蚂蚁实时低代码研发和流批一体的应用实践
摘要:本文整理自蚂蚁实时数仓架构师马年圣,在 Flink Forward Asia 2022 流批一体专场的分享。本篇内容主要分为四个部分:
- 实时应用场景与研发体系
- 低代码研发
- 流批一体
- 规划展望
点击查看原文视频 & 演讲PPT
一、实时应用场景与研发体系

蚂蚁实时的数据应用主要包括报表监控、实时标签和实时特征三部分。最底层的实时数据采集来源于线上日志、实时消息和数据库日志三大块,并由此构建了实时和离线的明细中间层,该中间层定义不同的主题域,如:流量、营销、交易等。再往上构建应用层数据去支撑前台业务的实时数据需求。
在这三个应用场景中,报表场景根据查询特性的不同,实时数据会被存储到 OLAP 引擎或 KV 库,在应用层进行实时/离线数据的融合,来构建实时数据报表;而在实时标签场景,将实时数据直写到 Hbase/Lindorm 库中,离线数据通过标签平台回流至线上库中;特征场景和标签场景链路类似,通过特征视图对流/批数据分别进行字段 Mapping。
以上的数据链路架构在研发、运维、消费的成本上均存在一定的问题,在开发阶段,首先突出的是实时研发的效率问题,一个实时任务从需求对接到数据交付往往需要较长时间,如果涉及到离线回补逻辑,则还需开发离线兜底链路,并同步离线数据到线上库中;在线上运维阶段,虽然 Flink 一直在降低任务调优难度,但实时离线计算引擎的运维压力是双重的,往往需要互相翻译口径进行问题排查;在消费链路中,实时离线两拨同学研发,往往报表会配置两份,其工作量重复之余,也会增加下游的数据使用成本。
最后再抛出一个实时中的老大难问题:长周期计算问题。支付宝大促活动频繁,计算活动期间累计去重 UV 这类指标,研发运维成本一直较高,这也是我们尝试在优化解决的问题。

蚂蚁实时研发体系在去年完成了的升级,构建了基于实时元表为载体的实时研发能力,从实时资产的定义、到实时代码研发、到线上的实时质量监控,再到实时元数据消费,都是基于元表来完成的,在数据研发时可快速的引用公共的实时资产。对于此套能力体系,研发同学还是需要经历相当多的研发过程,上图标星的是我们希望能够进行提效研发和缩短开发周期的环节,因此,我们推出了低代码研发和流批一体能力。
二、低代码研发

低代码主要解决我们实时开发中的两个大的命题:研发提效和降低实时研发门槛,对于这两个问题面向的用户群体还不一样。一类是资深的实时研发同学,他们比较了解实时研发中的各项细节,但是很多基础性的代码研发工作会极大影响他们的效率;另一类则是实时的入门级选手,他们对于实时研发的概念和使用方式都不太熟悉,可能是对照着 API 一步步试错。
对于这两个风格不一样的人群,他们本质的需求都是希望有个工具来解决他们的问题,由此我们构建了实时低代码研发能力。本着产品易用、任务易维护、代码正确的前提,我们通过配置化研发,将实时研发的范式抽象,并集成高阶的实时解决方案,最后期望能够强化任务自动化运维,让用户在低代码中所配即所得,即配即上线。
我们优先从数据场景入手考虑低代码研发工具所需具备的能力。汇总计算场景中,侧重对统计周期和维度的各种组合,而指标计算大部分是累加型(COUNT(1))、聚合型(SUM(xxx))和去重型(COUNT(DISTINCT xxx)),当然还需要具备简单的逻辑过滤、维表关联等基础代码操作。标签场景中,侧重对明细数据的处理和解析,需要能够支持各种实时计算算子。特征场景和指标计算场景很像,但是时间窗口多以滑窗为主,计算近 x 分钟/小时的窗口聚合数据,维度主要是 user 或 item 粒度(如计算商品、流量点位、店铺等),特征中计算算子较为丰富,且一个需求中需提供多个滑窗、多种指标的特征,需要能够支持多窗口多算子的实时计算能力。
综合以上三个场景,我们抽取三者共同的特点:算子支持、Flink 特性封装、批量研发
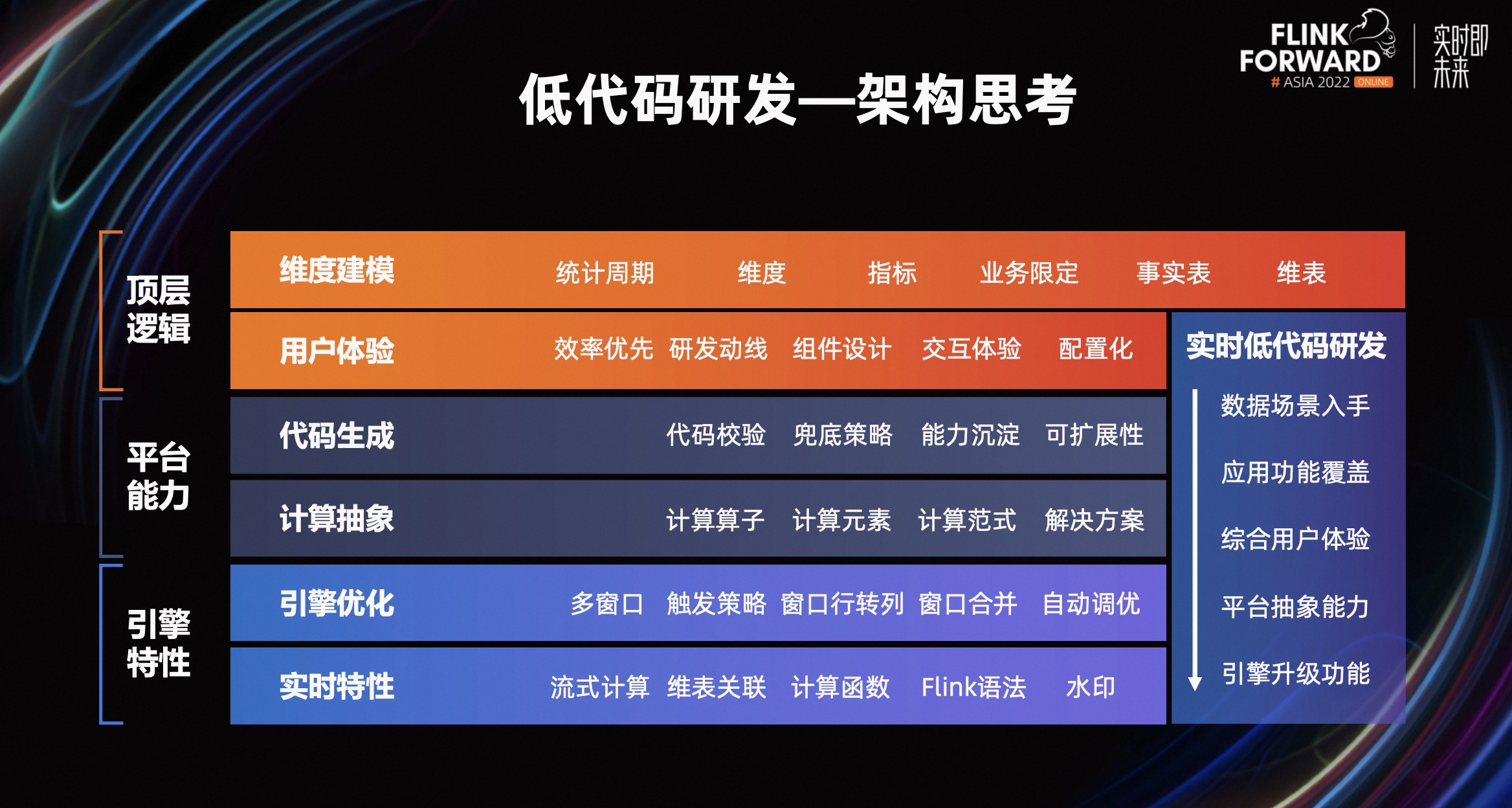
对于这么多能力需求,我们采用维度建模的理论来进行构建,Flink 实时计算中三大 Connector(Source/Sink/Dim)和维度建模理论天然的契合,从明细事实表出发,进行一系列的数据操作,设定统计周期和维度,计算相应的实时指标。剩下就是对于低代码能力细节的拆解,从用户体验、平台能力和引擎优化三个角度进行构建。
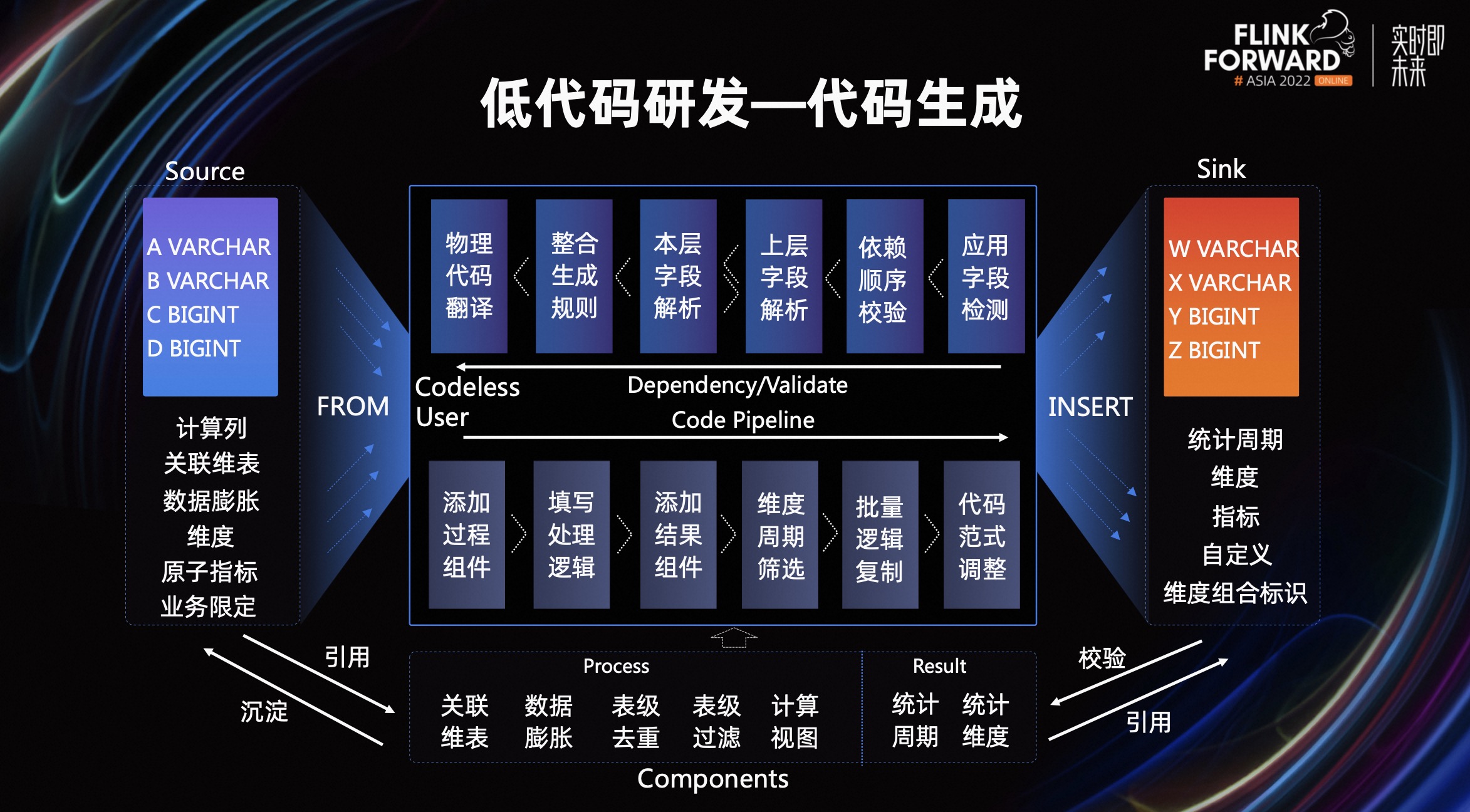
整个平台能力分为用户任务配置和代码逻辑生成两大块。
在用户操作界面,我们定义了关联维表、数据膨胀、表级去重、表级过滤四大过程组件,并通过计算视图这个能力兜底以上算子不能覆盖的场景。同时定义统计周期和统计维度两个结果组件,使用这两个组件则默认是汇总指标计算,反之则是明细数据处理。对于这些组件中的信息,我们抽象了计算元素的概念,将重要的组件内容和来源表绑定,一些通用的计算范式和资产消费口径,用户可以直接选用其他用户公共定义的逻辑,提高开发效率。
这样通过添加组件,筛选维度和周期,对结果表中的字段定义其类型,并选择具体的逻辑,调整维度分布后,便完成了实时任务的配置。
任务配置完,平台侧从结果表反向推导,判断任务配置的逻辑是否正确,这一步很像 Flink 执行计划生成的逻辑,从后向前不断循环校验各算子的正确性,直至整个任务代码生成,这便完成了代码的编辑工作,用户对物理任务进行执行计划配置即可上线。
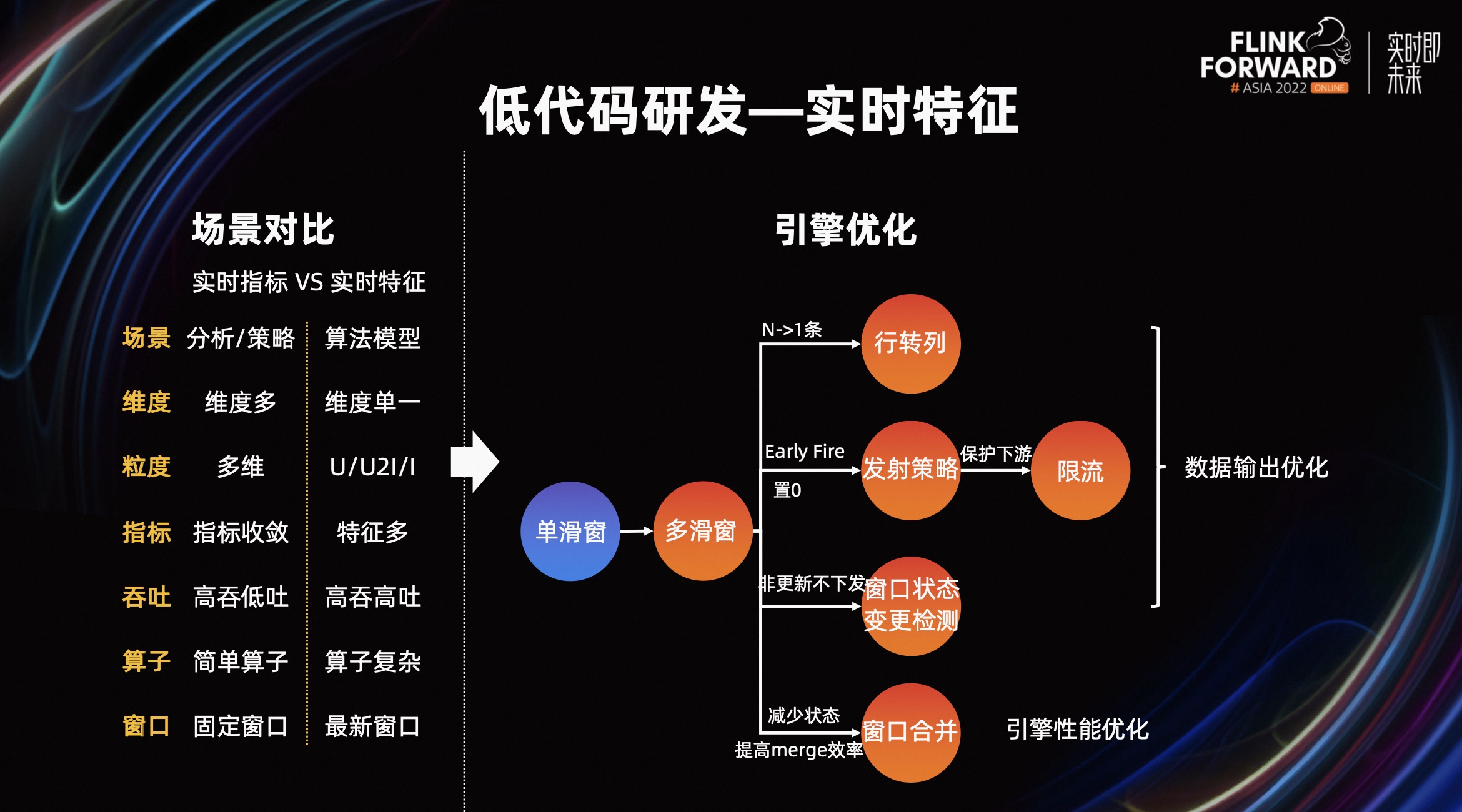
对于低代码研发中引擎的优化,我以实时特征举例。首先我们来对比下指标场景和特征场景的异同点,其最主要的差异在于窗口和算子的复杂度,同时特征中多以用户粒度也决定了下发数据相对较多,数据吞吐较高。
从以上这些现状出发,我们对 Flink 的窗口计算做了一系列优化,首先从单滑窗升级到了多划窗语义。根据下游使用横表和竖表数据需求,将多滑窗中的窗口行转列成多个指标,对数据进行拉横,减少下游输出的条数。
同时对触发策略进行升级,可支持窗口触发前后都能进行数据的更新,当然对于窗口触发后主要用来进行数据置 0 的操作。对于定时更新的数据下发,考虑到下游的数据库性能,对 Connector 加入了限流功能。还引入了对窗口状态变更检测能力,如果窗口内的数据没有变更,也不需要进行下发更新。
对于多滑窗的状态存储优化,和 Flink 开源版本类似,加入了子窗的概念,一个数据保证其只划分到最细粒度的窗口中,窗口计算时汇总各子窗中的数据即可完成数据聚合。
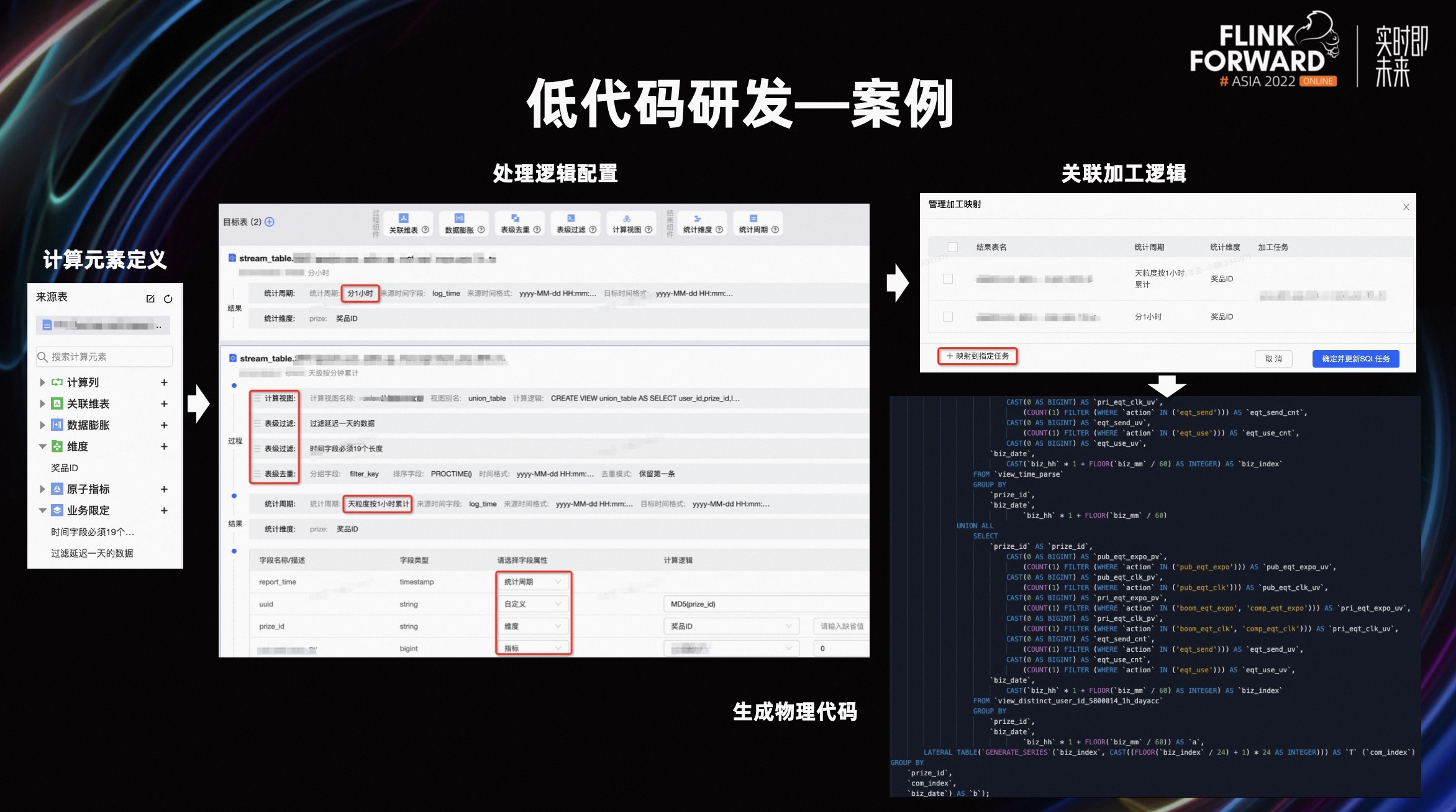
最后通过一个案例介绍实时低代码研发的使用
首先在来源表上定义计算元素,这些定义的逻辑可被过程和结果组件使用。配置面板中有三大块:过程配置、结果组件和面向结果表的字段定义,对于不同统计周期的相同计算逻辑,可使用批量复制,修改统计周期即可。
平台还提供了统计周期和维度的组合拆分能力,用户根据统计周期和维度的数据情况,选择是合并一个任务还是拆分多个任务。
最后便是生成的代码展示,这里提到的是,平台侧会感知 UV 和 PV 的计算逻辑,并对 UV 类累计指标单独拆成子任务计算,最后和 PV 类进行合并,用户还能使用我们内置的累计去重计算方案。
三、流批一体

在构建流批能力之前,我们先 REVIEW 下当前实时数仓中的数据链路情况。Lambda 架构中,三个消费场景的实时离线数据融合方案还不统一,从数据侧到应用侧都有触发流批数据融合的逻辑,但本质上还是流批模型字段对齐的语义表达,下游便可实现字段对齐逻辑。
其次在实时数仓中,大部分都是从 ODS/DWD 层直接计算累计结果,而离线数仓中,应用层数据大部分都是从轻度汇总层计算得到,在构建流批数据时需考虑这样的差异,可能流和批表的对齐方式就是明细和汇总。
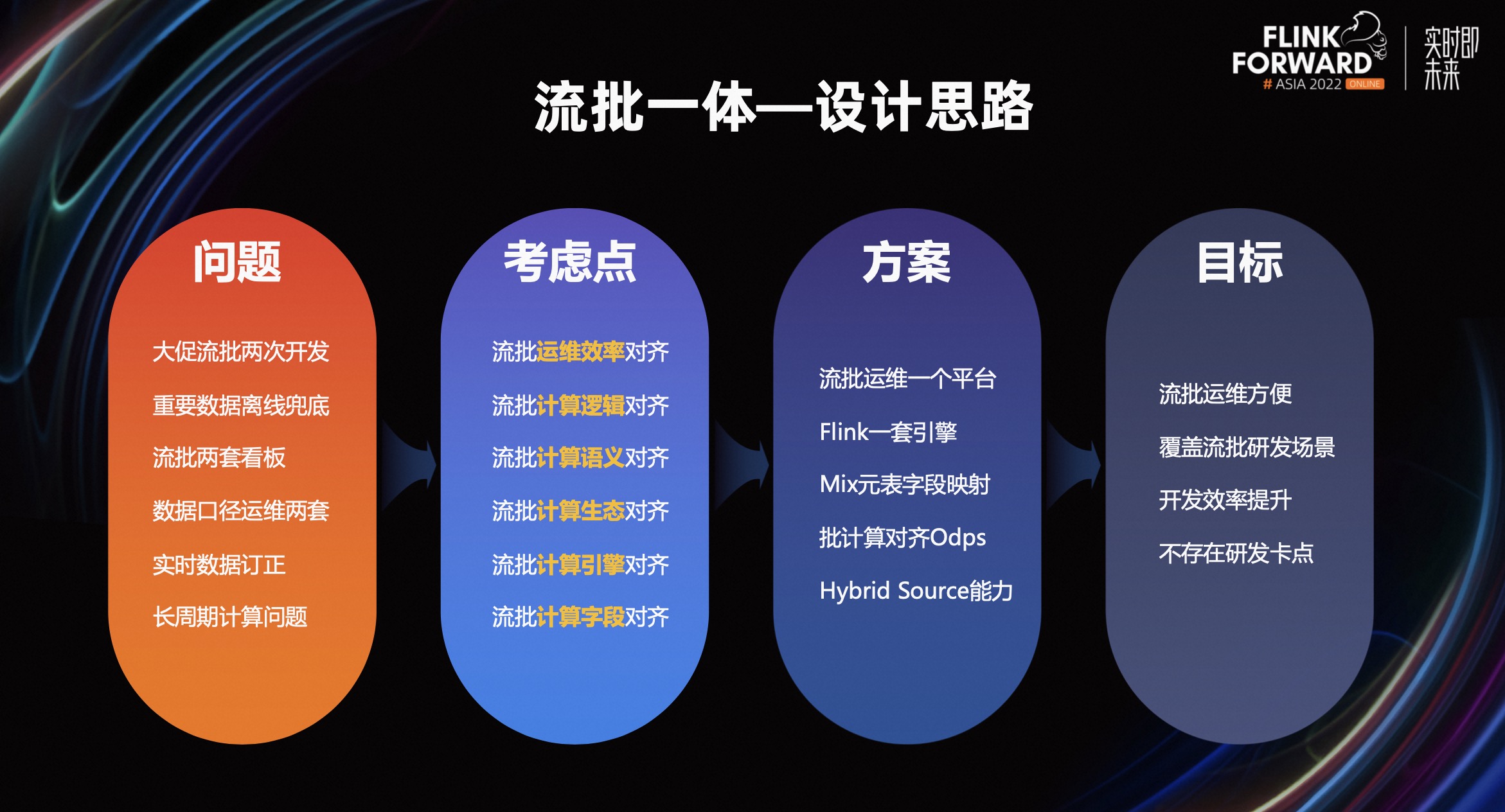
在频繁的大促过程中,实时和离线任务存在着重复开发的问题。对于研发口径一致性,实时离线报表指标对齐,都有着一定的挑战。对此我们考虑多个方面,从字段对齐到引擎的生态,再到研发运维效率,并参考业界流批计算的案例,最终选用 Flink 引擎来构建流批一体的研发能力。
通过一套资产、一套引擎、一份代码,完成流和批任务的研发,最终通过流批能力覆盖实时离线重复开发和兜底的场景,提高研发运维效率。

蚂蚁主流的实时研发引擎还是 Blink,对于通过 Flink 来构建流批研发能力,有很多的工作要做,我们规划了五个大的时间节奏点
- 首先将开源 Flink 适配到蚂蚁计算组件中,包括一些可插拔的组件,Connector 等,同时实时研发平台还要对 Flink 新引擎进行兼容,并对标 Blink 之前的体验进行能力的升级。
- 接着我们对 Hybrid Source 进行的 SQL 化定义,对 SQL 语法和 DDL 参数进行设计,同时引入了多源元表的能力,多源元表是在单源元表基础之上,对字段进行映射。
- 第一版的多源元表只能进行简单的字段映射,但发现往往流批 Source 表会出现字段不对齐、字段语义不一致、字段数量不相等的情况,这就引入了虚拟列和流批标识的能力,通过新增虚拟列,能够将某一方没有的字段补齐,并在代码中通过流批标识显式地对字段进行处理。
- 接下来对 Flink 批引擎进行了落地,和流引擎一样先完成了生态和平台的适配,接着便是对 Flink 批的运行参数,资源分配,并发推断等能特性进行调试。
- 最后便是流批一体的能力的落地,在平台侧实现多源元表定义、代码翻译和任务运维,目前正应用在大促场景。

流引擎和批引擎在落地的过程中有很多相同的工作量,这里主要介绍批计算引擎的架构。
首先是调度层,蚂蚁 Flink 的调度使用了原生的 K8S 调度,我们还在尝试集群调度模式,在 K8S 之上直接获取机器资源,减少任务发布上线的时间,同时能保证任务的稳定性。
在引擎这一层,Flink 研发运维同学做了很多的工作,从上往下看,首先对齐 Blink SQL 完成计算函数的新增,并优化了部分执行计划推断的逻辑。如一个源抽取了 ab 字段,同样的表抽取了 bc 字段,则会对 source 表进行合并读取。
在批引擎执行优化层面,对批计算中的并发度、CPU 和内存进行配置,Connector 的并发度根据数据量进行推断,而运行中搭配 AdaptiveBatchScheduler 进行动态调整。对于 CPU 和内存,则根据不同的算子类型进行设置。并对线上任务进行压测,发现并优化 Flink 批在大数据量和计算压力下的一些改进点,保证批任务的运行性能和稳定性。
Connector 层面则主要对齐 Blink 进行适配,考虑到批任务会在计算完成之后一次性同步会产生输出洪峰,为了保护线上库,设置限流是相当必要的,引擎侧在 Connector 插件中实现了限流的能力。
DataStream 引擎和算子主要使用开源能力。最后在可插拔组件中,我们主要对 Shuffle 组件、调度组件和后端状态进行了适配优化。批任务默认使用基于 TaskManager 本地磁盘的 Shuffle 方式,这种方式对本地磁盘的要求比较高,在上下游交互的时候存在依赖关系,我们引入了开源的 flink remote shuffle 组件,独立部分 Shuffle 组件,实现计存分离的架构。
在计算平台层面,对批任务的预编译、调试、提交、发布、运行监控进行了支持,对于离线代码中的时间变量、任务参数进行解析翻译。其中最重要的是将 Flink 批计算类型加入到离线调度引擎中,依赖 Odps 等其它的任务产出的数据,在调度运行是生成任务实例,并查询具体的运行日志。

对于流批表对齐的问题,我们来看以上两个 CASE。在流和批都是明细的情况下,流和批的字段含义不一致和不对齐是常见的,比如离线是否打标是 Y/N,实时打标 1/0。而对于流明细批汇总的场景,比如离线是算到用户粒度的轻度汇总数据,对于 PV 这样的字段,实时肯定没有的。
对于以上这类问题,一个方案是某一方进行数据的改造,保证两侧的数据字段对齐,但是成本相当高。因此,我们设计了虚拟列字段,对于某一方不存在的情况下,使用虚拟列标识,同时对流表和批表进行参数定义,这样就能在代码中显式的判断和处理,以此来解决流批字段不对齐的问题,在这样的能力支撑下,即使流和批表字段完全不一致的极端情况,也能进行特判和处理。

对齐来源表字段之后,我们来看下流批一体的整体方案。举个栗子来简述下具体的方案细节,有 stream_source 和 batch_source 两个来源表,其中 c 和 d 字段是不对齐的,通过虚拟列进行补充,注册成 mix_source 的多源元表,我们在正常开发流批任务的时候,根据流批标识进行逻辑判断,同时也能通过代码变量做流批的自定义逻辑。
平台侧会根据 mix_source 背后的单源元表进行物理代码的翻译,同时通过一个 View 的适配,将字段和虚拟列定义完成。批代码我们支持静态分区,也就是在 DDL 中定义分区,和动态分区,在代码中显示的指定时间变量,以此对离线分区进行裁剪。当然对于维表和结果表,当前只能支持单源或者字段完全一致的多源,这块目前没有特别强的诉求,需要将维表和结果表也要支持不同的字段定义。
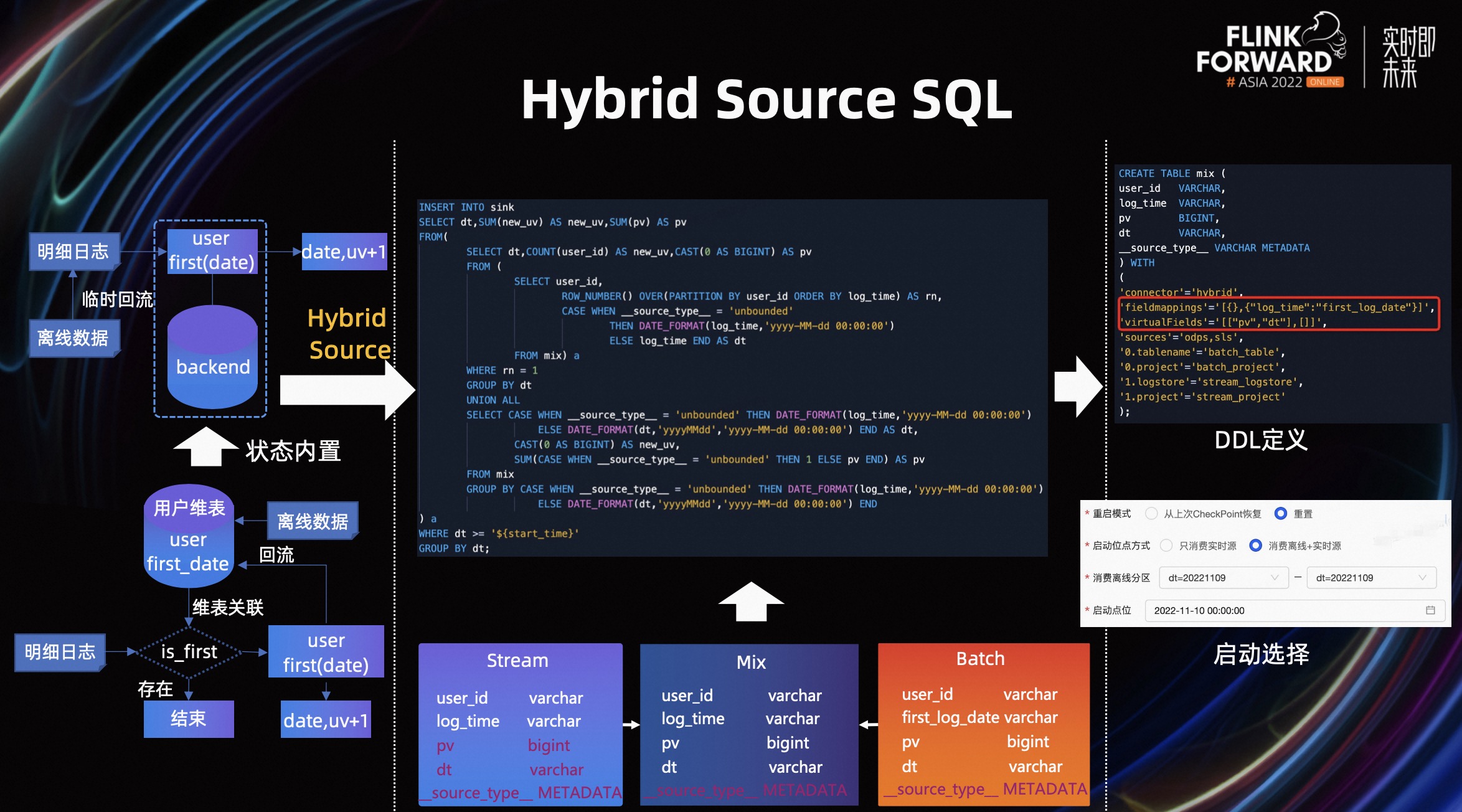
对于长周期去重计算指标,如大屏场景对数据结果查询性能有一定的要求,往往需要将数据计算到一个指标或者很小量级的数据,能够快速的进行累加。
对于这类场景,在没有应用 Hybrid Source 之前,我们通常的做法是借助 Hbase 这样的 KV 库,存储用户的访问状态,数据过来是校验用户是否访问过,最终算到天级的新增 UV 开窗累计即可。另一种方向则是直接在 Flink 中设置较大的状态过期时间,相当于把外部存储内置到引擎中,但此种方案需要考虑,如果在任务出现问题,状态需要丢弃,或者中途修改逻辑的情况下,实时回刷成本很高。
对于以上两个问题,我们设计通过 Hybrid Source 来支撑。Hybrid Source 也是使用多源元表,映射实时和离线字段,我们定义了 Hybird Source SQL 的 DDL 语义,0 和 1 标识批和流表,同时定义了 fieldMappings 字段来标识字段名称不对齐的情况,定义 virtualFields 表达虚拟列,在 Connector 插件中根据这些定义和流批标识,对数据进行打标,实时任务即可完成 Hybrid Source 场景复杂 SQL 开发。右下角图片是 Hybrid Source 任务发上线的启动界面,对于批和流分别选择启动的时间。
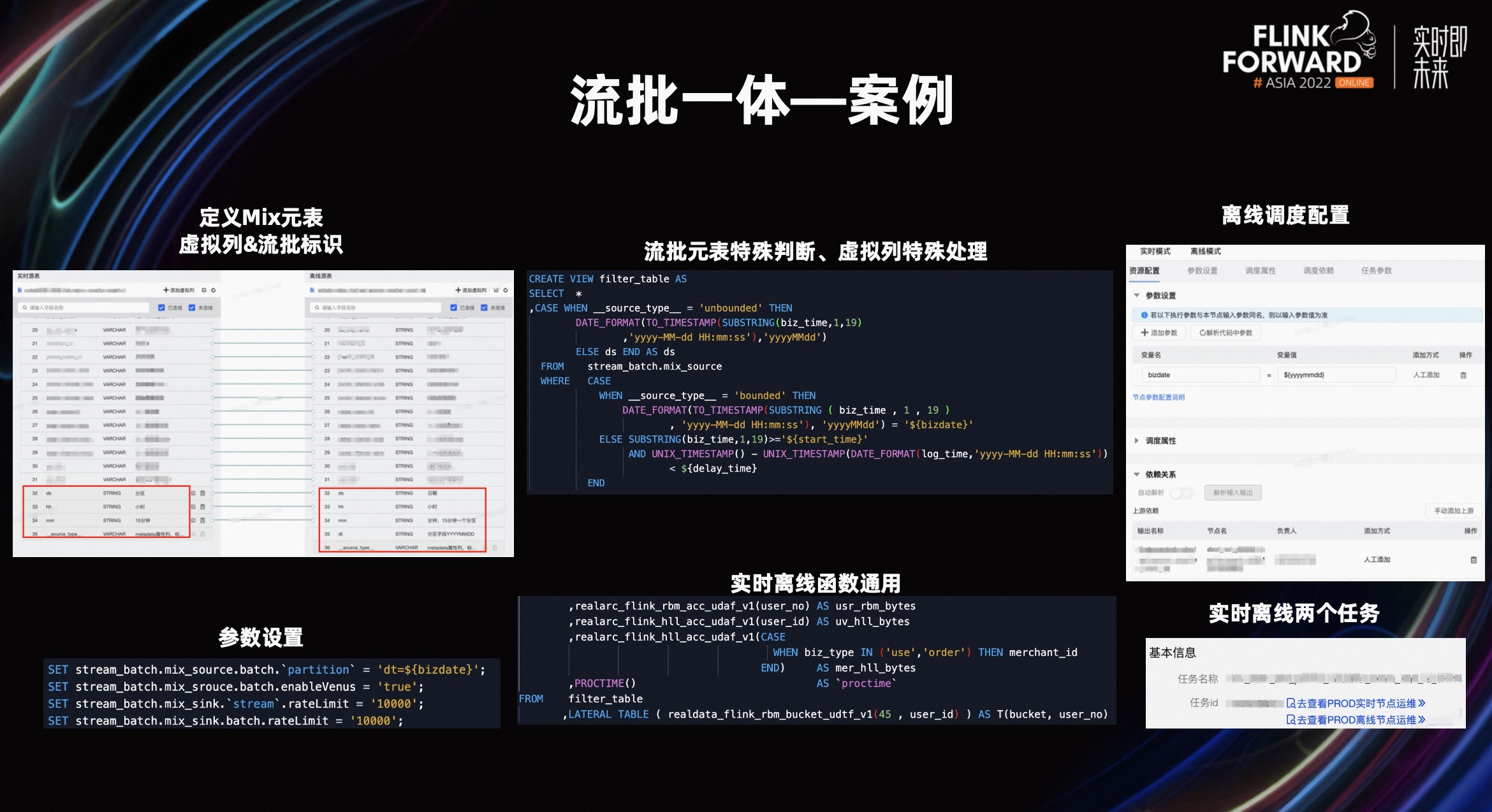
让我们看下这个流批一体的案例,需求是开发双十一活动中的权益领取核销情况,我们通过 Mix 元表定义了实时和离线明细表,在代码里面显式的处理了流和批不同的逻辑,实时侧会对任务开始时间和延迟数据做处理,批则会限制调度日期的数据。
同时该任务开发了 Bitmap 的自定义函数,实时和离线共用一份 UDX 进行计算,最后分别对流和批元表进行参数配置,设置调度属性后即可完成上线,上线后生成两个任务,分别进行运维。
四、规划展望
对于本次分享的低代码和流批一体能力,后续会不断的拓展使用场景,将实时数据应用到更多有价值的地方。同时在实时研发提效和降低门槛这件事情上,会继续往前走,后续两个功能稳定且用户积累一定程度后,会尝试将能力进行整合,在低代码中实现一站式开发。最后则是看向业界都在探索的数据湖命题,希望能够在几个业务场景中将这套较大的解决方案落地。
点击查看原文视频 & 演讲PPT
相关文章:
蚂蚁实时低代码研发和流批一体的应用实践
摘要:本文整理自蚂蚁实时数仓架构师马年圣,在 Flink Forward Asia 2022 流批一体专场的分享。本篇内容主要分为四个部分: 实时应用场景与研发体系低代码研发流批一体规划展望 点击查看原文视频 & 演讲PPT 一、实时应用场景与研发体系 蚂蚁…...

5 创建映射
5 映射 上边章节安装了ik分词器,如果在索引和搜索时去使用ik分词器呢?如何指定其它类型的field,比如日期类型、数 值类型等。 本章节学习各种映射类型及映射维护方法。 5.1 映射维护方法 1、查询所有索引的映射: GET…...
 windows注册表是不区分大小写的.)
windows注册表参数(%1,%2,%v) windows注册表是不区分大小写的.
windows注册表是不区分大小写的. 参数 含义 %1 文件路径 %2 系统默认的打印机 %3 文件扇区 %4 端口 %D 文件路径 %L 文件长路径 %V 文件路径 %W 当前文件的父目录的路径 参考:https://blog.csdn.net/meng_suiga/article/details/79485855 ————…...
基于SpringBoot的大学生租房系统
背景 大学生租房系统设计的目的是建立一个高效的平台,采用简洁高效的Java语言与Mysql数据库等技术,设计和开发了本大学生租房系统设计。该系统主要实现了用户和房主通过系统注册用户,登录系统后能够编辑自己的个人信息、查看首页,…...

NetApp 利用适用于混合云的实时解决方案解决芯片设计方面的数据管理挑战
电子设计自动化 (EDA) 成本持续增加,而周期时间缩短。这些都为 EDA 设计带来了前所未有的挑战,对现代高性能工作流的需求变得从未如此巨大。 联想凌拓芯片设计行业存储解决方案及最佳实践 联想凌拓芯片行业数据存储与管理解决方案,针对EDA…...
Rust + WASM 入门
一、参考资料 参考官方技术文档 https://rustwasm.github.io/ 二、安装脚手架 cargo-generate # cargo-generate 用于快速生成 WASM 项目的脚手架(类似 create-react-app) cargo install cargo-generate 三、下载安装 wasm-pack.exe 打包工具 双击安装…...
【操作系统】内存空间
最小的操作系统Hello world 想要pmap这个进程,需要进程号 但是这个进程在启动的一瞬间就执行完了 用GDB把程序暂停下来,然后用pmap观察地址空间 用info inferiors得到gdb里的进程号 ro 可读 :只读数据 rx 可读可执行 :代码 rw 可…...
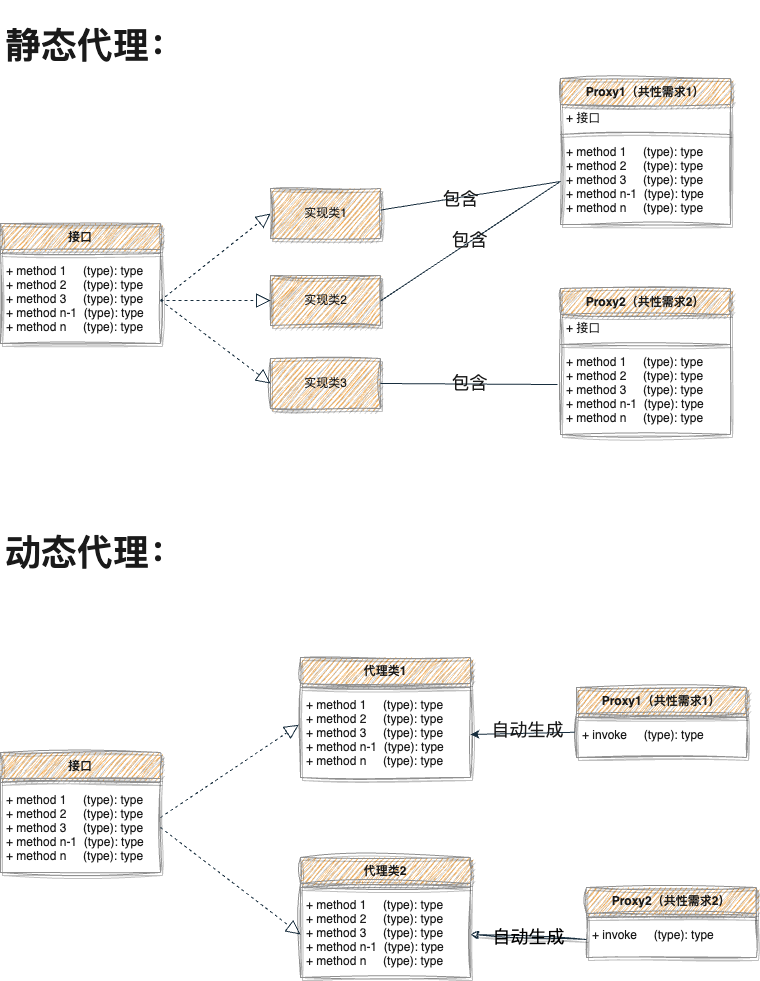
详解静态、动态代理以及应用场景
一篇不太一样的代理模式详解,仔细阅读,你一定会获取不一样的代理见解,而不是人云亦云。 查看了社区里关于代理模式描述,发现很多博客千篇一律甚至存在共性错误,写此文提出自己对代理的见解。 静态代理动态代理 JDKCGLi…...
ChatGLM-6B本地cpu部署
ChatGLM-6B是清华团队研发的机器人对话系统,类似ChatGPT,但是实际相差很多,可以当作一个简单的ChatGPT。 ChatGLM部署默认是支持GPU加速,内存需要32G以上。普通的机器无法运行。但是可以部署本地cpu版本。 本地部署,需…...
算法修炼之练气篇——练气七层
博主:命运之光 专栏:算法修炼之练气篇 前言:每天练习五道题,炼气篇大概会练习200道题左右,题目有C语言网上的题,也有洛谷上面的题,题目简单适合新手入门。(代码都是命运之光自己写的…...

vscode常用快捷方式
基本编辑 Ctrl X:剪切当前行或选定内容 Ctrl C:复制当前行或选定内容 Ctrl V:粘贴当前行或剪切板内容 Ctrl Z:撤销上一步操作 Ctrl Y:恢复上一步撤销的操作 Ctrl F:在当前文件中查找内容 Ctrl H&am…...
如何压缩mp3文件大小,5分钟学会4种方法
如何压缩mp3文件大小?我们在开车的时候都很喜欢听歌,一般歌曲库里的mp3文件都很多,小编的就有上千首。如果我们还想要增加更多mp3文件,有时候就会出现内存不足的情况啦。所以我们需要压缩mp3文件大小,这样才能在我们手…...
从0搭建Vue3组件库(十二):引入现代前端测试框架 Vitest
Vitest 是个高性能的前端单元测试框架,它的用法其实和 Jest 差不多,但是它的性能要优于 Jest 不少,还提供了很好的 ESM 支持,同时对于使用 vite 作为构建工具的项目来说有一个好处就是可以公用同一个配置文件vite.config.js。因此本项目将会使用 Vitest 作为测试框架。 安装 …...
使用Handler创建一个Android秒表应用
本文所有代码都放在以下链接中:https://github.com/MADMAX110/Stopwatch 0、应用是一个有活动、布局和其他资源组成的集合。其中一个活动是应用的主活动。每个应用都有一个主活动,在文件AndroidManifest.xml中指定。 1、默认地,每个应用都在…...

node-sass安装失败解决方法总结
node-sass 安装失败的原因 npm 安装 node-sass 依赖时,会从 github.com 上下载 .node 文件。由于国内网络环境的问题,这个下载时间可能会很长,甚至导致超时失败。 解决方法一:使用淘宝镜像源(推荐) npm …...

C++特殊类设计
文章目录 1.设计一个类,不能被拷贝2.设计一个类,只能在堆上创建对象3.设计一个类,只能在栈上创建对象4.设计一个类,不能被继承5.设计一个类,只能创建一个对象5.1 单例模式5.2 饿汉模式5.3 懒汉模式5.4 两种模式的析构函…...

常用的python gpu加速方法
在使用 PyCharm进行机器学习的时候,我们常常需要自己创建一些函数,这个过程中可能会浪费一些时间,在这里,我们为大家整理了一些常用的 Python加速方法,希望能给大家带来帮助。 在 Python中,我们经常需要创建…...
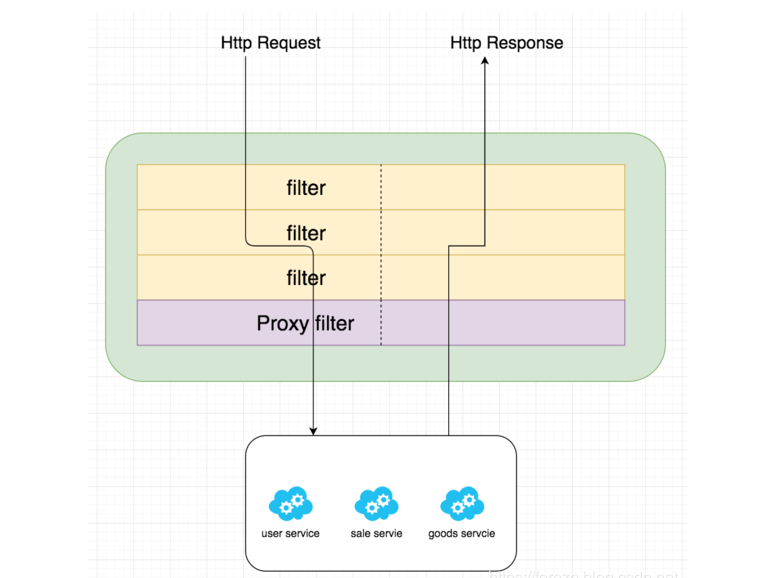
SpringCloud-Gateway
什么是网关? 网关是一个服务,是访问内部系统的唯一入口,提供内部服务的路由中转,额外还可以在此基础上提供如身份验证、监控、负载均衡、限流、降级与应用检测等功能。 Spring Cloud Gateway 与 Zuul 对比 zuul1.x与zuul2.x Zu…...

【C++ qt4】操作json学习笔记
本博文源于笔者在学习c qt4操作json文件,qt4不支持json,里面的函数是json.h与jsoncpp.cpp我已经附在文末,大家可复制重命名用,里面的案例可以自己拿来敲或者直接copy也行.,一定利用好目录拖动,不然很长。 文章目录 1.从…...
【牛客刷题专栏】0x25:JZ24 反转链表(C语言编程题)
前言 个人推荐在牛客网刷题(点击可以跳转),它登陆后会保存刷题记录进度,重新登录时写过的题目代码不会丢失。个人刷题练习系列专栏:个人CSDN牛客刷题专栏。 题目来自:牛客/题库 / 在线编程 / 剑指offer: 目录 前言问…...

Unity-MCP协议:可嵌入、可协商的AI上下文通信标准
1. 这不是又一个“AI插件”,而是Unity开发工作流的底层重定义你有没有过这样的时刻:在Unity里反复调整Animator Controller的过渡条件,只为让角色转身动画不穿模;写完一段NavMesh寻路逻辑,却要花两小时调试Agent卡在斜…...

ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题
ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vari…...
 —— STM32的SPI外设)
STM32单片机学习(28) —— STM32的SPI外设
文章目录概述SPI通信的移位机制(以bit为单位)SPI外设框图第一部分:数据通路SPI通信的数据帧格式SPI外设移位机制(以字节为单位)第二部分:主机时钟生成器SPI通信时钟频率与传输速率第三部分:主从…...

别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务
别再只用Service了!ROS1 Action通信保姆级教程:从导航进度条到任务取消,手把手教你实现带反馈的机器人任务当你的机器人正在执行一个长达10分钟的导航任务时,突然发现目标点设置错误,这时候如果只能干等着任务完成或者…...

Hirschmann RS20-0800M4M4SDAE工业以太网交换机
Hirschmann RS20-0800M4M4SDAE 工业以太网交换机产品特点:端口配置:共8个端口,含6个RJ45电口和2个ST光纤接口。端口速率:所有端口均为100Mbps快速以太网。光纤类型:2个光纤端口为多模、ST接头。管理类型:二…...

高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析
高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析 【免费下载链接】srs-windows 项目地址: https://gitcode.com/gh_mirrors/sr/srs-windows 在Windows平台上构建专业级流媒体服务系统,需要综合考虑协议兼容性、性能优化和部署架…...

小米MIMO最新邀请码
欢迎使用,各得10元体验金...

ARM PMU性能监控单元原理与实践指南
1. ARM PMU性能监控单元概述性能监控单元(PMU)是现代ARM处理器中用于硬件级性能分析的核心组件。它通过一组可编程的硬件计数器,实现对处理器内部各种关键事件的精确测量。这些事件涵盖了从指令执行、缓存访问到内存子系统行为等处理器活动的…...

PCB虚焊/走线断裂/焊盘脱落工程师易漏判
PCB 故障中,30% 并非元件损坏,而是 PCB 本身的隐性故障—— 虚焊、走线断裂、焊盘脱落、过孔开路。这类故障外观隐蔽、时好时坏、排查难度大,很多工程师反复更换元件仍无法解决,最终误判为 “板报废”。一、PCB 隐性故障核心成因…...

可解释AI新突破:基于局部帕累托最优的模型解释框架
1. 项目概述:当AI模型成为“黑箱”,我们如何撬开它?在机器学习项目里摸爬滚打十几年,我见过太多这样的场景:团队花大力气训练出一个准确率高达95%的复杂模型(比如深度神经网络),业务…...