sklearn中的特征工程(过滤法、嵌入法和包装法)
目录
编辑特征工程的第一步:理解业务
Filter过滤法
编辑方差过滤
编辑- 相关性过滤
- 卡方过滤
- F检验
- 互信息法
编辑嵌入法(Embedded)
包装法(Wrapper)

特征工程的第一步:理解业务
如果特征比较少且容易理解,我们可以自行判断特征的取舍,如前面的泰坦尼克号数据集。但是,在真正的数据应用领域,比如金融,医疗,电商,我们的数据不可能像泰坦尼克号数据的特征这样少,这样明显。那如果遇见极端情况,我们无法依赖对业务的理解来选择特征,该怎么办呢?我们有四种方法可以用来选择特征:过滤法,嵌入法,包装法,和降维算法
Filter过滤法
过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法。它是根据各种统计检验中的分数以及相关性的各项指标来选择特征。

方差过滤
VarianceThreshold
比如一个特征本身的方差很小,就表示样本在这个特征上基本没有差异,可能特征中的大多数值都一样,甚至整个特征的取值都相同,那这个特征对于样本区分没有什么作用。
所以无论接下来的特征工程要做什么,都要优先消除方差为0的特征。VarianceThreshold有重要参数threshold,表示方差的阈值,表示舍弃所有方差小于threshold的特征,不填默认为0,即删除所有的记录都相同的特征。
首先导入原函数
import pandas as pd
data = pd.read_csv(r'F:\data\digit recognizor.csv')
原函数的shape为(42000, 784)
然后我们采用方差过滤
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold() #实例化,不填参数默认方差为0
X_var0 = selector.fit_transform(X) #获取删除不合格特征之后的新特征矩阵
# 等同于 X_var0 = selector.fit_transform(VarianceThreshold())
方差过滤后函数的shape为(42000, 708)
至此,方差为0的特征全都删除了。
如果你只想保留一半的特征值,那么可以这样做
import numpy as np
np.median(X.var().values) # 这一步是取中位数
X_fsvar = VarianceThreshold(np.median(X.var().values)).fit_transform(X)
此时的X_fsvar.shape为(42000, 392)
当然,如果你想取前50个,你可以先把values排个序,然后阈值定义为第50的那个方差就可以啦。
此外,当方差是二分类的时候,特征的取值就是伯努利随机变量,这些变量的方差可以计算为Var[X] = p(1-p),p为二分类特征中的一类在这个特征中所占的概率。
可以定义,二分类特征中某种分类占到了80%以上的时候删除特征。
X_bvar = VarianceThreshold(.8 * (1 - .8)).fit_transform(X)
方差过滤对模型的影响
我们这样做了以后,对模型效果会有怎样的影响呢?在这里,我为大家准备了KNN和随机森林分别在方差过滤前和方差过滤后运行的效果和运行时间的对比。
#KNN vs 随机森林在不同方差过滤效果下的对比
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.model_selection import cross_val_score
import numpy as np
X = data.iloc[:,1:]
y = data.iloc[:,0]
X_fsvar = VarianceThreshold(np.median(X.var().values)).fit_transform(X)
#======【TIME WARNING:35mins +】======#
cross_val_score(KNN(),X,y,cv=5).mean()
#python中的魔法命令,可以直接使用%%timeit来计算运行这个cell中的代码所需的时间
#为了计算所需的时间,需要将这个cell中的代码运行很多次(通常是7次)后求平均值,因此运行%%timeit的时间会
远远超过cell中的代码单独运行的时间
#======【TIME WARNING:4 hours】======#
%%timeit
cross_val_score(KNN(),X,y,cv=5).mean()
#======【TIME WARNING:20 mins+】======#
cross_val_score(KNN(),X_fsvar,y,cv=5).mean()
#======【TIME WARNING:2 hours】======#
%%timeit
cross_val_score(KNN(),X,y,cv=5).mean()
cross_val_score(RFC(n_estimators=10,random_state=0),X,y,cv=5).mean()
Tsai
方差过滤前的KNN结果

#======【TIME WARNING:20 mins+】======#
cross_val_score(KNN(),X_fsvar,y,cv=5).mean()
#======【TIME WARNING:2 hours】======#
%%timeit
cross_val_score(KNN(),X,y,cv=5).mean()
方差过滤后的KNN结果

准确率稍有提升,但平均运行时间减少了10分钟,特征选择过后算法的效率上升了1/3。
那随机森林又如何呢?
随机森林方差过滤前

随机森林方差过滤后

首先可以观察到的是,随机森林的准确率略逊于KNN,但运行时间却连KNN的1%都不到,只需要十几秒钟。其次,方差过滤后,随机森林的准确率也微弱上升,但运行时间却几乎是没什么变化,依然是11秒钟。
为什么随机森林运行如此之快?为什么方差过滤对随机森林没很大的有影响?这是由于两种算法的原理中涉及到的计算量不同。最近邻算法KNN,单棵决策树,支持向量机SVM,神经网络,回归算法,都需要遍历特征或升维来进行运算,所以他们本身的运算量就很大,需要的时间就很长,因此方差过滤这样的特征选择对他们来说就尤为重要。但对于不需要遍历特征的算法,比如随机森林,它随机选取特征进行分枝,本身运算就非常快速,因此特征选择对它来说效果平平。这其实很容易理解,无论过滤法如何降低特征的数量,随机森林也只会选取固定数量的特征来建模;而最近邻算法就不同了,特征越少,距离计算的维度就越少,模型明显会随着特征的减少变得轻量。因此,过滤法的主要对象是:需要遍历特征或升维的算法们,而过滤法的主要目的是:在维持算法表现的前提下,帮助算法们降低计算成本。
总的来说
方差过滤的影响如下

- 相关性过滤
方差挑选完毕之后,我们就要考虑下一个问题:相关性了。我们希望选出与标签相关且有意义的特征,因为这样的特征能够为我们提供大量信息。如果特征与标签无关,那只会白白浪费我们的计算内存,可能还会给模型带来噪音。在sklearn当中,我们有三种常用的方法来评判特征与标签之间的相关性:卡方,F检验,互信息。
- 卡方过滤
卡方过滤是专门针对离散型标签(即分类问题)的相关性过滤。卡方检验类feature_selection.chi2计算每个非负特征和标签之间的卡方统计量,并依照卡方统计量由高到低为特征排名。再结合feature_selection.SelectKBest这个可以输入”评分标准“来选出前K个分数最高的特征的类,我们可以借此除去最可能独立于标签,与我们分类目的无关的特征。
另外,如果卡方检验检测到某个特征中所有的值都相同,会提示我们使用方差先进行方差过滤。并且,刚才我们已经验证过,当我们使用方差过滤筛选掉一半的特征后,模型的表现时提升的。因此在这里,我们使用threshold=中位数时完成的方差过滤的数据来做卡方检验(如果方差过滤后模型的表现反而降低了,那我们就不会使用方差过滤后的数据,而是使用原数据):
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2 #卡方检验
#假设在这里我们知道我们需要300个特征
X_fschi = SelectKBest(chi2,k=300).fit_transform(X_fsvar,Y)
cross_val_score(RFC(n_estimators=10,random_state=0),X_fschi,Y,cv=5).mean()
cross_val_score(RFC(n_estimators=10,random_state=0),X_fsvar,Y,cv=5).mean()
我们发现之前取中位数作方法过滤的时候,交叉检验打分为0.9388098166696807,而经过了卡方过滤,交叉检验的打分变成了0.9333098667649198,降低了!
这说明,K=300的设定有问题,我们K值调的太小了。
该如何选取K值?
我们可以采用学习曲线来跑一跑。
%matplotlib inline
import matplotlib.pyplot as plt
score = []
for i in range(390,200,-10):
X_fschi = SelectKBest(chi2,k=i).fit_transform(X_fsvar,Y)
once = cross_val_score(RFC(n_estimators=10,random_state=0),X_fschi,Y,cv=5).mean()
score.append(once)
plt.plot(range(390,200,-10),score)
plt.show()
另外一种选取k值的方式:看p值选k值
法:看p值选择k。
卡方检验的本质是推测两组数据之间的差异,其检验的原假设是”两组数据是相互独立的”。卡方检验返回卡方值和P值两个统计量,其中卡方值很难界定有效的范围,而p值,我们一般使用0.01或0.05作为显著性水平,即p值判断的边界,具体我们可以这样来看:
从特征工程的角度,我们希望选取卡方值很大,p值小于0.05的特征,即和标签是相关联的特征。而调用SelectKBest之前,我们可以直接从chi2实例化后的模型中获得各个特征所对应的卡方值和P值。
chivalue, pvalues_chi = chi2(X_fsvar,Y)
#k取多少?我们想要消除所有p值大于设定值,比如0.05或0.01的特征:
k = chivalue.shape[0] - (pvalues_chi > 0.05).sum()
- F检验
F检验,又称ANOVA,方差齐性检验,是用来捕捉每个特征与标签之间的线性关系的过滤方法。它即可以做回归也
可以做分类,因此包含feature_selection.f_classif(F检验分类)和feature_selection.f_regression(F检验回归)两个类。其中F检验分类用于标签是离散型变量的数据,而F检验回归用于标签是连续型变量的数据。
F检验的本质是寻找两组数据之间的线性关系,其原假设是”数据不存在显著的线性关系“。它返回F值和p值两个统计量。和卡方过滤一样,我们希望选取p值小于0.05或0.01的特征,这些特征与标签时显著线性相关的,而p值大于0.05或0.01的特征则被我们认为是和标签没有显著线性关系的特征,应该被删除。以F检验的分类为例,我们继续在数字数据集上来进行特征选择:
from sklearn.feature_selection import f_classif
F, pvalues_f = f_classif(X_fsvar,Y)
k = F.shape[0] - (pvalues_f > 0.05).sum()
- 互信息法
互信息法是用来捕捉每个特征与标签之间的任意关系(包括线性和非线性关系)的过滤方法。和F检验相似,它既可以做回归也可以做分类,并且包含两个类feature_selection.mutual_info_classif(互信息分类)和
feature_selection.mutual_info_regression(互信息回归)。这两个类的用法和参数都和F检验一模一样,不过互信息法比F检验更加强大,F检验只能够找出线性关系,而互信息法可以找出任意关系。
from sklearn.feature_selection import mutual_info_classif as MIC
result = MIC(X_fsvar,y)
k = result.shape[0] - sum(result <= 0)
#X_fsmic = SelectKBest(MIC, k=填写具体的k).fit_transform(X_fsvar, y)
#cross_val_score(RFC(n_estimators=10,random_state=0),X_fsmic,y,cv=5).mean()
建议:
先使用方差过滤,然后使用互信息法来捕捉相关性

嵌入法(Embedded)
因此相比于过滤法**,嵌入法的结果会更加精确到模型的效用本身,对于提高模型效力有更好的效果**。并且,由于考虑特征对模型的贡献,因此无关的特征(需要相关性过滤的特征)和无区分度的特征(需要方差过滤的特征)都会因为缺乏对模型的贡献而被删除掉,可谓是过滤法的进化版。

可以完全不过滤,直接使用嵌入法。
feature_selection.SelectFromModel

前两个参数是最重要的。
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier as RFC
RFC_ = RFC(n_estimators = 10,random_state = 0) #随机森林的实例化
X_embedded = SelectFromModel(RFC_, threshold=0.005).fit_transform(X,Y)
X_embedded.shape
结果为(42000, 47)
0.005这个阈值对780个特征的数据来说是非常高的,这里模型的维度明显降低了。
同样的,我们也可以通过画学习曲线来找最佳阈值。
import numpy as np
import matplotlib.pyplot as plt
RFC_.fit(X,Y).feature_importances_
threshold = np.linspace(0,(RFC_.fit(X,Y).feature_importances_).max(),20)
score = []
for i in threshold:
X_embedded = SelectFromModel(RFC_,threshold=i).fit_transform(X,Y)
once = cross_val_score(RFC_,X_embedded,Y,cv=5).mean()
score.append(once)
plt.plot(threshold,score)
plt.show()
代码结果如下:

随着阈值越来越高,模型的效果逐渐变差,被删除的特征越来越多,信息损失也逐渐变大。但是在0.00134之前,模型的效果都可以维持在0.93以上,因此我们可以从中挑选一个数值来验证一下模型的效果。
X_embedded = SelectFromModel(RFC_,threshold = 0.00067).fit_transform(X,Y)
X_embedded.shape
cross_val_score(RFC_,X_embedded,Y,cv=5).mean()
代码结果为
(42000, 324)
0.939905083368037
可以看出,特征个数瞬间缩小到324多,这比我们在方差过滤的时候选择中位数过滤出来的结果392列要小,并且交叉验证分数0.9399高于方差过滤后的结果0.9388,这是由于嵌入法比方差过滤更具体到模型的表现的缘故,换一个算法,使用同样的阈值,效果可能就没有这么好了。
和其他调参一样,我们可以在第一条学习曲线后选定一个范围,使用细化的学习曲线来找到最佳值:
score2 = []
for i in np.linspace(0,0.00134,20):
X_embedded = SelectFromModel(RFC_, threshold=i).fit_transform(X,Y)
once = cross_val_score(RFC_, X_embedded, Y, cv=5).mean()
score2.append(once)
plt.figure(figsize=[20,5])
plt.plot(np.linspace(0,0.00134,20),score2)
plt.xticks(np.linspace(0,0.00134,20))
plt.show()
X_embedded = SelectFromModel(RFC_,threshold=0.000564).fit_transform(X,Y)
X_embedded.shape
cross_val_score(RFC_,X_embedded,Y,cv=10).mean()
我们可能已经找到了现有模型的最佳结果。
(42000, 340)
0.9414774325210074
如果我们调整一下随机森林的参数呢?
cross_val_score(RFC(n_estimators=100,random_state=0),X_embedded,Y,cv=5).mean()
0.9639525817795566
得出的特征数目依然小于方差筛选,并且模型的表现也比没有筛选之前更高,已经完全可以和计算一次半小时的KNN相匹敌(KNN的准确率是96.58%),接下来再对随机森林进行调参,准确率应该还可以再升高不少。可见,在嵌入法下,我们很容易就能够实现特征选择的目标:减少计算量,提升模型表现。因此,比起要思考很多统计量的过滤法来说,嵌入法可能是更有效的一种方法。然而,在算法本身很复杂的时候,过滤法的计算远远比嵌入法要快,所以大型数据中,我们还是会优先考虑过滤法。
包装法(Wrapper)

包装法在初始特征集上训练评估器,并且通过coef_属性或通过feature_importances_属性获得每个特征的重要性。然后,从当前的一组特征中修剪最不重要的特征。在修剪的集合上递归地重复该过程,直到最终到达所需数量的要选择的特征。区别于过滤法和嵌入法的一次训练解决所有问题,包装法要使用特征子集进行多次训练,因此它所需要的计算成本是最高的。
最典型的目标函数是递归特征消除法(Recursive feature elimination, 简写为RFE)。它是一种贪婪的优化算法,旨在找到性能最佳的特征子集。 它反复创建模型,并在每次迭代时保留最佳特征或剔除最差特征,下一次迭代时,它会使用上一次建模中没有被选中的特征来构建下一个模型,直到所有特征都耗尽为止。 然后,它根据自己保留或剔除特征的顺序来对特征进行排名,最终选出一个最佳子集。包装法的效果是所有特征选择方法中最利于提升模型表现的,它可以使用很少的特征达到很优秀的效果。除此之外,在特征数目相同时,包装法和嵌入法的效果能够匹敌,不过它比嵌入法算得更见缓慢,所以也不适用于太大型的数据。相比之下,包装法是最能保证模型效果的特征选择方法。
feature_selection.RFE
class sklearn.feature_selection.RFE(estimator,n_features_to_select=None,step=1,verbose=0)

from sklearn.feature_selection import RFE
RFC_ = RFC(n_estimators=10, random_state=0)
selector = RFE(RFC_, n_features_to_select=340, step=50).fit(X,Y) #刚刚用嵌入法选出来的340
selector.support_.sum() #support返回的是boolean矩阵
selector.ranking_
X_wrapper = selector.transform(X)
cross_val_score(RFC_,X_wrapper,Y,cv=5).mean()
0.9389522459432109
接下来对包装法画学习曲线。
score = []
for i in range(1,751,50):
X_wrapper = RFE(RFC_, n_features_to_select=i, step=50).fit_transform(X,Y)
once = cross_val_score(RFC_, X_wrapper, Y, cv=5).mean()
score.append(once)
plt.figure(figsize=[20,5])
plt.plot(range(1,751,50),score)
plt.xticks(range(1,751,50))
plt.show()
明显能够看出,在包装法下面,应用50个特征时,模型的表现就已经达到了90%以上,比嵌入法和过滤法都高效很多。我们可以放大图像,寻找模型变得非常稳定的点来画进一步的学习曲线(就像我们在嵌入法中做的那样)。如果我们此时追求的是最大化降低模型的运行时间,我们甚至可以直接选择50作为特征的数目,这是一个在缩减了94%的特征的基础上,还能保证模型表现在90%以上的特征组合,不可谓不高效。
同时,我们提到过,在特征数目相同时,包装法能够在效果上匹敌嵌入法。试试看如果我们也使用340作为特征数目,运行一下,可以感受一下包装法和嵌入法哪一个的速度更加快。由于包装法效果和嵌入法相差不多,在更小的范围内使用学习曲线,我们也可以将包装法的效果调得很好,大家可以去试试看。
特征工程总结
当数据量很大的时候,优先使用方差过滤和互信息法调整,再上其他特征选择方法。
使用逻辑回归时,优先使用嵌入法。
使用支持向量机时,优先使用包装法。
原文链接:https://blog.csdn.net/xlperpetual/article/details/103402737
觉得这篇文章写的很好,然而浏览量却又很少,想把他带到大家的视野当中,更多人能够学习到。
相关文章:
sklearn中的特征工程(过滤法、嵌入法和包装法)
目录 编辑特征工程的第一步:理解业务 Filter过滤法 编辑方差过滤 编辑- 相关性过滤 - 卡方过滤 - F检验 - 互信息法 编辑嵌入法(Embedded) 包装法(Wrapper) 特征工程的第一步:理解业务 如…...
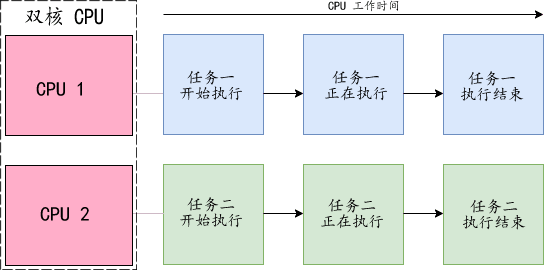
Linux C/C++并发编程实战(0)谈谈并发与并行
作为并发编程的第一讲,比较轻松,我们先来谈谈什么是并发和并行。 并发(Concurrency)是指一个处理器同时处理多个任务。 并行(Parallelism)是指多个处理器或者是多核的处理器同时处理多个不同的任务。 并发…...

2023年5月天津/南京/成都/深圳CDGA/CDGP数据治理认证报名
6月18日DAMA-CDGA/CDGP数据治理认证考试开放报名中! 考试开放地区:北京、上海、广州、深圳、长沙、呼和浩特、杭州、南京、济南、成都、西安。其他地区凑人数中… DAMA-CDGA/CDGP数据治理认证班进行中,报名从速! DAMA认证为数据管…...

【MySQL】MySQL批量插入测试数据的几种方式
文章目录 前言一、表二、使用函数生成设置允许创建函数产生随机字符串产生随机数字 三、创建存储过程插入角色表插入用户表 四、执行存储过程小结五、使用 Navicat自带的数据生成 前言 在开发过程中我们不管是用来测试性能还是在生产环境中页面展示好看一点, 又或者学习验证某…...
PowerShell install 一键部署virtualbox
VirtualBox 前言 VirtualBox 是一款开源虚拟机软件。VirtualBox 是由德国 Innotek 公司开发,由Sun Microsystems公司出品的软件,使用Qt编写,在 Sun 被 Oracle 收购后正式更名成 Oracle VM VirtualBox。Innotek 以 GNU General Public Licens…...
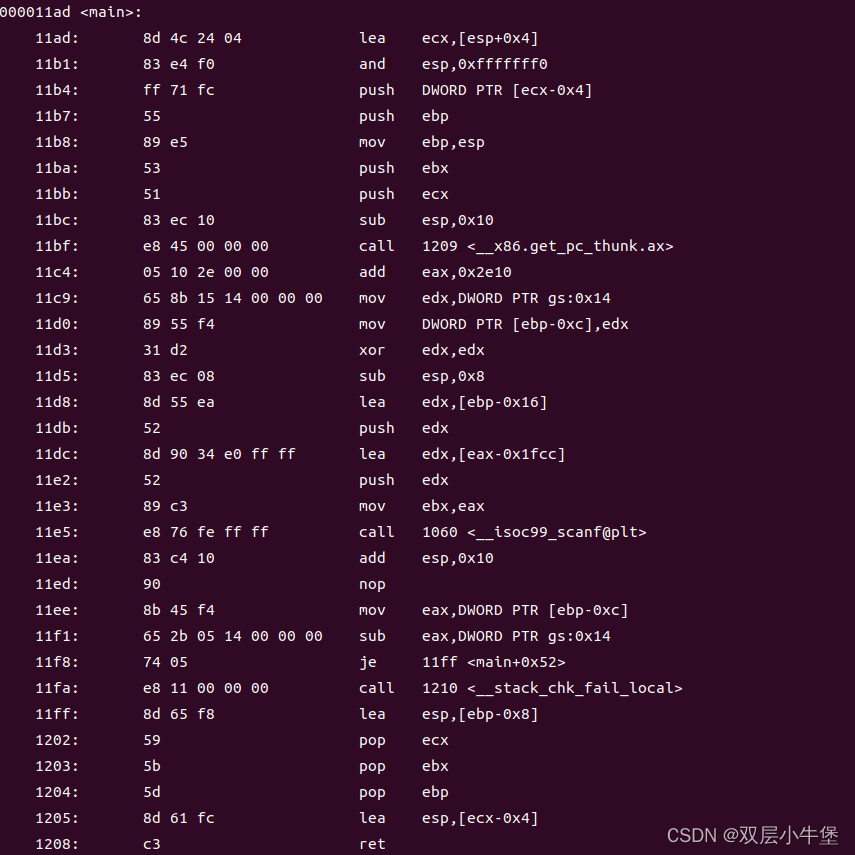
CTF权威指南 笔记 -第四章Linux安全机制-4.1-Stack Canaries
目录 Stack Canaries 简介 我们进行简单的例子 64 32 checksec Stack Canaries 是对抗栈溢出攻击的技术 SSP安全机制 Canary 的值 栈上的一个随机数 在程序启动时 随机生成并且保存在比返回地址更低值 栈溢出是从低地址向高地址进行溢出 如果攻击者要攻击 就一定要覆…...

KDZD400Q便携式三氯乙烯浓度检测仪
一、产品概述 检测仪用于快速检测多种气体浓度、温湿度测量并超标报警的场合。采用2.31寸高清彩屏实时显示,选用进口品牌的气体传感器,主要检测原理有:电化学、红外、催化燃烧、热导、PID 光离子等。 可以检测管道中或受限空间、大气环境中的…...
C++11 部分新特性
1. 关键字和语法 1.1 nullptr 空指针,能够和整数0进行区别,因为#define NULL 0 1.2 类中非静态成员变量定义时初始化 & 初始化列表 1.3 auto 可推导出右值类型,从而得知左边变量类型。 简单使用示例: auto func() {retur…...

selenium通过performance log获取状态码,Conten-Type,以及重定向路径
selenium的官方不提供获取状态码,Conten-Type,以及重定向路径的方法,并且官方说这些功能将来也不会有。java - How to get HTTP Response Code using Selenium WebDriver - Stack Overflow 非官方的方法大概有下面几种 1.通过requests重新请…...

GL绘制自定义线条3_自定义线帽
安卓Path搭配Paint可以设置线帽,我想能不能把我自己的线条绘制Demo也加上类似的功能。 线头规则描述: 1、设一个线宽一半的线段,坐标为(0, 0)到(-lineWidth / 2, 0)。 2、设步骤1的线段有一垂直于它的向量(0,1),然后传…...
【AGC】新版鸿蒙崩溃SDK集成使用方法
【背景】 我们知道AGC的Crash SDK都是需要强制集成华为分析SDK的,在使用时的崩溃数据上报都要依靠分析服务来完成,这就容易受到限制,有时出现无数据的情况就要依次排查崩溃SDK与分析SDK,比较麻烦。而就在不久前,鸿蒙崩…...

vue-7:组件库(移动端vant)(PC端element)
移动端vant 插件安装(按需导入) 重启生效 # 通过 npm 安装 npm i unplugin-vue-components -D# 通过 yarn 安装 yarn add unplugin-vue-components -D 导入基于 vite 的项目: 如果是基于 vite 的项目,在 vite.config.js 文件中…...
、slice()、split()三种方法的区别,及使用详细)
JavaScript中splice()、slice()、split()三种方法的区别,及使用详细
简介:splice、slice、split是JavaScript中,比较常用的三个数组方法,表面看起来有点相像,用处却大不相同,今天就来分别介绍下它们的用法。 1、splice()方法 splice方法可以用来删除数组中的元素,或者向数组…...
)
Linux更新操作系统Openssh版本9.3p1(源码编译安装)
Linux更新操作系统Openssh版本9.3p1(源码编译安装) 部署前准备 安装依赖 yum install -y gcc gcc-c glibc make autoconf openssl openssl-devel pcre-devel pam-develyum install -y pam* zlib* openssh-9.3p1.tar.gzopenssl-3.1.0.tar.gz备份文件 cp /etc/pam.d/sshd /etc/…...
MS COCO数据集介绍
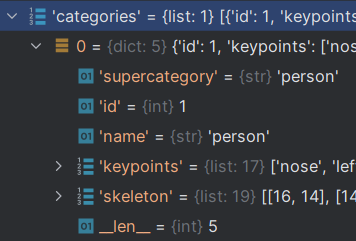
MS COCO数据集介绍 MS COCO全称是Microsoft Common Objects in Context,是由微软开发维护的大型图像数据集,包括不同检测任务: Object Detection([主要处理人、车、大象等]) DensePose(姿态密度检测&…...
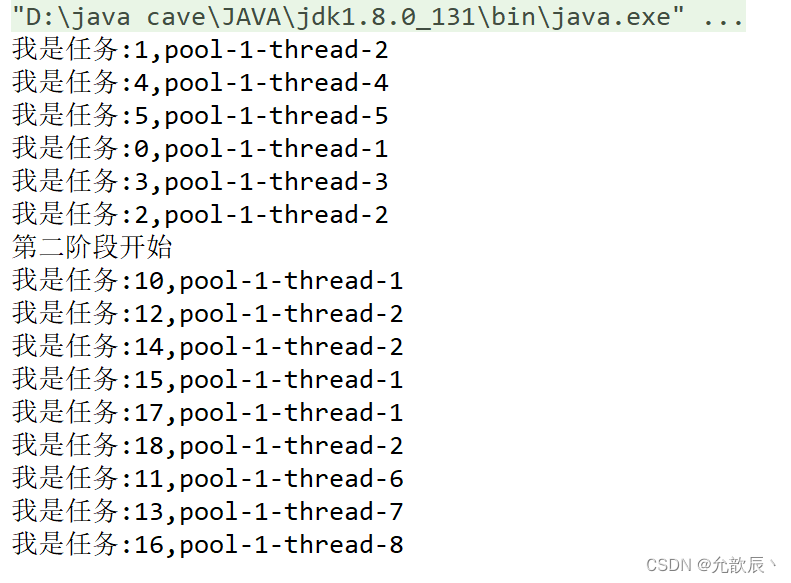
Java之线程池
目录 一.上节复习 1.阻塞队列 二.线程池 1.什么是线程池 2.为什么要使用线程池 3.JDK中的线程池 三.工厂模式 1.工厂模式的目的 四.使用线程池 1.submit()方法 2.模拟两个阶段任务的执行 五.自定义一个线程池 六.JDK提供线程池的详解 1.如何自定义一个线程池? 2.创…...

让你的网站变得更智能 - B2 Pro主题问答模块新增OpenAI ChatGPT机器人自动回答功能
作为一个网站管理员,你一定会希望能够给你的用户提供更多、更好的服务。那么,你是否曾经想过为你的B2 Pro主题问答模块新增一个智能机器人自动回答功能呢?相信你一定想要这个功能,因为它能够大大提升你网站的用户体验。 现在,我们为你提供了一个好消息。我们已经为B2 Pro…...
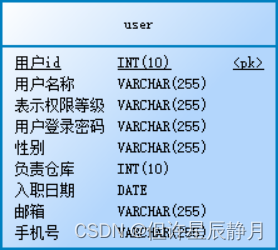
仓库信息管理系统设计与实现
一、数据库设计 1.数据库模型设计概览 2.数据库表设计 ①depository 描述: 该表存储仓库的信息,比如仓库名称,仓库地址和仓库介绍 表结构: 序号 字段名 数据类型 主键 非空 默认值 描述 1 id INT(10) 是 是 2…...
初识Java多线程编程
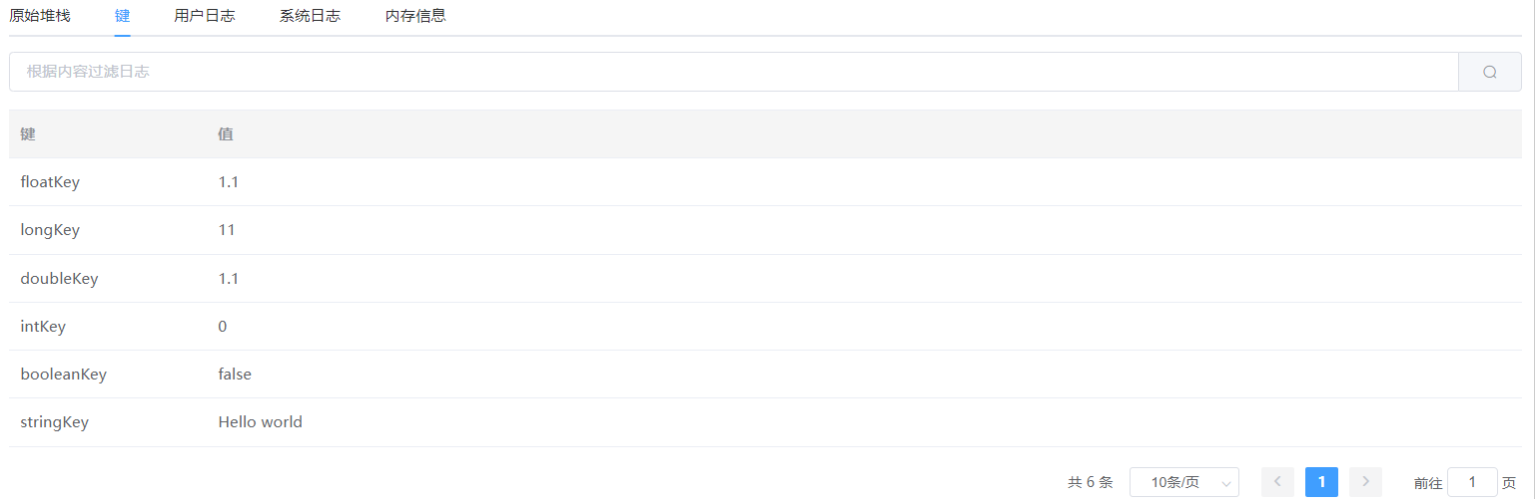
文章目录 一、线程的状态二、线程的常见属性三、多线程编程Thread类常用构造方法1.继承Thread类2.实现Runnable接口3.匿名内部类实现4.lambda 表达式创建 Runnable 子类对象 四、线程的常见方法 一、线程的状态 //线程的状态是一个枚举类型 Thread.State public class ThreadS…...

最新入河排污口设置论证、水质影响预测与模拟、污水处理工艺分析及典型建设项目入河排污口方案报告书实例分析
随着水资源开发利用量不断增大,全国废污水排放量与日俱增,部分河段已远远超出水域纳污能力。近年来,部分沿岸入河排污口设置不合理,超标排污、未经同意私设排污口等问题逐步显现,已威胁到供水安全、水环境安全和水生态安全&#x…...

如何用GetQzonehistory永久保存你的QQ空间记忆:免费备份工具完整指南
如何用GetQzonehistory永久保存你的QQ空间记忆:免费备份工具完整指南 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 你是否曾在深夜翻看QQ空间,想找回那些记录青…...

Python FastAPI 异步请求调度逻辑
Python FastAPI 异步请求调度逻辑解析 在当今高并发的互联网应用中,异步编程已成为提升性能的关键技术。Python的FastAPI框架凭借其原生支持异步请求处理的能力,成为开发高效API的热门选择。本文将深入探讨FastAPI的异步请求调度逻辑,帮助开…...

ACE-Step音乐模型部署体验:一键生成高质量音频,创作效率大提升
ACE-Step音乐模型部署体验:一键生成高质量音频,创作效率大提升 1. 音乐创作的新时代 你是否曾经遇到过这样的困境:脑海中有一段美妙的旋律,却苦于不会乐器或不懂乐理,无法将它变成现实?或者作为一名内容创…...

智能车全向组圆环处理实战:从识别到出环的完整状态机设计
1. 智能车圆环处理的挑战与状态机设计思路 第一次参加智能车比赛时,圆环处理简直是我的噩梦。记得当时连续熬了三个通宵,就是为了解决车子在圆环里"迷路"的问题。后来才发现,把整个圆环过程拆分成多个状态,用状态机来管…...
)
Arduino Uno + MPU6050:手把手教你用DMP库获取稳定的欧拉角(附完整代码与校准避坑指南)
Arduino Uno与MPU6050深度实战:DMP库高精度欧拉角获取全解析 当你第一次成功连接MPU6050传感器并看到串口输出的欧拉角数据时,那种兴奋感可能很快会被现实击碎——数据不断跳动、角度漂移严重,根本无法用于实际项目。这不是你的错,…...

PP-DocLayoutV3助力学术出版:LaTeX论文手稿的自动排版分析
PP-DocLayoutV3助力学术出版:LaTeX论文手稿的自动排版分析 每次看到那些排版精美、公式复杂的学术论文,你是不是也好奇过,这些文档里的结构信息——比如哪部分是标题、哪部分是公式、参考文献又在哪里——能不能被机器自动识别出来ÿ…...

Nginx同端口部署多个vue以及unapp项目
同一个端口部署pc和app端项目,Nginx配置,前端打包配置解决方案配置pc端vue项目打包配置配置uniapp项目打包配置,manifest.json文件添加配置123456789101112131415161718192021222324252627"h5": {"router": {"mode&…...

Jetson orin nano 中安装docker
检查当前系统是否已经安装了 Docker,以及当前安装的版本号。通常在安装前运行它是为了确认是否需要安装: docker --version使用 curl 工具从 Docker 官方网站下载“一键安装脚本”,-fsSL 是一些静默下载和处理重定向的参数,-o ge…...

如何处理旧版MongoDB升级到新版时密码哈希不兼容
bcrypt哈希值在MongoDB各版本间完全兼容,问题根源是认证机制升级:旧MONGODB-CR用户需重建为SCRAM-SHA-1,FCV须同步更新,驱动与连接字符串需显式指定authMechanism。bcrypt 哈希结果在新旧 MongoDB 版本间完全兼容,问题…...

rk3399平台rtl8723DS Wi-Fi模块SDIO接口驱动移植与双模配置实战
1. 认识rk3399与rtl8723DS这对黄金搭档 第一次拿到rk3399开发板和rtl8723DS模块时,我就像拿到新玩具的孩子一样兴奋。rk3399这颗六核处理器在嵌入式领域堪称性能怪兽,而rtl8723DS作为Wi-Fi蓝牙二合一模块,2.4GHz频段支持加上双模共存特性&…...