Sarsa增强版之Sarsa-λ依然走迷宫
Sarsa-λ(Sarsa Lambda)是Sarsa算法的一种变体,其中“λ”表示一个介于0和1之间的参数,用于平衡当前状态和之前所有状态的重要性。
Sarsa算法是一种基于Q-learning算法的增量式学习方法,通过在实际环境中不断探索和学习,逐渐更新策略函数和价值函数,以实现最优行为策略的学习。
Sarsa-λ算法在Sarsa算法的基础上引入了一个新的概念,即“λ衰减”,用于平衡当前状态和之前所有状态的重要性。在Sarsa-λ算法中,我们不仅考虑当前状态的奖励和下一个状态的Q值,还考虑了之前所有状态的Q值,并使用“λ衰减”参数来平衡它们的重要性。这样可以使得学习更具有长远的远见,可以对之前的行动进行更好的学习和回溯。
相比之下,Sarsa算法只考虑当前状态和下一个状态的Q值,不考虑之前所有状态的Q值,因此学习过程不够长远和细致。
总的来说,Sarsa-λ算法比Sarsa算法更适合在具有长时间依赖关系的任务中使用,能够更好地处理延迟奖励问题,同时也更加复杂和计算密集。
话不多说,来看代码上有什么不同:
首先是environment
import numpy as np
import time
import tkinter as tk#定义一些常量
UNIT=40
WIDTH=4
HIGHT=4class Palace(tk.Tk,object):def __init__(self):super(Palace, self).__init__()# 动作空间self.action_space = ['u', 'd', 'l', 'r']# self.n_action=len(self.action_space)self.title('maze')# 建立画布self.geometry('{0}x{1}'.format(HIGHT * UNIT, WIDTH * UNIT))self.build_maze()def build_maze(self):self.canvas = tk.Canvas(self, bg='white', height=HIGHT * UNIT, width=WIDTH * UNIT)# 绘制线框for i in range(0, WIDTH * UNIT, UNIT):x0, y0, x1, y1 = i, 0, i, WIDTH * UNITself.canvas.create_line(x0, y0, x1, y1)for j in range(0, HIGHT * UNIT, UNIT):x0, y0, x1, y1 = 0, j, HIGHT * UNIT, jself.canvas.create_line(x0, y0, x1, y1)# 创建迷宫中的地狱hell_center1 = np.array([100, 20])self.hell1 = self.canvas.create_rectangle(hell_center1[0] - 15, hell_center1[1] - 15, hell_center1[0] + 15,hell_center1[1] + 15, fill='black')hell_center2 = np.array([20, 100])self.hell2 = self.canvas.create_rectangle(hell_center2[0] - 15, hell_center2[1] - 15, hell_center2[0] + 15,hell_center2[1] + 15, fill='green')# 创建出口out_center = np.array([100, 100])self.oval = self.canvas.create_oval(out_center[0] - 15, out_center[1] - 15, out_center[0] + 15,out_center[1] + 15, fill='yellow')# 智能体origin = np.array([20, 20])self.finder = self.canvas.create_rectangle(origin[0] - 15, origin[1] - 15, origin[0] + 15, origin[1] + 15,fill='red')self.canvas.pack() # 一定不要忘记加括号# 智能体探索步def step(self, action):s = self.canvas.coords(self.finder) # 获取智能体当前的位置# 由于移动的函数需要传递移动大小的参数,所以这里需要定义一个移动的基准距离base_action = np.array([0, 0])# 根据action来确定移动方向if action == 'u':if s[1] > UNIT:base_action[1] -= UNITelif action == 'd':if s[1] < HIGHT * UNIT:base_action[1] += UNITelif action == 'l':if s[0] > UNIT:base_action[0] -= UNITelif action == 'r':if s[0] < WIDTH * UNIT:base_action[0] += UNIT# 移动self.canvas.move(self.finder, base_action[0], base_action[1])# 移动后记录新位置指标s_ = self.canvas.coords(self.finder)# 反馈奖励,terminal不是自己赋予的,而是判断出来的if s_ == self.canvas.coords(self.oval):reward = 1done = Trues_ = 'terminal' # 结束了elif s_ in (self.canvas.coords(self.hell2), self.canvas.coords(self.hell1)):reward = -1done = Trues_ = 'terminal'else:reward = 0done = False# 这个学习函数不但传入的参数多,返回的结果也多return s_, reward, donedef reset(self):self.update()time.sleep(0.5)self.canvas.delete(self.rect)origin = np.array([20, 20])self.rect = self.canvas.create_rectangle(origin[0] - 15, origin[1] - 15,origin[0] + 15, origin[1] + 15,fill='red')# return observationreturn self.canvas.coords(self.rect)def render(self):time.sleep(0.05)self.update()
environment没什么变化,接下来是智能体agent
"""
This part of code is the Q learning brain, which is a brain of the agent.
All decisions are made in here.View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""import numpy as np
import pandas as pdclass RL(object):def __init__(self, action_space, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):self.actions = action_space # a listself.lr = learning_rateself.gamma = reward_decayself.epsilon = e_greedyself.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64)def check_state_exist(self, state):if state not in self.q_table.index:# append new state to q tableself.q_table = self.q_table.append(pd.Series([0] * len(self.actions),index=self.q_table.columns,name=state,))def choose_action(self, observation):self.check_state_exist(observation)# action selectionif np.random.rand() < self.epsilon:# choose best actionstate_action = self.q_table.loc[observation, :]# some actions may have the same value, randomly choose on in these actionsaction = np.random.choice(state_action[state_action == np.max(state_action)].index)else:# choose random actionaction = np.random.choice(self.actions)return actiondef learn(self, *args):pass# backward eligibility traces
class SarsaLambdaTable(RL):# 注意,这里多了一个参数,trace_decay,步伐的衰减值,和奖励的衰减值类似,都是让离奖励越远的值影响越小def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9, trace_decay=0.9):super(SarsaLambdaTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)# backward view, eligibility trace.# 这里出现了lamba,其实它是干什么的我还不清楚,self.lambda_ = trace_decay# 拷贝,把q_table拷贝了一份self.eligibility_trace = self.q_table.copy()def check_state_exist(self, state):if state not in self.q_table.index:# append new state to q tableto_be_append = pd.Series([0] * len(self.actions),index=self.q_table.columns,name=state,)self.q_table = self.q_table.append(to_be_append)# also update eligibility trace# 这份拷贝的表是和原表同步更新的self.eligibility_trace = self.eligibility_trace.append(to_be_append)def learn(self, s, a, r, s_, a_):self.check_state_exist(s_)# 先检查状态,不在表中就添加q_predict = self.q_table.loc[s, a]if s_ != 'terminal':# 这是现实,q_target就是现实q_target = r + self.gamma * self.q_table.loc[s_, a_] # next state is not terminalelse:q_target = r # next state is terminal# 不直接更新,而是把误差计算出来,留着后面使用error = q_target - q_predict# increase trace amount for visited state-action pair# 这个lamba主要就是一个更新规则一起就是单步更新,但是那样效率有点慢,# eligiblity_trace就是做一个步伐轨迹的记录# Method 1:# self.eligibility_trace.loc[s, a] += 1# Method 2:self.eligibility_trace.loc[s, :] *= 0self.eligibility_trace.loc[s, a] = 1# Q updateself.q_table += self.lr * error * self.eligibility_trace# decay eligibility trace after updateself.eligibility_trace *= self.gamma * self.lambda_return self.q_table在强化学习中,Eligibility通常指的是某个状态-动作对(State-Action Pair)对价值函数的贡献。具体来说,它描述了某个状态-动作对对价值函数的影响程度,可以用于增量式地更新价值函数。
Eligibility一般被用于Sarsa-Lambda等强化学习算法中。在这些算法中,每个状态-动作对都会维护一个相关的Eligibility值,表示该状态-动作对对当前的价值函数有多大的贡献。每次更新价值函数时,Eligibility值会被相应地更新。
通常情况下,Eligibility值会根据时间衰减,即先前的状态-动作对对价值函数的贡献会随着时间的推移而逐渐减少,而当前状态-动作对对价值函数的贡献会更高。具体来说,Sarsa-Lambda等算法会使用一个衰减参数来控制Eligibility值的衰减速度,从而平衡过去和现在的状态-动作对对价值函数的贡献。
然后运行run
"""
Sarsa is a online updating method for Reinforcement learning.Unlike Q learning which is a offline updating method, Sarsa is updating while in the current trajectory.You will see the sarsa is more coward when punishment is close because it cares about all behaviours,
while q learning is more brave because it only cares about maximum behaviour.
"""from maze_env import Maze
from RL_brain import SarsaLambdaTabledef update():for episode in range(10):# initial observationobservation = env.reset()# RL choose action based on observationaction = RL.choose_action(str(observation))# initial all zero eligibility trace,每跑一次都置零,哎不管了,直接干RL.eligibility_trace *= 0while True:# fresh envenv.render()# RL take action and get next observation and rewardobservation_, reward, done = env.step(action)# RL choose action based on next observationaction_ = RL.choose_action(str(observation_))# RL learn from this transition (s, a, r, s, a) ==> Sarsaq_table = RL.learn(str(observation), action, reward, str(observation_), action_)# swap observation and actionobservation = observation_action = action_# break while loop when end of this episodeif done:break# end of gameprint('game over')print(q_table)q_table.to_csv('output.csv')env.destroy()if __name__ == "__main__":env = Maze()RL = SarsaLambdaTable(actions=list(range(env.n_actions)))env.after(10, update)env.mainloop()不知道是怎么回事,Sarsa-lambda的效果有时好于Sarsa,并不十分稳定,后面再继续研究研究
相关文章:

Sarsa增强版之Sarsa-λ依然走迷宫
Sarsa-λ(Sarsa Lambda)是Sarsa算法的一种变体,其中“λ”表示一个介于0和1之间的参数,用于平衡当前状态和之前所有状态的重要性。 Sarsa算法是一种基于Q-learning算法的增量式学习方法,通过在实际环境中不断探索和学…...

生成 Cypher 能力:MOSS VS ChatGLM
生成 Cypher 能力:MOSS VS ChatGLM 生成 Cypher 能力:MOSS VS ChatGLM一、 测试结果二、 测试代码(包含Prompt) Here’s the table of contents: 生成 Cypher 能力:MOSS VS ChatGLM MOSS介绍:MOSS 是复旦大…...

数据库的键和存储
主键:数据库表中对存储数据对象给予以唯一和完整表示的数据列或属性的组合。一个数据列只能有一个主键,且主键的取值不能缺失,即不能为空。 外键:在一个表中存在另一个表得主键称此为表的外键。 为什么用自增列作为主键? 如果我们定义了主…...
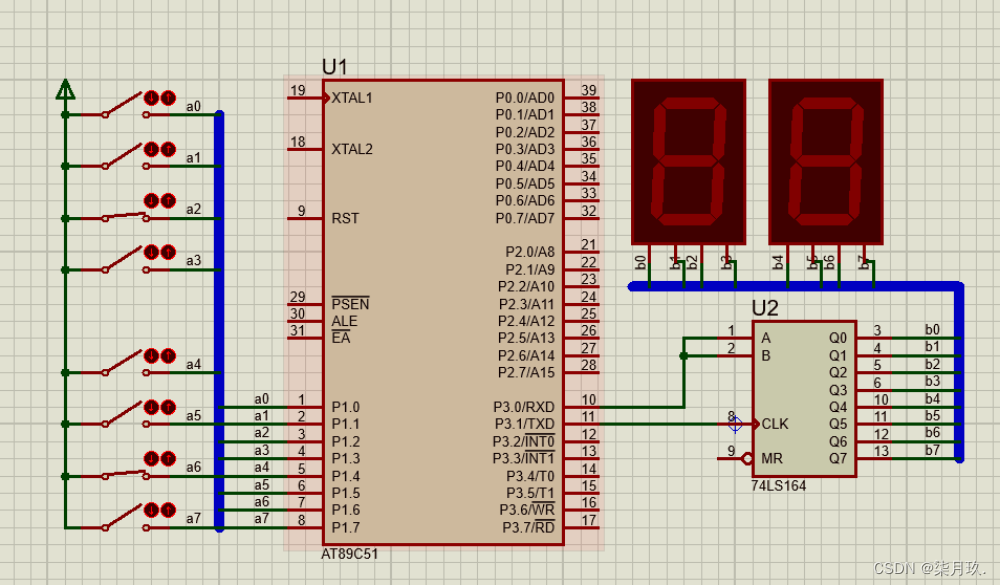
基于AT89C51单片机的并入串出乘法口诀的设计与仿真
点击链接获取Keil源码与Project Backups仿真图: https://download.csdn.net/download/qq_64505944/87779146?spm1001.2014.3001.5503 源码获取 并入串出乘法口诀的设计与仿真系统设计 目录 第一章 概述 3 1.1课题研究及意义 3 1.2课题设计内容 4 第二章系统设计…...

人生在世皆有过错,来一起看看Java中的异常吧!!!
Java中的异常问题详解 一、异常的概念与分类 1.异常概念 概念:Java异常是一个描述在代码段中发生异常的对象,当发生异常情况时,一个代表该异常的对象被创建并且在导致该异常的方法中被抛出,而该方法可以选择自己处理异常或者传…...

linux 测试连接网络和端口 telnet
一、安装telnet 1、检测telnet-server的rpm包是否安装 [rootlocalhost ~]# rpm -qa telnet-server 若无输入内容,则表示没有安装。出于安全考虑telnet-server.rpm是默认没有安装的,而telnet的客户端是标配。即下面的软件是默认安装的。 2、若未安装&…...

一文快速入门体验 Hibernate
前言 Hibernate 是一个优秀的持久层的框架,当然,虽然现在说用得比较多的是 MyBaits,但是我工作中也不得不接触 Hibernate,特别是一些老项目需要你维护的时候。所以,在此写下这篇文章,方便自己回顾…...

【RabbitMQ】SpringAMQP
RabbitMQ 1.初识MQ 1.1.同步和异步通讯 微服务间通讯有同步和异步两种方式: 同步通讯:就像打电话,需要实时响应。 异步通讯:就像发邮件,不需要马上回复。 两种方式各有优劣,打电话可以立即得到响应&am…...

错题汇总08
1.如果友元函数重载一个运算符时,其参数表中没有任何参数则说明该运算符是 A 一元运算符 B 二元运算符 C 选项A)和选项B)都可能 D 重载错误 运算符重载 1.重载成类的成员函数------>形参数目看起来比该运算符需要的参数个数少1&#x…...

使用urllib库简单入门
使用urllib库简单入门 Python中的urllib库是一个非常强大的工具,它提供了一些模块,如urllib.request、urllib.parse、urllib.error、urllib.robotparser等,可以用来处理URLs和网页数据的获取、发送和处理。 在本文中,我们将介绍…...

C++学习 Day11
目录 1. 再谈构造函数 1.1 构造函数体赋值 1.2 初始化列表 1.3 explicit关键字 2. stastic成员 2.1 概念 2.2 特性 1. 再谈构造函数 1.1 构造函数体赋值 在创建对象时,编译器通过调用构造函数,给对象中各个成员变量一个合适的初始值。 class Date…...
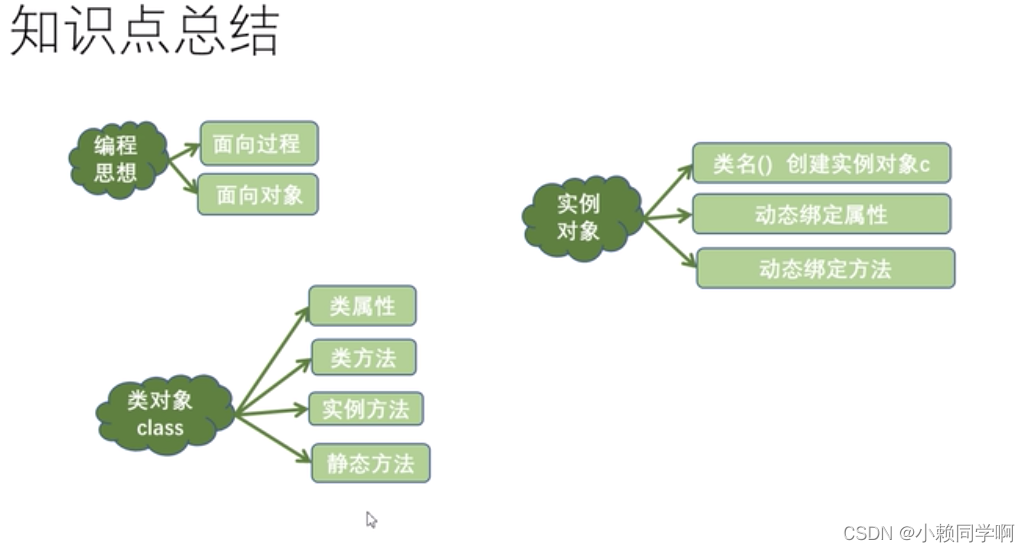
python中函数与类 类中的方法-静态方法/动态方法
class student():position即令def __init__(self,name,age):self.namenameself.ageagedef eat(self):passclassmethoddef cla(cls):passstaticmethoddef sta():passpassstustudent(name张三,age12) print(stu.position)stu.sta() stu.cla()# 直接使用静态和类方法 student.cla(…...

基于trace_id实现ForkJoinPool的链路追踪
一、引言 之前写过一篇博客:基于trace_id的链路追踪(含Feign、Hystrix、线程池等场景),主要介绍在微服务体系架构中,如何实现分布式系统的链路追踪的博客,其中主要实现了以下几种场景: Filter…...

Qt推流程序(视频文件/视频流/摄像头/桌面转成流媒体rtmp+hls+webrtc)可在网页和播放器远程观看
一、前言说明 推流直播就是把采集阶段封包好的内容传输到服务器的过程。其实就是将现场的视频信号从手机端,电脑端,摄影机端打包传到服务器的过程。“推流”对网络要求比较高,如果网络不稳定,直播效果就会很差,观众观…...

ChatGPT入门到高级【第一章】
第一章:Chatgpt的起源和发展 1.1 人工智能和Chatbot的概念 1.2 Chatbot的历史发展 1.3 机器学习技术在Chatbot中的应用 1.4 Chatgpt的诞生和发展 第二章:Chatgpt的技术原理 2.1 自然语言处理技术 2.2 深度学习技术 2.3 Transformer模型 2.4 GPT模型 第…...
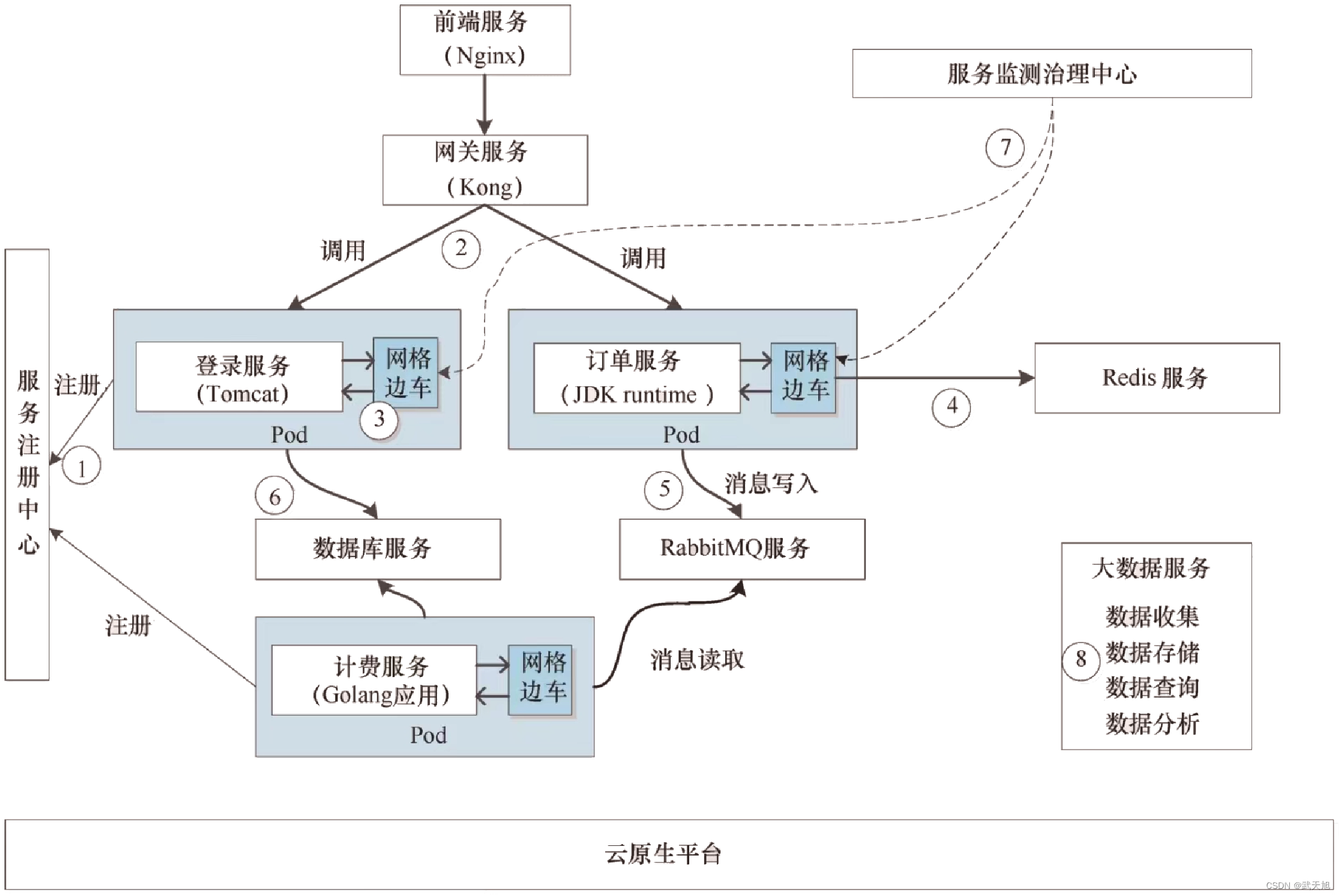
云原生应用架构
本博客地址:https://security.blog.csdn.net/article/details/130566883 一、什么是云原生应用架构 成为云原生应用至少需要满足下面几个特点: ● 使用微服务架构对业务进行拆分。单个微服务是个自治的服务领域,对这个领域内的业务实体能够…...
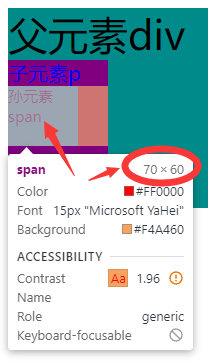
rem、px、em的区别 -前端
文章目录 三者的区别特点与换算举例emrem 总结一总结二 三者的区别 在css中单位长度用的最多的是px、em、rem,这三个的区别是: 一、px是固定的像素,一旦设置了就无法因为适应页面大小而改变。 二、em和rem相对于px更具有灵活性,…...
分享几款小白从零开始学习的会用到的工具/网站
大二狗接触编程也有两年了,差生文具多这大众都认可的一句话,在这里蹭一下这个活动分享一下从0开始学习编程有啥好用的工具 目录 伴侣一、Snipaste截图工具 伴侣二、Postman软件(可用ApiPost平替) 伴侣三、字体图标网站 伴侣四…...

第八章 文件处理命令
第八章 文件处理命令 一、 文本编辑器 vi • vi 是 Unix 类操作系统中最为流行的文本编辑器。尽管目前 已有 gedit 等一些工作在图形界面下使用起来也更为方便 的文本编辑器,但在很多情况下,vi 这种专为字符界面操 作而设计的编辑器恐怕还是要充当首…...

LVS 负载均衡群集的 NAT 模式和 DR 模式
1. 对比 LVS 负载均衡群集的 NAT 模式和 DR 模式,比较其各自的优势 DR 模式 * 负载各节点服务器通过本地网络连接,不需要建立专用的IP隧道 原理:首先负载均衡器接收到客户的请求数据包时,根据调度算法决定将请求发送给哪个后端的…...

硅橡胶资源平台对接的靠谱对接企业哪家强
在深圳这座创新与制造之都,硅橡胶产业上下游企业林立,从原材料、模具设计到制品生产,形成了一个庞大而复杂的产业链。对于许多企业而言,“深圳硅橡胶资源平台对接” 的需求日益迫切——无论是寻找稳定供应商、开拓新客户ÿ…...
缓冲流 + 转换流)
JAVA重点基础、进阶知识及易错点总结(15)缓冲流 + 转换流
🚀 Java 巩固进阶 第15天 主题:缓冲流 转换流 —— 高效 IO 与编码安全的终极方案📅 进度概览:今天学习 生产环境真正在用的流组合!掌握缓冲流 转换流,你的文件操作代码才能达到"标准、高效、不乱码…...

雷小兔:让学术论文排版变得简单高效
产品概述 雷小兔是一款专门为学生和研究人员设计的学术论文辅助工具。无论你是在准备毕业论文、学位论文还是学术发表,雷小兔都能为你提供全面的支持和帮助。 论文排版方面的核心优势 1. 模板齐全,开箱即用 雷小兔内置了数十种符合国内外高校标准的论…...

3分钟搞定100个Excel文件:极速多表格查询工具让数据搜索效率提升30倍
3分钟搞定100个Excel文件:极速多表格查询工具让数据搜索效率提升30倍 【免费下载链接】QueryExcel 多Excel文件内容查询工具。 项目地址: https://gitcode.com/gh_mirrors/qu/QueryExcel 你是否经历过这样的绝望时刻?当领导要求从20个Excel报表中…...
开源工具TranslucentTB启动错误0x800401E3完整解决方案
开源工具TranslucentTB启动错误0x800401E3完整解决方案 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB TranslucentTB是一款广受欢迎的Wi…...

效率飙升,跳过proteus安装配置,用快马ai秒建仿真项目
最近在做一个温度监测系统的项目,需要验证电路设计的可行性。按照传统方式,我得先下载安装Proteus软件,配置各种库文件,光是环境准备就得折腾半天。不过这次尝试了用InsCode(快马)平台的AI功能,整个过程变得异常高效。…...

【数字电路】从双稳态到触发器:时序逻辑的存储基石
1. 数字世界的记忆细胞:双稳态电路探秘 当你按下电脑电源键的瞬间,数十亿个微型存储单元开始工作,它们就像数字世界的记忆细胞,忠实地记录着每一个比特的信息。这一切的起点,正是我们今天要探讨的双稳态电路。想象一下…...

牙科手术显微镜市场:其中中国市场占比超15%
在口腔诊疗向精细化、微创化演进的进程中,牙科手术显微镜作为核心光学放大设备,凭借其高照度、高景深与高清晰度特性,成为提升根管治疗、牙周手术及种植修复等环节精准性的关键工具。该设备集成连续变倍观察、同轴照明、术野调焦及影像记录系…...

豪鹏科技2025年财报透视:毛利率提升5.2个百分点,费用管控成效显著
豪鹏科技2025年财报透视:毛利率提升5.2个百分点,费用管控成效显著豪鹏科技2025年业绩表现亮眼,全年实现营业收入57亿元至60亿元,同比增长11.58%至17.45%;归母净利润1.95亿元至2.2亿元,同比大幅增长113.69%至…...

Windows屏幕取色器ColorWanted:设计师和开发者的效率神器
Windows屏幕取色器ColorWanted:设计师和开发者的效率神器 【免费下载链接】ColorWanted Screen color picker for Windows (Windows 上的屏幕取色器) 项目地址: https://gitcode.com/gh_mirrors/co/ColorWanted 你是否经常需要在设计软件、网页开发或UI设计中…...