如何训练自己的大型语言模型

如何使用 Databricks、Hugging Face 和 MosaicML 训练大型语言模型 (LLM)
介绍
大型语言模型,如 OpenAI 的 GPT-4 或谷歌的 PaLM,已经席卷了人工智能世界。然而,大多数公司目前没有能力训练这些模型,并且完全依赖少数大型科技公司作为技术提供者。
在 Replit,我们大量投资于从头开始训练我们自己的大型语言模型所需的基础设施。在这篇博文中,我们将概述我们如何训练 LLM,从原始数据到面向用户的生产环境中的部署。我们将讨论我们在此过程中面临的工程挑战,以及我们如何利用我们认为构成现代 LLM 堆栈的供应商:Databricks、Hugging Face 和 MosaicML。
虽然我们的模型主要用于代码生成的用例,但所讨论的技术和课程适用于所有类型的 LLM,包括通用语言模型。我们计划在接下来的几周和几个月内通过一系列博客文章深入探讨我们流程的具体细节。
为什么要培养自己的法学硕士?
Replit 的 AI 团队最常见的问题之一是“为什么要训练自己的模型?” 公司可能决定培训自己的法学硕士的原因有很多,从数据隐私和安全到加强对更新和改进的控制。
在 Replit,我们主要关心定制化、减少依赖性和成本效率。
- 定制。训练自定义模型使我们能够根据我们的特定需求和要求对其进行定制,包括特定于平台的功能、术语和上下文,这些在通用模型(如 GPT-4)甚至特定代码模型(如 Codex)中都无法很好地涵盖. 例如,我们的模型经过训练可以更好地使用 Replit 上流行的特定基于 Web 的语言,包括 Javascript React (JSX) 和 Typescript React (TSX)。
- 减少依赖。虽然我们始终会根据手头的任务使用正确的模型,但我们相信减少对少数 AI 提供商的依赖是有好处的。这不仅适用于 Replit,也适用于更广泛的开发者社区。这就是为什么我们计划开源我们的一些模型,如果没有训练它们的方法,我们就无法做到这一点。
- 成本效益。尽管成本将继续下降,但 LLM 在全球开发者社区中的使用成本仍然高得令人望而却步。在 Replit,我们的使命是让下一个十亿软件创作者在线。我们相信,在印度用手机编程的学生应该可以使用与硅谷专业开发人员相同的 AI。为了使这成为可能,我们训练了更小、更高效并且可以以大幅降低的成本托管的自定义模型。
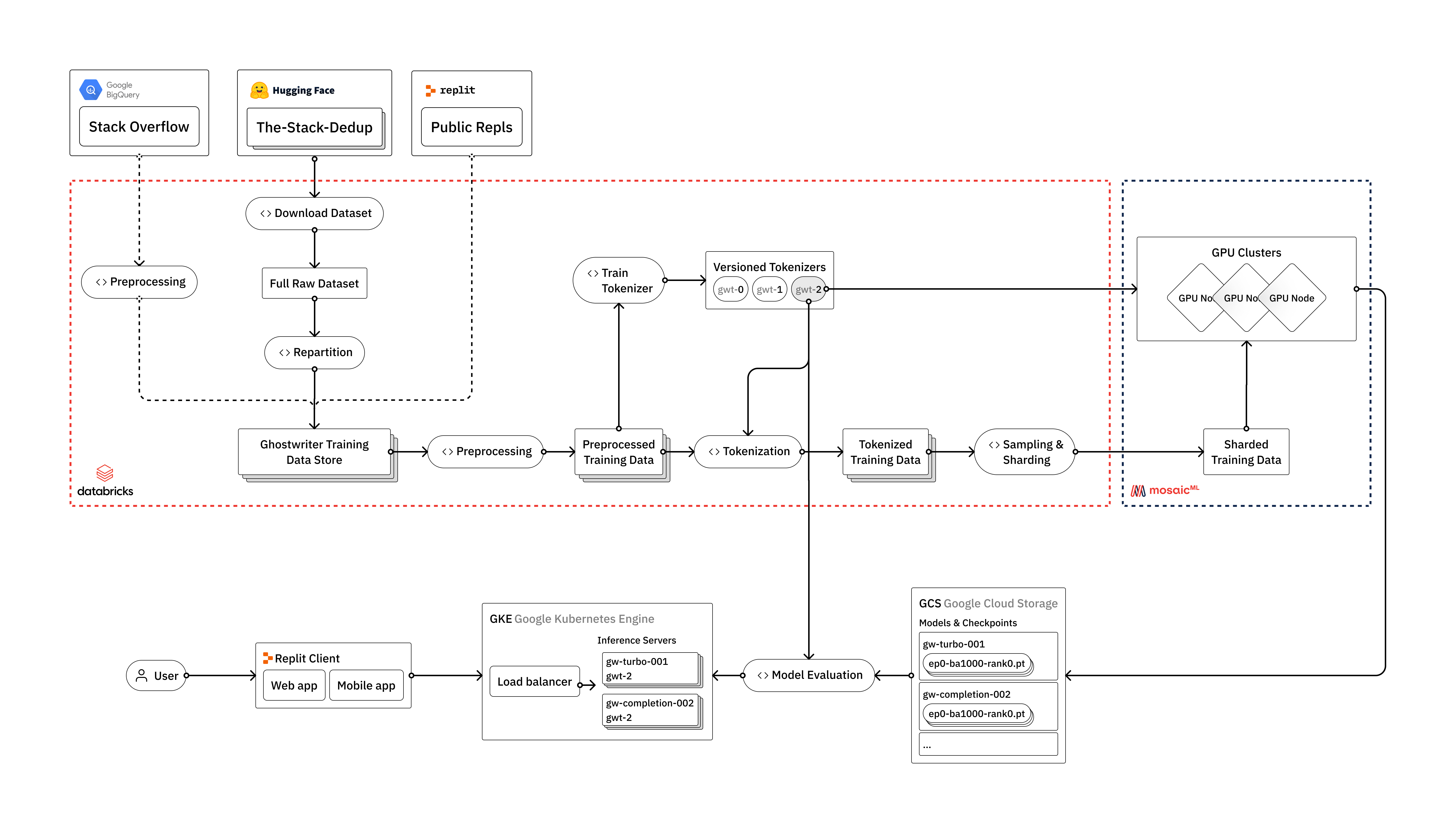
数据管道
LLM 需要大量数据进行训练。培训他们需要构建强大的数据管道,这些管道经过高度优化,但又足够灵活,可以轻松包含公共数据和专有数据的新来源。
堆栈
我们从Hugging Face上可用的 The Stack 作为我们的主要数据源开始。Hugging Face 是数据集和预训练模型的重要资源。它们还提供各种有用的工具作为 Transformers 库的一部分,包括用于标记化、模型推理和代码评估的工具。
Stack 由BigCode项目提供。Kocetkov 等人提供了数据集构建的详细信息。(2022)。删除重复数据后,数据集的 1.2 版包含约 2.7 TB 的许可源代码,这些源代码以 350 多种编程语言编写。
Transformers 库在抽象出许多与模型训练相关的挑战方面做得很好,包括处理大规模数据。然而,我们发现它不足以满足我们的流程,因为我们需要对数据进行额外的控制以及以分布式方式处理数据的能力。
数据处理
当需要进行更高级的数据处理时,我们使用Databricks来构建我们的管道。这种方法还使我们可以轻松地将其他数据源(例如 Replit 或 Stack Overflow)引入到我们的流程中,我们计划在未来的迭代中这样做。
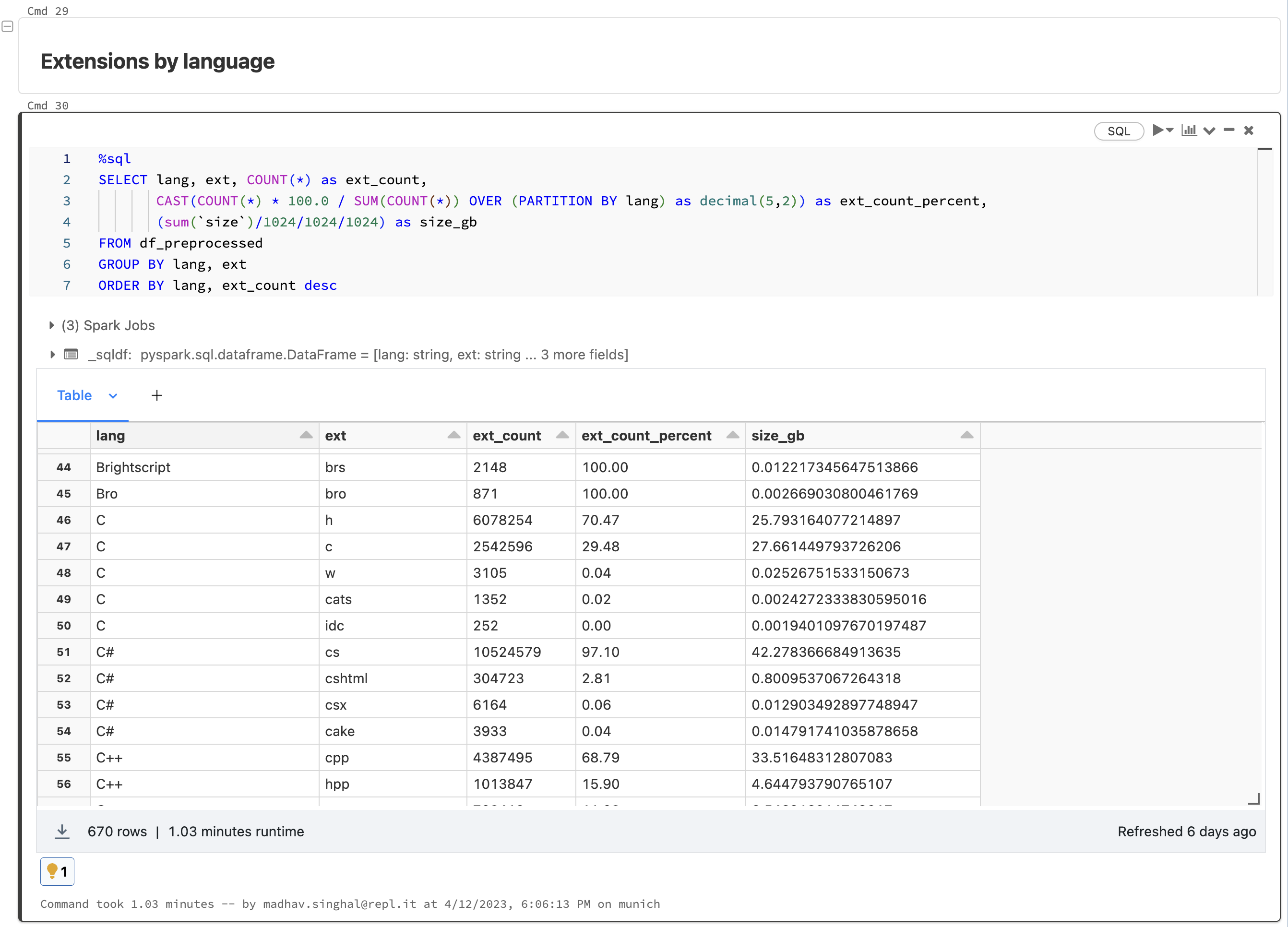
第一步是从 Hugging Face 下载原始数据。我们使用 Apache Spark 跨每种编程语言并行化数据集构建过程。然后,我们对数据进行重新分区,并使用针对下游处理的优化设置以镶木地板格式重写。
接下来,我们转向清理和预处理我们的数据。通常,对数据进行重复数据删除并修复各种编码问题很重要,但 The Stack 已经使用 Kocetkov 等人概述的近似重复数据删除技术为我们完成了这项工作。(2022)。然而,一旦我们开始将 Replit 数据引入我们的管道,我们将不得不重新运行重复数据删除过程。这就是拥有像 Databricks 这样的工具的好处所在,我们可以在其中将 Stack、Stackoverflow 和 Replit 数据视为更大数据湖中的三个来源,并根据需要在我们的下游流程中使用它们。
使用 Databricks 的另一个好处是我们可以对底层数据运行可扩展且易于处理的分析。我们对我们的数据源运行所有类型的汇总统计,检查长尾分布,并诊断过程中的任何问题或不一致。所有这些都是在 Databricks notebooks 中完成的,它也可以与 MLFlow 集成,以跟踪和重现我们在整个过程中的所有分析。这一步相当于对我们的数据进行定期 X 光检查,也有助于告知我们为预处理采取的各种步骤。
对于预处理,我们采取以下步骤:
- 我们通过删除任何个人身份信息 (PII) 来匿名化数据,包括电子邮件、IP 地址和密钥。
- 我们使用多种启发式方法来检测和删除自动生成的代码。
- 对于一部分语言,我们删除了无法编译或无法使用标准语法解析器解析的代码。
- 我们根据平均行长、最大行长和字母数字字符的百分比过滤掉文件。
标记化和词汇训练
在标记化之前,我们使用我们用于模型训练的相同数据的随机子样本来训练我们自己的自定义词汇表。自定义词汇表使我们的模型能够更好地理解和生成代码内容。这会提高模型性能,并加快模型训练和推理。
此步骤是该过程中最重要的步骤之一,因为它用于我们过程的所有三个阶段(数据管道、模型训练、推理)。它强调了为模型训练过程提供强大且完全集成的基础架构的重要性。
我们计划在未来的博文中更深入地探讨代币化。在高层次上,我们必须考虑的一些重要事项是词汇量、特殊标记和标记标记的保留空间。
一旦我们训练了我们的自定义词汇表,我们就会标记我们的数据。最后,我们构建了我们的训练数据集并将其写成一种分片格式,该格式经过优化以用于模型训练过程。
模型训练
我们使用MosaicML训练我们的模型。在之前部署了我们自己的训练集群后,我们发现 MosaicML 平台为我们提供了一些关键优势。
- 多个云提供商。Mosaic 使我们能够利用来自不同云提供商的 GPU,而无需设置帐户和所有必需的集成的开销。
- 法学硕士培训配置。Composer 库有许多调整良好的配置,用于训练各种模型和不同类型的训练目标。
- 托管基础设施。他们的托管基础架构为我们提供了编排、效率优化和容错(即从节点故障中恢复)。
在确定我们模型的参数时,我们考虑了模型大小、上下文窗口、推理时间、内存占用等之间的各种权衡。较大的模型通常提供更好的性能并且更能够进行迁移学习。然而,这些模型对训练和推理都有更高的计算要求。后者对我们尤为重要。Replit 是一种云原生 IDE,其性能感觉就像桌面原生应用程序,因此我们的代码完成模型需要快如闪电。出于这个原因,我们通常会选择具有较小内存占用和低延迟推理的较小模型。
除了模型参数外,我们还从各种训练目标中进行选择,每个训练目标都有其独特的优点和缺点。最常见的训练目标是下一个标记预测。这通常适用于代码完成,但未能考虑到文档下游的上下文。这可以通过使用“中间填充”目标来缓解,其中文档中的一系列标记被屏蔽,并且模型必须使用周围的上下文来预测它们。另一种方法是 UL2(无监督潜在语言学习),它将训练语言模型的不同目标函数构建为去噪任务,其中模型必须恢复给定输入的缺失子序列。
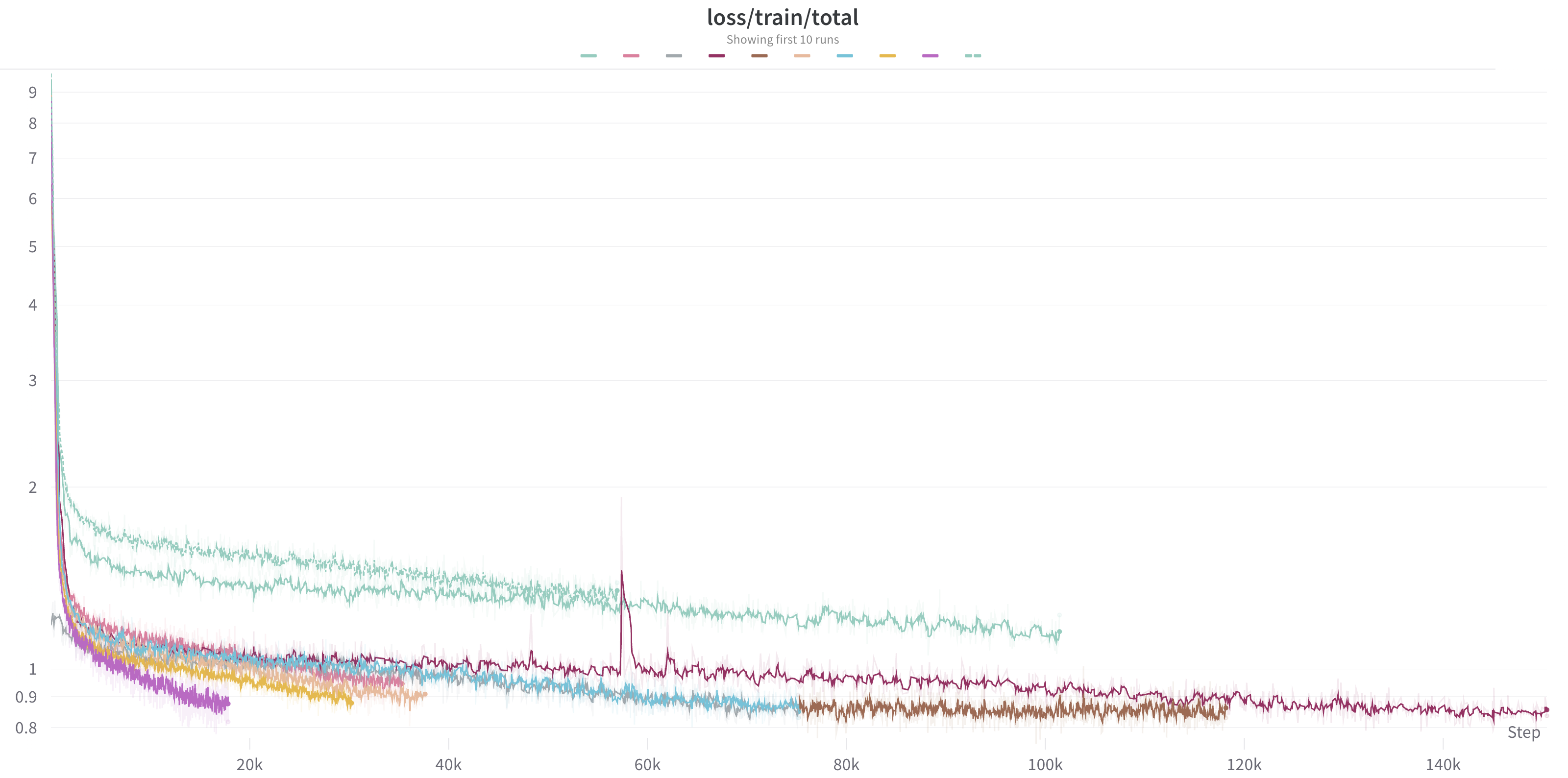
一旦我们决定了我们的模型配置和训练目标,我们就会在 GPU 的多节点集群上启动我们的训练运行。我们能够根据我们正在训练的模型的大小以及我们希望多快完成训练过程来调整为每次运行分配的节点数。运行大型 GPU 集群的成本很高,因此以尽可能最有效的方式利用它们很重要。我们密切监控 GPU 利用率和内存,以确保我们从计算资源中获得最大可能的使用率。
我们使用 Weights & Biases 来监控训练过程,包括资源利用率和训练进度。我们监控我们的损失曲线,以确保模型在训练过程的每个步骤中都能有效地学习。我们还关注损失峰值。这些是损失值的突然增加,通常表明底层训练数据或模型架构存在问题。因为这些事件通常需要进一步调查和潜在的调整,我们在我们的流程中强制执行数据确定性,因此我们可以更轻松地重现、诊断和解决任何此类损失峰值的潜在来源。
评估
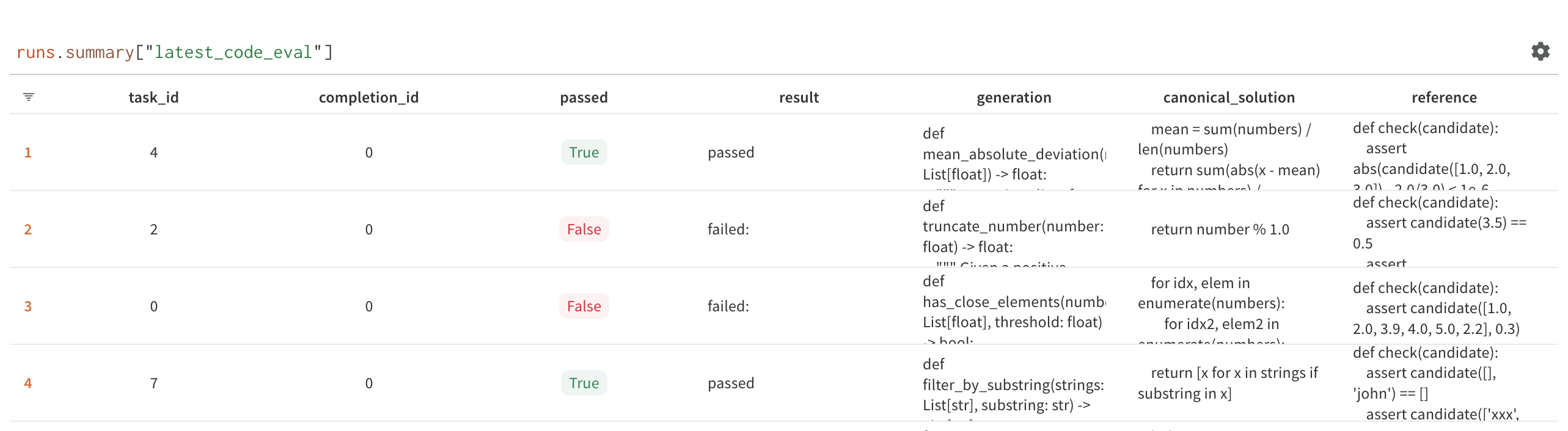
为了测试我们的模型,我们使用 Chen 等人中描述的 HumanEval 框架的变体。(2021)。给定函数签名和文档字符串,我们使用该模型生成一段 Python 代码。然后,我们对生成的函数运行测试用例,以确定生成的代码块是否按预期工作。我们运行多个样本并分析相应的Pass@K数字。
这种方法最适合 Python,可以使用评估器和测试用例。但由于 Replit 支持多种编程语言,我们需要评估各种其他语言的模型性能。我们发现这很难做到,并且没有广泛采用的工具或框架可以提供全面的解决方案。两个具体的挑战包括在任何编程语言中构建可重现的运行时环境,以及在没有广泛使用的测试用例标准(例如 HTML、CSS 等)的情况下编程语言的模糊性。幸运的是,“任何编程语言的可重现运行时环境”是 Replit 的特色!我们目前正在构建一个评估框架,允许任何研究人员插入并测试他们的多语言基准。我们'
部署到生产
一旦我们训练和评估了我们的模型,就可以将其部署到生产环境中了。正如我们之前提到的,我们的代码完成模型应该感觉很快,请求之间的延迟非常低。我们使用 NVIDIA 的 FasterTransformer 和 Triton Server 加速我们的推理过程。FasterTransformer 是一个为基于 transformer 的神经网络的推理实现加速引擎的库,而 Triton 是一个稳定且快速的推理服务器,易于配置。这种组合为我们在转换器模型和底层 GPU 硬件之间提供了一个高度优化的层,并允许对大型模型进行超快速分布式推理。
在将我们的模型部署到生产环境中后,我们能够使用我们的 Kubernetes 基础设施对其进行自动缩放以满足需求。尽管我们在之前的博文中讨论过自动缩放,但值得一提的是,托管推理服务器会带来一系列独特的挑战。这些包括大型工件(即模型权重)和特殊硬件要求(即不同的 GPU 大小/数量)。我们设计了我们的部署和集群配置,以便我们能够快速可靠地交付。例如,我们的集群旨在解决个别区域的 GPU 短缺问题,并寻找最便宜的可用节点。
在我们将模型放在实际用户面前之前,我们喜欢自己测试它并了解模型的“氛围”。我们之前计算的 HumanEval 测试结果很有用,但没有什么比使用模型来感受它更好的了,包括它的延迟、建议的一致性和一般帮助。将模型放在 Replit 工作人员面前就像拨动开关一样简单。一旦我们对它感到满意,我们就会翻转另一个开关并将其推广给我们的其他用户。
我们将继续监控模型性能和使用指标。对于模型性能,我们监控请求延迟和 GPU 利用率等指标。对于使用情况,我们跟踪代码建议的接受率,并将其分解到包括编程语言在内的多个维度。这也允许我们对不同的模型进行 A/B 测试,并获得一个模型与另一个模型比较的定量度量。
反馈与迭代
我们的模型训练平台使我们能够在不到一天的时间内将原始数据转化为部署在生产环境中的模型。但更重要的是,它允许我们训练和部署模型、收集反馈,然后根据该反馈快速迭代。
对于我们的流程来说,保持对底层数据源、模型训练目标或服务器架构的任何变化的鲁棒性也很重要。这使我们能够在一个快速发展的领域中利用新的进步和功能,在这个领域中,似乎每天都有新的和令人兴奋的公告。
接下来,我们将扩展我们的平台,使我们能够使用 Replit 本身来改进我们的模型。这包括基于人类反馈的强化学习 (RLHF) 等技术,以及使用从 Replit Bounties 收集的数据进行指令调整。
下一步
虽然我们取得了很大进步,但我们仍处于培训法学硕士的早期阶段。我们有很多改进要做,还有很多难题需要解决。随着语言模型的不断进步,这种趋势只会加速。将会有一系列与数据、算法和模型评估相关的新挑战。
如果您对培训 LLM 的许多工程挑战感到兴奋,我们很乐意与您交谈。我们喜欢反馈,也很乐意听取您的意见,了解我们缺少什么以及您会采取哪些不同的做法。
相关文章:
如何训练自己的大型语言模型
如何使用 Databricks、Hugging Face 和 MosaicML 训练大型语言模型 (LLM) 介绍 大型语言模型,如 OpenAI 的 GPT-4 或谷歌的 PaLM,已经席卷了人工智能世界。然而,大多数公司目前没有能力训练这些模型,并且完全依赖少数大型科技公司…...

Java中的SLF4J是什么?如何使用SLF4J进行日志管理
在Java开发中,日志管理是一个非常重要的问题。日志管理可以帮助开发人员更好地了解应用程序的运行情况,以及快速诊断和解决问题。而SLF4J是Java中最常用的日志管理框架之一。在本文中,我们将详细介绍SLF4J的概念和使用方法。 什么是SLF4J&am…...

PHP程序员面对的压力大不大?我来聊聊程序员转行的就业方向
作为一名程序员,不同领域、不同公司和不同项目所面对的压力程度可能会有所不同。但是,一般来说,程序员需要长时间专注于编写代码,需要不断学习和适应新的技术和变化,还需要在项目的压力下保证工作的质量和进度。因此&a…...
)
牛客网专项练习Pytnon分析库(十)
1.Python Pandas处理缺失值,以下哪个选项是对缺失值NaN进行删除操作(C)。 A.isnull B.notnull C.dropna D.fillna 解析: A选项,Isnull()返回表明哪些值是缺失值的布尔值; B选项,notnull()返…...
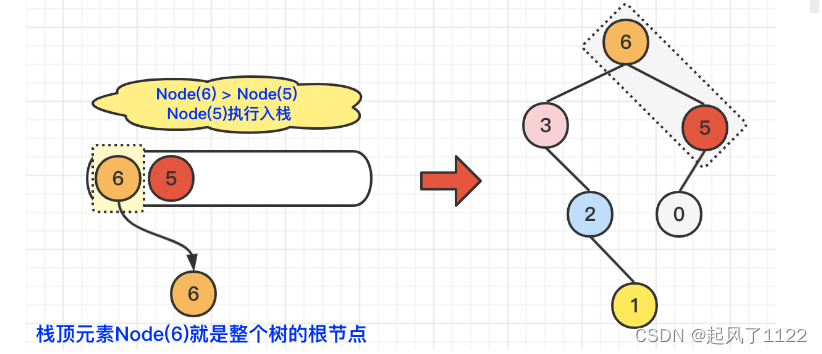
leecode654——最大二叉树
leecode最大二叉树 🌻题目要求: 给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建: 创建一个根节点,其值为 nums 中的最大值。 递归地在最大值 左边 的 子数组前缀上 构建左子树。 递归地在最大值 右边 的…...

【笔试强训选择题】Day12.习题(错题)解析
作者简介:大家好,我是未央; 博客首页:未央.303 系列专栏:笔试强训选择题 每日一句:人的一生,可以有所作为的时机只有一次,那就是现在!!! 文章目录…...

边缘计算与开放源代码的完美结合
随着人工智能、大数据和物联网等技术的快速发展,边缘计算已经成为一种普遍使用的计算方式,尤其是在物联网领域。与此同时,越来越多的开放源代码项目也在不断涌现,这些项目为边缘计算提供了更多的选择和灵活性。那么,边…...

边缘计算网关在储能系统中的应用——提高储能系统的安全性和稳定性
随着全球能源消耗和环境保护意识的不断提高,储能技术逐渐成为了各国电力系统中的重要一环。而作为储能技术中的关键设备之一,边缘计算网关在储能系统中的应用也越来越受到关注。本文将从边缘计算网关的定义、特点以及其在储能行业中的应用三个方面来介绍…...
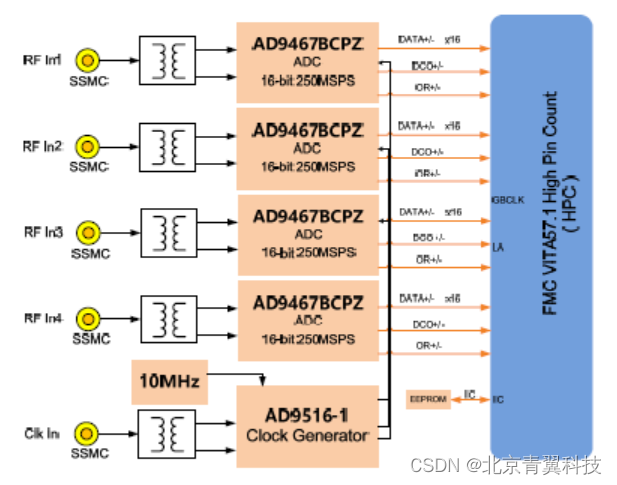
【FMC136】AD9467之4通道 250MSPS 采样率16位AD 采集子卡模块得设计原理图中文资料
板卡概述 FMC136 是一款4 通道250MHz 采样率16 位AD 采集FMC子卡,符合VITA57 规范,可以作为一个理想的IO 模块耦合至FPGA前端,4 通道AD 通过高带宽的FMC 连接器(HPC)连接至FPGA 从 而大大降低了系统信号延迟。该板卡支…...
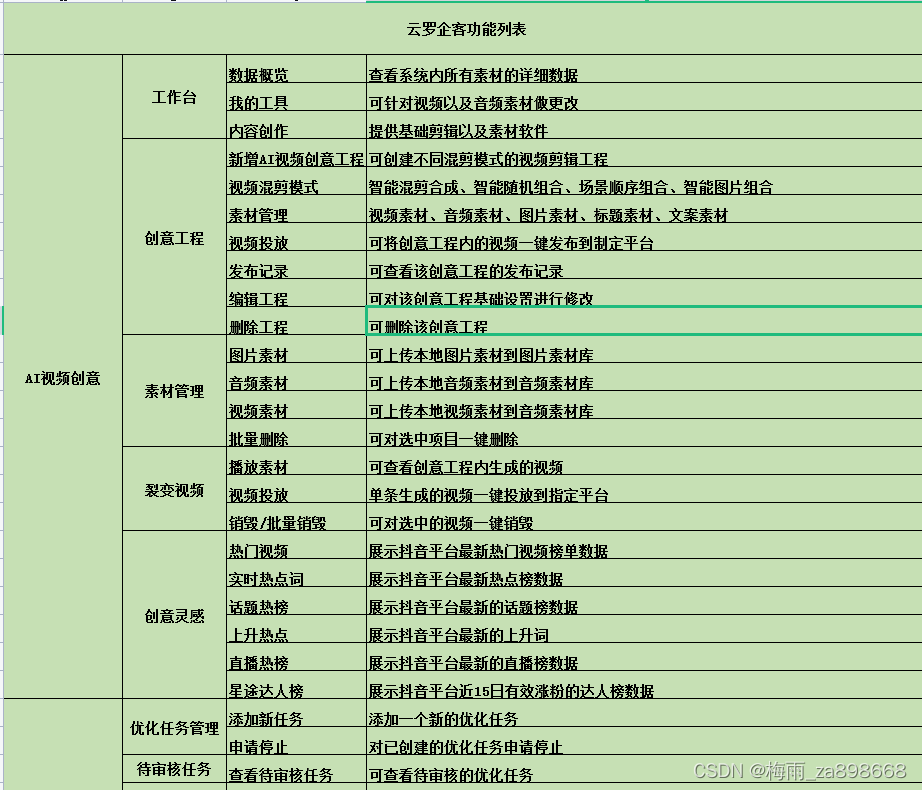
抖音SEO矩阵系统源码开发(一)
抖音seo矩阵营销系统/抖音SEO矩阵号管理系统/抖音霸屏源码开发搭建,抖音官方团队大力推广抖音SEO生态,我们应如何布局开发抖音SEO矩阵系统,来达到账号排名优化的效果,很显然,账号关键词起到了很关键的作用。首先&#…...
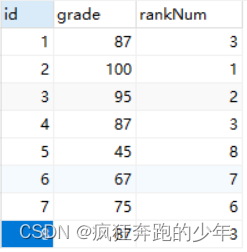
Mysql实现对某一字段排序并将排名写入另一字段
文章目录 前言一、数据库表结构和样例数据二、排名操作1.普通排名2.无间隔排名3.有间隔排名 总结 前言 最近业务上碰到这样一个需求,需要对表按照某一个字段进行排序,并且将得到的排名写入对应的排名字段。这个需求于我而言确实没有遇到过,好…...

vector容器 [上]
目录 一、 对于vector的介绍 二、vector的定义 0x01 无参构造 0x02 构造并初始化n个val 0x03 使用迭代器进行初始化构造 0x04 拷贝构造 0x05 比较 三、 vector的遍历 0x01 push_back() 0x02 operator[] 和at() 0x03 遍历 四、vector 容量空间 0x01 max_size : 返回v…...

React Native技术探究:开发高质量的跨平台移动应用的秘诀
作为一个跨平台移动应用开发框架,React Native在开发过程中能够有效提高开发效率、降低开发成本、缩短上线时间,因此备受开发者的欢迎。然而,如何使用React Native开发出高质量的跨平台移动应用呢?本文将探究这个问题,…...
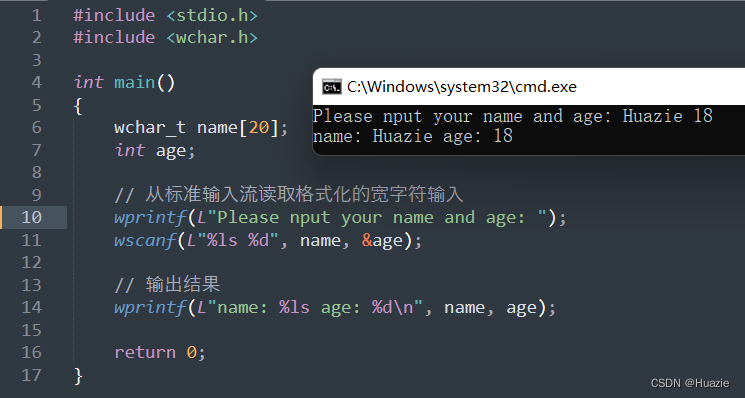
C语言函数大全-- w 开头的函数(2)
C语言函数大全 本篇介绍C语言函数大全-- w 开头的函数 1. wcstok 1.1 函数说明 函数声明函数功能wchar_t *wcstok(wchar_t *wcs, const wchar_t *delim, wchar_t **ptr);用于将一个长字符串拆分成几个短字符串(标记),并返回第一个标记的地…...

kafka启动创建topic报错:zookeeper is not a recognized option
当前使用版本:kafka_2.13-3.4.0 使用老版本的创建topic的命令,是用zookeeper来创建,但是报错如下 D:\Software\Doument\kafka_2.13-3.4.0> .\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 …...

11个超好用的SVG编辑工具
SVG的优势在于SVG图像可以更加灵活,自由收缩放大而不影响图片的质量,一个合适的SVG编辑工具能够让你的设计事半功倍,下面就一起来看看这些冷门软件好用在哪里。这11个超好用的SVG编辑工具依次为:即时设计、Justinmind、Sketsa SVG…...
低代码平台:10分钟从入门到原理
导航目录 一、低代码概念 二、优势及局限 三、基础功能及搭建 1、业务流程 2、用户权限 3、统计图表 四、使用感受 五、总结 传统的软件研发方式目前并不能很好地满足企业的需求:人员成本高、研发时间长、运维复杂。这时低代码工具的出现为快速开发软件提供…...

【JavaScript】如何获取客户端IP地址?
使用这个库:request-ip 它按照如下顺序获取请求的IP地址: X-Client-IPX-Forwarded-For (Header may return multiple IP addresses in the format: “client IP, proxy 1 IP, proxy 2 IP”, so we take the first one.)CF-Connecting-IP (Cloudflare)F…...
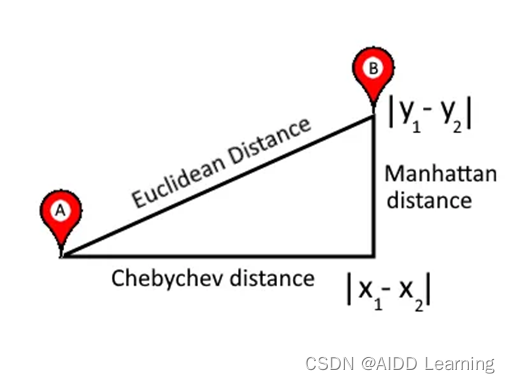
数据科学中使用的17 种相似性和相异性度量之欧氏距离
目录 1简介 2距离函数 2.1 L2范数(欧氏距离) 1简介 在数据科学中,相似性度量是一种衡量数据样本如何相互关联或相互接近的方法。另一方面,相异性度量是告诉数据对象有多少是不同的。此外,当相似的数据样本被分组到一…...

朋友去华为面试,轻松拿到30K的Offer,羡慕了......
最近有朋友去华为面试,面试前后进行了20天左右,包含4轮电话面试、1轮笔试、1轮主管视频面试、1轮hr视频面试。 据他所说,80%的人都会栽在第一轮面试,要不是他面试前做足准备,估计都坚持不完后面几轮面试。 其实&…...
)
Google Core Web Vitals(核心网页指标)
一、核心三大指标 (Core Web Vitals)1. LCP (Largest Contentful Paint) - 最大内容绘制:含义: 页面中最大的可见内容(如主图、大标题、视频)加载完成并渲染出来的时间。它代表了用户认为“主要内容已加载”的时刻。 目标…...
Z-Image-GGUF参数详解:EmptyLatentImage尺寸设置与边缘裁剪规避技巧
Z-Image-GGUF参数详解:EmptyLatentImage尺寸设置与边缘裁剪规避技巧 1. 引言:为什么你的图片总被“切掉”一部分? 如果你用过Z-Image-GGUF生成图片,可能遇到过这样的情况:明明想要一张横屏的风景图,结果生…...

HPE服务器固件升级后网络适配器端口配置重置问题解析与解决方案
1. 问题现象与影响范围 最近在给HPE ProLiant服务器升级固件时,不少工程师都遇到了一个让人头疼的问题:升级完成后,网络适配器的端口配置莫名其妙被重置了。这个问题特别容易出现在使用HPE Broadcom 33x系列网卡的服务器上,比如常…...

如何通过智能工具提升英雄联盟游戏效率:5个关键技巧指南
如何通过智能工具提升英雄联盟游戏效率:5个关键技巧指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League-Toolkit 是一款专为…...

从PTA L1-064看AI对话系统设计:那些隐藏在题目背后的自然语言处理技巧
从PTA L1-064看AI对话系统设计:那些隐藏在题目背后的自然语言处理技巧 在编程竞赛题目PTA L1-064"估值一亿的AI核心代码"中,看似简单的字符串处理规则背后,实则蕴含了自然语言处理(NLP)领域的多个基础但关键的技术点。这道题目要求…...

告别虚拟机!用WinSniffer v1.5 + MT7921网卡在Windows原生抓取WiFi 6E/7的6GHz报文
Windows原生抓取WiFi 6E/7的6GHz报文实战指南:WinSniffer v1.5与MT7921网卡完美组合 在无线网络技术快速迭代的今天,WiFi 6E和WiFi 7带来的6GHz频段为高速低延迟通信开辟了新天地。但对于网络工程师和技术爱好者而言,如何高效捕获和分析这些高…...

116:小模型蒸馏实战路径:将大模型能力转移到轻量级模型
作者: HOS(安全风信子) 日期: 2026-01-15 主要来源平台: GitHub 摘要: 本文详细介绍小模型蒸馏技术的实战路径,通过具体的技术方案和代码示例,展示如何将大模型的能力有效地转移到轻量级模型中。我们将探讨…...

Windows Defender终极移除指南:一键彻底关闭系统安全防护的完整解决方案
Windows Defender终极移除指南:一键彻底关闭系统安全防护的完整解决方案 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.c…...

基于OFA模型的智能客服系统开发:VQA技术实战
基于OFA模型的智能客服系统开发:VQA技术实战 想象一下这个场景:你是一家电商公司的客服主管,每天要处理上千张用户上传的图片问题——“这个商品有划痕正常吗?”、“我收到的包装破损了怎么办?”、“这个尺寸和我拍的…...

收藏!AI大模型时代,小白程序员如何进化?这三大路径助你抓住高薪机遇!
收藏!AI大模型时代,小白程序员如何进化?这三大路径助你抓住高薪机遇! AI技术崛起正冲击全球IT行业,导致裁员潮。传统IT面临AI效率革命、企业战略转移、经济成本重构、人才需求转变四重冲击。IT从业者需通过能力重构&am…...