JAVA8的新特性——Stream
JAVA8的新特性——Stream

在这个深夜写下这篇笔记,窗外很安静,耳机里是《季节更替》,我感触还不是很多,当我选择封面图片的时候才发现我们已经渐渐远去,我们都已经奔赴生活,都在拼命想着去换一个活法,六月就要真的结束这段关系,好怀念校园的那段日子,我们不用去思考以后,在这个象牙塔里幻想一份感情,互相玩笑,走出来了,就真的远去!愿我们所得皆所愿,不被生活磨平了棱角,聪哥,腿哥,伟哥,吕子,帆子,还有此刻读到文章的你,加油,我们一起向前冲!
——2023年5月15日凌晨 IT小辉同学
Java 8中引入的Stream是一种全新的数据处理方式,它使用简单而高效的方法对集合数据进行操作。下面对Stream进行详细介绍
什么是 Stream(引用菜鸟教程)
Stream(流)是一个来自数据源的元素队列并支持聚合操作
- 元素是特定类型的对象,形成一个队列。 Java中的Stream并不会存储元素,而是按需计算。
- 数据源 流的来源。 可以是集合,数组,I/O channel, 产生器generator 等。
- 聚合操作 类似SQL语句一样的操作, 比如filter, map, reduce, find, match, sorted等。
和以前的Collection操作不同, Stream操作还有两个基础的特征:
- Pipelining: 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。
- 内部迭代: 以前对集合遍历都是通过Iterator或者For-Each的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式, 通过访问者模式(Visitor)实现
Stream的用法
Stream是Java 8中针对集合数据的一种新的操作方式,使用了类似于SQL语句的流式操作方式。Stream由三部分构成:源、零个或多个中间操作、终止操作。
源是指Stream要处理的原始数据源,可以是Collection、Array、I/O资源等;
中间操作用来对数据进行转化、过滤、排序等操作,其中每一个中间操作都会返回一个新的Stream对象;
终止操作用来获取Stream处理结果。
Stream的特点
(1)流式操作:Stream提供了一种流式的操作方式,方便数据处理和转换;
(2)惰性求值:Stream使用惰性求值方式进行计算,只有在被终止操作时才会进行计算;
(3)并行处理:Stream支持并行处理,提高了处理大数据集的效率。
Stream的优缺点
优点:
(1)简洁:使用Stream可以让代码更加简洁易懂;
(2)高效:Stream支持惰性求值和并发处理,提高了处理效率;
(3)灵活:Stream提供了多种操作方式,可以适应不同的数据处理需求。
缺点:
(1)学习成本:Stream需要掌握一些新的操作方式,需要一定的学习成本;
(2)线程安全:并行处理时需要注意线程安全问题。
Stream的使用场景
Stream适用于处理大数据集和需要频繁进行转换、过滤、排序等操作的场景。例如,对于需要筛选和排序的订单列表或者用户列表等数据集合,Stream可以极大地提高处理效率和代码简洁度。
Stream的发展趋势
随着Java生态系统的不断发展,Stream也在不断完善和优化中。未来Stream可能会增加更多的功能和特性,同时也会进一步提升处理效率和优化用户体验。
总之,Stream是Java 8中非常重要的一个新特性,它为集合数据的处理提供了一种全新的方式,具有很多优点和适用场景。因此,熟练掌握Stream的各种用法和特点对Java开发者来说是非常重要的。
Java生成Stream
Java中可以通过多种方式来生成Stream,包括:
- 从集合中生成Stream:
可以使用Collection接口提供的stream()方法或parallelStream()方法来生成Stream对象。例如:
List<String> list = Arrays.asList("apple", "banana", "orange");
Stream<String> stream = list.stream();
- 从数组中生成Stream:
可以使用Arrays类提供的stream()方法或parallelStream()方法来生成Stream对象。例如:
int[] arr = new int[]{1, 2, 3, 4, 5};
IntStream stream = Arrays.stream(arr);
- 使用Stream.of()方法生成Stream:
可以使用Stream类提供的of()方法来生成Stream对象。例如:
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);
- 使用Stream.iterate()方法生成Stream:
可以使用Stream类提供的iterate()方法来生成Stream对象。该方法需要传入一个初始值和一个函数接口,用来生成无限长度的Stream。例如:
Stream<Integer> stream = Stream.iterate(1, n -> n + 1);
- 使用Stream.generate()方法生成Stream:
可以使用Stream类提供的generate()方法来生成Stream对象。该方法需要传入一个函数接口,用来生成无限长度的Stream。例如:
Stream<Double> stream = Stream.generate(Math::random);
总之,Java中可以通过多种方式来生成Stream对象,可以根据不同的需求选择不同的方式来生成Stream。
Stream中的filter过滤
filter()方法可以用于过滤出满足特定条件的元素。
具体来说,filter()方法会接收一个函数式接口Predicate<T>,该接口只有一个方法test(T t),该方法接受一个参数t,返回一个布尔值。当test()方法的返回值为true时,表示当前元素应该被保留;当返回值为false时,表示当前元素应该被过滤掉。
/*** @Description 过滤掉apple这个字符串* @Author IT小辉同学* @Date 2023/05/14*/@Testpublic void test1() {List<String> list = Arrays.asList("apple", "banana", "orange","cherry","Hami");Stream<String> stream = list.stream();//过滤掉apple这个字符串List<String> stringList =stream.filter(s -> !s.equals("apple")).collect(Collectors.toList());System.out.println("过滤掉apple这个字符串:"+stringList);}/*** @Description 过滤掉含字母a的字符串* @Author IT小辉同学* @Date 2023/05/14*/@Testpublic void test2() {List<String> list = Arrays.asList("apple", "banana", "orange","cherry","Hami");Stream<String> stream = list.stream();//过滤掉含字母a的字符串List<String> stringList1=stream.filter(s -> !s.contains("a")).collect(Collectors.toList());System.out.println("过滤掉含字母a的字符串:"+stringList1);}/*** @Description 过滤掉含字母a和i的字符串* @Author IT小辉同学* @Date 2023/05/14*/@Testpublic void test3() {List<String> list = Arrays.asList("apple", "banana", "orange","cherry","Hami");Stream<String> stream = list.stream();//过滤掉含字母a和i的字符串List<String> stringList1=stream.filter(s -> !s.contains("a")&&!s.contains("i")).collect(Collectors.toList());System.out.println("过滤掉含字母a和i的字符串:"+stringList1);}注意:同一个Stream不可进行多次操作,否则报错
错误示例
List<String> list = Arrays.asList("apple", "banana", "orange","cherry","Hami");Stream<String> stream = list.stream();//过滤掉apple这个字符串List<String> stringList =stream.filter(s -> !s.equals("apple")).collect(Collectors.toList());System.out.println("过滤掉apple这个字符串:"+stringList);//过滤掉含字母a和i的字符串List<String> stringList1=stream.filter(s -> !s.contains("a")&&!s.contains("i")).collect(Collectors.toList());System.out.println("过滤掉含字母a和i的字符串:"+stringList1);
报错情况
Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closedat java.util.stream.AbstractPipeline.<init>(AbstractPipeline.java:203)at java.util.stream.ReferencePipeline.<init>(ReferencePipeline.java:94)at java.util.stream.ReferencePipeline$StatelessOp.<init>(ReferencePipeline.java:618)at java.util.stream.ReferencePipeline$2.<init>(ReferencePipeline.java:163)at java.util.stream.ReferencePipeline.filter(ReferencePipeline.java:162)at com.demo.example.StreamDemo.main(StreamDemo.java:20)什么原因
详细解释
这个异常通常是因为对一个已经被操作或关闭的Stream进行了再次操作或关闭,导致Stream状态不正确,从而抛出IllegalStateException异常。解决这个问题的方法通常有以下几种:
- 避免在同一个Stream上进行多个终止操作:
即使多个终止操作被串联在一起,也只会执行最后一个终止操作。因此,在一个Stream对象上执行多个终止操作会导致Stream被关闭,从而引发IllegalStateException异常。如果需要对同一个Stream进行多个操作,可以将其保存到一个中间变量中,并对该中间变量进行操作。例如:
Stream<String> stream = list.stream();
stream = stream.filter(s -> s.length() > 5);
stream.forEach(System.out::println);
- 使用新建的Stream对象进行操作:
对于Stream对象的所有操作都会返回一个新的Stream对象,因此可以通过使用新建的Stream对象来避免对已经被操作或关闭的Stream进行操作。例如:
Stream<String> stream1 = list.stream();
Stream<String> stream2 = stream1.filter(s -> s.length() > 5);
stream2.forEach(System.out::println);
- 改用Stream.peek()方法:
peek()方法是一种类似于forEach()方法但不会关闭Stream的中间操作。可以通过使用peek()方法来进行调试和测试操作。例如:
Stream<String> stream = list.stream();
stream = stream.filter(s -> s.length() > 5).peek(System.out::println);
stream.forEach(System.out::println);
总之,如果出现了IllegalStateException异常,通常是因为对一个已经被操作或关闭的Stream进行了再次操作或关闭。可以通过避免在同一个Stream对象上进行多个终止操作、使用新建的Stream对象进行操作或改用Stream.peek()方法来解决这个问题。
Stream中的forEach遍历
forEach()方法是一种用于遍历Stream元素并对每个元素进行指定操作的终止操作方法。
forEach()方法接收一个Lambda表达式作为参数,该表达式会被应用到Stream中的每个元素上,用来执行指定的操作。该方法不返回任何值,只是将Lambda表达式应用到Stream中的每个元素上,从而实现对Stream的遍历操作。
/*** @Description 简单遍历* @Author IT小辉同学* @Date 2023/05/15*/@Testpublic void test4(){List<String> list = Arrays.asList("apple", "banana", "orange","cherry","Hami");Stream<String> stream = list.stream();stream.forEach(System.out::println);}/*** @Description 遍历去除含有字母b的字符串* @Author IT小辉同学* @Date 2023/05/15*/@Testpublic void test5(){List<String> list = Arrays.asList("apple", "banana", "orange","cherry","Hami");Stream<String> stream = list.stream();stream.filter(s -> !s.contains("b")).forEach(System.out::println);}/*** @Description 遍历去除含有字母b和i的字符串并且添加到arrayList* @Author IT小辉同学* @Date 2023/05/15*/@Testpublic void test6(){List<String> list = Arrays.asList("apple", "banana", "orange","cherry","Hami");ArrayList<String> arrayList=new ArrayList<>();Stream<String> stream = list.stream();stream.filter(s -> !s.contains("b")).forEach(arrayList::add);System.out.println(arrayList);}
Stream中的map映射
map操作可以将Stream中的每个元素映射到另一个元素上,并返回一个新的Stream。
map操作的语法如下:
Stream<T> map(Function<? super T, ? extends U> mapper)
其中,T是Stream中的元素类型,U是映射后的元素类型。mapper是一个函数式接口,它接受一个元素作为输入,并返回一个新的元素作为输出。
map操作的作用是将Stream中的每个元素映射到另一个元素上,并返回一个新的Stream。这个操作非常灵活,可以用于很多不同的场景。
/*** @Description 使用 map 输出了元素对应的平方数* @Author IT小辉同学* @Date 2023/05/15*/@Testpublic void test7() {List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5);// 获取对应的平方数List<Integer> squaresList = numbers.stream().map(i -> i * i).collect(Collectors.toList());System.out.println(squaresList);}/*** @Description 使用 map 输出了元素对应的平方数(去重)* @Author IT小辉同学* @Date 2023/05/15*/@Testpublic void test8() {List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5);// 获取对应的平方数List<Integer> squaresList = numbers.stream().map(i -> i * i).distinct().collect(Collectors.toList());System.out.println(squaresList);}/*** @Description 使用 map 输出了元素对应的平方数(去重并且排序)* @Author IT小辉同学* @Date 2023/05/15*/@Testpublic void test9() {List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5);// 获取对应的平方数List<Integer> squaresList = numbers.stream().map(i -> i * i).distinct().sorted().collect(Collectors.toList());System.out.println(squaresList);}/*** @Description 使用 map 输出了元素对应的平方数(去重并且排序,限制个数)* @Author IT小辉同学* @Date 2023/05/15*/@Testpublic void test10() {List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5);// 获取对应的平方数List<Integer> squaresList = numbers.stream().map(i -> i * i).distinct().sorted().limit(3).collect(Collectors.toList());System.out.println(squaresList);}
Stream中的parallel并行程序
parallel操作可以将Stream中的每个元素并行处理,并返回一个新的Stream。
parallel操作的语法如下:
Stream<T> parallel()
其中,T是Stream中的元素类型。
parallel操作的作用是将Stream中的每个元素并行处理,并返回一个新的Stream。这个操作可以用于处理大量数据,提高处理效率。
需要注意的是,parallel操作会创建一个新的线程来处理每个元素,这可能会导致性能开销。因此,在使用parallel操作时,需要根据具体的情况来评估其性能开销,并进行适当的优化。
/*** @Description 获取空字符串的数量* @Author IT小辉同学* @Date 2023/05/15*/@Testpublic void test11() {List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd", "", "jkl");// 获取空字符串的数量long count = strings.parallelStream().filter(string -> string.isEmpty()).count();System.out.println(count);}/*** @Description 去除空字符串转换为数组* @Author IT小辉同学* @Date 2023/05/15*/@Testpublic void test12() {List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd", "", "jkl");// 获取空字符串的数量List<String> stringList = strings.parallelStream().filter(string ->!string.isEmpty()).collect(Collectors.toList());System.out.println(stringList);}
Stream中的Collectors聚合操作
Stream中的Collectors聚合操作是一种用于对流数据进行处理的方法,它可以将流中的元素按照指定的规则进行分组、过滤、映射等操作,最终生成一个新的流。
以下是一些常见的聚合操作:
- toList():将流中的元素收集到一个List中。
List<Integer> list = stream.collect(Collectors.toList());
- toSet():将流中的元素收集到一个Set中,去重。
Set<Integer> set = stream.collect(Collectors.toSet());
- toMap():将流中的元素按照指定的键值对进行分组,并返回一个Map对象。
Map<String, Integer> map = stream.collect(Collectors.toMap(Function.identity(), Function.identity()));
- maxBy():按照指定的属性或方法对流中的元素进行比较,返回最大值。
Optional<Integer> max = stream.max(Comparator.comparingInt(i -> i));
- minBy():按照指定的属性或方法对流中的元素进行比较,返回最小值。
Optional<Integer> min = stream.min(Comparator.comparingInt(i -> i));
- sum():对流中的数字类型元素进行求和。
long sum = stream.mapToLong(i -> i).sum();
- count():统计流中元素的数量。
long count = stream.count();
- average():计算流中数字类型元素的平均值。
double average = stream.mapToDouble(i -> i).average().orElse(0d);
- filter():根据指定的条件过滤流中的元素。
stream.filter(i -> i > 10).forEach(System.out::println); // 输出大于 10 的元素
- distinct():去重操作,返回不同的元素组成的流。
List<Integer> distinctList = stream.distinct().collect(Collectors.toList()); // 去重后生成 List 集合
使用Collectors可以简化代码,提高开发效率,同时也可以实现更加灵活的数据处理方式。
Stream中的统计函数
另外,一些产生统计结果的收集器也非常有用。它们主要用于int、double、long等基本类型上,它们可以用来产生类似如下的统计结果。
好的,以下是Stream中的统计函数介绍:
- count():统计流中元素的数量。
long count = stream.count();
- min():返回流中最小的元素。
Optional<T> min = stream.min(Comparator.comparing(i -> i));
- max():返回流中最大的元素。
Optional<T> max = stream.max(Comparator.comparing(i -> i));
- sum():对流中的元素进行求和。
long sum = stream.mapToLong(i -> i).sum();
- average():计算流中元素的平均值。
double average = stream.mapToDouble(i -> i).average().orElse(0d);
- distinct():返回去重后的元素列表。
List<T> distinctList = stream.distinct().collect(Collectors.toList()); // 去重后生成 List 集合
- anyMatch():判断流中是否存在至少一个满足条件的元素。
boolean anyMatch = stream.anyMatch(i -> i > 10); // 判断是否存在大于 10 的元素
- allMatch():判断流中的所有元素是否都满足条件。
boolean allMatch = stream.allMatch(i -> i > 10); // 判断所有元素是否都大于 10
- noneMatch():判断流中是否不存在满足条件的元素。
boolean noneMatch = stream.noneMatch(i -> i < 10); // 判断是否不存在小于 10 的元素
一个小例子结束学习之旅
数字平方排序(倒叙)输出
字符串转 map 输出
public static void main(String[] args) {List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5);// 获取对应的平方数// List<Integer> squaresList = numbers.stream().map( i -> i*i).distinct().collect(Collectors.toList());List<Integer> squaresList = numbers.stream().map(i -> i * i).sorted((x, y) -> y - x).collect(Collectors.toList());// squaresList.forEach(System.out::println);squaresList.forEach(num -> {num++;System.out.println(num);});List<String> strList = Arrays.asList("a", "ba", "bb", "abc", "cbb", "bba", "cab");Map<Integer, String> strMap = new HashMap<Integer, String>();strMap = strList.stream().collect( Collectors.toMap( str -> strList.indexOf(str), str -> str ) );strMap.forEach((key, value) -> {System.out.println(key+"::"+value);});}
sorted()方法的第二个参数是一个比较器(Comparator),用于指定排序规则。比较器的逻辑接受两个参数,分别代表要比较的两个元素,返回一个负数、零或正数,表示第一个参数小于、等于或大于第二个参数。
在sorted((x, y) -> y - x)中,括号内的第一个参数x和第二个参数y分别代表要比较的两个元素。比较器的逻辑是按照从每个元素到自身的降序差值进行比较,即用第二个元素减去第一个元素,得到的结果就是它们之间的大小关系。如果结果为负数,则说明第一个元素小于第二个元素;如果结果为0,则说明它们相等;如果结果为正数,则说明第一个元素大于第二个元素。
因此,sorted((x, y) -> y - x)实际上定义了一个从每个元素到自身的降序差值的比较器,用于对列表进行排序操作。
前辈的文章推荐(如果感觉对于个人这篇文章已经透彻,可以看看前辈的文章,本人学习之后,方知自我之浅薄)
相关文章:
JAVA8的新特性——Stream
JAVA8的新特性——Stream 在这个深夜写下这篇笔记,窗外很安静,耳机里是《季节更替》,我感触还不是很多,当我选择封面图片的时候才发现我们已经渐渐远去,我们都已经奔赴生活,都在拼命想着去换一个活法&#…...

alias设置快捷键vim使用说明(解决服务器上输入长指令太麻烦的问题)
1. vi ~/.bashrc打开 2. (watch -n 1 gpustat 查看gpu使用情况 太麻烦)输入i进行编辑,最后一行输入 alias watchgpuwatch -n 1 gpustat alias gpuwatch -n 1 gpustat alias torch180source activate torch180 3. 按esc,然后输入:wq保存退出 4. source…...

英语基础句型之旅:从基础到高级
英语句型之旅:从基础到高级 一、起步:掌握英语基础句型 (Getting Started: Mastering Basic English Sentence Structures)1.1 英语句子的基本构成 (The Basic Components of English Sentences)1.2 五大基本句型解析 (Analysis of the Five Basic Sente…...
十四、Zuul网关
目录 一、API网关作用: 二、网关主要功能: 2.1、统一服务入口 2.2、接口鉴权 2.3、智能路由 2.4、API接口进行统一管理 2.5、限流保护 三、 新建一个项目作为网关服务器 3.1、项目中引入Zuul网关依赖 3.2、在项目application.yml中配置网关路由…...
5项目五:W1R3S-1(思路为主!)
特别注明:本文章只用于学习交流,不可用来从事违法犯罪活动,如使用者用来从事违法犯罪行为,一切与作者无关。 目录 前言 一、信息收集 二、网页信息的收集 三、提权 总结 前言 思路清晰: 1.信息收集,…...
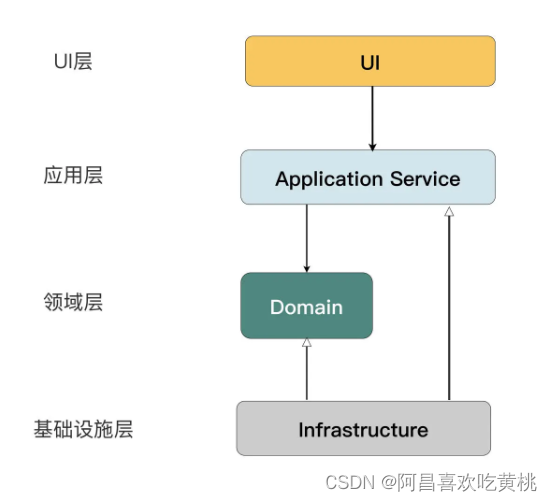
Day958.代码的分层重构 -遗留系统现代化实战
代码的分层重构 Hi,我是阿昌,今天学习记录的是关于代码的分层重构的内容。 来看看如何重构整体的代码,也就是如何对代码分层。 一、遗留系统中常见的模式 一个学校图书馆的借书系统。当时的做法十分“朴素”,在点击“借阅”按钮…...
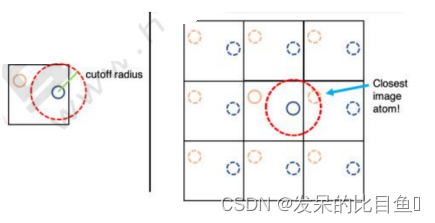
分子模拟力场
分子模拟力场 AMBER力场是在生物大分子的模拟计算领域有着广泛应用的一个分子力场。开发这个力场的是Peter Kollman课题组,最初AMBER力场是专门为了计算蛋白质和核酸体系而开发的,计算其力场参数的数据均来自实验值,后来随着AMBER力场的广泛…...

ERP 系统在集团化企业财务管理中的应用
(一)集团统一会计核算平台的构建原理及功能 第一,搭建集中统一会计核算平台的基础是确定财务组 织及岗位,在此基础上制定统一的会计核算政策、规范集中 基础数据、落实内控管理制度。 第二,具备了以上建立集中统一会计…...

达摩院开源多模态对话大模型mPLUG-Owl
miniGPT-4的热度至今未减,距离LLaVA的推出也不到半个月,而新的看图聊天模型已经问世了。今天要介绍的模型是一款类似于miniGPT-4和LLaVA的多模态对话生成模型,它的名字叫mPLUG-Owl。 论文链接:https://arxiv.org/abs/2304.14178…...

Group相关问题-组内节点限制移动范围
1.在节点中定义dragComputation,限制节点的移动范围 注意事项 组节点不定义go.Placeholder ,设置了占位符后组内节点移动将改变组节点位置dragComputation中自定义stayInGroup计算规则是根据groupNode的resizeObject计算 如果开启了resizable:true,建议指定其改变大的零部件r…...

程序员该如何学习技术
程序员该如何学习技术 前言 学习是第一生产力,我从来都是这么认为的,人只有只有不断地学习才能意识到自己的缺点和不足,身为程序员,我更认为人们应当抱着终身学习的想法实践下去,这是我所一直践行且相信的。 高处不胜寒…...

springboot+vue交流互动系统(源码+文档)
风定落花生,歌声逐流水,大家好我是风歌,混迹在java圈的辛苦码农。今天要和大家聊的是一款基于springboot的交流互动系统。项目源码以及部署相关请联系风歌,文末附上联系信息 。 💕💕作者:风歌&a…...

【2023华为OD笔试必会25题--C语言版】《01 预定酒店》——排序、二分查找
本专栏收录了华为OD 2022 Q4和2023Q1笔试题目,100分类别中的出现频率最高(至少出现100次)的25道,每篇文章包括原始题目 和 我亲自编写并在Visual Studio中运行成功的C语言代码。 仅供参考、启发使用,切不可照搬、照抄,查重倒是可以过,但后面的技术面试还是会暴露的。✨✨…...

C语言实现队列--数据结构
😶🌫️Take your time ! 😶🌫️ 💥个人主页:🔥🔥🔥大魔王🔥🔥🔥 💥代码仓库:🔥🔥魔…...

前端CSS经典面试题总结
前端CSS经典面试题总结 2.1 介绍一 下 CSS 的盒子模型?2.2 css 选择器优先级?2.3 垂直居中几种方式?2.4 简明说一下 CSS link 与 import 的区别和用法?2.5 rgba和opacity的透明效果有什么不同?2.6 display:none和visib…...
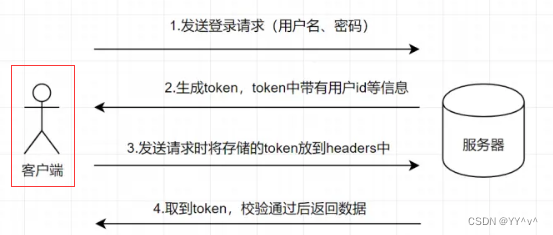
cookie、session、token的区别是什么
前言 今天就来说说session、cookie、token这三者之间的关系!最近这仨玩意搞得头有点大🤣 1.为什么会有它们三个? 我们都知道 HTTP 协议是无状态的,所谓的无状态就是客户端每次想要与服务端通信,都必须重新与服务端链接…...

leetcode分类刷题 -- 前缀和和哈希
力扣 class Solution { public int subarraySum(int[] nums, int k) { Map<Integer,Integer> map new HashMap<>(); int count0,sum0; map.put(0,1); for(int i:nums){ sum i; if(map.containsKey(sum-k)) count map.get(sum-k); map.compute(sum,(key,v)->…...

浅谈作为程序员如何写好文档:了解读者
我作为从一名懵懂的实习生转变为工程师的工作经历中,伴随着技术经验的成长,也逐渐意识到了编写文档是知识和经验传递给其他人的最有效方式。通过文档,可以分享我的技术知识和最佳实践,使其他人更好地理解我的工作。在这里…...
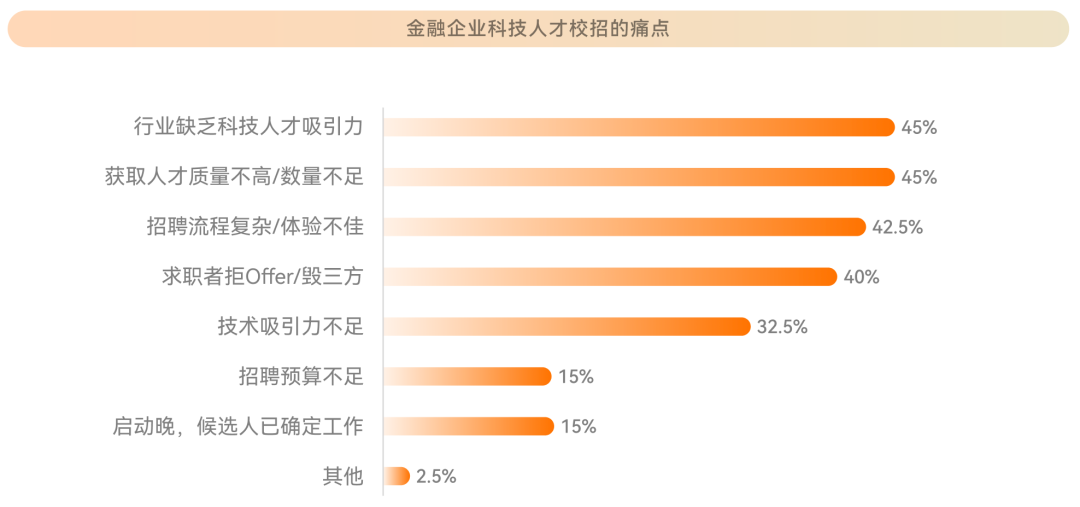
一文读懂国内首本《牛客2023金融科技校园招聘白皮书》
金融科技人才作为金融数字化转型的关键支撑,但当下金融科技人才培养体系尚未形成,优秀的金融科技人才供不应求,目前存在严重的人才供给问题。 据调研数据统计,96.8%的金融机构存在金融科技人才缺口,54.8%的机构认为新…...

深度学习03-卷积神经网络(CNN)
简介 CNN,即卷积神经网络(Convolutional Neural Network),是一种常用于图像和视频处理的深度学习模型。与传统神经网络相比,CNN 有着更好的处理图像和序列数据的能力,因为它能够自动学习图像中的特征&…...

Wan2.2-T2V-A5B常见错误排查:运行失败、生成卡顿的解决方法
Wan2.2-T2V-A5B常见错误排查:运行失败、生成卡顿的解决方法 1. 问题概述与快速诊断 Wan2.2-T2V-A5B作为一款轻量级文本到视频生成模型,虽然在资源消耗和响应速度上具有优势,但在实际使用过程中仍可能遇到运行失败或生成卡顿的问题。这些问题…...

TradingAgents-CN 多智能体金融分析系统:企业级容器化部署实战指南
TradingAgents-CN 多智能体金融分析系统:企业级容器化部署实战指南 【免费下载链接】TradingAgents-CN 基于多智能体LLM的中文金融交易框架 - TradingAgents中文增强版 项目地址: https://gitcode.com/GitHub_Trending/tr/TradingAgents-CN TradingAgents-CN…...

MT5 Zero-Shot参数详解:Temperature与Top-P对中文改写多样性的影响
MT5 Zero-Shot参数详解:Temperature与Top-P对中文改写多样性的影响 1. 项目概述 MT5 Zero-Shot Chinese Text Augmentation 是一个基于 Streamlit 和阿里达摩院 mT5 模型构建的本地化 NLP 工具。这个工具专门用于中文句子的语义改写和数据增强,能够在保…...

11.0592MHz晶振在51单片机串口通信中的优势解析
1. 为什么11.0592MHz晶振成为单片机工程师的首选在嵌入式系统设计中,晶振的选择往往决定了整个系统的稳定性和精度。作为一名从事单片机开发多年的工程师,我发现11.0592MHz的晶振在51单片机项目中出现的频率异常高。这绝非偶然,而是由一系列精…...

工程仿真平台OpenRocket:从物理试验到数字孪生的技术跃迁
工程仿真平台OpenRocket:从物理试验到数字孪生的技术跃迁 【免费下载链接】openrocket Model-rocketry aerodynamics and trajectory simulation software 项目地址: https://gitcode.com/GitHub_Trending/op/openrocket 在现代工程设计领域,物理…...

Linux配置静态ip地址和Oracle VM VirtualBox导入/导出虚拟机Centos7
导入虚拟机选择管理 - 导入虚拟电脑找到自己的虚拟机位置修改内存大小,默认虚拟机电脑位置,MAC地址等导入后点击设置如下图:修改网络-网 -- 卡1,其他基本不需要修改桥接网络选好网卡接入网线;设置好网络以后使用命令重…...

Qwen3-14B芯片设计辅助:Verilog注释生成、RTL代码解释、DFT建议
Qwen3-14B芯片设计辅助:Verilog注释生成、RTL代码解释、DFT建议 1. 镜像概述与硬件适配 Qwen3-14B私有部署镜像是专为芯片设计工程师打造的AI辅助工具,基于通义千问大语言模型优化定制。该镜像完美适配RTX 4090D 24GB显存配置,预装了完整的…...

Modelsim与Vivado仿真差异:从阻塞赋值到存储IP的深度解析
1. 当仿真结果“精神分裂”:一次真实的噩梦Debug之旅 昨天我经历了一场堪称“硬件工程师噩梦”的Debug。我和队友完成了一个LeNet神经网络推理的硬件实现,在Modelsim里跑得顺风顺水,功能验证完美通过。但当我们信心满满地准备移植到Vivado平台…...
Pixel Couplet Gen应用场景:微信小程序开发者如何复用像素皇城UI组件
Pixel Couplet Gen应用场景:微信小程序开发者如何复用像素皇城UI组件 1. 项目背景与价值 Pixel Couplet Gen是一款融合传统春节文化与现代像素艺术风格的创新应用。作为微信小程序开发者,您可以直接复用其UI组件库,快速构建具有以下特点的应…...

为什么小数据集上神经网络会突然‘开窍‘?揭秘Grokking现象背后的LU机制
为什么小数据集上神经网络会突然"开窍"?揭秘Grokking现象背后的LU机制 在机器学习实践中,我们常常观察到一种反直觉的现象:当神经网络在小规模算法数据集上训练时,测试准确率会在长时间停滞于随机猜测水平后突然跃升至接…...