Java面试知识点(全)-Java并发-多线程JUC三- JUC集合/线程池
Java面试知识点(全)
导航: https://nanxiang.blog.csdn.net/article/details/130640392
注:随时更新
JUC集合类
为什么HashTable慢? 它的并发度是什么? 那么ConcurrentHashMap并发度是什么?
Hashtable之所以效率低下主要是因为其实现使用了synchronized关键字对put等操作进行加锁,而synchronized关键字加锁是对整个对象进行加锁,也就是说在进行put等修改Hash表的操作时,锁住了整个Hash表,从而使得其表现的效率低下。
ConcurrentHashMap在JDK1.7和JDK1.8中实现有什么差别? JDK1.8解決了JDK1.7中什么问题
- HashTable : 使用了synchronized关键字对put等操作进行加锁;
- ConcurrentHashMap JDK1.7: 使用分段锁机制实现;
- ConcurrentHashMap JDK1.8: 则使用数组+链表+红黑树数据结构和CAS原子操作实现;
ConcurrentHashMap JDK1.7实现的原理是什么
在JDK1.5~1.7版本,Java使用了分段锁机制实现ConcurrentHashMap.
简而言之,ConcurrentHashMap在对象中保存了一个Segment数组,即将整个Hash表划分为多个分段;而每个Segment元素,它通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全;这样,在执行put操作时首先根据hash算法定位到元素属于哪个Segment,然后对该Segment加锁即可。因此,ConcurrentHashMap在多线程并发编程中可是实现多线程put操作。
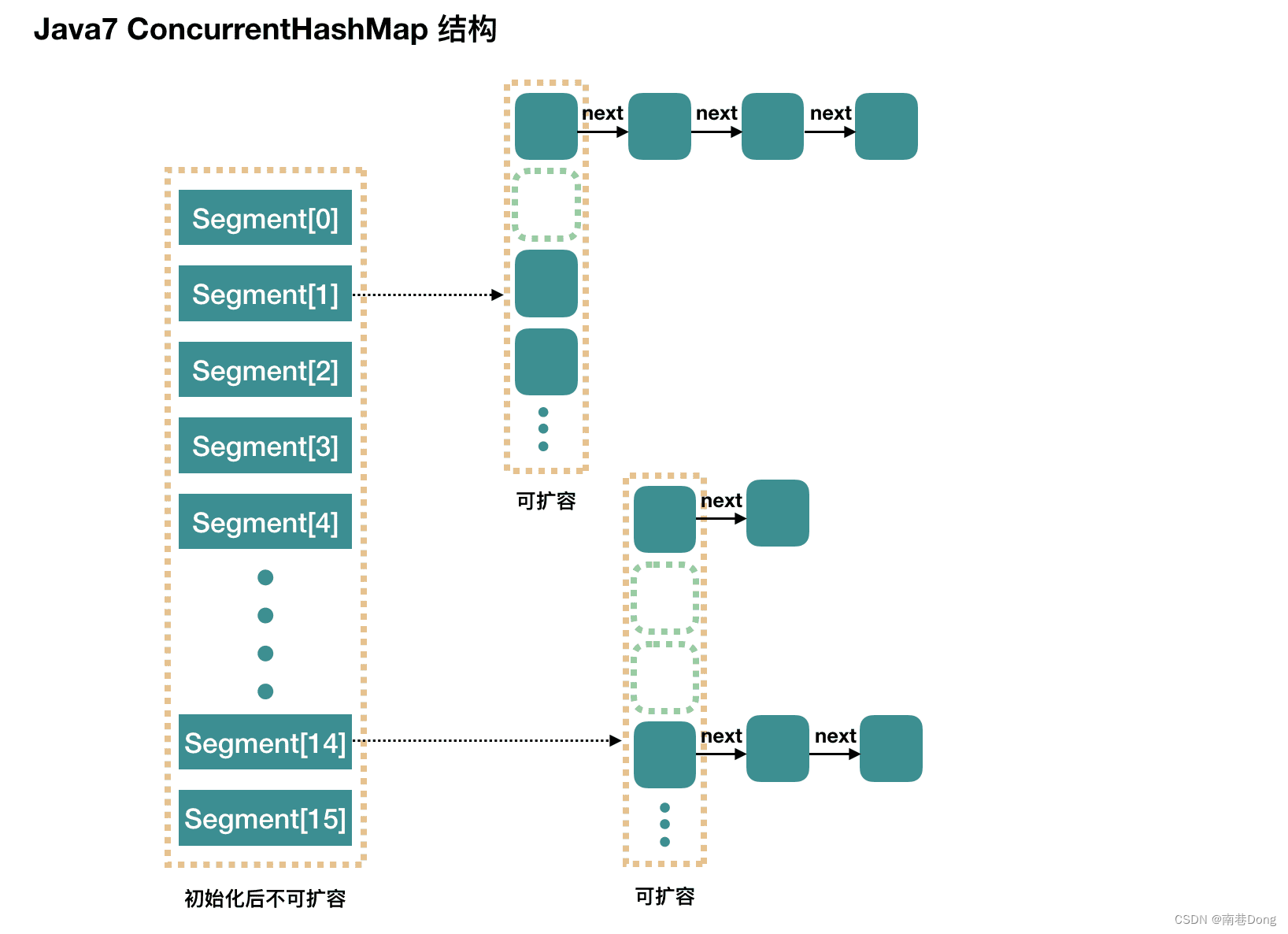
concurrencyLevel: Segment 数(并行级别、并发数)。默认是 16,也就是说 ConcurrentHashMap 有 16 个 Segments,所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。
ConcurrentHashMap JDK1.7中Segment数(concurrencyLevel)默认值是多少? 为何一旦初始化就不可再扩容?
默认是 16
ConcurrentHashMap JDK1.7说说其put的机制?
整体流程还是比较简单的,由于有独占锁的保护,所以 segment 内部的操作并不复杂
1. 计算 key 的 hash 值
2. 根据 hash 值找到 Segment 数组中的位置 j; ensureSegment(j) 对 segment[j] 进行初始化(Segment 内部是由 数组+链表 组成的)
3. 插入新值到 槽 s 中
ConcurrentHashMap JDK1.7是如何扩容的?
rehash(注:segment 数组不能扩容,扩容是 segment 数组某个位置内部的数组 HashEntry<K,V>[] 进行扩容)
ConcurrentHashMap JDK1.8实现的原理是什么?
在JDK1.7之前,ConcurrentHashMap是通过分段锁机制来实现的,所以其最大并发度受Segment的个数限制。因此,在JDK1.8中,ConcurrentHashMap的实现原理摒弃了这种设计,而是选择了与HashMap类似的数组+链表+红黑树的方式实现,而加锁则采用CAS和synchronized实现。
简而言之:数组+链表+红黑树,CAS
ConcurrentHashMap JDK1.8是如何扩容的?
tryPresize, 扩容也是做翻倍扩容的,扩容后数组容量为原来的 2 倍
ConcurrentHashMap JDK1.8链表转红黑树的时机是什么? 临界值为什么是8?
size = 8, log(N)
ConcurrentHashMap JDK1.8是如何进行数据迁移的?
transfer, 将原来的 tab 数组的元素迁移到新的 nextTab 数组中
先说说非并发集合中Fail-fast机制?
快速失败
CopyOnWriteArrayList的实现原理?
COW基于拷贝
// 将toCopyIn转化为Object[]类型数组,然后设置当前数组
setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));
属性中有一个可重入锁,用来保证线程安全访问,还有一个Object类型的数组,用来存放具体的元素。当然,也使用到了反射机制和CAS来保证原子性的修改lock域。
// 可重入锁
final transient ReentrantLock lock = new ReentrantLock();
// 对象数组,用于存放元素
private transient volatile Object[] array;
// 反射机制
private static final sun.misc.Unsafe UNSAFE;
// lock域的内存偏移量
private static final long lockOffset;
弱一致性的迭代器原理是怎么样的
COWIterator
COWIterator表示迭代器,其也有一个Object类型的数组作为CopyOnWriteArrayList数组的快照,这种快照风格的迭代器方法在创建迭代器时使用了对当时数组状态的引用。此数组在迭代器的生存期内不会更改,因此不可能发生冲突,并且迭代器保证不会抛出 ConcurrentModificationException。创建迭代器以后,迭代器就不会反映列表的添加、移除或者更改。在迭代器上进行的元素更改操作(remove、set 和 add)不受支持。这些方法将抛出 UnsupportedOperationException。
CopyOnWriteArrayList为什么并发安全且性能比Vector好
Vector对单独的add,remove等方法都是在方法上加了synchronized; 并且如果一个线程A调用size时,另一个线程B 执行了remove,然后size的值就不是最新的,然后线程A调用remove就会越界(这时就需要再加一个Synchronized)。这样就导致有了双重锁,效率大大降低,何必呢。于是vector废弃了,要用就用CopyOnWriteArrayList 吧。
CopyOnWriteArrayList有何缺陷
CopyOnWriteArrayList 有几个缺点:
- 由于写操作的时候,需要拷贝数组,会消耗内存,如果原数组的内容比较多的情况下,可能导致young gc或者full gc
- 不能用于实时读的场景,像拷贝数组、新增元素都需要时间,所以调用一个set操作后,读取到数据可能还是旧的,虽然CopyOnWriteArrayList 能做到最终一致性,但是还是没法满足实时性要求;
CopyOnWriteArrayList 合适读多写少的场景,不过这类慎用
因为谁也没法保证CopyOnWriteArrayList 到底要放置多少数据,万一数据稍微有点多,每次add/set都要重新复制数组,这个代价实在太高昂了。在高性能的互联网应用中,这种操作分分钟引起故障。
要想用线程安全的队列有哪些选择
Vector,Collections.synchronizedList( List list), ConcurrentLinkedQueue等
ConcurrentLinkedQueue实现的数据结构
ConcurrentLinkedQueue的数据结构与LinkedBlockingQueue的数据结构相同,都是使用的链表结构。ConcurrentLinkedQueue的数据结构如下:

说明: ConcurrentLinkedQueue采用的链表结构,并且包含有一个头节点和一个尾结点。
ConcurrentLinkedQueue底层原理
// 反射机制
private static final sun.misc.Unsafe UNSAFE;
// head域的偏移量
private static final long headOffset;
// tail域的偏移量
private static final long tailOffset;
说明: 属性中包含了head域和tail域,表示链表的头节点和尾结点,同时,ConcurrentLinkedQueue也使用了反射机制和CAS机制来更新头节点和尾结点,保证原子性。
ConcurrentLinkedQueue的核心方法
offer(),poll(),peek(),isEmpty()等队列常用方法
说说ConcurrentLinkedQueue的HOPS(延迟更新的策略)的设计
通过上面对offer和poll方法的分析,我们发现tail和head是延迟更新的,两者更新触发时机为:
- tail更新触发时机:当tail指向的节点的下一个节点不为null的时候,会执行定位队列真正的队尾节点的操作,找到队尾节点后完成插入之后才会通过casTail进行tail更新;当tail指向的节点的下一个节点为null的时候,只插入节点不更新tail。
- head更新触发时机:当head指向的节点的item域为null的时候,会执行定位队列真正的队头节点的操作,找到队头节点后完成删除之后才会通过updateHead进行head更新;当head指向的节点的item域不为null的时候,只删除节点不更新head。
并且在更新操作时,源码中会有注释为:hop two nodes at a time。所以这种延迟更新的策略就被叫做HOPS的大概原因是这个(猜的 😃),从上面更新时的状态图可以看出,head和tail的更新是“跳着的”即中间总是间隔了一个。那么这样设计的意图是什么呢?
如果让tail永远作为队列的队尾节点,实现的代码量会更少,而且逻辑更易懂。但是,这样做有一个缺点,如果大量的入队操作,每次都要执行CAS进行tail的更新,汇总起来对性能也会是大大的损耗。如果能减少CAS更新的操作,无疑可以大大提升入队的操作效率,所以doug lea大师每间隔1次(tail和队尾节点的距离为1)进行才利用CAS更新tail。对head的更新也是同样的道理,虽然,这样设计会多出在循环中定位队尾节点,但总体来说读的操作效率要远远高于写的性能,因此,多出来的在循环中定位尾节点的操作的性能损耗相对而言是很小的。
ConcurrentLinkedQueue适合什么样的使用场景
ConcurrentLinkedQueue通过无锁来做到了更高的并发量,是个高性能的队列,但是使用场景相对不如阻塞队列常见,毕竟取数据也要不停的去循环,不如阻塞的逻辑好设计,但是在并发量特别大的情况下,是个不错的选择,性能上好很多,而且这个队列的设计也是特别费力,尤其的使用的改良算法和对哨兵的处理。整体的思路都是比较严谨的,这个也是使用了无锁造成的,我们自己使用无锁的条件的话,这个队列是个不错的参考。
什么是BlockingDueue? 适合用在什么样的场景
BlockingQueue 通常用于一个线程生产对象,而另外一个线程消费这些对象的场景。下图是对这个原理的阐述:
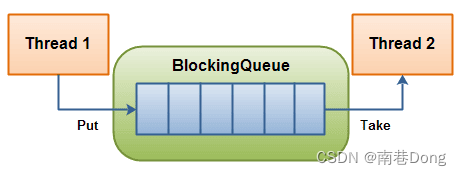
一个线程往里边放,另外一个线程从里边取的一个 BlockingQueue。
一个线程将会持续生产新对象并将其插入到队列之中,直到队列达到它所能容纳的临界点。也就是说,它是有限的。如果该阻塞队列到达了其临界点,负责生产的线程将会在往里边插入新对象时发生阻塞。它会一直处于阻塞之中,直到负责消费的线程从队列中拿走一个对象。 负责消费的线程将会一直从该阻塞队列中拿出对象。如果消费线程尝试去从一个空的队列中提取对象的话,这个消费线程将会处于阻塞之中,直到一个生产线程把一个对象丢进队列。
BlockingQueue大家族
ArrayBlockingQueue, DelayQueue, LinkedBlockingQueue, SynchronousQueue…
BlockingQueue常用的方法
BlockingQueue 具有 4 组不同的方法用于插入、移除以及对队列中的元素进行检查。如果请求的操作不能得到立即执行的话,每个方法的表现也不同。这些方法如下:
抛异常 特定值 阻塞 超时
插入 add(o) offer(o) put(o) offer(o, timeout, timeunit)
移除 remove() poll() take() poll(timeout, timeunit)
检查 element() peek()
四组不同的行为方式解释:
- 抛异常: 如果试图的操作无法立即执行,抛一个异常。
- 特定值: 如果试图的操作无法立即执行,返回一个特定的值(常常是 true / false)。
- 阻塞: 如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行。
- 超时: 如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行,但等待时间不会超过给定值。返回一个特定值以告知该操作是否成功(典型的是 true / false)。
BlockingQueue 实现例子?
这里是一个 Java 中使用 BlockingQueue 的示例。本示例使用的是 BlockingQueue 接口的 ArrayBlockingQueue 实现。 首先,BlockingQueueExample 类分别在两个独立的线程中启动了一个 Producer 和 一个 Consumer。Producer 向一个共享的 BlockingQueue 中注入字符串,而 Consumer 则会从中把它们拿出来。
public class BlockingQueueExample {public static void main(String[] args) throws Exception {BlockingQueue queue = new ArrayBlockingQueue(1024);Producer producer = new Producer(queue);Consumer consumer = new Consumer(queue);new Thread(producer).start();new Thread(consumer).start();Thread.sleep(4000);}
}
以下是 Producer 类。注意它在每次 put() 调用时是如何休眠一秒钟的。这将导致 Consumer 在等待队列中对象的时候发生阻塞。
public class Producer implements Runnable{protected BlockingQueue queue = null;public Producer(BlockingQueue queue) {this.queue = queue;}public void run() {try {queue.put("1");Thread.sleep(1000);queue.put("2");Thread.sleep(1000);queue.put("3");} catch (InterruptedException e) {e.printStackTrace();}}
}
以下是 Consumer 类。它只是把对象从队列中抽取出来,然后将它们打印到 System.out。
public class Consumer implements Runnable{protected BlockingQueue queue = null;public Consumer(BlockingQueue queue) {this.queue = queue;}public void run() {try {System.out.println(queue.take());System.out.println(queue.take());System.out.println(queue.take());} catch (InterruptedException e) {e.printStackTrace();}}
}
什么是BlockingDeque? 适合用在什么样的场景
java.util.concurrent 包里的 BlockingDeque 接口表示一个线程安放入和提取实例的双端队列。
BlockingDeque 类是一个双端队列,在不能够插入元素时,它将阻塞住试图插入元素的线程;在不能够抽取元素时,它将阻塞住试图抽取的线程。 deque(双端队列) 是 “Double Ended Queue” 的缩写。因此,双端队列是一个你可以从任意一端插入或者抽取元素的队列。
在线程既是一个队列的生产者又是这个队列的消费者的时候可以使用到 BlockingDeque。如果生产者线程需要在队列的两端都可以插入数据,消费者线程需要在队列的两端都可以移除数据,这个时候也可以使用 BlockingDeque。BlockingDeque 图解:

BlockingDeque 与BlockingQueue有何关系
BlockingDeque 接口继承自 BlockingQueue 接口。这就意味着你可以像使用一个 BlockingQueue 那样使用 BlockingDeque。如果你这么干的话,各种插入方法将会把新元素添加到双端队列的尾端,而移除方法将会把双端队列的首端的元素移除。正如 BlockingQueue 接口的插入和移除方法一样。
以下是 BlockingDeque 对 BlockingQueue 接口的方法的具体内部实现:
BlockingQueue BlockingDeque
add() addLast()
offer() x 2 offerLast() x 2
put() putLast()
remove() removeFirst()
poll() x 2 pollFirst()
take() takeFirst()
element() getFirst()
peek() peekFirst()
BlockingDeque大家族有哪些
LinkedBlockingDeque 是一个双端队列,在它为空的时候,一个试图从中抽取数据的线程将会阻塞,无论该线程是试图从哪一端抽取数据。
BlockingDeque 实现例子
既然 BlockingDeque 是一个接口,那么你想要使用它的话就得使用它的众多的实现类的其中一个。java.util.concurrent 包提供了以下 BlockingDeque 接口的实现类: LinkedBlockingDeque。
以下是如何使用 BlockingDeque 方法的一个简短代码示例:
BlockingDeque deque = new LinkedBlockingDeque();
deque.addFirst(“1”);
deque.addLast(“2”);
String two = deque.takeLast();
String one = deque.takeFirst();
线程池
为什么要有线程池?
线程池能够对线程进行统一分配,调优和监控:
- 降低资源消耗(线程无限制地创建,然后使用完毕后销毁)
- 提高响应速度(无须创建线程)
- 提高线程的可管理性
Java是实现和管理线程池有哪些方式? 请简单举例如何使用。
从JDK 5开始,把工作单元与执行机制分离开来,工作单元包括Runnable和Callable,而执行机制由Executor框架提供。
-
WorkerThread
public class WorkerThread implements Runnable {private String command;
public WorkerThread(String s){
this.command=s;
}@Override
public void run() {
System.out.println(Thread.currentThread().getName()+" Start. Command = “+command);
processCommand();
System.out.println(Thread.currentThread().getName()+” End.");
}private void processCommand() {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}@Override
public String toString(){
return this.command;
}
} -
SimpleThreadPool
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class SimpleThreadPool {
public static void main(String[] args) {ExecutorService executor = Executors.newFixedThreadPool(5);for (int i = 0; i < 10; i++) {Runnable worker = new WorkerThread("" + i);executor.execute(worker);}executor.shutdown(); // This will make the executor accept no new threads and finish all existing threads in the queuewhile (!executor.isTerminated()) { // Wait until all threads are finish,and also you can use "executor.awaitTermination();" to wait}System.out.println("Finished all threads");
}
}
程序中我们创建了固定大小为五个工作线程的线程池。然后分配给线程池十个工作,因为线程池大小为五,它将启动五个工作线程先处理五个工作,其他的工作则处于等待状态,一旦有工作完成,空闲下来工作线程就会捡取等待队列里的其他工作进行执行。
输出表明线程池中至始至终只有五个名为 “pool-1-thread-1” 到 “pool-1-thread-5” 的五个线程,这五个线程不随着工作的完成而消亡,会一直存在,并负责执行分配给线程池的任务,直到线程池消亡。
Executors 类提供了使用了 ThreadPoolExecutor 的简单的 ExecutorService 实现,但是 ThreadPoolExecutor 提供的功能远不止于此。我们可以在创建 ThreadPoolExecutor 实例时指定活动线程的数量,我们也可以限制线程池的大小并且创建我们自己的 RejectedExecutionHandler 实现来处理不能适应工作队列的工作。
ThreadPoolExecutor的原理
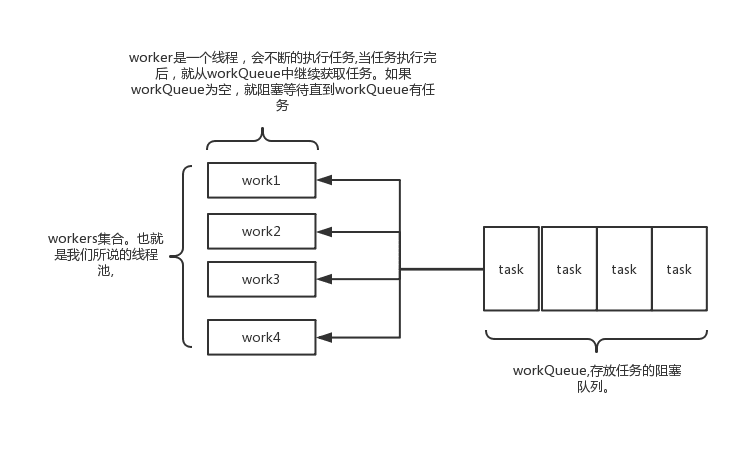
其实java线程池的实现原理很简单,说白了就是一个线程集合workerSet和一个阻塞队列workQueue。当用户向线程池提交一个任务(也就是线程)时,线程池会先将任务放入workQueue中。workerSet中的线程会不断的从workQueue中获取线程然后执行。当workQueue中没有任务的时候,worker就会阻塞,直到队列中有任务了就取出来继续执行。
当一个任务提交至线程池之后:
1. 线程池首先当前运行的线程数量是否少于corePoolSize。如果是,则创建一个新的工作线程来执行任务。如果都在执行任务,则进入2.
2. 判断BlockingQueue是否已经满了,倘若还没有满,则将线程放入BlockingQueue。否则进入3.
3. 如果创建一个新的工作线程将使当前运行的线程数量超过maximumPoolSize,则交给RejectedExecutionHandler来处理任务。
当ThreadPoolExecutor创建新线程时,通过CAS来更新线程池的状态ctl.
ThreadPoolExecutor有哪些核心的配置参数
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,RejectedExecutionHandler handler)
- corePoolSize 线程池中的核心线程数,当提交一个任务时,线程池创建一个新线程执行任务,直到当前线程数等于corePoolSize, 即使有其他空闲线程能够执行新来的任务, 也会继续创建线程;如果当前线程数为corePoolSize,继续提交的任务被保存到阻塞队列中,等待被执行;如果执行了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有核心线程。
- workQueue 用来保存等待被执行的任务的阻塞队列. 在JDK中提供了如下阻塞队列:
○ ArrayBlockingQueue: 基于数组结构的有界阻塞队列,按FIFO排序任务;
○ LinkedBlockingQueue: 基于链表结构的阻塞队列,按FIFO排序任务,吞吐量通常要高于ArrayBlockingQueue;
○ SynchronousQueue: 一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue;
○ PriorityBlockingQueue: 具有优先级的无界阻塞队列;
LinkedBlockingQueue比ArrayBlockingQueue在插入删除节点性能方面更优,但是二者在put(), take()任务的时均需要加锁,SynchronousQueue使用无锁算法,根据节点的状态判断执行,而不需要用到锁,其核心是Transfer.transfer(). - maximumPoolSize 线程池中允许的最大线程数。如果当前阻塞队列满了,且继续提交任务,则创建新的线程执行任务,前提是当前线程数小于maximumPoolSize;当阻塞队列是无界队列, 则maximumPoolSize则不起作用, 因为无法提交至核心线程池的线程会一直持续地放入workQueue.
- keepAliveTime 线程空闲时的存活时间,即当线程没有任务执行时,该线程继续存活的时间;默认情况下,该参数只在线程数大于corePoolSize时才有用, 超过这个时间的空闲线程将被终止;
- unit keepAliveTime的单位
- threadFactory 创建线程的工厂,通过自定义的线程工厂可以给每个新建的线程设置一个具有识别度的线程名。默认为DefaultThreadFactory
- handler 线程池的饱和策略,当阻塞队列满了,且没有空闲的工作线程,如果继续提交任务,必须采取一种策略处理该任务,线程池提供了4种策略:
○ AbortPolicy: 直接抛出异常,默认策略;
○ CallerRunsPolicy: 用调用者所在的线程来执行任务;
○ DiscardOldestPolicy: 丢弃阻塞队列中靠最前的任务,并执行当前任务;
○ DiscardPolicy: 直接丢弃任务;
当然也可以根据应用场景实现RejectedExecutionHandler接口,自定义饱和策略,如记录日志或持久化存储不能处理的任务。
ThreadPoolExecutor可以创建哪是哪三种线程池呢
- newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());
}
线程池的线程数量达corePoolSize后,即使线程池没有可执行任务时,也不会释放线程。
FixedThreadPool的工作队列为无界队列LinkedBlockingQueue(队列容量为Integer.MAX_VALUE), 这会导致以下问题:
- 线程池里的线程数量不超过corePoolSize,这导致了maximumPoolSize和keepAliveTime将会是个无用参数
- 由于使用了无界队列, 所以FixedThreadPool永远不会拒绝, 即饱和策略失效
- newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));
}
初始化的线程池中只有一个线程,如果该线程异常结束,会重新创建一个新的线程继续执行任务,唯一的线程可以保证所提交任务的顺序执行.
由于使用了无界队列, 所以SingleThreadPool永远不会拒绝, 即饱和策略失效
- newCachedThreadPool
public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
}
线程池的线程数可达到Integer.MAX_VALUE,即2147483647,内部使用SynchronousQueue作为阻塞队列; 和newFixedThreadPool创建的线程池不同,newCachedThreadPool在没有任务执行时,当线程的空闲时间超过keepAliveTime,会自动释放线程资源,当提交新任务时,如果没有空闲线程,则创建新线程执行任务,会导致一定的系统开销; 执行过程与前两种稍微不同:
- 主线程调用SynchronousQueue的offer()方法放入task, 倘若此时线程池中有空闲的线程尝试读取 SynchronousQueue的task, 即调用了SynchronousQueue的poll(), 那么主线程将该task交给空闲线程. 否则执行(2)
- 当线程池为空或者没有空闲的线程, 则创建新的线程执行任务.
- 执行完任务的线程倘若在60s内仍空闲, 则会被终止. 因此长时间空闲的CachedThreadPool不会持有任何线程资源.
当队列满了并且worker的数量达到maxSize的时候,会怎么样
当队列满了并且worker的数量达到maxSize的时候,执行具体的拒绝策略
private volatile RejectedExecutionHandler handler;
说说ThreadPoolExecutor有哪些RejectedExecutionHandler策略? 默认是什么策略
- AbortPolicy, 默认
该策略是线程池的默认策略。使用该策略时,如果线程池队列满了丢掉这个任务并且抛出RejectedExecutionException异常。 源码如下:
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
//不做任何处理,直接抛出异常
throw new RejectedExecutionException(“xxx”);
} - DiscardPolicy
这个策略和AbortPolicy的slient版本,如果线程池队列满了,会直接丢掉这个任务并且不会有任何异常。 源码如下:
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
//就是一个空的方法
} - DiscardOldestPolicy
这个策略从字面上也很好理解,丢弃最老的。也就是说如果队列满了,会将最早进入队列的任务删掉腾出空间,再尝试加入队列。 因为队列是队尾进,队头出,所以队头元素是最老的,因此每次都是移除对头元素后再尝试入队。 源码如下:
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
//移除队头元素
e.getQueue().poll();
//再尝试入队
e.execute®;
}
} - CallerRunsPolicy
使用此策略,如果添加到线程池失败,那么主线程会自己去执行该任务,不会等待线程池中的线程去执行。就像是个急脾气的人,我等不到别人来做这件事就干脆自己干。 源码如下:
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
//直接执行run方法
r.run();
}
}
简要说下线程池的任务执行机制?
execute –> addWorker –>runworker (getTask)
1. 线程池的工作线程通过Woker类实现,在ReentrantLock锁的保证下,把Woker实例插入到HashSet后,并启动Woker中的线程。
2. 从Woker类的构造方法实现可以发现: 线程工厂在创建线程thread时,将Woker实例本身this作为参数传入,当执行start方法启动线程thread时,本质是执行了Worker的runWorker方法。
3. firstTask执行完成之后,通过getTask方法从阻塞队列中获取等待的任务,如果队列中没有任务,getTask方法会被阻塞并挂起,不会占用cpu资源;
在配置线程池的时候需要考虑哪些配置因素
从任务的优先级,任务的执行时间长短,任务的性质(CPU密集/ IO密集),任务的依赖关系这四个角度来分析。并且近可能地使用有界的工作队列。
性质不同的任务可用使用不同规模的线程池分开处理:
- CPU密集型: 尽可能少的线程,Ncpu+1
- IO密集型: 尽可能多的线程, Ncpu*2,比如数据库连接池
- 混合型: CPU密集型的任务与IO密集型任务的执行时间差别较小,拆分为两个线程池;否则没有必要拆分。
为什么不允许使用Executors去创建线程池? 那么推荐怎么使用呢
线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。 说明:Executors各个方法的弊端:
- newFixedThreadPool和newSingleThreadExecutor: 主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至OOM。
- newCachedThreadPool和newScheduledThreadPool: 主要问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至OOM。
ScheduledThreadPoolExecutor要解决什么样的问题?
在很多业务场景中,我们可能需要周期性的运行某项任务来获取结果,比如周期数据统计,定时发送数据等。在并发包出现之前,Java 早在1.3就提供了 Timer 类(只需要了解,目前已渐渐被 ScheduledThreadPoolExecutor 代替)来适应这些业务场景。随着业务量的不断增大,我们可能需要多个工作线程运行任务来尽可能的增加产品性能,或者是需要更高的灵活性来控制和监控这些周期业务。这些都是 ScheduledThreadPoolExecutor 诞生的必然性。
ScheduledThreadPoolExecutor相比ThreadPoolExecutor有哪些特性?
ScheduledThreadPoolExecutor继承自 ThreadPoolExecutor,为任务提供延迟或周期执行,属于线程池的一种。和 ThreadPoolExecutor 相比,它还具有以下几种特性:
- 使用专门的任务类型—ScheduledFutureTask 来执行周期任务,也可以接收不需要时间调度的任务(这些任务通过 ExecutorService 来执行)。
- 使用专门的存储队列—DelayedWorkQueue 来存储任务,DelayedWorkQueue 是无界延迟队列DelayQueue 的一种。相比ThreadPoolExecutor也简化了执行机制(delayedExecute方法,后面单独分析)。
- 支持可选的run-after-shutdown参数,在池被关闭(shutdown)之后支持可选的逻辑来决定是否继续运行周期或延迟任务。并且当任务(重新)提交操作与 shutdown 操作重叠时,复查逻辑也不相同。
ScheduledThreadPoolExecutor有什么样的数据结构,核心内部类和抽象类?
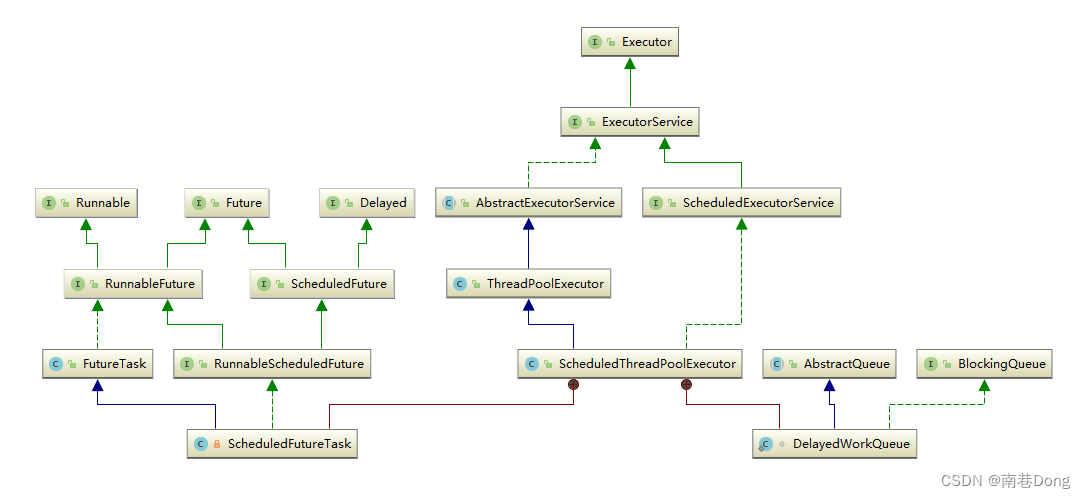
ScheduledThreadPoolExecutor继承自 ThreadPoolExecutor:
ScheduledThreadPoolExecutor 内部构造了两个内部类 ScheduledFutureTask 和 DelayedWorkQueue:
- ScheduledFutureTask: 继承了FutureTask,说明是一个异步运算任务;最上层分别实现了Runnable、Future、Delayed接口,说明它是一个可以延迟执行的异步运算任务。
- DelayedWorkQueue: 这是 ScheduledThreadPoolExecutor 为存储周期或延迟任务专门定义的一个延迟队列,继承了 AbstractQueue,为了契合 ThreadPoolExecutor 也实现了 BlockingQueue 接口。它内部只允许存储 RunnableScheduledFuture 类型的任务。与 DelayQueue 的不同之处就是它只允许存放 RunnableScheduledFuture 对象,并且自己实现了二叉堆(DelayQueue 是利用了 PriorityQueue 的二叉堆结构)。
ScheduledThreadPoolExecutor有哪两个关闭策略? 区别是什么?
shutdown: 在shutdown方法中调用的关闭钩子onShutdown方法,它的主要作用是在关闭线程池后取消并清除由于关闭策略不应该运行的所有任务,这里主要是根据 run-after-shutdown 参数(continueExistingPeriodicTasksAfterShutdown和executeExistingDelayedTasksAfterShutdown)来决定线程池关闭后是否关闭已经存在的任务。
showDownNow: 立即关闭
ScheduledThreadPoolExecutor中scheduleAtFixedRate 和 scheduleWithFixedDelay区别是什么?
注意scheduleAtFixedRate和scheduleWithFixedDelay的区别: 乍一看两个方法一模一样,其实,在unit.toNanos这一行代码中还是有区别的。没错,scheduleAtFixedRate传的是正值,而scheduleWithFixedDelay传的则是负值,这个值就是 ScheduledFutureTask 的period属性。
为什么ThreadPoolExecutor 的调整策略却不适用于 ScheduledThreadPoolExecutor?
例如: 由于 ScheduledThreadPoolExecutor 是一个固定核心线程数大小的线程池,并且使用了一个无界队列,所以调整maximumPoolSize对其没有任何影响(所以 ScheduledThreadPoolExecutor 没有提供可以调整最大线程数的构造函数,默认最大线程数固定为Integer.MAX_VALUE)。此外,设置corePoolSize为0或者设置核心线程空闲后清除(allowCoreThreadTimeOut)同样也不是一个好的策略,因为一旦周期任务到达某一次运行周期时,可能导致线程池内没有线程去处理这些任务。
Executors 提供了几种方法来构造 ScheduledThreadPoolExecutor?
- newScheduledThreadPool: 可指定核心线程数的线程池。
- newSingleThreadScheduledExecutor: 只有一个工作线程的线程池。如果内部工作线程由于执行周期任务异常而被终止,则会新建一个线程替代它的位置。
外传
😜 原创不易,如若本文能够帮助到您的同学
🎉 支持我:关注我+点赞👍+收藏⭐️
📝 留言:探讨问题,看到立马回复
💬 格言:己所不欲勿施于人 扬帆起航、游历人生、永不言弃!🔥相关文章:
Java面试知识点(全)-Java并发-多线程JUC三- JUC集合/线程池
Java面试知识点(全) 导航: https://nanxiang.blog.csdn.net/article/details/130640392 注:随时更新 JUC集合类 为什么HashTable慢? 它的并发度是什么? 那么ConcurrentHashMap并发度是什么? Hashtable之所以效率低下主要是因为其实现使用了synchro…...

Android 如何获取有效的DeviceId
目录 前言官方唯一标识符建议使用广告 ID使用实例 ID 和 GUID不要使用 MAC 地址标识符特性常见用例和适用的标识符 解决方案DeviceIdANDROID_IDMac地址UUID补充 总结 前言 从 Android 10 开始,应用必须具有 READ_PRIVILEGED_PHONE_STATE 特许权限才能访问设备的不可…...

<SQL>《SQL命令(含例句)精心整理版(2)》
《SQL命令(含例句)精心整理版(2)》 跳转《SQL命令(含例句)精心整理版(1)8 函数8.1 文本处理函数8.2 数值处理函数8.3 时间处理函数8.3.1 时间戳转化为自定义格式from_unixtime8.3.2 …...

完全自主研发,聚芯微发布3D dToF图像传感器芯片!
日前,由中国半导体行业协会IC设计分会(ICCAD)、芯原股份、松山湖管委会主办的主题为“AR/VR/XR元宇宙”的“2023松山湖中国IC创新高峰论坛”正式在广东东莞松山湖召开。武汉市聚芯微电子有限责任公司发布了完全自主知识产权的3D dToF图像传感…...

MySQL 事物(w字)
目录 事物 首先我们来看一个简单的问题 什么是事务 为什么会出现事务 事务的版本支持 事务提交方式 事务常见操作方式 设置隔离级别 事物操作 事物结论 事务隔离级别 理解隔离性 隔离级别 查看与设置隔离性 注意可重复读【Repeatable Read】的可能问题ÿ…...

字节跳动测试岗四面总结....
字节一面 1、 简单做一下自我介绍 2、 简要介绍一下项目/你负责的模块/选一个模块说一下你设计的用例 3 、get请求和post请求的区别 4、 如何判断前后端bug/3xx是什么意思 5、 说一下XXX项目中你做的接口测试/做了多少次 6、 http和https的区别 7、 考了几个ADB命令/查看…...
基于.NetCore开源的Windows的GIF录屏工具
推荐一个Github上Start超过20K的超火、好用的屏幕截图转换为 GIF 动图开源项目。 项目简介 这是基于.Net Core WPF 开发的、开源项目,可将屏幕截图转为 GIF 动画。它的核心功能是能够简单、快速地截取整个屏幕或者选定区域,并将其转为 GIF动画&#x…...
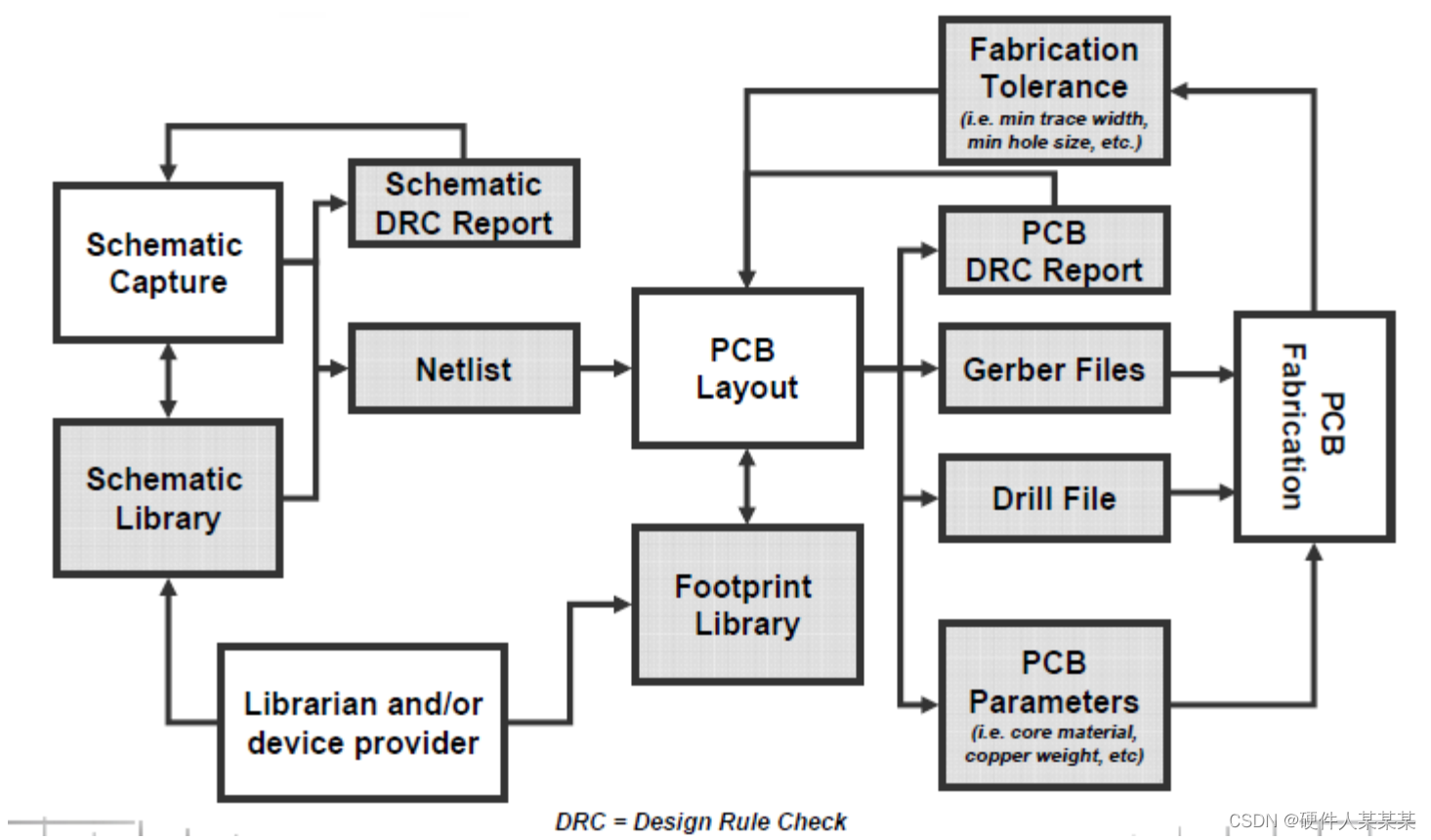
PCB 基础~典型的PCB设计流程,典型的PCB制造流程
典型的PCB设计流程 典型的PCB制造流程 • 从客户手中拿到Gerber, Drill以及其它PCB相关文件 • 准备PCB基片和薄片 – 铜箔的底片会被粘合在基材上 • 内层图像蚀刻 – 抗腐蚀的化学药水会涂在需要保留的铜箔上(例如走线和过孔) – 其他药水…...

Python logging使用
目录 logging模块 logging核心组件 logger handler StreamHandler:把日志内容在控制台中输出 FileHandler:把日志内容写入到文件中 filter formatter 注意日志级别的继承问题 logger.exception 上述样例的整体代码 日志的配置文件及其模板 lo…...

红黑树的实现原理和应用场景
红黑树的实现原理和应用场景; 有如图所示的表,现在希望查询的结果将列成行 建表语句如下: CREATE TABLE TEST_TB_GRADE2 ( ID int(10) NOT NULL AUTO_INCREMENT, USER_NAME varchar(20) DEFAULT NULL, CN_SCORE float DEFAULT NU…...
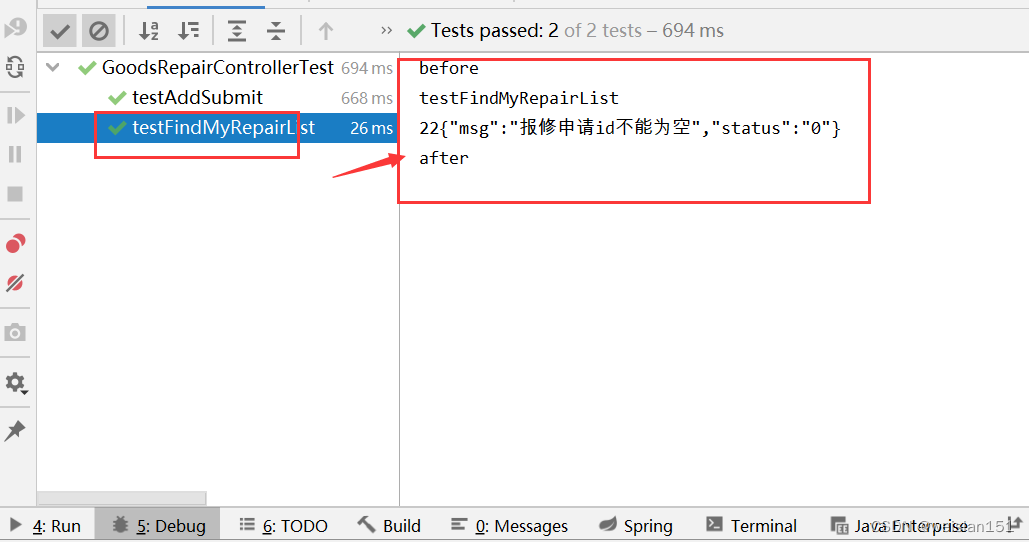
idea插件完成junit代码生成,和springboot代码示例
在idea环境下,可以用过插件的方式自动生成juint模板代码。不过具体要需要自己手动编写。 1、安装插件 打开idea,file–settings–plugins,搜索和安装插件(JunitGenerator V2.0和JUnit),安装后,后…...

【Redis面试点总结】
1、缓存 1.1、穿透 查询一个空数据,mysql也查不到也不会写入缓存可能导致多次请求数据库 方案一:缓存设空即可(可能发生数据不一致就是这条数据有了但此时缓存是空,消耗内存) 方案二:布隆过滤器&#x…...
打卡智能中国(五):博士都去哪儿了?
《打卡智能中国》系列更新了几期,有读者表示,很爱看这类接地气的真实故事,也有读者反映,不是电工,就是文员、农民、治沙人,人工智能不是高精尖学科吗?那些学历很高的博士都去哪儿了?…...
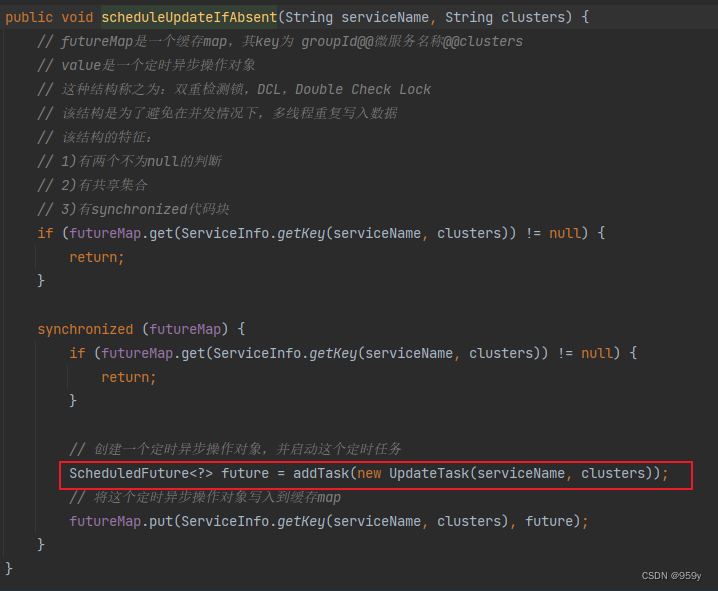
[Nacos] Nacos Client获取调用服务的提供者列表 (四)
文章目录 1.Nacos Client获取调用服务的提供者列表1.1 从Ribbon的负载均衡入手到Nacos Client获取调用服务的提高者列表1.2 getServers方法返回分析1.3 通过selectInstances方法查找Instances实例1.4 获取到要调用服务的serviceInfo Nacos Client 从Ribbon负载均衡调用服务。 …...
)
gcc编译一个程序的步骤(嵌入式学习)
1.预处理(Preprocessing): 在这个步骤中,预处理器将处理与#相关的代码,包括展开头文件、删除无用定义和替换宏定义。预处理器会生成一个经过宏替换和条件编译处理的中间文件。 gcc -E xxx.c -o xxx.i2.编译࿰…...
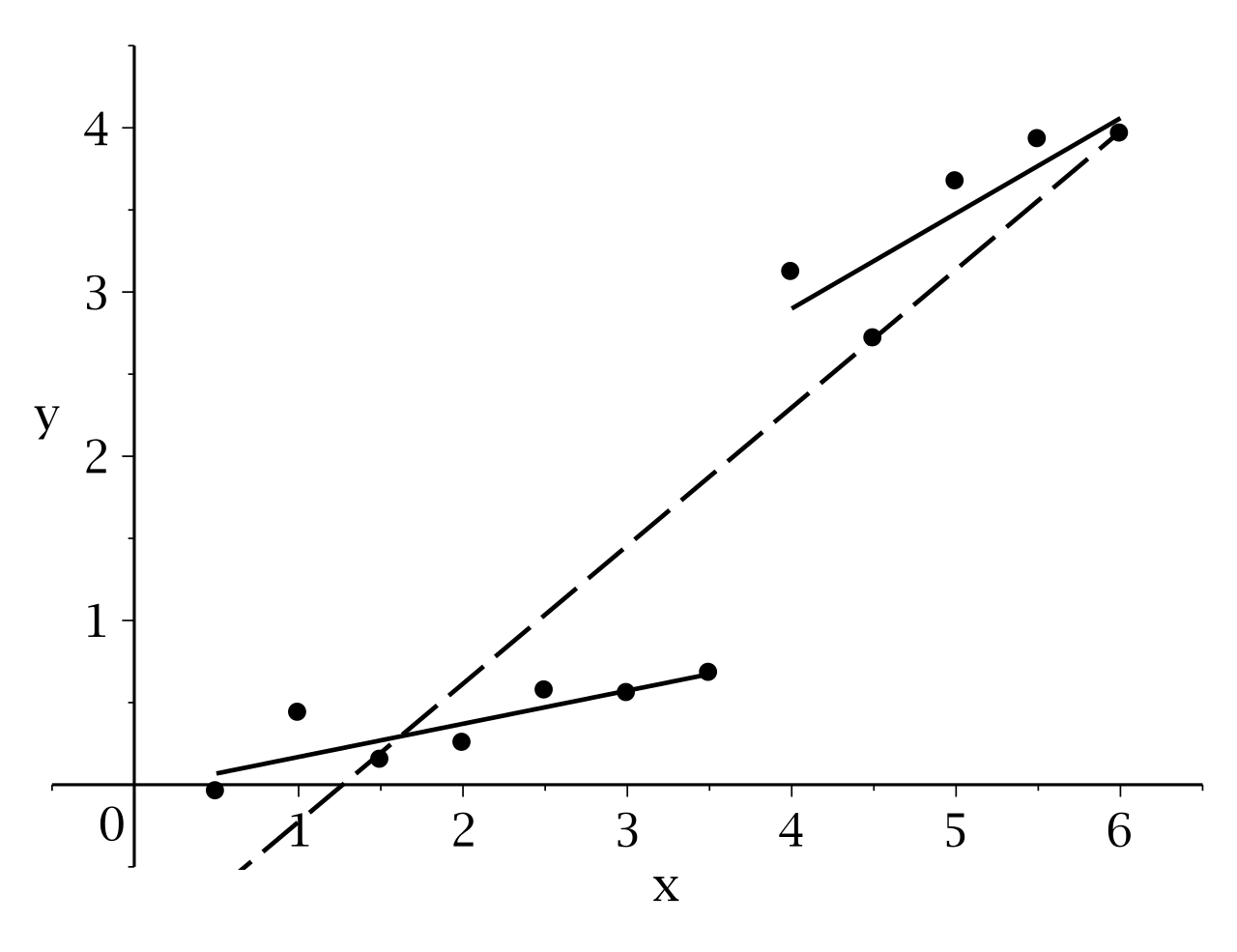
邹检验,结构变化识别及其R语言实现
在描述多维数据的维度关系时,线性模型无疑应用最多。然而某些情况下,我们关心随着时间变化或随着样本分组,线性关系的具体参数是否发生了变化,即是否发生结构变化Structural break。邹检验Chow test提供了最基本的一种结构变化显著…...
腾讯云,物联网开发平台产品,动态注册步骤
1. 下载后解压,qcloud_iot_mqtt_sign-master.zip GitHub - tencentyun/qcloud_iot_mqtt_signContribute to tencentyun/qcloud_iot_mqtt_sign development by creating an account on GitHub.https://github.com/tencentyun/qcloud_iot_mqtt_sign 2. 按照readme文…...
Padding, Spacer, Initializer 的使用
1. Padding 的使用 1.1 样式一 1) 实现 func testText1()-> some View{Text("Hello, World!").background(Color.yellow) // 背景颜色//.padding() // 默认间距.padding(.all, 10) // 所有的间距.padding(.leading, 20) // 开始的间距.ba…...

少儿编程 中国电子学会图形化编程等级考试Scratch编程四级真题解析(判断题)2023年3月
2023年3月scratch编程等级考试四级真题 判断题(共10题,每题2分,共20分) 11、在使用自定义积木时,不可以传递布尔型参数 答案:错 考点分析:考查自定义积木的使用,使用自定义积木的时候可以传递数字、文本和布尔型参数,所以错误 12、执行如下图程序后,输出的结果为“…...

Makefile学习笔记
目录 一、概述 1.1 Makefile 介绍 1.2规则 1.3核心 1.4示例 1.5定义命令 1.6 make是如何工作的 1.7、makefile中使用变量 1.8让make自动推导 1.9、另类风格的makefile 1.10、清空目标文件的规则 二、Makefile 总述 2.1、Makefile里有什么? 2.2、 mak…...
)
Veo 2提示词效能跃迁实战(工业级Prompt链构建全图谱)
更多请点击: https://codechina.net 第一章:Veo 2提示词编写的核心范式演进 Veo 2作为新一代视频生成模型,其提示词(prompt)工程已从早期的“关键词堆叠”转向结构化、语义分层与意图对齐的复合范式。这一演进并非简…...

新手村任务:成为一个架构师需要哪些装备?
新手村任务:成为一个架构师需要哪些装备? 一、前言 如果你刚入行不久,想成为一名架构师,那这篇文章就是为你写的。 我们把成为架构师比作一个RPG游戏,你是主角,需要收集各种装备、刷经验、升级技能。 新手村的第一个任务就是:了解你需要哪些装备。 二、架构师技能树…...

简单学习 --> SSE
我们使用AI时,AI对我们说的话不会一次性把全部内容弹出来,而是会像流水一样,一点点吐出来,那么这种丝滑的交互体验,背后的核心就是 SSE (Server-Sent Events)。 什么是 SSE? SSE(Server-Sent …...

终极免费音乐解锁工具:打破平台枷锁,让音乐重获自由
终极免费音乐解锁工具:打破平台枷锁,让音乐重获自由 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地…...

关于软件版本升级的故事
起因在群里有网友说软件的版本升级比较简单,俺就回了四个字母“PACS”,并补上了一个表情 然后看见开始细说了:一、PACS 属于哪一类?PACS 软件 第二类医疗器械(独立软件)国家药监局分类:Ⅱ 类 2…...

完整解决方案:PL2303 Windows 10驱动快速安装指南
完整解决方案:PL2303 Windows 10驱动快速安装指南 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 如果你正在Windows 10系统上使用PL-2303HXA或PL-2303XA芯…...

洛雪音乐桌面版:跨平台音乐聚合播放器的终极使用指南
洛雪音乐桌面版:跨平台音乐聚合播放器的终极使用指南 【免费下载链接】lx-music-desktop 一个基于 Electron 的音乐软件 项目地址: https://gitcode.com/GitHub_Trending/lx/lx-music-desktop 洛雪音乐桌面版是一款基于Electron和Vue 3技术栈开发的开源跨平台…...

技术指南:qobuz-dl无损音乐下载器架构解析与实战应用
技术指南:qobuz-dl无损音乐下载器架构解析与实战应用 【免费下载链接】qobuz-dl A complete Lossless and Hi-Res music downloader for Qobuz 项目地址: https://gitcode.com/gh_mirrors/qo/qobuz-dl 在数字音乐时代,音质追求者面临着一个核心矛…...

德国、奥地利和瑞士 SaaS 市场销售策略大揭秘:风险优先,节奏放慢!
1. 嵌入工作流介绍嵌入工作流有其官网主页,具备多种功能,如 ChatGPT 集成、专家支持、无需编码、白标、集成等;还有多种解决方案,包括代理商、CRM、iPaaS 替代方案、物业管理、房地产、初创企业、WordPress 插件、增加收入等&…...

如何5分钟搞定全网资源下载:res-downloader智能嗅探实战指南
如何5分钟搞定全网资源下载:res-downloader智能嗅探实战指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 还在…...