Lift, Splat, Shoot 论文学习
1. 解决了什么问题?
LSS 在工业界具有非常重要的地位。自从 Tesla AI Day 上提出了 BEV 感知后,不少公司都进行了 BEV 工程化的探索。当前 BEV 下的感知方法大致分为两类:
- 自下而上:利用 transformer 的 query 机制,通过 BEV query 构建 BEV 特征,隐式地变换深度信息;
- 自上而下:以本文 LSS 为代表的方法,直接估计图像的深度信息,将深度信息投影到 BEV。
传统的视觉任务如图像分类不考虑帧坐标系;而目标检测和分割任务则是在同一帧的坐标系进行预测。对于自动驾驶任务,输入来自于多个传感器,帧坐标系各不相同。算法最终的输出结果会表现在一个新的坐标系里(即车辆自身 ego frame 的坐标系),以供下游任务使用。
现有的方法比较简单,对所有的输入图像分别应用单帧图像的目标检测器,然后根据相机内外参对检测结果进行平移、旋转,得到 ego frame 坐标系的结果。但由于对单帧检测器的预测结果做了后处理,我们就很难在 ego frame 对预测结果进行追溯,它到底来自于哪个传感器,也就无法根据下游任务的反馈使用反向传播来自动改进感知系统。此外,单目融合也极具挑战性,我们需要深度信息来变换到 reference frame 的坐标系,但是每个像素的深度值是不明确的。
2. 提出了什么方法?

本文提出了一个端到端、可微的方法,直接从任意相机提供的图像里面提取场景 BEV 表征。对于每个相机,先将每张图像 “lift” 为一个特征视锥(frustum of features)。然后将所有的视锥 “splat” 为一个 BEV 栅格化的网格,作为 reference plane。最后将候选轨迹 “shoot” 到该 reference plane,进行后续的端到端的运动规划。
给定输入 n n n张图像 { X k ∈ R 3 × H × W } n \lbrace \text{X}_k\in \mathbb{R}^{3\times H\times W} \rbrace_n {Xk∈R3×H×W}n,每张图像都有一个外参矩阵 E k ∈ R 3 × 4 \text{E}_k\in \mathbb{R}^{3\times 4} Ek∈R3×4和内参矩阵 I k ∈ R 3 × 3 \text{I}_k\in \mathbb{R}^{3\times 3} Ik∈R3×3,输出是 BEV 坐标系里栅格化的表征 y ∈ R C × X × Y \text{y}\in \mathbb{R}^{C\times X\times Y} y∈RC×X×Y。对于每个相机,外参和内参矩阵将 reference 坐标系的坐标 ( x , y , z ) (x,y,z) (x,y,z)映射到图像的像素坐标 ( h , w , d ) (h,w,d) (h,w,d)。

2.1 Lift: Latent Depth Estimation
模型对每个相机的图片单独计算,将每张图像从局部的 2D 坐标系 “lift” 为 3D frame,该 3D frame 被所有相机共用。
整个 lift 过程可分为三个部分。
1. 特征提取和深度估计
如上图所示,多视角相机的画面输入主干网络提取图像特征。同时利用一个深度估计网络,生成每个像素点所有可能的深度表征。这里的深度表征和图像特征的宽度和高度是相等的,因为后续要进行外积操作。 X ∈ R 3 × H × W \text{X}\in \mathbb{R}^{3\times H\times W} X∈R3×H×W是一张图像,外参是 E \text{E} E,内参是 I \text{I} I。 p p p是图像上的一个像素点,坐标为 ( h , w ) (h,w) (h,w)。每个像素点会关联 ∣ D ∣ |D| ∣D∣个点 { ( h , w , d ) ∈ R 3 ∣ d ∈ D } \lbrace (h,w,d)\in \mathbb{R}^3 | d\in D \rbrace {(h,w,d)∈R3∣d∈D}, D D D是深度值的集合,定义为 { d 0 + Δ , . . . , d 0 + ∣ D ∣ Δ } \lbrace d_0+\Delta,...,d_0+|D|\Delta \rbrace {d0+Δ,...,d0+∣D∣Δ}。为每张图像创建一个大小是 D ⋅ H ⋅ W D\cdot H\cdot W D⋅H⋅W的点云。
2. 外积
这一步是 LSS 的灵魂操作。作者在论文里多次提到,深度信息是 ambiguous,因此作者并没有直接预测每个像素点的深度值,而是预测每个像素点的深度分布,来表示像素点的深度信息。使用外积操作,用 H × W × C H\times W\times C H×W×C维度的图像特征和 H × W × D H\times W\times D H×W×D维度的深度特征构造出一个 H × W × D × C H\times W\times D\times C H×W×D×C维度的特征视锥。在像素点 p p p,主干网络预测一个 context 向量 c ∈ R C \text{c}\in \mathbb{R}^C c∈RC,深度估计网络预测一个深度值分布 α ∈ Δ ∣ D ∣ − 1 \alpha \in \Delta^{|D|-1} α∈Δ∣D∣−1。特征 c d ∈ R C \text{c}_d\in \mathbb{R}^C cd∈RC与点 p d p_d pd关联,定义为:
c d = α d ⋅ c \text{c}_d = \alpha_d \cdot \text{c} cd=αd⋅c
总之,其目的是为每张图像构建一个函数: g c : ( x , y , z ) ∈ R 3 → c ∈ R C g_c:(x,y,z)\in \mathbb{R}^3 \rightarrow \text{c}\in \mathbb{R}^C gc:(x,y,z)∈R3→c∈RC,可以在每个空间位置都得到一个 context 向量。如下图,每个相机的可见空间都对应着一个视锥。 α \alpha α和 c \text{c} c的外积计算了每个点的特征。
3. Grid Sampling
目的是将上面构造的特征视锥利用相机外参和内参转换到 BEV 视角下。限定好 BEV 视角的范围,划定一个一个的 grid,将能投影到相应 grid 的特征汇总到一个 grid 里,之后进行 splat 操作。

2.2 Splat: Pillar Pooling
“Lift” 步骤会生成一个点云。“Pillar” 是高度无穷的 voxels。每个像素点会被分到最近的 pillar,用 sum pooling 得到一个 C × H × W C\times H\times W C×H×W 张量,然后通过 CNN 来推理出 BEV。
2.3 Shoot: Motion Planning
Lift-Splat 模型使我们只需相机输入,即可实现端到端的 cost map 学习,然后进行运动规划。测试时,我们将不同的轨迹 “shoot” 到 cost map 上,计算它们的代价,然后选取代价最低的轨迹。
本文将“规划”问题看作为一个分布预测问题,车辆自身共有 K K K个模板轨迹:
T = { τ i } K = { { x j , y j , t j } T } K \mathcal{T}=\lbrace\tau_i\rbrace_K=\lbrace\lbrace x_j,y_j,t_j\rbrace_T \rbrace_K T={τi}K={{xj,yj,tj}T}K
T \mathcal{T} T由传感器数据 p ( τ ∣ o ) p(\tau|o) p(τ∣o)决定。根据这 K K K个模板轨迹,作者将规划问题当作分类问题解决。 K K K个模板轨迹的分布符合下面形式:
p ( τ i ∣ o ) = exp ( − ∑ x i , y i ∈ τ i c o ( x i , y i ) ) ∑ τ ∈ T exp ( − ∑ x i , y i ∈ τ c o ( x i , y i ) ) p(\tau_i|o)=\frac{\exp(-\sum_{x_i,y_i\in\tau_i}c_o(x_i,y_i))}{\sum_{\tau\in \mathcal{T}}\exp(-\sum_{x_i,y_i\in\tau}c_o(x_i,y_i))} p(τi∣o)=∑τ∈Texp(−∑xi,yi∈τco(xi,yi))exp(−∑xi,yi∈τico(xi,yi))
给定位置 ( x , y ) (x,y) (x,y)处的观测值 o o o,在 cost map 上进行索引,得到 c o ( x , y ) c_o(x,y) co(x,y)。对于标签,给定一个 ground-truth 轨迹,我们计算与模板轨迹 T \mathcal{T} T的 L2 距离最近的轨迹,然后用交叉熵损失训练。
如下图,在实际操作中,我们使用 K-Means 算法在大量的专家轨迹上进行聚类,得到一组模板轨迹,然后将这些模板轨迹 shoot 到预测的代价图上。训练时,计算每个模板轨迹的代价,对这些模板计算出一个 1000 维的 Boltzman 分布。测试时,选择分布的 argmax 进行后续操作。

整体流程如下,模型的输入是 n n n张图像以及对应的外参和内参。在 “lift” 步骤,每张图像会产生一个视锥点云。然后用外参和内参将每个视锥 splat 到 BEV 平面。最后,BEV CNN 计算 BEV 表征,完成 BEV 语义分割或规划任务。

3. 有什么优点?
提出了一个端到端的训练方法,解决了多传感器融合的问题。传统的多传感器先单独检测再后处理的方法,无法将此过程的损失反向传播,从而调整相机输入,而 LSS 省去了这一阶段的后处理步骤,直接输出融合结果。
- 提出了一个很好的融合到 BEV 视角的办法。基于此方法,无论是动态目标检测,还是静态道路结构感知,甚至是红绿灯检测,前车转向检测等信息,都可以用该方法提取到 BEV 特征下进行输出,极大提高了自动驾驶感知框架的集成度;
- 虽然 LSS 初衷是为了融合多视角相机特征,为纯视觉模型服务。但在实际应用中,此方法完全兼容其它传感器的特征融合;
4. 有什么缺点?
- 极度依赖深度信息的准确性,必须显式地提供深度信息。如果直接使用此方法通过梯度反传来优化深度网络,而深度估计网络又比较复杂,会因为反传链过长而导致优化方向模糊,难以取得理想效果。
- 外积操作耗时。当图片的特征图较大时,且想要预测的深度距离和精细度高时,外积这一操作带来的计算量则会大大增加。这十分不利于模型的轻量化部署,而这一点上,Transformer 的方法反而还稍好一些。
相关文章:
Lift, Splat, Shoot 论文学习
1. 解决了什么问题? LSS 在工业界具有非常重要的地位。自从 Tesla AI Day 上提出了 BEV 感知后,不少公司都进行了 BEV 工程化的探索。当前 BEV 下的感知方法大致分为两类: 自下而上:利用 transformer 的 query 机制,…...
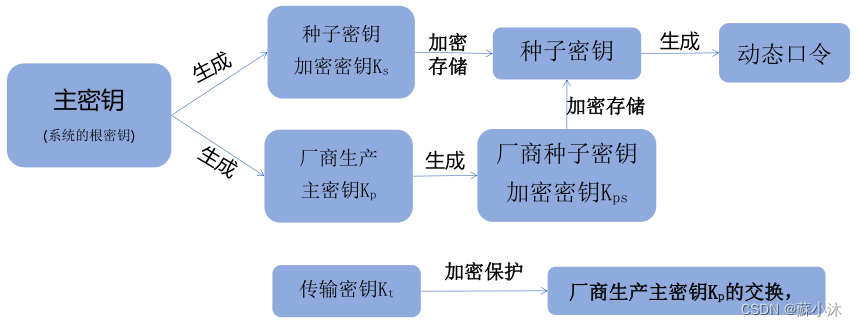
【密码产品篇】动态口令系统密钥体系结构(SM3、SM4)
【密码产品篇】动态口令系统密钥体系结构(SM3、SM4) 动态口令是一种一次性口令机制,用户无须记忆口令,也无须手工更改口令。口令通过用户持有的客户端器件生成,并基于一定的算法与服务端形成同步,从而作为…...

PDF工具Adobe Arcrobat Pro DC下载安装教程
wx供重浩:创享日记 对话框发送:adobe 免费获取Adobe Arcrobat Pro DC安装包 Acrobat是一款PDF(Portable Document Format,便携式文档格式)编辑软件。借助它,您可以以PDF格式制作和保存你的文档 ,…...

大量从IT培训班出来的程序员们最后都怎样了?
在当今信息时代,IT行业越来越受到人们的关注。越来越多的年轻人选择进入IT行业学习编程技术,而IT培训班也因此应运而生。据统计,在中国,每年约有100万人通过各种途径进入IT行业。其中,通过IT培训班获得技能认证的人数也…...

【论文阅读笔记】Federated Unlearning with Knowledge Distillation
个人阅读笔记,如有错误欢迎指出 Arxiv 2022 [2201.09441] Federated Unlearning with Knowledge Distillation (arxiv.org) 问题: 法律要求客户端有随时要求将其贡献从训练中消除的权利 让全局模型忘记特定客户的贡献的一种简单方法是从头开始对模型进…...
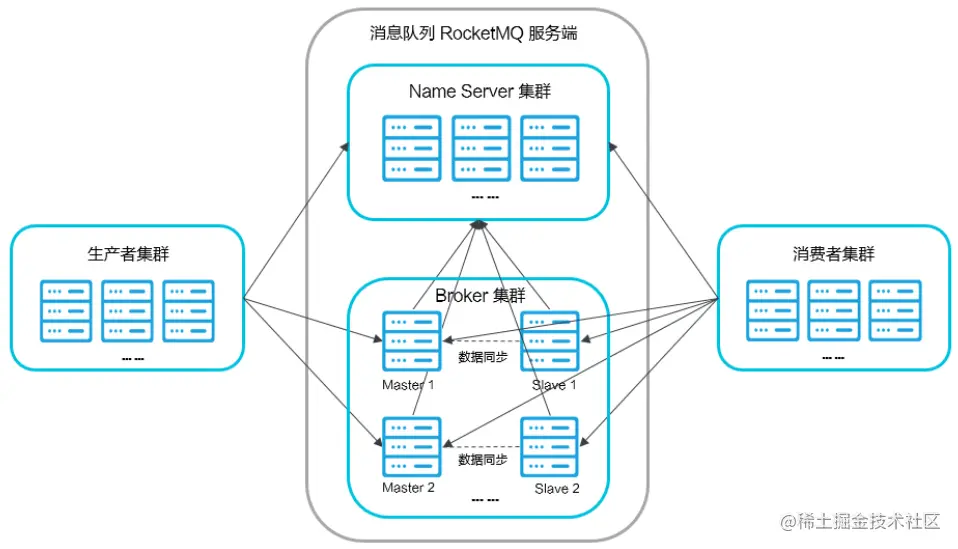
常用MQ介绍与区别
RabbitMQ RabbitMQ是实现AMQP协议(0.9.1) 的消息中间件的一种,由RabbitMQ Technologies Ltd开发并且提供商业支持的,最初起源于金融系统,服务器端用Erlang语言编写,用于在分布式系统中存储转发消息,在易用性、扩展性、…...

今天面试招了个20K的人,从腾讯出来的果然都有两把刷子···
现在找个会自动化测试的人真是难呀,10个里面有8个写了会自动化,但一问就是三不知 公司前段时间缺人,也面了不少测试,前面一开始瞄准的就是中级的水准,也没指望来大牛,提供的薪资在15-20k,面试的…...
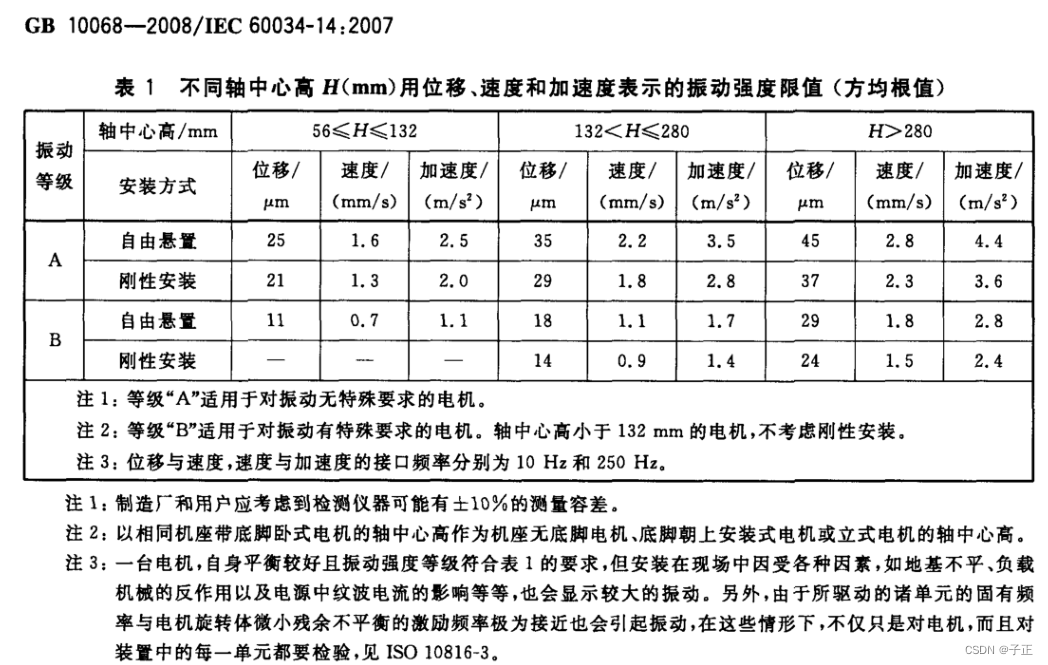
加速度传感器的量程估算
下面推导过程中包含一个重要的错误:sinx/x1没有错,但是这里的x是 t,当x t时,位移并非sin(t),而是n*sin(t),我稍後修訂。 在测震动和噪声的场合,现有的加速度传感器,需要客户提供加…...
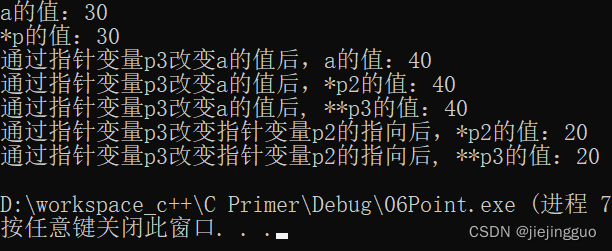
0601-指针的基础
内存 物理存储器和存储地址空间 物理存储器:实际存在的具体存储器芯片。比如:内存条、RAM芯片、ROM芯片。 存储地址空间:对存储器编码的范围。 编码:对每个物理存储单元(一个字节)分配一个号码寻址&…...

关于K8S库中高可用的锁机制详解
简介 对于无状态的组件来说,天然具备高可用特性,无非就是多开几个副本而已;而对于有状态组件来说,实现高可用则要麻烦很多,一般来说通过选主来达到同一时刻只能有一个组件在处理业务逻辑。 在Kubernetes中,…...

常用中外文献检索网站大盘点
一、常用中文文献检索权威网站: 1、知网:是全球最大的中文数据库。提供中国学术文献、外文文献、学位论文、报纸、会议、年鉴、工具书等各类资源,并提供在线阅读和下载服务。涵盖领域包括:基础科学、文史哲、工程科技、社会科学、…...

公司招了一个00后,以为是个小年轻,没想到人家是个卷王...
公司前段缺人,也面了不少测试,结果竟然没有一个合适的。一开始瞄准的就是中级的水准,也没指望来大牛,提供的薪资也不低,面试的人很多,但平均水平很让人失望。 令我印象最深的是一个00后测试员,…...

数字化转型难?怎么转?听听厂商、CIO、CEO怎么说
数字化转型已经成为当今商业领域中的热门话题。对于许多企业来说,数字化转型是一项重要而且必不可少的战略,以适应快速变化的市场环境并保持竞争力。然而,数字化转型并不是一项容易的任务,它涉及到许多方面,需要综合考虑技术、组织和文化等因素。那么,让我们来听听一些厂…...

C++面试题汇总
C面试题汇总 1. new/delete和malloc/free:2. delete和delete[]:3. 常引用:4. overload、override、overwrite的介绍5. C是不是类型安全的?6. main 函数执行以前,还会执行什么代码?7. 数组与指针的区别&…...

OpenAi编写基于Python+OpenCV的人脸识别实现带墨镜效果
要基于Python和OpenCV实现带墨镜效果的人脸识别,你可以按照以下步骤进行操作: 安装所需的库:确保你已经安装了Python和OpenCV库。你可以使用pip命令来安装OpenCV库:pip install opencv-python。 导入必要的库:在Pytho…...

安卓闲谈吹水
一、熟练掌握 Java 语言,面向对象分析设计能力,反射原理,自定义注解及泛型,多次采用设计模式重构项目 首先我们先了解什么是对象。 1.对象是由我们自己定义的类来创建出来的。 2.对象实际上就是类的具体实现。 (对象是类的一个实…...

测试类的使用
1.在pom文件中添加依赖 <dependencies> <dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>compile</scope> </dependency> </dependencies>2.在s…...

【物联网技术对生活的影响与展望】
随着科技日新月异的发展,物联网(IoT)技术正在快速地影响着我们的生活。它是将各种设备和物品连接在一起,通过互联网使它们可以相互交流和传递数据的技术。它的应用范围广泛,可以涵盖从智能家居到工业网络的各个领域。 …...

MySQL数据库函数详解及示例
以下是一份按照常见MySQL数据库函数,并且包含函数示例: 字符串函数 字符串函数用于处理和操作文本数据。 CONCAT:将多个字符串连接为一个字符串。SUBSTRING:提取字符串的一部分。LENGTH:返回字符串的长度。REPLACE&…...
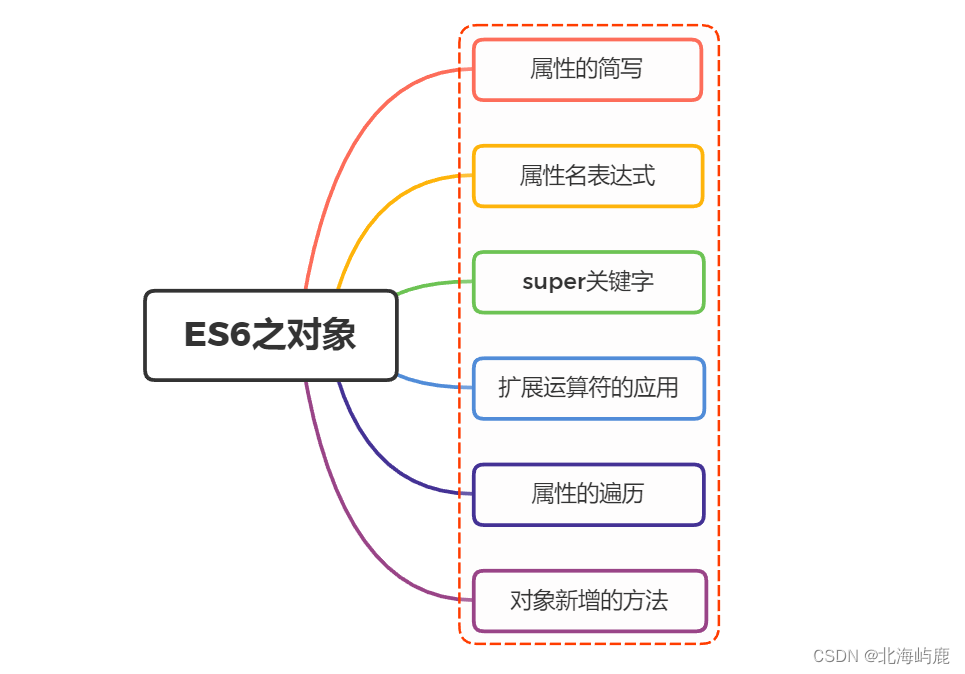
ES6对象新增了哪些扩展?
一、属性的简写 ES6中,当对象键名与对应值名相等的时候,可以进行简写 const baz {foo:foo}// 等同于 const baz {foo} 方法也能够进行简写 const o {method() {return "Hello!";} };// 等同于const o {method: function() {return &qu…...

除了ulimit -c unlimited:深入理解Linux core dump机制与高级配置指南
深入Linux核心转储:从基础配置到生产环境实战指南当服务器上的关键应用突然崩溃时,系统管理员最需要的就是一份完整的"事故现场记录"。Linux的core dump机制正是为此而生,它能保存程序崩溃时的内存状态、寄存器值和调用堆栈&#x…...

BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行
BetterJoy完整配置指南:5分钟让Switch手柄在PC上完美运行 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...
)
保姆级教程:Windows系统下Arcgis 10.2从下载、安装到汉化一次搞定(附常见License启动失败解决方案)
Windows系统下Arcgis 10.2完整安装与汉化实战指南第一次接触Arcgis的新手往往会被复杂的安装流程和神秘的License Manager搞得晕头转向。作为一款功能强大的地理信息系统软件,Arcgis在科研、城市规划、环境监测等领域有着广泛应用,但它的安装过程确实会让…...

Windows文件夹共享
目标:同一局域网实现在一台计算机上共享文件夹,在另一台电脑访问一、电脑A 1.点击要共享的文件夹 -> 属性 -> 共享2.添加Everyone用户组3.控制面板中网络共享关闭密码保存,在访问时不用输入账号密码。二、电脑B 1.在文件资源管理器路径…...

styled-theming 性能优化:如何避免主题切换时的性能瓶颈
styled-theming 性能优化:如何避免主题切换时的性能瓶颈 【免费下载链接】styled-theming Create themes for your app using styled-components 项目地址: https://gitcode.com/gh_mirrors/st/styled-theming styled-theming 是一个专为 styled-components …...

解决方法:庐山派K230接串口没识别到端口问题
一、插入usb转串口工具之前二、插入usb转串口工具之后三、解决方法说明:🔍 核心原因:USB Serial 设备,没有被识别为 COM 口你现在看到的 USB Serial,说明开发板已经正常启动了,USB 也被电脑识别到了&#x…...
)
Windows开机自动全屏打开指定网页?一个快捷方式参数就搞定(Chrome/Edge/Firefox教程)
Windows开机自动全屏展示网页的终极方案每次开机都要手动打开浏览器、输入网址、切换全屏模式?这种重复操作不仅浪费时间,还容易在重要演示时手忙脚乱。想象一下:电脑启动后自动全屏显示你的仪表盘、会议日程或是监控大屏,整个过程…...

用PyTorch复现FactorVAE:一个能同时预测收益和风险的量化模型实战教程
用PyTorch实战FactorVAE:构建收益与风险双预测的量化模型 在量化投资领域,传统线性因子模型正逐渐被非线性机器学习方法所取代。然而金融数据特有的低信噪比特性,使得直接从市场数据中提取有效因子成为一项艰巨挑战。本文将深入探讨如何利用P…...

中小企无需重型数据中台:轻量化数据体系搭建完整方案
过去几年,“数据中台”一度成为企业数字化的标配热词。大量中小企业盲目跟风搭建重型数据中台,投入高额成本、耗费数月甚至数年周期,最终落地效果极差:功能冗余、运维复杂、使用率低、投入产出比失衡。大量项目最终沦为“摆设式中…...