聊一聊,我对DDD的关键理解
作者:闵大为 阿里业务平台解决方案团队
当我们在学习DDD的过程中,感觉学而不得的时候,可能会问:我们还要学么?这的确引人深思。本文基于工作经验,尝试谈谈对DDD的一些理解。
一、序
《阿甘正传》中,阿甘开始了不停地跑步,一段时间后,后面就有了很多追随者一起跑,他们为什么跑呢?
-
阿甘:我也不知道,只是想跑而已。
-
追随者:感觉这样做是有意义的,而且阿甘也还在前面领跑。
类似地,一开始我也不知道DDD是什么,但当发现大家都在提DDD、都在学DDD的时候,我也像跟跑者一样不由自主地加入了前行:既然有大牛提出了DDD,既然那么多人趋之若鹜,那么肯定有可取的地方。
然而,有一天,阿甘停止了跑步,他不想跑了,追随者遇到了一个问题:我们还要跑么?当我们在学习DDD的过程中,感觉学而不得的时候,可能也会问:我们还要学么?这的确引人深思。
本文基于工作经验,尝试谈谈对DDD的一些理解,希望能够更好地探寻学习DDD的意义。
二、关注DDD的价值
无论做业务,还是做平台、中台,大家常常会被交错复杂的业务逻辑、晦涩耦合的业务代码搞得心力交瘁。我想,大家对DDD的追求,也是对轻松支撑业务发展的诉求,在探寻有没有合适的理论可以改善现状。毕竟,美好生活,共同向往。
2.1 现状:分层支撑机制
我们选择各种框架、进行各种组织设计,核心是为了提高生产效率。但如果业务逻辑都是case by case地进行实现、缺少复用,那么研发成本是非常高的、投入周期也会非常长。
为了增加复用、缩短业务的落地时间,就需要很多通用的能力、产品。在我们的交付过程中,主要有两个层次:
-
基础能力:相对原子的能力是基础(域)能力,这个可以较好地支持业务定制。由于比较基础,表达的产品能力范围也是很大的。但是,一个完善的产品需要串联的基础能力是非常多的,串联的成本也是非常高的。
-
平台产品:基础能力的通用性,意味着缺少对场景的理解,缺少了进一步提升生产效率的“基因”。所以在交付的时候,会基于一些高频场景进行抽象,形成平台的产品能力,争取做到“拆箱即用”。业务基于“平台产品”这层进行定制的时候,理解成本会大大减少。
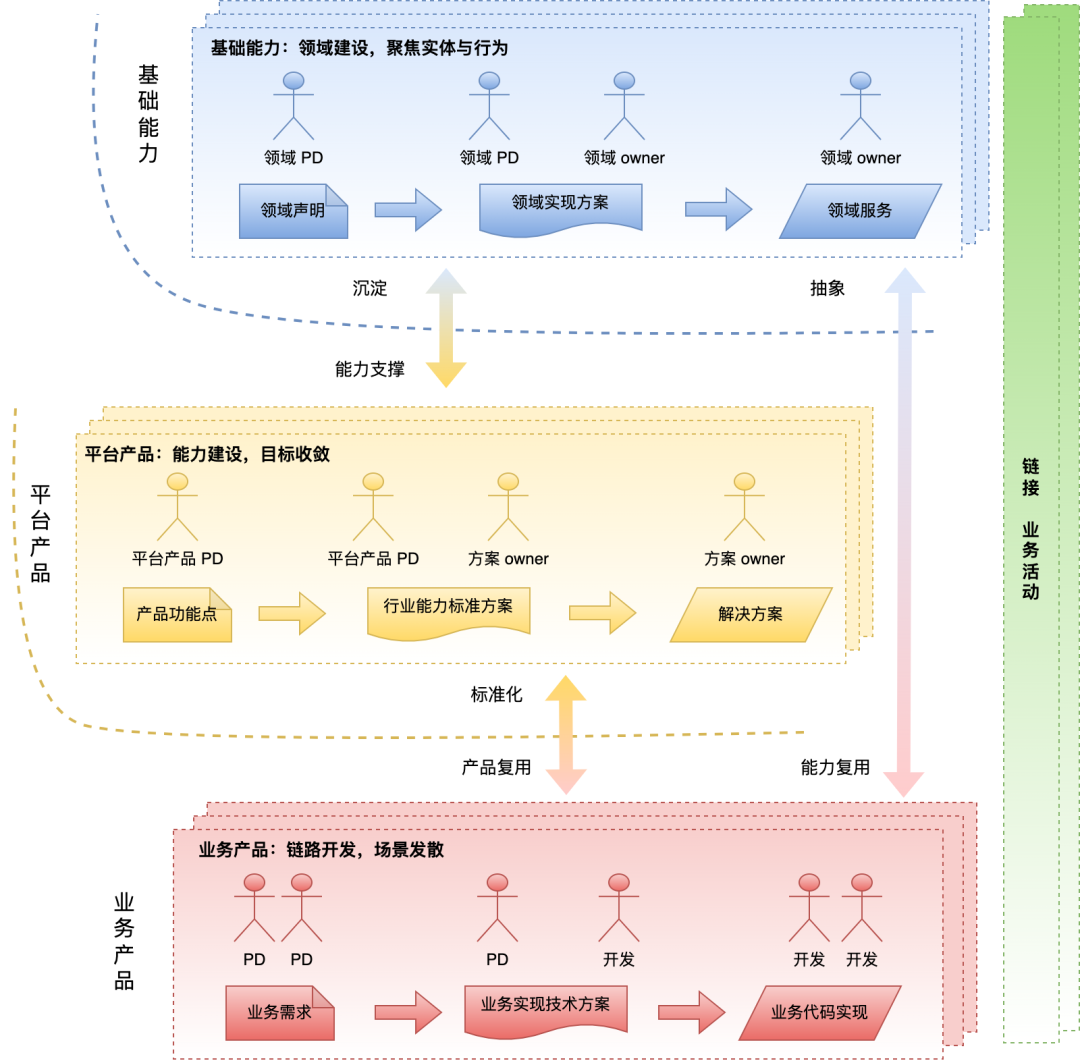
分层支撑框架
2.2 腐化:业务逻辑渗透
这样的层次,看上去很美好:在起步阶段,由于缺少历史包袱,的确可以提升一定的生产效率,这是能力本身的收益。但是,越往后,随着业务接入的增多,业务之间开始互相影响,研发的阻力也越来越大。
研发效能降低的重要原因在于:更多的时候,我们还是按照“业务能跑起来,怎么快怎么来“的逻辑去做相关工作,遇水搭桥,遇山开洞,然后直达目的地,进行信息的传达、数据库字段的操作。
这样的过程,违背了我们”希望通过业务场景,丰富平台能力,同时保证内核干净“的初衷。能力应该是基于相对多的用例、相对完善的思考进行抽象,是横向统一看,有更深刻的理解,但是垂直的交付,让我们更加纵向地处理问题,往往只是“窥探”了链路,在交付时长和业务节点的限制下,很难想得更加全面、深刻,难以做出更通用的设计。
2.3 抵御:平台框架守卫
那么,为什么关注DDD?如果说DDD直击了软件复杂度的核心——“问题域”,那可能还是比较抽象。具体来说,因为这的确符合我们追求的价值观【提升长期的生产效率】:
-
细分领域,培养专业的人、事:因为DDD的核心是要求让各个领域做好理解和封装,把一个业务需求拆解、安放在各自合理的地方,通过这样的分解与沉淀,保证了领域的输入,能够得到长期可持续的发展,形成竞争力。
-
机制保障,不依赖易变的事物:DDD其实在总结很多通用的技巧和经验,能够让这样的实施更具有确定性。无论是聚合根对领域实体的管控能力、限界上下文的交互策略、领域内核的抽象地位...等等,一旦选择尊奉,确定下来,就能够落在代码结构、组织关系、团队文档中,形成共识,不会因为人员等因素的变化而剧烈波动。
对DDD的关注,可以类比于我们对“工匠精神”的关注,对DDD的重视,也是我们对业务理解的重视。贴近业务,更要理解业务,不仅要理解业务,更需要理解大多数的业务。这样的追求,让我们往上看了一个层次,回归了最本质的问题:我们要解决什么问题?如何能够解决得更好?
三、学习DDD的困难
不知道大家是否有这样困惑:DDD的学习过程好像是”大海捞针“的过程。即使能够捞到点东西,使用起来,还是会有种“东施效颦”的感觉,并不是很自然。为什么学习DDD那么困难呢?
3.1 感受:不得其门
论语中的下面这个场景,和我们的困惑是比较相似的:
叔孙武叔语大夫于朝曰:“子贡贤于仲尼。” 子服景伯以告子贡,子贡曰:“譬之宫墙,赐之墙也及肩,窥见室家之好;夫子之墙数仞,不得其门而入,不见宗庙之美、百官之富。得其门者或寡矣,夫子之云不亦宜乎!”
正如要感受到孔子达到的境界,自己的学问也需要有一定的积累。我们要感受到DDD的力量,自己本身就要成长到一定程度(如:经历了一些成功或者失败的设计,有自己的经验或者教训),才能形成共鸣和认同。
工作中,的确很少看到DDD的最佳实践。在复杂的业务面前,谁也没有勇气说,哪个软件结构是理想的设计:
-
因为这不是一个确定性的问题分解,你的设计会被放在显微镜下研究,总能找到各种反例。
-
而且,我们深知,最佳的实践,一定是做得足够的“软”,对扩展留有设计,能够随着业务发展而迭代,不是一个静态的结果。
因此,打开学习的大门不是几个案例就能一蹴而就的,需要结合我们自己的工作,慢慢累积、体会。
3.2 困难:模式发散
我们有一种困惑,到底怎么样算是DDD:
-
实践的个例,难以信服:当我们看到“DDD实践”的时候,可能会发问:这也算DDD?不就是一个正常的服务端框架与方案,也无法涵盖其它的场景或者部门系统。
-
抽象的理论,觉得空洞:当我们看到“抽象的DDD定义与策略”的时候,可能会发问:这也算DDD?不就是一些软件设计的共识,然后强加了一些名词定义,有些策略与我们手上的系统也并不匹配。
无论往抽象看,还是往具体实现看,都很难找到令人信服的理论与实践(能够有确定性的落地能力)。因为这不像23个设计模式那样,可以通过N个模版就能涵盖大多数的模式。
为什么不能产生特定的模式呢?可以结合下图进一步来看:
-
抽象理论:如同抽象的接口一样,“DDD理解”最上面的学习主要是理论定义,比如:聚合根、值对象、资源库、核心域、支撑域等各种定义,这些是易于理解掌握的。
-
通用实践:如同相对具体的抽象类一样,“DDD理解”中间层次是一些通用原则和技巧,比如:上下文的映射策略、架构的选择等。这些因素是确定的,但需要自主进行取舍与选择,并且需要与时俱进,增量的部分需要自己学习补充。
-
具体实践:如同具体的类实例一样,“DDD理解”中下面层次是一系列的具体实践,结合各自的业务场景,进行了不同因素的设计、取舍与补充。因为涉及的选项较多,造成最终的选择结果往往是发散的,令人感觉“千人千面”。
两者不同的地方是:
-
“代码抽象层次”中层次关系是比较明确的,且有约束。
-
“领域驱动理解层次”中无法提供明确的约束,都是多个策略的取舍、一些关键的建议。
因此,由于问题的抽象层次较高,各种策略的不确定性较高,很难在DDD中产生像“23个设计模式”那样精炼的模式。一定要有的话,也是一系列的模式,比较发散。
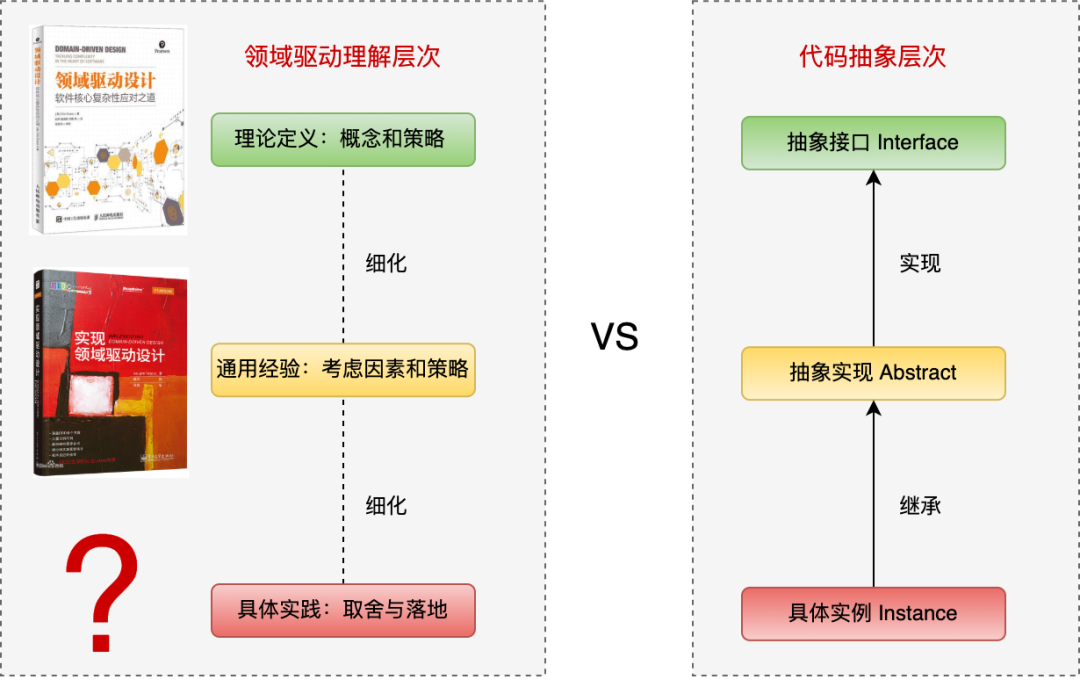
DDD理解层次的类比
因此,我们渐渐明白:DDD面向的是软件的“软”,涵盖方方面面。DDD的深入理解,需要“千锤百炼”后,才能明白那些深入简出的建议,才能体会那句“师傅领进门,修行靠个人”的箴言,才能感受到“众里寻他千百度,那人却在灯火阑珊处”的美妙瞬间。
四、基于设计原则看DDD
虽然DDD本身的实践可能千人千面,但是一些核心主题的思考应该是聚焦的,这些高频主题的理解,能让我们更好地进行设计,讨论的性价比也是较高的。接下来,会基于“6大设计原则”(solid 原则)为引子,去看看DDD中的一些关键理解。
4.1 单一职责原则:领域划分
单一职责是说:一个类应该只有一个发生变化的原因。职责的单一,可以更好地内聚,减少耦合,方便演化。
DDD里面的领域划分可以类比思考。对领域的划分,无论是按领域实体,还是按照功能模块,还是按照服务等划分,其实都想尽量保证领域的正交,能够独立演化和发展。

Single Responsibility Principle:单一职责原则
领域怎么切分比较合适?刚进入业务平台的时候,了解到领域切分是按“一个或多个实体对象”的边界来切分。这的确比较合理,因为领域的核心职责就是对领域实体进行管理。但这是果,还是因?在切分的时候,是因为我们有了对领域的判断,所以某些实体被分在一起比较合适;还是因为某些实体有明显边界,所以可以形成一个领域?就比如下面的图:
-
可以整体作为1个部分。
-
可以按竖着的正、负切分2个部分:上面1个(红),下面2个(黄、绿)。
-
可以按横轴的正、负切分2个部分:左边1个(黄),右边2个(红、绿)。
-
可以切分成3个部分(红、黄、绿)。

聚类的例子
这的确引入深思。切分比较容易的时候,往往是因为已经有了行业的标准(如:电商系统有订单、支付、物流、库存等领域是比较合理的)。那行业的标准来自哪里?是来自于演化:
-
开始的时候,可能只是一个大交易,比如:支付开始的时候只是买卖双方自己协议,也不需要建模。
-
后面支付发展了,也就独立出来一个域。原来不需要专人维护,后面会渐渐拉出一个团队来承接相关研发。
所以,领域的演化和划分,很类似“启发式算法”(一个基于直观或经验构造的算法,在可接受的花费下给出待解决组合优化问题每一个实例的一个可行解):
-
初始化:按照的经验初步的划分,也可以是行业标准(没有行业标准的时候,就只能靠经验了)。
-
花费评价:生产、交付过程的人力成本度量,关注理解成本、开发效率、系统稳定性、运维成本等因素。
-
更优解:在业务发展过程中,计算花费评价,分析影响评价的“好因素”、“坏因素”,进行进一步调整。
往往到最后,我们会发现:
-
调整的内容:其实是匹配生产关系。
-
调整的原则:追求职责的内聚,精细化分工。
-
不断调整的原因:业务在发展,内聚的标准也需要与时俱进。
此外,从关联的角度看,往往我们看组织架构,就能看到领域的边界,核心原因还是组织架构也是要适应生产关系,follow更优解的结构,是相辅相成的,也就能互相窥探。
4.2 开闭原则:实体行为
开闭原则是说:软件中的对象(类、模块、函数等)应该对于扩展是开放的,但是对于修改是封闭的。也就是说,对扩展区块是要有设计的,扩展的部分不应该影响稳定逻辑。
在DDD中,实体的行为,在保证对外封闭的情况下,也是需要考虑扩展能力的。

Open Closed Principle:开闭原则
在刚开始学习DDD的时候,我们可能会强行把一些逻辑放到实体中,进行控制和收敛。但后面随着业务的变化,会发现在实体中承担行为逻辑很难受:
-
影响较大:很难有勇气去频繁地修改一个核心类。
-
过于集中:随着方法和逻辑的增多,实体越来越臃肿。
-
场景较多:很多逻辑并不是正交的,不是if这样else那样的,充满着交集与叠加。
抛弃POJO的get、set,走向实体的丰富行为,让我们编写代码更加困难了么?其实,我们的烦恼来自于,太关注实体行为的收口,忽略了扩展的设计:
-
原来get set写法很舒服的本质在于,很多的扩展被放在了业务脚本中,业务脚本虽然千疮百孔,但是是在应用层,远离核心逻辑。底层模型、通用组件等基础逻辑还是比较干净的。
-
应用DDD的时候,把一些行为下沉到领域层之后,也是要考虑扩展的。如果只关注收口,不关注扩展,那的确是“画地为牢”、“捡了籽麻,丢了西瓜”。
但是,要突破这一个困境,能够在实体行为中设计扩展,其实要有这样的认同:要往上看一个层次,就是实体行为的表达,不一定只有一个类完成,可以通过策略模式等方式的路由,由一个模块中的一些类进行完成,只要对外有封装和管控就可以。
突破一个类的限制,走向更多的类的协作设计,也是我们进阶的方向。
4.3 里氏替换原则:资源库
里氏代换原则是说:任何基类可以出现的地方,子类一定可以出现。讲究的是合理的抽象和复用。引人深思的一个例子是:正方形是特殊的长方形,正方形如果作为长方形的子类,那么当设置长度的时候就会出现冲突,长方形的长和宽可以独立设置,正方形的长和宽是有约束的,使用继承的关系就比较别扭。
在DDD中,关于可替代性,想聊一聊资源库。

Liskov Substitution Principle:里氏替换原则
资源库的替代性需求
在原来的分层的架构中,数据库等存储能力作为一种底层基础设施,是被视为稳定的下层服务的。但在实际的交付过程中,往往要遇到不同场景:
-
本地部署:线下零售交易为了服务稳定性,期望可以具备本地保存数据的能力。
-
云上产品:售卖给外部企业的交易产品,成本的要求也不尽相同,期望在云上采购不同的存储服务。
这些场景,让大家逐渐深信:当面向更广阔的市场,基础设施也是充满着不确定性,需要具备可替换的能力。
存储实现间的复用策略
在具体实现的过程中,并不是每个领域都会独立部署,有些领域因为组织、性能的因素会一起部署。往往这些领域的代码也是在一个项目模块中的。出于横向效率的考虑,会设计统一的存储框架。
不同设施的存储能力不同,但整个存储流程又是类似的(协议转换,存储语句生成、执行与事务,返回结果),这样在不同存储能力的过程复用方式上需要进行取舍(数据库、Tair等是分开抽象还是统一抽象):
如果“大一统”为主,那么针对关系型存储、KV存储等不同存储进行抽象的时候,就会和“长方形与正方形的问题”一样犹豫:
-
收益:如果你长期维护,了解里面的特殊性,的确是可以省略一些主体代码,提高开发效率。
-
代价:但大多数人要做扩展的时候,会感到很多不解,有很多本不需要的适配,充满迷惑。
如果以组合为主,那么可以通过多套模版,更好地进行自主选择。这样分而治之,减少了大家的理解成本,也能独立演化,更能适合存储的能力特性。但是需要沉淀多套理解,往往也缺少人力支持。
我想,“基于不同的存储能力,设计不同的模版框架” 应该是首选。大一统的抽象,开始时,人力成本可能低一点,但因为抽象层次较高,在理解与维护上将是一个“人力成本黑洞”,随着时间的推移,会降低整体收益,长期看是得不偿失的。反之,不同的模版复用,最终可以获得更好的整体收益。
4.4 迪米特法则:领域协作
迪米特法则,又称最小知识原则,是说:一个软件实体应当尽可能少的与其他实体发生相互作用。应该和一些“关键类”进行沟通。
DDD里面,领域间的协作,也需要相关的规划和设计。如果对领域之间的相互调用不做管理,那么链路关系会膨胀到难以理解的地步。
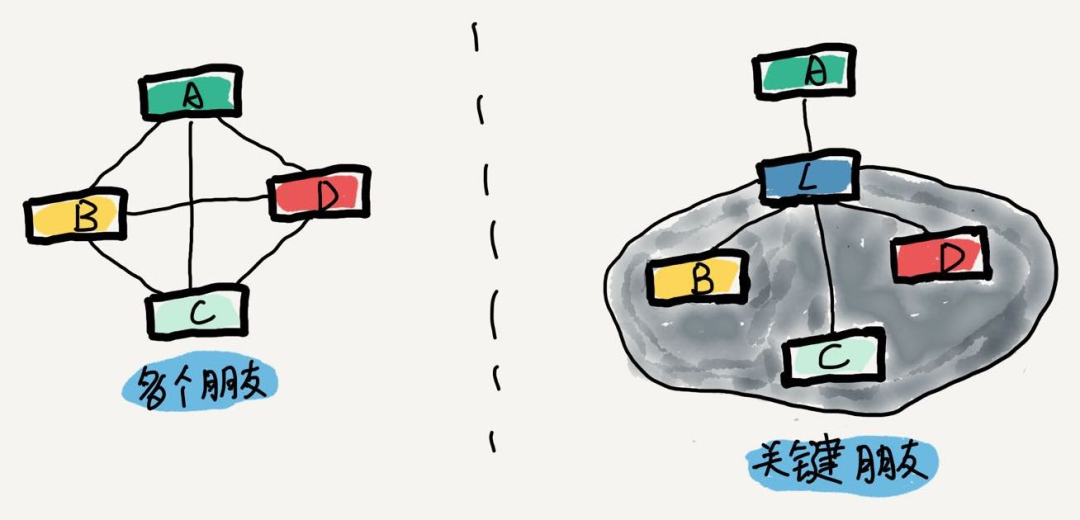
Law of Demeter:迪米特法则
设计模式中,无论是中介者模式,还是外观模式,都希望通过集中管理,让多对多的复杂关系,简化为多对一、一对多这样易于理解的结构。类似的,在领域协作与对外交付的过程中,往往可以增加一个协调层,去串联各个域的交互。这样即可以降低各域的协作成本,也可以降低外部的理解成本,有更好的研发体验。
协调层该如何产生?好比上课:虽然老师可以教,但是老师不在时,可以指定学生代理上课。学生虽然可以干,但教学技巧并不熟练,自己本身还有学习的职责,角色也很尴尬。下面将讨论一下协调层和域的角色关系。
域能否成为协调层
比较值得讨论的是交易里面“交易域”、“订单域”这样的概念:
-
“交易域”看上去是负责整个交易过程,可以协调各个域,逻辑上比较合适成为协调者,但是主要还是在管理订单,其它赋予的协调能力,这部分并没有领域实体。
-
“订单域”看上去只是负责订单本身的服务,不太关心其他域,但是因为订单合约上有着所有合约信息(无论是直接还是间接持有),这意味着,“订单域”本身就有协调的潜力,只是职责看上去不够单一而已。
没有实体,为什么会有“交易域”一说,本人是这么理解的:在交易流程等可以强管控的情况下,把交易的API服务当做域服务(如:下单),“交易域”在逻辑上是有边界、可以成立的。但本质还是在管理订单,靠订单域成为了域,同时想沉淀协调能力。
协调层能否成为域
那么,如果订单的模型的管理不给交易管理呢,就是本人一直想的问题:如果没有自己的数据库实体,只有内存模型,纯粹靠对下游业务活动理解、数据流转的理解,能否成为一个域?
答案大概率可能是不行的:
-
逻辑上个人是认可纯靠理解作为一个域,毕竟知识本身也是一种资产。
-
但实际上,没有载体,就做不了特别多事情,包括状态记录,数据服务等,只能辅助,没有核心竞争力,难以生存下来。
协调者的角色,想要成为一个比较公认的“域”,必定要自己持有数据模型,或者借助基础域的一些数据模型,并享有管理的权限。
协调层的名称
无论是域想承担协调者的角色,还是协调者想发展成一个域,其实都不太符合职责单一的逻辑,但是这样“兼职”的现象却时常发生,核心还是开发人员角色的重叠。
既然协调层不太适合从域中选出,也不太适合成为一个域,那么介于业务活动、各个域能力之间的协调部分,应该称之为什么?目前看“商业能力”、“解决方案”这样的词汇都是比较合适的。
4.5 接口隔离原则:业务活动
接口隔离原则是说:客户端不应该依赖它不需要的接口。一个类对另一个类的依赖应该建立在最小的接口上。
DDD里面除了领域建设的学习,也需要关注应用层如何更好地承接业务请求,并研究业务逻辑分割的依据。
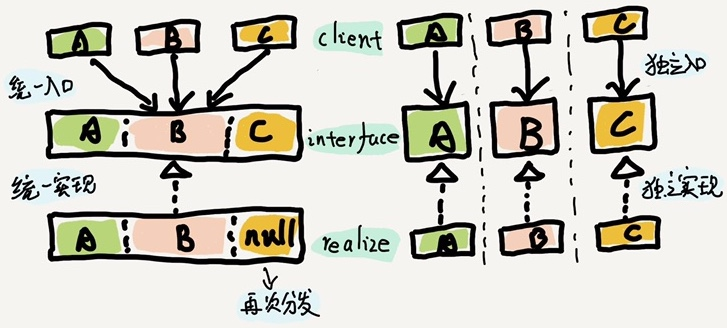
Interface Segregation Principle:接口隔离原则
没有规矩,难成方圆
之前在业务部门做业务的时候,并没有业务活动、流程等相关概念,往往是基于业务需求写业务脚本,经验的多少会影响代码的优雅。但除了经验,大家并没有比较好的结构框架、原则,去承接应用层的各种业务逻辑,因此也充满疑惑:
-
对外服务接口应该如何切分?
-
类似服务之间是否可以共用流程?
-
业务执行过程如何进一步结构化切分?
-
......
没有规范的结果是,往往各有各的看法,谁都想立一套结构,谁也不服谁起的一套,各有各的代码区域。
平台的稳定框架
现在工作中,因为在平台,平台思考和治理的时间也比较久了,也有比较稳定的共识。整体的设计,在业务入口和业务入口之间、业务入口和稳定逻辑之间,预留了空间和扩展能力去承接场景化的逻辑,结构也比较确定:
-
入口按业务活动切分:服务入口按照业务活动扩展,核心理解并关注用例,什么角色要干什么事情。
-
流程独立承接与编排:业务活动在到达复用层(如:领域服务、外部服务、业务扩展)前保持独立,各自编排。
-
借助流程文件编排执行过程:将执行过程切分为执行节点,节点的切分可以以“功能点”、”涉及的域“、“涉及的实体“等为依据。节点间的共同能力下沉到基础能力中。
-
......
反复review形成共识
分而治之,缩小大家的关注点,更好地切分协作,这样的确很容易理解并接受。但是要保证合理的切分,还是要有统一的共识和原则。
往往一致的形成,不是先一致共识,再切分,而是初步沟通后就尝试切分,再review达成一致,在曲折中前进。如果大家的看法、冲突较大,那么这个共识达成的过程就相对较慢。好在,这种切分也不是时常发生,也就大需求、大重构的时候。此时,预留的研讨时间、开发资源也是充足的。
4.6 依赖倒置原则:六边形架构
依赖倒置原则是说:程序要依赖于抽象接口,不要依赖于具体实现。
DDD里面提到的六边形架构,也是进一步提升了抽象内核的地位,把领域建设作为架构的核心目标。
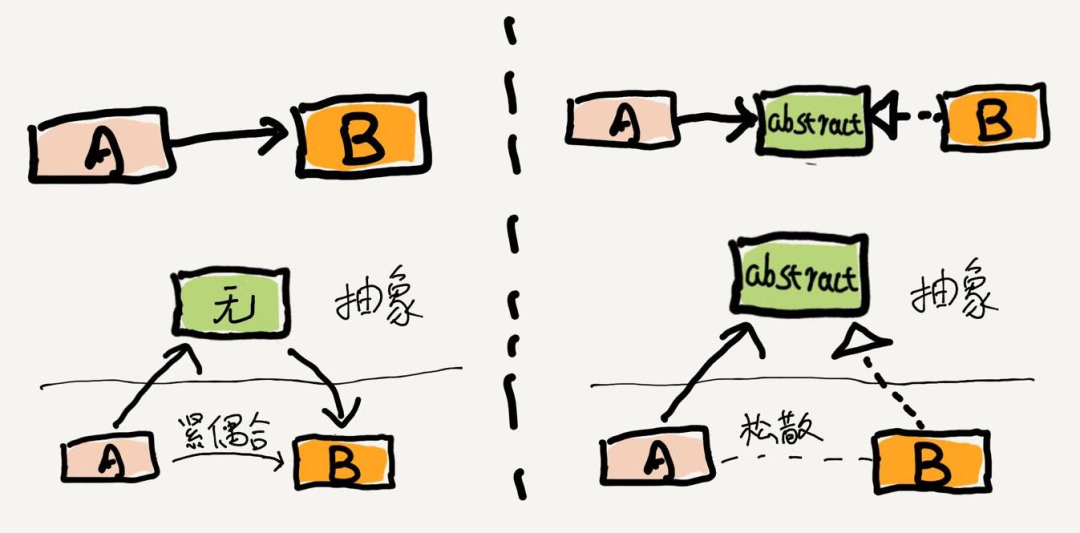
Dependence Inversion Principle:依赖倒置原则
以领域为中心,其实是一个比较重要的转变:
-
原来以分层架构为主:讲究按层次去看,尽量将能力下沉,进行更多工具复用,积累的是通用组件。
-
现在以领域为中心:讲究按抽象层次去看,尽量将理解融入到领域核心,进行更多“理解”复用,积累的是业务知识。
这样的转变,让我们有意识地将“领域理解”作为核心,形成行业竞争力,把“知识”作为资产进行售卖。
为了保证领域内核的抽象,需要定义好领域内核的边界,有两类接口:
-
对上游提供的能力:通过接口声明,说明能承担的职责,在领域内部进行实现支撑。
-
对下游的能力依赖:外部服务、业务扩展定制、存储服务都可以作为下游服务看待,通过接口声明服务依赖。
可以看到,领域内核与外部之间通过接口进行解耦。对于更基础的服务,会被视为和业务入口一样的外部端口,属于应用层。比如,存储服务:
-
原来更多的是基础能力:数据框架 + DO,不需要理解转换,转换在上游完成,DO也会作为核心模型被上游使用,在采用遵循模型策略的时候,上游完全使用DO作为核心对象进行流转。
-
现在可以理解为“业务组件“:需要实现领域的存储接口,承担协议转换,将领域对象转换为数据存储对象DO,DO也不会被领域直接理解,需要转换为领域对象再往外透,被领域内核定义了表现。
这样的架构,奠定了领域理解的抽象核心地位,让研发同学更加注重对业务问题的思考,建设更多“有血有肉”、“贴近业务核心问题”的软件,不仅仅是“基础骨架”,让我们更加走近客户的价值,是应对软件复杂性过程中,大家比较认可的方向。
五、总结
对DDD的追求,来自我们渴望优雅地解决各种业务问题,希望有一套框架可以引导我们去分解问题,得到稳定、高效的生产效率。
但是这好比对“永动机”的追求,是一个难以有肯定答案的过程。能够解决软件复杂性的方案,必定是结合相关场景并且不断演化的,单纯追求DDD是得不到“银弹”的。
不过正如对“永动机”的研究,能让我们关注能量的转换过程,可以引导我们制造出更加高效的能源机器。对DDD的研究与追捧,能够让我们更加关注对业务的深刻理解,可以引领我们写出更加易于扩展的代码实现。
我想,正是“业务的不断发展”、“软件的复杂性”的存在,才让编程充满了挑战,才让大家对框架的研究充满热情,这何尝不是一个美妙的事情。

相关文章:
聊一聊,我对DDD的关键理解
作者:闵大为 阿里业务平台解决方案团队 当我们在学习DDD的过程中,感觉学而不得的时候,可能会问:我们还要学么?这的确引人深思。本文基于工作经验,尝试谈谈对DDD的一些理解。 一、序 《阿甘正传》中…...
—— 认识复杂度和简单排序算法)
算法笔记(一)—— 认识复杂度和简单排序算法
时间复杂度是在一个算法流程中,常数操作的数量级指标。(最差情况下的算法表现) 比较两个算法的优劣,在足够的空间下,看时间复杂度指标,若相同,需要在大数据运行下来判断两个算法的“常数项指标…...
MQ消息中间件常见题及解决办法
目录儿常见MQRocketMQ2、RocketMQ测试可用MQ常见问题1、幂等性问题2、如何保证消息不丢失3、消息积压问题4、事务消息设计分析常见MQ RocketMQ RocketMQ又四部分组成 NameServer 同步Broker服务信息,给消费者和生产者提供可用Broker的服务信息。Broker 消息存储业…...
网关服务限流熔断降级分布式事务
目录一、网关服务限流熔断降级二、Seata--分布式事务1、分布式事务基础①事务②本地事物③分布式事务④分布式事务的场景2、分布式事务解决方案①全局事务②最大努力通知③TCC事务3、Seata介绍4、Seata实现分布式事务控制①案例基本代码(异常模拟)②启动…...
JVM——7JVM调优实战及常量池详解
Arthas工具的使用 阿里巴巴开源的java诊断工具 下载插件 上传至linux环境 在linux跑起来的java项目,可以用Arthas进行查看 项目上线前的时候没问题,上线了就出问题 ,用来查看线上代码 jad 项目名 :反编译线上正在运行的代码 用…...

子串分值【第十一届】【省赛】【A组】
问题描述 对于一个字符串 s,我们定义 s 的分值 f(s) 为 s 中恰好出现一次的字符个数。例如 f("aba")1,f("abc")3, f("aaa")0。 现在给定一个字符串 s[0..n−1](长度为 n),请你计算对于…...
SpringCloud 中 Config、Bus、Stream、Sleuth
文章目录🚏 第十三章 分布式配置中心🚬 一、Config 概述🚬 二、Config 快速入门🚭 config-server:🛹 1、使用gitee创建远程仓库,上传配置文件🛹 2、导入 config-server 依赖…...

Quantum 构建工具使用新的 TTP 投递 Agent Tesla
Zscaler 的研究人员发现暗网上正在出售名为 Quantum Builder 的构建工具,该工具可以投递 .NET 远控木马 Agent Tesla。与过去的攻击行动相比,本次攻击转向使用 LNK 文件。 Quantum Builder 能够创建恶意文件,如 LNK、HTA 与 PowerShell&…...

浏览器中的 JavaScript 执行机制
思维导图 本文为反复学习极客时间-《浏览器的工作原理与实践》-浏览器中的 JavaScript 执行机制章节中的一些思考与记录。 一些重要概念 变量提升 所谓的变量提升,是指在 JavaScript 代码执行过程中,JavaScript 引擎把变量的声明部分和函数的声明部分…...

kafka集群搭建及问题
一、zookeeper集群搭建 1、创建文件夹 cd /home mkdir zookeeper 2、下载 cd zookeeper wget https://downloads.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz 解压到当前文件夹 tar -zxvf apache-zookeeper-3.8.0-bin.tar.gz 文件夹重命…...
不要忽视web渗透测试在项目中起到的重要性
在当前数字化环境中,IT的一个里程碑式增长便是公司组织和企业数字化。为了扩大市场范围和方便业务,许多组织都在转向互联网。这导致了一股新的商业浪潮,它创造了网络空间中的商业环境。通过这种方式,公司和客户的官方或机密文件都…...
Early Stopping中基于测试集(而非验证集)上的表现选取模型的讨论
论文中一般都是用在验证集上效果最好的模型去预测测试集,多次预测的结果取平均计算准确率或者mAP值,而不是单纯的取一次验证集最好的结果作为论文的结果。如果你在写论文的过程中,把测试集当做验证集去验证的话,这其实是作假的&am…...

appium ios真机自动化环境搭建运行(送源码)
appium ios真机自动化环境搭建&运行(送源码) 目录:导读 (1)安装JDK,并配置环境变量,方法如下: (2)安装Xcode、Xcode commandline tools和iOS模拟器 &…...
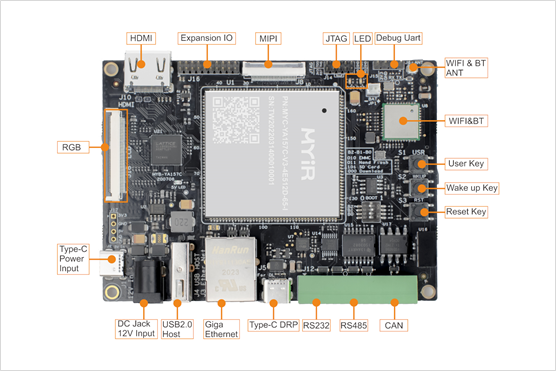
米尔基于ARM嵌入式核心板的电池管理系统(BMS)
BMS全称是Battery Management System,电池管理系统。它是配合监控储能电池状态的设备,主要就是为了智能化管理及维护各个电池单元,防止电池出现过充电和过放电,延长电池的使用寿命,监控电池的状态。 图片摘自网络 电池…...
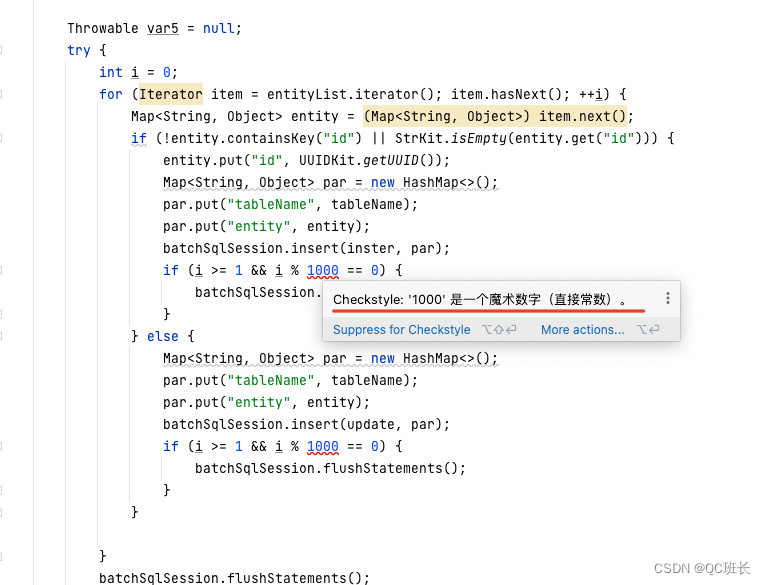
Java后端项目IDEA配置代码规范检查,使用checkStyle实现
最近的Java后端项目想实现代码的规范检查,调研了一圈,终于找到了简单的方式实现:以下是常见的几种方案: 1、在客户端做 git hook,主要是用 pre-commit 这个钩子。前端项目中常见的 husky 就是基于此实现的。但缺点也很…...
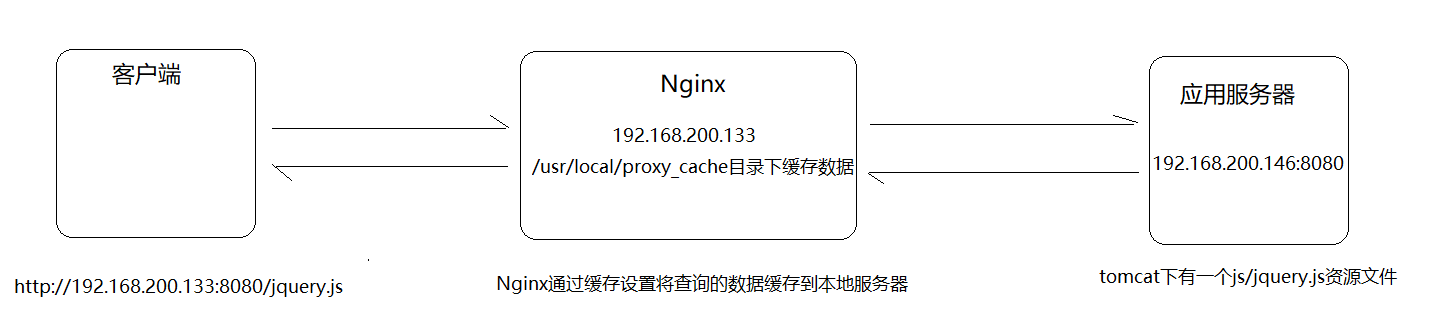
Nginx_4
Nginx负载均衡 负载均衡概述 早期的网站流量和业务功能都比较简单,单台服务器足以满足基本的需求,但是随着互联网的发展,业务流量越来越大并且业务逻辑也跟着越来越复杂,单台服务器的性能及单点故障问题就凸显出来了,…...
linux Ubuntu KUbuntu 系统安装相关
系统安装 本来想快到中午的时候调试一下服务器上的http请求接收代码。我的电脑上装的是kali的U盘系统,然后我的U盘居然找不到了(然后之前安装的系统不知道是否是写入软件的原因,没办法解析DNS,我都用的转发的,这让我体验非常差。kali的系统工具很多&…...

个人信息保护认证
个人信息保护认证是证明个人信息处理者在认证范围内开展的个人信息收集、存储、使用、加工、传输、提供、公开、删除以及跨境等处理活动符合认证依据标准要求。适用范围 本规则依据《中华人民共和国认证认可条例》制定,规定了对个人信息处理者开展个人信息收集、存储…...

Negative Prompt in Stable Diffusion
必读链接:https://www.reddit.com/r/StableDiffusion/comments/z7salo/with_the_right_prompt_stable_diffusion_20_can_do/ A lot of people have noticed that Negative Prompt works wonders in 2.0, and works even better in 2.1. Negative hints are the op…...

MLX90316KGO-BDG-100-RE传感器 旋转位置 角度测量
介绍MLX90316是Tria⊗is旋转位置传感器,提供在设备表面旋转的小偶极磁铁(轴端磁铁)的绝对角位置。得益于其表面的集成磁集中器(IMC),单片设备以非接触式方式感知应用磁通量密度的水平分量。这种独特的传感原理应用于旋转位置传感器,可在机械(…...

Codex:不只是程序员的代码助手,更是办公人士的高效伙伴
Codex:不只是程序员的代码助手,更是办公人士的高效伙伴 面向团队协作、文档处理、数据分析和日常执行的智能工作台 当人们谈到 Codex,第一反应往往是“写代码”。这当然是它的强项,但如果只把 Codex 看成程序员的专属工具&#…...

结构化生成式AI驱动材料设计:从生物启发到实验验证的完整实践
1. 项目概述:当AI遇见材料科学,一场设计范式的革命“AI驱动材料科学”这个标题,听起来宏大又前沿,但它的内核其实非常具体和务实。作为一名在材料计算与实验交叉领域摸爬滚打了十多年的从业者,我亲眼见证了这场变革从概…...

AI加速器架构对比:从GPU到专用芯片的性能与能效分析
1. AI加速器架构全景解析:从通用GPU到专用芯片的演进在深度学习计算领域,硬件架构的创新正以前所未有的速度推进。传统GPU凭借其强大的并行计算能力长期占据主导地位,但随着模型规模的指数级增长和能效要求的不断提高,各类专用AI加…...

3PEAK思瑞浦 TPA2772-VS1R MSOP8 运算放大器
特性 供电电压:3V至36V 偏移电压:在25C时最大3.5mV 轨到轨输入和输出 带宽:4.6 MHz 噪声容限:-良好,THD0.0008% 低噪声:1kHz时53nV/vHz 零交叉输入: -优异的总谐波失真加噪声:0.0008%...

Ctool架构深度解析:模块化开发工具集的高效实现方案
Ctool架构深度解析:模块化开发工具集的高效实现方案 【免费下载链接】Ctool 程序开发常用工具 chrome / edge / firefox / utools / windows / linux / mac 项目地址: https://gitcode.com/gh_mirrors/ct/Ctool 在程序开发过程中,开发者经常需要在…...

深度解析:Mermaid实时编辑器架构设计与工程实践指南
深度解析:Mermaid实时编辑器架构设计与工程实践指南 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-live-editor …...

InjectFix实战解析:在Unity IL2CPP环境下实现C#热修复的权衡与策略
1. InjectFix在IL2CPP环境下的核心价值 当你的Unity手游在应用商店上线后突然出现致命Bug,传统解决方案往往需要重新打包、提交审核、等待上架,这个过程可能耗时数天。而InjectFix提供的C#热修复能力,可以在不更新客户端的情况下快速修复线上…...

开源项目可持续性挑战:从OpenOffice兴衰看企业技术选型策略
1. 开源软件的理想与现实:从OpenOffice的兴衰谈起几年前,当我听说Apache软件基金会(ASF)正在考虑让OpenOffice项目“退休”时,内心的震动是实实在在的。对于我们这些经历过世纪之交软件大战的老兵来说,Open…...

[具身智能-680]:ROS2 可视化与调试工具与示例
按日常开发必用分类,每条可直接复制运行,新手也能马上上手。一、3D 可视化工具1. rviz2(核心 3D 可视化)功能查看:机器人模型、激光雷达、点云、地图、TF 坐标、导航路径、相机图像、机械臂、代价地图等。启动bash运行…...

【文件上传绕过】十六—十八:巧用文件幻数与内容伪装突破类型校验
1. 文件幻数:藏在二进制里的身份证 每次上传图片时,你有没有好奇过系统是怎么判断"这张图真的是JPG"的?这就像超市扫码器识别商品条形码一样,计算机其实是通过读取文件开头的几个特殊字节——我们称之为**幻数ÿ…...