MySQL高级SQL语句
创建两个表用于演示 location store_info
use kgc;
create table location (Region char(20),Store_Name char(20));
insert into location values('East','Boston');
insert into location values('East','New York');
insert into location values('West','Los Angeles');
insert into location values('West','Houston');
location 表格
+----------+--------------+
| Region | Store_Name |
|----------+--------------|
| East | Boston |
| East | New York |
| West | Los Angeles |
| West | Houston |
+----------+--------------+
create table store_info (Store_Name char(20),Sales int(10),Date char(10));
insert into store_info values('Los Angeles','1500','2020-12-05');
insert into store_info values('Houston','250','2020-12-07');
insert into store_info values('Los Angeles','300','2020-12-08');
insert into store_info values('Boston','700','2020-12-08');
Store_Info 表格
+--------------+---------+------------+
| Store_Name | Sales | Date |
|--------------+---------+------------|
| Los Angeles | 1500 | 2020-12-05 |
| Houston | 250 | 2020-12-07 |
| Los Angeles | 300 | 2020-12-08 |
| Boston | 700 | 2020-12-08 |
+--------------+---------+------------+
---- SELECT ----显示表格中一个或数个字段的所有数据记录
语法:SELECT "字段" FROM "表名";
SELECT Store_Name FROM Store_Info;
---- DISTINCT ----不显示重复的数据记录
语法:SELECT DISTINCT "字段" FROM "表名";
SELECT DISTINCT Store_Name FROM Store_Info;
---- WHERE ----有条件查询
语法:SELECT "字段" FROM "表名" WHERE "条件";
SELECT Store_Name FROM Store_Info WHERE Sales > 1000;
---- AND OR ----且 或 连接两个条件的逻辑关系
语法:SELECT "字段" FROM "表名" WHERE "条件1" {[AND|OR] "条件2"}+ ;
SELECT Store_Name FROM Store_Info WHERE Sales > 1000 OR (Sales < 500 AND Sales > 200);
---- IN ----用已知的值来判定数据记录范围
语法:SELECT "字段" FROM "表名" WHERE "字段" IN ('值1', '值2', ...);
SELECT * FROM Store_Info WHERE Store_Name IN ('Los Angeles', 'Houston');
---- BETWEEN ----显示两个值范围内的数据记录
语法:SELECT "字段" FROM "表名" WHERE "字段" BETWEEN '值1' AND '值2';
SELECT * FROM Store_Info WHERE Date BETWEEN '2020-12-06' AND '2020-12-10';
---- 通配符 ----通常通配符都是跟 LIKE 一起使用的 与like连用
% :百分号表示零个、一个或多个字符
_ :下划线表示单个字符
'A_Z':所有以 'A' 起头,另一个任何值的字符,且以 'Z' 为结尾的字符串。例如,'ABZ' 和 'A2Z' 都符合这一个模式,而 'AKKZ' 并不符合 (因为在 A 和 Z 之间有两个字符,而不是一个字符)。
'ABC%': 所有以 'ABC' 起头的字符串。例如,'ABCD' 和 'ABCABC' 都符合这个模式。
'%XYZ': 所有以 'XYZ' 结尾的字符串。例如,'WXYZ' 和 'ZZXYZ' 都符合这个模式。
'%AN%': 所有含有 'AN'这个模式的字符串。例如,'LOS ANGELES' 和 'SAN FRANCISCO' 都符合这个模式。
'_AN%':所有第二个字母为 'A' 和第三个字母为 'N' 的字符串。例如,'SAN FRANCISCO' 符合这个模式,而 'LOS ANGELES' 则不符合这个模式。
---- LIKE ----模式匹配 找出我们要的数据记录 与%和_连用
语法:SELECT "字段" FROM "表名" WHERE "字段" LIKE {模式};
SELECT * FROM Store_Info WHERE Store_Name like '%os%';
---- ORDER BY ----按关键字排序
语法:SELECT "字段" FROM "表名" [WHERE "条件"] ORDER BY "字段" [ASC, DESC];
#ASC 是按照升序进行排序的,是默认的排序方式。
#DESC 是按降序方式进行排序。
SELECT Store_Name,Sales,Date FROM Store_Info ORDER BY Sales DESC;
---- 函数 ----
数学函数:
abs(x) 返回 x 的绝对值
rand() 返回 0 到 1 的随机数
mod(x,y) 返回 x 除以 y 以后的余数
power(x,y) 返回 x 的 y 次方
round(x) 返回离 x 最近的整数
round(x,y) 保留 x 的 y 位小数四舍五入后的值
sqrt(x) 返回 x 的平方根
truncate(x,y) 返回数字 x 截断为 y 位小数的值
ceil(x) 返回大于或等于 x 的最小整数
floor(x) 返回小于或等于 x 的最大整数
greatest(x1,x2...) 返回集合中最大的值,也可以返回多个字段的最大的值
least(x1,x2...) 返回集合中最小的值,也可以返回多个字段的最小的值
SELECT abs(-1), rand(), mod(5,3), power(2,3), round(1.89);
SELECT round(1.8937,3), truncate(1.235,2), ceil(5.2), floor(2.1), least(1.89,3,6.1,2.1);
聚合函数:
avg() 返回指定列的平均值
count() 返回指定列中非 NULL 值的个数
min() 返回指定列的最小值
max() 返回指定列的最大值
sum(x) 返回指定列的所有值之和
SELECT avg(Sales) FROM Store_Info;
SELECT count(Store_Name) FROM Store_Info;
SELECT count(DISTINCT Store_Name) FROM Store_Info;
SELECT max(Sales) FROM Store_Info;
SELECT min(Sales) FROM Store_Info;
SELECT sum(Sales) FROM Store_Info;
City 表格
+----------+
| name |
|----------|
| beijing |
| nanjing |
| shanghai |
| <null> |
| <null> |
+----------+
SELECT count(name) FROM City;
SELECT count(*) FROM City;
#count(*) 包括了所有的列的行数,在统计结果的时候,不会忽略列值为 NULL
#count(列名) 只包括列名那一列的行数,在统计结果的时候,会忽略列值为 NULL 的行
字符串函数:
trim() 返回去除指定格式的值
concat(x,y) 将提供的参数 x 和 y 拼接成一个字符串
substr(x,y) 获取从字符串 x 中的第 y 个位置开始的字符串,跟substring()函数作用相同
substr(x,y,z) 获取从字符串 x 中的第 y 个位置开始长度为 z 的字符串
length(x) 返回字符串 x 的长度
replace(x,y,z) 将字符串 z 替代字符串 x 中的字符串 y
upper(x) 将字符串 x 的所有字母变成大写字母
lower(x) 将字符串 x 的所有字母变成小写字母
left(x,y) 返回字符串 x 的前 y 个字符
right(x,y) 返回字符串 x 的后 y 个字符
repeat(x,y) 将字符串 x 重复 y 次
space(x) 返回 x 个空格
strcmp(x,y) 比较 x 和 y,返回的值可以为-1,0,1
reverse(x) 将字符串 x 反转
SELECT concat(Region, Store_Name) FROM location WHERE Store_Name = 'Boston';
#如sql_mode开启了PIPES_AS_CONCAT,"||"视为字符串的连接操作符而非或运算符,和字符串的拼接函数Concat相类似,这和Oracle数据库使用方法一样的
SELECT Region || ' ' || Store_Name FROM location WHERE Store_Name = 'Boston';
SELECT substr(Store_Name,3) FROM location WHERE Store_Name = 'Los Angeles';
SELECT substr(Store_Name,2,4) FROM location WHERE Store_Name = 'New York';
SELECT TRIM ([ [位置] [要移除的字符串] FROM ] 字符串);
#[位置]:的值可以为 LEADING (起头), TRAILING (结尾), BOTH (起头及结尾)。
#[要移除的字符串]:从字串的起头、结尾,或起头及结尾移除的字符串。缺省时为空格。
SELECT TRIM(LEADING 'Ne' FROM 'New York');
SELECT Region,length(Store_Name) FROM location;
SELECT REPLACE(Region,'ast','astern')FROM location;
---- GROUP BY ----对GROUP BY后面的字段的查询结果进行汇总分组,通常是结合聚合函数一起使用的 avg cout min max sum 就先把该字段的值汇总在一起求平均 和 最大 最小 作为最后的结果
GROUP BY 有一个原则,凡是在 GROUP BY 后面出现的字段,必须在 SELECT 后面出现;
凡是在 SELECT 后面出现的、且未在聚合函数中出现的字段,必须出现在 GROUP BY 后面
语法:SELECT "字段1", SUM("字段2") FROM "表名" GROUP BY "字段1";
SELECT Store_Name, SUM(Sales) FROM Store_Info GROUP BY Store_Name ORDER BY sales desc;
---- HAVING ----用来过滤由 GROUP BY 语句返回的记录集,通常与 GROUP BY 语句联合使用
HAVING 语句的存在弥补了 WHERE 关键字不能与聚合函数联合使用的不足。
语法:SELECT "字段1", SUM("字段2") FROM "表格名" GROUP BY "字段1" HAVING (函数条件);
SELECT Store_Name, SUM(Sales) FROM Store_Info GROUP BY Store_Name HAVING SUM(Sales) > 1500;
---- 别名 ----字段別名 表格別名
语法:SELECT "表格別名"."字段1" [AS] "字段別名" FROM "表格名" [AS] "表格別名";
SELECT A.Store_Name Store, SUM(A.Sales) "Total Sales" FROM Store_Info A GROUP BY A.Store_Name;
---- 子查询 ----连接表格,在WHERE 子句或 HAVING 子句中插入另一个 SQL 语句
语法:SELECT "字段1" FROM "表格1" WHERE "字段2" [比较运算符] #外查询
(SELECT "字段1" FROM "表格2" WHERE "条件"); #内查询
#可以是符号的运算符,例如 =、>、<、>=、<= ;也可以是文字的运算符,例如 LIKE、IN、BETWEEN
SELECT SUM(Sales) FROM Store_Info WHERE Store_Name IN
(SELECT Store_Name FROM location WHERE Region = 'West');
SELECT SUM(A.Sales) FROM Store_Info A WHERE A.Store_Name IN
(SELECT Store_Name FROM location B WHERE B.Store_Name = A.Store_Name);
---- EXISTS ----用来测试内查询有没有产生任何结果,类似布尔值是否为真
#如果有的话,系统就会执行外查询中的SQL语句。若是没有的话,那整个 SQL 语句就不会产生任何结果。
语法:SELECT "字段1" FROM "表格1" WHERE EXISTS (SELECT * FROM "表格2" WHERE "条件");
SELECT SUM(Sales) FROM Store_Info WHERE EXISTS (SELECT * FROM location WHERE Region = 'West');
---- 连接查询 ----
location 表格
+----------+--------------+
| Region | Store_Name |
|----------+--------------|
| East | Boston |
| East | New York |
| West | Los Angeles |
| West | Houston |
+----------+--------------+
UPDATE Store_Info SET store_name='Washington' WHERE sales=300;
Store_Info 表格
+--------------+---------+------------+
| Store_Name | Sales | Date |
|--------------+---------+------------|
| Los Angeles | 1500 | 2020-12-05 |
| Houston | 250 | 2020-12-07 |
| Washington | 300 | 2020-12-08 |
| Boston | 700 | 2020-12-08 |
+--------------+---------+------------+
inner join(内连接):只返回两个表中联结字段相等的行
left join(左连接):返回包括左表中的所有记录和右表中联结字段相等的记录
right join(右连接):返回包括右表中的所有记录和左表中联结字段相等的记录
SELECT * FROM location A RIGHT JOIN Store_Info B on A.Store_Name = B.Store_Name ;
SELECT * FROM location A LEFT JOIN Store_Info B on A.Store_Name = B.Store_Name ;
内连接一:
SELECT * FROM location A INNER JOIN Store_Info B on A.Store_Name = B.Store_Name ;
内连接二:
SELECT * FROM location A, Store_Info B WHERE A.Store_Name = B.Store_Name;
SELECT A.Region REGION, SUM(B.Sales) SALES FROM location A, Store_Info B
WHERE A.Store_Name = B.Store_Name GROUP BY REGION;
自我连接,算排名:
+----------+-------+
| name | score |
+----------+-------+
| lisi | 100 |
| zhaoliu | 90 |
| wangwu | 80 |
| zhangsan | 70 |
+----------+-------+
分组汇总后统计 score 字段的值是比自己本身的值小的以及 score 字段 和 name 字段都相同的数量
SELECT A.name, A.score, count(B.score) rank FROM class A, class B
WHERE A.score < B.score OR (A.score = B.score AND A.Name = B.Name)
GROUP BY A.name, A.score ORDER BY rank;
---- CREATE VIEW ----视图,可以被当作是虚拟表或存储查询。
视图跟表格的不同是,表格中有实际储存数据记录,而视图是建立在表格之上的一个架构,它本身并不实际储存数据记录。
临时表在用户退出或同数据库的连接断开后就自动消失了,而视图不会消失。
视图不含有数据,只存储它的定义,它的用途一般可以简化复杂的查询。比如你要对几个表进行连接查询,而且还要进行统计排序等操作,写SQL语句会很麻烦的,用视图将几个表联结起来,然后对这个视图进行查询操作,就和对一个表查询一样,很方便。
语法:CREATE VIEW "视图表名" AS "SELECT 语句";
CREATE VIEW V_REGION_SALES AS SELECT A.Region REGION,SUM(B.Sales) SALES FROM location A
INNER JOIN Store_Info B ON A.Store_Name = B.Store_Name GROUP BY REGION;
SELECT * FROM V_REGION_SALES;
DROP VIEW V_REGION_SALES;
---- UNION ----联集,将两个SQL语句的结果合并起来,两个SQL语句所产生的字段需要是同样的数据记录种类
UNION :生成结果的数据记录值将没有重复,且按照字段的顺序进行排序
语法:[SELECT 语句 1] UNION [SELECT 语句 2];
UNION ALL :将生成结果的数据记录值都列出来,无论有无重复
语法:[SELECT 语句 1] UNION ALL [SELECT 语句 2];
SELECT Store_Name FROM location UNION SELECT Store_Name FROM Store_Info;
SELECT Store_Name FROM location UNION ALL SELECT Store_Name FROM Store_Info;
---- 交集值 ----取两个SQL语句结果的交集
SELECT A.Store_Name FROM location A INNER JOIN Store_Info B ON A.Store_Name = B.Store_Name;
SELECT A.Store_Name FROM location A INNER JOIN Store_Info B USING(Store_Name);
#取两个SQL语句结果的交集,且没有重复
SELECT DISTINCT A.Store_Name FROM location A INNER JOIN Store_Info B USING(Store_Name);
SELECT DISTINCT Store_Name FROM location WHERE (Store_Name) IN (SELECT Store_Name FROM Store_Info);
SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN Store_Info B USING(Store_Name) WHERE B.Store_Name IS NOT NULL;
SELECT A.Store_Name FROM (SELECT B.Store_Name FROM location B INNER JOIN Store_Info C ON B.Store_Name = C.Store_Name) A
GROUP BY A.Store_Name;
SELECT A.Store_Name FROM
(SELECT DISTINCT Store_Name FROM location UNION ALL SELECT DISTINCT Store_Name FROM Store_Info) A
GROUP BY A.Store_Name HAVING COUNT(*) > 1;
---- 无交集值 ----显示第一个SQL语句的结果,且与第二个SQL语句没有交集的结果,且没有重复
SELECT DISTINCT Store_Name FROM location WHERE (Store_Name) NOT IN (SELECT Store_Name FROM Store_Info);
SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN Store_Info B USING(Store_Name) WHERE B.Store_Name IS NULL;
SELECT A.Store_Name FROM
(SELECT DISTINCT Store_Name FROM location UNION ALL SELECT DISTINCT Store_Name FROM Store_Info) A
GROUP BY A.Store_Name HAVING COUNT(*) = 1;
---- CASE ----是 SQL 用来做为 IF-THEN-ELSE 之类逻辑的关键字
语法:
SELECT CASE ("字段名")
WHEN "条件1" THEN "结果1"
WHEN "条件2" THEN "结果2"
...
[ELSE "结果N"]
END
FROM "表名";
# "条件" 可以是一个数值或是公式。 ELSE 子句则并不是必须的。
SELECT Store_Name, CASE Store_Name
WHEN 'Los Angeles' THEN Sales * 2
WHEN 'Boston' THEN 2000
ELSE Sales
END
"New Sales",Date
FROM Store_Info;
#"New Sales" 是用于 CASE 那个字段的字段名。
---- 空值(NULL) 和 无值('') 的区别 ----
1.无值的长度为 0,不占用空间的;而 NULL 值的长度是 NULL,是占用空间的。
2.IS NULL 或者 IS NOT NULL,是用来判断字段是不是为 NULL 或者不是 NULL,不能查出是不是无值的。
3.无值的判断使用=''或者<>''来处理。<> 代表不等于。
4.在通过 count()指定字段统计有多少行数时,如果遇到 NULL 值会自动忽略掉,遇到无值会加入到记录中进行计算。
City 表格
+----------+
| name |
|----------|
| beijing |
| nanjing |
| shanghai |
| <null> |
| <null> |
| shanghai |
| |
+----------+
SELECT length(NULL), length(''), length('1');
SELECT * FROM City WHERE name IS NULL;
SELECT * FROM City WHERE name IS NOT NULL;
SELECT * FROM City WHERE name = '';
SELECT * FROM City WHERE name <> '';
SELECT COUNT(*) FROM City;
SELECT COUNT(name) FROM City;
---- 正则表达式 ----
匹配模式 描述 实例
^ 匹配文本的开始字符 ‘^bd’ 匹配以 bd 开头的字符串
$ 匹配文本的结束字符 ‘qn$’ 匹配以 qn 结尾的字符串
. 匹配任何单个字符 ‘s.t’ 匹配任何 s 和 t 之间有一个字符的字符串
* 匹配零个或多个在它前面的字符 ‘fo*t’ 匹配 t 前面有任意个 o
+ 匹配前面的字符 1 次或多次 ‘hom+’ 匹配以 ho 开头,后面至少一个m 的字符串
字符串 匹配包含指定的字符串 ‘clo’ 匹配含有 clo 的字符串
p1|p2 匹配 p1 或 p2 ‘bg|fg’ 匹配 bg 或者 fg
[...] 匹配字符集合中的任意一个字符 ‘[abc]’ 匹配 a 或者 b 或者 c
[^...] 匹配不在括号中的任何字符 ‘[^ab]’ 匹配不包含 a 或者 b 的字符串
{n} 匹配前面的字符串 n 次 ‘g{2}’ 匹配含有 2 个 g 的字符串
{n,m} 匹配前面的字符串至少 n 次,至多m 次 ‘f{1,3}’ 匹配 f 最少 1 次,最多 3 次
语法:SELECT "字段" FROM "表名" WHERE "字段" REGEXP {模式};
SELECT * FROM Store_Info WHERE Store_Name REGEXP 'os';
SELECT * FROM Store_Info WHERE Store_Name REGEXP '^[A-G]';
SELECT * FROM Store_Info WHERE Store_Name REGEXP 'Ho|Bo';
---- 存储过程 ----
存储过程是一组为了完成特定功能的SQL语句集合。
存储过程在使用过程中是将常用或者复杂的工作预先使用SQL语句写好并用一个指定的名称存储起来,这个过程经编译和优化后存储在数据库服务器中。当需要使用该存储过程时,只需要调用它即可。存储过程在执行上比传统SQL速度更快、执行效率更高。
存储过程的优点:
1、执行一次后,会将生成的二进制代码驻留缓冲区,提高执行效率
2、SQL语句加上控制语句的集合,灵活性高
3、在服务器端存储,客户端调用时,降低网络负载
4、可多次重复被调用,可随时修改,不影响客户端调用
5、可完成所有的数据库操作,也可控制数据库的信息访问权限
##创建存储过程##
DELIMITER $$ #将语句的结束符号从分号;临时改为两个$$(可以是自定义)
CREATE PROCEDURE Proc() #创建存储过程,过程名为Proc,不带参数
-> BEGIN #过程体以关键字 BEGIN 开始
-> select * from Store_Info; #过程体语句
-> END $$ #过程体以关键字 END 结束
DELIMITER ; #将语句的结束符号恢复为分号
##调用存储过程##
CALL Proc;
##查看存储过程##
SHOW CREATE PROCEDURE [数据库.]存储过程名; #查看某个存储过程的具体信息
SHOW CREATE PROCEDURE Proc;
SHOW PROCEDURE STATUS [LIKE '%Proc%'] \G
##存储过程的参数##
IN 输入参数:表示调用者向过程传入值(传入值可以是字面量或变量)
OUT 输出参数:表示过程向调用者传出值(可以返回多个值)(传出值只能是变量)
INOUT 输入输出参数:既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量)
的@variable语法在MySQL表示用户定义会话变量。变量在过程调用返回后保留该值。不带@前缀的变量语法是针对过程本地的变量,过程参数或过程体中使用DECLARE声明的局部变量。
DELIMITER $$
CREATE PROCEDURE Proc1(IN inname CHAR(16))
-> BEGIN
-> SELECT * FROM Store_Info WHERE Store_Name = inname;
-> END $$
DELIMITER ;
CALL Proc1('Boston');
delimiter $$
mysql> create procedure proc3(in myname char(10), out outname int)
-> begin
-> select sales into outname from t1 where name = myname;
-> end $$
delimiter ;
call proc3('yzh', @out_sales);
select @out_sales;
delimiter $$
mysql> create procedure proc4(inout insales int)
-> begin
-> select count(sales) into insales from t1 where sales < insales;
-> end $$
delimiter ;
set @inout_sales=1000;
call proc4(@inout_sales);
select @inout_sales;
##删除存储过程##
存储过程内容的修改方法是通过删除原有存储过程,之后再以相同的名称创建新的存储过程。如果要修改存储过程的名称,可以先删除原存储过程,再以不同的命名创建新的存储过程。
DROP PROCEDURE IF EXISTS Proc; #仅当存在时删除,不添加 IF EXISTS 时,如果指定的过程不存在,则产生一个错误
##存储过程的控制语句##
create table t (id int(10));
insert into t values(10);
(1)条件语句if-then-else ···· end if
DELIMITER $$
CREATE PROCEDURE proc2(IN pro int)
-> begin
-> declare var int;
-> set var=pro*2;
-> if var>=10 then
-> update t set id=id+1;
-> else
-> update t set id=id-1;
-> end if;
-> end $$
DELIMITER ;
CALL Proc2(6);
(2)循环语句while ···· end while
DELIMITER $$
CREATE PROCEDURE proc3()
-> begin
-> declare var int(10);
-> set var=0;
-> while var<6 do
-> insert into t values(var);
-> set var=var+1;
-> end while;
-> end $$
DELIMITER ;
CALL Proc3;
相关文章:

MySQL高级SQL语句
创建两个表用于演示 location store_info use kgc; create table location (Region char(20),Store_Name char(20)); insert into location values(East,Boston); insert into location values(East,New York); insert into location values(West,Los Angeles); insert into lo…...

rem和em的区别和使用场景,以及如何在实际开发中灵活运用它们
在前端开发中,我们经常使用rem和em作为长度单位来设置页面元素的大小。虽然它们都可以用于实现响应式布局,但是它们之间存在着一些区别。本文将深入探讨rem和em的区别和使用场景,以及如何在实际开发中灵活运用它们。 什么是rem rem是相对于…...

JDK源码阅读环境搭建
本次针对jdk8u版本的搭建 1.新建项目 新建java项目JavaSourceLearn ,这里我创建的是maven 2.获取JDK源码 打开Project Structure 找到本地JDK安装位置将src.zip解压到项目java包中 整理下项目结构,删除用不到的目录 提示: 添加源码到项目之后首次运行…...
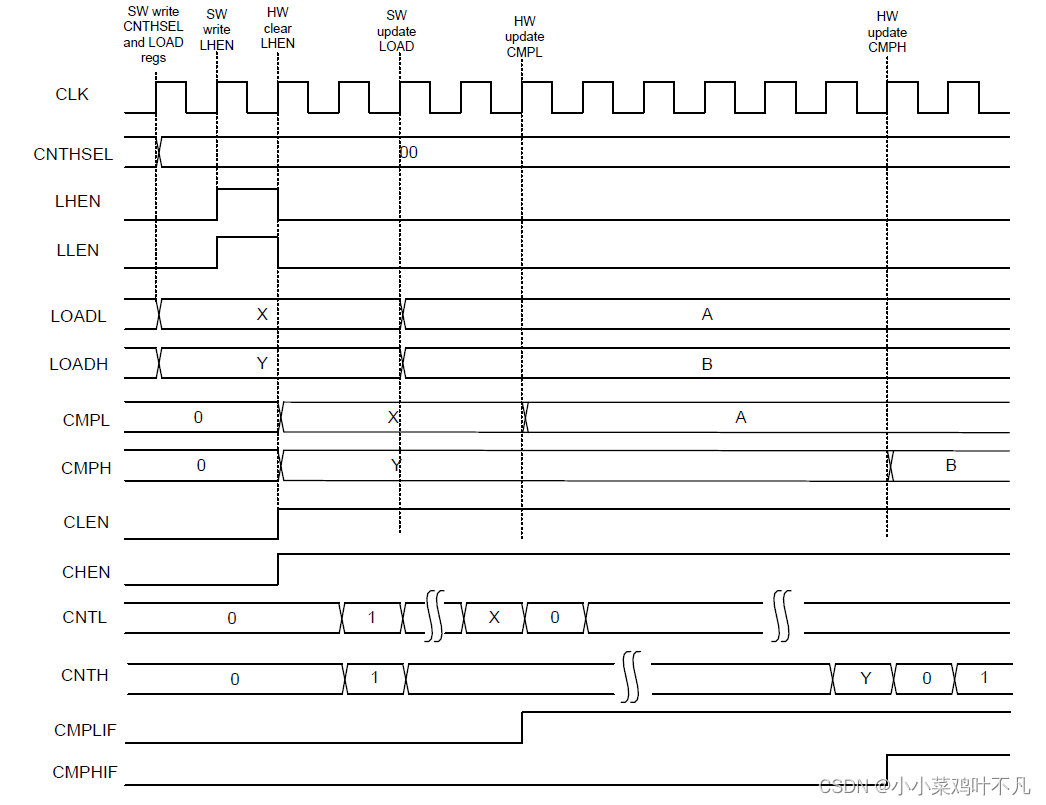
基本定时器工作模式
计数和定时 BasicTimer支持8位或16位向上计数模式。当计数值大于等于比较寄存器(CMPH、CMPL),会产生计数中断标志,并从自动重载寄存器(LOADH、LOADL)加载新的比较值。这样可以实时调整每个计数周期的计数长…...

【华为OD机试真题2023B卷 JAVA】报文重排序
华为OD2023(B卷)机试题库全覆盖,刷题指南点这里 报文重排序 时间限制:1s 空间限制:256MB 限定语言:不限 题目描述: 对报文进行重传和重排序是常用的可靠性机制,重传缓冲区内有一定数量的子报文,每个子报文在原始报文中的顺序已知,现在需要恢复出原始报文。。 输入描…...

【Docker】- 02 Docker-Compose
Docker-Compose Docker-Compose1 下载并安装Docker-Compose1.1 下载Docker-Compose1.2 设置权限1.3 配置环境变量1.4 测试 2 Docker-Compose管理MySQL和Tomcat容器3 使用docker-compose命令管理容器4 docker-compose配合Dockerfile使用4.1 docker-compose文件4.2 Dockerfile文件…...

工业相机的Pixel Binning和Pixel Skipping
一般图像传感器的不同分辨率都对应着不同的帧率。如果想要提高帧率,就要考虑是否需要缩小视野。若不希望视野缩小,就需要减小分辨率(resolution)。常用的减少分辨率的两种采样方式是:Skipping和Binning。 什么是Binni…...
 std::set(八))
c++ 11标准模板(STL) std::set(八)
定义于头文件 <set> template< class Key, class Compare std::less<Key>, class Allocator std::allocator<Key> > class set;(1)namespace pmr { template <class Key, class Compare std::less<Key>> using se…...

linux服务器断电重启后,发现时间误差八小时
文章目录 问题现象排查与解决时间同步与设置服务器时钟介绍 问题现象 客户的服务器已部署好平台,放入了机房,运行正常。服务器系统时间设置东八区(CST),时间日期也已修改正确客户是我省的某小县城,某台晚上…...

兼容人大金仓,异常信息报错解决大全
乱码报错 ISO-8859-1 SQL 错误 [55006]: : "ssss" (kbjdbc: autodetected server-encoding to be ISO-8859-1, if the message is not readable, please check database logs and/or host, port, dbname, user, password, pg_hba.conf) Detail: 3. : "sss…...

短睡眠 堀大辅 超短眠 人生更丰富
堀大辅是位每天只睡半小时的日本狠人,更多信息自行百度。以下内容,个人收集总结,仅供参考。 堀大辅大胆假设「只要能够减少睡眠的时间,我就能过得更充实」,便与朋友付诸行动,通过纪录观察每天的睡眠时数&a…...
私有GitLab仓库 - 本地搭建GitLab私有代码仓库并随时远程访问「内网穿透」
文章目录 前言1. 下载Gitlab2. 安装Gitlab3. 启动Gitlab4. 安装cpolar内网穿透5. 创建隧道配置访问地址6. 固定GitLab访问地址6.1 保留二级子域名6.2 配置二级子域名 7. 测试访问二级子域名 转载自远控源码文章:Linux搭建GitLab私有仓库,并内网穿透实现公…...

Debezium系列之:Debezium镜像仓库Quay.io,使用Debezium镜像仓库的方法和案例
Debezium系列之:Debezium镜像仓库Quay.io,使用Debezium镜像仓库的方法和案例 一、Debezium镜像仓库变动二、镜像仓库[Quay.io](https://quay.io/organization/debezium)三、使用镜像仓库Quay.io方法四、使用镜像仓库下载Debezium UI一、Debezium镜像仓库变动 Debezium2.2版本…...

文心一言和ChatGPT最全对比
文心一言和ChatGPT都是基于深度学习技术的自然语言处理模型,有各自的优势和使用场景,无法简单地比较 ChatGPT 和文心一言哪一个功能更强大,它们各自具有优势和局限性,需要根据具体需求进行选择,以下一些具体对比&#…...
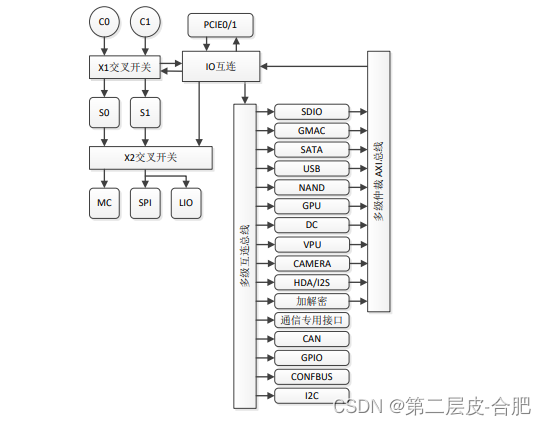
龙芯2K1000实战开发-平台介绍
文章目录 概要整体架构流程技术名词解释技术细节小结概要 龙芯 2K1000 处理器主要面向于网络应用,兼顾平板应用及工控领域应 用。采用 40nm 工艺,片内集成 2 个 GS264 处理器核,主频 1GHz,64 位 DDR3 控制器,以及各种系统 IO 接口。 整体架构 龙芯 2K1000 的结构如图 所…...
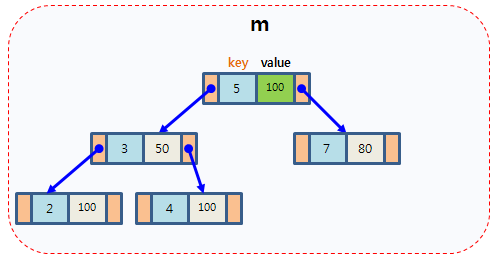
C++ map用法总结(整理)
1,map简介 map是STL的一个关联容器,它提供一对一的hash。 第一个可以称为关键字(key),每个关键字只能在map中出现一次;第二个可能称为该关键字的值(value); map以模板(泛型)方式实现,可以存储任意类型的…...

面向对象的第二个基本特征:继承011026
1.什么是继承? 生活中: 继承 ---> 延续 ---> 扩展 代码中: 继承 ---> 重复使用已有的类的代码(复用) ---> 扩展已有类的代码(扩展) 2.为什么要继承? ① 代码的复用和…...

机器学习项目实战-能源利用率 Part-3(特征工程与特征筛选)
博主前期相关的博客可见下: 机器学习项目实战-能源利用率 Part-1(数据清洗) 机器学习项目实战-能源利用率 Part-2(探索性数据分析) 这部分进行的特征工程与特征筛选。 三 特征工程与特征筛选 一般情况下我们分两步走…...
WebSocket的那些事(2-实操篇)
目录 一、概述二、Websocket API1、引入相关依赖2、配置WebSocket处理器3、WebSocket配置4、测试 三、总结 一、概述 在上一节 WebSocket的那些事(1-概念篇)中我们简单的介绍了关于WebSocket协议的相关概念、与HTTP的联系区别等等。 这一节将会带来Web…...
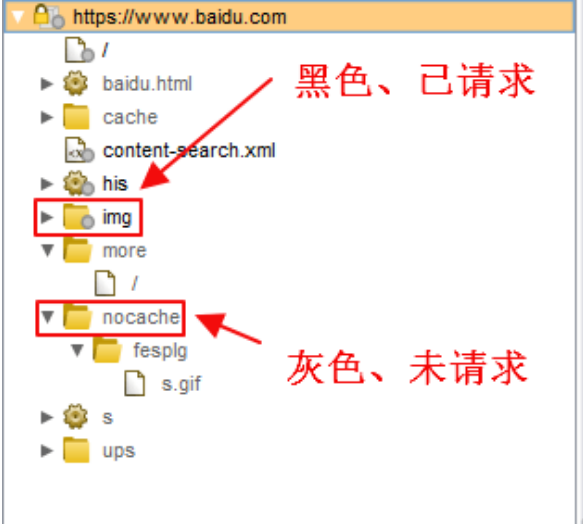
BurpSuite—-Target模块(目标模块)
前言 本文主要介绍BurpSuite—-Target模块(目标模块)的相关内容 关于BurpSuite的安装可以看一下之前这篇文章: http://t.csdn.cn/cavWt Target功能 目标工具包含了SiteMap,用你的目标应用程序的详细信息。它可以让你定义哪些对象在范围上为你目前的工…...

PrediPrune:机器学习驱动的编译器超级优化候选剪枝策略
1. 项目概述与核心挑战在编译器优化的世界里,我们总在追求极致的性能。传统的编译器优化器,比如LLVM的Pass,依赖于一系列预定义的、经过验证的转换规则。它们很高效,但想象力也受限于这些规则。超级优化器(Superoptimi…...

UnityExplorer:如何在游戏运行时实时调试和修改Unity项目
UnityExplorer:如何在游戏运行时实时调试和修改Unity项目 【免费下载链接】UnityExplorer An in-game UI for exploring, debugging and modifying IL2CPP and Mono Unity games. 项目地址: https://gitcode.com/gh_mirrors/un/UnityExplorer UnityExplorer是…...

别急着买内存条!先花5分钟用Win自带工具查清你的笔记本有几个卡槽、最大支持多少G
笔记本内存升级避坑指南:5分钟摸清扩容上限与双通道配置每次打开浏览器标签超过十个就开始卡顿,PS处理图片时进度条仿佛在爬行,剪辑视频时渲染时间足够泡一杯咖啡——这些场景是否让你动了升级笔记本内存的念头?先别急着下单&…...

3分钟掌握清华大学学位论文LaTeX模板:新手快速入门终极指南
3分钟掌握清华大学学位论文LaTeX模板:新手快速入门终极指南 【免费下载链接】thuthesis LaTeX Thesis Template for Tsinghua University 项目地址: https://gitcode.com/gh_mirrors/th/thuthesis 你是否正在为清华大学学位论文的格式要求而头疼?…...

LeetCode 每日一题笔记 日期:2026.05.24 题目:1340. 跳跃游戏 V
LeetCode 每日一题笔记 0. 前言 日期:2026.05.24题目:1340. 跳跃游戏 V难度:困难标签:数组、动态规划、记忆化搜索、单调栈 1. 题目理解 问题描述: 给定一个整数数组 arr 和整数 d,从下标 i 出发࿰…...
Transformer解码器在量子纠错中的应用:突破表面码实时解码瓶颈
1. 项目概述与核心挑战 量子计算这行干久了,你总会遇到一个绕不开的“拦路虎”:量子纠错。这玩意儿是通往实用化、容错量子计算机的必经之路,但其中的解码问题,尤其是针对表面码这类稳定子码的解码,其复杂度和实时性要…...

QMCDecode:解锁你的QQ音乐收藏,让加密音频重获自由
QMCDecode:解锁你的QQ音乐收藏,让加密音频重获自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录ÿ…...

LaTeX公式秒变Word格式:告别复制粘贴的烦恼,让数学表达更自由
LaTeX公式秒变Word格式:告别复制粘贴的烦恼,让数学表达更自由 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为学术…...

2026 收藏版|LangGraph 智能体三大核心工作流,程序员零基础上手大模型开发
本篇全面剖析 2026 主流 LangGraph 智能体三类经典工作流架构,依托任务拆分校验、智能任务分发、多任务并行处理三种思路,全方位提升大模型智能体运行精度与处理效率。每类模式均搭配可直接运行的实战代码案例,贴合新手学习场景,帮…...

5G O-RAN网络智能运维:基于随机森林的异常检测与切换优化实战
1. 项目概述:当5G网络学会“未卜先知”在5G乃至未来6G网络的运维战场上,故障处理正经历一场从“事后救火”到“事前预警”的深刻变革。传统基于静态阈值的告警系统,就像在高速公路上设置固定的限速牌,一旦遇到雨雪、拥堵等复杂路况…...