Flink Kafka-Source
文章目录
- Kafka Source
- 1. 使用方法
- 2. Topic / Partition 订阅
- 3. 消息解析
- 4. 起始消费位点
- 5. 有界 / 无界模式
- 6. 其他属性
- 7. 动态分区检查
- 8. 事件时间和水印
- 9. 空闲
- 10. 消费位点提交
- 11. 监控
- 12. 安全
- Apache Kafka 连接器
Flink 提供了 Apache Kafka 连接器使用精确一次(Exactly-once)的语义在 Kafka topic 中读取和写入数据。 - 依赖
<!-- flink kakfa --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.12</artifactId><version>${flink.version}</version></dependency>
Kafka Source
1. 使用方法
Kafka Source 提供了构建类来创建 KafkaSource 的实例。以下代码片段展示了如何构建 KafkaSource 来消费 “input-topic” 最早位点的数据, 使用消费组 “my-group”,并且将 Kafka 消息体反序列化为字符串:
KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers(brokers).setTopics("input-topic").setGroupId("my-group").setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema()).build();env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
2. Topic / Partition 订阅
以下属性在构建 KafkaSource 时是必须指定的:
- Bootstrap server,通过 setBootstrapServers(String) 方法配置
- 消费者组 ID,通过 setGroupId(String) 配置
- 要订阅的 Topic / Partition,请参阅 Topic / Partition 订阅一节
- 用于解析 Kafka 消息的反序列化器(Deserializer),请参阅消息解析一节
Kafka Source 提供了 3 种 Topic / Partition 的订阅方式:
- Topic 列表,订阅 Topic 列表中所有 Partition 的消息:
KafkaSource.builder().setTopics("topic-a", "topic-b");
- 正则表达式匹配,订阅与正则表达式所匹配的 Topic 下的所有 Partition:
KafkaSource.builder().setTopicPattern("topic.*");
- Partition 列表,订阅指定的 Partition:
final HashSet<TopicPartition> partitionSet = new HashSet<>(Arrays.asList(new TopicPartition("topic-a", 0), // Partition 0 of topic "topic-a"new TopicPartition("topic-b", 5))); // Partition 5 of topic "topic-b"
KafkaSource.builder().setPartitions(partitionSet);
3. 消息解析
代码中需要提供一个反序列化器(Deserializer)来对 Kafka 的消息进行解析。 反序列化器通过 setDeserializer(KafkaRecordDeserializationSchema) 来指定,其中 KafkaRecordDeserializationSchema 定义了如何解析 Kafka 的 ConsumerRecord。
如果只需要 Kafka 消息中的消息体(value)部分的数据,可以使用 KafkaSource 构建类中的 setValueOnlyDeserializer(DeserializationSchema) 方法,其中 DeserializationSchema 定义了如何解析 Kafka 消息体中的二进制数据。
也可使用 Kafka 提供的解析器 来解析 Kafka 消息体。例如使用 StringDeserializer 来将 Kafka 消息体解析成字符串:
import org.apache.kafka.common.serialization.StringDeserializer;KafkaSource.<String>builder().setDeserializer(KafkaRecordDeserializationSchema.valueOnly(StringDeserializer.class));
4. 起始消费位点
Kafka source 能够通过位点初始化器(OffsetsInitializer)来指定从不同的偏移量开始消费 。内置的位点初始化器包括:
KafkaSource.builder()// 从消费组提交的位点开始消费,不指定位点重置策略.setStartingOffsets(OffsetsInitializer.committedOffsets())// 从消费组提交的位点开始消费,如果提交位点不存在,使用最早位点.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST))// 从时间戳大于等于指定时间戳(毫秒)的数据开始消费.setStartingOffsets(OffsetsInitializer.timestamp(1657256176000L))// 从最早位点开始消费.setStartingOffsets(OffsetsInitializer.earliest())// 从最末尾位点开始消费.setStartingOffsets(OffsetsInitializer.latest());
如果内置的初始化器不能满足需求,也可以实现自定义的位点初始化器(OffsetsInitializer),如果未指定位点初始化器,将默认使用 OffsetsInitializer.earliest();
5. 有界 / 无界模式
Kafka Source 支持流式和批式两种运行模式。默认情况下,KafkaSource 设置为以流模式运行,因此作业永远不会停止,直到 Flink 作业失败或被取消。 可以使用 setBounded(OffsetsInitializer) 指定停止偏移量使 Kafka Source 以批处理模式运行。当所有分区都达到其停止偏移量时,Kafka Source 会退出运行。
流模式下运行通过使用 setUnbounded(OffsetsInitializer) 也可以指定停止消费位点,当所有分区达到其指定的停止偏移量时,Kafka Source 会退出运行。
6. 其他属性
除了上述属性之外,您还可以使用 setProperties(Properties) 和 setProperty(String, String) 为 Kafka Source 和 Kafka Consumer 设置任意属性。KafkaSource 有以下配置项:
- client.id.prefix,指定用于 Kafka Consumer 的客户端 ID 前缀
- partition.discovery.interval.ms,定义 Kafka Source 检查新分区的时间间隔。
- register.consumer.metrics 指定是否在 Flink 中注册 Kafka Consumer 的指标
- commit.offsets.on.checkpoint 指定是否在进行 checkpoint 时将消费位点提交至 Kafka broker
请注意,即使指定了以下配置项,构建器也会将其覆盖:
- key.deserializer 始终设置为 ByteArrayDeserializer
- value.deserializer 始终设置为 ByteArrayDeserializer
- auto.offset.reset.strategy 被 OffsetsInitializer#getAutoOffsetResetStrategy() 覆盖
- partition.discovery.interval.ms 会在批模式下被覆盖为 -1
7. 动态分区检查
为了在不重启 Flink 作业的情况下处理 Topic 扩容或新建 Topic 等场景,可以将 Kafka Source 配置为在提供的 Topic / Partition 订阅模式下定期检查新分区。要启用动态分区检查,请将 partition.discovery.interval.ms 设置为非负值:
KafkaSource.builder().setProperty("partition.discovery.interval.ms", "10000"); // 每 10 秒检查一次新分区
分区检查功能默认不开启。需要显式地设置分区检查间隔才能启用此功能。
8. 事件时间和水印
默认情况下,Kafka Source 使用 Kafka 消息中的时间戳作为事件时间。您可以定义自己的水印策略(Watermark Strategy) 以从消息中提取事件时间,并向下游发送水印:
env.fromSource(kafkaSource, new CustomWatermarkStrategy(), "Kafka Source With Custom Watermark Strategy");
9. 空闲
如果并行度高于分区数,Kafka Source 不会自动进入空闲状态。您将需要降低并行度或向水印策略添加空闲超时。如果在这段时间内没有记录在流的分区中流动,则该分区被视为“空闲”并且不会阻止下游操作符中水印的进度。
10. 消费位点提交
Kafka source 在 checkpoint 完成时提交当前的消费位点 ,以保证 Flink 的 checkpoint 状态和 Kafka broker 上的提交位点一致。如果未开启 checkpoint,Kafka source 依赖于 Kafka consumer 内部的位点定时自动提交逻辑,自动提交功能由 enable.auto.commit 和 auto.commit.interval.ms 两个 Kafka consumer 配置项进行配置。
注意:Kafka source 不依赖于 broker 上提交的位点来恢复失败的作业。提交位点只是为了上报 Kafka consumer 和消费组的消费进度,以在 broker 端进行监控。
11. 监控
Kafka source 会在不同的中汇报下列指标。
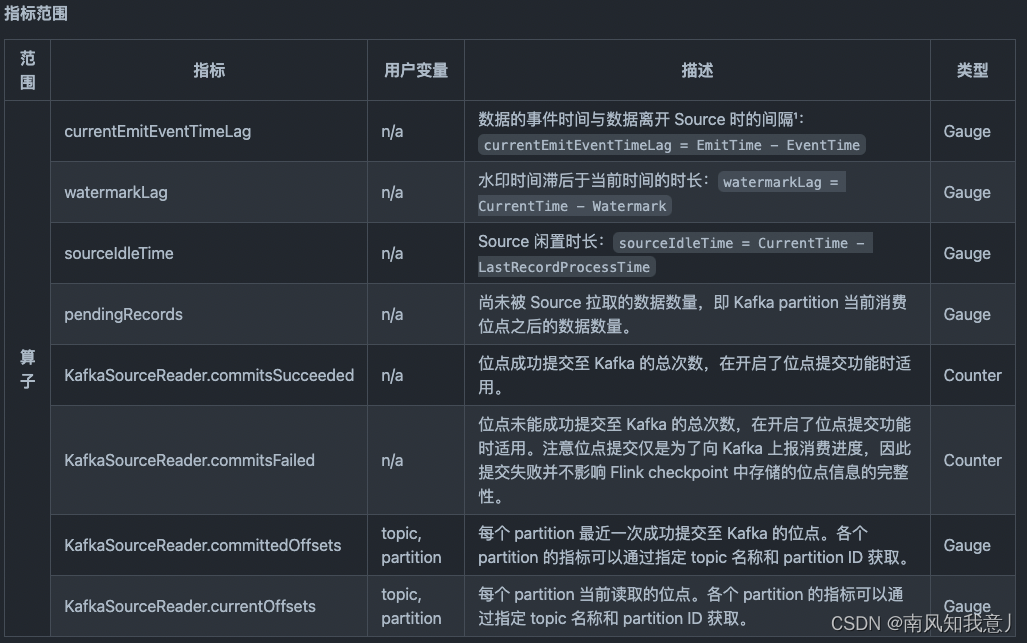
该指标反映了最后一条数据的瞬时值。之所以提供瞬时值是因为统计延迟直方图会消耗更多资源,瞬时值通常足以很好地反映延迟
指标监控参考
12. 安全
要启用加密和认证相关的安全配置,只需将安全配置作为其他属性配置在 Kafka source 上即可。下面的代码片段展示了如何配置 Kafka source 以使用 PLAIN 作为 SASL 机制并提供 JAAS 配置:
KafkaSource.builder().setProperty("security.protocol", "SASL_PLAINTEXT").setProperty("sasl.mechanism", "PLAIN").setProperty("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"username\" password=\"password\";");
另一个更复杂的例子,使用 SASL_SSL 作为安全协议并使用 SCRAM-SHA-256 作为 SASL 机制:
KafkaSource.builder().setProperty("security.protocol", "SASL_SSL")// SSL 配置// 配置服务端提供的 truststore (CA 证书) 的路径.setProperty("ssl.truststore.location", "/path/to/kafka.client.truststore.jks").setProperty("ssl.truststore.password", "test1234")// 如果要求客户端认证,则需要配置 keystore (私钥) 的路径.setProperty("ssl.keystore.location", "/path/to/kafka.client.keystore.jks").setProperty("ssl.keystore.password", "test1234")// SASL 配置// 将 SASL 机制配置为 as SCRAM-SHA-256.setProperty("sasl.mechanism", "SCRAM-SHA-256")// 配置 JAAS.setProperty("sasl.jaas.config", "org.apache.kafka.common.security.scram.ScramLoginModule required username=\"username\" password=\"password\";");
如果在作业 JAR 中 Kafka 客户端依赖的类路径被重置了(relocate class),登录模块(login module)的类路径可能会不同,因此请根据登录模块在 JAR 中实际的类路径来改写以上配置。
相关文章:
Flink Kafka-Source
文章目录 Kafka Source1. 使用方法2. Topic / Partition 订阅3. 消息解析4. 起始消费位点5. 有界 / 无界模式6. 其他属性7. 动态分区检查8. 事件时间和水印9. 空闲10. 消费位点提交11. 监控12. 安全 Apache Kafka 连接器 Flink 提供了 Apache Kafka 连接器使用精确一次…...
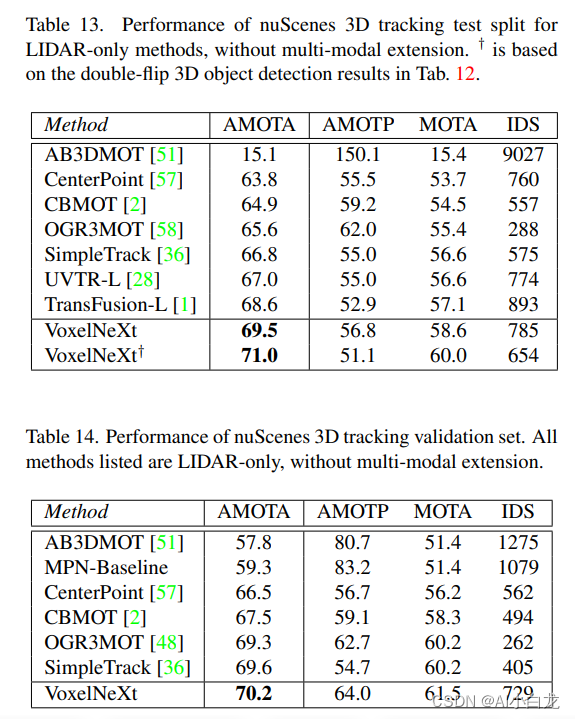
VoxelNeXt:用于3D检测和跟踪的纯稀疏体素网络
VoxelNeXt:Fully Sparse VoxelNet for 3D Object Detection and Tracking 目前自动驾驶场景的3D检测框架大多依赖于dense head,而3D点云数据本身是稀疏的,这无疑是一种低效和浪费计算量的做法。我们提出了一种纯稀疏的3D 检测框架 VoxelNeXt。该方法可以…...
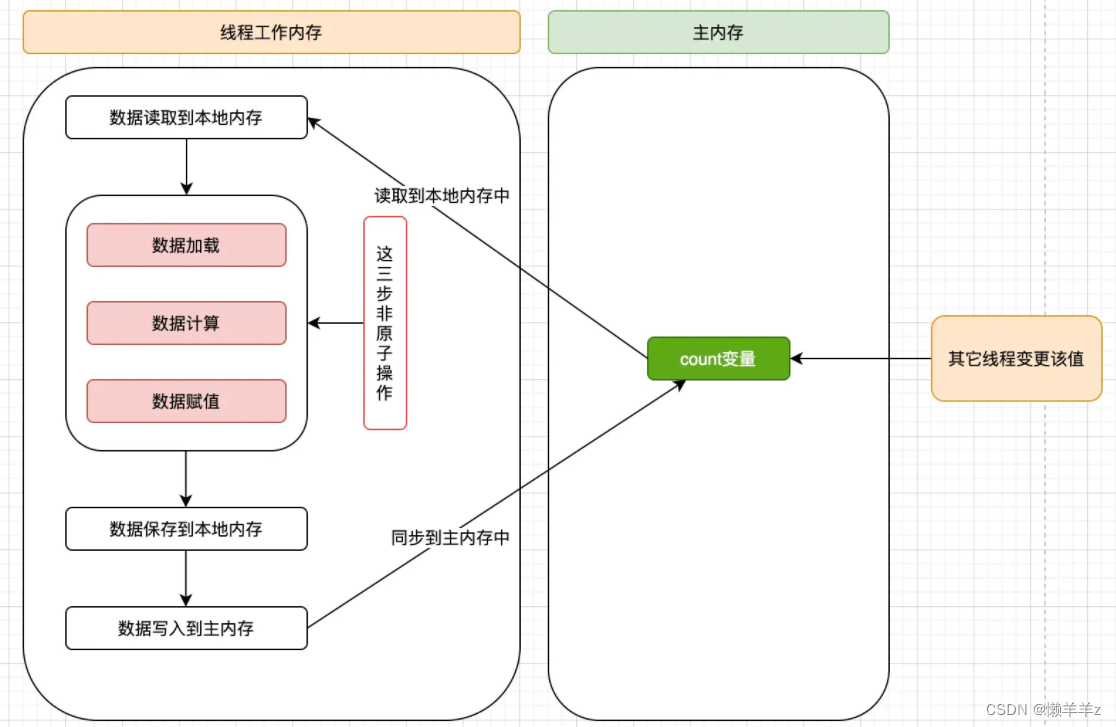
必须了解的内存屏障
目录 一,内存屏障1,概念2,内存屏障的效果3,cpu中的内存屏障 二,JVM中提供的四类内存屏障指令三,volatile 特性1,保证内存可见性定义2,禁止指令重排序3,不保证原子性 一&a…...
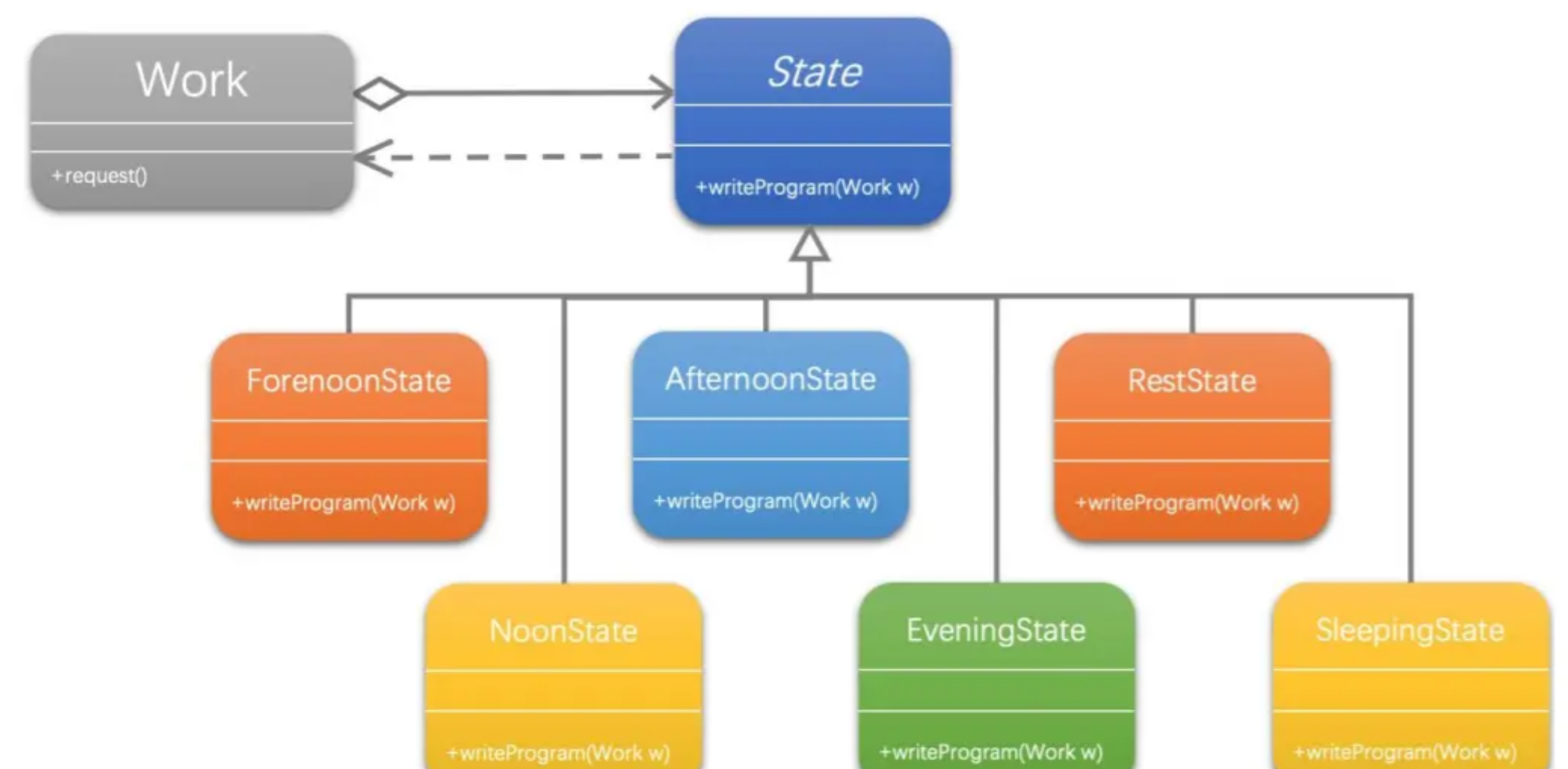
【设计模式】状态模式
文章目录 前言状态模式1、状态模式介绍1.1 存在问题1.2 解决问题1.3 状态模式结构图 2、具体案例说明状态模式2.1 不使用状态模式2.2 使用状态模式 3、状态模式总结 前言 状态模式主要解决的是当控制一个对象状态转换的条件表达式过于复杂时的情况。把状态的判断逻辑转移到表示…...

内核驱动支持浮点数运算
最近在调 iio 下的 ICM42686 驱动,因项目求需要在驱动对加速度和陀螺raw数据进行换算,避免不了浮点运算。内核编译时出现了报错,提示如下: drivers/iio/imu/tdk_icm42686/icm42686.o: In function gyro_data2float: /home/share/…...
)
Flink学习(一)
分布式计算框架 Java可以使用分布式计算来处理大规模的数据和计算任务,提高计算效率和性能。以下是一些Java分布式计算的例子: Apache Hadoop:Hadoop是一个开源的分布式计算框架,可以处理大规模数据集的分布式存储和处理。它使用Java编写,可以在分布式环境中运行MapReduc…...
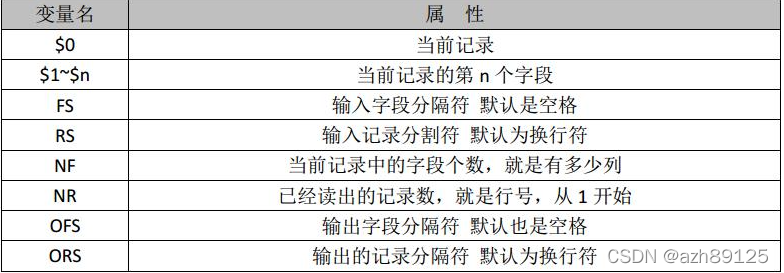
linux 常用命令awk
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。 AWK用法 awk 用法:awk pattern {action} files 1.RS, ORS, F…...

MySQL学习---15、流程控制、游标
1、流程控制 解决复杂问题不可能是通过一个SQL语句完成,我们需要执行多个SQL操作。流程控制语句的作用就是控制存储过程中SQL语句的执行顺序,是我们完成复杂操作必不可少的一部分。只要是执行的程序,流程就分为三大类: 1、顺序结…...

信息调查的观念
每次做一件事前都要把这件事调查清楚,比如考一门科目我们要把和这门科目有关的资源都收集起来,然后把再从中筛选出有用的信息,如数值计算方法我们在考试前就可以把b站有关的学习资源网课或者前人总结的考试经验做个收集总结,做出对…...

leetcode 337. 打家劫舍 III
题目链接:leetcode 337 1.题目 小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为 root 。 除了 root 之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的…...

基于Docker的深度学习环境NVIDIA和CUDA部署以及WSL和linux镜像问题
基于Docker的深度学习环境部署 1. 什么是Docker?2. 深度学习环境的基本要求3. Docker的基本操作3.1 在Windows上安装Docker3.2 在Ubuntu上安装Docker3.3 拉取一个pytorch的镜像3.4 部署自己的项目3.5 导出配置好项目的新镜像 4. 分享新镜像4.1 将镜像导出为tar分享给…...

c#中slice,substr,substring区别
1. 都使用一个参数: //栗子数据 var arr [1,2,3,4,5,6,7], str "helloworld!"; //防止空格干扰,不用带空格的,注意这里有个!号也算一位 console.log(str.slice(1)); //elloworld! console.log(str.substring(1)); //…...

java语言里redis在项目中使用场景,每个场景的样例代码
Redis是一款高性能的NoSQL数据库,常被用于缓存、消息队列、计数器、分布式锁等场景。以下是50个Redis在项目中使用的场景以及对应的样例代码和详细说明: ##1、缓存:将查询结果缓存在Redis中,下次查询时直接从缓存中获取ÿ…...

Mongo集合操作
2、创建切换数据库 2.1 默认数据库 mongo数据库和其他类型的数据库一样,可以创建数据库,且可以创建多个数据库。 mongo数据库默认会有四个数据库,分别是 admin:主要存储MongoDB的用户、角色等信息 config:主要存储…...

ConvTranspose2d 的简单例子理解
文章目录 参考基础概念output_padding 简单例子: stride2step1step2step3 参考 逆卷积的详细解释ConvTranspose2d(fractionally-strided convolutions)nn.ConvTranspose2d的参数output_padding的作用torch.nn.ConvTranspose2d Explained 基础概念 逆卷…...

酒精和肠内外健康:有帮助还是有害?
谷禾健康 酒精与健康 饮酒作为一种特殊的文化形式,在我们国家有其独特的地位,在几千年的发展中,酒几乎渗透到日常生活、社会经济、文化活动之中。 据2018年发表的《中国饮酒人群适量饮酒状况》白皮书数据显示,中国饮酒人群高达6亿…...

SylixOS Shell下操作环境变量方法
系统启动后会在内核中生成一份默认的环境变量,环境变量名和默认值由源程序决定。系统启动后如果文件系统中存在有效的/etc/profile文件,则还会自动读取文件中的内容,并导入到Shell环境中,覆盖对应变量或增加新的变量。程序运行时&…...
【dfs解决分组问题-两道例题——供佬学会!】(A元素是放在已经存在的组别中,还是再创建一个更好?--小孩子才做选择,dfs直接两种情况都试试)
问题关键就是: 一个点,可能 新开一个组 比 放到已经存在的组 更划算 因为后面的数据,我们遍历之前的点时,并不知道 所以我们应该针对每个点,都应该做出一个选择就是 新开一个元组或者放到之前的元组中,都尝…...
使用Hexo在Github上搭建个人博客
使用Hexo在Github上搭建个人博客 1. 安装Node和git2. 安装Hexo3. Git与Github的准备工作4. 将Hexo部署到Github5. 开始写作 1. 安装Node和git 在Mac上安装Node.js可以使用Homebrew,使用以下命令安装: brew install node使用以下命令安装Git: …...

【面试题】面试官:说说你对 CSS 盒模型的理解
前言 CSS 盒模型是 CSS 基础的重点难点,因此常被面试官们拿来考察候选人对前端基础的掌握程度,这篇文章将对 CSS 盒模型知识点进行全面的梳理。 我们先看个例子:下面的 div 元素的总宽度是多少呢? js <!DOCTYPE html> &…...

HFSS仿真结果怎么看?一文读懂S参数与电场图,让你的T型波导分析不再迷茫
HFSS仿真结果深度解析:从S参数到电场图的工程实践指南面对HFSS仿真生成的复杂数据图表,许多工程师常陷入"看得见数据却读不懂含义"的困境。本文将带您穿透数据表象,掌握T型波导性能分析的核心方法论。1. S参数:波导性能…...

告别浪费!SolidWorks企业级共享方案,实现降本增效全攻略
还在为 SolidWorks 高昂的硬件投入和混乱的图纸管理头疼?告别“一人一机”的浪费模式,企业级共享方案才是降本增效的正解。这套攻略基于“1 台高性能服务器 云飞云共享云桌面”架构,帮你把硬件成本砍掉 60%,把软件利用率翻倍。一…...

FT231XQ USB串口桥接板设计解析与实战应用指南
1. 项目概述:从FT232R到FT231XQ的USB串口桥接板演进在嵌入式开发和硬件调试的日常工作中,一个可靠、小巧且功能清晰的USB转串口(UART)桥接板(Breakout Board, 简称BoB)几乎是工程师手边的标配工…...

孤舟笔记 互联网常用框架篇三 Dubbo是如何动态感知服务下线的?注册中心和服务端双保险
文章目录先说结论机制一:注册中心通知机制二:心跳检测机制三:连接事件感知机制四:定时拉取四种机制的协作回答技巧与点评加分回答面试官点评个人网站微服务环境下,服务实例随时可能上下线——重启、扩容、宕机……调用…...

Web渗透测试能力成长地图:从工具使用到漏洞认知跃迁
1. 这不是工具清单,而是一张Web渗透测试的“能力成长地图”你刚点开这篇文章,大概率正站在两个路口之间:一边是网上铺天盖地的“十大免费扫描器推荐”,点进去全是截图下载链接一句“一键扫漏洞”,结果装完跑两下&#…...

OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心
OmenSuperHub:释放惠普游戏本性能的纯净开源控制中心 【免费下载链接】OmenSuperHub Control Omen laptop performance, fan speeds, and keyboard lighting, and unlock power limits. 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为官方…...

基于Cynthion逆向USB协议,为DP100电源开发Linux控制软件
1. 项目概述:用Cynthion嗅探USB,为DP100电源打造Linux软件作为一名长期在Linux环境下折腾硬件和嵌入式开发的爱好者,我经常遇到一个头疼的问题:很多不错的桌面小设备,比如电源、示波器、逻辑分析仪,它们的官…...

AI算法工程师如何进行模型部署?这2个工具+3个技巧,快速上线
对于软件测试从业者来说,模型部署并不是一个陌生的概念——随着AI功能逐渐渗透到各类应用软件中,测试工程师不仅需要验证模型输出的准确性,更需要理解部署流程对模型稳定性、响应速度和结果一致性的影响。很多测试同学会有这样的困惑…...

CMSIS-DAP调试器原理与应用:以Elektor mbed interface为例
1. 项目概述:Elektor mbed interface [150554] 是什么?如果你玩过ARM Cortex-M系列的单片机,尤其是NXP LPC800系列,那你可能对“CMSIS-DAP”这个调试器标准不陌生。它是由ARM官方推出的一个开源调试接口标准,最大的好处…...

基于EMA与轻量级机器学习的Wi-Fi链路质量预测实战
1. 项目概述与核心价值在工业自动化、仓储物流和智能制造等场景里,无线网络的稳定性正变得前所未有的重要。想象一下,一个自动导引运输车(AGV)正在执行物料搬运任务,或者一个机械臂正在与中央控制系统进行实时数据同步…...