【数据结构】线性表之链表
目录
- 前言
- 一、链表的定义
- 二、链表的分类
- 1. 单向和双向
- 2. 带头和不带头
- 3. 循环和不循环
- 4. 常用(无头单向非循环链表和带头双向循环链表)
- 三、无头单向非循环链表的接口及实现
- 1. 单链表的接口
- 2. 接口的实现
- 四、带头双向循环链表接口的及实现
- 1. 双向链表的接口
- 2. 接口的实现
- 五、带头双向循环链表VS无头单向非循环链表
- 1. 带头双向循环链表
- 1.1 带头双向循环链表的优点:
- 1.2 带头双向循环链表的缺点:
- 2. 无头单向非循环链表
- 2.1 无头单向非循环链表的优点:
- 2.2 无头单向非循环链表的缺点:
- 3. 小结
- 六、链表VS顺序表
- 1. 带头双向循环链表
- 1.1 链表的优点:
- 2. 链表的缺点:
- 2. 顺序表
- 2.1顺序表的优点
- 2.2顺序表的缺点
- 结尾
前言
上一篇文章讲述了线性表中的顺序表,这篇文章讲述关于链表的定义、类别、实现、多种不同链表的优缺点和链表与顺序表的优缺点。
关于上一篇文章的链接:线性表之顺序表
一、链表的定义
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。

二、链表的分类
1. 单向和双向

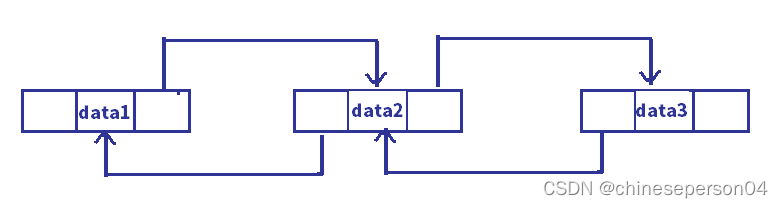
2. 带头和不带头


3. 循环和不循环
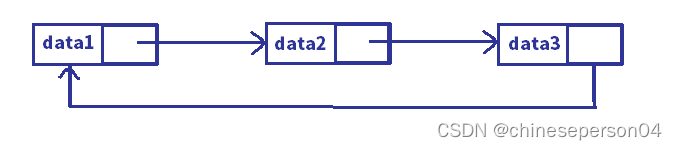
4. 常用(无头单向非循环链表和带头双向循环链表)
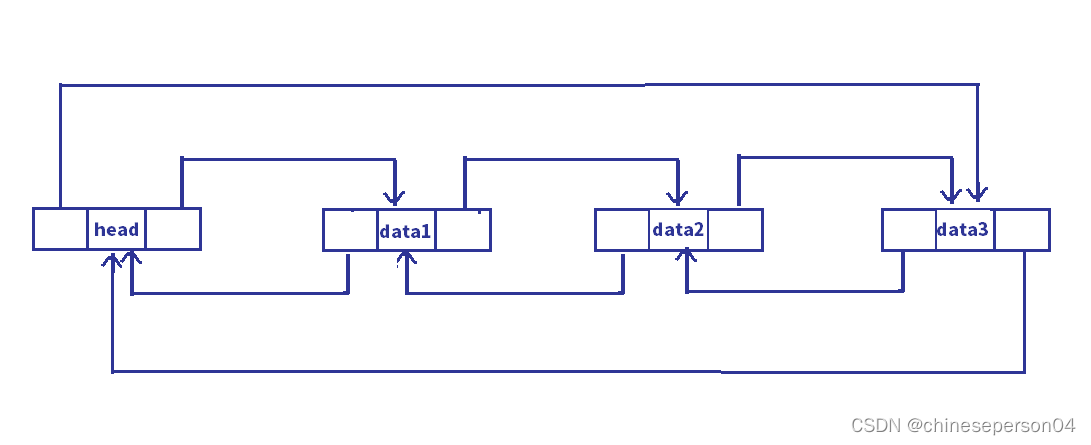
三、无头单向非循环链表的接口及实现
1. 单链表的接口
#pragma once
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <assert.h>// slist.h
typedef int SLTDateType;
typedef struct SListNode
{SLTDateType data;struct SListNode* next;
}SListNode;// 动态申请一个节点
SListNode* BuySListNode(SLTDateType x);
// 单链表打印
void SListPrint(SListNode* plist);
// 单链表尾插
void SListPushBack(SListNode** pplist, SLTDateType x);
// 单链表的头插
void SListPushFront(SListNode** pplist, SLTDateType x);
// 单链表的尾删
void SListPopBack(SListNode** pplist);
// 单链表头删
void SListPopFront(SListNode** pplist);
// 单链表查找
SListNode* SListFind(SListNode* plist, SLTDateType x);
// 单链表在pos位置之后插入x
void SListInsertAfter(SListNode* pos, SLTDateType x);
// 单链表删除pos位置之后的值
void SListEraseAfter(SListNode* pos);
// 单链表的销毁
void SListDestroy(SListNode* plist);
2. 接口的实现
#include "slist.h"SListNode* BuySListNode(SLTDateType x)
{//创造新节点SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));if (newnode == NULL){perror("malloc");return NULL;}//新节点初始化newnode->data = x;newnode->next = NULL;return newnode;
}void SListPushBack(SListNode** pplist, SLTDateType x)
{//这里使用二级指针的原因是://若链表为空,需要改变的就是结构体指针,需要结构体指针的地址//若传入的是一级指针,这里传入的只是临时拷贝,无法改变函数外的变量if (*pplist == NULL){*pplist = BuySListNode(x);}//若不为空,需要改变的是结构体,只需要结构体的指针else{SListNode* tail = *pplist;SListNode* newnode = BuySListNode(x);while (tail->next){tail = tail->next;}tail->next = newnode;}}void SListPrint(SListNode* plist)
{while (plist){printf("%d->", plist->data);plist = plist->next;}printf("NULL");
}void SListPushFront(SListNode** pplist, SLTDateType x)
{//这里使用二级指针的原因是:每次头删都需要改变头节点SListNode* newnode = BuySListNode(x);newnode->next = *pplist;*pplist = newnode;
}//无头单链表尾删删除节点的时候有三种情况
void SListPopBack(SListNode** pplist)
{//没有节点assert(*pplist);//一个节点if ((*pplist)->next == NULL){free(*pplist);*pplist = NULL;}//多个节点else{//尾删既可以找尾找尾的前一个节点,也可以创造一个变量记录尾节点的前一个节点//创造一个变量记录尾节点的前一个节点// SListNode* tail = *pplist;// SListNode* prev = NULL;// while (tail->next)// {// prev = tail;// tail = tail->next;// }// free(prev->next);// prev->next = NULL;//找尾找尾的前一个节点SListNode* tail = *pplist;while (tail->next->next){tail = tail->next;}free(tail->next);tail->next = NULL;}
}//无头单链表头删删除节点的时候有三种情况,但只有一个节点和多个节点的情况可以合并
void SListPopFront(SListNode** pplist)
{//无节点时assert(*pplist);//有节点时SListNode* del = *pplist;*pplist = del->next;free(del);
}SListNode* SListFind(SListNode* plist, SLTDateType x)
{SListNode* cur = plist;while (cur){if (cur->data == x)return cur;cur = cur->next;}return NULL;
}void SListInsertAfter(SListNode* pos, SLTDateType x)
{//断言:在pos后面插入一个节点,最差的情况是pos为尾节点,但不能为NULLassert(pos);SListNode* cur = (SListNode*)malloc(sizeof(SListNode));if (cur == NULL){perror("malloc");return;}cur->data = x;cur->next = pos->next;pos->next = cur;
}void SListEraseAfter(SListNode* pos)
{//需要删除节点的前一个节点不能为NULL,删除节点也不能为NULLassert(pos);assert(pos->next);SListNode* next = pos->next;pos->next = next->next;free(next);
}void SListDestroy(SListNode* plist)
{SListNode* del = NULL;while (plist){del = plist;plist = plist->next;free(del);}
}
四、带头双向循环链表接口的及实现
1. 双向链表的接口
#pragma once#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <stdbool.h>// 带头+双向+循环链表增删查改实现
typedef int LTDataType;
typedef struct ListNode
{LTDataType data;struct ListNode* next;struct ListNode* prev;
}ListNode;// 创建返回链表的头结点.
ListNode* ListCreate();
// 双向链表销毁
void ListDestory(ListNode* pHead);
// 双向链表打印
void ListPrint(ListNode* pHead);
// 双向链表尾插
void ListPushBack(ListNode* pHead, LTDataType x);
// 双向链表尾删
void ListPopBack(ListNode* pHead);
// 双向链表头插
void ListPushFront(ListNode* pHead, LTDataType x);
// 双向链表头删
void ListPopFront(ListNode* pHead);
// 双向链表查找
ListNode* ListFind(ListNode* pHead, LTDataType x);
// 双向链表在pos的前面进行插入
void ListInsert(ListNode* pos, LTDataType x);
// 双向链表删除pos位置的节点
void ListErase(ListNode* pos);
2. 接口的实现
#include "list.h"// 创建返回链表的头结点.
ListNode* ListCreate()
{ListNode* phead = (ListNode*)malloc(sizeof(ListNode));if (phead == NULL){perror("malloc");return NULL;}//让头的 next 和 prev 都指向自己//则双向链表为空phead->next = phead;phead->prev = phead;return phead;
}// 创造新节点
ListNode* BuyTLNode(LTDataType x)
{ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));if (newnode == NULL){perror("malloc");return NULL;}newnode->data = x;return newnode;
}// 双向链表尾插
void ListPushBack(ListNode* pHead, LTDataType x)
{/*ListNode* tail = pHead->prev;ListNode* newnode = BuyTLNode(x);newnode->next = pHead;newnode->prev = tail;tail->next = newnode;pHead->prev = newnode;*/ListInsert(pHead, x); //复用
}// 双向链表打印
void ListPrint(ListNode* pHead)
{printf("header <--> ");//打印的时候,由于头内的 data 的值没用//则从头的的下一个节点开始打印//并且在循环到头的时候打印结束ListNode* cur = pHead ->next;while (cur != pHead){printf("%d <--> ", cur->data);cur = cur->next;}printf("\n");
}// 判断双向链表是否为空
bool LTEmpty(ListNode* pHead)
{assert(pHead);return pHead->next == pHead;
}// 双向链表头删
void ListPopFront(ListNode* pHead)
{assert(pHead);assert(!(LTEmpty(pHead)));/*ListNode* first = pHead->next;ListNode* second = first->next;pHead->next = second;second->prev = pHead;free(first);*/ListErase(pHead->next); //复用
}// 双向链表头插
void ListPushFront(ListNode* pHead, LTDataType x)
{/*ListNode* next = pHead->next;ListNode* newnode = BuyTLNode(x);newnode->next = next;newnode->prev = pHead;next->prev = newnode;pHead->next = newnode;*/ListInsert(pHead->next, x);//复用
}// 双向链表尾删
void ListPopBack(ListNode* pHead)
{assert(pHead); assert(!(LTEmpty(pHead)));/*ListNode* tail = pHead->prev;ListNode* tailPrev = tail->prev;tailPrev->next = pHead;pHead->prev = tailPrev;free(tail);*/ListErase(pHead->prev); //复用
}// 双向链表查找
ListNode* ListFind(ListNode* pHead, LTDataType x)
{ListNode* cur = pHead ->next;while (cur){if (cur->data == x){return cur;}cur = cur->next;}return NULL;
}// 双向链表在pos的前面进行插入
void ListInsert(ListNode* pos, LTDataType x)
{assert(pos);ListNode* newnode = BuyTLNode(x);ListNode* posPrev = pos->prev;newnode->next = pos;newnode->prev = posPrev;posPrev->next = newnode;pos->prev = newnode;
}
// 双向链表删除pos位置的节点
void ListErase(ListNode* pos)
{assert(pos);ListNode* posPrev = pos->prev;ListNode* posNext = pos->next;posPrev->next = posNext;posNext->prev = posPrev;free(pos);
}
五、带头双向循环链表VS无头单向非循环链表
1. 带头双向循环链表
1.1 带头双向循环链表的优点:
- 可以自由地在链表中任意位置插入和删除节点,这是因为双向链表可以方便地找到前驱和后继节点。
- 可以支持双向遍历,即可以从前往后或从后往前遍历链表。
- 可以更加高效地实现某些特殊的操作,比如在链表中删除指定节点,需要同时修改其前驱和后继节点的指针,双向链表则可以直接完成这个操作,而单向链表则需要遍历到前驱节点才能完成。
1.2 带头双向循环链表的缺点:
- 因为每个节点都要额外存储一个前驱节点的指针,所以需要更多的内存空间。
- 因为需要维护前驱和后继节点的指针,所以在插入和删除节点时需要更多的操作,导致时间复杂度较高。
2. 无头单向非循环链表
2.1 无头单向非循环链表的优点:
- 因为每个节点只需存储一个后继节点的指针,所以需要较少的内存空间。
- 在插入和删除节点时,只需要修改前一个节点的指针,不需要修改后一个节点的指针,操作相对简单,导致时间复杂度较低。
2.2 无头单向非循环链表的缺点:
- 无法实现双向遍历,即无法从后往前遍历链表。
- 在删除指定节点时,需要先遍历到其前驱节点,才能完成删除操作,导致删除效率较低。
3. 小结
总之,选择哪种链表数据结构应该根据具体的应用场景和需要做的操作来决定。如果需要频繁地插入和删除节点,且需要支持双向遍历,可以选择带头双向循环链表;如果需要占用较少的内存空间,且不需要双向遍历,可以选择无头单向非循环链表。
六、链表VS顺序表
1. 带头双向循环链表
1.1 链表的优点:
- 动态内存分配:链表可以在运行时动态地分配内存,因此可以根据实际需要灵活地增加或减少节点数。
- 插入和删除操作高效:由于链表中的元素不必在连续的内存空间中存储,所以插入和删除操作非常高效,只需要修改指针,而不需要移动所有后续元素。
- 大小不受限制:链表的大小不受限制,可以根据实际需要进行扩展。
2. 链表的缺点:
- 随机访问低效:由于链表中的元素不是按顺序存储的,因此随机访问某个元素的效率比较低,需要从头开始遍历
O(N)。 - 存储空间开销大:链表每个节点都需要额外的指针来指向下一个节点,这样会增加存储空间的开销。
- 缓存不友好:由于链表中的元素不是按顺序存储的,因此可能会导致缓存未命中,降低访问效率。
2. 顺序表
2.1顺序表的优点
- 随机访问高效:下标的随机访问效率高
O(1)。 - 尾删尾插高效:顺序表的尾插尾删不需要移动数据,效率高。
- 缓存友好:由于链表中的元素是按顺序存储的,缓存命中率高,访问效率高。
2.2顺序表的缺点
- 部分插入删除操作低效:由于顺序表中的元素是物理结构上是连续的,当数据插入删除前面顺序表的时候需要移动数据,效率低
O(N)。 - 内存大小受限:当顺序表内存存满后需要扩容,扩容需要代价,并且顺序表通常会有内存的浪费情况。
结尾
如果有什么建议和疑问,或是有什么错误,希望大家能够提一下。
希望大家以后也能和我一起进步!!
如果这篇文章对你有用的话,希望能给我一个小小的赞!
相关文章:
【数据结构】线性表之链表
目录 前言一、链表的定义二、链表的分类1. 单向和双向2. 带头和不带头3. 循环和不循环4. 常用(无头单向非循环链表和带头双向循环链表) 三、无头单向非循环链表的接口及实现1. 单链表的接口2. 接口的实现 四、带头双向循环链表接口的及实现1. 双向链表的…...
微服架构基础设施环境平台搭建 -(四)在Kubernetes集群基础上搭建Kubesphere平台
微服架构基础设施环境平台搭建 -(四)在Kubernetes集群基础上搭建Kubesphere平台 通过采用微服相关架构构建一套以KubernetesDocker为自动化运维基础平台,以微服务为服务中心,在此基础之上构建业务中台,并通过Jekins自动…...

Linux开发板安装Python环境
1. 环境介绍 硬件:STM32MP157,使用的是野火出的开发板。 软件:Debian ARM 架构制作的 Linux 发行版,版本信息如下: Linux发行版本:Debian GNU/Linux 10 内核版本:4.19.94 2. Python 简介…...
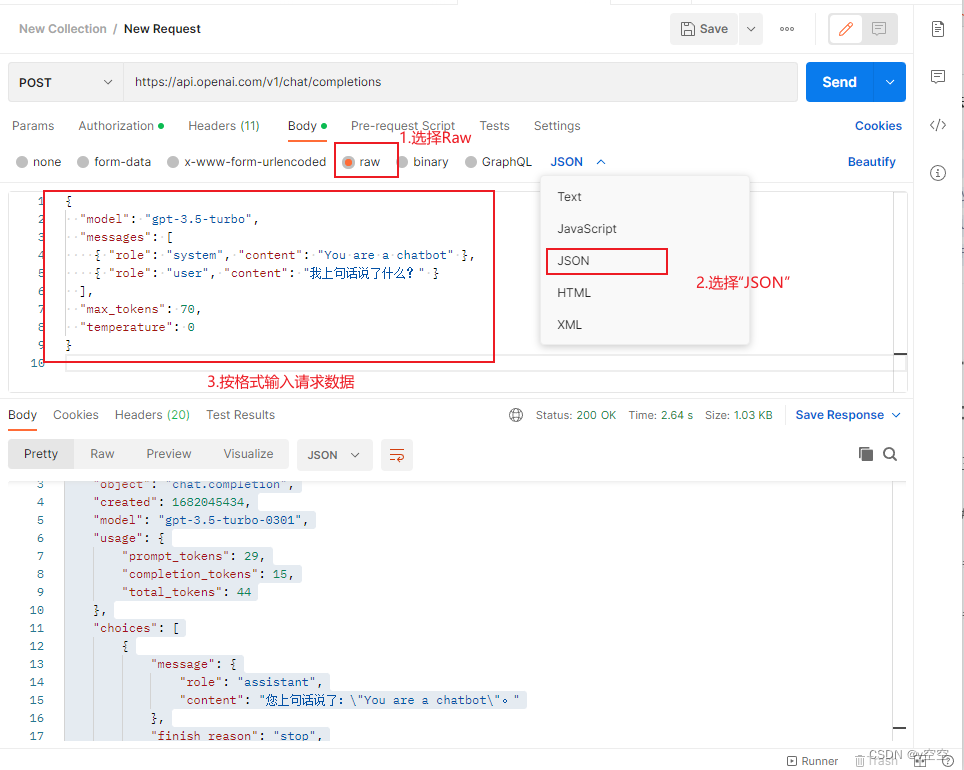
ChatGPT 聊天接口API 使用
一、准备工作 1.准备 OPENAI_ACCESS_TOKEN 2.准备好PostMan 软件 二、测试交流Demo 本次使用POSTMAN工具进行快速测试,旨在通过ChatGPT API实现有效的上下文流。在测试过程中,我们发现了三个问题: 1.如果您想要进行具有上下文的交流&…...

软件测试月薪2万,需要技术达到什么水平?
最近跟朋友在一起聚会的时候,提了一个问题,说一个软件测试工程师如何能月薪达到二万,技术水平需要达到什么程度?人回答说这只能是大企业或者互联网企业工程师才能拿到。也许是的,小公司或者非互联网企业拿二万的不太可…...

从入门到进阶,Vue框架让Web开发更简单高效
Vue是现代前端开发中最为流行的JavaScript框架之一,它具有轻量、易学、易用的特点,能够帮助开发者构建出高效、交互丰富的Web应用。在本文中,我们将会深入探索Vue框架的各个方面,包括Vue组件、Vue路由、Vue状态管理等,…...
怎么缩小照片的kb,压缩照片kb的几种方法
缩小照片的KB大小是我们日常工作生活中遇到的常见问题。虽然听起来十分专业,但其实很简单。照片的KB是指照片文件的大小,通常以“KB”为单位表示。缩小照片的KB就是减小照片文件的大小,以便占用更少的磁盘空间或更快地上传和下载照片。在实际…...

2. 注解Annotation
Java注解(Annotation)又称为Java标注,是JDK5.0引入的一种注释机制.注解是原数据的一种形式,提供有关于程序但不属于程序本身的数据.注解对他们注解的代码的操作没有直接的影响. 声明方式 注解的声明方式使用interface关键字,举例说明: public interface MyInject{ }元注解 Ta…...

【Leetcode -495.提莫攻击 -496.下一个更大的元素Ⅰ】
Leetcode Leetcode -495.提莫攻击Leetcode - 496.下一个更大的元素Ⅰ Leetcode -495.提莫攻击 题目:在《英雄联盟》的世界中,有一个叫 “提莫” 的英雄。他的攻击可以让敌方英雄艾希(编者注:寒冰射手)进入中毒状态。 …...
肝一肝设计模式【八】-- 外观模式
系列文章目录 肝一肝设计模式【一】-- 单例模式 传送门 肝一肝设计模式【二】-- 工厂模式 传送门 肝一肝设计模式【三】-- 原型模式 传送门 肝一肝设计模式【四】-- 建造者模式 传送门 肝一肝设计模式【五】-- 适配器模式 传送门 肝一肝设计模式【六】-- 装饰器模式 传送门 肝…...
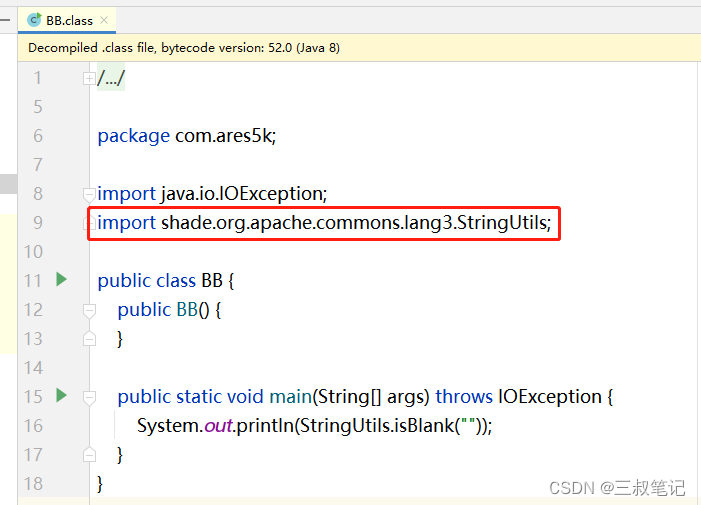
Maven uber-jar(带依赖的打包插件)maven-shade-plugin
文章目录 最基础的 maven-shade-plugin 使用生成可执行的 Jar 包 和 常用的资源转换类包名重命名打包时排除依赖与其他常用打包插件比较 本文是对 maven-shade-plugin 常用配置的介绍,更详细的学习请参照 Apache Maven Shade Plugin 官方文档 通过使用 maven-shade…...
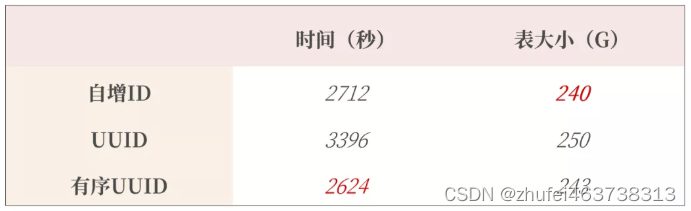
MySQL基础(二十八)索引优化与查询优化
都有哪些维度可以进行数据库调优?简言之: 索引失效、没有充分利用到索引——索引建立关联查询太多JOIN (设计缺陷或不得已的需求)——SQL优化服务器调优及各个参数设置(缓冲、线程数等)———调整my.cnf。数据过多――分库分表 关于数据库调优的知识点非常分散。不同的DBMS&…...
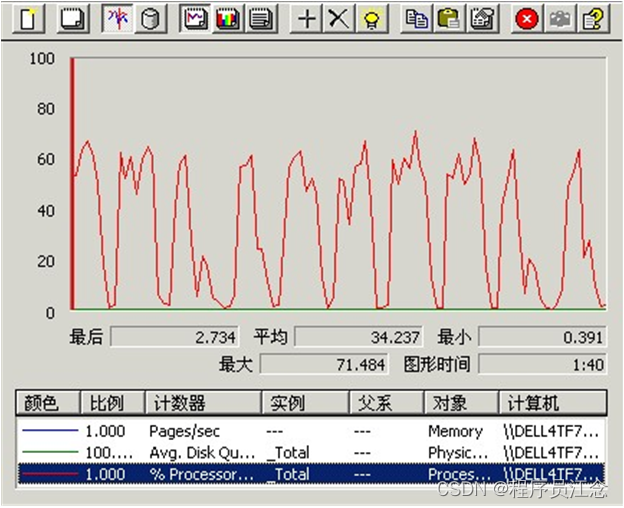
初步认识性能测试和完成一次完整的性能测试
上一篇博文主要通过两个例子让测试新手了解一下测试思想,和在做测试之前应该了解人几点,那么我们在如何完成一次完整的性能测试呢? 测试报告是一次完整性能测试的体现,所以,这里我给出一个完整的性能测试报告ÿ…...
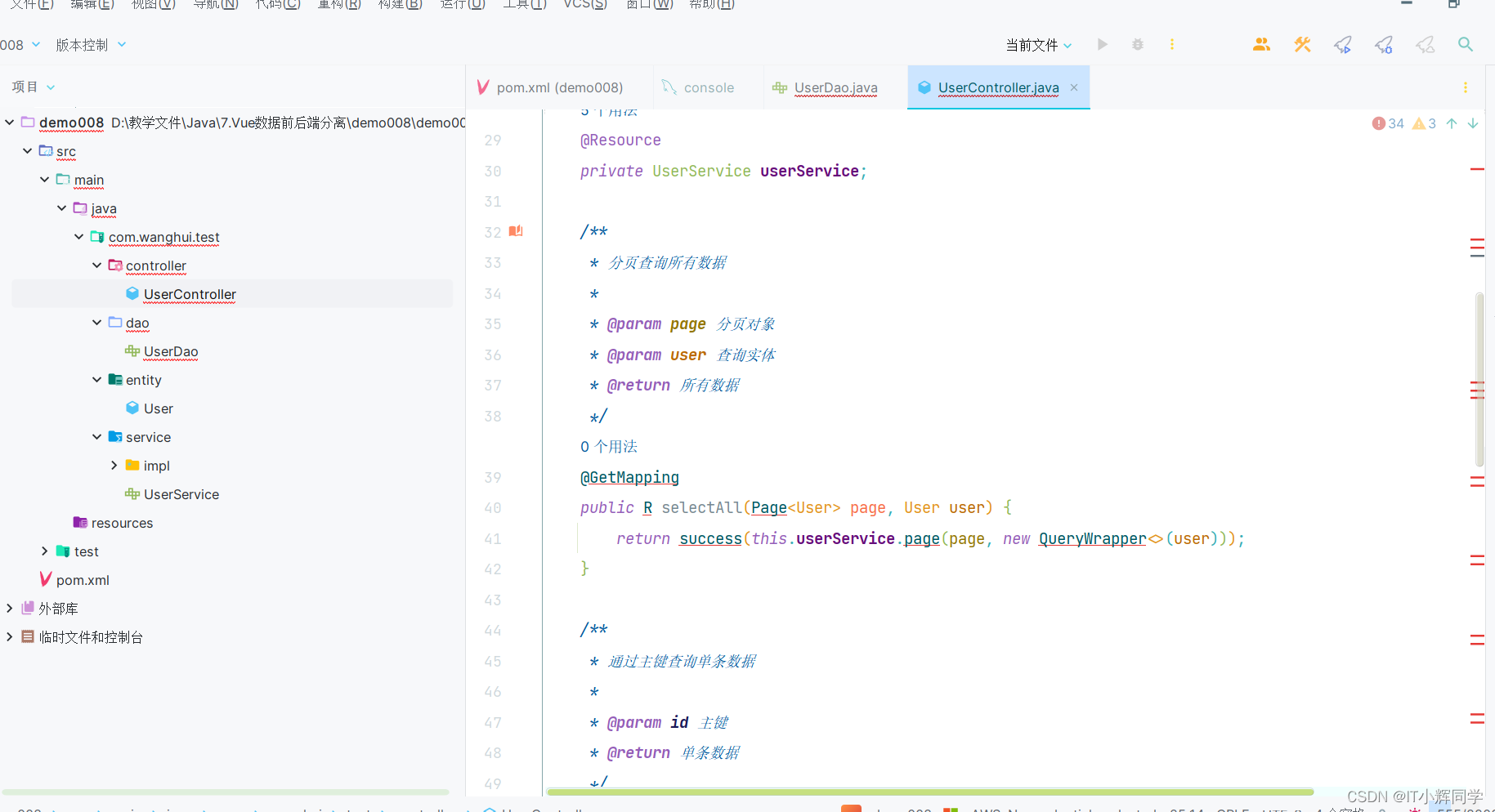
使用插件快速生成代码
使用插件快速生成代码 咋们常说,授人以鱼不如授人以渔,在这里给大家提供一些技巧性的东西,方便一些新手同学可以快速上手,同时,也提高我们的开发兴趣与开发热情! 主要讲什么呢,我们来学一学如何…...
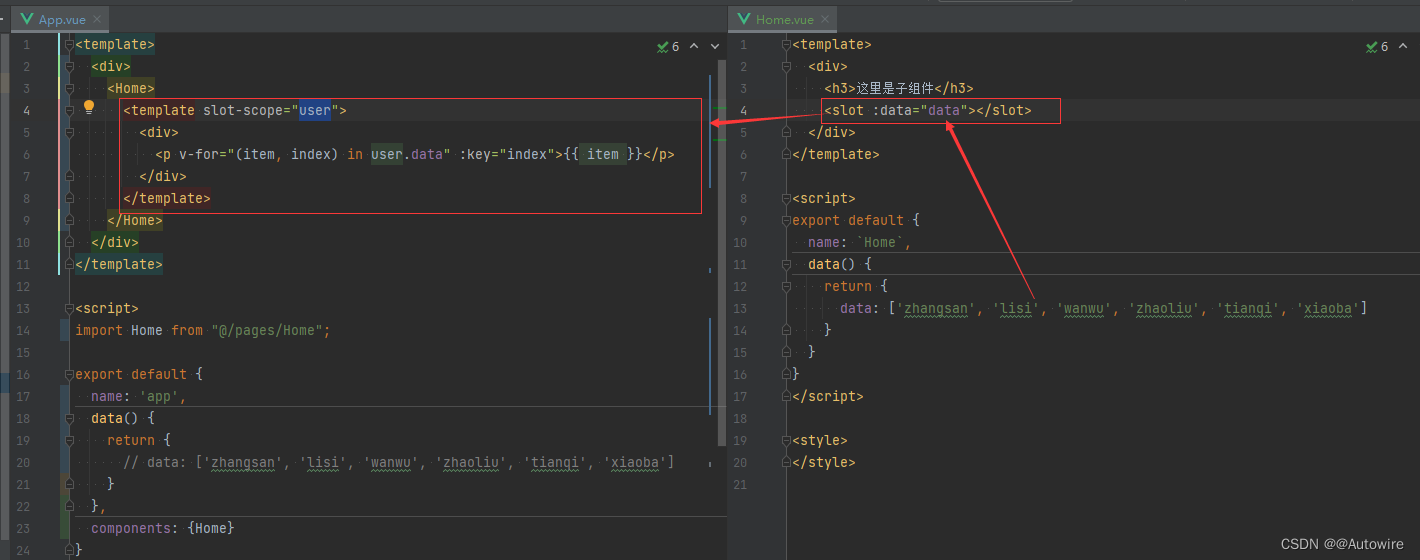
FE_Vue学习笔记 插槽 slot
插槽分为匿名插槽、具名插槽、作用域插槽。子组件中: 匿名插槽只能有一个;可以有多个具名插槽;作用域插槽中可以有匿名插槽和具名插槽。 当项目中一个组件可以多次复用时,我们可以把这个组件封装成单独的.vue文件,从…...

单链表的成环问题
前言:链表成环问题不仅考察双指针的用法,该问题还需要一定的数学推理和分析能力,看似简单的题目实则细思缜密,值得斟酌~ 目录 1.问题背景引入-判断链表是否成环: 1.1.正解:快慢指针 1.2 STL的集合判重 …...

横截面收益率
横截面收益率指的是在经典资产定价模型中,在横截面上线性确定的一个与资产风险匹配的资产收益率。 横截面收益率的预测[1] (一)变量和方法 我们主要使用月度频率数据进行检验。交易数据和公司财务数据来自于CSMAR数据库。CSMAR数据库的收益率调整了送股、配股以及拆…...
C++解析JSON JSONCPP库的使用
首先去GitHub下载JSONCPP的源码: JSonCpp的源码 解压后得到:jsoncpp-master 文件夹 需要的是:jsoncpp-master\src\lib_json 目录下的所有文件和 jsoncpp-master\include\json 目录下的所有文件,在MFC工程目录下新建两个文件夹或…...
不会Elasticsearch标准查询语句,如何分析数仓数据?
1 Elasticsearch的查询语句 ES中提供了一种强大的检索数据方式,这种检索方式称之为Query DSL,Query DSL是利用Rest API传递JSON格式的请求体(Request Body)数据与ES进行交互,这种方式的丰富查询语法让ES检索变得更强大,更简洁。 1.1 查询预发 # GET /…...

获得GitHub Copilot并结合VS Code使用
一、什么是GitHub Copilot GitHub Copilot是一种基于AI的代码生成工具。它使用OpenAI的GPT(生成式预训练Transformer)技术来提供建议。它可以根据您正在编写的代码上下文建议代码片段甚至整个函数。 要使用GitHub Copilot,您需要在编辑器中…...

BGE-M3快速入门:多语言文本相似度分析从零到一
BGE-M3快速入门:多语言文本相似度分析从零到一 1. 引言:从“关键词匹配”到“语义理解” 你有没有遇到过这样的场景?在搜索引擎里输入“苹果”,结果既出现了水果,也出现了手机公司。或者,你想找“如何学习…...

AI智能证件照制作工坊高可用部署:生产环境配置建议
AI智能证件照制作工坊高可用部署:生产环境配置建议 1. 项目概述与核心价值 AI智能证件照制作工坊是一个商业级证件照生产工具,基于Rembg高精度抠图引擎构建。这个工具能够将普通的生活照或自拍照,通过全自动流程转换为符合标准的证件照&…...

从会议录音到字幕生成:基于FunASR和SpringBoot搭建一个轻量级语音处理中台
从会议录音到字幕生成:基于FunASR和SpringBoot搭建轻量级语音处理中台 每周例会后,行政小张总要花两小时反复听录音整理纪要。市场部的跨国会议录音,技术团队的头脑风暴存档,管理层战略讨论的逐字记录——这些音频文件堆积在共享…...

微信H5页面如何通过wx-open-launch-weapp标签跳转小程序?完整配置指南
微信H5跳转小程序全链路实战:从零配置wx-open-launch-weapp标签 在移动互联网生态中,微信H5与小程序的无缝跳转已成为提升用户体验的关键技术节点。许多开发者首次接触wx-open-launch-weapp标签时,往往会在业务域名验证、HTTPS部署等环节遭遇…...
 做3D目标检测?手把手教你复现SAM3D论文核心流程)
用Segment Anything Model (SAM) 做3D目标检测?手把手教你复现SAM3D论文核心流程
从BEV到3D检测:基于Segment Anything的零样本实践指南 当Meta的Segment Anything Model(SAM)横空出世时,计算机视觉领域掀起了一阵"分割一切"的浪潮。但大多数应用仍停留在2D图像领域,直到SAM3D论文提出将这…...

英伟达黄仁勋力荐!2026年AI Agent元年,掌握这5大关键技术,成为行业风口!
0****1 什么是AI Agent? 随着人工智能技术加速演进,AI Agent(人工智能代理,常称智能体)正悄然渗透到企业运营与日常生活的各个角落,从大家熟悉的虚拟助手(如Siri、小爱同学、豆包)&a…...

解决QGroundControl或华科尔地面站因QT版本冲突导致的启动失败问题
1. 当QGroundControl或华科尔地面站打不开时该怎么办 遇到QGroundControl或华科尔地面站安装后无法启动的问题,很多用户第一反应是软件安装包损坏了。但实际上,这很可能是由于QT框架版本冲突导致的。QT是一个跨平台的C图形用户界面应用程序开发框架&…...
)
知识点总结--day09(Mybatis及Mybatis-Plus)
目录 1、系统架构流程? 2结果集映射? 3mapper传参? 4、xml常用配置 5、缓存机制 6、分页插件 7、Mybatis-Plus常用API 末尾页 1、系统架构流程? 执行过程: mybatis配置 mybatis-config.xml,名称可变,此文件作为mybatis的全局配置…...

Z-Image-GGUF模型解析:C语言视角下的文件读写与GGUF格式处理
Z-Image-GGUF模型解析:C语言视角下的文件读写与GGUF格式处理 你是不是也好奇,那些动辄几十GB的大模型文件,计算机到底是怎么“看懂”并加载它们的?今天我们不聊高层的API调用,而是拿起C语言这把“手术刀”,…...

爆款AI写教材工具登场!一键生成低查重教材,轻松开启编写之旅
编写教材的困境与AI的解决方案 在编写教材时,如何准确地满足多样化的需求呢?不同年级的学生在认知能力上存在显著差异,教材内容若过于深奥或过于简单都无法达到效果;而课堂教学和自主学习等不同的环境对教材的要求各不相同&#…...