【论文阅读】Pseudo-Labeling and Confirmation Bias in Deep Semi-Supervised Learning
论文下载
GitHub
bib:
@INPROCEEDINGS{,title = {Pseudo-Labeling and Confirmation Bias in Deep Semi-Supervised Learning},author = {Eric Arazo and Diego Ortego and Paul Albert and Noel E O'Connor and Kevin McGuinness},booktitle = {IJCNN},year = {2020},pages = {1--8}
}
1. 摘要
Semi-supervised learning, i.e. jointly learning from labeled and unlabeled samples, is an active research topic due to its key role on relaxing human supervision.
总览半监督学习。
In the context of image classification, recent advances to learn from unlabeled samples are mainly focused on consistency regularization methods that encourage invariant predictions for different perturbations of unlabeled samples.
提到半监督分类中的一致性正则。
We, conversely, propose to learn from unlabeled data by generating soft pseudo-labels using the network predictions.
提到本文中适用了伪标签技术(soft pseudo-labels)。
We show that a naive pseudo-labeling overfits to incorrect pseudo-labels due to the so-called confirmation bias and demonstrate that mixup augmentation and setting a minimum number of labeled samples per mini-batch are effective regularization techniques for reducing it.
核心的贡献。提出了确认偏差(confirmation bias),本文贡献是证明了mixup augmentation和setting a minimum number of labeled samples per mini-batch是有效减少确认偏差的正则技术。
The proposed approach achieves state-of-the-art results in CIFAR-10/100, SVHN, and Mini-ImageNet despite being much simpler than other methods.
These results demonstrate that pseudo-labeling alone can outperform consistency regularization methods, while the opposite was supposed in previous work.
这一点就很令人惊讶了,伪标签技术的方法超过了一致性正则的方法。还没看原文,应该是还没有出现FixMatch和FlexMatch方法。
2. 算法描述
| 符号 | 意义 |
|---|---|
| D l = { ( x i , y i ) } i = 1 N l D_l = \{(x_i, y_i)\}^{N_l}_{i=1} Dl={(xi,yi)}i=1Nl | 有标记数据 |
| D u = { x i } i = 1 N u D_u = \{x_i\}^{N_u}_{i=1} Du={xi}i=1Nu | 无标记数据 |
| D ~ u = { ( x i , y ~ i } i = 1 N \widetilde{D}_u = \{(x_i, \widetilde{y}_i\}^{N}_{i=1} D u={(xi,y i}i=1N | 训练数据,其中对于有标记数据 y ~ i \widetilde{y}_i y i表示真实标签,对于无标记数据 y ~ i \widetilde{y}_i y i表示对应伪标签。 |
| h θ h_{\theta} hθ | 模型及对应的参数 θ \theta θ |
经典的交叉熵损失函数:
ℓ ∗ ( θ ) = − ∑ i = 1 N y ~ i T log ( h θ ( x i ) ) (1) \ell^*(\theta) = -\sum_{i=1}^{N}\widetilde{y}_i^{\mathsf{T}}\log(h_{\theta}(x_i)) \tag{1} ℓ∗(θ)=−i=1∑Ny iTlog(hθ(xi))(1)
Note:
In particular, we store the softmax predictions h θ ( x i ) h_{\theta}(x_i) hθ(xi) of the network in every mini-batch of an epoch and use them to modify the soft pseudo-label y ~ \widetilde{y} y for the N u N_u Nu unlabeled samples at the end of every epoch.
We proceed as described from the second to the last training epoch, while in the first epoch we use the softmax predictions for the unlabeled samples from a model trained in a 10 epochs warm-up phase using the labeled data subset D u D_u Du.
Soft pseudo-labels在本文中表示上一个阶段网络对于无标记样本的预测。注意区别于Hard pseudo-labels,Soft pseudo-labels不是one-hot向量,而是对于样本预测的概率向量(softmax)。
Two Regularizations:
ℓ = ℓ ∗ + λ A R A + λ H R H (2) \ell = \ell^*+\lambda_A R_A + \lambda_H R_H \tag{2} ℓ=ℓ∗+λARA+λHRH(2)
where
- R A = ∑ c = 1 C p c log ( p c h ‾ c ) R_A = \sum_{c=1}^{C}p_c\log(\frac{p_c}{\overline{h}_c}) RA=∑c=1Cpclog(hcpc);
- R H = − 1 N ∑ i = 1 N ∑ c = 1 C h θ c ( x i ) log ( h θ c ( x i ) ) R_H = -\frac{1}{N}\sum_{i=1}^{N}\sum_{c=1}^{C}h_{\theta}^c(x_i) \log(h_{\theta}^c(x_i)) RH=−N1∑i=1N∑c=1Chθc(xi)log(hθc(xi)).
R A R_A RA不鼓励将所有样本分配到单个类。其中 p c p_c pc表示类别 c c c的先验概率分布, h ‾ c \overline{h}_c hc表示模型在数据集中所有 c c c类别样本中的平均概率(softmax)。意思是本来有猫有狗的类别,网络为了省事,直接不管三七二十一,直接预测一个猫,这个现象在不平衡数据集上很容易出现。
R H R_H RH(entropy regularization)鼓励每个软伪标记的概率分布集中在单个类上,避免了网络可能因弱引导而陷入的局部最优。这一点容易理解,就是对于一个样本,鼓励预测的类的概率远远大于其他类别。
Confirmation bias:
Overfitting to incorrect pseudo-labels predicted by the network is known as confirmation bias.
It is natural to think that reducing the confidence of the network on its predictions might alleviate this problem and improve generalization.
Note: 这里将确认偏差(confirmation bias)定义为网络对于不正确伪标签的过拟合。降低对于不正确标签的权重可以缓解这一现象。
mixup regularization:
Recently, mixup data augmentation introduced a strong regularization technique that combines data augmentation with label smoothing, which makes it potentially useful to deal with this bias.
Question:
- mixup的细节,在单个批次中,怎么mixup?
- mixup样本的标签如何确定?
setting a minimum number of labeled samples per mini-batch:
Oversamplingthe labelled examples by setting a minimum number of labeled samples per mini-batch k (as done in other works provides a constant reinforcement with correct labels during training, reducing confirmation bias and helping to produce better pseudo-labels.
Question:
- 单个批次样本如何配置,多少个有标记数据,多少个无标记数据?
相关文章:

【论文阅读】Pseudo-Labeling and Confirmation Bias in Deep Semi-Supervised Learning
论文下载 GitHub bib: INPROCEEDINGS{,title {Pseudo-Labeling and Confirmation Bias in Deep Semi-Supervised Learning},author {Eric Arazo and Diego Ortego and Paul Albert and Noel E OConnor and Kevin McGuinness},booktitle {IJCNN},year {2020},pages …...
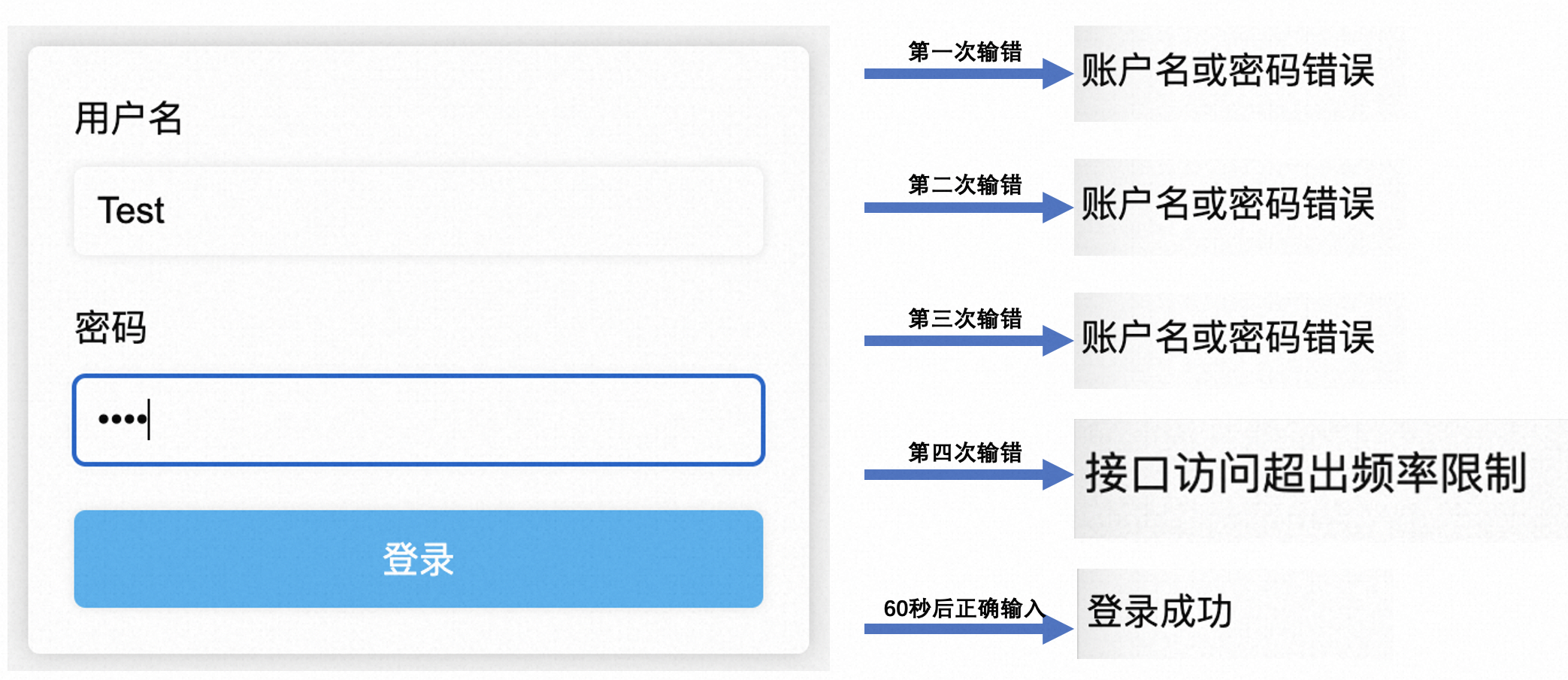
三次输错密码后,系统是怎么做到不让我继续尝试的?
故事背景 忘记密码这件事,相信绝大多数人都遇到过,输一次错一次,错到几次以上,就不允许你继续尝试了。 但当你尝试重置密码,又发现新密码不能和原密码重复: 相信此刻心情只能用一张图形容: 虽…...
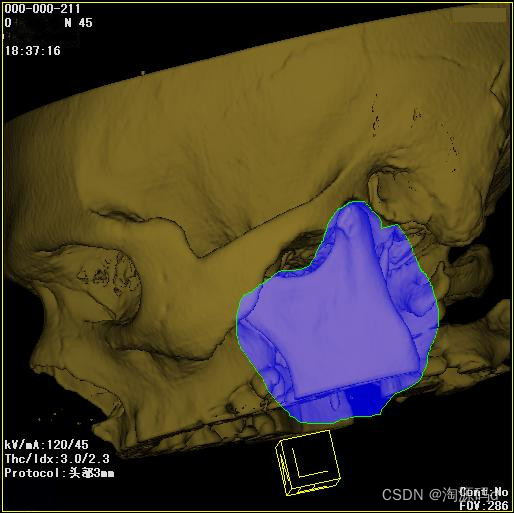
医学影像系统源码,三维后处理和重建 PACS源码
医学影像系统源码,三维后处理和重建 PACS源码 医学影像系统由PACS系统、RIS系统组成,提供与HIS的接口(HL7或其他类型)。 主要功能介绍 信息预约登记 支持对患者、检查项目、申请医生、申请单据、设备等信息进行管理。且支持检查…...
)
golang汇编之函数(四)
基本语法 函数标识符通过TEXT汇编指令定义,表示该行开始的指令定义在TEXT内存段。TEXT语句后的指令一般对应函数的实现,但是对于TEXT指令本身来说并不关心后面是否有指令。我个人觉得TEXT和LABEL定义的符号是类似的,区别只是LABEL是用于跳转…...
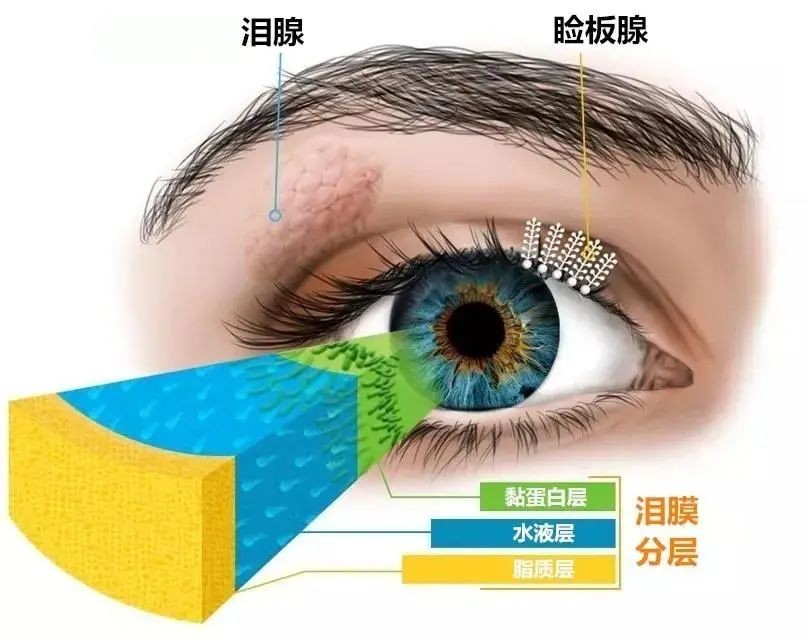
成都爱尔李晓峰主任:眼睛干到发出求救信号,快注意!
眼睛总感觉痒痒的,时不时干涩、酸胀、畏光? 它在提醒你,它太干了救救它! 干眼如何判断? 干眼症是由于泪液的质和量异常或者泪液的流体动力学障碍而导致眼表无法保持湿润的一种眼病。会发生眼睛干涩、酸胀、畏光、灼热感、异物感、看东西容易…...

HiEV独家 | 比亚迪高阶智驾终于来了 ,新款汉首发,多车型将搭载
作者 | 德新 编辑 | 马波 比亚迪上马高阶辅助驾驶,首先从高速NOA开始。 HiEV获悉,今年第三季度,比亚迪将在新的 汉车型 上,搭载高速领航辅助驾驶功能(俗称高速NOA)。继汉之后,王朝系列唐…...
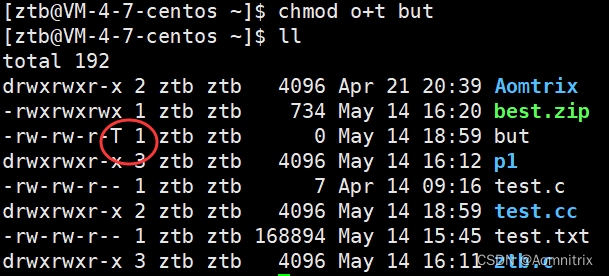
全面解析Linux指令和权限管理
目录 一.指令再讲解1.时间相关的指令2.find等搜索指令与grep指令3.打包和压缩相关的指令4.一些其他指令与热键二.Linux权限1.Linux的权限管理2.文件类型与权限设置3.目录的权限与粘滞位 一.指令再讲解 1.时间相关的指令 date指令: date 用法:date [OPTION]… [FOR…...

C++ enum 和enum class
文章目录 C enum 和 enum class共同点区别 C enum 和 enum class 在C中, enum 是一种定义枚举类型的方法。 一个枚举是一个整数值的命名集合。 可以通过以下方式创建一个枚举类型: enum Color {RED,GREEN,BLUE };这里我们定义了一个名为 Color 的枚举类…...

设计模式之中介者模式
参考资料 曾探《JavaScript设计模式与开发实践》;「设计模式 JavaScript 描述」中介者模式JavaScript 设计模式之中介者模式 定义 在我们生活的世界中,每个人每个物体之间都会产生一些错综复杂的联系。在应用程序里也是一样,程序由大大小小…...
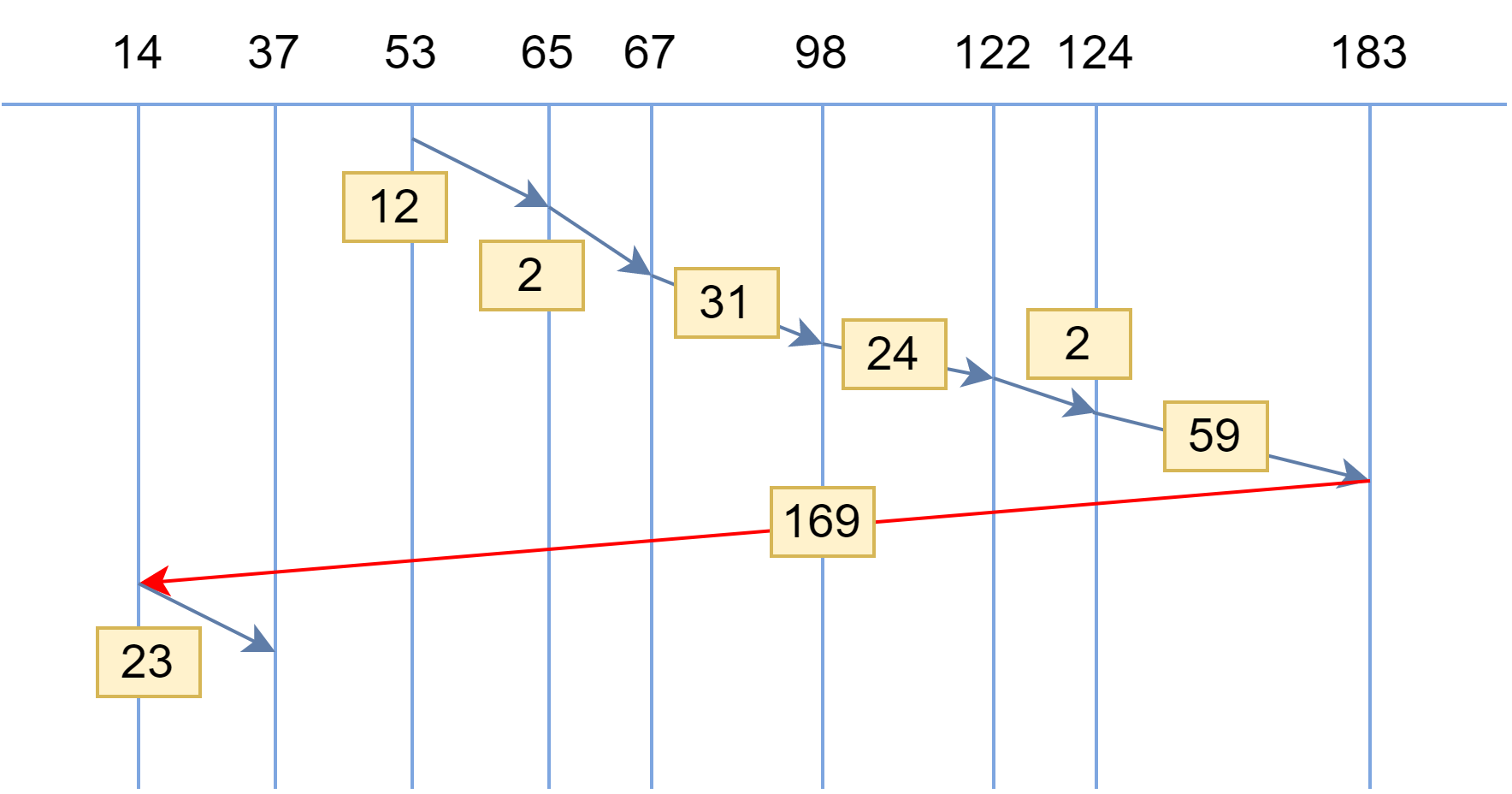
DJ5-8 磁盘存储器的性能和调度
目录 5.8.1 磁盘性能简述 1、磁盘的结构和布局 2、磁盘的类型 3、磁盘数据的组织和格式 4、磁盘的访问过程 5、磁盘访问时间 5.8.2 磁盘调度算法 1、先来先服务 FCFS 2、最短寻道时间优先 SSTF 3、扫描算法(电梯算法)SCAN 4、循环扫描算法 …...

springboot+vue留守儿童爱心网站(源码+文档)
风定落花生,歌声逐流水,大家好我是风歌,混迹在java圈的辛苦码农。今天要和大家聊的是一款基于springboot的留守儿童爱心网站。项目源码以及部署相关请联系风歌,文末附上联系信息 。 💕💕作者:风…...
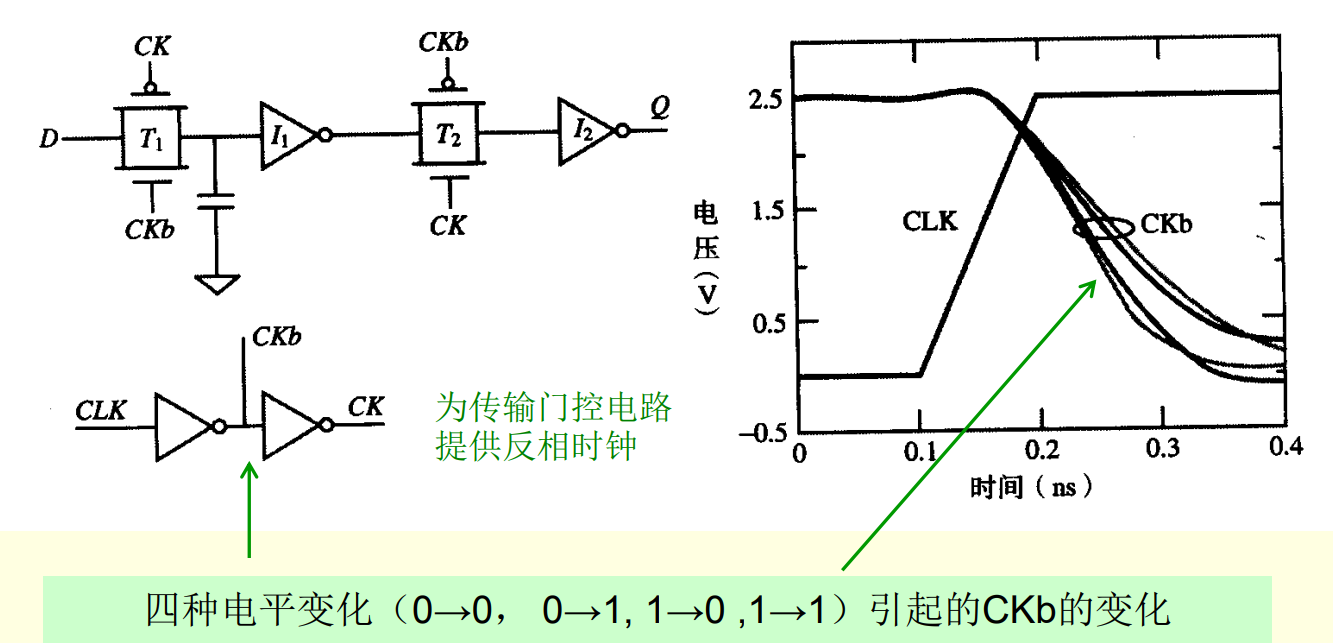
数字设计小思 - 谈谈非理想时钟的时钟偏差
写在前面 本系列整理数字系统设计的相关知识体系架构,为了方便后续自己查阅与求职准备。在FPGA和ASIC设计中,时钟信号的好坏很大程度上影响了整个系统的稳定性,本文主要介绍了数字设计中的非理想时钟的偏差来源与影响。 (本文长…...

智慧厕所引导系统的应用
智慧公厕引导系统是一种基于智能化技术的公厕管理系统,可以为如厕者提供更加便捷、舒适、安全的如厕环境和服务,同时也可以引导如厕者文明如厕,营造文明公厕的氛围。智慧公厕引导系统可以通过智能引导屏、手机小程序等方式,为如厕…...
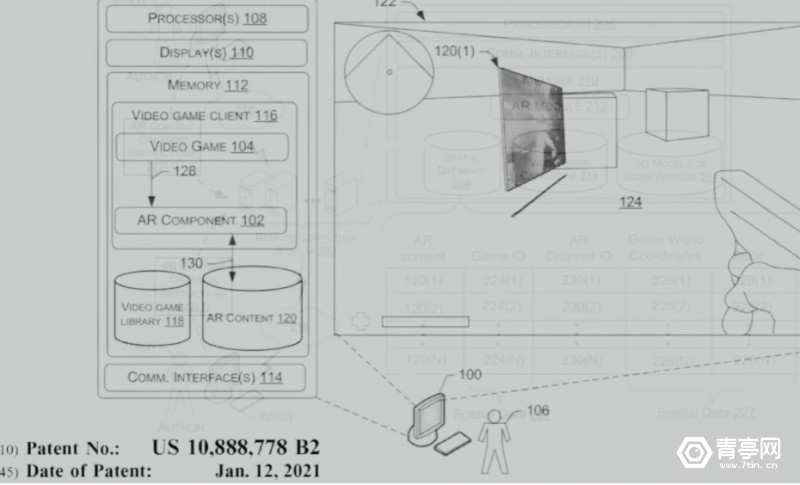
眼球追踪、HDR、VST,从代码挖掘Valve下一代VR头显
擅长爆料、挖掘线索的Brad Lynch,此前发布了Quest Pro等设备的线索文章引发关注。近期,又公布一系列与“Valve Deckard”VR头显相关消息,比如支持眼球追踪、HDR、VST透视、Wi-Fi网络等等。在SteamVR 1.26.1测试版更新、Steam用户端、Gamesc…...
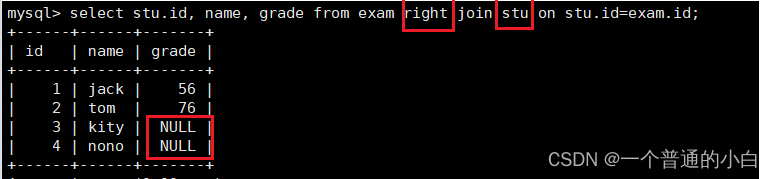
【MYSQL】聚合函数和单表/多表查询练习、子查询、内外连接
目录 1.聚合函数 1.1.group by子句 1.2.having语句 2.单表查询 2.2单表查询 3.多表查询 3.2.子查询 5.内链接 6.外连接 1.聚合函数 函数说明count返回查询到的数据的数量sum返回查询到的数据的总和avg返回查询到的数据的平均值max返回查询到的数据的最大值min返回查询…...
分布式数据库集成解决方案
分布式数据库集成解决方案 分析访问部署扩展.1 以界面方式创建数据库(采用DBCA) # 背景 由于公司业务的发展,要求在其它三个城市设立货仓,处理发货业务。公司本部运行着一套用Sybase数据库的MIS系统可以实现发货,该系统…...

如何配置静态路由?这个实例详解交换机的静态路由配置
一、什么是静态路由 静态路由是一种路由的方式,它需要通过手动配置。静态路由与动态路由不同,静态路由是固定的,不会改变。一般来说,静态路由是由网络管理员逐项加入路由表,简单来说,就是需要手动添加的。…...

OpenCV教程——图像操作。读写像素值,与/或/非/异或操作,ROI
1.读取像素值 我们可以通过mat.ptr<uchar>()获取图像某一行像素数组的指针。因此如果想要读取点(x50,y0)(⚠️即(row0,col50))的像素值,可以这样做:mat.ptr<uchar>(0)[50]。 在本节将介绍另外几种直接读…...
Winforms不可见组件开发
Winforms不可见组件开发 首先介绍基本知识,有很多的朋友搞不清楚Component与Control之间的区别,比较简单形象的区别有下面两点: 1、Component在运行时不能呈现UI,而Control可以在运行时呈现UI。 2、Component是贴在容器Container上的,而Control则是贴…...

静态链接库与动态链接库
静态链接库与动态链接库 一、从源程序到可执行文件二、编译、链接和装入三、静态链接库与动态链接库四、静态链接库与动态链接库的制作与使用1.静态库的制作及使用2.动态库的制作及使用 一、从源程序到可执行文件 由于计算机无法直接理解和执行高级语言(C、C、Java…...

AMLP:基于大语言模型的自动化机器学习势函数构建平台
1. 项目概述:当AI遇见原子模拟,AMLP如何重塑机器学习势函数构建在计算材料科学和化学物理领域,分子动力学模拟是我们窥探微观世界动态行为的“显微镜”。无论是研究新材料的相变过程,还是探索生物大分子的折叠机制,其核…...

ARM指令追踪技术及TRCVICTLR寄存器详解
1. ARM指令追踪技术概述在嵌入式系统开发和调试过程中,指令追踪(Instruction Trace)是一项至关重要的技术。它通过硬件机制记录处理器的执行流程,为开发者提供程序运行的完整轨迹。ARM架构从v7开始引入嵌入式跟踪宏单元࿰…...

Unity发行版DLL调试实战:DnSpy无源码IL级断点指南
1. 这不是“反编译”,而是Unity游戏开发者的日常调试手段你有没有遇到过这样的情况:接手一个Unity发行版游戏,想快速验证某个功能逻辑是否按预期执行,或者排查一个偶发的崩溃,但手头只有打包后的Assembly-CSharp.dll&a…...

LangGraph状态机工程:构建复杂AI工作流的完整指南
传统RAG(检索增强生成)在处理简单的"单跳"问题时表现良好——“文章里提到了什么” “这个概念是什么意思”——但当问题涉及多个实体之间的关系、需要跨多个文档推理时,传统RAG就显得力不从心。GraphRAG(Graph-based R…...

CausalVLR基准测试报告:在IU X-Ray和MIMIC-CXR数据集上的性能分析
CausalVLR基准测试报告:在IU X-Ray和MIMIC-CXR数据集上的性能分析 【免费下载链接】CausalVLR CausalVLR: A Toolbox and Benchmark for Vision-Language Causal Reasoning (多模态因果推理开源框架) 项目地址: https://gitcode.com/gh_mirrors/ca/CausalVLR …...

探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破
探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破 【免费下载链接】WSA-Windows-10 This is a backport of Windows Subsystem for Android to Windows 10. 项目地址: https://gitcode.com/gh_mirrors/ws/WSA-Windows-10 想象一下&#…...

PrivacyGuard实战:基于实证差分隐私的机器学习模型隐私审计框架
1. 项目概述与核心价值在过去的几年里,我亲眼见证了机器学习模型从实验室走向银行、医疗、社交网络等各个敏感领域的全过程。模型性能的每一次飞跃都令人兴奋,但随之而来的隐私泄露事件也一次次为我们敲响警钟。一个在医疗数据上训练出的诊断模型&#x…...

如何快速掌握MPC视频渲染器:面向初学者的完整教程
如何快速掌握MPC视频渲染器:面向初学者的完整教程 【免费下载链接】VideoRenderer Внешний видео-рендерер 项目地址: https://gitcode.com/gh_mirrors/vi/VideoRenderer 想要在Windows系统上获得影院级的视频播放体验吗?MPC…...
提升你的图表专业度?)
从科研图表到商业报表:如何用Matplotlib的legend()提升你的图表专业度?
从科研图表到商业报表:如何用Matplotlib的legend()提升你的图表专业度? 在数据驱动的决策时代,图表不仅是科研论文中的证据载体,更是商业汇报中的说服工具。我曾见证一位生物统计学家将同一组临床试验数据呈现给三种不同受众&…...

TII投稿避坑指南:LaTeX模板编译报错‘xxx-eps-converted-to.pdf not found’的终极解决方案
TII投稿LaTeX避坑实战:从编译报错到完美PDF生成的终极指南 凌晨三点的实验室,屏幕上闪烁的xxx-eps-converted-to.pdf not found错误提示仿佛在嘲笑你连续八小时的徒劳尝试。这不是科幻场景,而是每位用LaTeX撰写TII论文的研究者都可能遭遇的真…...