Azkaban学习——单机版安装与部署
目录
1.解压改名
2.修改装有mysql的虚拟机的my.cnf文件
3.重启装有mysql的虚拟机
4.Datagrip创建azkaban数据库,执行脚本文件
5.修改/opt/soft/azkaban-exec/conf/azkaban.properties文件
6.修改commonprivate.properties
7.传入mysql-connector-java-8.0.29.jar
8.开启Azkaban服务
9.进入Datagrip查看是否成功激活
10.激活executor
11.修改/opt/soft/azkaban-web/conf/azkaban.properties文件
12.修改/opt/soft/azkaban-web/conf/azkaban-users.xml文件
13.复制mysql-connector-java-8.0.29.jar
14.开启AzkabanWeb工程
15.浏览器打开Azkaban服务
16.Azkaban的关闭
1.解压改名
注意:安装Azkaban尽量与安装了mysql的机器避开
[root@lxm147 install]# tar -zxf azkaban-db-3.84.4.tar.gz -C /opt/soft/
[root@lxm147 install]# tar -zxf azkaban-exec-server-3.84.4.tar.gz -C /opt/soft/
[root@lxm147 install]# tar -zxf azkaban-web-server-3.84.4.tar.gz -C /opt/soft/[root@lxm147 soft]# mv azkaban-db-0.1.0-SNAPSHOT/ azkaban-db
[root@lxm147 soft]# mv azkaban-exec-server-0.1.0-SNAPSHOT/ azkaban-exec
[root@lxm147 soft]# mv azkaban-web-server-0.1.0-SNAPSHOT/ azkaban-web
2.修改装有mysql的虚拟机的my.cnf文件
进入/opt/soft/mysql8目录下,修改my.cnf文件,第31行
31 max_allowed_packet = 1024M3.重启装有mysql的虚拟机
[root@localhost mysql8]# shutdown -r now
PolicyKit daemon disconnected from the bus.
We are no longer a registered authentication agent.
Connection closing...Socket close.# 或者
[root@localhost mysql8]# service mysqld restart4.Datagrip创建azkaban数据库,执行脚本文件
Datagrip连接mysql数据库,执行以下命令:
create database if not exists azkaban;use azkaban;CREATE TABLE active_executing_flows (exec_id INT,update_time BIGINT,PRIMARY KEY (exec_id)
);
CREATE TABLE active_sla (exec_id INT NOT NULL,job_name VARCHAR(128) NOT NULL,check_time BIGINT NOT NULL,rule TINYINT NOT NULL,enc_type TINYINT,options LONGBLOB NOT NULL,PRIMARY KEY (exec_id, job_name)
);
CREATE TABLE execution_dependencies(trigger_instance_id varchar(64),dep_name varchar(128),starttime bigint(20) not null,endtime bigint(20),dep_status tinyint not null,cancelleation_cause tinyint not null,project_id INT not null,project_version INT not null,flow_id varchar(128) not null,flow_version INT not null,flow_exec_id INT not null,primary key(trigger_instance_id, dep_name)
);CREATE INDEX ex_end_timeON execution_dependencies (endtime);
CREATE TABLE execution_flows (exec_id INT NOT NULL AUTO_INCREMENT,project_id INT NOT NULL,version INT NOT NULL,flow_id VARCHAR(128) NOT NULL,status TINYINT,submit_user VARCHAR(64),submit_time BIGINT,update_time BIGINT,start_time BIGINT,end_time BIGINT,enc_type TINYINT,flow_data LONGBLOB,executor_id INT DEFAULT NULL,use_executor INT DEFAULT NULL,flow_priority TINYINT NOT NULL DEFAULT 5,PRIMARY KEY (exec_id)
);CREATE INDEX ex_flows_start_timeON execution_flows (start_time);
CREATE INDEX ex_flows_end_timeON execution_flows (end_time);
CREATE INDEX ex_flows_time_rangeON execution_flows (start_time, end_time);
CREATE INDEX ex_flows_flowsON execution_flows (project_id, flow_id);
CREATE INDEX executor_idON execution_flows (executor_id);
CREATE INDEX ex_flows_stausON execution_flows (status);
CREATE TABLE execution_jobs (exec_id INT NOT NULL,project_id INT NOT NULL,version INT NOT NULL,flow_id VARCHAR(128) NOT NULL,job_id VARCHAR(512) NOT NULL,attempt INT,start_time BIGINT,end_time BIGINT,status TINYINT,input_params LONGBLOB,output_params LONGBLOB,attachments LONGBLOB,PRIMARY KEY (exec_id, job_id, flow_id, attempt)
);CREATE INDEX ex_job_idON execution_jobs (project_id, job_id);
-- In table execution_logs, name is the combination of flow_id and job_id
--
-- prefix support and lengths of prefixes (where supported) are storage engine dependent.
-- By default, the index key prefix length limit is 767 bytes for innoDB.
-- from: https://dev.mysql.com/doc/refman/5.7/en/create-index.htmlCREATE TABLE execution_logs (exec_id INT NOT NULL,name VARCHAR(640),attempt INT,enc_type TINYINT,start_byte INT,end_byte INT,log LONGBLOB,upload_time BIGINT,PRIMARY KEY (exec_id, name, attempt, start_byte)
);CREATE INDEX ex_log_attemptON execution_logs (exec_id, name, attempt);
CREATE INDEX ex_log_indexON execution_logs (exec_id, name);
CREATE INDEX ex_log_upload_timeON execution_logs (upload_time);
CREATE TABLE executor_events (executor_id INT NOT NULL,event_type TINYINT NOT NULL,event_time DATETIME NOT NULL,username VARCHAR(64),message VARCHAR(512)
);CREATE INDEX executor_logON executor_events (executor_id, event_time);
CREATE TABLE executors (id INT NOT NULL PRIMARY KEY AUTO_INCREMENT,host VARCHAR(64) NOT NULL,port INT NOT NULL,active BOOLEAN DEFAULT FALSE,UNIQUE (host, port)
);CREATE INDEX executor_connectionON executors (host, port);
CREATE TABLE project_events (project_id INT NOT NULL,event_type TINYINT NOT NULL,event_time BIGINT NOT NULL,username VARCHAR(64),message VARCHAR(512)
);CREATE INDEX logON project_events (project_id, event_time);
CREATE TABLE project_files (project_id INT NOT NULL,version INT NOT NULL,chunk INT,size INT,file LONGBLOB,PRIMARY KEY (project_id, version, chunk)
);CREATE INDEX file_versionON project_files (project_id, version);
CREATE TABLE project_flow_files (project_id INT NOT NULL,project_version INT NOT NULL,flow_name VARCHAR(128) NOT NULL,flow_version INT NOT NULL,modified_time BIGINT NOT NULL,flow_file LONGBLOB,PRIMARY KEY (project_id, project_version, flow_name, flow_version)
);
CREATE TABLE project_flows (project_id INT NOT NULL,version INT NOT NULL,flow_id VARCHAR(128),modified_time BIGINT NOT NULL,encoding_type TINYINT,json MEDIUMBLOB,PRIMARY KEY (project_id, version, flow_id)
);CREATE INDEX flow_indexON project_flows (project_id, version);
CREATE TABLE project_permissions (project_id VARCHAR(64) NOT NULL,modified_time BIGINT NOT NULL,name VARCHAR(64) NOT NULL,permissions INT NOT NULL,isGroup BOOLEAN NOT NULL,PRIMARY KEY (project_id, name, isGroup)
);CREATE INDEX permission_indexON project_permissions (project_id);
CREATE TABLE project_properties (project_id INT NOT NULL,version INT NOT NULL,name VARCHAR(255),modified_time BIGINT NOT NULL,encoding_type TINYINT,property BLOB,PRIMARY KEY (project_id, version, name)
);CREATE INDEX properties_indexON project_properties (project_id, version);
CREATE TABLE project_versions (project_id INT NOT NULL,version INT NOT NULL,upload_time BIGINT NOT NULL,uploader VARCHAR(64) NOT NULL,file_type VARCHAR(16),file_name VARCHAR(128),md5 BINARY(16),num_chunks INT,resource_id VARCHAR(512) DEFAULT NULL,startup_dependencies MEDIUMBLOB DEFAULT NULL,uploader_ip_addr VARCHAR(50) DEFAULT NULL,PRIMARY KEY (project_id, version)
);CREATE INDEX version_indexON project_versions (project_id);
CREATE TABLE projects (id INT NOT NULL PRIMARY KEY AUTO_INCREMENT,name VARCHAR(64) NOT NULL,active BOOLEAN,modified_time BIGINT NOT NULL,create_time BIGINT NOT NULL,version INT,last_modified_by VARCHAR(64) NOT NULL,description VARCHAR(2048),enc_type TINYINT,settings_blob LONGBLOB
);CREATE INDEX project_nameON projects (name);
CREATE TABLE properties (name VARCHAR(64) NOT NULL,type INT NOT NULL,modified_time BIGINT NOT NULL,value VARCHAR(256),PRIMARY KEY (name, type)
);
-- This file collects all quartz table create statement required for quartz 2.2.1
--
-- We are using Quartz 2.2.1 tables, the original place of which can be found at
-- https://github.com/quartz-scheduler/quartz/blob/quartz-2.2.1/distribution/src/main/assembly/root/docs/dbTables/tables_mysql.sqlDROP TABLE IF EXISTS QRTZ_FIRED_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_PAUSED_TRIGGER_GRPS;
DROP TABLE IF EXISTS QRTZ_SCHEDULER_STATE;
DROP TABLE IF EXISTS QRTZ_LOCKS;
DROP TABLE IF EXISTS QRTZ_SIMPLE_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_SIMPROP_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_CRON_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_BLOB_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_JOB_DETAILS;
DROP TABLE IF EXISTS QRTZ_CALENDARS;CREATE TABLE QRTZ_JOB_DETAILS(SCHED_NAME VARCHAR(120) NOT NULL,JOB_NAME VARCHAR(200) NOT NULL,JOB_GROUP VARCHAR(200) NOT NULL,DESCRIPTION VARCHAR(250) NULL,JOB_CLASS_NAME VARCHAR(250) NOT NULL,IS_DURABLE VARCHAR(1) NOT NULL,IS_NONCONCURRENT VARCHAR(1) NOT NULL,IS_UPDATE_DATA VARCHAR(1) NOT NULL,REQUESTS_RECOVERY VARCHAR(1) NOT NULL,JOB_DATA BLOB NULL,PRIMARY KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)
);CREATE TABLE QRTZ_TRIGGERS(SCHED_NAME VARCHAR(120) NOT NULL,TRIGGER_NAME VARCHAR(200) NOT NULL,TRIGGER_GROUP VARCHAR(200) NOT NULL,JOB_NAME VARCHAR(200) NOT NULL,JOB_GROUP VARCHAR(200) NOT NULL,DESCRIPTION VARCHAR(250) NULL,NEXT_FIRE_TIME BIGINT(13) NULL,PREV_FIRE_TIME BIGINT(13) NULL,PRIORITY INTEGER NULL,TRIGGER_STATE VARCHAR(16) NOT NULL,TRIGGER_TYPE VARCHAR(8) NOT NULL,START_TIME BIGINT(13) NOT NULL,END_TIME BIGINT(13) NULL,CALENDAR_NAME VARCHAR(200) NULL,MISFIRE_INSTR SMALLINT(2) NULL,JOB_DATA BLOB NULL,PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),FOREIGN KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)REFERENCES QRTZ_JOB_DETAILS(SCHED_NAME,JOB_NAME,JOB_GROUP)
);CREATE TABLE QRTZ_SIMPLE_TRIGGERS(SCHED_NAME VARCHAR(120) NOT NULL,TRIGGER_NAME VARCHAR(200) NOT NULL,TRIGGER_GROUP VARCHAR(200) NOT NULL,REPEAT_COUNT BIGINT(7) NOT NULL,REPEAT_INTERVAL BIGINT(12) NOT NULL,TIMES_TRIGGERED BIGINT(10) NOT NULL,PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);CREATE TABLE QRTZ_CRON_TRIGGERS(SCHED_NAME VARCHAR(120) NOT NULL,TRIGGER_NAME VARCHAR(200) NOT NULL,TRIGGER_GROUP VARCHAR(200) NOT NULL,CRON_EXPRESSION VARCHAR(200) NOT NULL,TIME_ZONE_ID VARCHAR(80),PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);CREATE TABLE QRTZ_SIMPROP_TRIGGERS(SCHED_NAME VARCHAR(120) NOT NULL,TRIGGER_NAME VARCHAR(200) NOT NULL,TRIGGER_GROUP VARCHAR(200) NOT NULL,STR_PROP_1 VARCHAR(512) NULL,STR_PROP_2 VARCHAR(512) NULL,STR_PROP_3 VARCHAR(512) NULL,INT_PROP_1 INT NULL,INT_PROP_2 INT NULL,LONG_PROP_1 BIGINT NULL,LONG_PROP_2 BIGINT NULL,DEC_PROP_1 NUMERIC(13,4) NULL,DEC_PROP_2 NUMERIC(13,4) NULL,BOOL_PROP_1 VARCHAR(1) NULL,BOOL_PROP_2 VARCHAR(1) NULL,PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);CREATE TABLE QRTZ_BLOB_TRIGGERS(SCHED_NAME VARCHAR(120) NOT NULL,TRIGGER_NAME VARCHAR(200) NOT NULL,TRIGGER_GROUP VARCHAR(200) NOT NULL,BLOB_DATA BLOB NULL,PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);CREATE TABLE QRTZ_CALENDARS(SCHED_NAME VARCHAR(120) NOT NULL,CALENDAR_NAME VARCHAR(200) NOT NULL,CALENDAR BLOB NOT NULL,PRIMARY KEY (SCHED_NAME,CALENDAR_NAME)
);CREATE TABLE QRTZ_PAUSED_TRIGGER_GRPS(SCHED_NAME VARCHAR(120) NOT NULL,TRIGGER_GROUP VARCHAR(200) NOT NULL,PRIMARY KEY (SCHED_NAME,TRIGGER_GROUP)
);CREATE TABLE QRTZ_FIRED_TRIGGERS(SCHED_NAME VARCHAR(120) NOT NULL,ENTRY_ID VARCHAR(95) NOT NULL,TRIGGER_NAME VARCHAR(200) NOT NULL,TRIGGER_GROUP VARCHAR(200) NOT NULL,INSTANCE_NAME VARCHAR(200) NOT NULL,FIRED_TIME BIGINT(13) NOT NULL,SCHED_TIME BIGINT(13) NOT NULL,PRIORITY INTEGER NOT NULL,STATE VARCHAR(16) NOT NULL,JOB_NAME VARCHAR(200) NULL,JOB_GROUP VARCHAR(200) NULL,IS_NONCONCURRENT VARCHAR(1) NULL,REQUESTS_RECOVERY VARCHAR(1) NULL,PRIMARY KEY (SCHED_NAME,ENTRY_ID)
);CREATE TABLE QRTZ_SCHEDULER_STATE(SCHED_NAME VARCHAR(120) NOT NULL,INSTANCE_NAME VARCHAR(200) NOT NULL,LAST_CHECKIN_TIME BIGINT(13) NOT NULL,CHECKIN_INTERVAL BIGINT(13) NOT NULL,PRIMARY KEY (SCHED_NAME,INSTANCE_NAME)
);CREATE TABLE QRTZ_LOCKS(SCHED_NAME VARCHAR(120) NOT NULL,LOCK_NAME VARCHAR(40) NOT NULL,PRIMARY KEY (SCHED_NAME,LOCK_NAME)
);commit;
CREATE TABLE ramp (rampId VARCHAR(45) NOT NULL,rampPolicy VARCHAR(45) NOT NULL,maxFailureToPause INT NOT NULL DEFAULT 0,maxFailureToRampDown INT NOT NULL DEFAULT 0,isPercentageScaleForMaxFailure TINYINT NOT NULL DEFAULT 0,startTime BIGINT NOT NULL DEFAULT 0,endTime BIGINT NOT NULL DEFAULT 0,lastUpdatedTime BIGINT NOT NULL DEFAULT 0,numOfTrail INT NOT NULL DEFAULT 0,numOfFailure INT NOT NULL DEFAULT 0,numOfSuccess INT NOT NULL DEFAULT 0,numOfIgnored INT NOT NULL DEFAULT 0,isPaused TINYINT NOT NULL DEFAULT 0,rampStage TINYINT NOT NULL DEFAULT 0,isActive TINYINT NOT NULL DEFAULT 0,PRIMARY KEY (rampId)
);CREATE INDEX idx_rampON ramp (rampId);
CREATE TABLE ramp_dependency (dependency VARCHAR(45) NOT NULL,defaultValue VARCHAR (500),jobtypes VARCHAR (1000),PRIMARY KEY (dependency)
);CREATE INDEX idx_ramp_dependencyON ramp_dependency(dependency);
CREATE TABLE ramp_exceptional_flow_items (rampId VARCHAR(45) NOT NULL,flowId VARCHAR(128) NOT NULL,treatment VARCHAR(1) NOT NULL,timestamp BIGINT NULL,PRIMARY KEY (rampId, flowId)
);CREATE INDEX idx_ramp_exceptional_flow_itemsON ramp_exceptional_flow_items (rampId, flowId);
CREATE TABLE ramp_exceptional_job_items (rampId VARCHAR(45) NOT NULL,flowId VARCHAR(128) NOT NULL,jobId VARCHAR(128) NOT NULL,treatment VARCHAR(1) NOT NULL,timestamp BIGINT NULL,PRIMARY KEY (rampId, flowId, jobId)
);CREATE INDEX idx_ramp_exceptional_job_itemsON ramp_exceptional_job_items (rampId, flowId, jobId);
CREATE TABLE ramp_items (rampId VARCHAR(45) NOT NULL,dependency VARCHAR(45) NOT NULL,rampValue VARCHAR (500) NOT NULL,PRIMARY KEY (rampId, dependency)
);CREATE INDEX idx_ramp_itemsON ramp_items (rampId, dependency);
CREATE TABLE triggers (trigger_id INT NOT NULL AUTO_INCREMENT,trigger_source VARCHAR(128),modify_time BIGINT NOT NULL,enc_type TINYINT,data LONGBLOB,PRIMARY KEY (trigger_id)
);
CREATE TABLE validated_dependencies (file_name VARCHAR(128),file_sha1 CHAR(40),validation_key CHAR(40),validation_status INT,PRIMARY KEY (validation_key, file_name, file_sha1)
);
5.修改/opt/soft/azkaban-exec/conf/azkaban.properties文件
vim /opt/soft/azkaban-exec/conf/azkaban.properties7 default.timezone.id=Asia/Shanghai21 azkaban.webserver.url=http://192.168.180.147:808144 mysql.host=192.168.180.14145 mysql.database=azkaban46 mysql.user=root47 mysql.password=root52 executor.port=123216.修改commonprivate.properties
[root@lxm147 jobtypes]# vim /opt/soft/azkaban-exec/plugins/jobtypes/commonprivate.properties3 azkaban.native.lib=false
7.传入mysql-connector-java-8.0.29.jar
进入/opt/soft/azkaban-exec/lib目录下
[root@lxm147 lib]# cp /opt/soft/hive312/lib/mysql-connector-java-8.0.29.jar /opt/soft/azkaban-exec/lib[root@lxm147 lib]# rm -rf /opt/soft/azkaban-exec/lib/mysql-connector-java-5.1.28.jar8.开启Azkaban服务
进入 /opt/soft/azkaban-exec/bin目录下
[root@lxm147 bin]# ./start-exec.sh[root@lxm147 bin]# jps
14647 AzkabanExecutorServer
15581 Jps
9.进入Datagrip查看是否成功激活
use azkaban;
select * from executors;
10.激活executor
[root@lxm147 bin]# curl -G "192.168.180.147:12321/executor?action=activate" && echo
{"status":"success"}
激活成功(忽略我的id,因为已经启动过很多次了)

11.修改/opt/soft/azkaban-web/conf/azkaban.properties文件
vim /opt/soft/azkaban-web/conf/azkaban.properties 7 default.timezone.id=Asia/Shanghai41 mysql.host=192.168.180.14142 mysql.database=azkaban43 mysql.user=root44 mysql.password=root48 # MinimumFreeMemory 默认6G,实际服务器内存如果小于此值不启动49 azkaban.executorselector.filters=StaticRemainingFlowSize,CpuStatus
12.修改/opt/soft/azkaban-web/conf/azkaban-users.xml文件
vim /opt/soft/azkaban-web/conf/azkaban-users.xml <azkaban-users><user groups="azkaban" password="azkaban" roles="admin" username="azkaban"/><user password="metrics" roles="metrics" username="metrics"/><user password="123456" roles="admin" username="kb21"/><role name="admin" permissions="ADMIN"/><role name="metrics" permissions="METRICS"/>
</azkaban-users>13.复制mysql-connector-java-8.0.29.jar
进入/opt/soft/azkaban-web/lib目录下
[root@lxm147 lib]# cp /opt/soft/hive312/lib/mysql-connector-java-8.0.29.jar /opt/soft/azkaban-web/lib[root@lxm147 lib]# rm -rf /opt/soft/azkaban-web/lib/mysql-connector-java-5.1.28.jar 14.开启AzkabanWeb工程
进入/opt/soft/azkaban-web目录下
注意:这里不要进入到bin目录下执行start-web.sh命令,因为conf/azkaban-users.xml目录中的某些文件路径是在/conf上面的
[root@lxm147 azkaban-web]# ./bin/start-web.sh
[root@lxm147 azkaban-web]# jps
14647 AzkabanExecutorServer
15641 Jps
15615 AzkabanWebServer
15.浏览器打开Azkaban服务
浏览器输入localhost:8081,如果有下面的页面弹出,就说明Azkaban真正启动,如果没有,可以看看有没有遗漏的步骤,或者写错的单词。
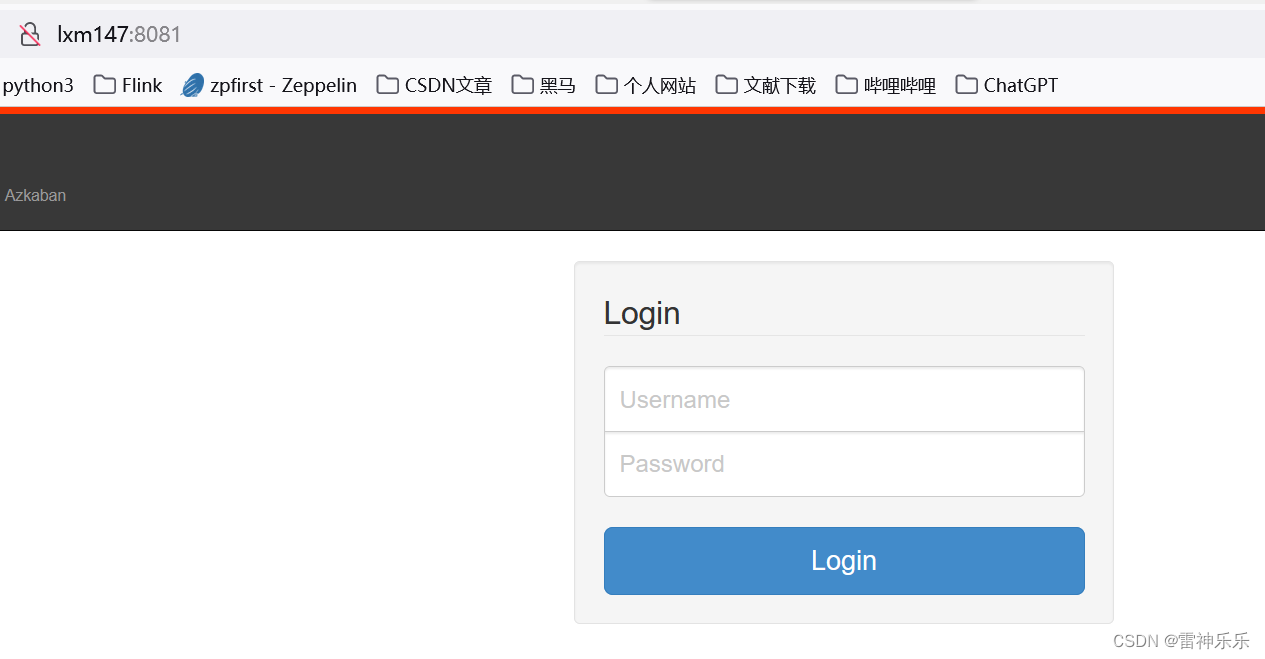
登录的用户名和密码就是步骤11新增的

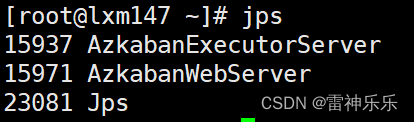
16.Azkaban的关闭
我们之前开启的顺序是:
# 进入 /opt/soft/azkaban-exec/bin目录下
[root@lxm147 bin]# ./start-exec.sh[root@lxm147 bin]# curl -G "192.168.180.147:12321/executor?action=activate" && echo
{"status":"success"}# 进入 /opt/soft/azkaban-web目录下
[root@lxm147 azkaban-web]# ./bin/start-web.sh 关闭服务要反着来:
# 先关闭web
[root@lxm147 ~]# cd /opt/soft/azkaban-web/[root@lxm147 azkaban-web]# ./bin/shutdown-web.sh
Killing web-server. [pid: 15971], attempt: 1
shutdown succeeded[root@lxm147 azkaban-web]# jps
15937 AzkabanExecutorServer
23110 Jps# 再关闭exec
[root@lxm147 azkaban-web]# cd /opt/soft/azkaban-exec/[root@lxm147 azkaban-exec]# ./bin/shutdown-exec.sh
Killing executor. [pid: 15937], attempt: 1
shutdown succeeded[root@lxm147 azkaban-exec]# jps
23139 Jps关于Azkaban的使用,后面会写,敬请期待。
相关文章:
Azkaban学习——单机版安装与部署
目录 1.解压改名 2.修改装有mysql的虚拟机的my.cnf文件 3.重启装有mysql的虚拟机 4.Datagrip创建azkaban数据库,执行脚本文件 5.修改/opt/soft/azkaban-exec/conf/azkaban.properties文件 6.修改commonprivate.properties 7.传入mysql-connector-java-8.0.29…...

table标签-移动端适配
封装一个组件,该组件需要根据不同设备屏幕宽度自适应调整展示方式。对于 PC 端,以类似 el-table 的形式展示数据,而移动端则以一个类似 item 的形式展示每行数据。 可以先在组件中判断设备类型,如以下示例代码所示: …...

Yolov8改进---注意力机制:DoubleAttention、SKAttention,SENet进阶版本
目录 🏆🏆🏆🏆🏆🏆Yolov8魔术师🏆🏆🏆🏆🏆🏆 1. DoubleAttention 2. SKAttention 3.总结...
【逆向工程核心原理:TLS回调函数】
TLS 代码逆向分析领域中,TLS(Thread Local Storage,线程局部存储)回调函数(Callback Function)常用反调试。TLS回调函数的调用运行要先于EP代码的执行,该特征使它可以作为一种反调试技术的使用…...
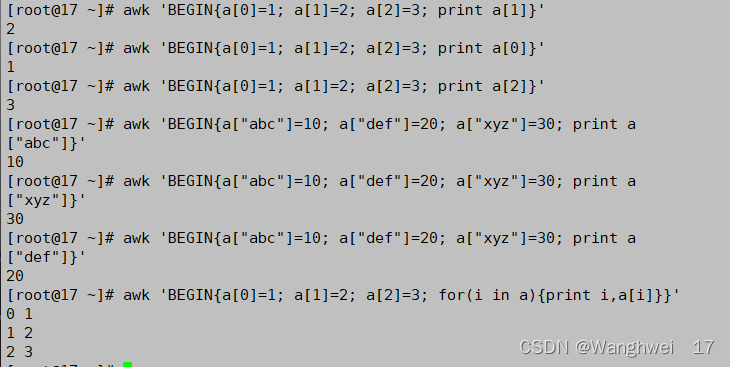
“Shell“Awk命令
文章目录 一.Awk二.Awk按行输出文本三.Awk按字段输出文本四.通过管道,双引号调用shell命令五.总结: 一.Awk Awk的工作原理: 逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中&a…...
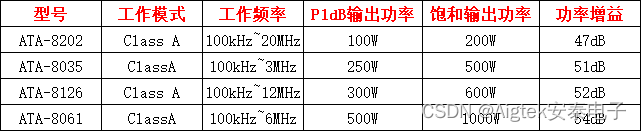
射频放大器的原理和作用(射频放大器和功率放大器的区别)
射频放大器是一种电子电路,用于将输入信号增强到足够高的电平以驱动射频输出负载。其原理和作用如下: 射频放大器的工作原理是利用晶体管的三极管效应,将输入信号放大到足够的电平以驱动输出负载。在射频放大器中,输入信号经过输入…...

揭秘KubeEdge边缘网络项目EdgeMesh:如何打造高速、安全、低延迟的互联网连接
KubeEdge是由百度主导的边缘计算项目,旨在为物联网设备提供一种高效、安全的互联网连接方式。EdgeMesh是KubeEdge的核心组件之一,它是一种基于OpenDaylight的边缘网络协议,能够在物联网设备之间提供高速、可靠的互联网连接。 EdgeMesh的设计目…...
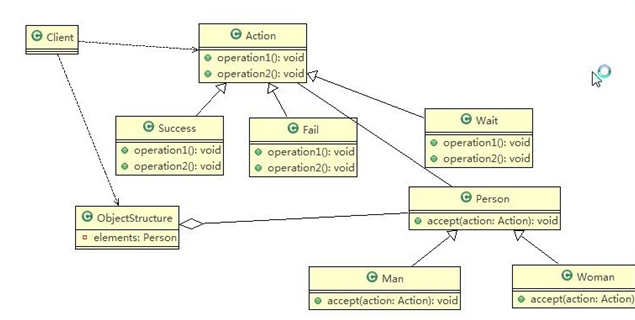
Java设计模式 14-访问者模式
访问者模式 这个模式用的很少,《设计模式》的作者评价为: 大多情况下,你不需要使用访问者模式,但是一旦需要使用它时,那就真的需要使用了 一、测评系统的需求 1)将观众分为男人和女人,对歌手进行测评&…...
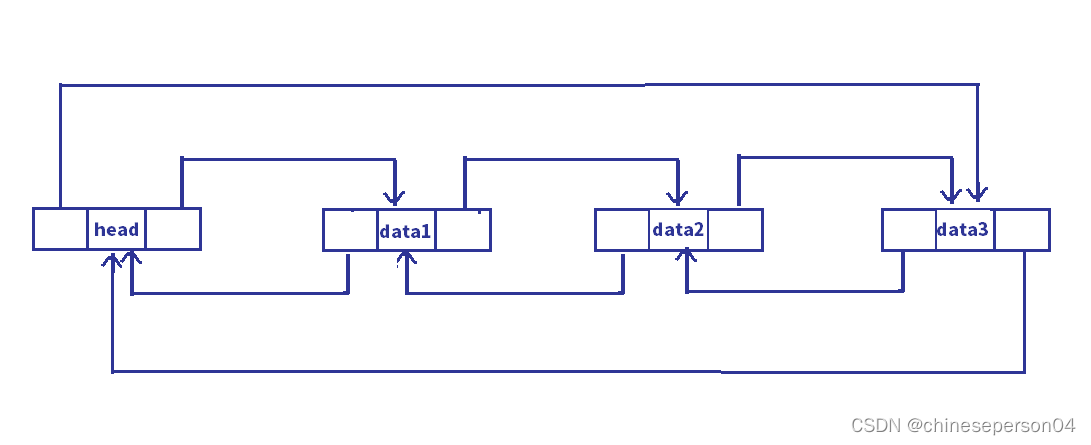
【数据结构】线性表之链表
目录 前言一、链表的定义二、链表的分类1. 单向和双向2. 带头和不带头3. 循环和不循环4. 常用(无头单向非循环链表和带头双向循环链表) 三、无头单向非循环链表的接口及实现1. 单链表的接口2. 接口的实现 四、带头双向循环链表接口的及实现1. 双向链表的…...
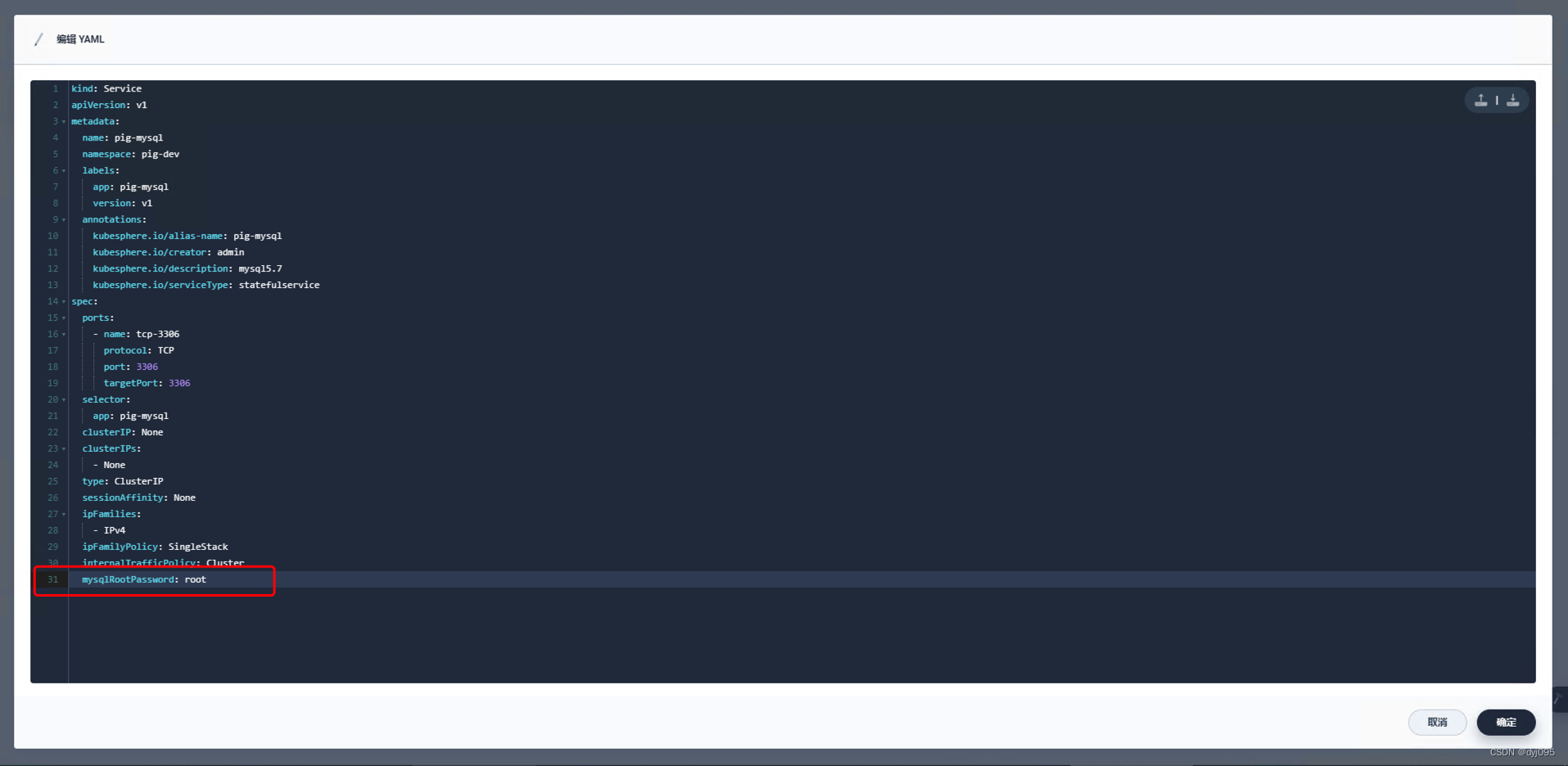
微服架构基础设施环境平台搭建 -(四)在Kubernetes集群基础上搭建Kubesphere平台
微服架构基础设施环境平台搭建 -(四)在Kubernetes集群基础上搭建Kubesphere平台 通过采用微服相关架构构建一套以KubernetesDocker为自动化运维基础平台,以微服务为服务中心,在此基础之上构建业务中台,并通过Jekins自动…...

Linux开发板安装Python环境
1. 环境介绍 硬件:STM32MP157,使用的是野火出的开发板。 软件:Debian ARM 架构制作的 Linux 发行版,版本信息如下: Linux发行版本:Debian GNU/Linux 10 内核版本:4.19.94 2. Python 简介…...
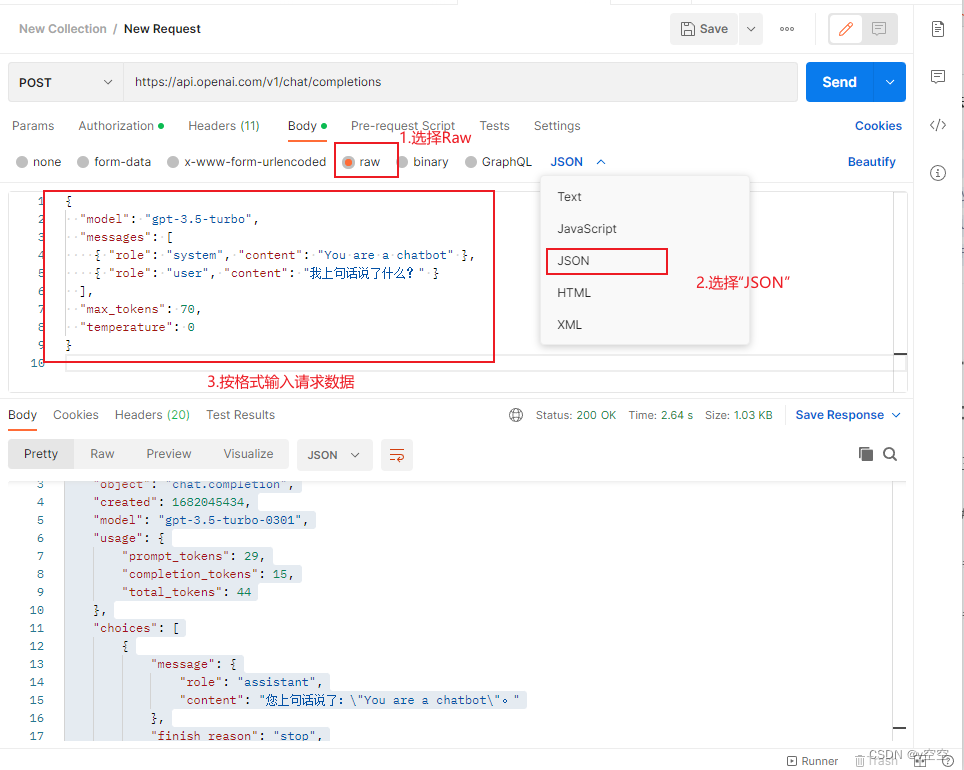
ChatGPT 聊天接口API 使用
一、准备工作 1.准备 OPENAI_ACCESS_TOKEN 2.准备好PostMan 软件 二、测试交流Demo 本次使用POSTMAN工具进行快速测试,旨在通过ChatGPT API实现有效的上下文流。在测试过程中,我们发现了三个问题: 1.如果您想要进行具有上下文的交流&…...

软件测试月薪2万,需要技术达到什么水平?
最近跟朋友在一起聚会的时候,提了一个问题,说一个软件测试工程师如何能月薪达到二万,技术水平需要达到什么程度?人回答说这只能是大企业或者互联网企业工程师才能拿到。也许是的,小公司或者非互联网企业拿二万的不太可…...

从入门到进阶,Vue框架让Web开发更简单高效
Vue是现代前端开发中最为流行的JavaScript框架之一,它具有轻量、易学、易用的特点,能够帮助开发者构建出高效、交互丰富的Web应用。在本文中,我们将会深入探索Vue框架的各个方面,包括Vue组件、Vue路由、Vue状态管理等,…...
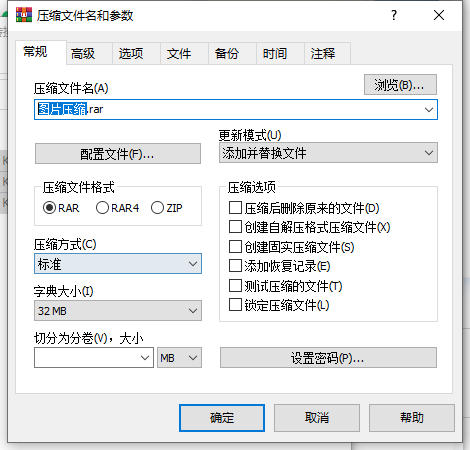
怎么缩小照片的kb,压缩照片kb的几种方法
缩小照片的KB大小是我们日常工作生活中遇到的常见问题。虽然听起来十分专业,但其实很简单。照片的KB是指照片文件的大小,通常以“KB”为单位表示。缩小照片的KB就是减小照片文件的大小,以便占用更少的磁盘空间或更快地上传和下载照片。在实际…...

2. 注解Annotation
Java注解(Annotation)又称为Java标注,是JDK5.0引入的一种注释机制.注解是原数据的一种形式,提供有关于程序但不属于程序本身的数据.注解对他们注解的代码的操作没有直接的影响. 声明方式 注解的声明方式使用interface关键字,举例说明: public interface MyInject{ }元注解 Ta…...

【Leetcode -495.提莫攻击 -496.下一个更大的元素Ⅰ】
Leetcode Leetcode -495.提莫攻击Leetcode - 496.下一个更大的元素Ⅰ Leetcode -495.提莫攻击 题目:在《英雄联盟》的世界中,有一个叫 “提莫” 的英雄。他的攻击可以让敌方英雄艾希(编者注:寒冰射手)进入中毒状态。 …...
肝一肝设计模式【八】-- 外观模式
系列文章目录 肝一肝设计模式【一】-- 单例模式 传送门 肝一肝设计模式【二】-- 工厂模式 传送门 肝一肝设计模式【三】-- 原型模式 传送门 肝一肝设计模式【四】-- 建造者模式 传送门 肝一肝设计模式【五】-- 适配器模式 传送门 肝一肝设计模式【六】-- 装饰器模式 传送门 肝…...
Maven uber-jar(带依赖的打包插件)maven-shade-plugin
文章目录 最基础的 maven-shade-plugin 使用生成可执行的 Jar 包 和 常用的资源转换类包名重命名打包时排除依赖与其他常用打包插件比较 本文是对 maven-shade-plugin 常用配置的介绍,更详细的学习请参照 Apache Maven Shade Plugin 官方文档 通过使用 maven-shade…...
MySQL基础(二十八)索引优化与查询优化
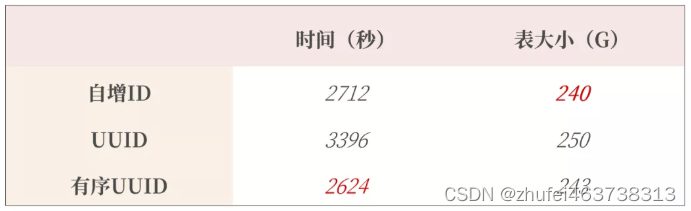
都有哪些维度可以进行数据库调优?简言之: 索引失效、没有充分利用到索引——索引建立关联查询太多JOIN (设计缺陷或不得已的需求)——SQL优化服务器调优及各个参数设置(缓冲、线程数等)———调整my.cnf。数据过多――分库分表 关于数据库调优的知识点非常分散。不同的DBMS&…...

基于高频脉冲注入法的转子初始位置辨识算法代码及其应用
基于高频脉冲注入法转子初始位置辨识算法代码,无感启动中最重要的便是初始位置估计,高频注入法无感运行的方法适用于带电机运行,用在初始位置检测时,时间不固定,依赖电机参数。 采用脉冲注入法后,检测时间固…...

数据仓库的设计与实现:从概念到落地
数据仓库的设计与实现:从概念到落地 前言 作为一个在数据深渊里捞了十几年 Bug 的女码农,我深知数据仓库在企业数据管理中的重要性。一个好的数据仓库不仅能帮助企业整合分散的数据,还能为业务决策提供有力支持。今天,我就来聊聊数…...

Rivets.js实际项目案例:构建电商应用的数据绑定架构
Rivets.js实际项目案例:构建电商应用的数据绑定架构 【免费下载链接】rivets Lightweight and powerful data binding. 项目地址: https://gitcode.com/gh_mirrors/ri/rivets Rivets.js是一个轻量级且功能强大的数据绑定库,它能帮助你快速构建响应…...

多无人机协同避障之自适应重构 V 型编队与分布式控制算法探索
多无人机 协同避障 自适应重构v型编队 分布式控制算法 包含参考文献和完整代码 #无人机 #协同避障 #重构队形 #分布式控制 #自适应重构编队在无人机应用领域,多无人机协同作业已成为研究热点。其中,协同避障以及自适应重构编队是实现高效任务执行的关键技…...

码农专用,轻松拥有小金库
作为天天和代码、BUG、项目进度死磕的程序员,咱们这辈子靠理性思维、逻辑推演解决了无数技术难题,可一碰到理财这件事,几乎全员踩坑:要么没时间研究,要么怕风险不敢下手,最后只能把辛苦攒下的工资、年终奖丢…...

Umi-OCR PDF文字识别全攻略:从技术原理到实战应用
Umi-OCR PDF文字识别全攻略:从技术原理到实战应用 【免费下载链接】Umi-OCR Umi-OCR: 这是一个免费、开源、可批量处理的离线OCR软件,适用于Windows系统,支持截图OCR、批量OCR、二维码识别等功能。 项目地址: https://gitcode.com/GitHub_T…...

Qwen-Image-2512保姆级教程:从零开始构建个人像素艺术AI工作室
Qwen-Image-2512保姆级教程:从零开始构建个人像素艺术AI工作室 1. 为什么选择Qwen-Image-2512做像素艺术 像素艺术近年来在游戏开发、NFT创作和数字艺术领域越来越受欢迎。传统手工绘制像素图需要专业美术功底,而Qwen-Image-2512结合Pixel Art LoRA的技…...

795. 广告标识工厂哪家上门维修最及时?
在当今商业社会,广告标识对于企业的品牌展示和宣传起着至关重要的作用。然而,广告标识在使用过程中难免会出现各种问题,这就需要及时的上门维修服务。那么,广告标识工厂哪家上门维修最及时呢?今天就为大家推荐河北兴盛…...

数据恢复与Python环境重建指南
数据恢复前的准备工作确认Anaconda安装路径及删除方式(如回收站清理、命令行删除等),避免覆盖原始数据。列出常用存储位置:C:\Users\<用户名>\Anaconda3(Windows)或/home/<用户名>/anaconda3&a…...

C# 爬虫抓图遇到TLS 1.3报错?.NET Framework 4.7 的终极自救指南
C# 爬虫抓图遇到TLS 1.3报错?.NET Framework 4.7 的终极自救指南 当你的C#爬虫在.NET Framework 4.7环境下突然开始报错"未能创建 SSL/TLS 安全通道",而昨天还能正常运行——这很可能是因为目标服务器升级到了TLS 1.3协议。作为一个长期维护企…...