MySql-高级(分库分表问题简析) 学习笔记
文章目录
- 1. 为什么要分库分表?
- 2. 用过哪些分库分表中间件?不同的分库分表中间件都有什么优点和缺点?
- 3. 你们具体是如何对数据库如何进行垂直拆分或水平拆分的?
- 4. 分库分表时,数据迁移方案
- 5. 如何设计可以动态扩容缩容的分库分表方案?
- 6. 分库分表之后,id 主键如何处理?
- 7. 如何实现 MySQL 的读写分离?
- 8. MySQL 主从复制原理的是啥?
- 9. MySQL 主从同步延时问题
1. 为什么要分库分表?
- 说白了,分库分表是两回事儿,大家可别搞混了,可能是光分库不分表,也可能是光分表不分库,都有可能。
- 我先给大家抛出来一个场景。
- 假如我们现在是一个小创业公司,现在注册用户就 20 万,每天活跃用户就 1 万,每天单表数据量就 1000,然后高峰期每秒钟并发请求最多就 10。天,就这种系统,随便找一个有几年工作经验的,然后带几个刚培训出来的,随便干干都可以。
- 结果没想到我们运气居然这么好,碰上个 CEO 带着我们走上了康庄大道,业务发展迅猛,过了几个月,注册用户数达到了 2000 万!每天活跃用户数 100 万!每天单表数据量 10 万条!高峰期每秒最大请求达到 1000!
- 好吧,没事,现在大家感觉压力已经有点大了,为啥呢?因为每天多 10 万条数据,一个月就多 300 万条数据,现在咱们单表已经几百万数据了,马上就破千万了。但是勉强还能撑着。高峰期请求现在是 1000,咱们线上部署了几台机器,负载均衡搞了一下,数据库撑 1000QPS 也还凑合。但是大家现在开始感觉有点担心了,接下来咋整呢…
- 再接下来几个月,我的天,CEO 太牛逼了,公司用户数已经达到 1 亿,因为此时每天活跃用户数上千万,每天单表新增数据多达 50 万,目前一个表总数据量都已经达到了两三千万了!扛不住啊!数据库磁盘容量不断消耗掉!高峰期并发达到惊人的 5000~8000!别开玩笑了,哥。我跟你保证,你的系统支撑不到现在,已经挂掉了!
- 好吧,所以你看到这里差不多就理解分库分表是怎么回事儿了,实际上这是跟着你的公司业务发展走的,你公司业务发展越好,用户就越多,数据量越大,请求量越大,那你单个数据库一定扛不住。
分表
- 比如你单表都几千万数据了,你确定你能扛住么?绝对不行,单表数据量太大,会极大影响你的 sql 执行的性能,到了后面你的 sql 可能就跑的很慢了。一般来说,就以我的经验来看,单表到几百万的时候,性能就会相对差一些了,你就得分表了。
- 分表是啥意思?就是把一个表的数据放到多个表中,然后查询的时候你就查一个表。比如按照用户 id 来分表,将一个用户的数据就放在一个表中。然后操作的时候你对一个用户就操作那个表就好了。这样可以控制每个表的数据量在可控的范围内,比如每个表就固定在 200 万以内。
分库
- 分库是啥意思?就是你一个库一般我们经验而言,最多支撑到并发 2000,一定要扩容了,而且一个健康的单库并发值你最好保持在每秒 1000 左右,不要太大。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。
| # | 分库分表前 | 分库分表后 |
|---|---|---|
| 并发支撑情况 | MySQL 单机部署,扛不住高并发 | MySQL从单机到多机,能承受的并发增加了多倍 |
| 磁盘使用情况 | MySQL 单机磁盘容量几乎撑满 | 拆分为多个库,数据库服务器磁盘使用率大大降低 |
| SQL 执行性能 | 单表数据量太大,SQL 越跑越慢 | 单表数据量减少,SQL 执行效率明显提升 |
2. 用过哪些分库分表中间件?不同的分库分表中间件都有什么优点和缺点?
- 这个其实就是看看你了解哪些分库分表的中间件,各个中间件的优缺点是啥?然后你用过哪些分库分表的中间件。
- 比较常见的包括:
Cobar
TDDL
Atlas
Sharding-jdbc
Mycat
1. Cobar
- 阿里 b2b 团队开发和开源的,属于 proxy 层方案,就是介于应用服务器和数据库服务器之间。应用程序通过 JDBC 驱动访问 Cobar 集群,Cobar 根据 SQL 和分库规则对 SQL 做分解,然后分发到 MySQL 集群不同的数据库实例上执行。早些年还可以用,但是最近几年都没更新了,基本没啥人用,差不多算是被抛弃的状态吧。而且不支持读写分离、存储过程、跨库 join 和分页等操作。
2. TDDL
- 淘宝团队开发的,属于 client 层方案。支持基本的 crud 语法和读写分离,但不支持 join、多表查询等语法。目前使用的也不多,因为还依赖淘宝的 diamond 配置管理系统。
3. Atlas
- 360 开源的,属于 proxy 层方案,以前是有一些公司在用的,但是确实有一个很大的问题就是社区最新的维护都在 5 年前了。所以,现在用的公司基本也很少了。
4. Sharding-jdbc
- 当当开源的,属于 client 层方案,目前已经更名为 ShardingSphere(后文所提到的 Sharding-jdbc,等同于 ShardingSphere)。确实之前用的还比较多一些,因为 SQL 语法支持也比较多,没有太多限制,而且截至 2019.4,已经推出到了 4.0.0-RC1 版本,支持分库分表、读写分离、分布式 id 生成、柔性事务(最大努力送达型事务、TCC 事务)。而且确实之前使用的公司会比较多一些(这个在官网有登记使用的公司,可以看到从 2017 年一直到现在,是有不少公司在用的),目前社区也还一直在开发和维护,还算是比较活跃,个人认为算是一个现在也可以选择的方案。
5. Mycat
- 基于 Cobar 改造的,属于 proxy 层方案,支持的功能非常完善,而且目前应该是非常火的而且不断流行的数据库中间件,社区很活跃,也有一些公司开始在用了。但是确实相比于 Sharding jdbc 来说,年轻一些,经历的锤炼少一些。
6. 总结
- 综上,现在其实建议考量的,就是 Sharding-jdbc 和 Mycat,这两个都可以去考虑使用。
- Sharding-jdbc 这种 client 层方案的优点在于不用部署,运维成本低,不需要代理层的二次转发请求,性能很高,但是如果遇到升级啥的需要各个系统都重新升级版本再发布,各个系统都需要耦合 Sharding-jdbc 的依赖;
- Mycat 这种 proxy 层方案的缺点在于需要部署,自己运维一套中间件,运维成本高,但是好处在于对于各个项目是透明的,如果遇到升级之类的都是自己中间件那里搞就行了。
- 通常来说,这两个方案其实都可以选用,但是我个人建议中小型公司选用 Sharding-jdbc,client 层方案轻便,而且维护成本低,不需要额外增派人手,而且中小型公司系统复杂度会低一些,项目也没那么多;但是中大型公司最好还是选用 Mycat 这类 proxy 层方案,因为可能大公司系统和项目非常多,团队很大,人员充足,那么最好是专门弄个人来研究和维护 Mycat,然后大量项目直接透明使用即可。
3. 你们具体是如何对数据库如何进行垂直拆分或水平拆分的?
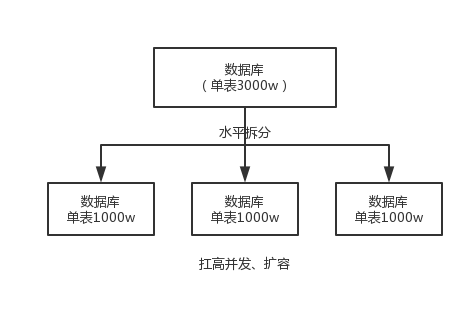
- 水平拆分的意思,就是把一个表的数据给弄到多个库的多个表里去,但是每个库的表结构都一样,只不过每个库表放的数据是不同的,所有库表的数据加起来就是全部数据。水平拆分的意义,就是将数据均匀放更多的库里,然后用多个库来扛更高的并发,还有就是用多个库的存储容量来进行扩容。
- 垂直拆分的意思,就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,会将较少的访问频率很高的字段放到一个表里去,然后将较多的访问频率很低的字段放到另外一个表里去。因为数据库是有缓存的,你访问频率高的行字段越少,就可以在缓存里缓存更多的行,性能就越好。这个一般在表层面做的较多一些。
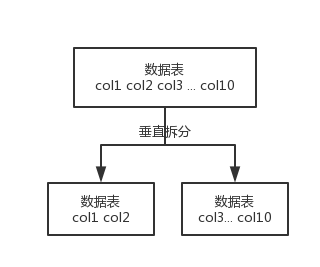
- 这个其实挺常见的,不一定我说,大家很多同学可能自己都做过,把一个大表拆开,订单表、订单支付表、订单商品表。
- 还有表层面的拆分,就是分表,将一个表变成 N 个表,就是让每个表的数据量控制在一定范围内,保证 SQL 的性能。否则单表数据量越大,SQL 性能就越差。一般是 200 万行左右,不要太多,但是也得看具体你怎么操作,也可能是 500 万,或者是 100 万。你的SQL越复杂,就最好让单表行数越少。
- 好了,无论分库还是分表,上面说的那些数据库中间件都是可以支持的。就是基本上那些中间件可以做到你分库分表之后,中间件可以根据你指定的某个字段值,比如说 userid,自动路由到对应的库上去,然后再自动路由到对应的表里去。
- 你就得考虑一下,你的项目里该如何分库分表?一般来说,垂直拆分,你可以在表层面来做,对一些字段特别多的表做一下拆分;水平拆分,你可以说是并发承载不了,或者是数据量太大,容量承载不了,你给拆了,按什么字段来拆,你自己想好;分表,你考虑一下,你如果哪怕是拆到每个库里去,并发和容量都 ok 了,但是每个库的表还是太大了,那么你就分表,将这个表分开,保证每个表的数据量并不是很大。
- 而且这儿还有两种分库分表的方式:
- 一种是按照 range 来分,就是每个库一段连续的数据,这个一般是按比如时间范围来的,但是这种一般较少用,因为很容易产生热点问题,大量的流量都打在最新的数据上了。
- 或者是按照某个字段 hash 一下均匀分散,这个较为常用。
- range 来分,好处在于说,扩容的时候很简单,因为你只要预备好,给每个月都准备一个库就可以了,到了一个新的月份的时候,自然而然,就会写新的库了;缺点,但是大部分的请求,都是访问最新的数据。实际生产用 range,要看场景。
- hash 分发,好处在于说,可以平均分配每个库的数据量和请求压力;坏处在于说扩容起来比较麻烦,会有一个数据迁移的过程,之前的数据需要重新计算 hash 值重新分配到不同的库或表。
4. 分库分表时,数据迁移方案
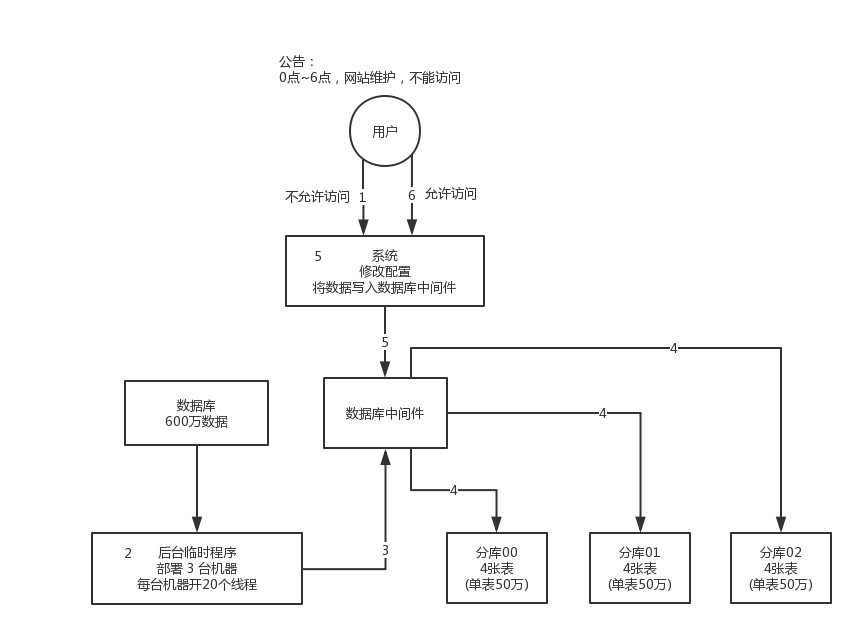
1. 停机迁移方案
- 先是,app 挂个公告,说 0 点到早上 6 点进行运维,无法访问。
- 接着到 0 点停机,系统停掉,没有流量写入了,此时老的单库单表数据库静止了。
- 然后使用之前得写好一个导数的一次性工具,此时直接跑起来,然后将单库单表的数据读出来,写到分库分表里面去。
- 导数完了之后,修改系统的数据库连接配置啥的,包括可能代码和 SQL 也许有修改,那你就用最新的代码,然后直接启动连到新的分库分表上去。
- 验证一下,ok了。
- 但是这种方法的问题就是必须停机,若一天没有迁移成功需要接连几天凌晨进行迁移
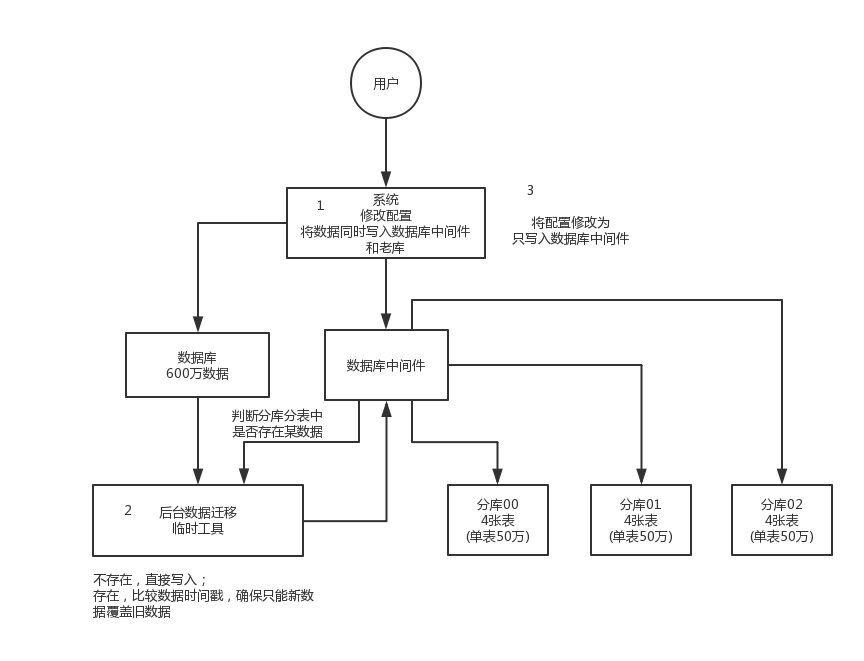
2. 双写迁移方案
- 这个是我们常用的一种迁移方案,比较靠谱一些,不用停机。
- 简单来说,就是在线上系统里面,之前所有写库的地方,增删改操作,除了对老库增删改,都加上对新库的增删改,这就是所谓的双写,同时对老库和新库写入。
- 然后系统部署之后,新库数据差太远,使用导数工具,跑起来读老库数据写新库,写的时候要根据更新时间这类字段判断这条数据最后修改的时间,除非是读出来的数据在新库里没有,或者是比新库的数据新才会写。简单来说,就是不允许用老数据覆盖新数据。
- 导完一轮之后,有可能数据还是存在不一致,那么就程序自动做一轮校验,比对新老库每个表的每条数据,接着如果有不一样的,就针对那些不一样的,从老库读数据再次写。反复循环,直到两个库每个表的数据都完全一致为止。
- 最后将向老库写数据的代码删除,重新部署一次,就好了
- 这种方式也不需要停机,只需要导数工具在后台一直运行即可。
5. 如何设计可以动态扩容缩容的分库分表方案?
- 对于分库分表来说,主要是面对以下问题:
- 选择一个数据库中间件,调研、学习、测试;
- 设计你的分库分表的一个方案,你要分成多少个库,每个库分成多少个表,比如 3 个库,每个库 4 个表;
- 基于选择好的数据库中间件,以及在测试环境建立好的分库分表的环境,然后测试一下能否正常进行分库分表的读写;
- 完成单库单表到分库分表的迁移,双写方案;
- 线上系统开始基于分库分表对外提供服务;
- 扩容了,扩容成 6 个库,每个库需要 12 个表,你怎么来增加更多库和表呢?
分库方案
- 设定好几台数据库服务器,每台服务器上几个库,每个库多少个表,推荐是 32 库 * 32 表,对于大部分公司来说,可能几年都够了。
- 路由的规则,orderId % 32 = 库,orderId / 32 % 32 = 表
- 扩容的时候,申请增加更多的数据库服务器,装好 mysql,呈倍数扩容,4 台服务器,扩到 8 台服务器,再到 16 台服务器。
- 由 dba 负责将原先数据库服务器的库,迁移到新的数据库服务器上去,库迁移是有一些便捷的工具的。
- 我们这边就是修改一下配置,调整迁移的库所在数据库服务器的地址。
- 重新发布系统,上线,原先的路由规则变都不用变,直接可以基于 n 倍的数据库服务器的资源,继续进行线上系统的提供服务。
6. 分库分表之后,id 主键如何处理?
1. 基于数据库的实现方案
-
使用一个单独的库,这个库不做分库分表,就只有它一个,此时当系统里每次得到一个 id,都是往这个库的一个表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个 id。拿到这个 id 之后再往对应的分库分表里去写入。
-
这个方案的好处就是方便简单,谁都会用;
-
缺点就是单库生成自增 id,要是高并发的话,就会有瓶颈的;如果你硬是要改进一下,那么就专门开一个服务出来,这个服务每次就拿到当前 id 最大值,然后自己递增几个 id,一次性返回一批 id,然后再把当前最大 id 值修改成递增几个 id 之后的一个值;但是无论如何都是基于单个数据库。
2. UUID
-
好处就是本地生成,不要基于数据库来了;
-
不好之处就是
- UUID 太长了、占用空间大,作为主键性能太差了;
- ,UUID 不具有有序性,会导致 B+ 树索引在写的时候有过多的随机写操作(连续的 ID 可以产生部分顺序写)
- 由于在写的时候不能产生有顺序的 append 操作,而需要进行 insert 操作,将会读取整个 B+ 树节点到内存,在插入这条记录后会将整个节点写回磁盘,这种操作在记录占用空间比较大的情况下,性能下降明显。
-
适合的场景:如果你是要随机生成个什么文件名、编号之类的,你可以用 UUID,但是作为主键是不能用 UUID 的。
3. snowflake 算法
-
snowflake 算法是 twitter 开源的分布式 id 生成算法,采用 Scala 语言实现,是把一个 64 位的 long 型的 id,1 个 bit 是不用的,用其中的 41 bit 作为毫秒数,用 10 bit 作为工作机器 id,12 bit 作为序列号。
0 | 0001 1001 0100 0101 0111 1101 0001 0010 1011 1000 0 | 1000 1 | 1100 1 | 0000 0000 0000- 1 bit:不用,为啥呢?因为二进制里第一个 bit 为如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个 bit 统一都是 0。
- 41 bit:表示的是时间戳,单位是毫秒。41 bit 可以表示的数字多达 241 - 1,也就是可以标识 241 - 1 个毫秒值,换算成年就是表示69年的时间。
- 10 bit:记录工作机器 id,代表的是这个服务最多可以部署在 210台机器上哪,也就是1024台机器。但是 10 bit 里 5 个 bit 代表机房 id,5 个 bit 代表机器 id。意思就是最多代表 25个机房(32个机房),每个机房里可以代表 25 个机器(32台机器)。
- 12 bit:这个是用来记录同一个毫秒内产生的不同 id,12 bit 可以代表的最大正整数是 212 - 1 = 4096,也就是说可以用这个 12 bit 代表的数字来区分同一个毫秒内的 4096 个不同的 id。
-
Java 改写的雪花算法
public class IdWorker {private long workerId;private long datacenterId;private long sequence;public IdWorker(long workerId, long datacenterId, long sequence) {// sanity check for workerId// 这儿不就检查了一下,要求就是你传递进来的机房id和机器id不能超过32,不能小于0if (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));}if (datacenterId > maxDatacenterId || datacenterId < 0) {throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));}System.out.printf("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d",timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId);this.workerId = workerId;this.datacenterId = datacenterId;this.sequence = sequence;}private long twepoch = 1288834974657L;private long workerIdBits = 5L;private long datacenterIdBits = 5L;// 这个是二进制运算,就是 5 bit最多只能有31个数字,也就是说机器id最多只能是32以内private long maxWorkerId = -1L ^ (-1L << workerIdBits);// 这个是一个意思,就是 5 bit最多只能有31个数字,机房id最多只能是32以内private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);private long sequenceBits = 12L;private long workerIdShift = sequenceBits;private long datacenterIdShift = sequenceBits + workerIdBits;private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;private long sequenceMask = -1L ^ (-1L << sequenceBits);private long lastTimestamp = -1L;public long getWorkerId() {return workerId;}public long getDatacenterId() {return datacenterId;}public long getTimestamp() {return System.currentTimeMillis();}public synchronized long nextId() {// 这儿就是获取当前时间戳,单位是毫秒long timestamp = timeGen();if (timestamp < lastTimestamp) {System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));}if (lastTimestamp == timestamp) {// 这个意思是说一个毫秒内最多只能有4096个数字// 无论你传递多少进来,这个位运算保证始终就是在4096这个范围内,避免你自己传递个sequence超过了4096这个范围sequence = (sequence + 1) & sequenceMask;if (sequence == 0) {timestamp = tilNextMillis(lastTimestamp);}} else {sequence = 0;}// 这儿记录一下最近一次生成id的时间戳,单位是毫秒lastTimestamp = timestamp;// 这儿就是将时间戳左移,放到 41 bit那儿;// 将机房 id左移放到 5 bit那儿;// 将机器id左移放到5 bit那儿;将序号放最后12 bit;// 最后拼接起来成一个 64 bit的二进制数字,转换成 10 进制就是个 long 型return ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift)| (workerId << workerIdShift) | sequence;}private long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}private long timeGen() {return System.currentTimeMillis();}// ---------------测试---------------public static void main(String[] args) {IdWorker worker = new IdWorker(1, 1, 1);for (int i = 0; i < 30; i++) {System.out.println(worker.nextId());}}} -
大概这个意思吧,就是说 41 bit 是当前毫秒单位的一个时间戳,就这意思;然后 5 bit 是你传递进来的一个机房 id(但是最大只能是 32 以内),另外 5 bit 是你传递进来的机器 id(但是最大只能是 32 以内),剩下的那个 12 bit序列号,就是如果跟你上次生成 id 的时间还在一个毫秒内,那么会把顺序给你累加,最多在 4096 个序号以内。
-
所以你自己利用这个工具类,自己搞一个服务,然后对每个机房的每个机器都初始化这么一个东西,刚开始这个机房的这个机器的序号就是 0。然后每次接收到一个请求,说这个机房的这个机器要生成一个 id,你就找到对应的 Worker 生成。
-
这个 snowflake 算法相对来说还是比较靠谱的,所以你要真是搞分布式 id 生成,如果是高并发啥的,那么用这个应该性能比较好,一般每秒几万并发的场景,也足够你用了。
7. 如何实现 MySQL 的读写分离?
- 其实很简单,就是基于主从复制架构,简单来说,就搞一个主库,挂多个从库,然后我们就单单只是写主库,然后主库会自动把数据给同步到从库上去。
- 一个主库最多也就挂三五个从库就可以了,再多也会影响到性能。
8. MySQL 主从复制原理的是啥?
-
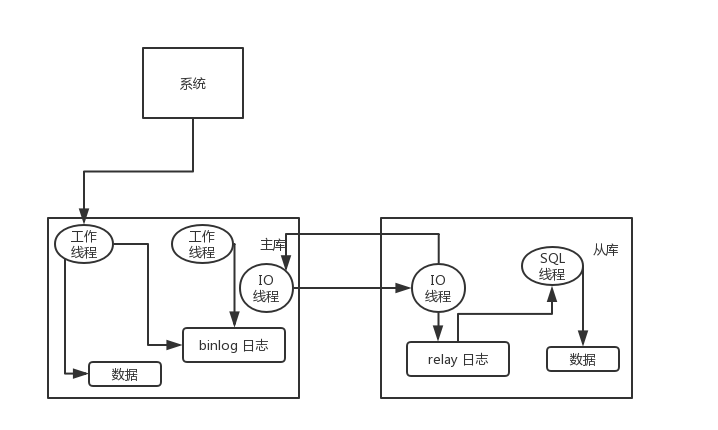
主库将变更写入 binlog 日志,然后从库连接到主库之后,从库有一个 IO 线程,将主库的 binlog 日志拷贝到自己本地,写入一个 relay 中继日志中。接着从库中有一个 SQL 线程会从中继日志读取 binlog,然后回放 binlog 日志中的内容,也就是在自己本地再次执行一遍 SQL,这样就可以保证自己跟主库的数据是一样的。
-
这里有一个非常重要的一点,就是从库同步主库数据的过程是串行化的,也就是说主库上并行的操作,在从库上会串行执行。所以这就是一个非常重要的点了,由于从库从主库拷贝日志以及串行执行 SQL 的特点,在高并发场景下,从库的数据一定会比主库慢一些,是有延时的。所以经常出现,刚写入主库的数据可能是读不到的,要过几十毫秒,甚至几百毫秒才能读取到。
-
而且这里还有另外一个问题,就是如果主库突然宕机,然后恰好数据还没同步到从库,那么有些数据可能在从库上是没有的,有些数据可能就丢失了。
-
所以 MySQL 实际上在这一块有两个机制,
- 一个是半同步复制,用来解决主库数据丢失问题;
- 一个是并行复制,用来解决主从同步延时问题。
-
半同步复制,也叫 semi-sync 复制,指的就是主库写入 binlog 日志之后,就会将强制此时立即将数据同步到从库,从库将日志写入自己本地的 relay log 之后,接着会返回一个 ack 给主库,主库接收到至少一个从库的 ack 之后才会认为写操作完成了。
-
并行复制,指的是从库开启多个线程,并行读取 relay log 中不同库的日志,然后并行重放不同库的日志,这是库级别的并行。
9. MySQL 主从同步延时问题
-
以前线上确实处理过因为主从同步延时问题而导致的线上的 bug,属于小型的生产事故。
-
是这个么场景。有个同学是这样写代码逻辑的。先插入一条数据,再立马把它查出来,然后更新这条数据。在生产环境高峰期,写并发达到了 2000/s,这个时候,主从复制延时大概是在小几十毫秒。线上会发现,每天总有那么一些数据,我们期望更新一些重要的数据状态,但在高峰期时候却没更新。
-
我们通过 MySQL 命令:
show status查看 Seconds_Behind_Master,可以看到从库复制主库的数据落后了几 ms。
-
一般来说,如果主从延迟较为严重,有以下解决方案:
- 分库,将一个主库拆分为多个主库,每个主库的写并发就减少了几倍,此时主从延迟可以忽略不计。
- 打开 MySQL 支持的并行复制,多个库并行复制。如果说某个库的写入并发就是特别高,单库写并发达到了 2000/s,并行复制还是没意义。
- 重写代码,写代码的同学,要慎重,插入数据时立马查询可能查不到。
- 如果确实是存在必须先插入,立马要求就查询到,然后立马就要反过来执行一些操作,对这个查询设置直连主库。不推荐这种方法,你要是这么搞,读写分离的意义就丧失了。
相关文章:
MySql-高级(分库分表问题简析) 学习笔记
文章目录 1. 为什么要分库分表?2. 用过哪些分库分表中间件?不同的分库分表中间件都有什么优点和缺点?3. 你们具体是如何对数据库如何进行垂直拆分或水平拆分的?4. 分库分表时,数据迁移方案5. 如何设计可以动态扩容缩容…...
【5.20】五、安全测试——安全测试工具
目录 5.4 常见的安全测试工具 1. Web漏洞扫描工具——AppScan 2. 端口扫描工具——Nmap 3. 抓包工具——Fiddler 4. Web渗透测试工具——Metasploit 小提示:Kali Linux 5.4 常见的安全测试工具 安全测试是一个非常复杂的过程,测试所使用到的工具也…...
【13900k】i9 核显升级驱动
这里写自定义目录标题 官方的助手不能用显卡控制中心提示最新的更新搜索显卡 intel uhd graphics 770 手动下载安装自定义音频为啥也要卸载?新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片…...

使用Python将绿色转换为红色、红色转换为蓝色的图像处理
使用Python将绿色转换为红色、红色转换为蓝色的图像处理 在图像处理中,我们经常需要对图像进行颜色转换和修改。本篇博客介绍了如何使用Python的Pillow库来读取一个文件夹中的所有图像,并将其中的绿色转换为红色,红色转换为蓝色。我们还展示…...

Web2与Web3开发的不同之处
Web2是引入交互功能的第二代互联网,也是我们今天所熟悉的。随着Web的不断发展,第三代互联网,也被称为Web3,正处于积极开发中。Web3引入了在区块链上运行的去中心化和无需许可的系统。但是Web2和Web3开发之间有什么区别呢ÿ…...

递增数组的判断【python实现】
有时候需要对某一组数组的数据进行判断是否 递增 的场景,比如我在开发一些体育动作场景下,某些肢体动作是需要持续朝着垂直方向向上变化,那么z轴的值是会累增的。同理,逆向考虑,递减就是它的对立面。 下面是查找总结到…...

在自定义数据上训练 YOLOv8 实例分割
图像分割是一个核心视觉问题,可以为大量用例提供解决方案。从医学成像到分析流量,它具有巨大的潜力。实例分割,即对象检测+分割,甚至更强大,因为它允许我们在单个管道中检测和分割对象。为此,Ultralytics YOLOv8 模型提供了一个简单的管道。在本文中,我们将对自定义数据…...

洛谷密钥被破解:加密安全面临新挑战
密钥管理是加密系统中非常重要的一环,它涉及到密钥的生成、存储、分发、管理和销毁等多个方面。在密码学中,密钥是保护数据隐私和安全性的核心因素之一,因此,确保密钥的安全和保密性显得尤为重要。在2016年举办的 CQOI 数论竞赛中…...
02 Android开机启动之BootLoader及kernel的启动
Android开机启动之BootLoader及kernel的启动 1、booloader的启动流程 第一阶段:硬件初始化,SVC模式,关闭中断,关闭看门狗,初始化栈,进入C代码 第二阶段:cpu/board/中断初始化;初始化内存以及flash,将kernel从flash中拷贝到内存中,执行bootm,启动内核 2、kernel的启…...

代码随想录算法训练营 Day 49 | 121.买卖股票的最佳时机,122.买卖股票的最佳时机 II
121.买卖股票的最佳时机 讲解链接:代码随想录-121.买卖股票的最佳时机 确定 dp 数组以及下标的含义: dp[i][0] 表示第 i 天持有股票所得最多现金dp[i][1] 表示第 i 天不持有股票所得最多现金 确定递推公式: 如果第 i 天持有股票即 dp[i][0]&…...
精炼计算机网络——数据链路层(一)
文章目录 前言3.1 数据链路和帧3.1.1 数据链路和帧3.1.2 三个基本问题 3.2 点对点协议PPP3.2.1 PPP协议的特点3.2.2 PPP协议3.2.3 PPP协议的工作状态 总结 前言 上篇文章,我们一同学完了物理层的全部内容,在本篇文章中,我们初步学习数据链路…...

猿创征文|Spring系列框架之面向切面编程AOP
⭐️前面的话⭐️ 本篇文章将介绍一种特别重要的思想,AOP(Aspect Oriented Programming),即面向切面编程,可以说是OOP(Object Oriented Programming,面向对象编程)的补充和完善。 …...

IoT架构设计
当前有一个支持5000万用户并发访问的网站,每个用户都有一个IOT设备,用户可以查看设备状态,接受设备通知 1.架构设计 针对不同的业务量模型,可以采用不同的架构设计,如下: 低业务量模型 针对低业务量模型…...
EasyRecovery16电脑硬盘数据恢复软件功能讲解
硬盘是很常见的存储数据的设备,硬盘中很多重要的数据一旦丢失会很麻烦,不过现在有硬盘数据恢复软件可以自行在家恢复数据。今天的文章就带大家来看看硬盘恢复数据的软件EasyRecovery。 EasyRecovery 是一款专业的数据恢复软件,支持恢复不同存…...
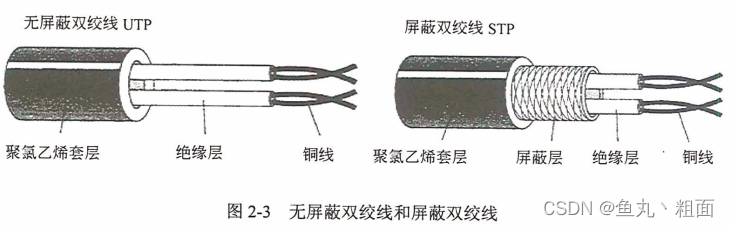
信道通信基础 - 传输介质(双绞线、光纤)
文章目录 1 概述2 传输介质2.1 双绞线2.2 光纤 3 扩展3.1 网工软考真题 1 概述 2 传输介质 2.1 双绞线 双绞线:8 根铜导线每 2 根扭在一起(百兆用 4 根,千兆必须用 8 根)分类 2.2 光纤 光纤:利用光在 玻璃或塑料纤…...

黑马Redis原理篇
黑马Redis原理篇 1、数据结构1.1、动态字符串SDS1.2、IntSet1.3、Dict1.4、ZipList1.5、QuickList1.6、SkipList1.7、RedisObject1.8、五种数据结构1. String(小EMBSTR,大RAW (SDS),少量整数INT)2. List(Redis3.2之后使用QuickList实现&#…...

Sql Server增加字段、修改字段、修改类型、修改默认值
1、修改字段名: alter table 表名 rename column A to B 2、修改字段类型: alter table 表名 alter column 字段名 type not null 3、修改字段默认值 alter table 表名 add default (0) for 字段名 with values 如果字段有默认值,则需要…...
计算机网络第一章(谢希仁第8版学习)
作者:爱塔居 专栏:计算机网络 作者简介:大三学生,希望和大家一起加油 文章目录 目录 文章目录 一、网络、互连网、互联网(因特网)的概念 二、因特网的组成 三、交换方式 3.1 电路交换 3.2 分组交换 3.3 电路…...

Java反射机制
文章目录 Java反射机制一、反射的用处二、获取字节码文件对象的三种方式1.Class.forName形式2.class属性获取形式3.Student对象获取形式 三、获取构造方法四、获取成员变量五、获取成员方法六、反射的好处(面试题)七、反射的实例1.泛型擦除2.修改字符串的…...

New:dbForge Edge 2023 4in1 Enterprise Edition Crack
dbForge Edge 2023 4in1 Enterprise Edition 赋予自己开发和管理 SQL Server、MySQL、Oracle 和 PostgreSQL 数据库的广泛能力 dbForge Edge:您的终极多数据库解决方案 让我们来看看。您需要处理多个数据库管理系统。同时,您希望能够灵活有效地处理范围广…...

Playwright文件上传避坑指南:遇到动态生成的文件选择框怎么办?
Playwright文件上传避坑指南:动态生成文件选择框的实战解决方案最近在为一个电商平台做自动化测试时,遇到了一个棘手的问题——商品图片上传功能总是失败。页面上的"上传图片"按钮明明可以点击,但传统的set_input_files()方法却毫无…...

Actor Framework里的“多米诺骨牌”:一个错误如何让整个嵌套操作者链崩溃?
Actor Framework中的“多米诺效应”:如何避免嵌套操作者链的崩溃 在分布式系统设计中,Actor模型因其天然的并发处理能力而备受青睐。LabVIEW的Actor Framework(AF)通过操作者(actor)的嵌套结构,为复杂系统提供了模块化解决方案。然而&#x…...

机器学习加速分子晶体偏振拉曼光谱模拟:非谐效应与准谐效应的分离
1. 项目概述:当机器学习遇见偏振拉曼光谱 偏振-取向拉曼光谱(PO-Raman)一直是我在材料光谱分析领域里觉得既迷人又头疼的技术。它就像给材料的“分子指纹”加上了方向滤镜,能揭示出振动模式在空间中的对称性和各向异性,…...

第十五章:Agent产品的监控与可观测性:如何构建“看得见、管得住“的AI系统
导读 想象一下:你上线了一个客服Agent,第一个月运行平稳。第二个月开始,你陆续收到用户投诉说"答案不对"。但你的监控系统显示:请求量正常、延迟正常、错误率正常。你打开日志,发现Agent确实"成功"处理了每个请求——只是它给错了答案。 这不是监控…...

模拟调音台数字化改造:基于STM32与MOTU音频接口的智能控制方案
1. 项目概述:为老旧模拟调音台注入数字灵魂在不少社区广播电台、校园电台或是小型制作室里,你依然能看到那些服役了十几年甚至几十年的模拟调音台。它们皮实耐用,推子手感扎实,旋钮的阻尼感让人安心,但面对如今以数字文…...

MySQL全局ID生成实战:从自增主键到自定义Sequence的平滑升级方案与避坑指南
MySQL全局ID生成实战:从自增主键到自定义Sequence的平滑升级方案与避坑指南 当电商平台的日订单量突破百万时,技术团队突然发现系统开始频繁出现"Duplicate entry"错误——那些原本可靠的自增主键,在分库分表的环境下变成了数据一致…...

【独家披露】DeepSeek灰度发布SLI/SLO基线标准:99.95%可用性背后的4层验证漏斗
更多请点击: https://codechina.net 第一章:DeepSeek灰度发布策略全景图 DeepSeek模型服务的灰度发布并非简单的流量切分,而是一套融合可观测性、渐进式验证与多维熔断机制的工程化闭环体系。其核心目标是在保障线上推理稳定性的同时&#x…...

HoRain云--Ollama 安装
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

Resend + Cloudflare 域名邮箱搭建实战:避坑指南与 Foxmail 配置全解析
一、 前言:为什么选择这套方案?在互联网上混,专属域名邮箱(如 adminyourdomain.com)就是你的“赛博身份证”。相比于使用 xxxxqq.com,它能瞬间提升你的职业感与信任度。目前最稳、最快且零成本的配置方案是…...

8051编译器优化:LCALL与LJMP指令替换原理与实践
1. C51编译器优化:LCALL与LJMP指令替换解析 在8051单片机开发中,C51编译器对代码的优化处理常常会让开发者感到困惑。最近我就遇到一个典型案例:在反汇编代码中,原本预期的LCALL指令被替换成了LJMP。这种现象其实反映了编译器在资…...