【计算机视觉 | Pytorch】timm 包的具体介绍和图像分类案例(含源代码)
一、具体介绍
timm 是一个 PyTorch 原生实现的计算机视觉模型库。它提供了预训练模型和各种网络组件,可以用于各种计算机视觉任务,例如图像分类、物体检测、语义分割等等。
timm 的特点如下:
- PyTorch 原生实现:timm 的实现方式与 PyTorch 高度契合,开发者可以方便地使用 PyTorch 的 API 进行模型训练和部署。
- 轻量级的设计:timm 的设计以轻量化为基础,根据不同的计算机视觉任务,提供了多种轻量级的网络结构。
- 大量的预训练模型:timm 提供了大量的预训练模型,可以直接用于各种计算机视觉任务。
- 多种模型组件:timm 提供了各种模型组件,如注意力模块、正则化模块、激活函数等等,这些模块都可以方便地插入到自己的模型中。
- 高效的代码实现:timm 的代码实现高效并且易于使用。
需要注意的是,timm 是一个社区驱动的项目,它由计算机视觉领域的专家共同开发和维护。在使用时需要遵循相关的使用协议。
二、图像分类案例
下面以使用 timm 实现图像分类任务为例,进行简单的介绍。
2.1 安装 timm 包
!pip install timm
2.2 导入相关模块,读取数据集
import torch
import torch.nn as nn
import timm
import torchvision.transforms as transforms
from torchvision.datasets import CIFAR10# 数据增强
train_transforms = transforms.Compose([transforms.RandomCrop(size=32, padding=4),transforms.RandomHorizontalFlip(p=0.5),transforms.RandomRotation(degrees=15),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])test_transforms = transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])# 数据集
train_dataset = CIFAR10(root='data', train=True, download=True, transform=train_transforms)
test_dataset = CIFAR10(root='data', train=False, download=True, transform=test_transforms)# DataLoader
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=4)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=4)
导入相关模块,其中 timm 和 torchvision.datasets.CIFAR10 需要分别安装 timm 和 torchvision 包。
定义数据增强的方式,其中训练集和测试集分别使用不同的增强方式,并且对图像进行了归一化处理。transforms.Compose() 可以将各种操作打包成一个 transform 操作流,transforms.ToTensor() 将图像转化为 tensor 格式,transforms.Normalize() 将图像进行标准化处理。
使用自带的 CIFAR10 数据集,设置 train=True 定义训练集,设置 train=False 定义测试集。数据集会自动下载到指定的 root 路径下,并进行数据增强操作。
使用 torch.utils.data.DataLoader 定义数据加载器,将数据集包装成一个高效的可迭代对象,其中 batch_size 定义批次大小,shuffle 定义是否对数据进行随机洗牌,num_workers 定义使用多少个 worker 来加载数据。

2.3 定义模型
# 加载预训练模型
model = timm.create_model('resnet18', pretrained=True)# 修改分类器
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, len(train_dataset.classes))
这里使用 timm.create_model() 函数来创建一个预训练模型,其中参数 resnet18 定义了使用的模型架构,参数 pretrained = True 表示要使用预训练权重。
这里修改了模型的分类器,首先使用 model.fc.in_features 获取模型 fc 层的输入特征数,然后使用 nn.Linear() 重新定义了一个 nn.Linear 层,输入为上一层的输出特征数,输出为类别数(即 len(train_dataset.classes))。这里直接使用了数据集类别数来定义输出层,以适配不同分类任务的需求。

在这里,我们使用了 timm 中的 ResNet18 模型,并将其修改为我们需要的分类器,同时在创建模型时,设置参数 pretrained=True 来加载预训练权重。
2.4 定义损失函数和优化器
# 损失函数
criterion = nn.CrossEntropyLoss()# 优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
在深度学习中,损失函数是评估模型预测结果与真实标签之间差异的一种指标,常用于模型训练过程中。nn.CrossEntropyLoss() 是一个常用的损失函数,适用于多分类问题。
优化器用于更新模型参数以使损失函数最小化。在这里,我们使用了随机梯度下降法(SGD)优化器,以控制模型权重的变化。通过 model.parameters() 指定需要优化的参数,lr 定义了学习率,表示每次迭代时参数必须更新的量的大小,momentum 则是添加上次迭代更新值的一部分到这一次的更新值中,以减小参数更新的方差,稳定训练过程。
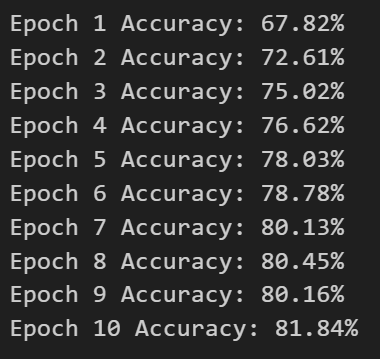
2.5 训练模型
num_epochs = 10for epoch in range(num_epochs):# 训练model.train()for images, labels in train_loader:# 前向传播outputs = model(images)# 计算损失loss = criterion(outputs, labels)# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()# 测试model.eval()with torch.no_grad():correct = 0total = 0for images, labels in test_loader:outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Epoch {} Accuracy: {:.2f}%'.format(epoch+1, 100*correct/total))
这段代码是模型训练和测试的循环。num_epochs 定义了循环的次数,每次循环表示一个训练周期。
在训练阶段,首先将模型切换到训练模式,然后使用 train_loader 迭代地读取训练集数据,进行前向传播、计算损失、反向传播和优化器更新等操作。
在测试阶段,模型切换到评估模式,然后使用 test_loader 读取测试集数据,进行前向传播和计算模型预测结果,使用预测结果和真实标签进行准确率计算,并输出每个训练周期的准确率。
其中,torch.max() 函数用于返回每行中最大值及其索引,total 记录了总的测试样本数,correct 记录了正确分类的样本数,最后计算准确率并输出。
输出结果为:
相关文章:
【计算机视觉 | Pytorch】timm 包的具体介绍和图像分类案例(含源代码)
一、具体介绍 timm 是一个 PyTorch 原生实现的计算机视觉模型库。它提供了预训练模型和各种网络组件,可以用于各种计算机视觉任务,例如图像分类、物体检测、语义分割等等。 timm 的特点如下: PyTorch 原生实现:timm 的实现方式…...

轻博客Plume的搭建
什么是 Plume ? Plume 是一个基于 ActivityPub 的联合博客引擎。它是用 Rust 编写的,带有 Rocket 框架,以及 Diesel 与数据库交互。前端使用 Ructe模板、WASM 和SCSS。 反向代理 假设我们实际访问地址为: https://plume.laosu.ml…...

机器人关节电机PWM
脉冲宽度调制(Pulse width modulation,PWM)技术。一种模拟控制方式 机器人关节电机的控制通常使用PWM(脉冲宽度调制)技术。PWM是一种用于控制电子设备的技术,通过控制高电平和低电平之间的时间比例,实现对电子设备的控制。在机器人关节电机中,PWM信号可以控制电机的…...

MPU6050详解(含源码)
前言:MPU6050是一款强大的六轴传感器,需要理解MPU6050首先得有IIC的基础,MPU6050 内部整合了 3 轴陀螺仪和 3 轴加速度传感器,并且含有一个第二 IIC 接口,可用于连接外部磁力传感器,内部有硬件算法支持. 1…...

Vue入门学习笔记:TodoList(三):实例中的数据、事件和方法
目录: Vue入门学习笔记:TodoList(一):HelloWorld Vue入门学习笔记:TodoList(二):挂载点、模板、实例 Vue入门学习笔记:TodoList(三)&a…...

怎么找到引发回流的JavaScript代码?
要找到引发回流的JavaScript代码,可以使用浏览器的开发者工具中的性能分析器。不同的浏览器有不同的名称和位置,例如Google Chrome的开发者工具中的性能分析器被称为Performance,Firefox的开发者工具中的性能分析器被称为Profiler。 以下是在…...

未来广告策划,转型还是淘汰?
在广告行业呆了十来年了,最近我越来越感觉到广告行业真的是一个需要与时俱进,并且应用场景非常广泛的一个专业。 而且由于这是一个需要创意能力的行业,所以对比于重复性容易被机器以及人工智能所代替的岗位行业来说,广告的可替代…...

【vscode远程开发】使用SSH远程连接服务器 「内网穿透」
文章目录 前言视频教程1、安装OpenSSH2、vscode配置ssh3. 局域网测试连接远程服务器4. 公网远程连接4.1 ubuntu安装cpolar内网穿透4.2 创建隧道映射4.3 测试公网远程连接 5. 配置固定TCP端口地址5.1 保留一个固定TCP端口地址5.2 配置固定TCP端口地址5.3 测试固定公网地址远程 转…...

七天从零实现Web框架Gee - 扩展
到这里前七天的任务已经完成,但我们可以对Gee框架进行一些扩展 补充HTTP请求方法 原作者只实现了 GET, POST 路由添加,其他的 PUT, DELETE 等标准 HTTP 方法未实现,实现方法也很简单,只需在gee.go中增加如下代码 // PUT define…...

什么是土壤水分传感器
土壤水分传感器又称土壤湿度传感器由不锈钢探针和防水探头构成,可长期埋设于土壤和堤坝内使用,对表层和深层土壤进行墒情的定点监测和在线测量。与数据采集器配合使用,可作为水分定点监测或移动测量的工具(即农田墒情检测仪&#…...

月薪17k需要什么水平?98年测试员的面试全过程…
我的情况 大概介绍一下个人情况,男,本科,三年多测试工作经验,懂python,会写脚本,会selenium,会性能,然而到今天都没有收到一份offer!从年后就开始准备简历,年…...

知了汇智:坚持发展产教融合,做好高校、人才与企业之间的桥梁
6月将正式迎来高校毕业季,大学生就业是聚焦全社会关注的头等大事。5月9日,成都知了汇智科技有限公司(以下简称“知了汇智”)组织开展“深化产教融合、聚焦人才培养”的主题座谈会议,联动高校与合作企业参加,…...
MyBatis缓存-一级缓存--二级缓存的非常详细的介绍
目录 MyBatis-缓存-提高检索效率的利器 缓存-官方文档 一级缓存 基本说明 一级缓存原理图 代码演示 修改MonsterMapperTest.java, 增加测试方法 结果 debug 一级缓存执行流程 一级缓存失效分析 关闭sqlSession会话后 , 一级缓存失效 如果执行sqlSession.clearCache(…...
macOS Ventura 13.4 RC2(22F63)发布
系统介绍 根据黑果魏叔官网提供:5 月 12 日消息,苹果今天面向开发人员,发布了 macOS Ventura 13.4 的第 2 个候选 RC 版本(内部版本号 22F63),距离上个候选版本相隔数天时间。 macOS Ventura 带来了台前调…...
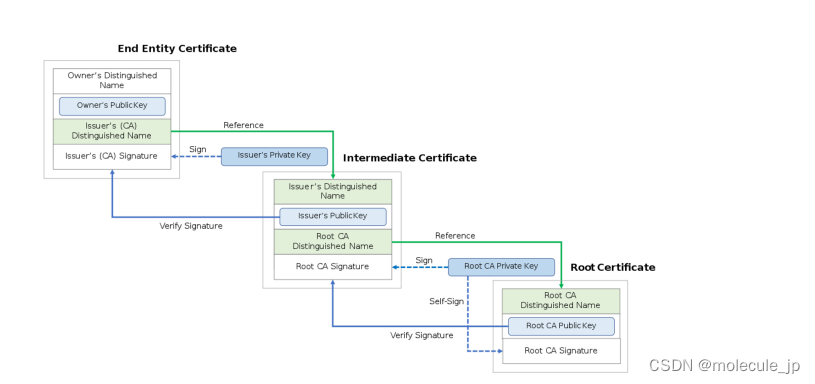
【为什么可以相信一个HTTPS网站】
解决信用,仅仅有加密和解密是不够的。加密解密解决的只是传输链路的安全问题,相当于两个人说话不被窃听。可以类比成你现在生活 的世界——货币的信用,是由政府在背后支撑的;购房贷款的信用,是由银行在背后支撑的&…...
4.进阶篇
目录 一、按照测试对象划分 1.界面测试(UI测试) 界面测试的常见错误: 2.可靠性测试 3.容错性测试 4.文档测试 5.兼容性测试 6.易用性 7.安装卸载测试 8.安全性测试 9.性能测试 10.内存泄漏 二、按照是否查看代码 1.黑盒测试 2.…...

conda init
在输入conda activate 的时候出现报错: 解决: "需要使用 conda init 进行初始化" 的错误通常是由于你的系统环境缺少 conda 的初始化脚本所致。当你尝试在终端中执行 conda activate 命令时,会出现此错误提示。 要解决这个问题,可以通过以下步骤进行操作: 打…...

Elasticsearch(二)
Clasticsearch(二) DSL查询语法 文档 文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html 常见查询类型包括: 查询所有:查询出所有数据,一般测试用。如:…...

工业视觉检测的8个技术优势
工业4.0时代,自动化生产线成为了这个时代的主旋律,而工业视觉检测技术也成为其中亮眼的表现,其机器视觉技术为设备提供了智慧的双眼,让自动化的脚步得以加速! 在实际的生产应用中,视觉技术方案往往先被着手…...

16 KVM虚拟机配置-其他常见配置项
文章目录 16 KVM虚拟机配置-其他常见配置项16.1 概述16.2 元素介绍16.3 配置示例 16 KVM虚拟机配置-其他常见配置项 16.1 概述 除系统资源和虚拟设备外,XML配置文件还需要配置一些其他元素,本节介绍这些元素的配置方法。 16.2 元素介绍 iothreads&…...

30岁裸辞后,我用两个月拿下AI应用认证,现在OFFER选择困难症犯了
30岁裸辞那天,我最怕的不是没收入,而是突然发现:过去积累的经验,正在被AI重新定价。以前会写方案、做表格、跟项目,算是职场硬通货;到了2026年,招聘JD里开始频繁出现AI工具应用、智能工作流、Pr…...

基于Arduino的模块化DIY智能时钟:从RTC到RGB LED的完整实现
1. 项目概述:打造一台高度可定制的DIY RGB LED时钟如果你和我一样,对市面上千篇一律的电子钟感到审美疲劳,同时又对Arduino和电子DIY充满热情,那么这个项目可能就是为你准备的。我们不是在简单地组装一个套件,而是在亲…...

PlayAI语音合成质量到底如何?12款竞品横向对比+5项MOS/LSD/STOI硬指标揭榜
更多请点击: https://kaifayun.com 第一章:PlayAI语音合成质量评测报告 PlayAI 是一款面向开发者与内容创作者的实时语音合成(TTS)服务,支持多语种、多音色及情感可控输出。本报告基于客观可复现的评测流程࿰…...

从CTF题看RSA安全:为什么你的密钥不能‘共享素数’?
从CTF实战看RSA密钥安全:那些年我们踩过的坑 在网络安全竞赛和实际渗透测试中,RSA算法的错误实现方式往往成为突破的关键点。本文将通过典型CTF赛题案例,揭示五种常见RSA实现漏洞背后的数学原理和安全启示,帮助开发者在实际项目中…...

配置OpenClaw Agent使用Taotoken作为后端模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 配置OpenClaw Agent使用Taotoken作为后端模型提供商 基础教程类,指导希望使用OpenClaw等Agent工具的开发者,…...

Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件
Unity UI交互进阶:手把手教你打造一个支持单击、双击、长按的万能按钮组件在游戏开发中,UI交互的流畅性和多样性直接影响玩家的游戏体验。想象一下,当你在开发一个RPG游戏的背包系统时,需要实现道具的单击查看详情、双击快速使用、…...

Sora 2 MOV导出画质崩坏真相:HDR10元数据丢失、BT.2020色域截断、帧率标志位误写——3大隐性缺陷紧急修复方案
更多请点击: https://intelliparadigm.com 第一章:Sora 2 MOV导出画质崩坏的系统性认知 Sora 2 在生成高保真视频后,导出为 MOV 格式时频繁出现色度抽样失真、动态范围压缩、帧间伪影加剧等现象,其本质并非单一环节失效ÿ…...

保姆级教程:在Ubuntu上配置Frida环境,搞定Android App的IO重定向与签名绕过
在Ubuntu上构建Android逆向工程环境:Frida实战与IO重定向技术解析 对于习惯Linux环境的安全研究人员而言,Windows-centric的逆向工具链往往带来诸多不便。本文将系统性地介绍如何在Ubuntu上搭建完整的Android逆向环境,并深入探讨如何利用Frid…...

HoRain云--CLAUDE.md 使用指南
🎬 HoRain云小助手:个人主页 🔥 个人专栏: 《Linux 系列教程》《c语言教程》 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!…...
)
告别KITTI!用TartanAir数据集在Unreal Engine仿真环境里“虐”你的VSLAM算法(附保姆级下载与使用指南)
用TartanAir数据集在Unreal Engine中打造VSLAM算法的"极限考场"当你的视觉SLAM算法在KITTI数据集上跑出98%的准确率时,是否意味着它已经准备好应对真实世界的复杂场景?现实往往会给乐观的开发者当头一棒——实验室里的"优等生"在遇到…...