YOLO V3 SPP ultralytics 第二节:根据yolo的数据集,生成准备文件和yolo的配置文件
目录
1. 介绍
2. 完整代码
3. 代码讲解
3.1 生成 my_train_data.txt和my_val_data.txt
3.2 生成 my_data.data 文件
3.3 生成 my_yolov3.cfg
3.4 关于my_data_label.names文件
1. 介绍
根据 第一节 的操作,已经生成了下图中圆圈中的部分,而本章的内容就是通过代码生成矩形框中的部分,为后面的工作做准备
- my_yolov3.cfg 是将官方的yolov3-spp.cfg 网络的配置文件根据自定义的数据集修改得到的自己的网络配置(因为检测的分类个数不同,yolo输出的信息也会不同)
- my_train_data.txt 和 my_val_data.txt 是训练集 / 验证集中,所有图片的完整路径,也就是my_yolo_dataset 中 两个 images 下面的所有图片的路径
- my_data.data 是分类个数、my_train_data.txt 和 my_val_data.txt这两个文件的路径、以及my_data_label.names 的路径(如果,一开始数据集就是yolo格式的,就不会经过第一节的操作,也不会生成这个.names文件,所以要自己建立)

2. 完整代码
实现代码为 calculate_dataset.py
"""
该脚本有3个功能:
1.统计训练集和验证集的数据并生成相应.txt文件
2.创建my_data.data文件,记录目标检测的 classes个数, train以及 val数据集文件(.txt)路径和 label.names文件路径
3.根据 yolov3-spp.cfg创建 my_yolov3.cfg文件修改其中的 predictor filters以及 yolo classes参数(这两个参数是根据类别数改变的)
"""
import os# 生成训练集、验证集的所有数据路径文件
def calculate_data_txt(txt_path, dataset_dir):with open(txt_path, "w") as w:for file_name in os.listdir(dataset_dir): # 遍历数据的标注文件train、val下的labelsif file_name == "classes.txt":continue# 根据标注文件找到对应的图片,图片后缀需要是jpgimg_path = os.path.join(dataset_dir.replace("labels", "images"),file_name.split(".")[0]) + ".jpg"line = img_path + "\n" # 写入一个数据路径就换行assert os.path.exists(img_path), "file:{} not exist!".format(img_path)w.write(line)# 创建data.data文件,记录分类类别个数、训练集、验证集、分类类别的文件路径
def create_data_data(create_data_path, train_path, val_path, classes_info):with open(create_data_path, "w") as w:w.write("classes={}".format(len(classes_info)) + "\n") # 记录类别个数w.write("train={}".format(train_path) + "\n") # 记录训练集对应txt文件路径w.write("valid={}".format(val_path) + "\n") # 记录验证集对应txt文件路径w.write("names=data/my_data_label.names" + "\n") # 记录label.names文件路径# 创建yolo v3 spp的配置信息
def change_and_create_cfg_file(classes_info, save_cfg_path="./cfg/my_yolov3.cfg"):filters_lines = [636, 722, 809]classes_lines = [643, 729, 816]cfg_lines = open(cfg_path, "r").readlines()for i in filters_lines:assert "filters" in cfg_lines[i-1], "filters param is not in line:{}".format(i-1)output_num = (5 + len(classes_info)) * 3 # (x,y,w,h+置信度 + 类别的个数) * 每一个cell生成 3 个预测框cfg_lines[i-1] = "filters={}\n".format(output_num)for i in classes_lines:assert "classes" in cfg_lines[i-1], "classes param is not in line:{}".format(i-1)cfg_lines[i-1] = "classes={}\n".format(len(classes_info))with open(save_cfg_path, "w") as w:w.writelines(cfg_lines)def main():# 统计训练集和验证集的数据并生成相应 txt文件train_txt_path = "data/my_train_data.txt"val_txt_path = "data/my_val_data.txt"calculate_data_txt(train_txt_path, train_annotation_dir) # 所有训练集的路径calculate_data_txt(val_txt_path, val_annotation_dir) # 所有验证集的路径# 获取检测的所有类别classes_info = [line.strip() for line in open(classes_label, "r").readlines() if len(line.strip()) > 0]# 创建data.data文件,记录classes个数, train以及val数据集文件(.txt)路径和 label.names文件路径create_data_data("./data/my_data.data", train_txt_path, val_txt_path, classes_info)# 根据yolov3-spp.cfg创建my_yolov3.cfg文件修改其中的predictor filters以及yolo classes参数(这两个参数是根据类别数改变的)change_and_create_cfg_file(classes_info)if __name__ == '__main__':train_annotation_dir = "./my_yolo_dataset/train/labels" # 训练集的标注文件val_annotation_dir = "./my_yolo_dataset/val/labels" # 验证集的标注文件classes_label = "./data/my_data_label.names" # 检测的分类labelcfg_path = "./cfg/yolov3-spp.cfg" # 官方的yolov3-spp 的配置文件assert os.path.exists(train_annotation_dir), "train_annotation_dir not exist!"assert os.path.exists(val_annotation_dir), "val_annotation_dir not exist!"assert os.path.exists(classes_label), "classes_label not exist!"assert os.path.exists(cfg_path), "cfg_path not exist!"main()
3. 代码讲解
代码有些部分自己又加了些注释,这里会挑着讲解
首先将相关路径设定好

3.1 生成 my_train_data.txt和my_val_data.txt
然后生成数据集图片的路径,这里训练集和测试集一样,只讲解训练集

对于训练集来说,写入my_train_data.txt 文件。

其中,file_name 就是labels 下面文件名,因为这里文件名就是图片的名称。通过路径替换就能、后缀替换就可以找到images所有的图片完整路径,写入my_train_data.txt 文件即可
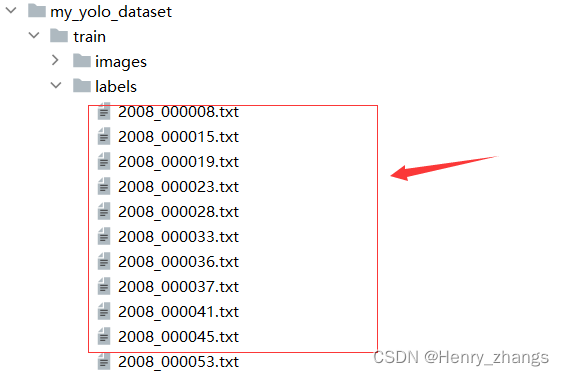
生成的my_train_data.txt 和my_val_data.txt 如下:

3.2 生成 my_data.data 文件
代码如下

其中,classes_info 信息如下:['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'] ,其实就是分类的名称
然后,进入create_data_data 函数内部,将对应的文件路径写入即可

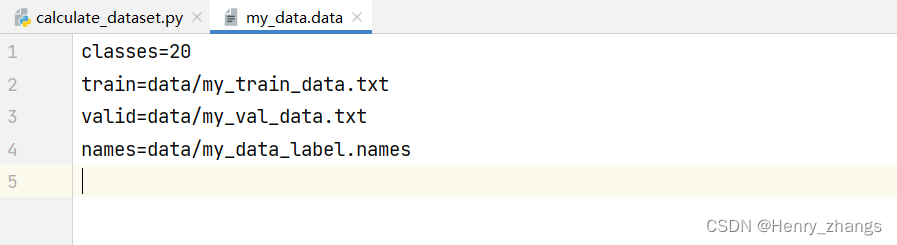
my_data.data 文件
3.3 生成 my_yolov3.cfg
因为不同检测任务的分类个数可能不同,因此需要更改yolo的配置信息

实现的方式如下:
因为yolo输出是三个尺度的,而 filters_lines = [636, 722, 809] classes_lines = [643, 729, 816]就是对应三个尺度的信息。除了检测的类别更改自定义数据集的类别个数外。预测框输出的tensor也和类别有关
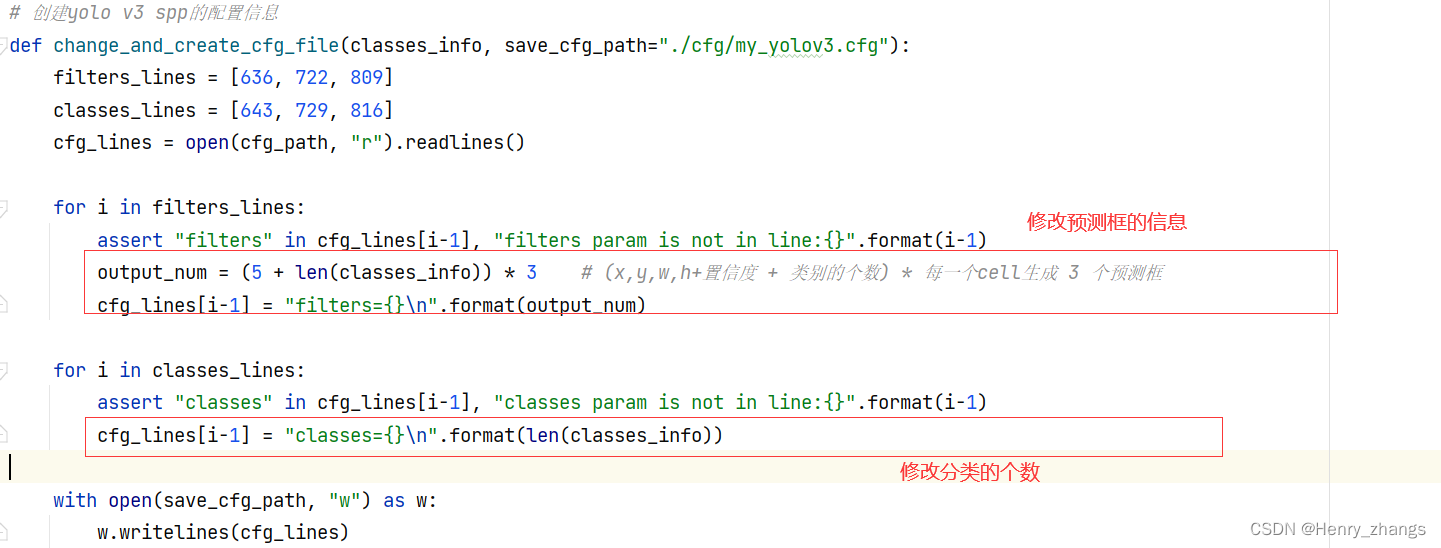
如下,官方的classes 是coco所以是80类别。这里使用的是pascal voc 所以是20类别
75 = (x、y、w、h+置信度 + 类别个数)* 3(每一个cell生成3个预测框) = 25 * 3
官方是 (5 + 80)*3 = 255

3.4 关于my_data_label.names文件
如果本身就是yolo 数据集的话,是不需要进行第一节的操作的
那么这个文件my_data_label.names是不存在的,需要手工建立,如下:
只需要更改文件名就行了

相关文章:
YOLO V3 SPP ultralytics 第二节:根据yolo的数据集,生成准备文件和yolo的配置文件
目录 1. 介绍 2. 完整代码 3. 代码讲解 3.1 生成 my_train_data.txt和my_val_data.txt 3.2 生成 my_data.data 文件 3.3 生成 my_yolov3.cfg 3.4 关于my_data_label.names文件 1. 介绍 根据 第一节 的操作,已经生成了下图中圆圈中的部分,而本…...

camunda流程引擎connector如何使用
在 Camunda 中,Connector 是一种用于与外部系统或服务交互的机制。它允许 BPMN 模型中的 Service Task 节点与外部系统或服务进行通信,从而使流程更加灵活和可扩展。使用 Connector,可以将业务流程与外部系统集成在一起,而无需编写…...

ECO基本概念:pre-mask eco gen patch flow
使用conformal LEC 进行pre-mask eco 时,如何产生patch,参考以下步骤: 官方推荐 Flattened ECO Flow(FEF) Conformal支持Flattened ECO Flow和Hierarchical ECO Flow。Flattened下,工具会将 ECO 分析重点…...
【初学人工智能原理】【4】梯度下降和反向传播:能改(下)
前言 本文教程均来自b站【小白也能听懂的人工智能原理】,感兴趣的可自行到b站观看。 本文【原文】章节来自课程的对白,由于缺少图片可能无法理解,故放到了最后,建议直接看代码(代码放到了前面)。 代码实…...

微信小程序路由传参
微信小程序路由传参 在微信小程序中,可以通过路由传参将数据传递给目标页面。以下是一种常见的方式: 在源页面中,使用 wx.navigateTo 或 wx.redirectTo 方法跳转到目标页面,并通过 URL 参数传递数据。示例: wx.navi…...
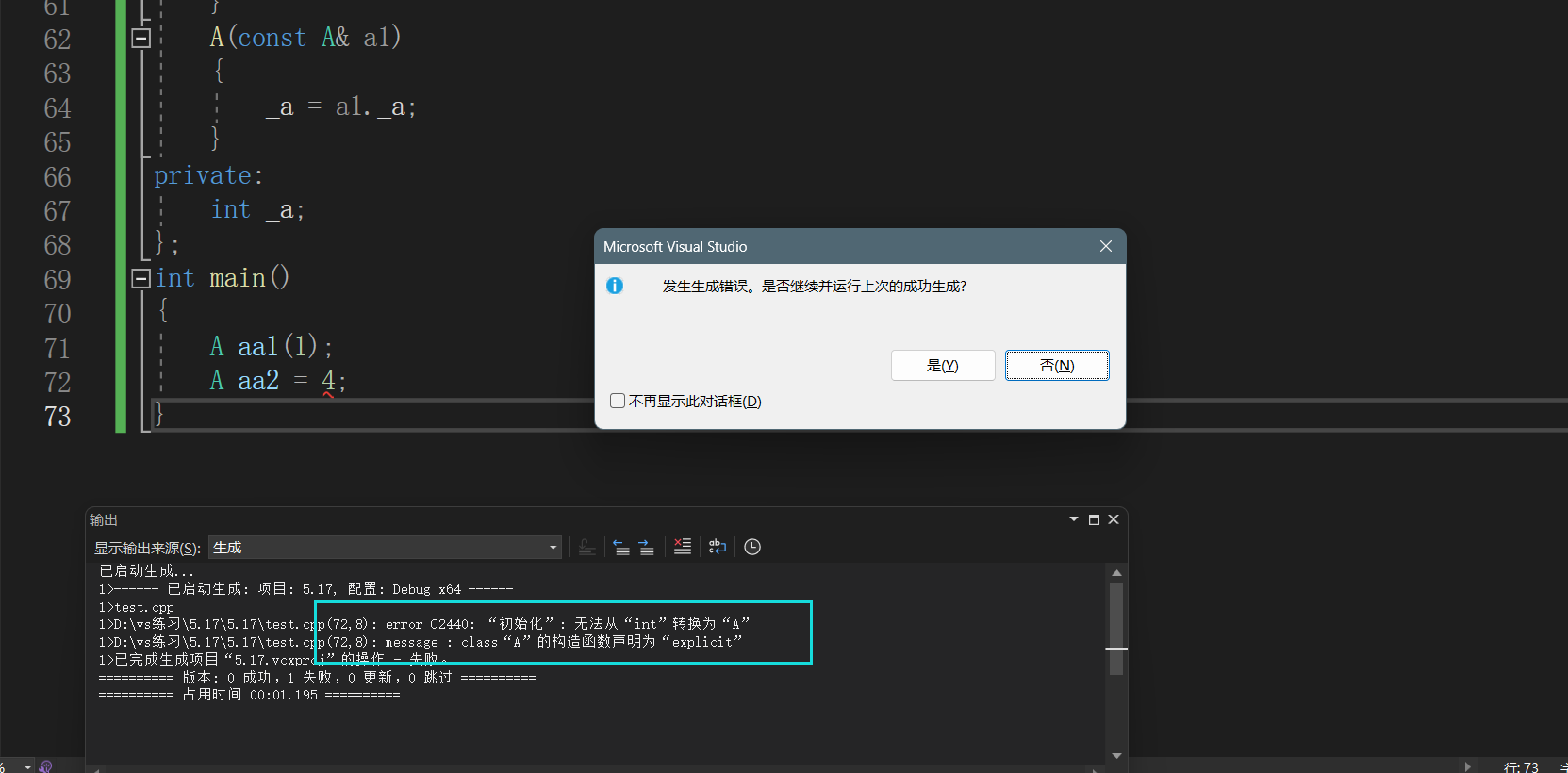
深入篇【C++】类与对象:再谈构造函数之初始化列表与explicit关键字
深入篇【C】类与对象:再谈构造函数之初始化列表与explicit关键字 Ⅰ.再谈构造函数①.构造函数体赋值②.初始化列表赋值【<特性分析>】1.至多性2.特殊成员必在性3.必走性:定义位置4.一致性5.不足性 Ⅱ.explicit关键字①.隐式类型转化②.作用 Ⅰ.再谈…...

广东棒球发展建设·棒球1号位
一、概述 棒球是一项源于美国的运动,自20世纪初开始传入中国,近年来在广东省的发展也逐渐受到关注。本文将就广东棒球的发展现状及未来发展方向进行分析。 二、发展现状 目前广东省内棒球赛事主要有以下几种: 1. 业余棒球联赛:…...

浅谈PMO对组织战略的支持︱美团骑行事业部项目管理中心负责人边国华
美团骑行事业部项目管理中心负责人边国华先生受邀为由PMO评论主办的2023第十二届中国PMO大会演讲嘉宾,演讲议题:浅谈PMO对组织战略的支持。大会将于6月17-18日在北京举办,更多内容请浏览会议日程 议题内容简要: 战略是组织运行的…...

互联网医院资质代办|互联网医院牌照的申请流程
随着互联网技术的不断发展,互联网医疗已经逐渐成为人们关注的热点话题。而互联网医院作为互联网医疗的一种重要形式,也越来越受到社会各界的关注。若想开展互联网医院业务,则需要具备互联网医院牌照。那么互联网医院牌照的申请流程和需要的资…...

网络:DPDK复习相关知识点_2
1.RTC运行至完成时模式,单核单模块 2.pipeline模式,多核多模块,每个模块都是一个处理引擎,但会有缓存一致性问题 3.Mbuff数据包内存操作对象,相当于是数据包的一个索引,对网络的处理都集中在这个Buff上 …...

阿里云大学考试Java中级题目及解析-java中级
阿里云大学考试Java中级题目及解析 1.servlet释放资源的方法是? A.int()方法 B.service()方法 C.close() 方法 D.destroy()方法 D servlet释放资源的方法是destroy() 2.order by与 group by的区别? A.order by用于排序,group by用于排序…...
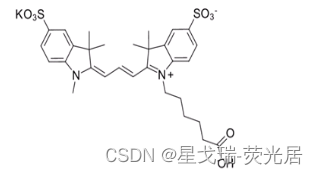
【星戈瑞】Sulfo-CY3-COOH磺化/水溶性Cyanine3羧酸1121756-11-3
Sulfo-CY3 COOH是一种荧光染料,其分子结构中含有COOH官能团,最大吸收波长为550纳米左右,可以通过分光光度计等设备进行检测。Sulfo-CY3 COOH是一种带有羧基的荧光染料,可以与含有氨基的生物分子通过偶联反应形成共价键,…...

Java NIO和IO的主要区别
当学习了Java NIO和IO的API后,一个问题马上涌入脑海: 我应该何时使用IO,何时使用NIO呢?在本文中,我会尽量清晰地解析Java NIO和IO的差异、它们的使用场景,以及它们如何影响您的代码设计。 下表总结了Java N…...

SQL查询语句
DQL语句--排序查询 # 格式: select * from 表名 order by 要排序的列1 [asc/desc], 要排序的列2 [asc/desc]; # 解释: # 1. 无论SQL语句简单或者是复杂, order by语句一般都放最后, 注意: 如果有limit(分页), 则它(limit)在最后. # 2. asc表示升序, desc表示降序, 其中, 默…...
四象限法进程调度
周二收到一篇推送 一次云上网络毫秒级的优化与实践,很有意义的实践和探索,建议阅读,文章不长,没有冗长的源码分析,结论很清晰。 谈谈我的看法。 多少有种感觉,Linux 越来越像个响应系统而不是服务器。 虚…...
蓝桥杯拿到一等奖,并分享经验
昨天和群里的小伙伴在群里聊,有的小伙伴竟然说蓝桥杯一等奖没有含量,我也是醉了! 就像去年看了一个号主写的:研究生遍地都是! 放眼全国14亿人口,别说研究生了,本科生占比有多少? “蓝桥杯是我人生中得到…...
)
vue3。 Cannot use JSX unless the ‘–jsx’ flag is provided. ts(17004)
react用tsx或者jsx很常见,也有配套的配置 那如果是vue呢? 默认是没问题的,可是我用了jsdoc,并开启了checkjs,然后vscode就爆红了 谷歌,百度,一个晚上 查到的答案: 推荐我新增tsco…...

HVV面试题目总结
蓝队 如何识别安全设备中的无效告警? 常见的端口有哪些? 这些端口对应的服务是什么? 针对这些服务,红队攻击方式有哪些? 常用的威胁情报平台有哪些? 有没有做过关于情报输出的工作? 木马驻留系统的方式有哪些? 当收到钓鱼邮件的时候,说说处置思路…...

Access denied for user ‘root‘@‘localhost‘ (using password:YES) 解决方案
文章目录 问题描述解决方案: 问题描述 Access denied for user ‘root’‘localhost’:拒绝用户’root’localhost’的访问。 出现这个报错语句的一般原因是输入了错误的密码,也有可能是是root帐户默认不开放远程访问权限。 相关的解决方法是重新设置…...
为什么C++这么复杂还不被淘汰?
C是一门广泛使用的编程语言,主要用于系统和应用程序的开发。尽管C具有一些复杂的语法和概念,但它仍然是编程界的重量级选手,在编程语言排行榜中一直位居前列。为什么C这么复杂还不被淘汰呢? C有以下优势 1、C具有高性能 C是一门编…...

SwitchyOmega+Burp无感抓包实战:解决HTTPS拦截与流量路由难题
1. 为什么“无感抓包”是BurpSuite日常使用的分水岭刚接触Web安全测试的朋友常有个错觉:装上Burp Suite,配好代理,打开浏览器,点几下网页——流量就该自动进来了。结果现实是:首页打不开、登录态丢失、HTTPS报错满屏、…...

2026 新视角:化妆品开发的底层逻辑,做好一款产品,从选对原料开始
在化妆品研发链条中,配方架构、生产工艺、包装设计固然重要,但决定一款产品上限的,永远是原料。一款稳定、安全、表现优异的护肤成品,离不开纯净、达标、批次一致的优质原料。对于品牌方、配方师、代工企业而言,原料不…...

如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南
如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI UAss…...

解决Claude Code访问不稳定与Token不足的痛点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code访问不稳定与Token不足的痛点 许多开发者将Claude Code作为日常编程的得力助手,用于代码生成、问题调试…...

WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案
WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专…...

通过curl命令快速测试Taotoken大模型API的连通性与返回格式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken大模型API的连通性与返回格式 在集成大模型能力到应用时,开发者通常需要一种快速、轻量的…...

告别DLL缺失烦恼!Visual C++运行库合集一键搞定Windows应用依赖问题
告别DLL缺失烦恼!Visual C运行库合集一键搞定Windows应用依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在打开某个软件或游戏时…...

【DeepSeek漏洞扫描辅助实战指南】:20年安全专家亲授3大避坑法则与5步提效流程
更多请点击: https://intelliparadigm.com 第一章:DeepSeek漏洞扫描辅助的核心价值与适用边界 DeepSeek漏洞扫描辅助并非通用型渗透测试引擎,而是一个聚焦于大语言模型(LLM)应用层安全的轻量级分析工具。其核心价值在…...

3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南
3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的…...

完整指南:如何在5分钟内快速上手BioAge生物年龄计算工具包
完整指南:如何在5分钟内快速上手BioAge生物年龄计算工具包 【免费下载链接】BioAge Biological Age Calculations Using Several Biomarker Algorithms 项目地址: https://gitcode.com/gh_mirrors/bi/BioAge BioAge生物年龄计算工具包是一款基于R语言开发的强…...