvidia)的gtx1050
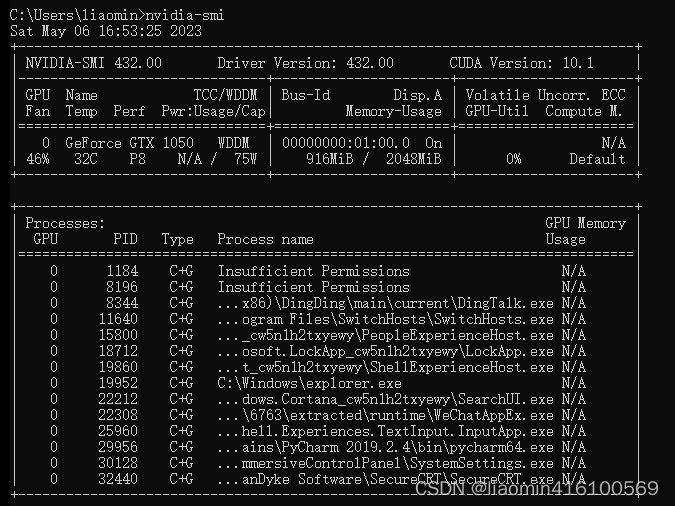
如果电脑已经安装显卡驱动,cuda肯定是自带的,我们可以使用nvidia-smi命令查看
tensorflow安装。
tensorflow版本
tensorflow-gpu需要至少4GB的GPU显存才能运行,并且在训练模型时需要大量的计算资源。而tensorflow-cpu则是专门为CPU设计的版本,能够在CPU上高效地运行,同时不需要GPU显存。一般pc电脑的环境中,建议使用tensorflow-cpu会更加适合。当然,如果你未来有升级GPU的计划,可以考虑使用tensorflow-gpu。
安装Anaconda
首先我们安装Anaconda,教程参考:
打开命令行
同时这里建议使用anaconda的替代方案mamba,因为conda包多了之后安装超级慢,会让你崩溃的,mamba基本匹配pip的速度,官网。
在window上打开powershell,执行web命令下载压缩包
mkdir d:\green\mamba && cd d:\green\mamba
Invoke-Webrequest -URI https://micro.mamba.pm/api/micromamba/win-64/latest -OutFile micromamba.tar.bz2
tar xf micromamba.tar.bz2
比如我的下载这里,直接将解压路径添加到path环境变量中

其他命令就和conda一样了,比如
micromamba env list
micomamba activate base
创建python环境
在其他盘创建一个环境,假设使用python3.7版本
conda create --prefix=d:\condaenv\env_name python=3.7
切换
activate d:\condaenv\env_name
(d:\condaenv\env_name) C:\Users\liaomin>python --version
Python 3.7.4
安装tensorflow-gpu
通过版本关系图
可以确定我们可以使用python3.7版本安装tensorflow-gpu 2.0.0以上所有版本,我们选择一个2.6.0
#设置镜像源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
#安装tensorflow-gpu
conda install tensorflow-gpu==2.6.0
#或者(建议用mamba)
micomamba install tensorflow-gpu==2.6.0
#如果是cpu版本直接
micomamba install tensorflow==2.6.0
安装完成我们先不急着安装cuddn和cuda可以先写个helloworld测试下
pycharm配置
配置conda环境
创建一个项目pure python项目,点击project interpreter 选择Existing interpreter,点击右侧的…
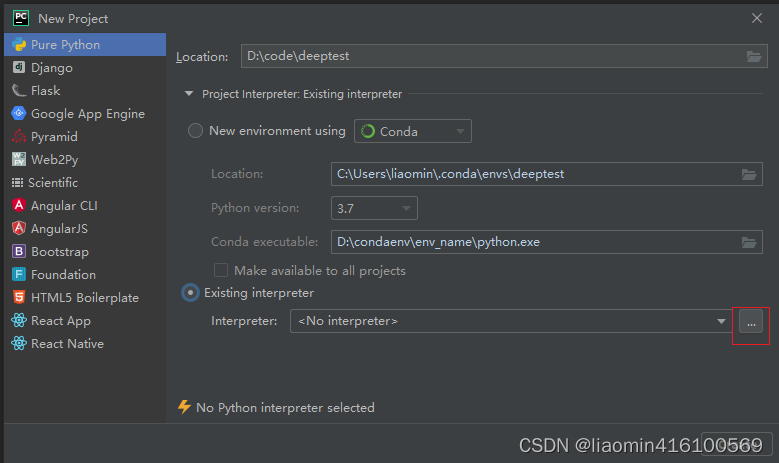
选择conda environment
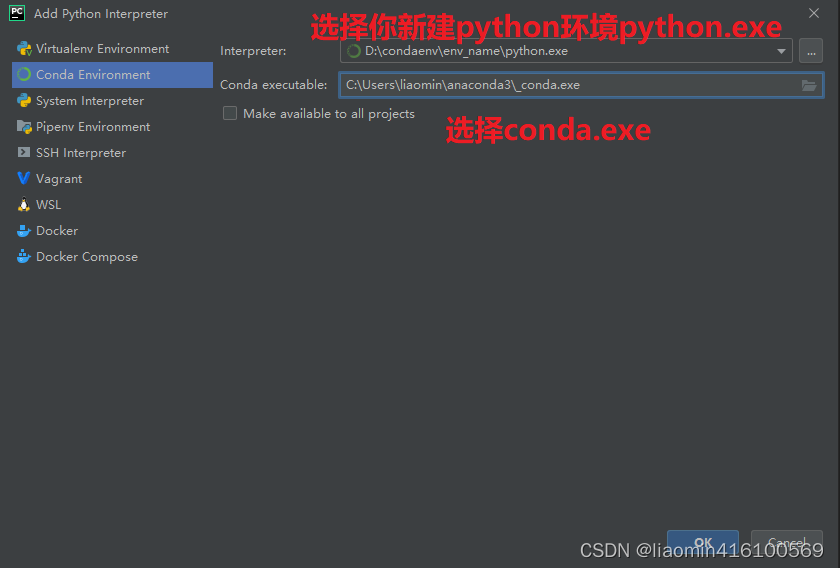
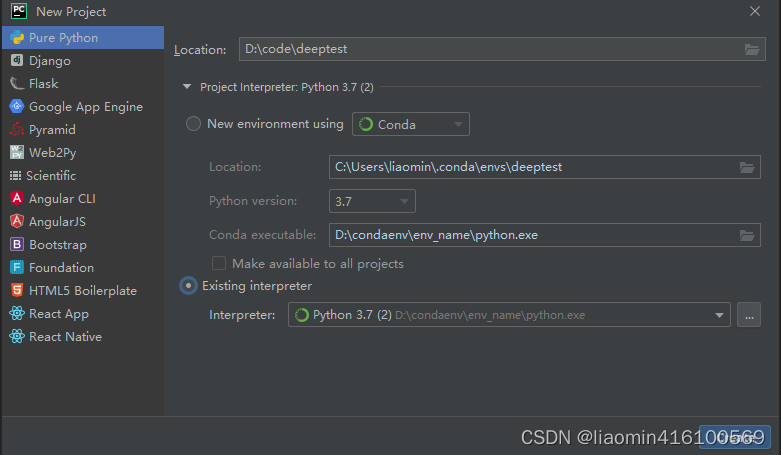
然后点击ok 在interpreter下拉框中选择刚新建的那个
编写一段helloworld代码
import tensorflow as tf# 创建一个常量张量
x = tf.constant([1, 2, 3])# 创建一个变量张量
y = tf.Variable([3, 2, 1])# 计算两个张量的和
z = tf.add(x, y)# 输出结果
print(z.numpy())
运行,虽然能输出结果[4 4 4],但是有红色警告
2023-05-06 16:43:35.610912: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cudart64_110.dll'; dlerror: cudart64_110.dll not found
#下面这段是安装好cuda后报的错。
2023-05-06 17:37:38.727999: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cudnn64_8.dll'; dlerror: cudnn64_8.dll not found
2023-05-06 17:37:38.728345: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1835] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices...
2023-05-06 17:37:38.729310: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
显然缺少cuda和cudnn,注意这里缺少cudart64_110.dll并不是说cuda就是110版本,实际你11.2安装后也是这个dll。
配置juypternotebook
打开anaconda prompt,并且激活你新穿件的环境,安装jupyter
conda install jupyter notebook
#或者(建议用mamba)
micomamba install jupyter notebook
在pycharm中右键创建一个notebook
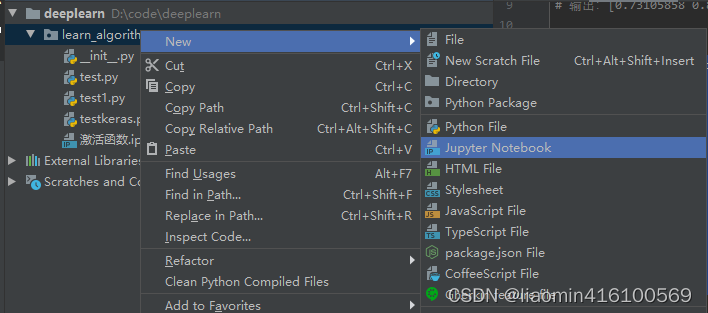
输入之前的helloword代码,选择运行或者调试
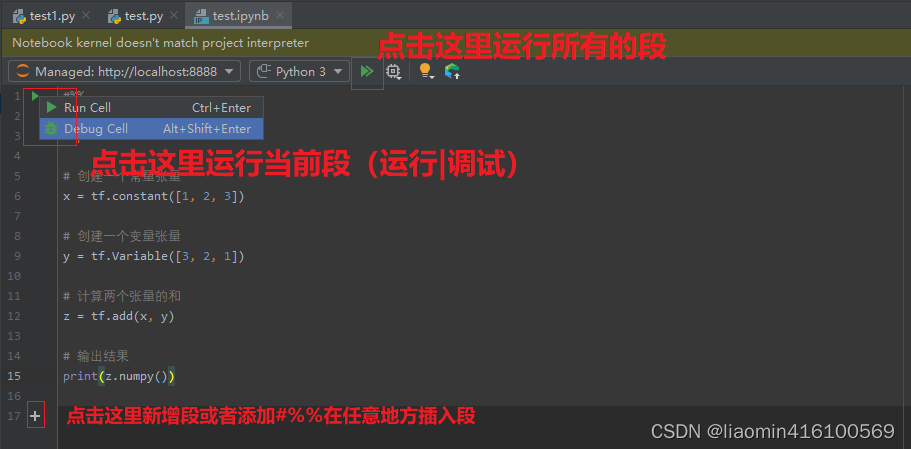
右侧输出结果
安装cuda
通过版本关系图,我们知道tensorflow-gpu 2.6.0需要安装11.2的cuda
如果是cpu版本无需安装
cuda历史版本下载位置,下载对应版本安装
这里有三个版本选择最高的11.2.2

点击进入后 选择window版本
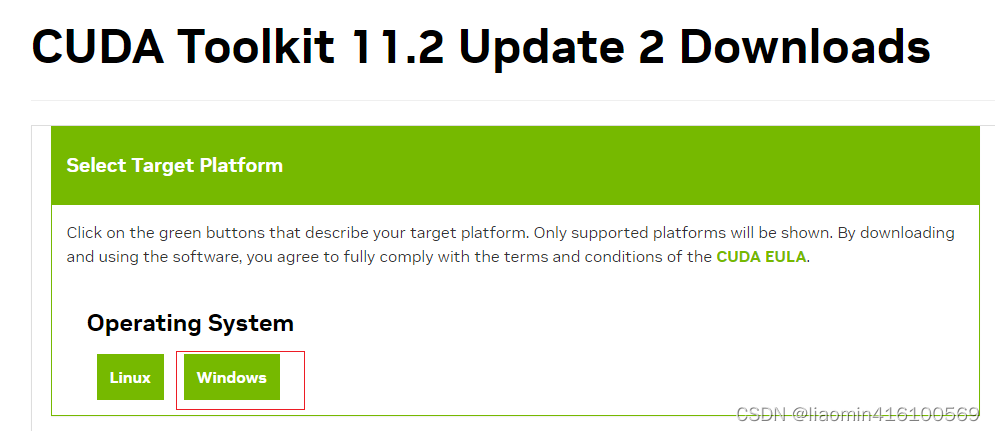
默认安装路径是C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA
打开电脑设置——>系统——>系统高级设置——>环境变量——>系统变量——>PATH
将C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\bin加入到环境变量PATH中
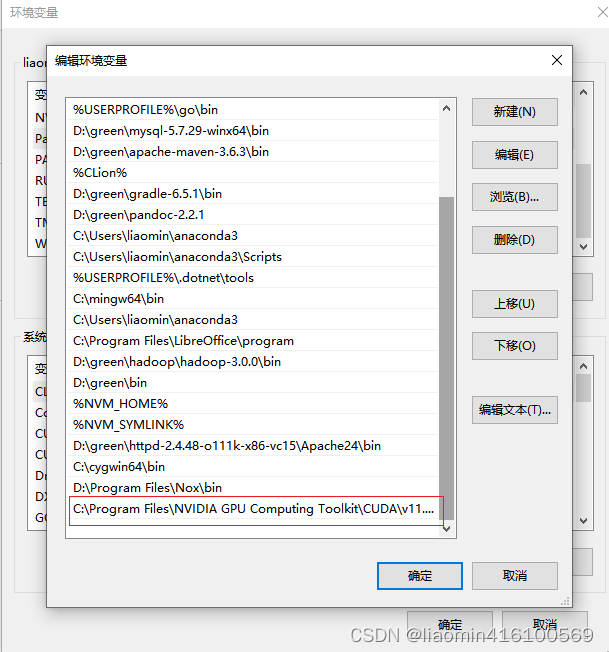
cmd重新执行nvidia-smi,发现版本更新了
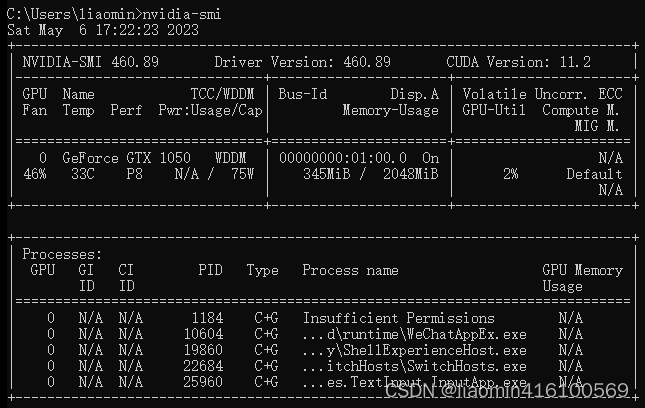
发现之前缺失的cudart64_110.dll确实在C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\bin
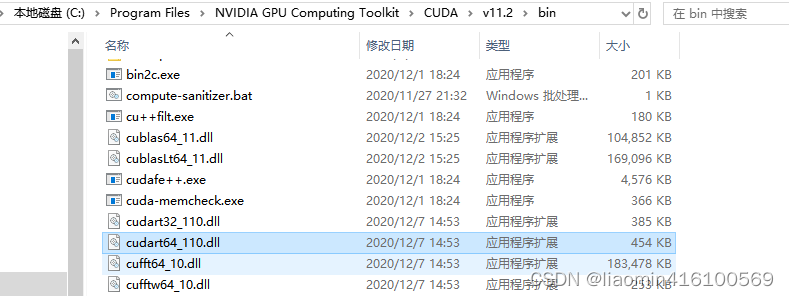
安装cudnn
通过版本关系图,我们知道tensorflow-gpu 2.6.0需要安装8.1的cudnn
cudnn历史版本下载位置,下载对应版本8.1,下载cudnn需要注册nvidia

选择cudnn library for window(x86)点击下载
打开cudnn文件夹
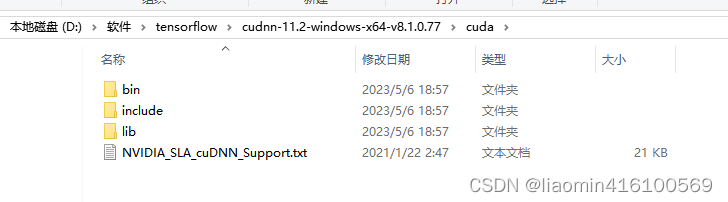
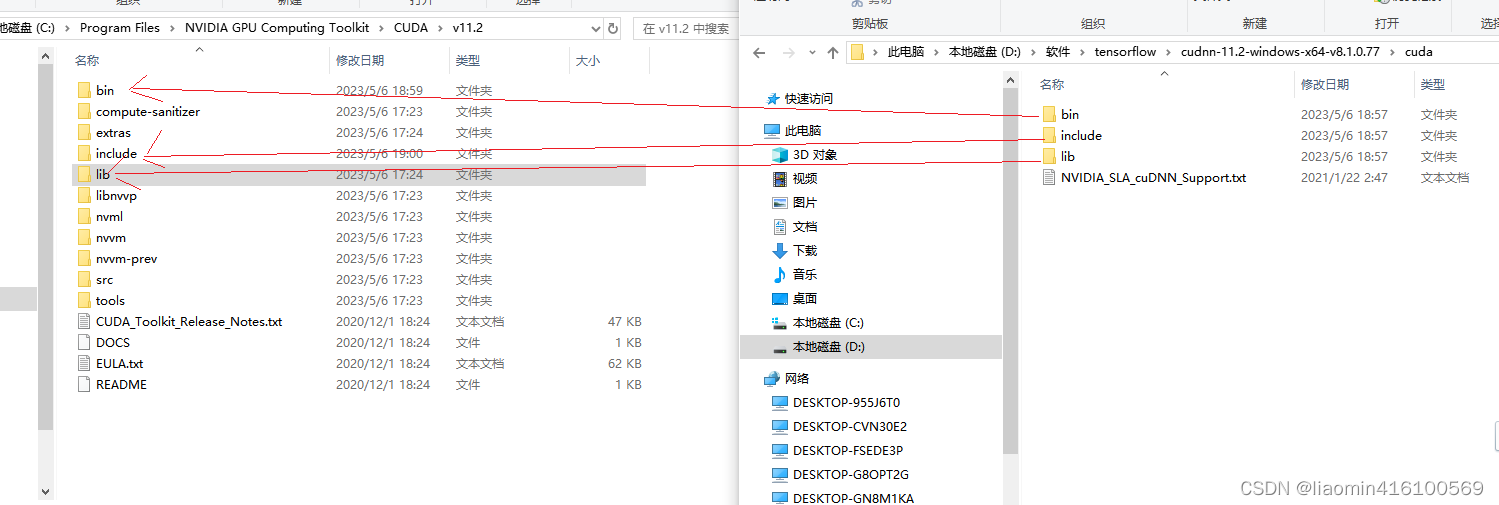
将上述cudnn里面的文件移动或copy到cuda对应文件夹目录下即可!
此时在运行helloworld程序使用gpu正常运行
2023-05-06 19:01:23.403530: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-05-06 19:01:24.075663: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 1320 MB memory: -> device: 0, name: GeForce GTX 1050, pci bus id: 0000:01:00.0, compute capability: 6.1
[4 4 4]
安装blas
TensorFlow 是一个使用 C++ 编写的开源机器学习框架,它支持在 CPU 和 GPU 上运行计算。在 TensorFlow 中,BLAS(Basic Linear Algebra Subprograms)库是用于执行线性代数计算的关键库,例如矩阵乘法和向量加法。由于这些操作在机器学习中非常常见,因此 BLAS 库对于 TensorFlow 的性能和稳定性至关重要。
切换到你的python环境,使用以下命令来安装 BLAS 库:
conda install blas
#或者(建议用mamba)
micomamba install openblas
安装完成后,因为安装的是动态链接库最终仍然会安装在你的anaconda的base环境下,找到动态链接库的位置
C:\Users\你的用户名\anaconda3\pkgs\blas-2.116-blis\Library\bin
将上面的路径添加到环境变量PATH中,如果不添加tensorflow会报错找不到blas
执行以下代码测试
python -c "import tensorflow as tf; print(tf.linalg.matmul(tf.ones([1, 2]), tf.ones([2, 2])))"
运行结果
(d:\condaenv\env_name) C:\Users\liaomin>python -c "import tensorflow as tf; print(tf.linalg.matmul(tf.ones([1, 2]), tf.ones([2, 2])))"
2023-05-10 09:39:23.654612: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-05-10 09:39:24.372107: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 1320 MB memory: -> device: 0, name: GeForce GTX 1050, pci bus id: 0000:01:00.0, compute capability: 6.1
tf.Tensor([[2. 2.]], shape=(1, 2), dtype=float32)
云服务器运行
云服务器提供高性能的CPU和GPU运算服务器,对个人开发者来说非常便宜一般几十块钱半个月的秒杀团很多,可以提供强大的计算能力。对于需要大量计算资源的TensorFlow程序,使用腾讯云服务器可以提高计算效率
云服务器选择
我这里选择腾讯云,对个人友好,可以微信登录,微信支付。
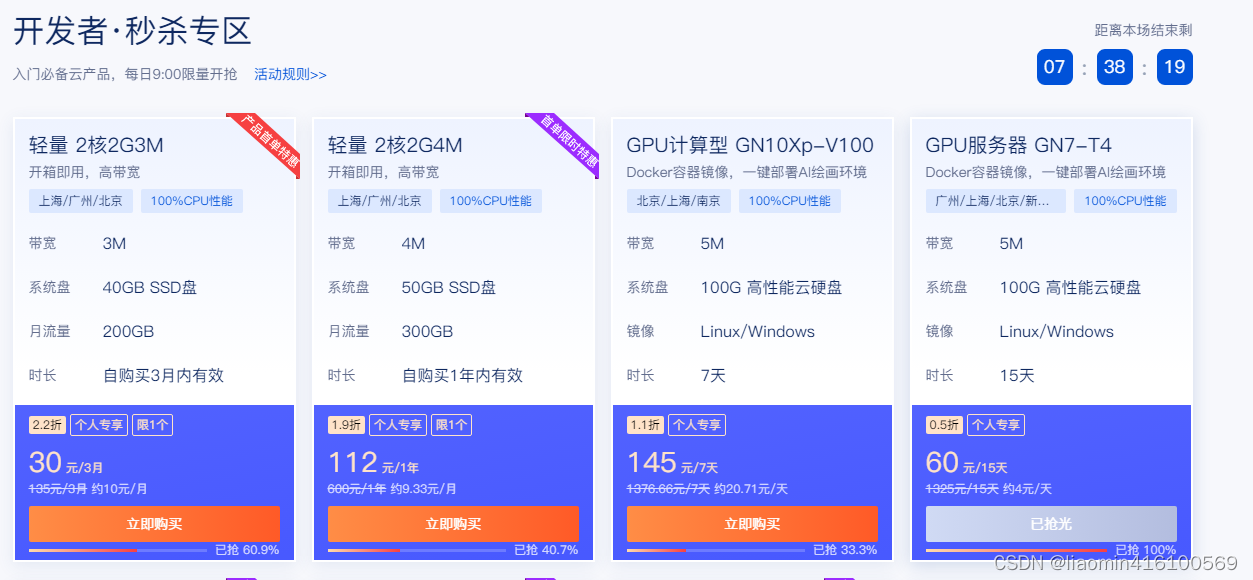
右侧的gpu服务器是gpu 8gb的适合个人学习来跑神经网络。
购买的时候选择系统为:unbuntu的tensorflow版本,我选择的是:TensorFlow 2.8.0 Ubuntu 18.04 GPU基础镜像(预装460驱动),不要选window自己安装环境,麻烦,因为我们的pycharm支持远程ssh编程,用服务器跑,结果显示在pycharm中。
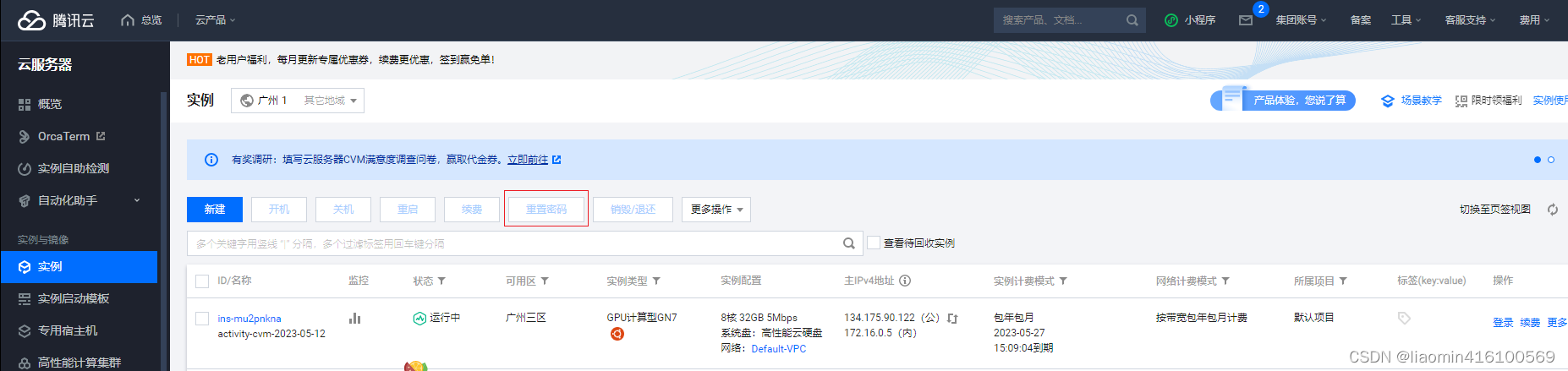
重置你的ubuntu密码(系统默认的账号是ubuntu,不是root),主机会给你配个公网地址

pycharm配置
代码自动同步
我们在/homt/ubuntu用户目录下新建一个deeplearn目录用于映射本地代码
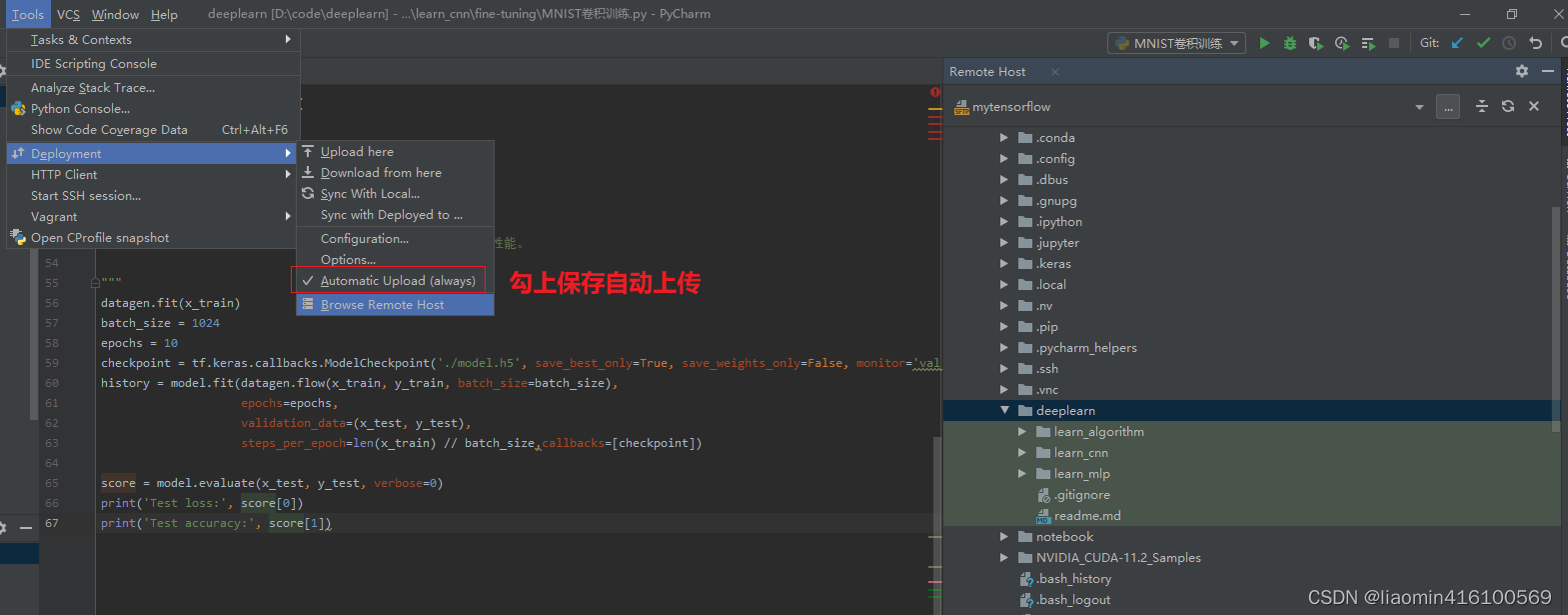
点击tools-deployment-configuation
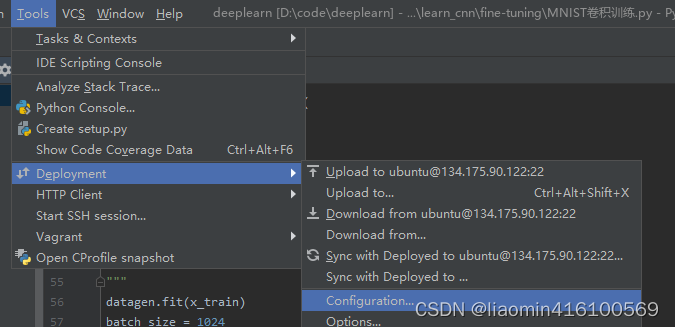
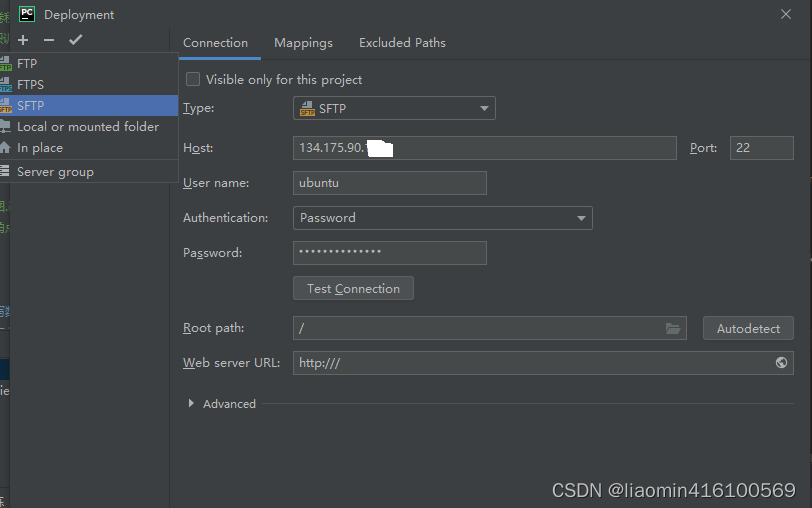
选择sftp,输入账号密码测试连接
点击mappings目录映射本地目录和远程目录
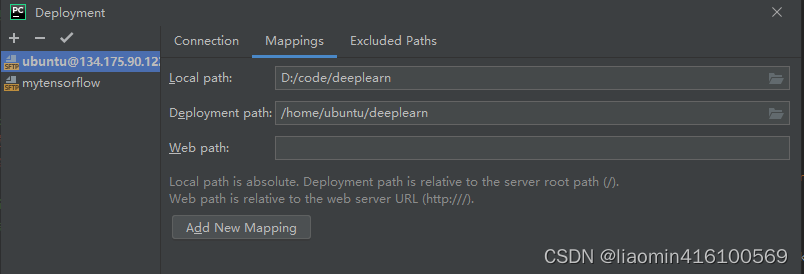
确定后在享有右键deployments->upload 上传代码
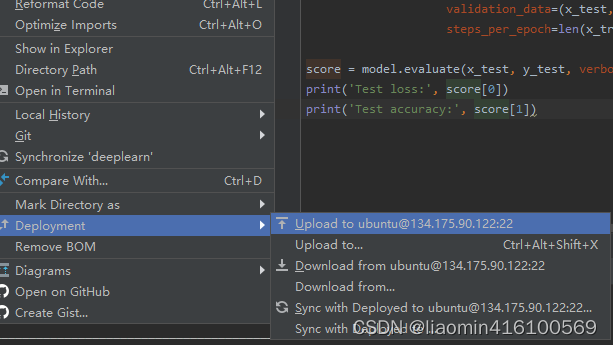
点击tools-deployments-browe remote host查看远程目录是否上传(勾上Automatic upload(always)保存代码自动上传)
远程interpreter
点击File-Settings-Project(项目名)-Project interpreter add一个
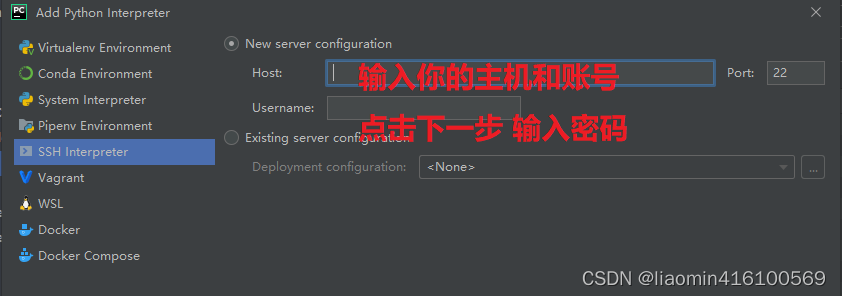
输入密码后下一步进入配置python目录,我们可以使用shell登录到远程服务器执行
ubuntu@VM-0-5-ubuntu:~$ which python3
/usr/local/miniconda3/bin//python3
在interpreter上输入python3的路径即可
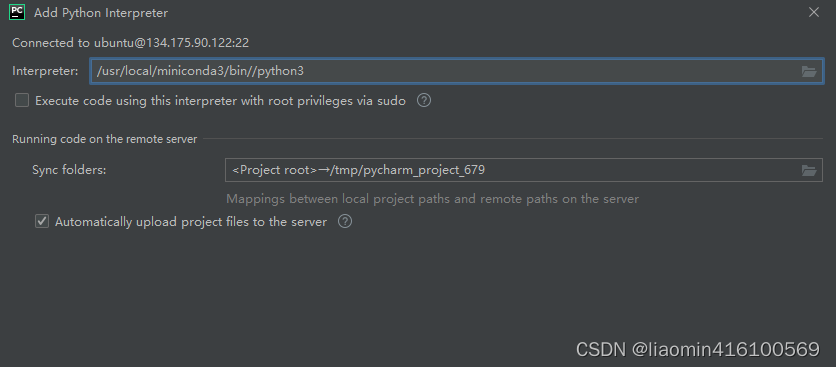
确认项目选择了该interpreter
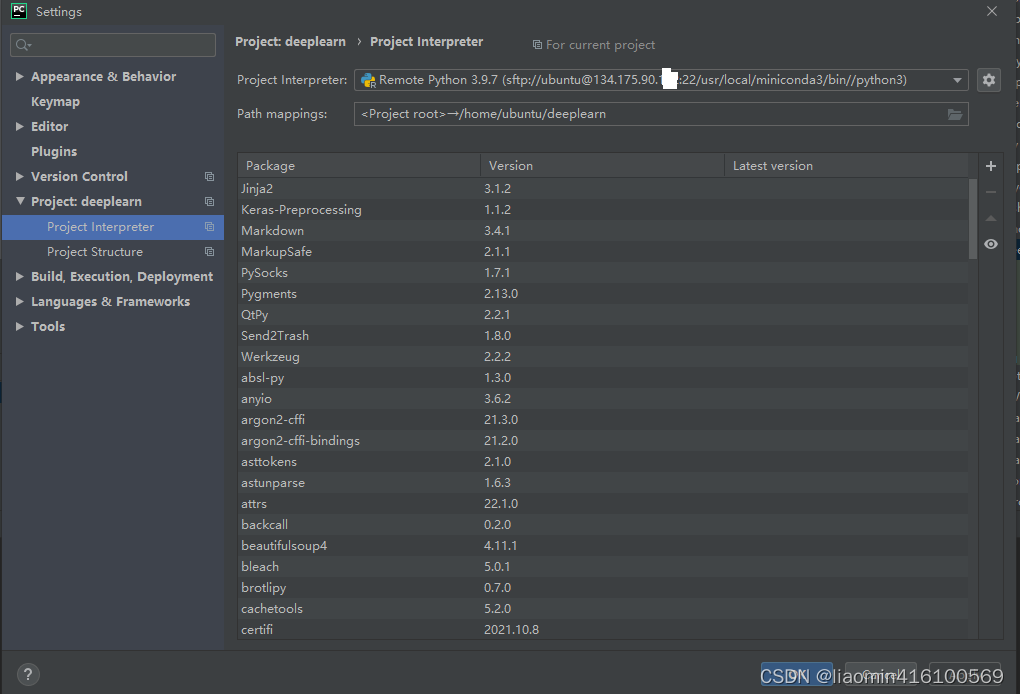
接下来打开神经网络代码,,代码右键运行,可看到运行是ssh运行的
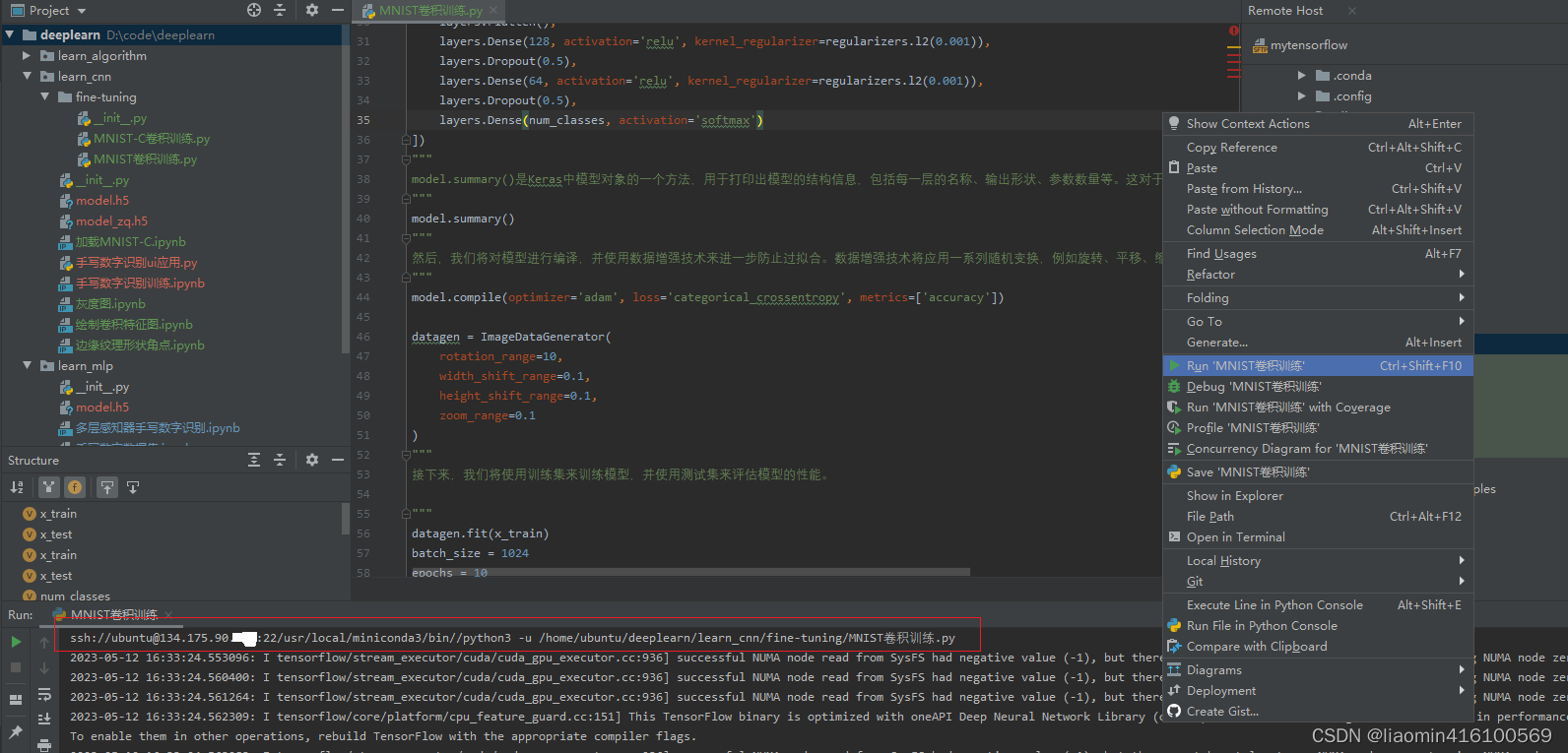
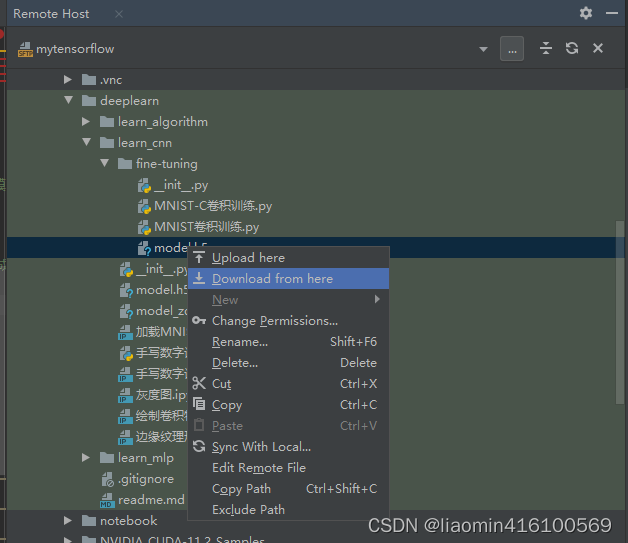
执行后的模型实际上是在远程服务器的可以使用brwoer remote host右键下载下来覆盖本地
相关文章:
深度学习01-tensorflow开发环境搭建
文章目录 简介运行硬件cuda和cuddntensorflow安装。tensorflow版本安装Anaconda创建python环境安装tensorflow-gpupycharm配置配置conda环境配置juypternotebook 安装cuda安装cudnn安装blas 云服务器运行云服务器选择pycharm配置代码自动同步远程interpreter 简介 TensorFlow是…...

linux相关操作
1 系统调用 通过strace直接看程序运行过程中的系统调用情况 其中每一行为一个systemcall ,调用write系统调用将内容最终输出。 无论什么编程语言都必须通过系统调用向内核发起请求。 sar查看进程分别在用户模式和内核模式下的运行时间占比情况, ALL显…...
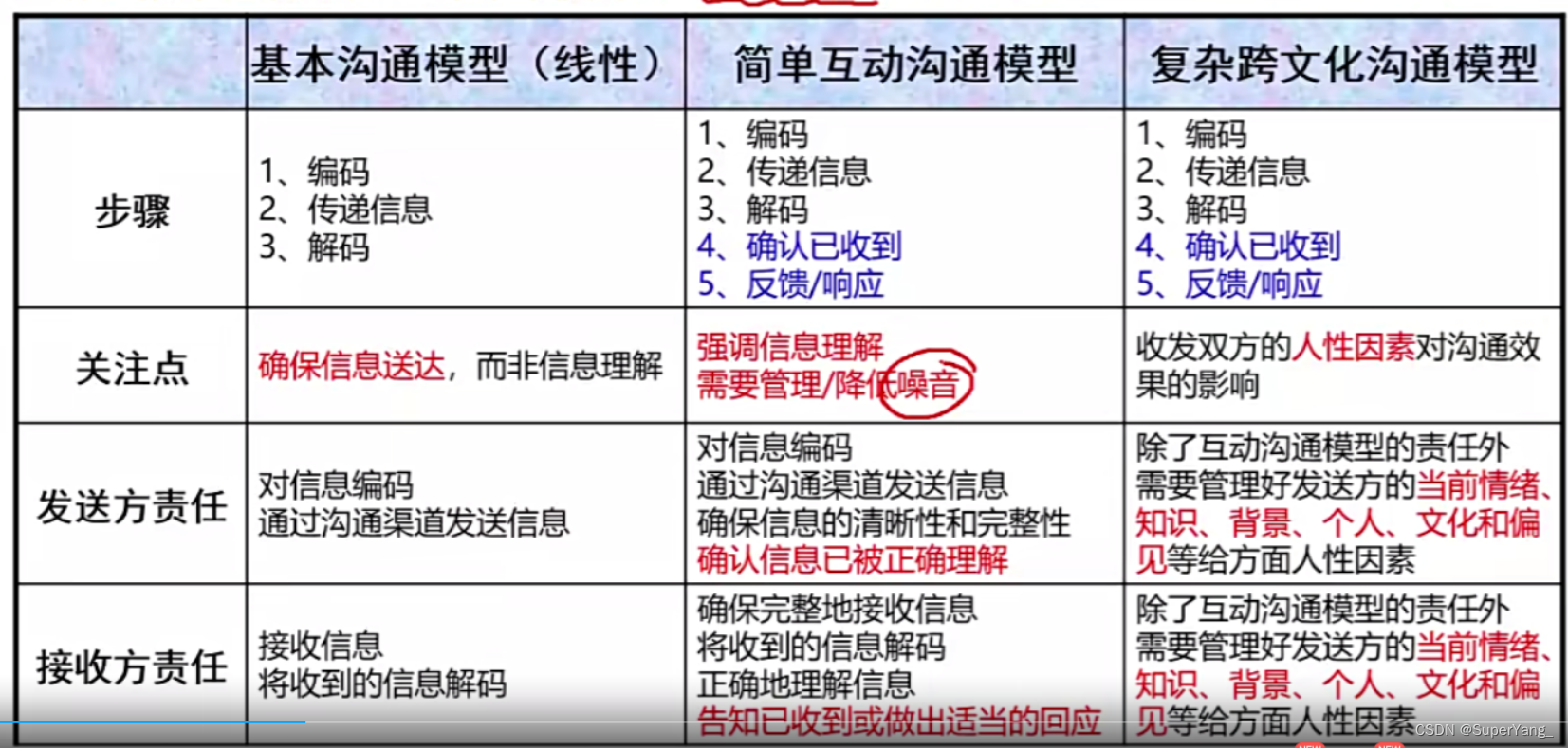
PMP项目管理-[第十章]沟通管理
沟通管理知识体系: 规划沟通管理: 10.1 沟通维度划分 10.2 核心概念 定义:通过沟通活动(如会议和演讲),或以工件的方式(如电子邮件、社交媒体、项目报告或项目文档)等各种可能的方式来发送或接受消息 在项目沟通中,需要…...
13个UI设计软件,一次满足你的UI设计需求
UI设计师的角色是当今互联网时代非常重要的一部分。许多计算机和移动软件都需要UI设计师的参与,这个过程复杂而乏味。这里将与您分享13个UI设计软件,希望帮助您正确选择UI设计软件,节省工作量,创建更多优秀的UI设计作品。 1.即时…...
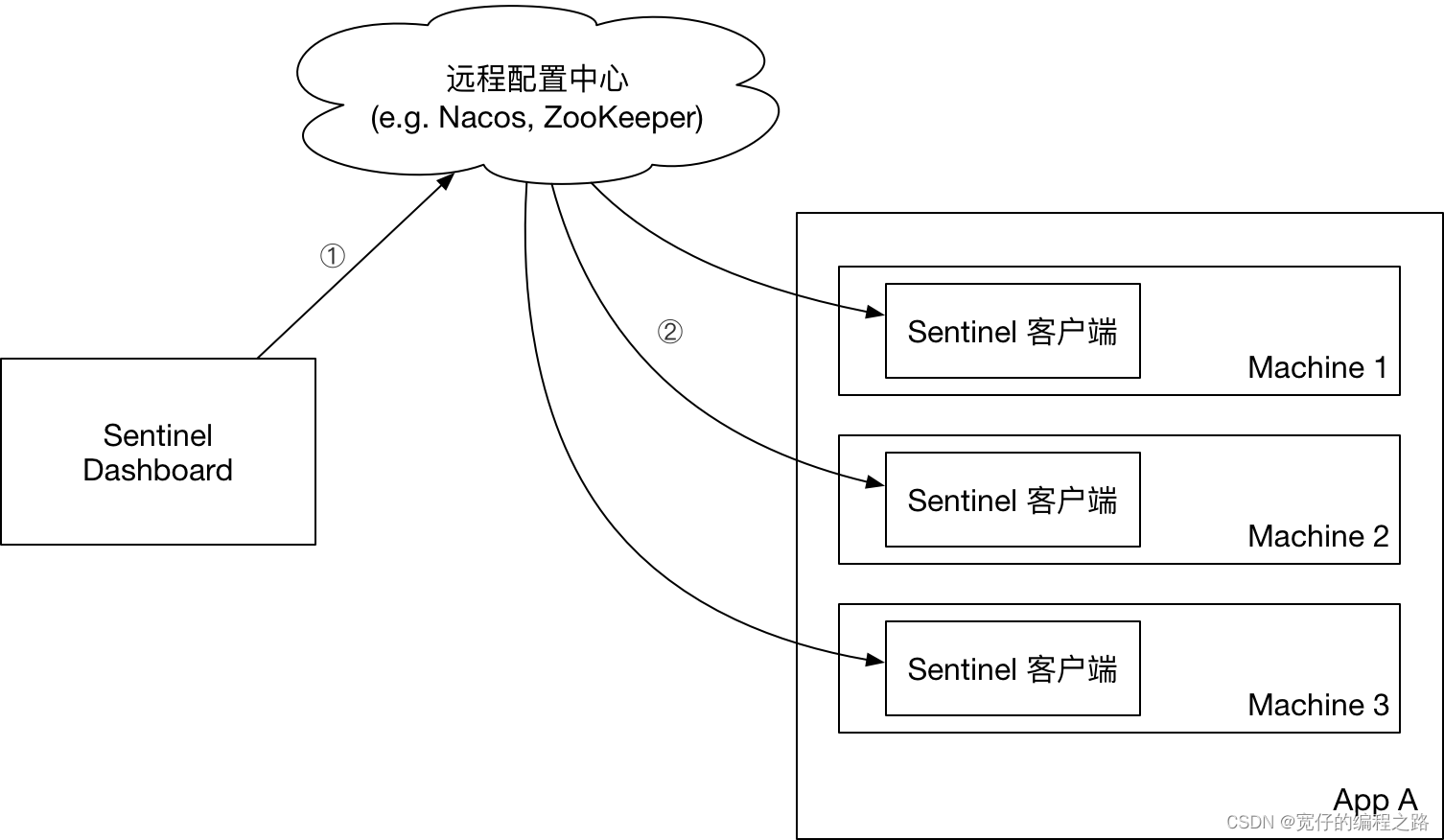
sentinel介绍
介绍 官网地址 Sentinel 和 Hystrix 的原则是一致的: 当调用链路中某个资源出现不稳定,例如,表现为 timeout,异常比例升高的时候,则对这个资源的调用进行限制,并让请求快速失败,避免影响到其它的资源&…...
手把手教你怎么搭建自己的ChatGPT和Midjourney绘图(含源码)
AI程序采用NUXT3LARAVEL9开发(目前版本V1.1.7) 授权方式:三个顶级域名两次更换 1.AI智能对话-对接官方和官方反代(markdown输出)PS:采用百度与自用库检测文字 2.AI绘图-根据关键词绘图-增加dreamStudio绘画-增加mid…...

继承多态经典笔试题
注:visual studio复制当前行粘贴到下一行: CTRLD 杂项 调用子类重写的虚函数(带默认参数),但参数用的是基类的虚函数中的默认参数: 这是由于参数是在编译时压入 试题一 交换两个基类指针指向的对象的vf…...

如何使用Typeface-Helper-自定义字体
随着科技的不断发展,人们对于视觉效果的要求也越来越高。在设计领域中,字体设计是非常重要的一环,因为它直接影响了整个设计的风格和品质。因此,越来越多的设计师开始寻找能够帮助他们自定义字体的工具。在这个过程中,…...

SubMain CodeIt.Right 2022.2 Crack
CodeIt.Right,从源头上提高产品质量,在编写代码时获取有关问题的实时反馈,支持最佳实践和合规性,自动执行代码审查,轻松避免与您的群组无关的通知,一目了然地了解代码库的运行状况 自动执行代码审查 使用自…...
)
文艺复兴的核心是“以人为本”:圣母百花大教堂(Duomo)
文章目录 引言I 圣母百花大教堂的建筑技术故事1.1 布鲁内莱斯基1.2 表现三维立体的透视画法II 美第奇家族的贡献2.1 科西莫德美第奇2.2 洛伦佐美第奇III 历史中的偶然性与必然性。3.1 文艺复兴的诞生其实是必然的事情3.2 文艺复兴的偶然性引言 从科技的视角再次理解文艺复兴,…...

校招失败后,在小公司熬了 2 年终于进了百度,竭尽全力....
其实两年前校招的时候就往百度投了一次简历,结果很明显凉了,随后这个理想就被暂时放下了,但是这个种子一直埋在心里这两年除了工作以外,也会坚持写博客,也因此结识了很多优秀的小伙伴,从他们身上学到了特别…...

【C++学习】函数模板
模板的概念 模板就是建立通用的模具,大大提高复用性。 模板的特点: 模板不可以直接使用,它只是一个模型 模板的通用不是万能的 基本语法 C中提供两种模板机制:函数模板和类模板 函数模板作用: 建立一个通用函数&…...
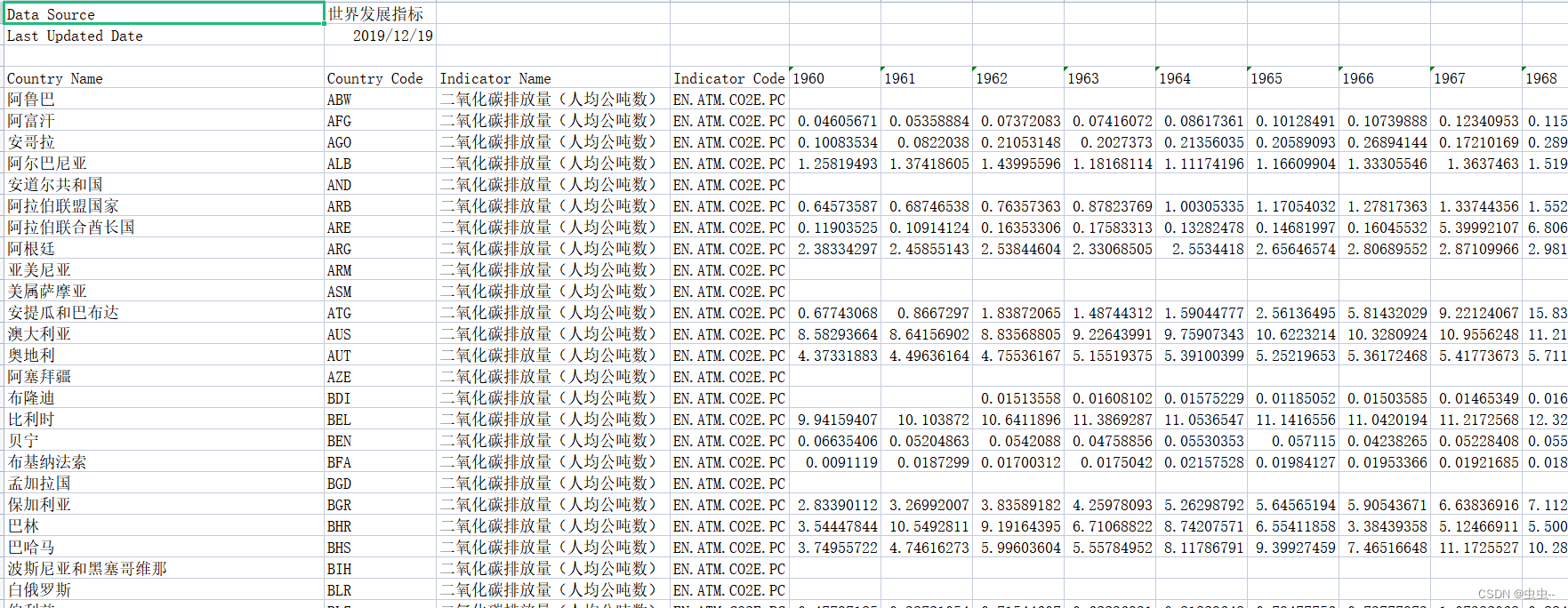
1960-2014年各国二氧化碳排放量(人均公吨数)
1960-2014年各国二氧化碳排放量(人均公吨数)(世界发展指标, 2019年12月更新) 1、来源:世界发展指标 2、时间:1960-2014年 3、范围:世界各国 4、指标: 二氧…...

【java-04】深入浅出多态、内部类、常用API
主要内容 多态 内部类 常用API 1 多态 1.1 面向对象三大特征 ? 封装 , 继承 , 多态 1.2 什么是多态 ? 一个对象在不同时刻体现出来的不同形态 举例 : 一只猫对象 我们可以说猫就是猫 : Cat cat new Cat();我们也可以说猫是动物 : Animal cat new Cat();这里对象在不…...

【逐函数详细讲解ORB_SLAM2算法和C++代码|Viewer|1-26】
Viewer类的主要目的是实现ORB-SLAM2算法的可视化部分,帮助用户更好地理解算法的运行过程和结果。为此,Viewer类与其他类(如System、FrameDrawer、MapDrawer和Tracking)协同工作,根据摄像机的帧率实时更新可视化界面。 在Viewer类中,有一些成员变量和成员函数。 成员变量…...

【C语言】测试2 C程序设计初步
以下能正确定义整型变量 a,b 和 c,并对它们赋初值为5的语句是( )。 A. int a=b=c=5; B. int a, b, c=5; C. int a=5, b=5, c=5; D. a=b=c=5; 正确答案: C 当输入数据的形式为:25,13,10<回车 >时,以下程序的输出结果为( )。 main() {int x,y,z; scanf(“ %…...

SpringBoot3 integrate SpringDoc
SpringDoc 官方文档 Springdoc3取代swagger2 pom xml加载Springdoc JarOpenAPIDefinition,声明一个OpenAPI对API进行分组,方便查询访问地址springdoc ConfigurationRequestMapping pom xml加载Springdoc Jar <dependency><groupId>org.sprin…...

一文解决Xshell无法连接vmware上的centos
问题描述 win10系统上安装VMware workstation16 pro,装好后安装centos虚拟机,在设置network & hostname时选择的NAT模式,即使用自定义的网关和IPv4地址,最后配置完成后centos主机地址信息如下,在虚拟机内部进行pi…...
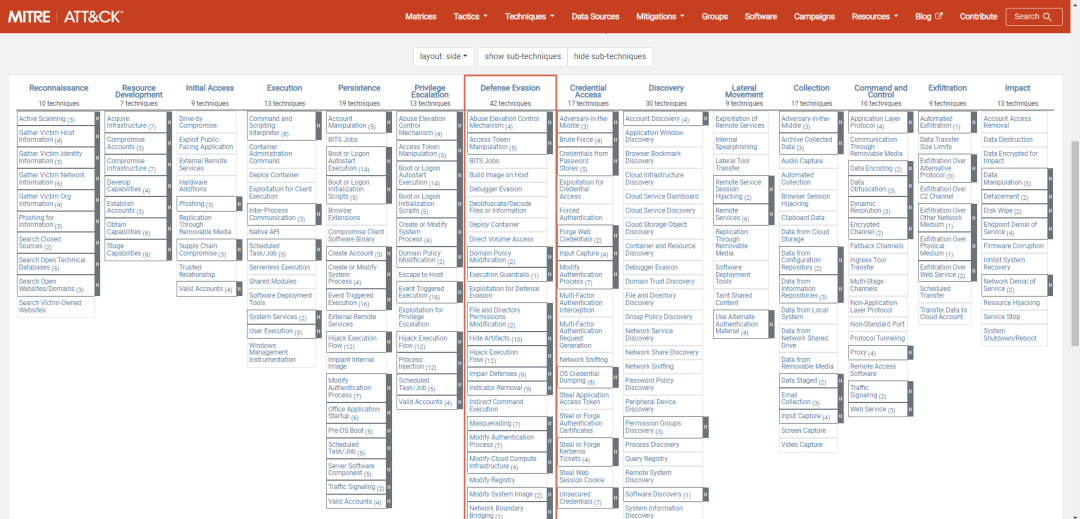
ATTCK v13版本战术介绍——防御规避(五)
一、引言 在前几期文章中我们介绍了ATT&CK中侦察、资源开发、初始访问、执行、持久化、提权战术理论知识及实战研究、部分防御规避战术,本期我们为大家介绍ATT&CK 14项战术中防御规避战术第25-30种子技术,后续会介绍防御规避其他子技术…...

祁宁:社区问答是激荡企业高级智慧的头脑风暴 | 开发者说
在祁宁家里,有一套完整的赛车模拟器,他甚至还请人到国外代购了最新的 VR 设备。作为沉浸式赛车游戏发烧友,除了享受速度与激情带来的愉悦感,祁宁在玩的过程中更多的是思考如何将技术能力进行产品化的问题。 Answer.dev 就是将技术…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

警惕!AI正在悄悄重构全球攻防格局
警惕!AI 正在悄悄重构全球攻防格局 热点聚焦 AI重构网络安全:全球巨头加速布局 2026年5月,全球网络安全领域迎来重大变革,AI技术正在重塑攻防格局。OpenAI发布专为网络安全防御打造的集成化AI平台Daybreak,将安全防…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...

OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心
OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为官方…...

NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台
NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经面对Minecraft世界文件…...

如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题
如何利用开源工具Unlock-Music解决音乐平台加密格式兼容问题 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://gi…...

【C++】零基础入门 · 第 5 节:函数基础
前面四节我们写的代码都集中在 main 函数里。随着程序变复杂,所有逻辑堆在一起会越来越难维护。函数就是用来解决这个问题的——它把一段代码「打包」起来,取个名字,需要的时候调用就行。 1. 为什么需要函数 假设你需要在程序的不同地方打印一行分隔线: cout << &…...