一文实现部署AutoGPT
一文实现部署AutoGPT
- 简介
- AutoGPT的概述
- AutoGPT的用途和优势
- 预备知识
- Python基础
- 机器学习基础
- 自然语言处理基础
- 环境设置
- Python环境安装和配置
- 需要的库和框架的安装,例如PyTorch, Transformers等
- AutoGPT模型加载
- 如何下载和加载预训练的AutoGPT模型
- 模型参数和配置
- 使用AutoGPT进行预测
- 构建输入数据
- 使用模型进行预测
- 解析模型输出
- 测试模型
- 创建测试数据集
- 使用测试数据集进行测试
- 评估模型性能
- 部署模型
- 创建API接口
- 集成模型到API
- 测试API接口
- 优化和调试
- 性能优化技术
- 常见错误和解决方法
- 结论
- AutoGPT的可能应用
- 对AutoGPT的未来展望
- 参考资料
简介
在当今的人工智能领域,大规模的预训练模型已经显示出他们在各种任务中的强大能力。其中,AutoGPT作为GPT系列的新成员,继承了其先辈们的优良传统,并引入了新的特性,为我们提供了新的机会和可能
AutoGPT的概述
AutoGPT是OpenAI基于GPT-4架构开发的大规模预训练模型。它以Transformer为基础,通过在大量文本数据上进行无监督学习,让模型理解人类的语言,包括语法、情感、事实和一些常识。训练完成后,它可以生成连贯的、符合上下文的文本,甚至进行问题回答、写文章、编程等复杂任务。
与GPT-3相比,AutoGPT在模型规模、训练数据和一些技术细节上有所提升,以提高模型的性能和效率。特别的,它还引入了一些自动化的特性,比如自动微调,使得模型能更好地适应各种具体任务。
AutoGPT的用途和优势
作为一种大规模的预训练模型,AutoGPT具有广泛的用途。它可以用于文本生成,包括写文章、写诗、写代码等。它还可以用于问答系统,帮助人们获取他们需要的信息。此外,它还可以用于聊天机器人,提供自然、友好的对话体验。
AutoGPT的优势主要来自于它的大规模和预训练。首先,通过在大量文本数据上训练,模型可以学习到丰富的语言知识,使得它在处理各种文本任务时具有很高的能力。其次,预训练的模型可以直接使用,或者进行简单的微调,从而大大减少了开发和训练的时间和资源。这使得我们可以更快、更有效地开发和部署AI系统。
另外,AutoGPT的自动化特性也是其优势之一。通过自动微调,模型可以更好地适应具体任务,从而提高性能。这让我们在使用模型时,可以更多地关注于任务本身,而不是模型的细节。
总的来说,AutoGPT以其强大的能力和高效的性能,已经成为了人工智能领域的重要工具。通过学习和部署AutoGPT,我们可以更好地利用AI的力量,开发出更多的创新应用。
预备知识
在我们开始深入部署AutoGPT之前,我们需要确保对一些基础知识有所理解和掌握。这包括Python编程语言的基础,机器学习的基本概念,以及自然语言处理的原理和技术
Python基础
Python是一种广泛使用的高级编程语言,以其清晰的语法和强大的功能在科学计算和数据分析中特别受欢迎。为了有效地使用AutoGPT,我们需要理解Python的基础知识,包括变量、数据类型、控制结构、函数、类等。此外,我们还需要熟悉一些Python的科学计算库,如NumPy和Pandas,以及深度学习框架,如PyTorch或TensorFlow。
机器学习基础
机器学习是人工智能的一个重要分支,通过让机器从数据中学习,我们可以使其完成各种复杂的任务。AutoGPT是一种基于机器学习的模型,因此,理解机器学习的基本概念和方法是非常重要的。这包括有监督学习、无监督学习、强化学习,以及一些常见的算法,如线性回归、决策树、支持向量机和神经网络等。
自然语言处理基础
自然语言处理(NLP)是人工智能的一个重要领域,它让计算机能理解和生成人类的语言。AutoGPT是一种自然语言处理模型,因此,我们需要理解自然语言处理的基本技术和原理,包括词袋模型、词嵌入、语言模型、序列到序列模型等。此外,我们还需要理解一些更高级的技术,如Transformer和注意力机制,它们是AutoGPT的核心技术。
在我们掌握了这些基础知识后,我们就可以开始部署AutoGPT了。在接下来的章节中,我们将详细介绍如何在Python环境中加载和使用AutoGPT,如何创建API接口,以及如何进行模型的测试和优化。
环境设置
在开始部署AutoGPT之前,我们需要准备好我们的编程环境。这包括Python环境的安装和配置,以及需要的库和框架的安装。
Python环境安装和配置
首先,我们需要安装Python。Python有多个版本,但是在此我们推荐使用Python 3.7或更高版本,因为这些版本提供了更好的功能和支持。你可以从Python官网(https://www.python.org/)下载最新的Python版本,并按照指示进行安装。
安装Python后,我们需要配置Python环境。这通常涉及到设置环境变量,以便我们可以在命令行中方便地运行Python。此外,我们还推荐使用虚拟环境,例如venv或conda,它可以帮助我们管理不同项目的依赖,避免库版本之间的冲突。
需要的库和框架的安装,例如PyTorch, Transformers等
安装和配置好Python环境后,我们需要安装一些库和框架,以便我们使用AutoGPT。
首先,我们需要安装PyTorch。PyTorch是一个强大的深度学习框架,提供了丰富的功能和高性能的计算。你可以从PyTorch官网(https://pytorch.org/)下载和安装PyTorch。在安装时,请根据你的系统和硬件选择合适的版本。
其次,我们需要安装Transformers库。Transformers是Hugging Face公司开发的一个库,提供了大量预训练的NLP模型,包括AutoGPT。你可以使用pip进行安装,命令如下:
pip install transformers
请注意,如果你在虚拟环境中,你应该在虚拟环境激活的情况下运行这个命令。如果你没有使用虚拟环境,你可能需要使用sudo进行安装。
在完成了这些设置后,我们就准备好开始部署AutoGPT了。在接下来的章节中,我们将详细介绍如何加载和使用AutoGPT,如何创建API接口,以及如何进行模型的测试和优化。
AutoGPT模型加载
部署AutoGPT首先需要加载预训练好的模型。OpenAI提供了预训练的AutoGPT模型,我们可以很容易地下载并加载它。
如何下载和加载预训练的AutoGPT模型
Hugging Face的Transformers库提供了方便的API来下载和加载预训练的AutoGPT模型。以下是Python代码示例:
from transformers import AutoTokenizer, AutoModelWithLMHead# AutoGPT的模型名,你需要替换为实际的模型名
model_name = "openai/autogpt-base"# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_name)# 加载模型
model = AutoModelWithLMHead.from_pretrained(model_name)
在这个代码中,我们首先导入了需要的库。然后,我们使用AutoTokenizer.from_pretrained和AutoModelWithLMHead.from_pretrained方法下载并加载了分词器和模型。这两个方法都需要一个模型名,你需要替换为实际的AutoGPT模型名。这些模型名可以在Hugging Face的模型库中找到。
模型参数和配置
AutoGPT模型有很多参数和配置,它们决定了模型的行为和性能。在加载模型后,我们可以通过模型的config属性访问这些配置。
以下是一些主要的配置和它们的含义:
- vocab_size: 词汇表的大小,决定了模型可以处理的词的种类。
- hidden_size: 隐藏层的大小,决定了模型的复杂性和容量。
- num_attention_heads: 注意力头的数量,决定了模型在处理输入时的并行能力。
- num_layers: 层数,决定了模型的深度。
- intermediate_size: 中间层的大小,用于Transformer的前馈网络。你可以使用以下代码查看这些配置:
# 输出模型配置
print(model.config)
你可以根据你的任务和资源调整这些配置。但是请注意,修改配置可能需要重新训练模型,因此在大多数情况下,我们使用预训练模型的默认配置。
在了解了如何加载AutoGPT模型和它的配置后,我们可以开始使用模型进行预测。在接下来的章节中,我们将详细介绍如何使用AutoGPT进行预测,如何创建API接口,以及如何进行模型的测试和优化
使用AutoGPT进行预测
加载了AutoGPT模型后,我们可以使用它进行预测。这通常涉及到构建输入数据、使用模型进行预测和解析模型输出三个步骤。
构建输入数据
要使用AutoGPT进行预测,我们首先需要构建输入数据。输入数据通常是一段文本,我们需要将其转化为模型可以处理的形式。
以下是Python代码示例:
# 输入文本
text = "Hello, how are you?"# 使用分词器将文本转化为输入数据
inputs = tokenizer.encode(text, return_tensors="pt")
在这个代码中,我们首先定义了输入文本。然后,我们使用之前加载的分词器的encode方法将文本转化为模型的输入数据。return_tensors="pt"参数告诉分词器我们希望得到PyTorch张量。
使用模型进行预测
得到了输入数据后,我们就可以使用模型进行预测了。以下是Python代码示例:
# 使用模型进行预测
outputs = model.generate(inputs, max_length=50, temperature=0.7, num_return_sequences=1)
在这个代码中,我们使用模型的generate方法进行预测。我们传入了输入数据,以及一些控制生成的参数:
- max_length:控制生成文本的最大长度。
- temperature:控制生成的随机性。较高的值会使生成更随机,而较低的值会使生成更确定。
- num_return_sequences:控制生成的序列数量。
解析模型输出
预测完成后,我们需要解析模型的输出。模型的输出是一个数字序列,我们需要将其转化为文本。以下是Python代码示例:
# 解析模型输出
text = tokenizer.decode(outputs[0])
print(text)
在这个代码中,我们使用分词器的decode方法将模型的输出转化为文本。注意我们只解析了第一条输出,如果你生成了多条序列,你可能需要解析更多的输出。现在你已经知道如何使用AutoGPT进行预测了。在接下来的章节中,我们将详细介绍如何创建API接口,以及如何进行模型的测试和优化。
测试模型
在部署AutoGPT之前,我们需要对其进行测试以确认它的效果。这包括创建测试数据集,使用测试数据集进行测试,以及评估模型性能
创建测试数据集
测试数据集应该反映模型在实际应用中可能遇到的情况。这可能包括各种各样的文本,包括不同的主题、风格和复杂性。一个好的测试数据集应该包含足够的样本,以便我们可以对模型的性能有一个准确的估计。
以下是一个简单的Python代码示例,创建一个包含两个样本的测试数据集
# 测试数据集
test_data = ["Hello, how are you?","What's the weather like today?",
]
使用测试数据集进行测试
有了测试数据集后,我们就可以使用模型进行测试了。测试通常涉及到遍历测试数据集,对每个样本进行预测,并收集预测结果。
以下是Python代码示例:
# 对每个样本进行预测
for text in test_data:# 构建输入数据inputs = tokenizer.encode(text, return_tensors="pt")# 使用模型进行预测outputs = model.generate(inputs, max_length=50, temperature=0.7, num_return_sequences=1)# 解析模型输出text = tokenizer.decode(outputs[0])print(text)
在这个代码中,我们首先遍历了测试数据集。对每个样本,我们首先构建输入数据,然后使用模型进行预测,最后解析模型输出。我们将预测结果打印出来以供查看
评估模型性能
测试完成后,我们需要评估模型的性能。这通常涉及到计算一些评估指标,例如准确率、召回率、F1值等。具体的评估指标取决于你的任务和需求。
注意,对于生成任务(如文本生成),评估模型性能可能需要人工评估,因为生成的质量可能无法通过简单的指标来完全衡量。
在接下来的章节中,我们将详细介绍如何创建API接口,以及如何进行模型的优化
部署模型
完成了模型的测试和评估后,我们可以开始部署模型。这通常涉及到创建API接口,集成模型到API,以及测试API接口
创建API接口
为了让其他应用可以方便地使用我们的模型,我们通常会创建一个API接口。这个接口应该接收输入数据,将其传递给模型,然后返回模型的预测结果。
以下是一个使用Flask创建API接口的Python代码示例
from flask import Flask, request, jsonify
app = Flask(__name__)@app.route("/predict", methods=["POST"])
def predict():# 获取输入数据data = request.json# TODO: 使用模型进行预测# 返回预测结果return jsonify(results)if __name__ == "__main__":app.run(host='0.0.0.0', port=5000)
在这个代码中,我们首先创建了一个Flask应用。然后,我们定义了一个/predict路由,它接收POST请求。在这个路由中,我们首先获取输入数据,然后使用模型进行预测,最后返回预测结果。我们使用jsonify函数将预测结果转化为JSON格式。
集成模型到API
创建了API接口后,我们需要将模型集成到API中。这涉及到获取输入数据,使用模型进行预测,以及返回预测结果。
以下是Python代码示例,我们在上一个代码的基础上添加了模型的预测部分
from flask import Flask, request, jsonify
app = Flask(__name__)@app.route("/predict", methods=["POST"])
def predict():# 获取输入数据data = request.jsontext = data.get("text")# 构建输入数据inputs = tokenizer.encode(text, return_tensors="pt")# 使用模型进行预测outputs = model.generate(inputs, max_length=50, temperature=0.7, num_return_sequences=1)# 解析模型输出text = tokenizer.decode(outputs[0])# 返回预测结果return jsonify({"text": text})if __name__ == "__main__":app.run(host='0.0.0.0', port=5000)
在这个代码中,我们首先从输入数据中获取文本。然后,我们使用之前的方法构建输入数据,使用模型进行预测,解析模型输出。最后,我们将预测结果返回为JSON格式。
测试API接口
创建并集成了API接口后,我们需要进行测试以确保它可以正确工作。我们可以使用任何支持HTTP请求的工具进行测试,例如curl、Postman等。
以下是一个使用curl进行测试的命令行示例:
curl -X POST -H "Content-Type: application/json" -d '{"text":"Hello, how are you?"}' http://localhost:5000/predict
在这个命令中,我们发送了一个POST请求到http://localhost:5000/predict,请求的数据是一个包含文本的JSON对象。我们应该能看到模型的预测结果。
注意,你需要确保你的API接口已经启动并可以访问。
至此,你已经学会了如何部署AutoGPT模型。在接下来的章节中,我们将详细介绍如何进行模型的优化以提高其性能和效率。
优化和调试
部署AutoGPT模型的工作并不止于此。为了实现最佳的性能和效率,我们可能需要进行一些优化和调试。
性能优化技术
模型的性能可以通过多种方式进行优化。以下是一些常见的优化技术:
- 模型压缩:这通常涉及到减小模型的大小,以降低内存使用和提高预测速度。常见的模型压缩技术包括模型剪枝、知识蒸馏和量化。
- 批处理:批处理是一种通过一次性处理多个输入来提高效率的方法。这可以有效利用GPU的并行处理能力。
- 异步处理:异步处理可以让我们同时处理多个请求。这可以有效提高系统的吞吐量。
常见错误和解决方法
部署模型过程中可能会遇到各种问题。以下是一些常见的问题以及解决方法:
- 内存溢出:如果你的模型太大,可能会导致内存溢出。解决这个问题的方法是使用较小的模型,或者优化你的模型以减小其大小。
- 预测结果不准确:如果你的预测结果不准确,可能是因为模型没有正确训练或者输入数据的处理有误。你需要检查你的模型训练和数据处理代码。
- API接口无法访问:如果你的API接口无法访问,可能是因为网络问题或者服务器问题。你需要检查你的网络连接和服务器配置。
以上就是关于如何部署AutoGPT的全过程。希望这篇文章能帮到你。
结论
经过上述步骤,我们已经成功地部署了AutoGPT模型,并对其进行了优化和调试。那么,这个模型将在哪些领域发挥作用,未来又将如何发展呢?
AutoGPT的可能应用
AutoGPT模型的应用非常广泛。以下是一些可能的应用:
- 自动文本生成:AutoGPT模型可以生成各种类型的文本,包括新闻文章、博客文章、产品描述等。
- 聊天机器人:AutoGPT模型可以用于创建聊天机器人,它可以理解用户的输入,并生成有意义的回复。
- 自动编程:AutoGPT模型也可以用于自动编程,它可以帮助开发人员编写代码,从而提高开发效率。
对AutoGPT的未来展望
尽管AutoGPT模型已经非常强大,但仍有很多提升的空间。以下是对未来的一些展望:
- 更大的模型:随着硬件性能的提升,我们将能够训练更大的模型,从而得到更准确的预测结果。
- 更好的优化技术:随着深度学习技术的发展,我们将有更多的优化技术,这将让我们的模型更小、更快、更准确。
- 更多的应用:随着人工智能的发展,我们将找到更多的应用场景。这将使我们的模型能够在更多的领域发挥作用。
参考资料
The Illustrated GPT-2 (Visualizing Transformer Language Models)
OpenAI’s Documentation
相关文章:

一文实现部署AutoGPT
一文实现部署AutoGPT 简介AutoGPT的概述AutoGPT的用途和优势 预备知识Python基础机器学习基础自然语言处理基础 环境设置Python环境安装和配置需要的库和框架的安装,例如PyTorch, Transformers等 AutoGPT模型加载如何下载和加载预训练的AutoGPT模型模型参数和配置 使…...
数值计算 - 误差的来源
误差的来源是多方面的,但主要来源为:过失误差,描述误差,观测误差,截断误差和舍入误差。 过失误差 过失误差是由设备故障和人为的错误所产生的误差,在由于每个人都有“权利”利用机器进行数值计算,所以在计算…...
【软件测试】5年测试老鸟总结,自动化测试成功实施,你应该知道的...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 自动化测试 Pytho…...
【Hadoop】二、Hadoop MapReduce与Hadoop YARN
文章目录 二、Hadoop MapReduce与Hadoop YARN1、Hadoop MapReduce1.1、理解MapReduce思想1.2、Hadoop MapReduce设计构思1.3、Hadoop MapReduce介绍1.4、Hadoop MapReduce官方示例1.5、Map阶段执行流程1.6、Reduce阶段执行流程1.7、Shuffle机制 2、Hadoop YARN2.1、Hadoop YARN…...

Python教程:文件I/O的用法
本章只讲述所有基本的的I/O函数,更多函数请参考Python标准文档。 1.打印到屏幕 最简单的输出方法是用print语句,你可以给它传递零个或多个用逗号隔开的表达式。此函数把你传递的表达式转换成一个字符串表达式,并将结果写到标准输出如下&…...

序员工作1年,每天上班清闲,但却焦虑万分,若是你,你会吗?
有个学弟在后台留言 他谈到了自己去年毕业的 因为在大学里边有一些校企合作 所以呢他也是花了钱 然后去培训了有半年 去年毕业之后到现在工作有一年了 那目前的薪资是8,000块钱 虽然说相较于其他同学呢 这个薪资呢还算可以 但是呢 自己每天现在就处于一种非常 压抑的那种状态 所…...

Bed Bath and Beyond EDI 需求分析
Bed Bath and Beyond(Bed Bath and Beyond)是一家美国的家居用品零售商,成立于1971年,总部位于新泽西州Union。该公司在美国、加拿大和墨西哥拥有超过1500家门店。其产品涵盖了床上用品、浴室用品、厨房用品、家居装饰等领域&…...
【5.20】五、安全测试——渗透测试
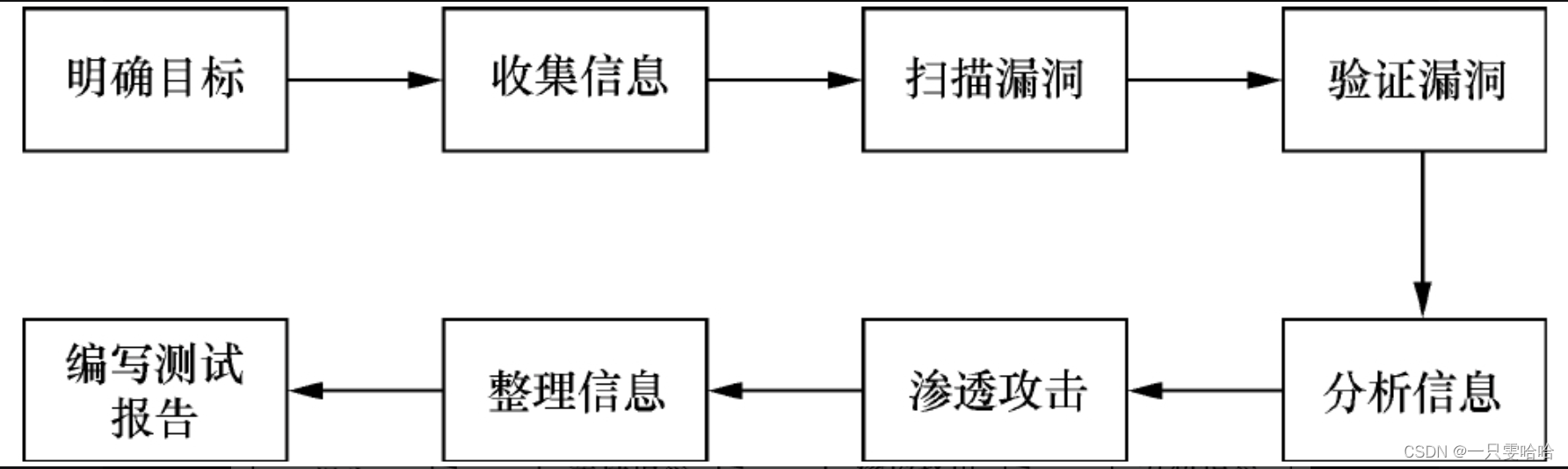
目录 5.3 渗透测试 5.3.1 什么是渗透测试 5.3.2 渗透测试的流程 5.3 渗透测试 5.3.1 什么是渗透测试 渗透测试是利用模拟黑客攻击的方式,评估计算机网络系统安全性能的一种方法。这个过程是站在攻击者角度对系统的任何弱点、技术缺陷或漏洞进行主动分析&#x…...
java版鸿鹄工程项目管理系统 Spring Cloud+Spring Boot+前后端分离构建工程项目管理系统源代码
鸿鹄工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离构建工程项目管理系统 1. 项目背景 一、随着公司的快速发展,企业人员和经营规模不断壮大。为了提高工程管理效率、减轻劳动强度、提高信息处理速度和准确性,公司对内部工程管…...

大语言模型架构设计
【大模型慢学】GPT起源以及GPT系列采用Decoder-only架构的原因探讨 - 知乎本文回顾GPT系列模型的起源论文并补充相关内容,中间主要篇幅分析讨论为何GPT系列从始至终选择采用Decoder-only架构。 本文首发于微信公众号,欢迎关注:AI推公式最近Ch…...
SpringBoot整合Swagger2,让接口文档管理变得更简单
在软件开发的过程中,接口文档的编写往往是一个非常重要的环节,因为它是前端和后端沟通的桥梁,帮助团队更好地协作。然而,手动编写接口文档不仅耗费时间,还容易出错,因此我们需要一种简单的方法来管理接口文…...

socket | 网络套接字、网络字节序、sockaddr结构
欢迎关注博主 Mindtechnist 或加入【Linux C/C/Python社区】一起学习和分享Linux、C、C、Python、Matlab,机器人运动控制、多机器人协作,智能优化算法,滤波估计、多传感器信息融合,机器学习,人工智能等相关领域的知识和…...

golang-websocket
WebSocket 是一种新型的网络通信协议,可以在 Web 应用程序中实现双向通信。 WebSocket与HTTP协议的主要区别是: HTTP 和 WebSocket 协议的区别 HTTP 是单向的,而 WebSocket 是双向的。 在客户端和服务器之间的通信中,每个来自客…...
Nginx + fastCGI 实现动态网页部署
简介 本文章主要介绍下,如何通过Nginx fastCGI来部署动态网页。 CGI介绍 在介绍fastCGI之前先介绍下CGI是什么。CGI : Common Gateway Interface,公共网关接口。在物理层面上是一段程序,运行在服务器上,提供同客户端HTML页面的…...

精彩回顾 | Fortinet Accelerate 2023·中国区巡展厦门站
Fortinet Accelerate 2023中国区 5月16日,Fortinet Accelerate 2023中国区巡展来到魅力“鹭岛”——厦门,技术、产品和业务专家,携手亚马逊云科技、唯一网络等云、网、安合作伙伴,与交通、物流、金融等各行业典型代表客户&#x…...

ChatGPT 和对话式 AI 的未来:2023 年的进展和应用
人工智能(Artificial Intelligence)在过去一段时间以来以前所未有的速度快速发展。从自动化日常任务到重要提醒的设定,AI以各种方式渗透到我们的生活中。然而,在这个领域中迈出的最重要一步是ChatGPT。 ChatGPT被瑞银(UBS)评为“有史以来增长最快的消费者应用程序”,于…...
和WebSocket Secure(WSS)的完整指南)
Nginx配置WebSocket(WS)和WebSocket Secure(WSS)的完整指南
😀点点关注~ 😀点点关注~ 😀点点关注~ Nginx是一款广泛使用的高性能Web服务器和反向代理服务器。除了传统的HTTP和HTTPS协议支持外,Nginx还可以配置WebSocket(WS)和WebSocket Secure(WSS&…...
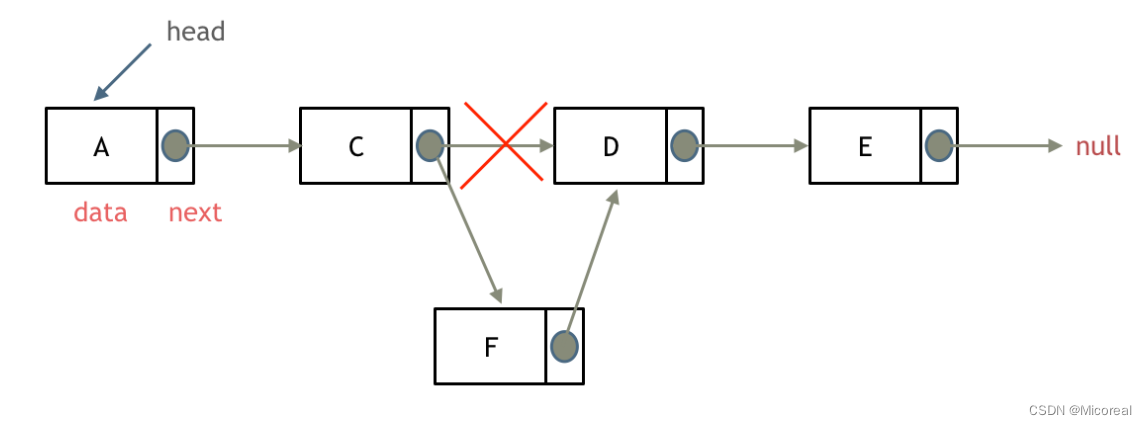
链表--part 1--链表基础理论(概括)
文章目录 单链表双链表循环链表链表链表的定义删除节点增加节点 首先什么是链表,链表是一种通过指针串联在一起的线性结构,每一个节点由两部分组成,一个是数据域一个是指针域(存放指向下一个节点的指针),最…...
【V2G】电动汽车接入电网优化调度研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
Excel中时间戳与标准日期格式的互相转换
背景 在excel中将13位毫秒级别的时间戳转换为标准的日期格式(yyyy-mm-dd hh:mm:ss.000),使用如下模板 TEXT(<source_cell>/1000/8640070*36519,"yyyy-mm-dd hh:mm:ss.000") 在excel中将10位秒级别的时间戳转换为标准的日期格式(yyyy-mm-dd hh:mm:ss…...

ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程
ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程 【免费下载链接】ZjDroid Android app dynamic reverse tool based on Xposed framework. 项目地址: https://gitcode.com/gh_mirrors/zj/ZjDroid ZjDroid是一款基于Xposed框架的Android应用动态逆向分…...

64_《智能体微服务架构企业级实战教程》授权与认证之授权认证集成测试
前言 配套视频教程: 在 Bilibili课堂、CSDN课程、51CTO学堂 同步发售,提供:源码+部署脚本+文档。 bilibili课堂视频教程:智能体微服务架构企业级实战教程_哔哩哔哩_bilibili CSDN课程视频教程:智能体微服务架构企业级实战教程_在线视频教程-CSDN程序员研修院 51CTO学堂…...

机器学习赋能6G近场通信:从信道估计到波束赋形的智能革命
1. 项目概述:当6G遇见近场,为何机器学习成为破局关键?如果你关注过5G到6G的技术演进路线,会发现一个核心趋势:天线阵列的规模正在从“大规模”走向“极大规模”。这不仅仅是数量的堆砌,更是通信物理原理的一…...

PA100K数据集实战:从下载到结构化解析全流程
1. PA100K数据集初探:为什么选择它?如果你正在研究行人属性识别,PA100K绝对是个绕不开的宝藏数据集。这个数据集包含了10万张真实监控场景下的行人图像,每张图都标注了26种常见属性——从衣着风格(比如是否穿T恤、裙子…...

Lampiao 靶场
Lampiao 靶场完整渗透解析一、靶场环境信息攻击机(Kali)IP:192.168.146.128靶机 IP:192.168.146.129目标:获取靶机 root 权限与 flag二、步骤 1:信息收集(端口与服务扫描)nmap -p- -…...

C语言双端队列完整实现:一行代码吃透头尾操作,算法效率拉满
一、为什么C语言实现双端队列,是数据结构的必学天花板?在C语言数据结构里,队列、栈都是基础中的基础,但真正能把灵活度、效率、内存管理三者揉到一起的,还得是双端队列(deque)。普通队列只能一头…...

别再死记硬背SMO公式了!用Python手写一个SVM分类器,带你一步步拆解SMO核心逻辑
用Python手写SVM分类器:代码驱动理解SMO算法核心在机器学习领域,支持向量机(SVM)以其优秀的分类性能和坚实的数学基础著称。然而,许多学习者在理解其核心算法——序列最小优化(SMO)时,往往被复杂的数学推导所困扰。本文将采用一种…...
:数组排序、去重、查找)
数组专项(一):数组排序、去重、查找
大家好,欢迎来到《算法面试60讲(2026最新版全真题带解析)》第19篇!上一篇我们彻底吃透了字符串专项的核心难点——BF暴力匹配与KMP高效匹配算法,搞定了字符串模块面试最难的算法考点。从本节课开始,我们正式进入算法面试第一高频模块:数组专项。 在算法面试中,数组是出…...

ARM架构CONSTRAINED UNPREDICTABLE行为解析与应对
1. ARM架构中的CONSTRAINED UNPREDICTABLE行为解析在处理器架构设计中,UNPREDICTABLE行为通常指架构规范未明确定义的执行结果,可能导致不可预期的系统状态。ARM架构通过引入CONSTRAINED UNPREDICTABLE机制,将这类行为限制在特定范围内&#…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...