Redis数据结构——动态字符串、Dict、ZipList
一、Redis数据结构-动态字符串
我们都知道Redis中保存的Key是字符串,value往往是字符串或者字符串的集合。可见字符串是Redis中最常用的一种数据结构。
不过Redis没有直接使用C语言中的字符串,因为C语言字符串存在很多问题:
- 获取字符串长度的需要通过运算。
- 非二进制安全。
- 不可修改。
Redis构建了一种新的字符串结构,称为简单动态字符串(Simple Dynamic String),简称SDS。
例如,我们执行命令:

那么Redis将在底层创建两个SDS,其中一个是包含“name”的SDS,另一个是包含“KEKE”的SDS。
Redis是C语言实现的,其中SDS是一个结构体,源码如下:

例如,一个包含字符串“name”的sds结构如下:

SDS之所以叫做动态字符串,是因为它具备动态扩容的能力,例如一个内容为“hi”的SDS:

假如我们要给SDS追加一段字符串“,Amy”,这里首先会申请新内存空间:
如果新字符串小于1M,则新空间为扩展后字符串长度的两倍+1;
如果新字符串大于1M,则新空间为扩展后字符串长度+1M+1。称为内存预分配。

优点:
- 获取字符串长度的时间复杂度为O(1)。
- 支持动态扩容。
- 减少内存分配次数。
- 二进制安全。
Redis数据结构-intset
IntSet是Redis中set集合的一种实现方式,基于整数数组来实现,并且具备长度可变、有序等特征。
结构如下:

其中的encoding包含三种模式,表示存储的整数大小不同:

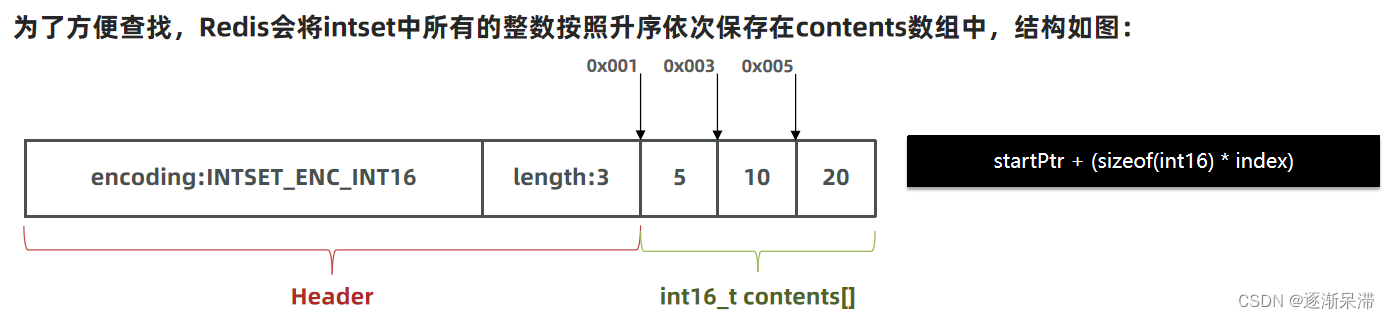
现在,数组中每个数字都在int16_t的范围内,因此采用的编码方式是INTSET_ENC_INT16,每部分占用的字节大小为:
encoding:4字节
length:4字节
contents:2字节 * 3 = 6字节

我们向该其中添加一个数字:50000,这个数字超出了int16_t的范围,intset会自动升级编码方式到合适的大小。
以当前案例来说流程如下:
- 升级编码为INTSET_ENC_INT32, 每个整数占4字节,并按照新的编码方式及元素个数扩容数组。
- 倒序依次将数组中的元素拷贝到扩容后的正确位置。
- 将待添加的元素放入数组末尾。
- 最后,将inset的encoding属性改为INTSET_ENC_INT32,将length属性改为4。

源码如下:
intset *intsetAdd(intset *is, int64_t value, uint8_t *success){uint8_t valenc = _intsetValueEncoding(value);//获取当前值编码uint32_t pos;//要插入的位置if (success) *success = 1;//判断编码是不是超过了当前intset的编码if (valenc > intrev32ifbe(is->encoding)){//超出编码,需要升级return intsetUpgradeAndAdd(is,value);} else {//在当前intset中查找值与value—样的元素的角标posif (intsetSearch(is,value,&pos)) {if (success)*success = O;//如果找到了,则无需插入,直接结束并返回失败return is;}//数组扩容is = intsetResize(is,intrev32ifbe(is->length)+1);//移动数组中pos之后的元素到pos+1,给新元素腾出空间if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);}//插入新元素_intsetSet(is,pos,value);/重置元素长度is->length = intrev32ifbe(intrev32ifbe(is->length)+ 1);return is;
}static intset *intsetUpgradeAndAdd(intset *is, int64_t value){//获取当前intset编码uint8_t curenc = intrev32ifbe(is->encoding);//获取新编码uint8_t newenc = _intsetValueEncoding(value);//获取元素个数int length = intrev32ifbe(is->length);//判断新元素是大于0还是小于0,小于0插入队首、大于0插入队尾int prepend = value < 0 ? 1 : 0;//重置编码为新编码is->encoding = intrev32ifbe(newenc);//重置数组大小is = intsetResize(is,intrev32ifbe(is->length)+1);//倒序遍历,逐个搬运元素到新的位置,_intsetGetEncoded按照旧编码方式查找旧元素while(length--) // _intsetSet按照新编码方式插入新元素intsetSet(is,length+prepend, _intsetGetEncoded(is,length,curenc));//插入新元素,prepend决定是队首还是队尾if (prepend)_intsetSet(is,0,value);else_intsetSet(is,intrev32ifbe(is->length),value);//修改数组长度is- >length = intrev32ifbe(intrev32ifbe(is->length)+ 1);return is;
}小总结:
Intset可以看做是特殊的整数数组,具备一些特点:
- Redis会确保Intset中的元素唯一、有序。
- 具备类型升级机制,可以节省内存空间。
- 底层采用二分查找方式来查询。
二、 Redis数据结构-Dict
我们知道Redis是一个键值型(Key-Value Pair)的数据库,我们可以根据键实现快速的增删改查。而键与值的映射关系正是通过Dict来实现的。
Dict由三部分组成,分别是:哈希表(DictHashTable)、哈希节点(DictEntry)、字典(Dict)。
typedef struct dictht {// entry数组//数组中保存的是指向entry的指针dictEntry **table;//哈希表大小unsigned long size;//哈希表大小的掩码,总等于size - 1unsigned long sizemask;// entry个数unsigned long used;
} dictht;typedef struct dictEntry {void *key;//键union {void *val;uint64_t u64;int64_t s64;double d;} v;//值//下一个Entry的指针struct dictEntry *next;
} dictEntry;当我们向Dict添加键值对时,Redis首先根据key计算出hash值(h),然后利用 h & sizemask来计算元素应该存储到数组中的哪个索引位置。我们存储k1=v1,假设k1的哈希值h =1,则1&3 =1,因此k1=v1要存储到数组角标1位置。

Dict由三部分组成,分别是:哈希表(DictHashTable)、哈希节点(DictEntry)、字典(Dict)。
typedef struct dict {dictType *type; // dict类型,内置不同的hash函数void *privdata;//私有数据,在做特殊hash运算时用dictht ht[2];//一个Dict包含两个哈希表,其中一个是当前数据,另一个一般是空,rehash时使用long rehashidx; // rehash的进度,-1表示未进行int16_t pauserehash; // rehash是否暂停,1则暂停,0则继续
} dict;typedef struct dictht {// entry数组//数组中保存的是指向entry的指针dictEntry **table;//哈希表大小unsigned long size;//哈希表大小的掩码,总等于size - 1unsigned long sizemask;// entry个数unsigned long used;
}dictht;typedef struct dictEntry {void *key;//键union {void *val;uint64_t u64;int64_t s64;double d;} v;//值//下一个Entry的指针struct dictEntry *next;
}dictEntry;typedef struct dict {dictType *type; // dict类型,内置不同的hash函数void *privdata;//私有数据,在做特殊hash运算时用dictht ht[2];//一个Dict包含两个哈希表,其中一个是当前数据,另一个一般是空,rehash时使用long rehashidx; // rehash的进度,-1表示未进行int16_t pauserehash; // rehash是否暂停,1则暂停,O则继续
} dict;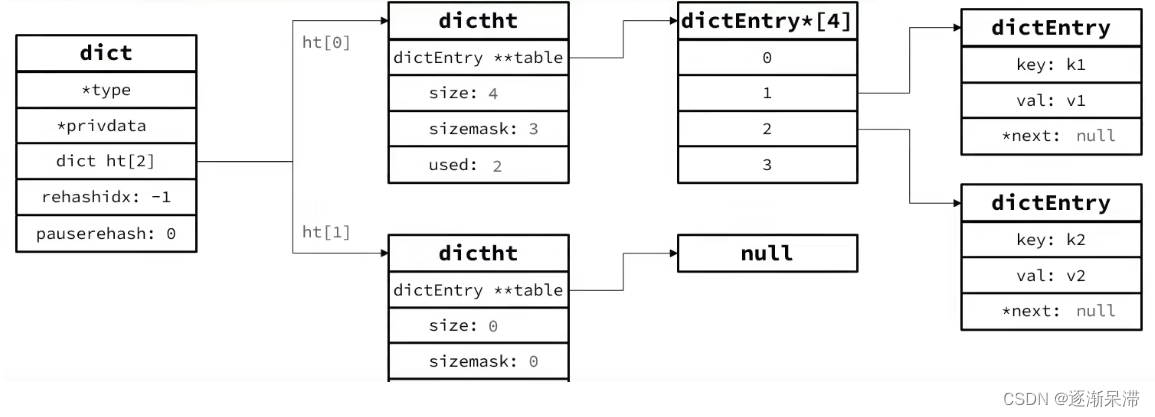
Dict的扩容
Dict中的HashTable就是数组结合单向链表的实现,当集合中元素较多时,必然导致哈希冲突增多,链表过长,则查询效率会大大降低。
Dict在每次新增键值对时都会检查负载因子(LoadFactor = used/size) ,满足以下两种情况时会触发哈希表扩容:
哈希表的 LoadFactor >= 1,并且服务器没有执行 BGSAVE 或者 BGREWRITEAOF 等后台进程;
哈希表的 LoadFactor > 5 ;
static int dictExpandlfNeeded(dict*d){//如果正在rehash,则返回okif (dictlsRehashing(d)) return DICT_OK;//如果哈希表为空,则初始化哈希表为默认大小:4if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);//当负载因子(used/size)达到1以上,并且当前没有进行bgrewrite等子进程操作//或者负载因子超过5,则进行dictExpand ,也就是扩容if (d->ht[0].used >= d->ht[0].size &i&(dict_can_resize || d->ht[0].used/d->ht[0].size > dict_force_resize_ratio){//扩容大小为used + 1,底层会对扩容大小做判断,实际上找的是第一个大于等于used+1的2^nreturn dictExpand(d, d->ht[0].used + 1);}return DICT_OK;
}// t_hash.c # hashTypeDeleted()
//……
if (dictDelete((dict*)o->ptr, field) == C_OK){deleted = 1;//删除成功后,检查是否需要重置Dict大小,如果需要则调用dictResize重置/*Always check if the dictionary needs a resize after a delete.*/if (htNeedsResize(o->ptr)) dictResize(o->ptr);
}
……// server.c文件
int htNeedsResize(dict *dict) {long long size, used;//哈希表大小size = dictSlots(dict);// entry数量used = dictSize(dict);// size > 4(哈希表初识大小)并且负载因子低于0.1return (size > DICT_HT_INITIAL_SIZE && (used*100/size <HASHTABLE_MIN_FILL));
}int dictResize(dict *d){unsigned long minimal;//如果正在做bgsave或bgrewriteof或rehash,则返回错误if (!dict_can_resize |l dictlsRehashing(d))return DICT_ERR;//获取used,也就是entry个数minimal = d->ht[0].used;//如果used小于4,则重置为4if (minimal < DICT_HT_INITIAL_SIZE)minimal = DICT_HT_INITIAL_SIZE;//重置大小为minimal,其实是第一个大于等于minimal的2^nreturn dictExpand(d, minimal);
}Dict的rehash
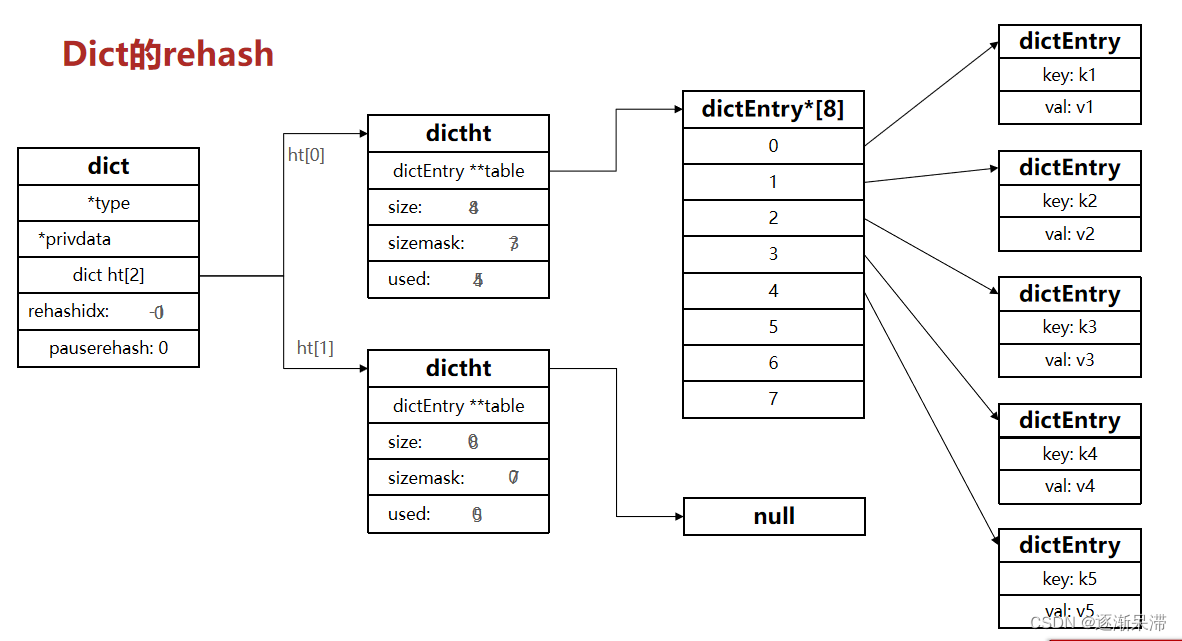
不管是扩容还是收缩,必定会创建新的哈希表,导致哈希表的size和sizemask变化,而key的查询与sizemask有关。因此必须对哈希表中的每一个key重新计算索引,插入新的哈希表,这个过程称为rehash。过程是这样的:
-
计算新hash表的realeSize,值取决于当前要做的是扩容还是收缩:
- 如果是扩容,则新size为第一个大于等于dict.ht[0].used + 1的2^n。
- 如果是收缩,则新size为第一个大于等于dict.ht[0].used的2^n (不得小于4)。
-
按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]。
-
设置dict.rehashidx = 0,标示开始rehash。
-
将dict.ht[0]中的每一个dictEntry都rehash到dict.ht[1]。
-
将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存。
-
将rehashidx赋值为-1,代表rehash结束。
-
在rehash过程中,新增操作,则直接写入ht[1],查询、修改和删除则会在dict.ht[0]和dict.ht[1]依次查找并执行。这样可以确保ht[0]的数据只减不增,随着rehash最终为空。
整个过程可以描述成:
小总结:
Dict的结构:
- 类似java的HashTable,底层是数组加链表来解决哈希冲突。
- Dict包含两个哈希表,ht[0]平常用,ht[1]用来rehash。
Dict的伸缩:
- 当LoadFactor大于5或者LoadFactor大于1并且没有子进程任务时,Dict扩容。
- 当LoadFactor小于0.1时,Dict收缩。
- 扩容大小为第一个大于等于used + 1的2^n。
- 收缩大小为第一个大于等于used 的2^n。
- Dict采用渐进式rehash,每次访问Dict时执行一次rehash。
- rehash时ht[0]只减不增,新增操作只在ht[1]执行,其它操作在两个哈希表。
三、 Redis数据结构-ZipList
ZipList 是一种特殊的“双端链表” ,由一系列特殊编码的连续内存块组成。可以在任意一端进行压入/弹出操作, 并且该操作的时间复杂度为 O(1)。
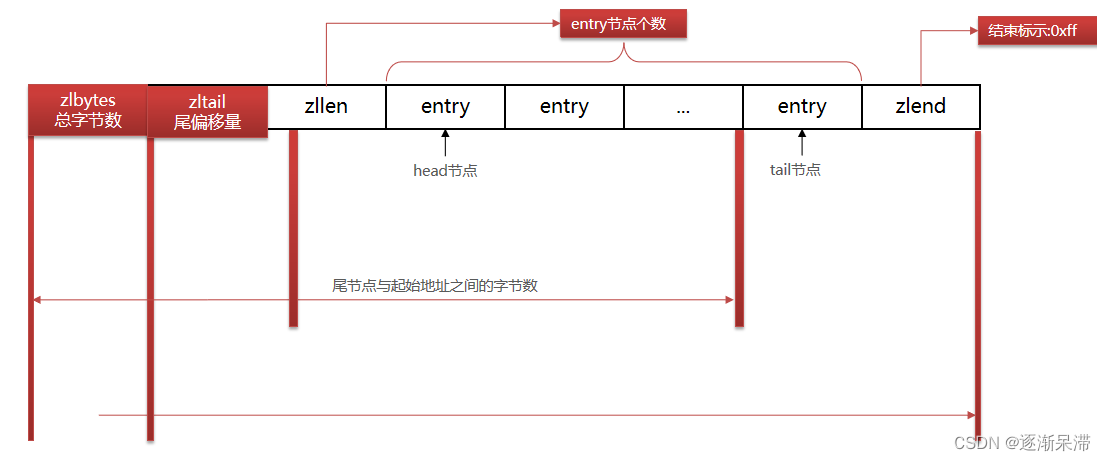

| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zlbytes | uint32_t | 4 字节 | 记录整个压缩列表占用的内存字节数 |
| zltail | uint32_t | 4 字节 | 记录压缩列表表尾节点距离压缩列表的起始地址有多少字节,通过这个偏移量,可以确定表尾节点的地址。 |
| zllen | uint16_t | 2 字节 | 记录了压缩列表包含的节点数量。 最大值为UINT16_MAX (65534),如果超过这个值,此处会记录为65535,但节点的真实数量需要遍历整个压缩列表才能计算得出。 |
| entry | 列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定。 |
| zlend | uint8_t | 1 字节 | 特殊值 0xFF (十进制 255 ),用于标记压缩列表的末端。 |
ZipListEntry
ZipList 中的Entry并不像普通链表那样记录前后节点的指针,因为记录两个指针要占用16个字节,浪费内存。而是采用了下面的结构:

-
previous_entry_length:前一节点的长度,占1个或5个字节。
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值。
- 如果前一节点的长度大于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后四个字节才是真实长度数据。
-
encoding:编码属性,记录content的数据类型(字符串还是整数)以及长度,占用1个、2个或5个字节。
-
contents:负责保存节点的数据,可以是字符串或整数。
ZipList中所有存储长度的数值均采用小端字节序,即低位字节在前,高位字节在后。例如:数值0x1234,采用小端字节序后实际存储值为:0x3412。
Encoding编码
ZipListEntry中的encoding编码分为字符串和整数两种:
字符串:如果encoding是以“00”、“01”或者“10”开头,则证明content是字符串。
| 编码 | 编码长度 | 字符串大小 |
|---|---|---|
| |00pppppp| | 1 bytes | <= 63 bytes |
| |01pppppp|qqqqqqqq| | 2 bytes | <= 16383 bytes |
| |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| | 5 bytes | <= 4294967295 bytes |
例如,我们要保存字符串:“ab”和 “bc”。

ZipListEntry中的encoding编码分为字符串和整数两种:
- 整数:如果encoding是以“11”开始,则证明content是整数,且encoding固定只占用1个字节。
| 编码 | 编码长度 | 整数类型 |
|---|---|---|
| 11000000 | 1 | int16_t(2 bytes) |
| 11010000 | 1 | int32_t(4 bytes) |
| 11100000 | 1 | int64_t(8 bytes) |
| 11110000 | 1 | 24位有符整数(3 bytes) |
| 11111110 | 1 | 8位有符整数(1 bytes) |
| 1111xxxx | 1 | 直接在xxxx位置保存数值,范围从0001~1101,减1后结果为实际值 |

Redis数据结构-ZipList的连锁更新问题
ZipList的每个Entry都包含previous_entry_length来记录上一个节点的大小,长度是1个或5个字节:
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值。
- 如果前一节点的长度大于等于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后四个字节才是真实长度数据。
现在,假设我们有N个连续的、长度为250~253字节之间的entry,因此entry的previous_entry_length属性用1个字节即可表示,如图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r3EpMeDL-1683891939936)(.\原理篇.assets\1653986217182.png)]](https://img-blog.csdnimg.cn/35305cf1b0c544e5a40bda69a20f8ace.png)
ZipList这种特殊情况下产生的连续多次空间扩展操作称之为连锁更新(Cascade Update)。新增、删除都可能导致连锁更新的发生。
小总结:
ZipList特性:
- 压缩列表的可以看做一种连续内存空间的"双向链表"。
- 列表的节点之间不是通过指针连接,而是记录上一节点和本节点长度来寻址,内存占用较低。
- 如果列表数据过多,导致链表过长,可能影响查询性能。
- 增或删较大数据时有可能发生连续更新问题。
相关文章:
Redis数据结构——动态字符串、Dict、ZipList
一、Redis数据结构-动态字符串 我们都知道Redis中保存的Key是字符串,value往往是字符串或者字符串的集合。可见字符串是Redis中最常用的一种数据结构。 不过Redis没有直接使用C语言中的字符串,因为C语言字符串存在很多问题: 获取字符串长度…...

ipad可以用别的品牌的手写笔吗?便宜的ipad电容笔
而对于那些把ipad当做学习工具的人而言,苹果Pencil就成了必备品。但因为苹果Pencil太贵了,学生们买不起。因此,最好的选择还是平替电容笔。作为一个ipad的忠实用户,同时也是一个数字热爱着,这两年来,我一直…...

【数据库】关于SQL SERVER的排序规则的问题分析
在安装报表系统,运行sql语句时候提示“无法解决 equal to 操作的排序规则冲突。”,费了半天时间才搞定,原来是因为sql语句中没有加全collate Chinese_PRC_CI_AI_WS ! 用排序规则特点计算汉字笔划和取得拼音首字母 SQL SERVER的…...

算法修炼之练气篇——练气十三层
博主:命运之光 专栏:算法修炼之练气篇 目录 题目 1023: [编程入门]选择排序 题目描述 输入格式 输出格式 样例输入 样例输出 题目 1065: 二级C语言-最小绝对值 题目描述 输入格式 输出格式 样例输入 样例输出 题目 1021: [编程入门]迭代法求…...
ChatGPT:AI不取代程序员,只取代的不掌握AI的程序员
作者:成都兰亭集势信息技术有限公司技术总监张雄 可能大家会有如下的问题,我就使用chatGPT这个AI工具的API来问一下。 问:chatGPT会替换掉程序员吗?如果能,预计好久? 答:作为一名 AI 语言模型&a…...

数字革命下的产品:百数十年变迁的启示与思考。
随着数字化时代的到来,软件开发成为各行各业不可或缺的一部分。然而,传统的软件开发方法需要长时间的开发周期,高昂的成本和大量的人力资源。因此,低代码开发平台应运而生。低代码开发平台通过简化开发人员的工作和加速软件开发流…...

部门新来一00后,给我卷崩溃了...
2022年已经结束结束了,最近内卷严重,各种跳槽裁员,相信很多小伙伴也在准备今年的金三银四的面试计划。 在此展示一套学习笔记 / 面试手册,年后跳槽的朋友可以好好刷一刷,还是挺有必要的,它几乎涵盖了所有的…...

使用Spring Boot和Docker构建可伸缩的微服务架构,应对增长的业务需求
使用Spring Boot和Docker构建可伸缩的微服务架构,应对增长的业务需求 一、简介1. 微服务架构的定义2. Spring Boot和Docker的概述 二、Spring Boot1. Spring Boot的介绍2. Spring Boot的优势3. Spring Boot的组件4. Spring Boot的应用 三、Docker1. Docker的介绍2. …...

计算机组成原理基础练习题第四章
1.下述说法中()是正确的。 A、半导体RAM信息可读可写,且断电后仍能保持记忆 B、半导体RAM是易失性RAM,而静态RAM中的存储信息是不易失的 C、半导体RAM是易失性RAM,而静态RAM只有在电源不掉电时,所存信息是不易失的 D、以上选项都不对 解析…...

浅谈Gradle构建工具
一、序言 常见的项目构建工具有Ant、Maven、Gradle,以往项目常见采用Maven进构建,但随着技术的发展,越来越多的项目采用Gradle进行构建,例如 Spring-boot。Gradle站在了Ant和Maven构建工具的肩膀上,使用强大的表达式语…...

如何获取和制作免费的icon图标素材
icon 图标在界面设计中虽然占比不大,但却是不可缺少的设计元素之一。设计师通过 icon 图标,将抽象的概念通俗化,降低用户理解某个操作的难度。而设计师也会通过改变 icon 图标的样式来展现整体界面的视觉效果。icon 图标的风格有很多…...
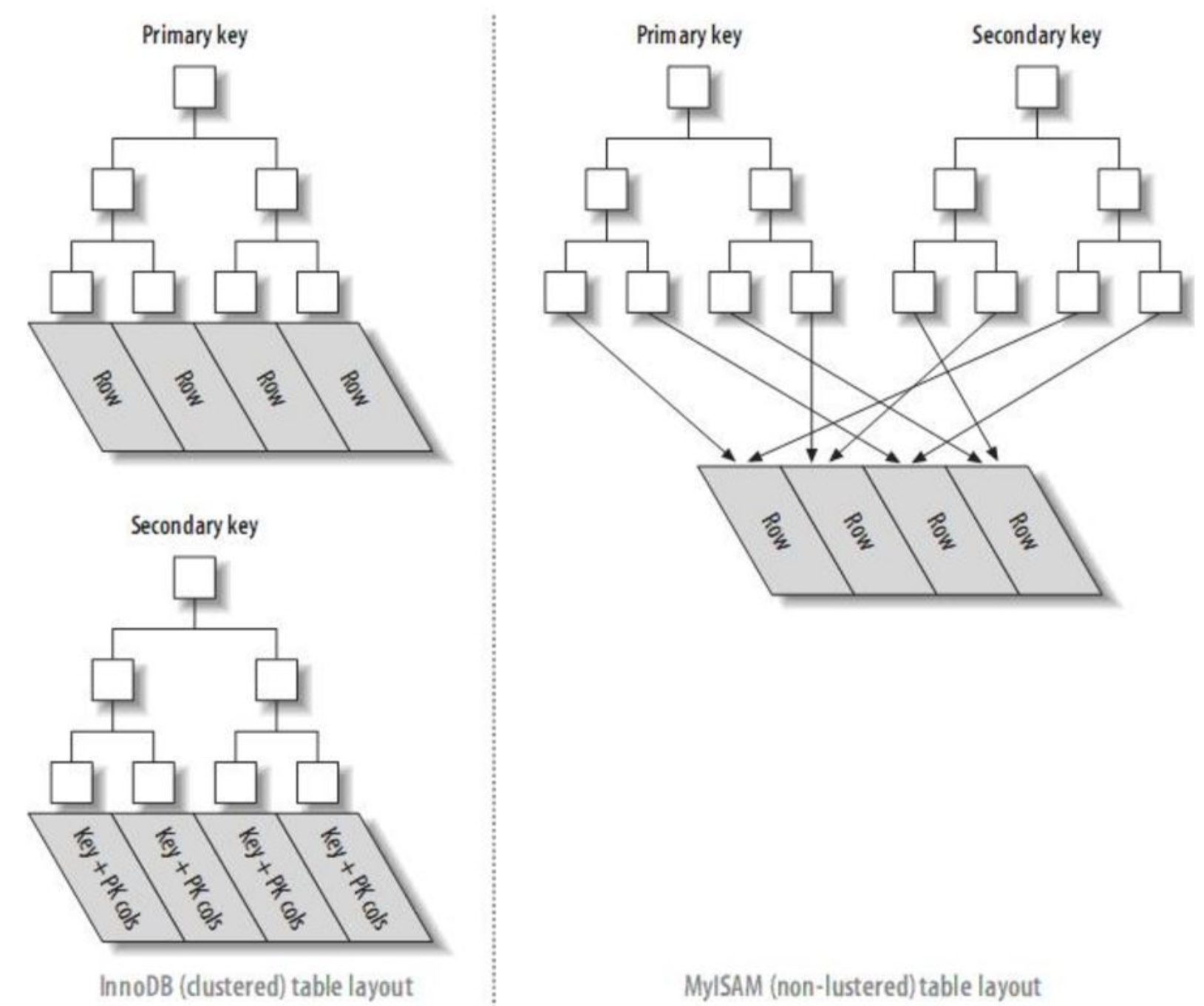
【MySQL】MySQL索引--聚簇索引和非聚簇索引的区别
文章目录 前言1.聚簇索引和非聚簇索引的概念2.两者详细介绍2.1 聚簇索引2.2 非聚簇索引 3. 两者的区别3.1 数据存储方式3.2 二级索引查询 前言 1.聚簇索引和非聚簇索引的概念 数据库表的索引从数据存储方式上可以分为聚簇索引和非聚簇索引两种。“聚簇”的意思是数据行被按照…...

如何使用 SVG.js 中的一些相关方法来创建、设置和操作 image 元素
SVG.js 是一个基于 JavaScript 的 SVG 库,提供了许多常用的 SVG 元素和方法,方便开发者进行 SVG 图形的创建和操作。其中,image 元素是 SVG.js 中较为常用的元素之一,本文将详细介绍 SVG.js 中与 image 元素相关的方法。 一、创建…...

展会进行时!5月16-18日箱讯与您相约中国航交会
宁波国际会展中心7、8号馆 第五届中国(宁波)国际航运物流交易会 暨2023全球物流企业合作博览会 火爆进行中 箱讯与您相约 8号馆 C033K-C036展位 期待您的光临! 2023年5月16-18日,第五届中国(宁波)国际…...

CMake:递归检查并拷贝所有需要的DLL文件
文章目录 1. 目的2. 设计整体思路多层依赖的处理获取 DLL 所在目录探测剩余的 DLL 文件 3. 代码实现判断 stack 是否为空判断 stack 是否为空获取所有 target检测并拷贝 DLL 4. 使用 1. 目的 在基于 CMake 构建的 C/C 工程中,拷贝当前工程需要的每个DLL文件到 Visu…...

python常见问题及解决方案
Python是一种高级编程语言,具有易于学习、易于阅读和易于维护的特点。然而,即使是最有经验的Python开发人员也可能会遇到一些常见的错误。在本文中,我们将讨论一些常见的Python运行时错误,并提供解决这些错误的办法。 语法错误 …...

JUC之Synchronized与Lock
Synchronized 称之为”同步锁 作用: 保证在同一时刻, 被修饰的代码块或方法只会有一个线程执行,以达到保证并发安全的效果 用法: 1.修饰方法:方法锁,锁的对象是当前对象 2.修饰静态方法:类锁…...

动态规划理论基础
文章目录 定义动态规划与分治问题的区别两种方式实现动态规划方法一:带备忘录的自顶向下法方法二:自底向上法 本质核心解题步骤常见题型划分 定义 动态规划方法通常用来求解最优化问题(optimization problem)。这类问题可以有很多可行解,每个…...

Redis的数据类型
参考文档:https://www.runoob.com/redis/redis-tutorial.html redis当中一共支持五种数据类型,分别是: string字符串 list列表 set集合 hash表 zset有序集合 1、对字符串string的操作 下表列出了常用的 redis 字符串命令 1 设置值 获取…...
vue3鼠标经过显示按钮
在前端开发中,我们经常需要在页面中添加一些交互效果来提升用户体验。其中一个常见的需求就是鼠标经过某个元素时显示一个按钮,这个按钮可以用于触发一些操作或者显示更多的内容。 在本篇文章中,我将会介绍如何使用 Vue3 实现一个鼠标经过显…...

3个步骤实现教育资源高效获取:电子教材下载工具全攻略
3个步骤实现教育资源高效获取:电子教材下载工具全攻略 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具 项目地址: https://gitcode.com/GitHub_Trending/tc/tchMaterial-parser tchMaterial-parser是一款专为教育工作者和学习…...

别再让运动模糊毁了你的检测!一文搞懂工业相机飞拍里的CMOS传感器与快门速度怎么配
工业相机飞拍实战:CMOS传感器与快门速度的黄金搭配法则 在一条每分钟处理300个瓶盖的高速灌装线上,质检员小王发现相机拍摄的字符总是出现拖影——这已经是本周第三次因图像模糊导致误检停线了。类似场景每天都在全球数以万计的自动化产线上演࿰…...

从科研到工程:为什么我选择用ROS2重构Apollo/autoware的规控算法?
从科研到工程:为什么我选择用ROS2重构Apollo/autoware的规控算法? 在自动驾驶领域,从实验室原型到量产系统的跨越,往往伴随着技术栈的全面升级。三年前,当我第一次将Apollo的规划控制模块移植到ROS1环境时,…...

告别音乐平台干扰!铜钟音乐如何让你重拾纯净听歌体验?
告别音乐平台干扰!铜钟音乐如何让你重拾纯净听歌体验? 【免费下载链接】tonzhon-music 铜钟 (Tonzhon.com): 免费听歌; 没有直播, 社交, 广告, 干扰; 简洁纯粹, 资源丰富, 体验独特!(密码重置功能已回归) 项目地址: https://gitcode.com/Gi…...

【SpringAI篇04】:从内存到MySQL,构建可重启的智能对话系统
1. 为什么需要从内存存储升级到数据库持久化 刚开始接触SpringAI开发时,很多开发者都会选择默认的内存存储方案。这种方案简单直接,不需要额外配置数据库,特别适合快速原型开发。但当你真正要把应用部署到生产环境时,就会发现内存…...

CodeSys自定义HTML5控件:从零构建到工程实践
1. 为什么需要自定义HTML5控件? 在工业自动化领域,可视化监控是设备管理的重要环节。CodeSys作为主流的工业控制开发平台,其WebVisu功能虽然提供了基础控件库,但在实际项目中经常会遇到这样的尴尬:标准控件无法满足特定…...

DASD-4B-Thinking效果对比:在HumanEval代码生成任务中超越Qwen2.5-7B
DASD-4B-Thinking效果对比:在HumanEval代码生成任务中超越Qwen2.5-7B 1. 为什么这个40亿参数模型值得关注? 你可能已经用过不少大模型,但有没有遇到过这种情况:写一段Python函数时,模型直接给出答案,却跳…...

别光看论文!手把手带你复现CVPR 2025扩散模型加速新星:TinyFusion与DiG的代码实战
别光看论文!手把手带你复现CVPR 2025扩散模型加速新星:TinyFusion与DiG的代码实战 如果你已经厌倦了在arXiv上收藏一堆永远打不开第二次的论文链接,或是被那些充满数学符号却缺少可运行代码的"理论创新"搞得头大,那么这…...

FLUX.1-dev像素生成器教程:多提示词加权与逻辑组合语法详解
FLUX.1-dev像素生成器教程:多提示词加权与逻辑组合语法详解 1. 像素幻梦创意工坊简介 像素幻梦 (Pixel Dream Workshop) 是一款基于FLUX.1-dev扩散模型的像素艺术生成工具,专为创作者设计。它采用16-bit像素风格的现代明亮界面,提供沉浸式的…...

元素偏析系数计算:从概念到实际应用
元素偏析系数计算(Pandat代算或自己操作) 实例32: 偏析系数k是指在熔体凝固过程中,溶质元素在固相和液相中浓度的比值。 通过计算偏析系数,可以预测在凝固过程中某一溶质元素的分布情况,从而帮助设计合金的微观组织结构。 偏析系数 k1 则倾向…...