Pytorch从零开始实现Vision Transformer (from scratch)
Pytorch从零开始实现Vision Transformer
- 前言
- 一、Vision Transformer架构介绍
- 1. Patch Embedding
- 2. Multi-Head Attention
- 3. Transformer Block
- Feed Forward
- 二、预备知识
- 1. Einsum
- 2. Einops
- 三、Vision Transformer代码实现
- 0. 导入库
- 1. Patch Embedding
- 2. Residual & Norm
- 3. Multi-Head Attention & FeedForward
- 4. Transformer Encoder
- 6. Vision Transformer
- 7. Test Code
- 模型参数量计算
- 1. 卷积核参数量计算
- 2. 全连接层参数量计算
- 3. ViT参数量计算
- 总结
- 日志
- 参考文献
前言
Transformer在NLP领域大放异彩,而实际上NLP(Natural Language Processing,自然语言处理)领域技术的发展都要先于CV(Computer Vision,计算机视觉),那么如何将Transformer这类模型也能适用到图像数据上呢?
在2017年Transformer发布后,历经3年时间,Vision Transformer于2020年问世。与Transformer相同,Vision Transformer也是由Google Brain和Google Research团队开发,然而并不是同一批人(除了Jakob Uszkoreit)。
值得一提的是,Vision Transformer并不是第一个将Transformer应用到CV上的,因为这些巨头的存在(如Google,FaceBook),论文的名气也自然会更大,而且从如今ViT的泛用程度来看也是,大家对其认可度更高纷纷follow。和这些巨头庞大资源比,高校产出的论文光芒显得黯淡了许多。而在大模型时代更是如此,都是“大力出奇迹”的结果。可大模型大数据训练就是AI的最终形态了吗,我觉得不然……或许在AI真正具有“智能”时,深度学习的模型也并不需要这么大吧,因为人脑正是有了联想推理才能拥有知识和技能,而不完全单靠记忆。
一、Vision Transformer架构介绍

1. Patch Embedding
2. Multi-Head Attention
3. Transformer Block
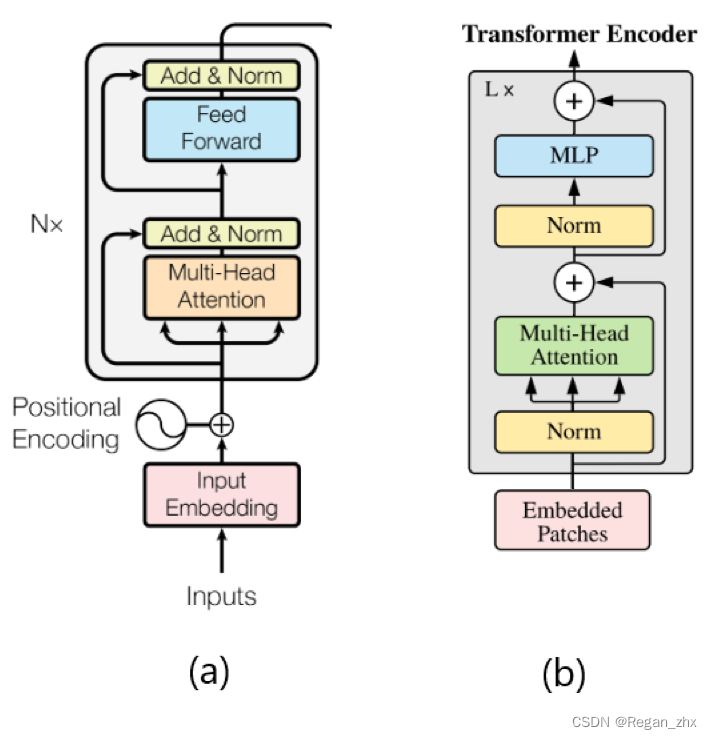
如图,(a) 是最初Transformer的Encoder结构图, (b)则是ViT的。可以明显看出,Transformer是在multi-head attention和feedforward模块后进行残差操作(即Add)和Norm(标准化),而ViT则是在这些模块前使用Norm操作。
Feed Forward
ViT的Feed Forward模块使用两层全连接层(Linear)和GeLU激活函数。而Transformer使用的是ReLu激活函数。
GeLu于2016年被提出,见于Bridging Nonlinearities and Stochastic Regularizers with Gaussian Error Linear Units,后来经过论文修改改名为“Gaussian Error Linear Units (GELUs)”。论文给出了ReLu和GeLu的图示:

ReLu确实好用,但缺点也很明显,其在输入值小于0时都会输出0,这样“一刀切”的策略势必会丢掉信息,累计error。因此后来出现了GeLu、LeakyReLu等一系列激活函数来解决神经元”死亡“问题,让输入值小于0时输出不总是0。
二、预备知识
本节的两个操作都是为了方便编程人员更好对tensor进行操作,且让代码更具可读性。
1. Einsum
Einsum即爱因斯坦和,torch.einsum即可调用。
2. Einops
是大牛 受Einsum启发所开发的一个库,主要用于张量的变形等操作。
三、Vision Transformer代码实现
这次代码并不是直接取用某一份代码,而是参考包括Pytorch官方的代码库、网上博客、github项目综合出的一份Vision Transformer代码,尽可能还原ViT又兼顾代码可读性以便读者学习理解。此处引用比ViT原论文更加具体的ViT模型图:

此图出自论文Vision Transformers for Remote Sensing Image Classification。
0. 导入库
import torch
import torch.nn as nn
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
1. Patch Embedding
class PatchEmbedding(nn.Module):def __init__(self, embed_size=768, patch_size=16, channels=3, img_size=224):super(PatchEmbedding, self).__init__()self.patch_size = patch_size# Version 1.0# self.patch_projection = nn.Sequential(# Rearrange("b c (h h1) (w w1) -> b (h w) (h1 w1 c)", h1=patch_size, w1=patch_size),# nn.Linear(patch_size * patch_size * channels, embed_size)# )# Version 2.0self.patch_projection = nn.Sequential(nn.Conv2d(channels, embed_size, kernel_size=(patch_size, patch_size), stride=(patch_size, patch_size)),Rearrange("b e (h) (w) -> b (h w) e"),)self.cls_token = nn.Parameter(torch.randn(1, 1, embed_size))self.positions = nn.Parameter(torch.randn((img_size // patch_size) ** 2 + 1, embed_size))def forward(self, x):batch_size = x.shape[0]x = self.patch_projection(x)# prepend the cls token to the inputcls_tokens = repeat(self.cls_token, "() n e -> b n e", b=batch_size)x = torch.cat([cls_tokens, x], dim=1)# add position embeddingx += self.positionsreturn x
2. Residual & Norm
class Residual(nn.Module):def __init__(self, fn):super(Residual, self).__init__()self.fn = fndef forward(self, x, **kwargs):return self.fn(x, **kwargs) + xclass PreNorm(nn.Module):def __init__(self, dim, fn):super(PreNorm, self).__init__()self.norm = nn.LayerNorm(dim)self.fn = fndef forward(self, x, **kwargs):return self.fn(self.norm(x), **kwargs)
3. Multi-Head Attention & FeedForward
class FeedForward(nn.Module):def __init__(self, dim, hidden_dim, dropout=0.):super(FeedForward, self).__init__()self.mlp = nn.Sequential(nn.Linear(dim, hidden_dim),nn.GELU(),nn.Dropout(dropout),nn.Linear(hidden_dim, dim),nn.Dropout(dropout),)def forward(self, x):return self.mlp(x)class MultiHeadAttention(nn.Module):def __init__(self, embed_dim=768, n_heads=8, dropout=0.):"""Args:embed_dim: dimension of embeding vector outputn_heads: number of self attention heads"""super(MultiHeadAttention, self).__init__()self.embed_dim = embed_dim # 768 dimself.n_heads = n_heads # 8self.head_dim = self.embed_dim // self.n_heads # 768/8 = 96. each key,query,value will be of 96dself.scale = self.head_dim ** -0.5self.attn_drop = nn.Dropout(dropout)# key,query and value matrixesself.to_qkv = nn.Linear(self.embed_dim, self.embed_dim * 3, bias=False)self.to_out = nn.Sequential(nn.Linear(self.embed_dim, self.embed_dim),nn.Dropout(dropout))def forward(self, x):"""Args:x : a unified vector of key query valueReturns:output vector from multihead attention"""qkv = self.to_qkv(x).chunk(3, dim=-1)q, k, v = map(lambda t: rearrange(t, "b n (h d) -> b h n d", h=self.n_heads), qkv)dots = torch.einsum('bhid,bhjd->bhij', q, k) * self.scaleattn = dots.softmax(dim=-1)attn = self.attn_drop(attn)out = torch.einsum('bhij,bhjd->bhid', attn, v)out = rearrange(out, "b h n d -> b n (h d)")out = self.to_out(out)return out4. Transformer Encoder
class Transformer(nn.Module):def __init__(self, dim=768, depth=12, n_heads=8, mlp_expansions=4, dropout=0.):super(Transformer, self).__init__()self.layers = nn.ModuleList([])for _ in range(depth):self.layers.append(nn.ModuleList([Residual(PreNorm(dim, MultiHeadAttention(dim, n_heads, dropout))),Residual(FeedForward(dim, dim * mlp_expansions, dropout))]))def forward(self, x):for attn, ff in self.layers:x = attn(x)x = ff(x)return x
6. Vision Transformer
class VisionTransformer(nn.Module):def __init__(self, dim=768,patch_size=16,channels=3,img_size=224,depth=12,n_heads=8,mlp_expansions=4,dropout=0.,num_classes=0,global_pool='avg'):super(VisionTransformer, self).__init__()assert global_pool in ('avg', 'token')self.global_pool = global_poolself.patch_embedding = PatchEmbedding(dim, patch_size, channels, img_size)self.transformer = Transformer(dim, depth, n_heads, mlp_expansions, dropout)self.mlp_head = nn.Sequential(nn.LayerNorm(dim),nn.Linear(dim, num_classes)) if num_classes > 0 else nn.Identity()def forward(self, img):x = self.patch_embedding(img)x = self.transformer(x)x = x[:, 1:].mean(dim=1) if self.global_pool == 'avg' else x[:, 0]x = self.mlp_head(x)return x
7. Test Code
if __name__ == '__main__':device = torch.device("cuda" if torch.cuda.is_available() else "cpu")images = torch.randn((16, 3, 224, 224)).to(device)vit = VisionTransformer(num_classes=4, global_pool="token").to(device)output = vit(images)print(output)torch.save(vit.state_dict(), "model.pth")
模型参数量计算
1. 卷积核参数量计算
对于二维卷积层,其参数量由输入通道数(C)、卷积核的大小(KxK)、卷积核的数量或者说输出通道数(F)、偏置项的数量等因素决定。计算公式为:
( K × K × C + 1 ) × F (K \times K \times C + 1)\times F (K×K×C+1)×F,其中1为偏置项。
2. 全连接层参数量计算
对于某一层全连接层的参数量只由其输入维度和输出维度(是否带偏置项)决定,将全连接层理解为一个映射函数,假设输入为矩阵A(维度为HxW),输出为矩阵C(维度为HxH),那么一层全连接层参数量就来自其所代表的矩阵B根据矩阵乘法其维度应为WxH,即Linear(W,H),输入维度W,输出维度也是H。计算公式易得:
W × H + H × 1 W \times H + H\times 1 W×H+H×1,其中1代表偏置项,需要输出维度个偏置项。
3. ViT参数量计算
| 模块/变量名 | 计算过程 | 参数量 |
|---|---|---|
| PatchEmbedding | c o n v 2 d + c l s _ t o k e n + p o s t i t i o n s conv2d + cls\_token + postitions conv2d+cls_token+postitions | 742656 |
| conv2d | ( 16 × 16 × 3 + 1 ) × 768 (16\times 16\times 3 + 1)\times 768 (16×16×3+1)×768 | 590592 |
| cls_token | 1 × 1 × 768 1\times1\times768 1×1×768 | 768 |
| postitions | ( ( 224 ÷ 16 ) 2 + 1 ) × 768 ((224\div 16)^2+1)\times768 ((224÷16)2+1)×768 | 151296 |
| Feedforward | ( 768 × ( 768 × 4 ) + ( 768 × 4 ) ) + ( ( 768 × 4 ) × 768 + 768 ) (768\times(768\times4)+(768\times4)) + ((768\times4)\times768+768) (768×(768×4)+(768×4))+((768×4)×768+768) | 4722432 |
| MultiHeadAttention | t o _ q k v + t o _ o u t to\_qkv + to\_out to_qkv+to_out | 2360064 |
| to_qkv | 768 × ( 768 × 3 ) 768\times(768\times3) 768×(768×3) | 1769472 |
| to_out | 768 × 768 + 768 768\times768+768 768×768+768 | 590592 |
| Transformer | 12 × ( F e e d f o r w a r d + M u l t i H e a d A t t e n t i o n ) 12\times(Feedforward+MultiHeadAttention) 12×(Feedforward+MultiHeadAttention) | 84989952 |
| ViT | T r a n s f o r m e r + P a t c h E m b e d d i n g + m l p _ h e a d Transformer+PatchEmbedding+mlp\_head Transformer+PatchEmbedding+mlp_head | 85735684 |
| mlp_head | 768 × n u m _ c l a s s e s + n u m _ c l a s s e s ,本文设置 n u m _ c l a s s e s 为 4 768\times num\_classes+num\_classes,本文设置num\_classes为4 768×num_classes+num_classes,本文设置num_classes为4 | 3076 |
最终参数量为 85735684 × 4 ( B ) = 342942736 ( B ) 85735684\times 4(B) = 342942736(B) 85735684×4(B)=342942736(B),为什么要乘以4字节呢?
因为这些参数权重默认为float32保存,需要用到32bits即4Bytes,最终通过换算得,
342942736 ( B ) ÷ 1024 ÷ 1024 = 327.055679321 ( M B ) 342942736(B)\div 1024\div 1024 = 327.055679321(MB) 342942736(B)÷1024÷1024=327.055679321(MB)
因为我们在Test code有保存模型权重为model.pth文件,可以查看model.pth属性来验证计算是否准确。

在字节数上有所偏差,但足以表明计算过程大致是正确的! 偏差可能原因是model.pth不止要保存权重,还会附带一些其他信息,所以实际文件大小会比参数量要略大。
总结
日志
参考文献
https://theaisummer.com/vision-transformer/
https://medium.com/mlearning-ai/vision-transformers-from-scratch-pytorch-a-step-by-step-guide-96c3313c2e0c
https://www.kaggle.com/code/hannes82/vision-transformer-trained-from-scratch-pytorch
https://towardsdatascience.com/implementing-visualttransformer-in-pytorch-184f9f16f632
https://github.com/FrancescoSaverioZuppichini/ViT
相关文章:
Pytorch从零开始实现Vision Transformer (from scratch)
Pytorch从零开始实现Vision Transformer 前言一、Vision Transformer架构介绍1. Patch Embedding2. Multi-Head Attention3. Transformer BlockFeed Forward 二、预备知识1. Einsum2. Einops 三、Vision Transformer代码实现0. 导入库1. Patch Embedding2. Residual & Norm…...

ES6函数新增了哪些扩展?
目录 一、参数二、属性函数的length属性name属性 三、作用域四、严格模式五、箭头函数 一、参数 ES6允许为函数的参数设置默认值 function log(x, y World) {console.log(x, y); }console.log(Hello) // Hello World console.log(Hello, China) // Hello China console.log(…...
【firewalld防火墙】
目录 一、firewalld概述二、firewalld 与 iptables 的区别1、firewalld 区域的概念 三、firewalld防火墙默认的9个区域四、Firewalld 网络区域1、区域介绍2、firewalld数据处理流程 五、firewalld防火墙的配置方法1、使用firewall-cmd 命令行工具。2、使用firewall-config 图形…...
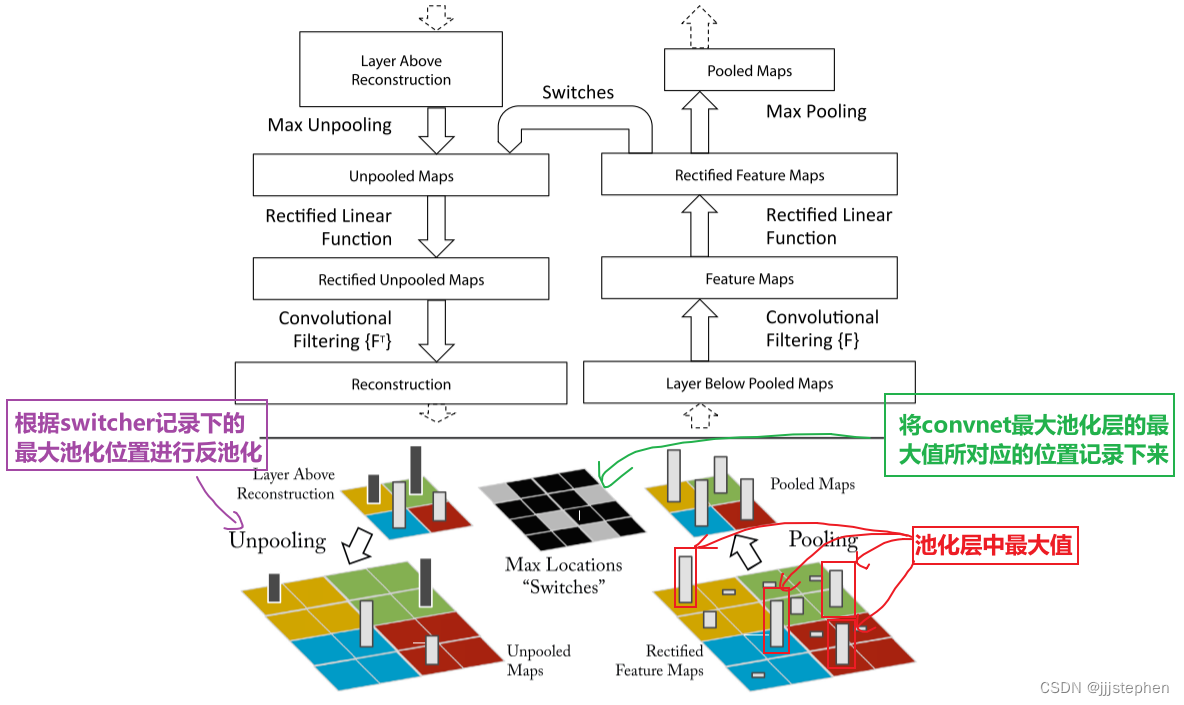
CNNs: ZFNet之CNN的可视化网络介绍
CNNs: ZFNet之CNN的可视化网络介绍 导言Deconvnet1. Unpooling2. ReLU3. Transpose conv AlexNet网络修改AlexNet Deconv网络介绍特征可视化 导言 上一个内容,我们主要学习了AlexNet网络的实现、超参数对网络结果的影响以及网络中涉及到一些其他的知识点࿰…...

云原生之深入解析Airbnb的动态Kubernetes集群扩缩容
一、前言 Airbnb 基础设施的一个重要作用是保证我们的云能够根据需求上升或下降进行自动扩缩容,我们每天的流量波动都非常大,需要依靠动态扩缩容来保证服务的正常运行。为了支持扩缩容,Airbnb 使用了 Kubernetes 编排系统,并且使…...
Django框架之模板其他补充
本篇文章是对django框架模板内容的一些补充。包含注释、html转义和csrf内容。 目录 注释 单行注释 多行注释 HTML转义 Escape Safe Autoescape CSRF 防止csrf方式 表单中使用 ajax请求添加 注释 单行注释 语法:{# 注释内容 #} 示例: {# 注…...
安装Maven 3.6.1:图文详细教程(适用于Windows系统)
一、官网下载对应版本 推荐使用maven3.6.1版本,对应下载链接: Maven3.6.1下载地址 或者,这里提供csdn下载地址,点击下载即可: Maven3.6.1直链下载 其他版本下载地址: 进入网址:http://mave…...

计算机图形学 | 实验八:Phong模型
计算机图形学 | 实验八:Phong模型 计算机图形学 | 实验八:Phong模型Phong模型光源设置 光照计算定向光点光源聚光 华中科技大学《计算机图形学》课程 MOOC地址:计算机图形学(HUST) 计算机图形学 | 实验八:…...

第三十一回:GestureDetector Widget
文章目录 概念介绍使用方法示例代码 我们在上一章回中介绍了ListView响应事件的内容t,本章回中将介绍 GestureDetector Widget.闲话休提,让我们一起Talk Flutter吧。 概念介绍 我们在这里介绍的GestureDetector是一个事件响应Widget,它可以响应双击事件࿰…...
Java面试知识点(全)-Java并发-多线程JUC三- JUC集合/线程池
Java面试知识点(全) 导航: https://nanxiang.blog.csdn.net/article/details/130640392 注:随时更新 JUC集合类 为什么HashTable慢? 它的并发度是什么? 那么ConcurrentHashMap并发度是什么? Hashtable之所以效率低下主要是因为其实现使用了synchro…...

Android 如何获取有效的DeviceId
目录 前言官方唯一标识符建议使用广告 ID使用实例 ID 和 GUID不要使用 MAC 地址标识符特性常见用例和适用的标识符 解决方案DeviceIdANDROID_IDMac地址UUID补充 总结 前言 从 Android 10 开始,应用必须具有 READ_PRIVILEGED_PHONE_STATE 特许权限才能访问设备的不可…...

<SQL>《SQL命令(含例句)精心整理版(2)》
《SQL命令(含例句)精心整理版(2)》 跳转《SQL命令(含例句)精心整理版(1)8 函数8.1 文本处理函数8.2 数值处理函数8.3 时间处理函数8.3.1 时间戳转化为自定义格式from_unixtime8.3.2 …...

完全自主研发,聚芯微发布3D dToF图像传感器芯片!
日前,由中国半导体行业协会IC设计分会(ICCAD)、芯原股份、松山湖管委会主办的主题为“AR/VR/XR元宇宙”的“2023松山湖中国IC创新高峰论坛”正式在广东东莞松山湖召开。武汉市聚芯微电子有限责任公司发布了完全自主知识产权的3D dToF图像传感…...

MySQL 事物(w字)
目录 事物 首先我们来看一个简单的问题 什么是事务 为什么会出现事务 事务的版本支持 事务提交方式 事务常见操作方式 设置隔离级别 事物操作 事物结论 事务隔离级别 理解隔离性 隔离级别 查看与设置隔离性 注意可重复读【Repeatable Read】的可能问题ÿ…...

字节跳动测试岗四面总结....
字节一面 1、 简单做一下自我介绍 2、 简要介绍一下项目/你负责的模块/选一个模块说一下你设计的用例 3 、get请求和post请求的区别 4、 如何判断前后端bug/3xx是什么意思 5、 说一下XXX项目中你做的接口测试/做了多少次 6、 http和https的区别 7、 考了几个ADB命令/查看…...
基于.NetCore开源的Windows的GIF录屏工具
推荐一个Github上Start超过20K的超火、好用的屏幕截图转换为 GIF 动图开源项目。 项目简介 这是基于.Net Core WPF 开发的、开源项目,可将屏幕截图转为 GIF 动画。它的核心功能是能够简单、快速地截取整个屏幕或者选定区域,并将其转为 GIF动画&#x…...
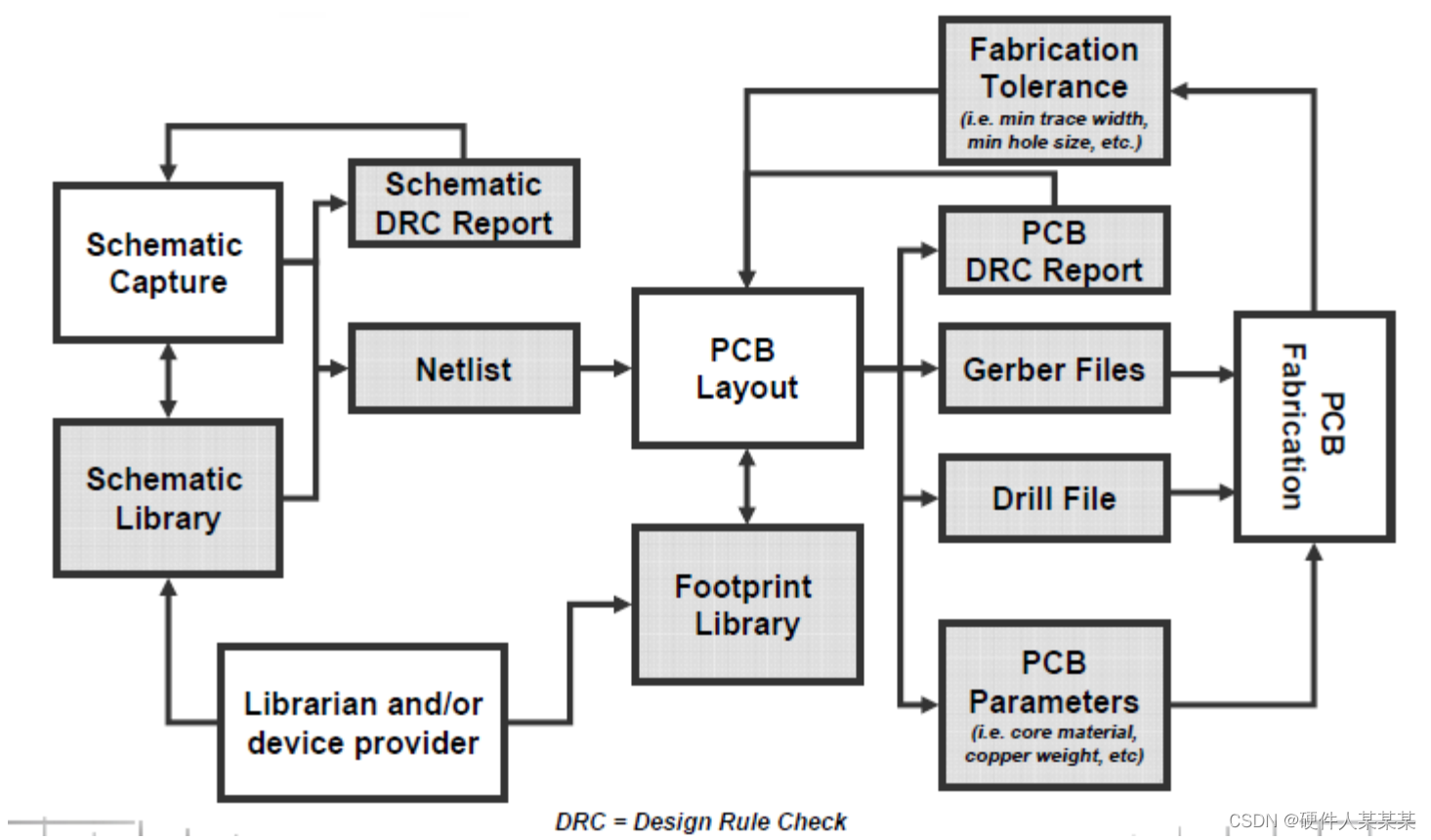
PCB 基础~典型的PCB设计流程,典型的PCB制造流程
典型的PCB设计流程 典型的PCB制造流程 • 从客户手中拿到Gerber, Drill以及其它PCB相关文件 • 准备PCB基片和薄片 – 铜箔的底片会被粘合在基材上 • 内层图像蚀刻 – 抗腐蚀的化学药水会涂在需要保留的铜箔上(例如走线和过孔) – 其他药水…...

Python logging使用
目录 logging模块 logging核心组件 logger handler StreamHandler:把日志内容在控制台中输出 FileHandler:把日志内容写入到文件中 filter formatter 注意日志级别的继承问题 logger.exception 上述样例的整体代码 日志的配置文件及其模板 lo…...

红黑树的实现原理和应用场景
红黑树的实现原理和应用场景; 有如图所示的表,现在希望查询的结果将列成行 建表语句如下: CREATE TABLE TEST_TB_GRADE2 ( ID int(10) NOT NULL AUTO_INCREMENT, USER_NAME varchar(20) DEFAULT NULL, CN_SCORE float DEFAULT NU…...
idea插件完成junit代码生成,和springboot代码示例
在idea环境下,可以用过插件的方式自动生成juint模板代码。不过具体要需要自己手动编写。 1、安装插件 打开idea,file–settings–plugins,搜索和安装插件(JunitGenerator V2.0和JUnit),安装后,后…...

Visual Studio 项目属性页开发完全教程:从基础到高级
Visual Studio 项目属性页开发完全教程:从基础到高级 【免费下载链接】project-system The .NET Project System for Visual Studio 项目地址: https://gitcode.com/gh_mirrors/pr/project-system Visual Studio 项目属性页是开发者管理项目配置的核心界面&a…...

量子计算中Loschmidt回声相位测量的创新方法
1. 量子计算中的Loschmidt回声相位测量方法概述Loschmidt回声是量子动力学中一个重要的概念,它描述了量子系统在时间反演演化后与初始状态的相似程度。在量子计算领域,精确测量Loschmidt回声的相位信息对于理解量子系统的非平衡态行为、计算能量本征值以…...

告别拍脑袋规划!用ArcGIS做绿道选线:如何科学量化坡度、水域、道路成本并加权计算
科学规划绿道的ArcGIS高阶技法:从成本栅格构建到最优路径生成绿道规划从来不是简单的"两点之间直线最短",而是需要综合考虑地形、生态、人文等多维因素的复杂决策过程。传统规划中常见的"拍脑袋"决策方式,往往导致建成后…...
)
ROS Noetic实战:从bag包里‘抠’出雷达点云和IMU数据的保姆级教程(Ubuntu 20.04)
ROS Noetic实战:从bag包里提取雷达点云和IMU数据的完整指南(Ubuntu 20.04)在机器人开发中,ROS bag文件就像是一个装满珍贵数据的宝箱,而雷达点云和IMU数据则是其中最闪亮的宝石。作为一名长期与ROS打交道的开发者&…...

FeHelper前端助手:30+开发工具集,让你的浏览器变身效率神器
FeHelper前端助手:30开发工具集,让你的浏览器变身效率神器 【免费下载链接】FeHelper 😍FeHelper--Web前端助手(Awesome!Chrome & Firefox & MS-Edge Extension, All in one Toolbox!) 项目地址:…...

《我看见的世界:李飞飞自传》第1-6章阅读笔记:从移民少女到AI教母的“看见“之旅
前言 当我们谈论人工智能时,我们谈论的是算法、数据、算力,是那些冰冷的代码和复杂的模型。但在《我看见的世界:李飞飞自传》中,李飞飞用她独特的视角告诉我们:AI的本质,是人类对"看见"世界的渴望…...

Burp Suite证书安装全解:HTTPS抓包失败的根源与跨平台命令行方案
1. 为什么必须亲手安装Burp Suite证书——不是“点一下就完事”的操作很多人第一次在手机或测试设备上配置Burp Suite代理时,会下意识认为:只要把电脑上的Burp监听地址填进Wi-Fi代理设置,再用浏览器访问http://burp,点击那个绿色的…...

自制极低频电流探头:负电阻补偿原理与低频方波测量实践
1. 项目概述:为极低频电流测量而生在电子测试领域,电流探头是个再常见不过的工具,无论是排查开关电源的纹波,还是分析电机驱动的波形,都离不开它。但如果你尝试用市面上常见的电流探头去观察一个频率低至几赫兹&#x…...

当 AI Coding 进入复杂企业系统,为什么提效远没有宣传里那么美好 ?
以 Claude Code、Codex 为代表的自主编码智能体(Coding Agents),正在以惊人的速度席卷软件开发者生态。与此同时,类似“10 倍开发效率”“普通人也能随手构建软件”“程序员即将失业”的说法,也随处可见。这种不分场景…...

OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权
OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权 【免费下载链接】firmware Alternative IP Camera firmware from an open community 项目地址: https://gitcode.com/gh_mirrors/fir/firmware 还在为网络摄像头的封闭系统而烦恼吗?想要完全掌控…...