机器学习项目实战-能源利用率 Part-3(特征工程与特征筛选)
博主前期相关的博客可见下:
机器学习项目实战-能源利用率 Part-1(数据清洗)
机器学习项目实战-能源利用率 Part-2(探索性数据分析)
这部分进行的特征工程与特征筛选。
三 特征工程与特征筛选
一般情况下我们分两步走:特征工程与特征筛选:
特征工程: 概括性来说就是尽可能的多在数据中提取特征,各种数值变换,特征组合,分解等各种手段齐上阵。
特征选择: 就是找到最有价值的那些特征作为我们模型的输入,但是之前做了那么多,可能有些是多余的,有些还没被发现,所以这俩阶段都是一个反复在更新的过程。比如我在建模之后拿到了特征重要性,这就为特征选择做了参考,有些不重要的我可以去掉,那些比较重要的,我还可以再想办法让其做更多变换和组合来促进我的模型。所以特征工程并不是一次性就能解决的,需要通过各种结果来反复斟酌。
3.1 特征变换 与 One-hot encode
有点像分析特征之间的相关性
features = data.copy()
numeric_subset = data.select_dtypes('number')
for col in numeric_subset.columns:if col == 'score':nextelse:numeric_subset['log_' + col] = np.log(abs(numeric_subset[col]) + 0.01)categorical_subset = data[['Borough', 'Largest Property Use Type']]
categorical_subset = pd.get_dummies(categorical_subset)features = pd.concat([numeric_subset, categorical_subset], axis = 1)
features.shape
这段代码的目的是为了生成特征矩阵 features,它包含了原始数据 data 的数值特征和分类特征的处理结果。
首先,代码复制了原始数据 data,并将其赋值给 features。
接下来,通过 select_dtypes('number') 选择了 data 中的数值类型的列,并将结果存储在 numeric_subset 中。
然后,使用一个循环遍历 numeric_subset 的列,对每一列进行处理。对于列名为 ‘score’ 的列,直接跳过(使用 next)。对于其他列,将其绝对值加上一个很小的常数(0.01),然后取对数,并将结果存储在 numeric_subset 中以 ‘log_’ 开头的列名中。
接着,从 data 中选择了 ‘Borough’ 和 ‘Largest Property Use Type’ 两列作为分类特征,并使用 pd.get_dummies 进行独热编码(One-Hot Encoding)得到它们的编码结果,并将结果存储在 categorical_subset 中。
最后,使用 pd.concat 将 numeric_subset 和 categorical_subset 按列方向(axis=1)进行拼接,得到最终的特征矩阵 features。
最后一行代码输出了 features 的形状(行数和列数)。

3.2 共线特征
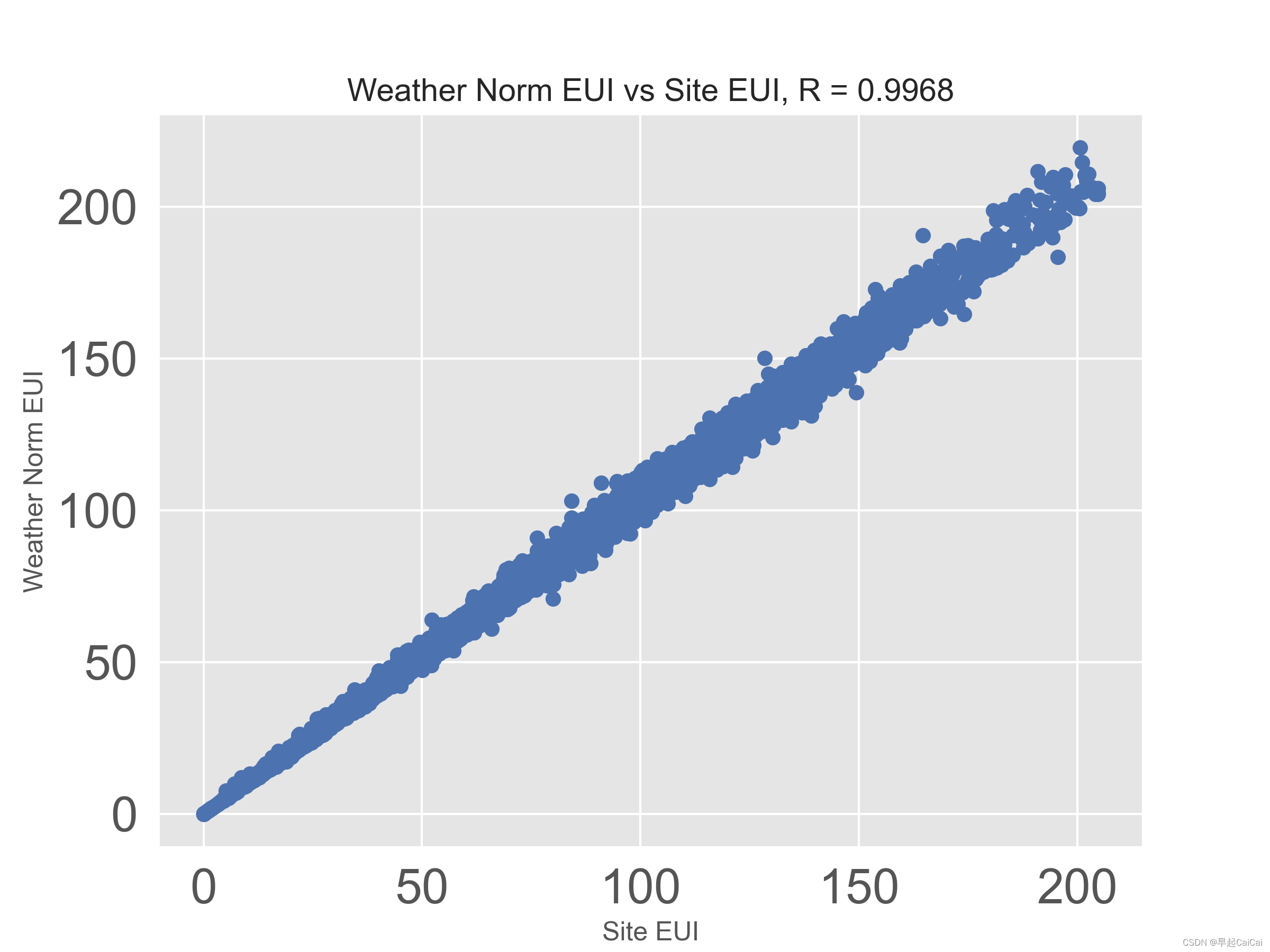
在数据中Site EUI 和 Weather Norm EUI就是要考虑的目标,他俩描述的基本是同一个事
plot_data = data[['Weather Normalized Site EUI (kBtu/ft²)', 'Site EUI (kBtu/ft²)']].dropna()plt.plot(plot_data['Site EUI (kBtu/ft²)'], plot_data['Weather Normalized Site EUI (kBtu/ft²)'], 'bo')
plt.xlabel('Site EUI'); plt.ylabel('Weather Norm EUI')
plt.title('Weather Norm EUI vs Site EUI, R = %.4f' % np.corrcoef(data[['Weather Normalized Site EUI (kBtu/ft²)', 'Site EUI (kBtu/ft²)']].dropna(), rowvar=False)[0][1])
3.3 剔除共线特征
def remove_collinear_features(x, threshold):'''Objective:Remove collinear features in a dataframe with a correlation coefficientgreater than the threshold. Removing collinear features can help a modelto generalize and improves the interpretability of the model.Inputs: threshold: any features with correlations greater than this value are removedOutput: dataframe that contains only the non-highly-collinear features'''y = x['score']x = x.drop(columns = ['score'])corr_matrix = x.corr()iters = range(len(corr_matrix.columns) - 1)drop_cols = []for i in iters:for j in range(i):item = corr_matrix.iloc[j: (j+1), (i+1): (i+2)] col = item.columnsrow = item.indexval = abs(item.values) if val >= threshold:# print(col.values[0], "|", row.values[0], "|", round(val[0][0], 2))drop_cols.append(col.values[0])drops = set(drop_cols)# print(drops)x = x.drop(columns = drops)x = x.drop(columns = ['Weather Normalized Site EUI (kBtu/ft²)', 'Water Use (All Water Sources) (kgal)','log_Water Use (All Water Sources) (kgal)','Largest Property Use Type - Gross Floor Area (ft²)'])x['score'] = yreturn xfeatures = remove_collinear_features(features, 0.6) # 阈值为0.6
features = features.dropna(axis = 1, how = 'all')
print(features.shape)
features.head()这段代码定义了一个名为 remove_collinear_features 的函数,用于移除具有高相关性的特征。移除具有高相关性的特征可以帮助模型泛化并提高模型的解释性。
函数的输入参数为 x(包含特征和目标变量的数据框)和 threshold(相关系数的阈值),阈值以上的特征相关性会被移除。
首先,将目标变量 score 存储在变量 y 中,并将其从 x 中移除。
接下来,计算特征之间的相关系数矩阵 corr_matrix。
然后,使用两个嵌套的循环遍历相关系数矩阵中的元素。当相关系数的绝对值大于等于阈值时,将该特征的列名添加到 drop_cols 列表中。
完成循环后,将 drop_cols 转换为集合 drops,以去除重复的特征列名。
然后,从 x 中移除 drops 中的特征列,以及其他预定义的特征列。
接下来,将目标变量 y 添加回 x 中,并将结果返回。
最后,对更新后的特征矩阵 features 进行处理,移除所有包含缺失值的列,并输出其形状(行数和列数),并展示前几行数据。
3.4 数据集划分
no_score = features[features['score'].isna()]
score = features[features['score'].notnull()]
print('no_score.shape: ', no_score.shape)
print('score.shape', score.shape)from sklearn.model_selection import train_test_split
features = score.drop(columns = 'score')
labels = pd.DataFrame(score['score'])
features = features.replace({np.inf: np.nan, -np.inf: np.nan})
X, X_test, y, y_test = train_test_split(features, labels, test_size = 0.3, random_state = 42)
print(X.shape)
print(X_test.shape)
print(y.shape)
print(y_test.shape)
这段代码分为几个步骤:
-
首先,将特征矩阵
features分为两部分:no_score和score。其中,no_score是features中目标变量score为空的部分,而score则是features中目标变量score不为空的部分。 -
输出
no_score和score的形状(行数和列数),分别使用no_score.shape和score.shape打印结果。 -
导入
sklearn.model_selection模块中的train_test_split函数。 -
从
score中移除目标变量score列,得到特征矩阵features。 -
创建标签(目标变量)矩阵
labels,其中只包含目标变量score列。 -
使用
replace方法将features中的无穷大值替换为缺失值(NaN)。 -
使用
train_test_split函数将特征矩阵features和标签矩阵labels划分为训练集和测试集。参数test_size设置测试集的比例为 0.3,random_state设置随机种子为 42。将划分后的结果分别存储在X、X_test、y和y_test中。 -
输出训练集
X、测试集X_test、训练集标签y和测试集标签y_test的形状(行数和列数),分别使用X.shape、X_test.shape、y.shape和y_test.shape打印结果。
这段代码的目的是将数据集划分为训练集和测试集,并准备好用于训练和评估模型的特征矩阵和标签矩阵。

3.5 建立一个Baseline
在建模之前,我们得有一个最坏的打算,就是模型起码得有点作用才行。
# 衡量标准: Mean Absolute Error
def mae(y_true, y_pred):return np.mean(abs(y_true - y_pred))baseline_guess = np.median(y)print('The baseline guess is a score of %.2f' % baseline_guess)
print('Baseline Performance on the test set: MAE = %.4f' % mae(y_test, baseline_guess))
这段代码定义了一个衡量标准函数 mae,并计算了一个基准预测结果。
-
mae函数计算了预测值与真实值之间的平均绝对误差(Mean Absolute Error)。它接受两个参数y_true和y_pred,分别表示真实值和预测值。函数内部通过np.mean(abs(y_true - y_pred))计算平均绝对误差,并返回结果。 -
baseline_guess是基准预测的结果,它被设置为标签(目标变量)y的中位数。这相当于一种简单的基准方法,用中位数作为所有预测的固定值。 -
使用
print函数打印基准预测结果的信息。'The baseline guess is a score of %.2f' % baseline_guess会输出基准预测结果的值,保留两位小数。'Baseline Performance on the test set: MAE = %.4f' % mae(y_test, baseline_guess)会输出基准预测结果在测试集上的性能,即平均绝对误差(MAE),保留四位小数。
这段代码的目的是计算基准预测结果,并输出基准预测结果的信息以及在测试集上的性能评估(使用平均绝对误差作为衡量标准)。

3.6 保存数据
no_score.to_csv('data/no_score.csv', index = False)
X.to_csv('data/training_features.csv', index = False)
X_test.to_csv('data/testing_features.csv', index = False)
y.to_csv('data/training_labels.csv', index = False)
y_test.to_csv('data/testing_labels.csv', index = False)
Reference
机器学习项目实战-能源利用率 Part-1(数据清洗)
机器学习项目实战-能源利用率 Part-2(探索性数据分析)
机器学习项目实战-能源利用率1-数据预处理
相关文章:
机器学习项目实战-能源利用率 Part-3(特征工程与特征筛选)
博主前期相关的博客可见下: 机器学习项目实战-能源利用率 Part-1(数据清洗) 机器学习项目实战-能源利用率 Part-2(探索性数据分析) 这部分进行的特征工程与特征筛选。 三 特征工程与特征筛选 一般情况下我们分两步走…...
WebSocket的那些事(2-实操篇)
目录 一、概述二、Websocket API1、引入相关依赖2、配置WebSocket处理器3、WebSocket配置4、测试 三、总结 一、概述 在上一节 WebSocket的那些事(1-概念篇)中我们简单的介绍了关于WebSocket协议的相关概念、与HTTP的联系区别等等。 这一节将会带来Web…...
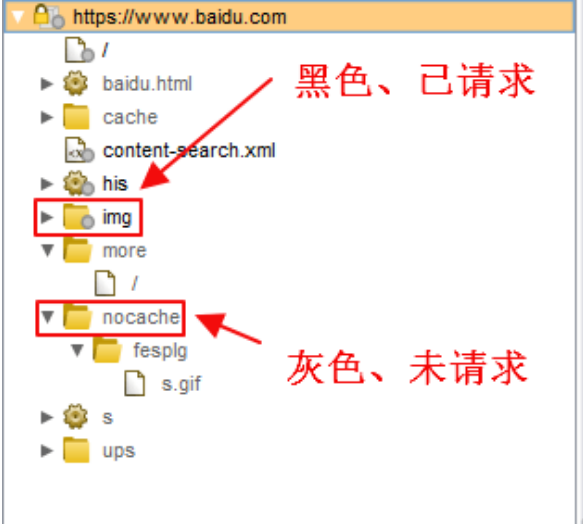
BurpSuite—-Target模块(目标模块)
前言 本文主要介绍BurpSuite—-Target模块(目标模块)的相关内容 关于BurpSuite的安装可以看一下之前这篇文章: http://t.csdn.cn/cavWt Target功能 目标工具包含了SiteMap,用你的目标应用程序的详细信息。它可以让你定义哪些对象在范围上为你目前的工…...

部门来了个测试开发,听说是00后,上来一顿操作给我看呆了...
公司新来了个同事,听说大学是学的广告专业,因为喜欢IT行业就找了个培训班,后来在一家小公司实习半年,现在跳槽来我们公司。来了之后把现有项目的性能优化了一遍,服务器缩减一半,性能反而提升4倍!…...

Godot引擎 4.0 文档 - 入门介绍 - Godot简介
本文为Google Translate英译中结果,DrGraph在此基础上加了一些校正。英文原版页面:Introduction to Godsot — Godot Engine (stable) documentation in English Godot简介 本文旨在帮助您确定 Godot 是否适合您。我们将介绍该引擎的一些广泛功能&#…...

数据通信基础 - 码元速率 和 数据速率 详解
文章目录 1 概述1.1 码元速率(波特率)1.2 数据速率(比特率)1.3 码元速率 和 数据速率 换算 2 网工软考真题 1 概述 1.1 码元速率(波特率) 码元速率:表示单位时间内信号波形的变换次数…...

听我一句劝,别去外包,干了三年,废了....
先说一下自己的情况,大专生,18年通过校招进入湖南某软件公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测试…...

全域兴趣电商:国货品牌的新策略、新玩法
【潮汐商业评论/原创】 消费的方向标已经变了。 在消费市场的滚滚浪潮里,国人的“衣食住行”在全面的“国货化”,一个个有颜值有实力的国货品牌如雨后春笋般出现在寻常百姓家,如今在这片肥沃的土壤上正结出适合国人使用的果实。 01 国货二…...
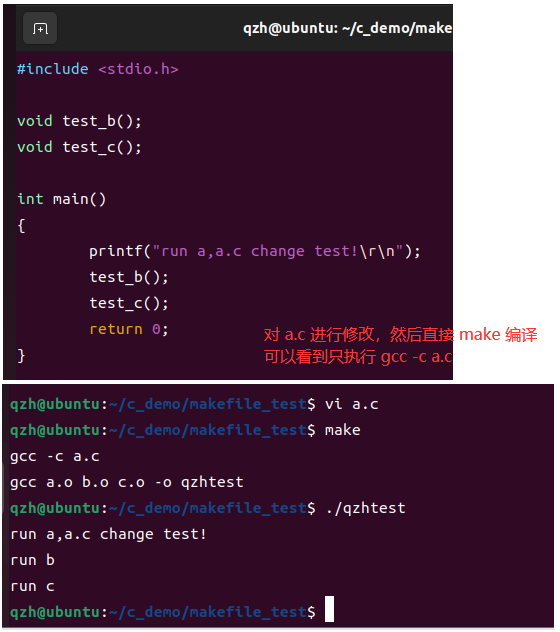
嵌入式 Linux 入门(十一、make 和 MakeFile)
嵌入式 Linux 入门第十一课,Make 工具和 Makefile 的引入...... 矜辰所致目录 前言一、Linux 下多文件编译二、make 工具和 Makefile2.1 make 和 Makefile 是什么?2.2 通过 STM32 提前熟悉 Makefile2.3 GCC 与 make 的关系/区别? 三、一个简单的 Makefi…...
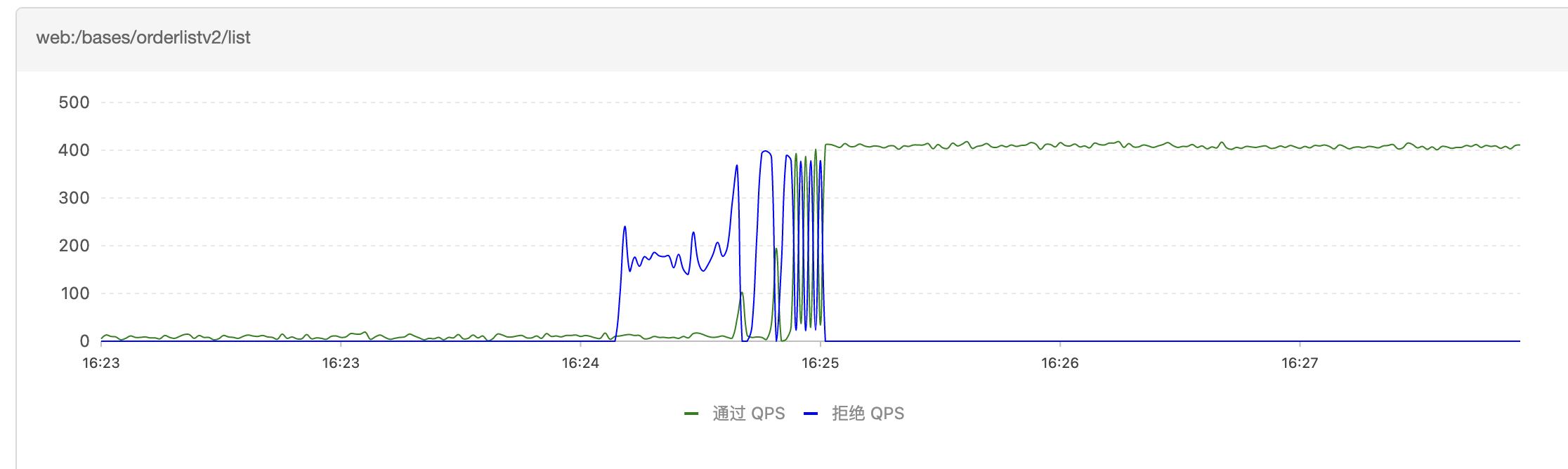
Serverless冷扩机器在压测中被击穿问题 | 京东云技术团队
一、现象回顾 在今天ForceBot全链路压测中,有位同事负责的服务做Serverless扩容(负载达到50%之后自动扩容并上线接入流量)中,发现新扩容的机器被击穿,监控如下(关注2:40-3:15时间段的数据)&…...
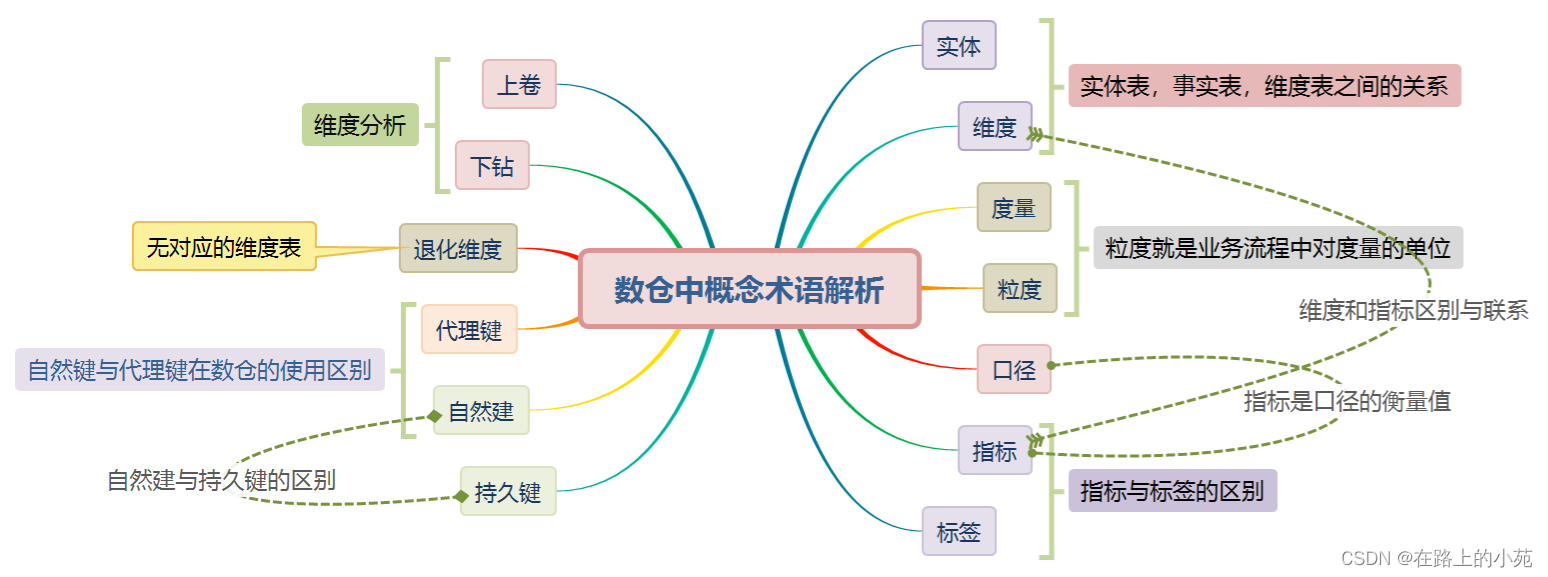
数仓中指标-标签,维度-度量,自然键-代理键等各名词深度解析
作为一个数据人,是不是经常被各种名词围绕,是不是对其中很多概念认知模糊。有些词虽然只有一字之差,但是它们意思完全不同,今天我们就来了解下数仓建设及数据分析时常见的一些概念含义及它们之间的关系。 本文首发于公众号【五分钟…...
(Mono))
Baumer工业相机堡盟工业相机使用BGAPI SDK将图像数据转换为Bitmap的几种方式(C++)(Mono)
Baumer工业相机堡盟工业相机使用BGAPI SDK将图像数据转换为Bitmap的几种方式(C) Baumer工业相机Baumer工业相机图像数据转为Bitmap的技术背景Baumer工业相机使用BGAPISDK将图像数据转换为Bitmap的几种方式1.引用合适的类文件2.BGAPI SDK原始图像数据为Bi…...
C++笔试笔记2
C笔试笔记2 百富计算机的笔试 const限定符:首先作用于左边,如果左边没东西,就作用于右边。 const int: 左边没有内容,所以const作用于右边,就是“整型常量”。等同于int const; int * const&am…...

手写Spring框架
手写Spring框架 各位道友,我发现现在贼卷底层代码,看完源码发下几天后,额!!!我当时看了啥! 还是自己写个迷你的spring框架,这样印象更加深刻,上干货,代码仓…...
)
微服务学习笔记--(Docker)
目录 初识DockerDcoker的基本操作Dockerfile自定义镜像Docker-ComposeDocker镜像服务 初始Docter 什么是DockerDocker和虚拟机的区别Docker架构安装Docker 初识Docker-什么是docker 项目部署的问题 大型项目组件较多,运行环境也较为复杂,部署时会碰…...

ChatGPT 国内版免费
ChatGPT 是最新的聊天机器人技术,它可以让你更快地完成各种任务。如果你想要一个在国内的免费版本,你来对地方了!在这篇文章中,我们将会分享与你 ChatGPT的最新信息,以及在国内使用 ChatGPT 的方法。如果你想要了解更多…...
推荐5个免费好用的UI模板网站!
1、即时设计 即时设计资源广场是一个聚集了大量优秀设计作品和大厂设计系统超过3000个UI组件库的设计师灵感库。该广场每月更新上百个精品模板,且还将这些模板分门别类按不同类型素材进行分类,其丰富的设计资源包括移动设计、网页设计、插画、线框图、矢…...
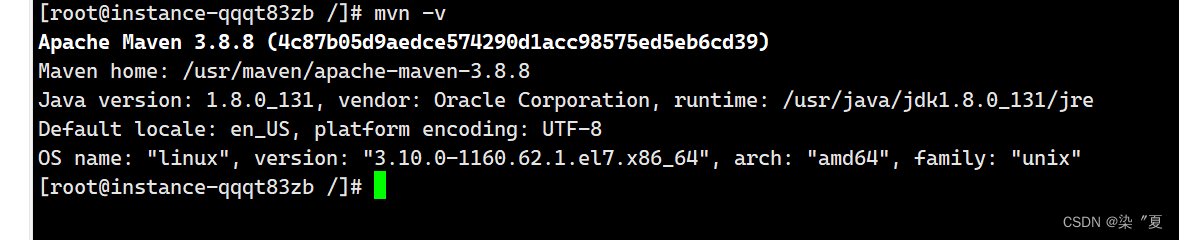
linux 安装 maven 3.8 版本
文章目录 1:maven 仓库官网 2、下载安装包 3、使用:Xftp 上传到你想放的目录 4、解压文件 编辑 5、配置环境变量 编辑 6、刷新 /etc/profile 文件 7、查看maven 版本 1:maven 仓库官网 Maven – Download Apache Mavenhttps://mave…...

Redis的三种持久化策略及选取建议
文章目录 Redis的三种持久化策略及选取建议前言RDB(快照)概述优缺点 AOF(追加文件)概述优缺点AOF刷盘策略AOF重写 选取正确的持久化策略AOF和RDB的选择AOF与RDB的混合模式AOF重写和RDB持久化的冲突AOF校验机制三种模式的选择建议 …...

力扣LCP 33. 蓄水
LCP 33. 蓄水 给定 N 个无限容量且初始均空的水缸,每个水缸配有一个水桶用来打水,第 i 个水缸配备的水桶容量记作 bucket[i]。有以下两种操作: 升级水桶:选择任意一个水桶,使其容量增加为 bucket[i]1 蓄水࿱…...

GEP协议深度解读:AI智能体自我进化的基因工程
OpenAI 官宣全面支持MCP协议,标志着AI应用架构的"连接标准"已定。如果说MCP是AI时代的USB-C,解决了模型与工具的连接问题,那么GEP(Genome Evolution Protocol,基因组进化协议)则正在解决另一个更本质的问题——智能体的自我进化与生命周期管理。 作为下一代AI基…...

手机也能玩转无人机仿真:用安卓QGC App连接同一WiFi下的PX4 JMAVSim模拟器
手机也能玩转无人机仿真:用安卓QGC App连接同一WiFi下的PX4 JMAVSim模拟器 无人机开发者和爱好者们,是否曾想过用手机就能完成整个无人机仿真测试流程?告别笨重的电脑束缚,只需一部安卓设备,就能在沙发上调试飞控算法。…...

如何用Nucleus Co-Op让单机游戏变身本地多人分屏神器
如何用Nucleus Co-Op让单机游戏变身本地多人分屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为想和朋友一起玩游戏却只有一台电脑而烦…...

SHAP原理与特征贡献解析
SHAP(SHapley Additive exPlanations)是一种基于博弈论中Shapley值的模型解释方法,它为机器学习模型的预测提供了一种统一、理论完备的特征归因框架。其核心思想是将模型的预测值视为所有特征协同合作的“总收益”,然后公平地分配…...

Windows多显示器DPI缩放终极解决方案:告别模糊显示,享受清晰视觉体验
Windows多显示器DPI缩放终极解决方案:告别模糊显示,享受清晰视觉体验 【免费下载链接】SetDPI 项目地址: https://gitcode.com/gh_mirrors/se/SetDPI 你是不是曾经遇到过这样的困扰?连接多个显示器时,文字和图标大小不一&…...

CANoe测试效率翻倍:手把手教你用XML Test Module搭建可复用的测试套件
CANoe测试效率翻倍:手把手教你用XML Test Module搭建可复用的测试套件在车载电子系统开发中,测试环节往往占据整个项目周期的40%以上时间。面对频繁的ECU软件迭代和多样化配置需求,传统逐个脚本执行测试的方式已经无法满足敏捷开发的要求。本…...

量子循环神经网络在混沌时序预测中的参数效率与架构对比
1. 项目概述 最近几年,量子机器学习(QML)的热度持续攀升,大家都想看看,用量子计算那套“叠加”和“纠缠”的玩法来处理经典问题,到底能不能带来点惊喜。时序预测,尤其是混沌系统预测,…...

Unity Find Reference2 2.5.2版本深度解析与正确接入指南
1. 这不是普通插件下载:Find Reference2 的真实价值与误用重灾区“Unity Find Reference2 2.5.2版本资源下载”——看到这个标题,很多Unity开发者第一反应是点开就找网盘链接、GitHub Release页面或某论坛的打包附件。我试过不下二十次:复制标…...

从一次PR被拒说起:我是如何用Git Upstream优雅同步Gitee Fork仓库的
从一次PR被拒说起:我是如何用Git Upstream优雅同步Gitee Fork仓库的 那天下午,当我满怀期待地打开Gitee通知,看到的却是项目维护者冰冷的回复:"PR存在大量冲突,请先同步最新代码"。作为一个刚接触开源贡献的…...

MySQL报错注入与堆叠注入的底层原理与实战对抗
1. 这不是“学SQL注入”,而是重建你对数据库交互的认知边界2021年7月8日这个日期,对很多刚入CTF圈的朋友来说,可能只是训练平台里一个普通题目的提交时间戳。但对我而言,那天在调试一道看似简单的报错注入题时,连续卡了…...