【计算机视觉】如何利用 CLIP 做简单的人脸任务?(含源代码)
文章目录
- 一、数据集介绍
- 二、源代码 + 结果
- 三、代码逐行解读
一、数据集介绍
CELEBA 数据集(CelebFaces Attributes Dataset)是一个大规模的人脸图像数据集,旨在用于训练和评估人脸相关的计算机视觉模型。该数据集由众多名人的脸部图像组成,提供了丰富的人脸属性标注信息。
以下是 CELEBA 数据集的一些详细信息:
- 规模:CELEBA 数据集包含超过 20 万张名人的脸部图像样本。
- 图像内容:数据集中的图像涵盖了各种不同种族、年龄、性别、发型、妆容等的人脸图像,以提供更广泛的人脸表征。
- 标注信息:除了图像本身,CELEBA 数据集还提供了一系列的属性标注信息。这些属性包括性别、年龄、眼镜、微笑等。每个图像都有对应的二进制属性标签,用于指示该图像是否具有某个属性。
- 数据集组织:CELEBA 数据集的图像以 JPEG 格式存储,并使用标注文件进行关联。标注文件( list_attr_celeba.txt )包含每个图像的文件名及其相关属性标签。
- 应用领域:CELEBA 数据集被广泛用于人脸属性识别、人脸检测、人脸生成、人脸识别等计算机视觉任务的研究和开发。
CELEBA 数据集的丰富性和规模使其成为人脸相关算法的重要基准数据集之一。研究人员和开发者可以利用该数据集来训练和评估人脸相关的深度学习模型,推动人脸识别、人脸属性分析等领域的进展。
需要注意的是,CELEBA 数据集的具体细节和使用方式可能会有更新和改变。建议在使用数据集时查阅最新的文档和数据集发布者的说明。
CELEBA 数据集每一部分的解释和名称如下:
CELEBA 数据集由多个部分组成,每个部分包含不同的信息和用途。以下是 CELEBA 数据集的一些主要部分及其解释和名称:
- 图像文件夹(img_align_celeba):该部分包含了 CELEBA 数据集的人脸图像文件,以 JPEG 格式存储。图像文件夹通常包含大量的人脸图像,用于进行人脸相关任务的训练、测试和评估。
- 标注文件(list_attr_celeba.txt):该部分是 CELEBA 数据集的属性标注文件,它提供了每个图像的属性信息。属性标注文件是一个文本文件,包含了图像文件名及其对应的属性标签。这些属性标签描述了图像中的人脸属性,例如性别、年龄、微笑、眼镜等。
- 划分文件(list_eval_partition.txt):这个部分是 CELEBA 数据集的划分文件,用于将数据集划分为训练集、验证集和测试集。划分文件是一个文本文件,包含了每个图像的文件名及其所属的划分集合。
- 人脸边界框文件(list_bbox_celeba.txt):这个部分包含了 CELEBA 数据集中每个图像的人脸边界框信息。人脸边界框文件是一个文本文件,包含了每个图像的文件名以及对应的人脸边界框的坐标信息。
- 人脸关键点文件(list_landmarks_celeba.txt):这个部分包含了 CELEBA 数据集中每个图像的人脸关键点信息。人脸关键点文件是一个文本文件,包含了每个图像的文件名以及对应的人脸关键点的坐标信息。
这些部分是 CELEBA 数据集中常用的部分,用于获取图像、属性标注、划分信息以及人脸边界框和关键点信息。使用这些部分的数据,可以进行各种人脸相关任务的训练、评估和分析。
二、源代码 + 结果
import clip
import torch
import torchvision
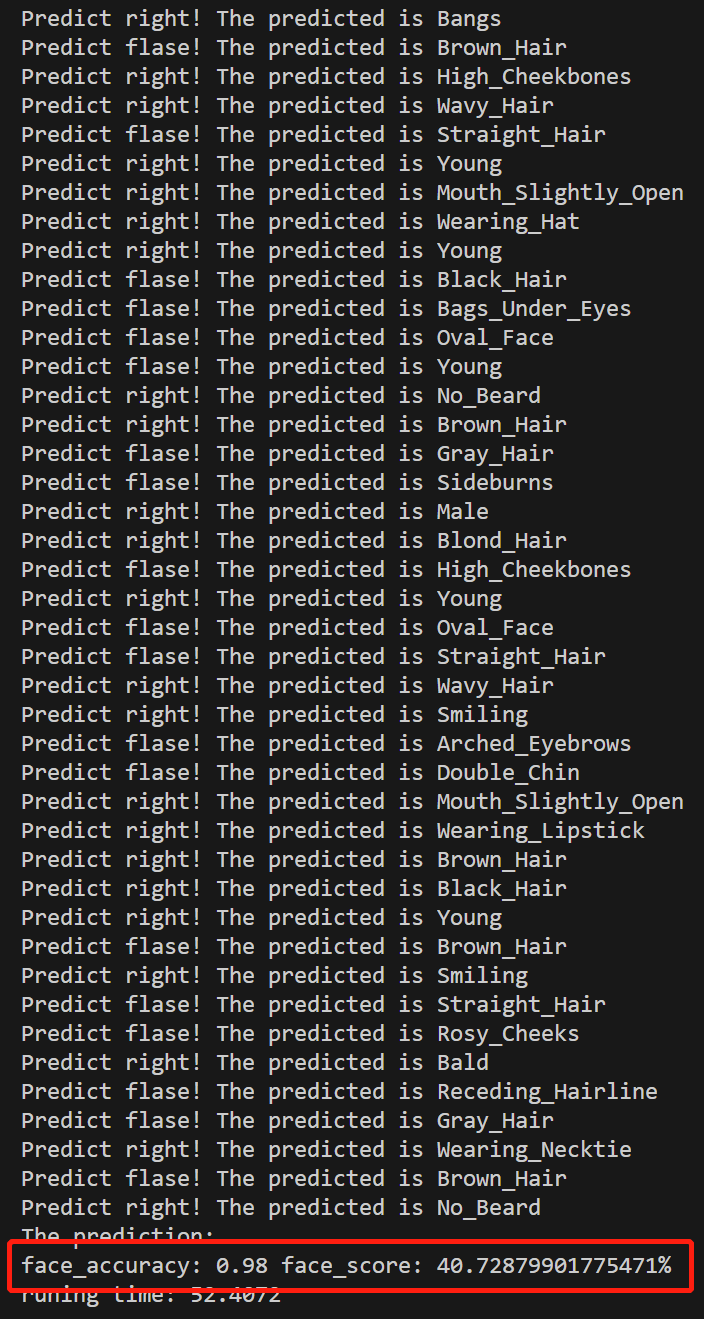
import timedevice = "cuda" if torch.cuda.is_available() else "cpu"def model_load(model_name):# 加载模型model, preprocess = clip.load(model_name, device) #ViT-B/32 RN50x16return model, preprocessdef data_load(data_path):# 加载数据集和文字描述celeba = torchvision.datasets.CelebA(root = './39.AIGC/CELEBA', split = 'test', download = True)text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in celeba.attr_names]).to(device)return celeba, text_inputsdef test_model(start, end, celeba, text_inputs, model, preprocess):# 测试模型length = end - start + 1face_accuracy = 0face_score = 0for i, data in enumerate(celeba):face_result = 0if i < start:continueimage, target = dataimage_input = preprocess(image).unsqueeze(0).to(device)with torch.no_grad():image_features = model.encode_image(image_input)text_features = model.encode_text(text_inputs)image_features /= image_features.norm(dim = -1, keepdim = True)text_features /= text_features.norm(dim = -1, keepdim = True)text_probs = (100.0 * image_features @ text_features.T).softmax(dim = -1)top_score, top_label = text_probs.topk(6, dim = -1)for k, score in zip(top_label[0], top_score[0]):if k.item() < 40 and target[k.item()] == 1:face_result = 1face_score += score.item()print('Predict right! The predicted is {}'.format(celeba.attr_names[k.item()]))else:print('Predict flase! The predicted is {}'.format(celeba.attr_names[k.item()]))face_accuracy += face_resultif i == end:breakface_score = face_score / lengthface_accuracy = face_accuracy / lengthreturn face_score, face_accuracyif __name__ == '__main__':start = 0end = 1000model_name = 'ViT-B/32'data_path = 'CELEBA'time_start = time.time()model, preprocess = model_load(model_name)celeba, text_inputs = data_load(data_path)face_score, face_accuracy = test_model(start, end, celeba, text_inputs, model, preprocess)time_end = time.time()print('The prediction:')print('face_accuracy: {:.2f} face_score: {}%'.format(face_accuracy, face_score * 100))print('runing time: %.4f' % (time_end - time_start))
三、代码逐行解读
import clip
import torch
import torchvision
import time
这段代码导入了 clip、torch、torchvision 和 time 库。这些库提供了用于计算机视觉和深度学习任务的功能和工具。
- clip 是一个用于视觉和文本数据的深度学习模型库,可以将图像和文本进行编码和匹配。
- torch 是 PyTorch 库,提供了张量操作、神经网络模型、优化器等工具。
- torchvision 是 PyTorch 的一个扩展库,提供了常用的计算机视觉数据集、模型架构和图像处理工具。
- time 是 Python 标准库,提供了计时和时间相关的函数。
device = "cuda" if torch.cuda.is_available() else "cpu"
这行代码用于选择设备(device),可以是 CUDA 加速的 GPU 设备或者 CPU 设备。它使用了条件表达式(if-else)来检查系统是否有可用的 CUDA 设备。如果有可用的 CUDA 设备,将设备设置为 “cuda” ;否则,将设备设置为 “cpu”。
def model_load(model_name):# 加载模型model, preprocess = clip.load(model_name, device) #ViT-B/32 RN50x16return model, preprocess
这个函数用于加载 CLIP 模型和预处理函数。
具体解读如下:
- model_load 是一个函数,接受一个 model_name 参数作为输入。
- 在函数内部,调用了 clip.load(model_name, device) 来加载 CLIP 模型和预处理函数。 model_name 指定了要加载的 CLIP 模型的名称,device 指定了要在哪个设备上加载模型(之前定义的 device 变量)。
- clip.load() 函数返回一个模型对象和一个预处理函数对象。
- 最后,函数将加载的模型对象和预处理函数对象作为结果返回。
def data_load(data_path):# 加载数据集和文字描述celeba = torchvision.datasets.CelebA(root = './39.AIGC/CELEBA', split = 'test', download = True)text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in celeba.attr_names]).to(device)return celeba, text_inputs
这个函数用于加载数据集和生成与数据集相关的文字描述。
- data_load 是一个函数,接受一个 data_path 参数作为输入。
- 在函数内部,调用了 torchvision.datasets.CelebA 来加载 CelebA 数据集。root 参数指定了数据集的根目录路径,split 参数指定了要加载的数据集划分(这里使用的是测试集),download 参数指定了是否下载数据集(设为 True 表示下载)。
- 在加载 CelebA 数据集后,通过遍历 celeba.attr_names 中的每个属性名称,使用 clip.tokenize() 函数生成与属性名称相关的文字描述,并使用 torch.cat() 函数将这些描述连接起来。最终,得到的文字描述张量被转移到指定的设备上(之前定义的 device 变量)。
- 最后,函数将加载的数据集对象和生成的文字描述张量作为结果返回。
def test_model(start, end, celeba, text_inputs, model, preprocess):# 测试模型length = end - start + 1face_accuracy = 0face_score = 0for i, data in enumerate(celeba):face_result = 0if i < start:continueimage, target = dataimage_input = preprocess(image).unsqueeze(0).to(device)with torch.no_grad():image_features = model.encode_image(image_input)text_features = model.encode_text(text_inputs)image_features /= image_features.norm(dim = -1, keepdim = True)text_features /= text_features.norm(dim = -1, keepdim = True)text_probs = (100.0 * image_features @ text_features.T).softmax(dim = -1)top_score, top_label = text_probs.topk(6, dim = -1)for k, score in zip(top_label[0], top_score[0]):if k.item() < 40 and target[k.item()] == 1:face_result = 1face_score += score.item()print('Predict right! The predicted is {}'.format(celeba.attr_names[k.item()]))else:print('Predict flase! The predicted is {}'.format(celeba.attr_names[k.item()]))face_accuracy += face_resultif i == end:breakface_score = face_score / lengthface_accuracy = face_accuracy / lengthreturn face_score, face_accuracy
这个函数用于测试模型的性能。
- test_model 是一个函数,接受 start、end、celeba、text_inputs、model 和 preprocess 作为输入。
- 在函数内部,首先初始化一些变量,包括 length(表示要处理的图像数量)、face_accuracy(用于记录人脸识别的准确率)和 face_score(用于记录人脸识别的得分)。
- 然后,使用 enumerate(celeba) 遍历 CelebA 数据集,其中i表示当前迭代的索引,data 表示当前迭代的数据。
- 在每次迭代中,首先将 face_result 初始化为 0。然后,通过 data 获取当前图像和目标标签。
- 接下来,将图像输入预处理函数 preprocess 进行预处理,并通过 unsqueeze(0) 在批次维度上添加一个维度。然后将处理后的图像输入到模型中,分别使用 model.encode_image() 和 model.encode_text() 来获取图像特征和文字特征。
- 对于图像特征和文字特征,进行归一化处理,将每个特征向量除以其范数,以使其长度为 1。
- 使用归一化后的特征计算图像特征与文字特征之间的相似度,通过矩阵乘法和 softmax 操作得到预测的文本概率分布 text_probs。
- 接下来,使用 topk() 函数获取预测概率最高的 6 个标签,并遍历每个标签和对应的得分。
- 如果预测的标签索引小于 40 且目标标签中对应索引的值为 1(表示该属性为真),则将 face_result 设置为 1,并将得分累加到 face_score 中,同时打印预测正确的信息;否则,打印预测错误的信息。
- 最后,将 face_result 累加到 face_accuracy 中,判断是否达到了指定的结束索引 end,如果是,则终止循环。
- 计算平均得分和平均准确率,并将其作为结果返回。
总的来说,这个函数的作用是对模型进行测试,并计算人脸识别的平均得分和平均准确率。在测试过程中,它遍历 CelebA 数据集中的图像,计算图像与文字特征之间的相似度,并根据预测的结果评估模型的性能。
if __name__ == '__main__':start = 0end = 1000model_name = 'ViT-B/32'data_path = 'CELEBA'time_start = time.time()model, preprocess = model_load(model_name)celeba, text_inputs = data_load(data_path)face_score, face_accuracy = test_model(start, end, celeba, text_inputs, model, preprocess)time_end = time.time()print('The prediction:')print('face_accuracy: {:.2f} face_score: {}%'.format(face_accuracy, face_score * 100))print('runing time: %.4f' % (time_end - time_start))
这段代码是整个程序的入口点,它实现了整个流程的控制和输出结果。
- if name == ‘main’:是 Python 中的条件语句,表示当该脚本被直接运行时(而不是作为模块导入时),以下的代码块将被执行。
- 在该代码块中,首先定义了一些变量,包括 start(开始索引)、end(结束索引)、model_name(模型名称)和 data_path(数据集路径)。
- 通过 time.time() 获取当前时间,将其记录为 time_start,以便后续计算程序的运行时间。
- 调用 model_load(model_name) 函数加载指定名称的模型,并将返回的 model 和 preprocess 赋值给 model 和 preprocess 变量。
- 调用 data_load(data_path) 函数加载数据集,并将返回的 celeba 和 text_inputs 赋值给 celeba 和 text_inputs 变量。
- 调用 test_model(start, end, celeba, text_inputs, model, preprocess) 函数对模型进行测试,获取人脸识别的得分和准确率,分别赋值给 face_score 和 face_accuracy 变量。
- 通过 time.time() 获取当前时间,将其记录为 time_end,以便计算程序的运行时间。
- 使用 print() 函数输出预测结果,包括人脸准确率、人脸得分和运行时间。
总的来说,该部分代码是整个程序的入口,它负责加载模型、加载数据集、测试模型并输出结果。通过设定的参数对模型进行测试,并打印出人脸识别的准确率、得分和程序运行时间。
相关文章:
【计算机视觉】如何利用 CLIP 做简单的人脸任务?(含源代码)
文章目录 一、数据集介绍二、源代码 结果三、代码逐行解读 一、数据集介绍 CELEBA 数据集(CelebFaces Attributes Dataset)是一个大规模的人脸图像数据集,旨在用于训练和评估人脸相关的计算机视觉模型。该数据集由众多名人的脸部图像组成&a…...

基于显扬科技3D视觉相机的医疗试管分拣系统
行业现状: 医疗试管分拣是医疗行业中的一个重要环节,指将医疗实验室或生物技术研究中的试管按照一定的规则进行分拣,并对试管的类型、位置、数量等信息进行识别和管理。 随着医疗技术的不断发展和诊断治疗的精细化,医疗试管分拣…...
编译zlib
zlib被设计为一个免费的,通用的,法律上不受限制的-即不受任何专利保护的无损数据压缩库,几乎可以在任何计算机硬件和操作系统上使用。 官网:http://www.zlib.net/ 下载zlib源码:http://www.zlib.net/zlib1213.zip 备用地址&#x…...

如何让“ChatGPT自己写出好的Prompt的“脚本在这里
写个好的Prompt太费力了 在网上,你可能会看到很多人告诉你如何写Prompt,需要遵循各种规则,扮演不同的角色,任务明确、要求详细,还需要不断迭代优化。写一个出色的Prompt需要投入大量的时间和精力。甚至有一些公开的Pr…...

菜单选择shell
[rootes3 data]# vi action.sh #!/bin/bash . /etc/init.d/functionsecho -en "\E[$[RANDOM%731];1m"cat <<EOF请选择:1) 备份数据库2)清理日志3)软件升级4)软件回滚5)删库跑路EOFecho -en \E[0mread -p "请选择上面的项对应的数字1-5…...
Redis高可用性详解
目录 编辑 高可用性: 主从复制(Master-Slave Replication): 主从复制的一般工作流程: 哨兵模式(Sentinel Mode): 哨兵模式的一般工作流程: 集群模式(…...
MySQL(1) ---- 数据库介绍与MySQL概述
介绍 1、什么是数据库? 数据库:DateBase(DB),是存储和管理数据的仓库。数据库管理系统:DataBase Management System(DBMS),操纵和管理数据库的大型软件。SQL࿱…...

面试题之软件测试流程
说说公司的软件测试流程,这,是常考的面试题之一。 不同公司的流程不一样,现状决定流程,没有绝对的对错。 以结果为导向,保证产品质量,提高测试效率,才是王道。 以下的流程为业界比较标准的流程&…...

MyBatis中#{}与${}的区别,与各自的应用场景
#{}和${}的区别: #{}: 底层使用PreparedStatement。特点:先进行SQL语句的编译,然后给SQL语句的占位符问号?传值。可以避免SQL注入的风险。 ${}:底层使用Statement。特点:先进行SQL语句的拼接,然后再对SQL语…...

泛型类相关
package com.test.test02;/* * GenericTest就是一个普通的类 * GenericTest<E>就是一个泛型类 * <>里面就是一个参数类型,但是这个类型是什么呢?这个类型现在是不确定的,相当于一个占位。 * 但是现在确定的是这个类型一定是一…...

一文速学数模-季节性时序预测SARIMA模型详解+Python实现
目录 前言 一、季节时间序列模型概述 二、SARIMA模型定义 三.SARIMA模型算法原理...
)
二叉树与图(C++刷题笔记)
二叉树与图(C刷题笔记) 113. 路径总和 II 力扣 从根节点深度遍历二叉树,先序遍历时,将节点存储至path栈中,使用path_val累加节点值 当遍历到叶子节点,检查path_val是否为sum,若是,…...
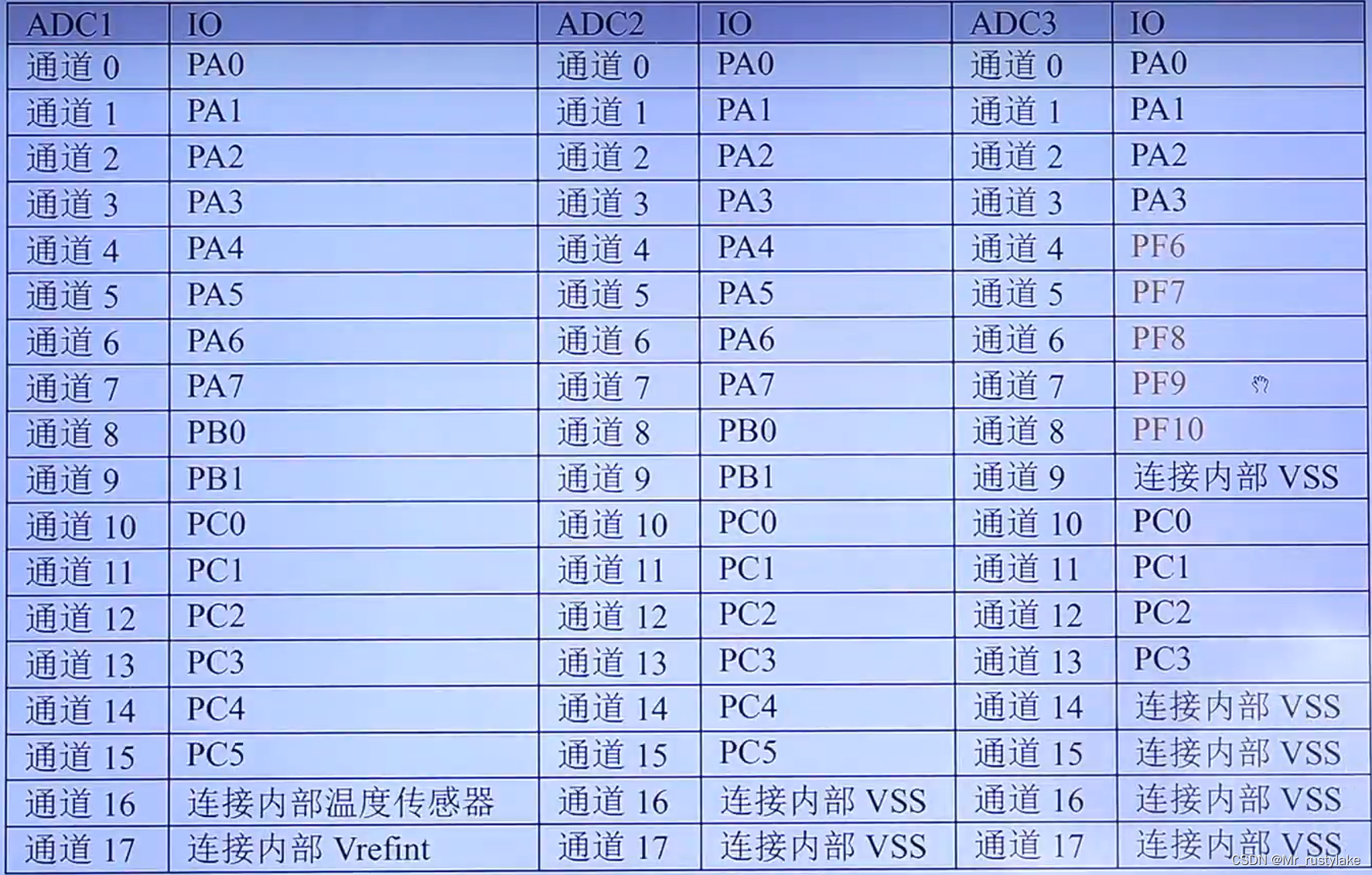
STM32-ADC多通道输入实验
之前已经介绍了几个ADC的笔记和实验了,链接如下: 关于ADC的笔记1_Mr_rustylake的博客-CSDN博客 STM32-ADC单通道采集实验_Mr_rustylake的博客-CSDN博客 STM32-单通道ADC采集(DMA读取)实验_Mr_rustylake的博客-CSDN博客 接下来…...
javaIO流之文件流
目录 简介一、File的构造方法二、File的常用方法1、获取功能的方法2、绝对路径和相对路径3、判断功能的方法4、创建、删除功能的方法5、目录的遍历6、递归遍历 三、RandomAccessFile1、主要方法 四、Apache FileUtils 类1、复制文件或目录:2、删除文件或目录&#x…...

DMA-STM32
DMA-STM32 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设和存储器或者存储器和存储器之间的高速数据传输,无须CPU干预,节省了CPU的资源 12个独立可配置的通道:DMA1 (7个通道),DMA2 (5个通道) 每个通道都支持软件触发和特定的硬件触发 STM32…...

代码随想录算法训练营第二十七天|39. 组合总和、40.组合总和II、131.分割回文串
目录 39. 组合总和 40.组合总和II 131.分割回文串 39. 组合总和 本题是 集合里元素可以用无数次,那么和组合问题的差别 其实仅在于 startIndex上的控制 题目链接/文章讲解:代码随想录 视频讲解:带你学透回溯算法-组合总和(对应…...
 <? extends T>,<? super T>)
泛型(Generic) <? extends T>,<? super T>
通配符边界引入背景 使用泛型的过程中,经常出现一种很别扭的情况。我们有 Fruit 类,和它的派生类 Apple 类。 class Fruit {}class Apple extends Fruit {}然后有一个最简单的容器:Plate 类。盘子里可以放一个泛型的 “东西”. class Plat…...

数云融合|数字化转型中的利器:揭秘云技术的重要角色
数字化转型不仅是一个流行语,而是一项真正能够改变你的业务流程并提高客户参与度的重要战略。要实现数字化转型,必须重新构建业务流程,同时利用AI、物联网、AR、ML、大数据分析等先进技术不断提升客户参与度。这就需要利用云技术提供的强大计…...

Linux篇2
Linux 0. 终端提示信息1. 文件目录结构1.1 文件目录 2. 文本编辑器VI/VIM2.1 VIM编辑器2.1 一般模式2.2 编辑模式2.3 命令模式 3. 网络配置3.1 VMware提供的三种网络连接模式3.2 静态配置网络IP地址3.3 配置主机名3.3.1 修改主机名3.3.2 配置主机名-IP地址映射关系:…...
《微服务实战》 第九章 Gitlab使用
前言 微服务项目,常常需要多人协作完成工作,本章教程是介绍Gitlab使用,使多人协作告别低端的手动拷贝,也告别传统的SVN。 1、下载安装git https://git-scm.com/download/win 1.1、安装好以后,cmd中输入git 2、生成ssh-key ssh-keygen -t rsa -C “zhangsan@163.com”…...

Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器
Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经在MacBook的触控板和鼠标之间切换时࿰…...

FT231XQ USB串口桥接板设计解析与实战应用指南
1. 项目概述:从FT232R到FT231XQ的USB串口桥接板演进在嵌入式开发和硬件调试的日常工作中,一个可靠、小巧且功能清晰的USB转串口(UART)桥接板(Breakout Board, 简称BoB)几乎是工程师手边的标配工…...

【深度解析】AI Coding 模型竞速:从 Claude Mythos 安全编码到 GPT-5.6 传闻,如何落地代码审查智能体
摘要 AI 编码模型正在从“代码补全”进入“复杂代码库理解、漏洞发现与自动修复”阶段。本文结合 Claude Mythos、Claude Opus 4.8 与 GPT-5.6 相关信息,解析新一代 Coding Agent 的技术趋势,并给出基于大模型 API 的代码安全审查实战方案。背景介绍&…...
)
保姆级避坑指南:在Ubuntu 22.04上搞定ROS2 Humble、PX4与Gazebo的联合仿真(附Empy版本降级)
保姆级避坑指南:Ubuntu 22.04下ROS2 Humble与PX4联合仿真的21个关键陷阱当你在Ubuntu 22.04上第一次尝试搭建ROS2 Humble、PX4与Gazebo的联合仿真环境时,可能会遇到比预期更多的挑战。这不是一个简单的"复制粘贴命令就能完成"的任务——版本冲…...

5个必知的Universal-Updater高级功能:从QR扫描到后台安装
5个必知的Universal-Updater高级功能:从QR扫描到后台安装 【免费下载链接】Universal-Updater An easy to use app for installing and updating 3DS homebrew 项目地址: https://gitcode.com/gh_mirrors/un/Universal-Updater Universal-Updater是一款专为任…...

PCB的常规机械通孔与HDI工艺钻孔差异
结合常规 4 层通孔 PCB(非 HDI) 标准制程,分步骤讲清钻孔时机、先后顺序,区分机械通孔与板件结构,专业且贴合工厂实际流程。一、先明确 4 层通孔板基础结构4 层板结构:L1 → PP 半固化片 → L2/L3ÿ…...

通过用量看板分析团队大模型API消耗发现优化调用策略的机会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板分析团队大模型API消耗发现优化调用策略的机会 作为团队的技术负责人,确保大模型API调用在满足业务需求的…...

保姆级教程:在Windows 10上用QEMU+Kylin搭建可内外网访问的完整开发环境
在Windows 10上构建QEMUKylin全功能开发环境的终极指南当开发者需要在本地快速搭建一个隔离的国产操作系统开发环境时,QEMU虚拟化方案配合银河麒麟系统能提供高度灵活的沙箱体验。本文将手把手带你完成从零配置到内外网联通的完整工作流,涵盖虚拟化环境部…...

AhMyth位置跟踪:GPS定位与地理围栏技术深度解析
AhMyth位置跟踪:GPS定位与地理围栏技术深度解析 【免费下载链接】AhMyth Cross-Platform Android Remote Administration Tool | The only maintained version of AhMyth on github | A revival of the original repository at https://GitHub.com/AhMyth/AhMyth-An…...

京东自动购物终极指南:告别缺货烦恼,智能抢购神器
京东自动购物终极指南:告别缺货烦恼,智能抢购神器 【免费下载链接】Jd-Auto-Shopping 京东商品补货监控及自动下单 项目地址: https://gitcode.com/gh_mirrors/jd/Jd-Auto-Shopping 还在为心仪商品瞬间售罄而苦恼吗?还在熬夜等待补货却…...