深度学习课程:手写体识别示例代码和详细注释
Pytorch 的快速入门,参见 通过两个神经元的极简模型,清晰透视 Pytorch 工作原理。本文结合手写体识别项目,给出一个具体示例和直接关联代码的解释。
1. 代码
下面代码展示了完整的手写体识别的 Python 程序代码。代码中有少量注释。在本文后半部分,给出其中关键代码的详细注释。
import numpy as np
import torch
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import torchvision'''
运行说明
安装依赖命令,要安装这个版本。
pip install torch==1.4.0 torchvision==0.5.0
pip install matplotlib numpy
代码按照内容的顺序,方便阅读。
'''# 1 导入数据集train_loader = torch.utils.data.DataLoader(datasets.MNIST(root='./data', #root表示数据加载的相对目录train=True, #train表示是否加载数据库的训练集,False时加载测试集download=True,#download表示是否自动下载transform=transforms.Compose([#transform表示对数据进行预处理的操作transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=64, shuffle=True)#batch_size表示该批次的数据量 shuffle表示是否洗牌'''
关于下面这段代码的说明:transform=transforms.Compose([#transform表示对数据进行预处理的操作transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])这段代码使用了PyTorch的transforms模块,将数据预处理操作组合到一起。其中,transforms.Compose()函数用于将多个数据预处理操作(也称为transform)组合成一个可执行的函数。而在这个例子中,Compose()函数传入了两个transform函数:ToTensor()和Normalize()。ToTensor()函数用于将PIL Image或numpy.ndarray数据类型转换成torch.FloatTensor类型,即将图片转换成tensor。Normalize()函数则用于对tensor进行归一化操作。它需要传入两个参数,分别是均值和标准差。这个例子中,均值为0.1307,标准差为0.3081。这意味着对于每个通道,像素的值都将被减去均值后再除以标准差,使得处理后的数据均值为0,标准差为1。这样做的好处是可以使模型更容易地学习到数据的特征,加速训练过程。因此,这段代码所做的工作是将输入的图片数据先转换为tensor,再进行归一化处理,最终返回处理后的tensor数据。
'''test_loader = torch.utils.data.DataLoader(datasets.MNIST('./data', train=False, transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=64, shuffle=True)def imshow(img):img = img / 2 + 0.5 # unnormalizenpimg = img.numpy()plt.imshow(np.transpose(npimg, (1, 2, 0)))plt.show()# 得到batch中的数据
dataiter = iter(train_loader) # 通过 iter(train_loader) 将 train_loader 转换为一个 Iterator 迭代器对象。
images, labels = dataiter.next() # 通过 dataiter.next() 获取这个迭代器对象的下一个元素,即从 train_loader 中取出一批数据。# 将这一批数据中的图像数据和标签数据分别赋值给变量 images 和 labels。
# 展示图片
imshow(torchvision.utils.make_grid(images))# 1.2.1 定义神经网络
import torch
import torch.nn as nn
import torch.nn.functional as F#可以调用一些常见的函数,例如非线性以及池化等class Net(nn.Module):def __init__(self):super(Net, self).__init__()# 1 input image channel, 6 output channels, 5x5 square convolution# 输入图片是1 channel输出是6 channel 利用5x5的核大小self.conv1 = nn.Conv2d(1, 6, 5)self.conv2 = nn.Conv2d(6, 16, 5)# 全连接 从16 * 4 * 4的维度转成120self.fc1 = nn.Linear(16 * 4 * 4, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):# 在(2, 2)的窗口上进行池化x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))x = F.max_pool2d(F.relu(self.conv2(x)), 2)#(2,2)也可以直接写成数字2x = x.view(-1, self.num_flat_features(x))#将维度转成以batch为第一维 剩余维数相乘为第二维x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xdef num_flat_features(self, x):size = x.size()[1:] # 第一个维度batch不考虑num_features = 1for s in size:num_features *= sreturn num_featuresnet = Net()
print(net)# 1.2.2 前向传播image = images[:2]
label = labels[:2]
print(image.size())
print(label)
out = net(image)
print(out)# 1.2.3 计算损失image = images[:2]
label = labels[:2]
out = net(image)
criterion = nn.CrossEntropyLoss()
loss = criterion(out, label)
print(loss)# 1.2.4 反向传播与更新参数#创建优化器
import torch.optim as optim
optimizer = optim.SGD(net.parameters(), lr=0.01)#lr代表学习率
criterion = nn.CrossEntropyLoss()
# 在训练过程中
image = images[:2]
label = labels[:2]
optimizer.zero_grad() # 消除累积梯度
out = net(image)
loss = criterion(out, label)
loss.backward()
optimizer.step() # 更新参数# 1.3 开始训练def train(epoch):net.train() # 设置为training模式running_loss = 0.0for i, data in enumerate(train_loader):# 得到输入 和 标签inputs, labels = data# 消除梯度optimizer.zero_grad()# 前向传播 计算损失 后向传播 更新参数outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()# 打印日志running_loss += loss.item()if i % 100 == 0: # 每100个batch打印一次print('[%d, %5d] loss: %.3f' %(epoch + 1, i + 1, running_loss / 100))running_loss = 0.0train(1)# 1.4 观察模型预测效果correct = 0
total = 0
with torch.no_grad():#或者model.eval()for data in test_loader:images, labels = dataoutputs = net(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))
2. 注释
2.1 transforms.Compose()
transform=transforms.Compose([#transform表示对数据进行预处理的操作transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])
这段代码使用了PyTorch的transforms模块,将数据预处理操作组合到一起。
其中,transforms.Compose()函数用于将多个数据预处理操作(也称为transform)组合成一个可执行的函数。而在这个例子中,Compose()函数传入了两个transform函数:ToTensor()和Normalize()。
-
ToTensor()函数用于将PIL Image或numpy.ndarray数据类型转换成torch.FloatTensor类型,即将图片转换成tensor。
-
Normalize()函数则用于对tensor进行归一化操作。它需要传入两个参数,分别是均值和标准差。这个例子中,均值为0.1307,标准差为0.3081。这意味着对于每个通道,像素的值都将被减去均值后再除以标准差,使得处理后的数据均值为0,标准差为1。这样做的好处是可以使模型更容易地学习到数据的特征,加速训练过程。
因此,这段代码所做的工作是将输入的图片数据先转换为tensor,再进行归一化处理,最终返回处理后的tensor数据。
2.2 transforms.ToTensor()
transforms.ToTensor() 是 PyTorch 中的一个数据预处理方法,用于将 PIL 图像或 numpy 数组转换为张量(Tensor)类型,并进行标准化。具体来说,该方法将 PIL 图像或 numpy 数组的值缩放到 [0, 1] 的范围内,并将其通道顺序从 H x W x C 转换为 C x H x W。
以下是一个简单的例子:
import torch
from torchvision import transforms
from PIL import Image# 读取一张图片
img = Image.open("example.jpg")# 对图片进行预处理
transform = transforms.Compose([transforms.Resize((224, 224)), # 重设图片大小为 224x224transforms.ToTensor() # 将 PIL 图像或 numpy 数组转换为张量类型
])
img_tensor = transform(img)print(img_tensor.shape) # 输出 (3, 224, 224)
print(torch.min(img_tensor), torch.max(img_tensor)) # 输出 0 和 1,表示值已经被缩放到 [0, 1] 的范围内
此示例从文件加载一张图像,并使用 transforms.Resize() 方法重设图像大小。然后使用 transforms.ToTensor() 方法将图像转换为张量。最后,将处理后的张量打印出来,显示它的形状和最小/最大值。
2.3 transforms.Normalize()
transforms.Normalize() 是 PyTorch 中的一个数据预处理方法,用于对张量进行标准化,即让所有元素都满足均值为 0、方差为 1 的分布。在深度学习中,对数据进行标准化是提高训练稳定性和效果的常用方法之一。
该方法需要传入两个参数:均值(mean)和标准差(std)。标准化公式为:
output = (input - mean) / std
在这个公式中,input 是输入的张量,mean 和 std 是指定的均值和标准差,在对每个元素逐一计算(减去均值再除以标准差)之后得到 output 张量。
以下是一个简单的示例:
import torch
from torchvision import transforms# 构造一个三通道的张量,大小为 3x5
tensor = torch.tensor([[[1.0, 2.0, 3.0, 4.0, 5.0],[6.0, 7.0, 8.0, 9.0, 10.0],[11.0, 12.0, 13.0, 14.0, 15.0]],[[2.0, 3.0, 4.0, 5.0, 6.0],[7.0, 8.0, 9.0, 10.0, 11.0],[12.0, 13.0, 14.0, 15.0, 16.0]],[[3.0, 4.0, 5.0, 6.0, 7.0],[8.0, 9.0, 10.0, 11.0, 12.0],[13.0, 14.0, 15.0, 16.0, 17.0]]
])# 求均值和标准差
mean = torch.mean(tensor)
std = torch.std(tensor)# 借助 transforms.Normalize 对张量进行标准化
transform = transforms.Normalize(mean=mean, std=std)
normalized_tensor = transform(tensor)print(normalized_tensor)
在这个例子中,我们构造了一个大小为 3x5 的张量,并对它进行了标准化。标准化的结果是把每个元素都减去了张量的均值,然后除以了张量的标准差。最后我们输出标准化后的结果。
更进一步的例子:
import torch
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt# 读取一张图片
img = Image.open("example.jpg")
plt.imshow(img)
plt.show()# 对图片进行预处理
transform = transforms.Compose([transforms.Resize((224, 224)), # 重设图片大小为 224x224transforms.ToTensor() # 将 PIL 图像或 numpy 数组转换为张量类型
])
img_tensor = transform(img)print(img_tensor.shape) # 输出 (3, 224, 224)
print(torch.min(img_tensor), torch.max(img_tensor)) # 输出 0 和 1,表示值已经被缩放到 [0, 1] 的范围内# 转换张量维度,并把它转换为 numpy 数组
img_numpy = img_tensor.permute(1, 2, 0).numpy()
plt.imshow(img_numpy)
plt.show()
运行结果如下:

2.4 torchvision.utils.make_grid()
torchvision.utils.make_grid(images) 是 PyTorch 的一个函数,用于将多张图片合成一张组合图,可用于可视化多张图像的数据。
该函数的主要参数是 images,代表输入的张量的列表或者张量。除此之外,还可以接受一些其他参数来控制输出的组合图的样式和尺寸。
下面是一个简单的代码示例:
import torch
import torchvision
import matplotlib.pyplot as plt# 读取一些用于示例的图片
images = [torch.randn((3, 256, 256)), torch.randn((3, 256, 256)), torch.randn((3, 256, 256))]# 将图片进行组合,并转换为可显示的numpy数组格式
grid_image = torchvision.utils.make_grid(images, padding=10)
numpy_image = grid_image.cpu().numpy().transpose((1, 2, 0))# 显示组合图
plt.imshow(numpy_image)
plt.show()
在上面的示例中,我们模拟生成了三张 3 × 256 × 256 3\times 256\times 256 3×256×256 的图片,使用 torchvision.utils.make_grid 将这三张图片组合成一张 3 × 514 × 778 3\times 514 \times 778 3×514×778 的大图,并且添加了 padding=10 参数来增加每个小图之间的边框宽度,最后将组合图转换为numpy数组格式,并使用 matplotlib 库进行显示。执行上述代码,将会得到如下的组合图:

2.5 x.view()
x.view函数可以将一个PyTorch Tensor(张量)重塑成一个新的形状,这个新形状中每个维度的大小都可以指定。例如:对于一个形状为(2,3)的二维Tensor(张量),我们可以使用view(6)函数将其重塑成一个大小为(6,)的一维Tensor(张量)。在该语句x.view(-1, self.num_flat_features(x))中,-1的含义是我们不知道应该设定的维度数字,需要让PyTorch帮助我们计算,同时保证重塑后的张量元素数量与原来的张量一致。
作为一个例子,假设有一个形状为(2,3,4)的三维张量x,其中2表示batch size,3表示width,4表示height。我们可以使用以下代码将其重塑为一个2D张量:
x = x.view(-1, 3*4) # 将width和height两个维度合并成为一个维度3*4
其中,-1指示在执行重塑操作时,根据原张量的shape自动计算剩余维度的大小,具体而言,在这个例子中,-1表示batch size保持不变,由原张量的batch size的值决定,而重塑后的张量每个元素都相同,都是一个大小为3*4的一维数组。
2.6 nn.CrossEntropyLoss()
nn.CrossEntropyLoss() 是一个用于计算分类问题中损失函数的PyTorch模块。该损失函数是基于交叉熵衡量预测输出和真实标签之间的距离,常用于多分类问题中。
假设我们有一个3分类的分类问题,每个样本有4个特征。我们可以使用以下代码来定义模型和损失函数:
import torch
import torch.nn as nn# 定义模型
class MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()self.fc = nn.Linear(4, 3) # 4个特征,3个类别def forward(self, x):out = self.fc(x)return outmodel = MyModel()# 定义损失函数
criterion = nn.CrossEntropyLoss()
接下来,我们可以加载训练数据,例如利用DataLoader将数据分成batch进行处理。假定一个batch中包含了10个样本,我们可以使用以下代码计算出这个batch中所有样本的损失函数值:
# 假设X是一个10*4的张量,y是一个包含10个整数的列表,表示10个样本的标签
X = torch.randn(10, 4)
y = torch.randint(0, 3, (10,))# 前向传播,获取预测输出
outputs = model(X)# 计算损失
loss = criterion(outputs, y)
其中,outputs是一个10*3的张量,表示对于这10个样本来说,模型对3个类别的预测输出。 y是一个长度为10的列表,表示这10个样本的标签(整数形式)。 criterion(outputs, y)计算了这个batch中所有样本的损失函数值,返回一个大小为1的tensor。
更具体地说,使用nn.CrossEntropyLoss()时,损失函数的具体计算过程如下:
- 对于每个预测输出(即模型对于一个样本对每个类别的预测概率),通过softmax函数将其转换为概率值;
- 找到该样本真实标签所对应的类别,并将其对应的概率值作为损失函数的一部分;
- 将所有样本的损失函数值进行求和或平均。
以下是使用nn.CrossEntropyLoss()计算损失的具体实现:
假设有一个3分类问题,我们已经得到了一个大小为 1 × 3 的张量outputs和一个大小为1的张量y。其中outputs表示模型对于这个样本属于每个类别的概率,例如outputs=[0.1, 0.8, 0.1]表示该样本对于第二个类别(对应0.8这个最大概率)的预测最准确。
import torch.nn.functional as Foutputs = torch.tensor([0.1, 0.8, 0.1])
y = torch.tensor([1])# 将outputs通过softmax函数转化为概率值
probs = F.softmax(outputs, dim=0)
print('probs:', probs) # 如 output=[0.1, 0.8, 0.1] 则 probs=[0.2119, 0.5761, 0.2120]# 使用y作为索引从probs中选取对应的概率值
loss = F.nll_loss(torch.log(probs), y)
print('loss:', loss) # tensor(0.5472)
这里使用了nn.functional.nll_loss()函数的反向版本,该函数用于计算负对数似然损失,即输入是log概率而不是概率本身。其中,torch.log(probs)用于将概率转换成对数概率。上面的例子中,输出的loss值为0.5472。
关于 F.nll_loss 补充说明如下:
F.nll_loss是PyTorch中计算负对数似然损失的函数,其使用方式一般与nn.CrossEntropyLoss()相同。使用F.nll_loss时,需要将模型输出(即经过softmax后得到的每个类别的概率)的log值以及真实标签作为该函数的输入。
在上面的例子中,我们首先使用了softmax函数对模型输出进行转换,得到了一个大小为1×3的概率张量probs,其中每个元素表示该样本属于这个类别的可能性。然后,使用torch.log函数获取probs的对数,以略微减少计算开销,并将其作为负对数似然损失函数的输入,同时传入真实标签y进行计算。
更具体地解释,原理如下:
首先,将probs进行对数化处理,可以把交叉熵函数转化为nll_loss函数。此处使用log函数。这样得到的结果就不会那么离散,让训练变得更加稳定。
然后,我们希望用probs的值来估算输出结果的概率真相性,因此需要找到对应的真实标签,这个标签被单独编码成了一个整数。这里使用了索引技巧:将每个样本的真实标签y作为索引,从probs张量中选取对应的概率值。由于处于计算负对数似然损失,需要对所选出的概率再取反。最终的结果即为使用该样本计算得到的损失值。
在上面的例子中,我们的模型输出[0.1, 0.8, 0.1]表示该样本可能属于第二个类别的概率最高,因此真实标签为1,可以得到以下计算过程:
outputs=[0.1, 0.8, 0.1]probs=[0.266, 0.468, 0.266],对outputs使用了softmax函数转换为概率值log_probs=[-1.3235, -0.7586, -1.3235],对probs使用了torch.log()函数, 进行log操作nll_loss(log_probs, y)=0.7586,函数使用y作为索引从log_probs中选取做为结果和计算梯度。
这个值可以用于反向传播和更新权重值,以提高模型预测能力。
2.7 loss.backward()
loss.backward() 是一个 PyTorch 中用来计算误差反向传播(Backpropagation)的函数,它将使用自动微分(Automatic differentiation)来计算图中每个参数的梯度。
在神经网络中,我们通常需要最小化模型输出与真实标签之间的误差。通过解析损失函数中的参数梯度,我们可以更新每个参数的值以使误差逐渐减少。这就是反向传播算法的核心思想。
在计算过程中,每一步计算结果都会被存储在计算图中,而 loss.backward() 函数就是用来计算该计算图中所有参数的梯度,并将它们累加到各自的变量对象中。
在具体使用时,用户需要在代码中定义所有涉及到的参数,并且对需要进行反向传播的损失函数调用 backward() 方法。例如:
import torch# 定义神经网络
net = torch.nn.Linear(10, 1)# 定义优化器
optimizer = torch.optim.SGD(net.parameters(), lr=0.1)# 定义损失函数
criterion = torch.nn.MSELoss()# 模型训练
for epoch in range(10):optimizer.zero_grad() # 梯度清零input = torch.randn(1, 10) # 随机生成训练数据output = net(input) # 将输入送入神经网络得到输出target = torch.randn(1, 1) # 随机生成目标标签loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新优化器参数print("Training finished!")
在这个简单的示例中,我们定义了一个简单的神经网络,使用随机数据进行训练。每个 epoch 中,我们执行一次正向传播以计算模型输出,然后计算损失。接着,调用 loss.backward() 函数计算梯度,最后使用优化器更新参数。
optimizer.step() 是一个 PyTorch 中用来更新模型参数的函数。在反向传播计算完成后,我们需要更新模型中各个参数的值,从而优化训练效果。
3. 代码中用到的几个代码 Python 包
这段代码使用了以下几个 Python 库:
-
numpy:Python 的开源数学计算库,用于处理向量、矩阵等多维数组数据,以及数值计算、线性代数等操作。 -
torch:PyTorch 是基于 Python 的开源机器学习框架,提供了动态计算图、自动微分等功能,可以方便地构建深度神经网络模型。 -
torchvision:PyTorch 的扩展库,提供了常用图像数据集、变换(transforms)、模型结构和预训练权重等功能。它可以帮助我们更方便地处理图像数据,并且提供了常见的网络结构(如 VGG、ResNet 等)。 -
matplotlib.pyplot:Python 的绘图库,提供了一些函数用于绘制图形,例如折线图、柱状图、散点图等。 -
torch.nn:PyTorch 中的模型层或损失函数等等都在这里。这个包只是一个为 nn 设定的空间,同样也会有定义网络中常见的层结构(如全连接层、卷积层、池化层等)的代码。 -
torch.nn.functional:PyTorch 中提供了各种常用的非线性函数、池化函数,以及 softmax 等函数。 -
torch.optim:PyTorch 提供了各种优化器,例如 SGD、Adam 等。这些优化器可以帮助我们更方便地更新神经网络中的参数,提高模型的训练效果。
相关文章:
深度学习课程:手写体识别示例代码和详细注释
Pytorch 的快速入门,参见 通过两个神经元的极简模型,清晰透视 Pytorch 工作原理。本文结合手写体识别项目,给出一个具体示例和直接关联代码的解释。 1. 代码 下面代码展示了完整的手写体识别的 Python 程序代码。代码中有少量注释。在本文后…...

10-03 单元化架构设计
设计原则 透明 对开发者透明 在做实现时,不依赖于单元划分和部署对组件透明 在组件运行时,不感知其承载单元对数据透明 数据库并不知道为哪个单元提供服务 业务可分片 系统业务复杂度足够高系统可以按照某一维度进行切分系统数据必须可以被区分 业务…...
JAVA—实验3 继承与多态
一、实验目的 1.掌握类的继承机制 2.掌握抽象类的定义方法 2.熟悉类中成员变量和方法的访问控制 3.熟悉成员方法或构造方法的多态性 二、实验内容 1. Circle类及其子类 【问题描述】 实现类Circle,半径为整型私有数据成员 1)构造方法:参数为…...

TCP协议和相关特性
1.TCP协议的报文结构 TCP的全称为:Transmission Control Protocol。 特点: 有连接可靠传输面向字节流全双工 下面是TCP的报文结构: 源端口和目的端口: 源端口表示数据从哪个端口传输出来,目的端口表示数据传输到哪个端口去。…...

【SpringCloud组件——Eureka】
前置准备: 分别提供订单系统(OrderService)和用户系统(UserService)。订单系统主要负责订单相关信息的处理,用户系统主要负责用户相关信息的处理。 一、微服务当中的提供者和消费者 1.1、概念 服务提供…...
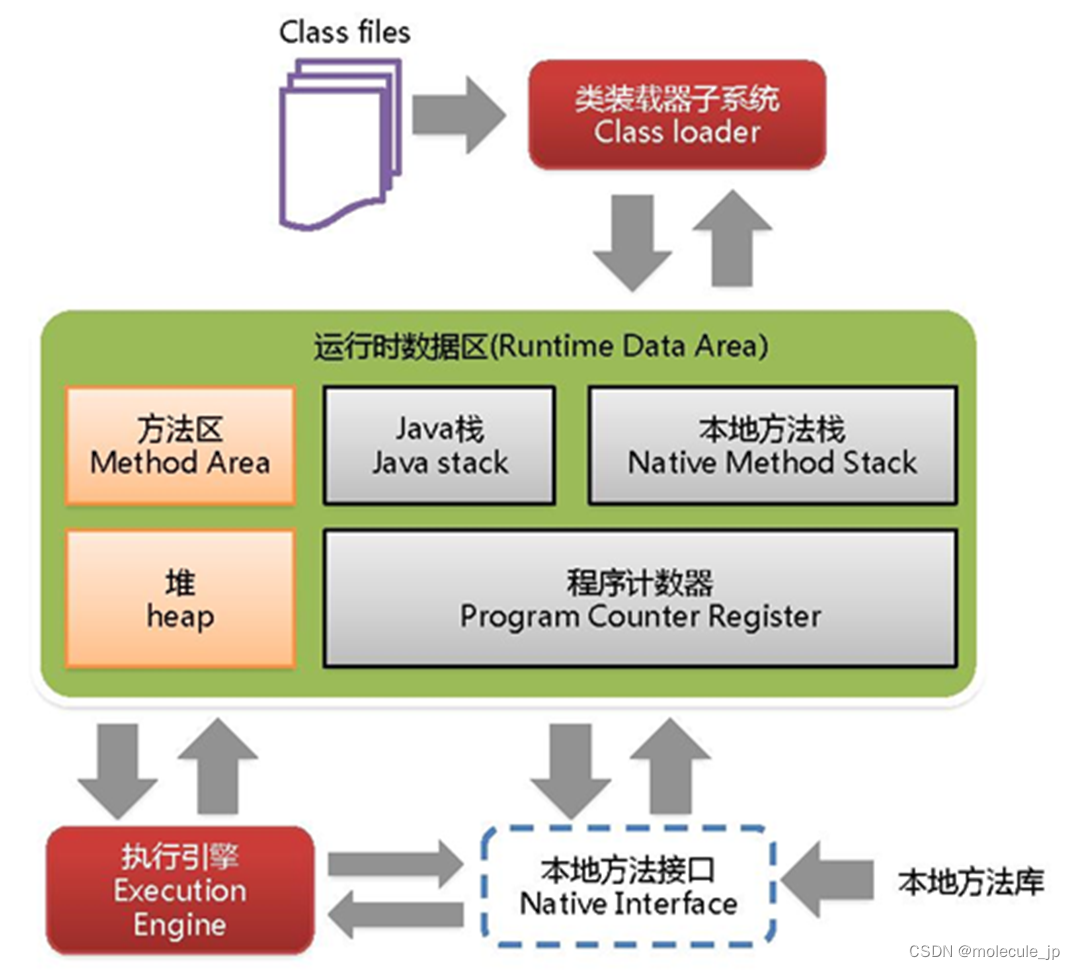
JVM面试题(一)
JVM内存分哪几个区,每个区的作用是什么? java虚拟机主要分为以下几个区: JVM中方法区和堆空间是线程共享的,而虚拟机栈、本地方法栈、程序计数器是线程独享的。 (1)方法区: a. 有时候也成为永久代,在该区内…...

c# 无损压缩照片大小,并且设计了界面,添加了外部Ookii.Dialogs.dll,不一样的选择文件夹界面,并且可以把外部dll打包进exe中
c# 无损压缩照片大小,并且设计了界面,添加了外部Ookii.Dialogs.dll,不一样的选择文件夹界面,并且可以把外部dll打包进exe中 using System; using System.Collections; using System.Collections.Generic; using System.ComponentM…...

《统计学习方法》——隐马尔可夫模型(上)
引言 这是《统计学习方法》第二版的读书笔记,由于包含书上所有公式的推导和大量的图示,因此文章较长,正文分成三篇,以及课后习题解答,在习题解答中用Numpy实现了维特比算法和前向后向算法。 《统计学习方法》——隐马…...

ElasticSearch删除索引【真实案例】
文章目录 背景分析解决遇到的问题 - 删除超时报错信息解决办法1:调大超时时间解决办法2:调大ES堆内存参考背景 项目中使用了ELK技术栈实现了日志管理,但是日志管理功能目前并没有在生产上实际使用。 但ELK程序依然在运行,导致系统磁盘发生告警,剩余可用磁盘不足10%。 所以…...

基于FPGA+JESD204B 时钟双通道 6.4GSPS 高速数据采集设计(三)连续多段触发存储及传输逻辑设计
本章将完成数据速率为 80MHz 、位宽为 12bits 的 80 路并行采样数据的连续多 段触发存储。首先,给出数据触发存储的整体框架及功能模块划分。然后,简介 MIG 用户接口、设置及读写时序。最后,进行数据跨时钟域模块设计,内存…...

对 Iterator, Generator 的理解?
Iterator Iterator是最简单最好理解的。 简单的说,我们常用的 for of 循环,都是通过调用被循环对象的一个特殊函数 Iterator 来实现的,但是以前这个函数是隐藏的我们无法访问, 从 Symbol 引入之后,我们就可以通过 Sy…...

C++基础
文章目录 C命名空间定义命名空间using指令不连续的命名空间嵌套的命名空间 面向对象类类成员的访问权限及类的封装对象类成员函数类访问修饰符构造函数和析构函数类的构造函数带参数的构造函数使用初始化列表来初始化字段类的析构函数拷贝构造函数 友元函数内联函数this指针指向…...

软件测试全流程
软件测试全流程 一、制定测试策略二、制定测试方案三、编辑测试用例四、执行测试用例五、输出问题单六、回归测试七、测试文件归档 一、制定测试策略 1、测试目的测试范围 2、用什么测试方法工具(例如功能测试用黑盒测试) 3、测试优先级(功能…...
【软件测试】支付模块测试攻略,这些测试方法和注意事项你掌握了么?
对于大部分人而言,支付模块或许是日常生活中最为关注和使用的功能之一,因此,对于支付模块的质量控制也显得尤为重要。 但考虑到支付涉及到金钱流转等敏感信息,一旦出现问题可能带来非常严重后果。因此,在支付模块测试…...

刷完这个笔记,17K不能再少了....
大家好,最近有不少小伙伴在后台留言,得准备面试了,又不知道从何下手!为了帮大家节约时间,特意准备了一份面试相关的资料,内容非常的全面,真的可以好好补一补,希望大家在都能拿到理想…...

知识变现创业指南-《知识变现秘籍》
《知识变现秘籍》 知识变现创业者指南 读完将改变你的认知 开阔你的知识变现思路 系统掌握知识变现的要点 知识付费创业方法 帮你利用知识赚到你弟一桶金 如果你有一技之长,想变现 如果你有一身才华,想变现 如果你在某个领域有绝活 如果你是&am…...
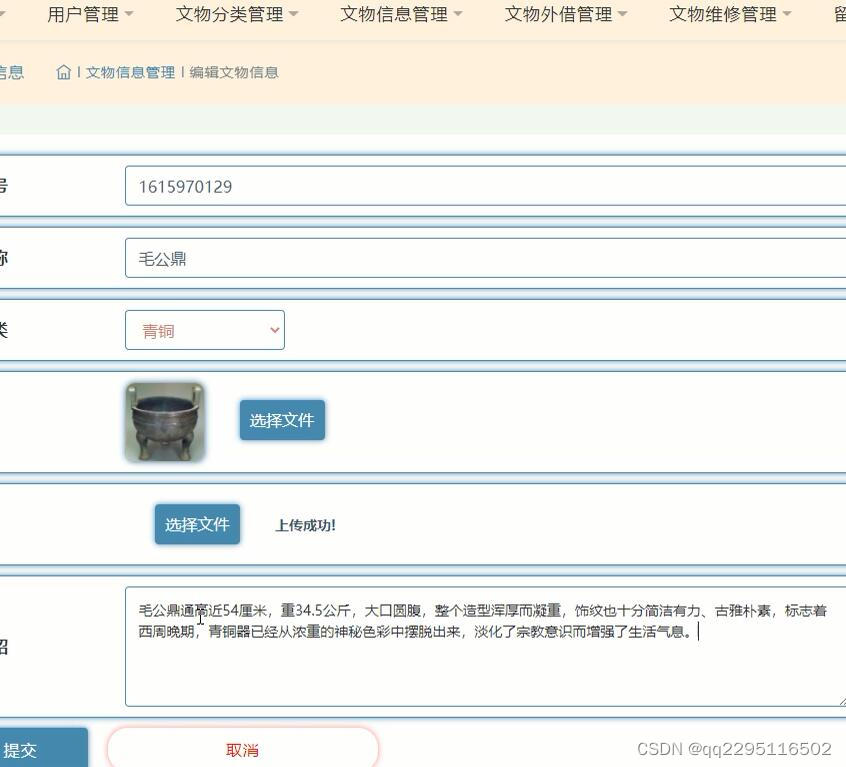
springboot+java博物馆文物管理系统
用户前台进入系统可以进行首页、文物信息、论坛交流、文物资讯、留言反馈、我的、跳转到后台等springboot是基于spring的快速开发框架, 相比于原生的spring而言, 它通过大量的java config来避免了大量的xml文件, 只需要简单的生成器便能生成一个可以运行的javaweb项目, 是目前最…...
——Ansible 的脚本(playbook 剧本))
Ansible 自动化运维工具(二)——Ansible 的脚本(playbook 剧本)
Ansible 自动化运维工具—Ansible 的脚本playbook 剧本 playbooks 概述以及实例操作playbooks 的组成操作示例一:编写yaml文件也就是playbook修改配置文件并放入/opt/目录下运行playbook 操作实例二:定义、引用变量操作示例三:指定远程主机su…...
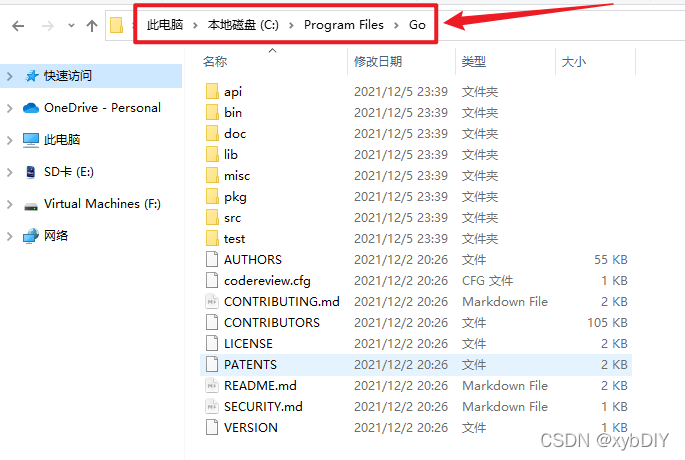
阿里云镜像服务下载并安装Go环境
【阿里云镜像】下载并安装Go环境 一、参考链接 阿里巴巴开源镜像站-OPSX镜像站-阿里云开发者社区 (aliyun.com) golang镜像-golang下载地址-golang安装教程-阿里巴巴开源镜像站 (aliyun.com) GO语言安装以及国内镜像 - DbWong_0918 - 博客园 (cnblogs.com) 二、Go介绍 Gol…...

工作线程快速优雅退出方式探讨
本文我们不用定时器。定时器会阻塞消息循环。先看需求: 我们先看第一种,有一个任务,要求每1秒钟执行一次,最常见的写法如下两种 bool bExitThread false; DWORD WorkThread1(LPVOID param) {while (false bExitThread){//// to…...

深圳实体门店有必要做GEO AI代运营吗
深圳实体门店有必要做GEO AI代运营吗一、开篇引言2026年深圳本地实体商业竞争进入白热化阶段,全城数百万家线下实体门店涵盖本地生活、家装工装、汽车服务、餐饮娱乐、教育培训等全品类,传统线下地推、门店自然客流、传统团购平台引流效果持续下滑&#…...

作业本耐用度差距巨大?深圳大明印刷厂拆解合规工艺,告别定制作业本掉页开裂通病
在校园日常教学中,很多学校都会遇到同一个难题:同一学期采购的作业本、定制作业本,品质差距悬殊,有的完好无损用到期末,有的短短几周就出现书脊开裂、页面脱落、边角破损、翻页卡顿等问题。不少人误以为是学生使用习惯…...

DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉!
更多请点击: https://kaifayun.com 第一章:DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉! 当 DeepSeek 的系统设计辅助能力突然变“笨”——接口建议频繁失准、上下文感知错乱、生成代码无法通过基础编…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...
)
ROS Noetic实战:从bag包里‘抠’出雷达点云和IMU数据的保姆级教程(Ubuntu 20.04)
ROS Noetic实战:从bag包里提取雷达点云和IMU数据的完整指南(Ubuntu 20.04)在机器人开发中,ROS bag文件就像是一个装满珍贵数据的宝箱,而雷达点云和IMU数据则是其中最闪亮的宝石。作为一名长期与ROS打交道的开发者&…...

随机森林算法在儿童出行方式预测中的实战应用与优化
1. 项目概述:用随机森林预测孩子怎么上学做城市交通规划或者做家长接送方案的时候,你肯定想过一个问题:孩子们到底是怎么上学的?是走路、骑车、坐公交还是家长开车送?这个问题看似简单,背后却牵扯到城市规划…...
)
【2025】AWVS安装保姆级教程(最新25.1.2可用)
【2025】AWVS安装保姆级教程(最新25.1.2可用) 文章目录 工具下载Host 重定向AWVS安装AWVS查看安装失败原因 工具下载 点击下载即可 下载完的工具后缀格式为.apk,需要将其改为.zip,然后将其解压得到以下工具后续安装使用 Host 重…...

3步快速上手Whisper-WebUI:轻松实现语音转字幕的完整指南
3步快速上手Whisper-WebUI:轻松实现语音转字幕的完整指南 【免费下载链接】Whisper-WebUI A Web UI for easy subtitle using whisper model. 项目地址: https://gitcode.com/gh_mirrors/wh/Whisper-WebUI 还在为视频制作繁琐的字幕而烦恼吗?Whis…...

终极指南:Windows 10完美安装PL2303驱动,解决老旧USB转串口芯片兼容性问题
终极指南:Windows 10完美安装PL2303驱动,解决老旧USB转串口芯片兼容性问题 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 你是否还在为Windows…...

3步开启Windows 11安卓应用新体验:WSA完整使用指南
3步开启Windows 11安卓应用新体验:WSA完整使用指南 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA Windows Subsystem for Android(简…...