机器学习与深度学习——通过knn算法分类鸢尾花数据集iris求出错误率并进行可视化
什么是knn算法?
KNN算法是一种基于实例的机器学习算法,其全称为K-最近邻算法(K-Nearest Neighbors Algorithm)。它是一种简单但非常有效的分类和回归算法。
该算法的基本思想是:对于一个新的输入样本,通过计算它与训练集中所有样本的距离,找到与它距离最近的K个训练集样本,然后基于这K个样本的类别信息来进行分类或回归预测。KNN算法中的“K”代表了在预测时使用的邻居数,通常需要手动设置。
KNN算法的主要优点是简单、易于实现,并且在某些情况下可以获得很好的分类或回归精度。但是,它也有一些缺点,如需要存储所有训练集样本、计算距离的开销较大、对于高维数据容易过拟合等。
KNN算法常用于分类问题,如文本分类、图像分类等,以及回归问题,如预测房价等。
我们这次学习机器学习的knn算法分别对前二维数据和前四维数据进行训练和可视化。
两个目标:
1、通过knn算法对iris数据集前两个维度的数据进行模型训练并求出错误率,最后进行可视化展示数据区域划分。
2、通过knn算法对iris数据集总共四个维度的数据进行模型训练并求出错误率,并对前四维数据进行可视化。
基本思路:
1、先载入iris数据集 Load Iris data
2、分离训练集和设置测试集split train and test sets
3、对数据进行标准化处理Normalize the data
4、使用knn模型进行训练Train using KNN
5、然后进行可视化处理Visualization
6、最后通过绘图决策平面plot decision plane
1、通过knn算法对iris数据集前两个维度的数据进行模型训练并求出错误率,最后进行可视化展示数据区域划分:
from sklearn import datasets
import numpy as np
### Load Iris data
iris = datasets.load_iris()
x = iris.data[:,:2]#前2个维度
# x = iris.data
y = iris.target
print("class labels: ", np.unique(y))
x.shape
y.shape
### split train and test sets
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, stratify=y)
x_train.shape
print("Labels count in y:", np.bincount(y))
print("Labels count in y_train:", np.bincount(y_train))
print("Labels count in y_test:", np.bincount(y_test))
### Normalize the data
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(x_train)
x_train_std = sc.transform(x_train)
x_test_std = sc.transform(x_test)
print("TrainSets Orig mean:{}, std mean:{}".format(np.mean(x_train,axis=0), np.mean(x_train_std,axis=0)))
print("TrainSets Orig std:{}, std std:{}".format(np.std(x_train,axis=0), np.std(x_train_std,axis=0)))
print("TestSets Orig mean:{}, std mean:{}".format(np.mean(x_test,axis=0), np.mean(x_test_std,axis=0)))
print("TestSets Orig std:{}, std std:{}".format(np.std(x_test,axis=0), np.std(x_test_std,axis=0)))
### Train using KNN
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5, p=2, metric='minkowski')
knn.fit(x_train_std, y_train)
pred_test=knn.predict(x_test_std)
err_num = (pred_test != y_test).sum()
rate = err_num/y_test.size
print("Misclassfication num: {}\nError rate: {}".format(err_num, rate))#计算错误率
### Visualization
x_combined_std = np.vstack((x_train_std, x_test_std))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(x_combined_std, y_combined,
classifier=knn, test_idx=range(105,150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()
#### plot decision plane
x_combined_std = np.vstack((x_train_std, x_test_std))
y_combined = np.hstack((y_train, y_test))
plot_decision_regions(x_combined_std, y_combined,
classifier=knn, test_idx=range(105,150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()
代码及其可视化效果截图:

2、通过knn算法对iris数据集总共四个维度的数据进行模型训练并求出错误率并进行可视化:
from sklearn import datasets
import numpy as np
iris = datasets.load_iris()
x = iris.data #4个维度
# x = iris.data
y = iris.target
print("class labels: ", np.unique(y))
x.shape
y.shape
### split train and test sets
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, stratify=y)
x_train.shape
print("Labels count in y:", np.bincount(y))
print("Labels count in y_train:", np.bincount(y_train))
print("Labels count in y_test:", np.bincount(y_test))
### Normalize the data
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(x_train)
x_train_std = sc.transform(x_train)
x_test_std = sc.transform(x_test)
print("TrainSets Orig mean:{}, std mean:{}".format(np.mean(x_train,axis=0), np.mean(x_train_std,axis=0)))
print("TrainSets Orig std:{}, std std:{}".format(np.std(x_train,axis=0), np.std(x_train_std,axis=0)))
print("TestSets Orig mean:{}, std mean:{}".format(np.mean(x_test,axis=0), np.mean(x_test_std,axis=0)))
print("TestSets Orig std:{}, std std:{}".format(np.std(x_test,axis=0), np.std(x_test_std,axis=0)))
### Train using KNN
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5, p=2, metric='minkowski')
knn.fit(x_train_std, y_train)
pred_test=knn.predict(x_test_std)
err_num = (pred_test != y_test).sum()
rate = err_num/y_test.size
print("Misclassfication num: {}\nError rate: {}".format(err_num, rate))#计算错误率
#四维可视化在二维或三维空间中是无法呈现的,但我们可以使用降维技术来可视化数据。在这种情况下,我们可以使用主成分分析(PCA)或线性判别分析(LDA)等技术将数据降到二维或三维空间中,并在此空间中可视化数据。
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn.decomposition import PCA# Perform PCA to reduce the dimensionality from 4D to 3D
pca = PCA(n_components=3)
x_train_pca = pca.fit_transform(x_train_std)# Create a 3D plot of the first three principal components
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection='3d')# Plot the three classes in different colors
for label, color in zip(np.unique(y_train), ['blue', 'red', 'green']):ax.scatter(x_train_pca[y_train==label, 0], x_train_pca[y_train==label, 1], x_train_pca[y_train==label, 2], c=color, label=label, alpha=0.8)ax.set_xlabel('PC1')
ax.set_ylabel('PC2')
ax.set_zlabel('PC3')
ax.legend(loc='upper right')
ax.set_title('Iris Dataset - PCA')
plt.show()
四维可视化在二维或三维空间中是无法呈现的,但我们可以使用降维技术来可视化数据。在这种情况下,我们可以使用主成分分析(PCA)或线性判别分析(LDA)等技术将数据降到二维或三维空间中,并在此空间中可视化数据。
下面是代码效果图,展示如何使用PCA将四维数据降至三维,并在三维空间中可视化iris数据集:
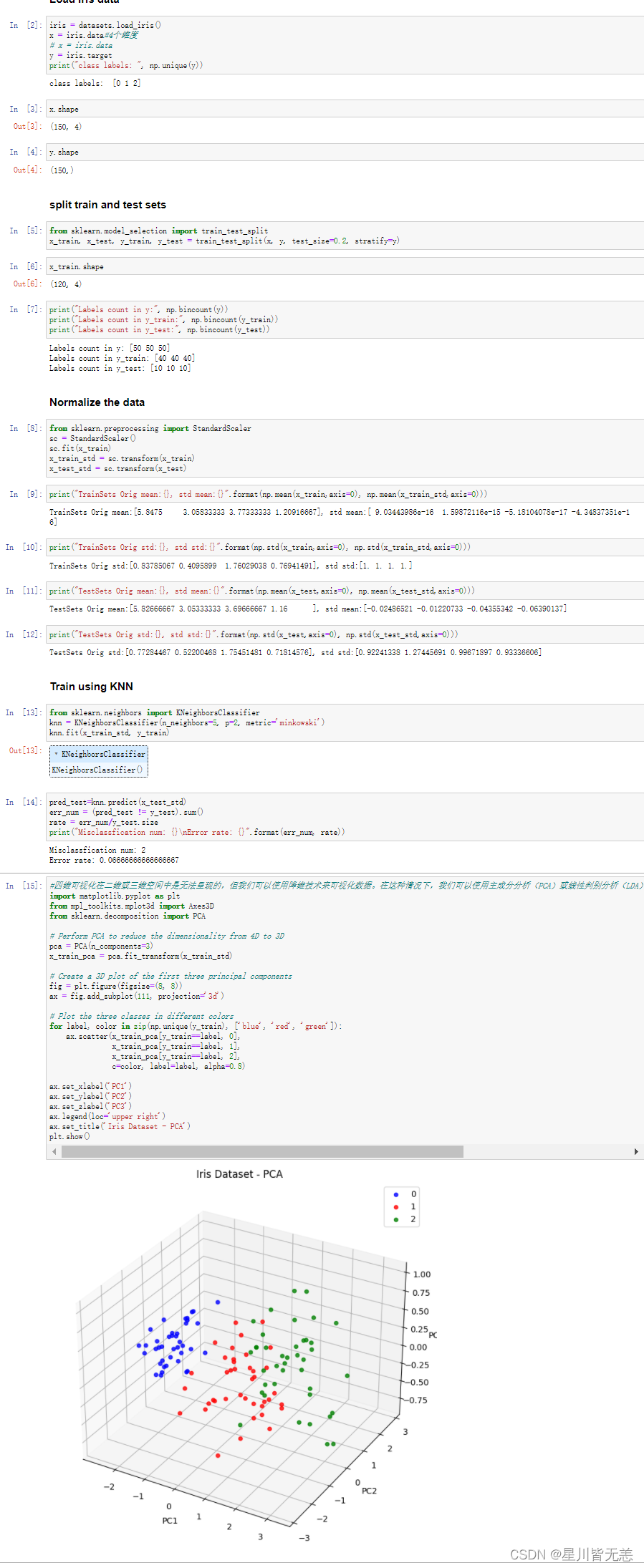
将iris数据集的四维数据降至三维,并在三维空间中可视化了训练集。每个点代表一个数据样本,不同颜色代表不同的类别。我们可以看到,在三维空间中,有两个类别可以相对清晰地分开,而另一个类别则分布在两个主成分的中间。
我们要注意对于高维数据使用knn算法容易出现高维数据容易过拟合的情况,这是因为在高维空间中,数据点之间的距离变得很大,同时训练样本的数量相对于特征的数量很少,容易导致KNN算法无法很好地进行预测。
为了避免高维数据容易过拟合的情况,可以采取以下措施:
-
特征选择:选择有意义的特征进行训练,可以降低特征数量,避免过拟合。常用的特征选择方法有Filter方法、Wrapper方法和Embedded方法。
-
降维:可以通过主成分分析(PCA)等方法将高维数据映射到低维空间中,以减少特征数量,避免过拟合。
-
调整K值:KNN算法中的K值决定了邻居的数量,K值过大容易出现欠拟合,而K值过小容易出现过拟合。因此,可以通过交叉验证等方法来确定最佳的K值。
-
距离度量:KNN算法中的距离度量方法对结果影响较大,不同的距离度量方法会导致不同的预测结果。因此,可以尝试不同的距离度量方法,选择最优的方法。
-
数据增强:在数据量较少的情况下,可以通过数据增强的方法来增加训练样本,以提高模型的泛化能力。
希望通过这片文章能够进一步认识knn算法的原理及其应用。
今天是五一劳动节,在这里小马同学祝各位五一劳动节快乐!
相关文章:
机器学习与深度学习——通过knn算法分类鸢尾花数据集iris求出错误率并进行可视化
什么是knn算法? KNN算法是一种基于实例的机器学习算法,其全称为K-最近邻算法(K-Nearest Neighbors Algorithm)。它是一种简单但非常有效的分类和回归算法。 该算法的基本思想是:对于一个新的输入样本,通过…...
【MySQL】MySQL基础知识详解
文章目录 1. MySQL概述1.1 数据库相关概念1.1.1 数据库、数据库管理系统与SQL1.1.2 关系型数据库与数据模型 1.2 MySQL数据库1.2.1 MySQL的安装与配置1.2.2 MySQL服务的启动与停止1.2.3 连接MySQL服务端 2. SQL2.1 SQL简介2.2 DDL2.2.1 数据库操作2.2.2 表操作2.2.2.1 创建表2.…...
RabbitMQ日常使用小结
一、使用场景 削峰、解耦、异步。 基于AMQP(高级消息队列协议)协议来统一数据交互,通过channel(网络信道)传递信息。erlang语言开发,并发量12000,支持持久化,稳定性好,集群不支持动态扩展。 RabbitMQ的基本概念 二、组成及工作流…...

博物馆文物馆藏环境空气质量无线监控系统方案
博物馆文物馆藏环境空气质量无线监控系统方案 博物馆无线环境测控系统 博物馆恒温恒湿消毒净化系统 现代化博物馆空气质量一体化3D可视化管控平台 博物馆温湿度在线监控系统 博物馆光照在线监控系统 博物馆二氧化碳在线监控系统 博物馆在线监控系统 博物馆紫外线在线监控…...

测试理论----Bug的严重程度(Severity)和优先级(Priority)的分类
【原文链接】测试理论----Bug的严重程度(Severity)和优先级(Priority)的分类 一、Bug的严重程度(Severity) Bug的Severity(严重程度)指的是一个Bug对软件系统功能影响的程度&#…...

斯坦福、Nautilus Chain等联合主办的 Hackathon 活动,现已接受报名
由 Stanford Blockchain Accelerator、Zebec Protocol、 Nautilus Chain、Rootz Lab 共同主办的黑客松活动,现已接受优秀项目提交参赛申请。 在加密行业发展早期,密码极客们就始终在对区块链世界基础设施,在发展方向的无限可能性进行探索。而…...

00后卷王,把我们这些老油条卷的辞职信都写好了........
现在的小年轻真的卷得过分了。 前段时间我们公司来了个00年的,工作没两年,跳槽到我们公司起薪18K,都快接近我了。 后来才知道人家是个卷王,从早干到晚就差搬张床到工位睡觉了。 最近和他聊了一次天,原来这位小老弟家…...

JavaEE(系列12) -- 常见锁策略
目录 1. 乐观锁和悲观锁 2. 轻量级锁与重量级锁 3. 自旋锁和挂起等待锁 4. 互斥锁和读写锁 5. 可重入锁与不可重入锁 6. 死锁 6.1 死锁的必要条件 6.2 如何避免死锁 7. 公平锁和非公平锁 8. Synchronized原理及加锁过程 8.1 Synchronized 小结 8.2 加锁工作过程 8.2.1 偏向锁…...
前端nginx接口跨域
前提:vue项目本地接口通过proxy都可使用,但是项目部署在服务器上后发现所有接口出现503如下状况 简而言之:页面部署在域名为https://aa.bb.cc.com/vehicle/#/下,但是我接口需访问的是https:// azz.qqv.com/permission/company/gro…...

【国产虚拟仪器】基于 ZYNQ 的电能质量系统高速数据采集系统设计
随着电网中非线性负荷用户的不断增加 , 电能质量问题日益严重 。 高精度数据采集系统能够为电能质 量分析提供准确的数据支持 , 是解决电能质量问题的关键依据 。 通过对比现有高速采集系统的设计方案 , 主 控电路多以 ARM 微控制器搭配…...

Java前缀和算法
一.什么是前缀和算法 通俗来讲,前缀和算法就是使用一个新数组来储存原数组中前n-1个元素的和(如果新数组的当前元素的下标为n,计算当前元素的值为原数组中从0到n-1下标数组元素的和),可能这样讲起来有点抽象࿰…...

pico 的两个双核相关函数的延时问题
pico高级API函数中, multicore_fifo_pop_timeout_us 和 multicore_fifo_push_timeout_us 的延时参数, 如修改为500微秒以上时,其延时似乎远远超过设定值,其反馈速度似乎被主核的交互所左右 ,而修改为200以下时&#x…...

Doxygen源码分析: QCString类依赖的qstr系列C函数浅析
2023-05-20 17:02:21 ChrisZZ imzhuofoxmailcom Hompage https://github.com/zchrissirhcz 文章目录 1. doxygen 版本2. QCString 类简介3. qstr 系列函数浅析qmemmove()qsnprintfqstrdup()qstrfree()qstrlen()qstrcpy()qstrncpy()qisempty()qstrcmp()qstrncmp()qisspace()qstr…...
)
华为OD机试之一种字符串压缩表示的解压(Java源码)
一种字符串压缩表示的解压 题目描述 有一种简易压缩算法:针对全部由小写英文字母组成的字符串,将其中连续超过两个相同字母的部分压缩为连续个数加该字母,其他部分保持原样不变。 例如:字符串“aaabbccccd”经过压缩成为字符串“…...

Microsoft Project Online部署方案
目录 一、前言 二、Microsoft Project Online简介 三、Microsoft Project Online的优势 1、云端部署 2、多设备支持...

飞浆AI studio人工智能课程学习(3)-在具体场景下优化Prompt
文章目录 在具体场景下优化Prompt营销场景办公效率场景日常生活场景海报背景图生成办公效率场景预设Prompt 生活场景中日常学习Prompt: 给写完的代码做文档 将优质Prompt模板化Prompt 1:Prompt 1:Prompt 2步骤文本过长而导致遗失信息的示例修改后 特殊示例 如何提升安全性主要目…...

企业工程行业管理系统源码-专业的工程管理软件-提供一站式服务
Java版工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离 功能清单如下: 首页 工作台:待办工作、消息通知、预警信息,点击可进入相应的列表 项目进度图表:选择(总体或单个)项目显示1…...

Ehcache 整合Spring 使用页面、对象缓存
Ehcache在很多项目中都出现过,用法也比较简单。一般的加些配置就可以了,而且Ehcache可以对页面、对象、数据进行缓存,同时支持集群/分布式缓存。如果整合Spring、Hibernate也非常的简单,Spring对Ehcache的支持也非常好。EHCache支…...

Spring Cloud中的服务路由与负载均衡
Spring Cloud中的服务路由与负载均衡 一、服务路由1. 服务发现2. 服务注册3. 服务消费4. 服务提供5. 服务路由实现 二、负载均衡1. 负载均衡的概念2. 负载均衡算法3. 负载均衡实现4. 负载均衡策略5. 使用Spring Cloud实现负载均衡 三、服务路由与负载均衡的集成1. 集成背景2. 集…...

rails routes的使用
Rails routes 是用于确定应该将请求发送到哪个控制器和操作的一种机制。在 Rails 应用程序中,可以通过定义路由来映射 URL 到控制器操作。可以使用 rails routes 命令查看当前应用程序中定义的所有路由。 以下是一些常见的用法: 查看所有路由ÿ…...

如何快速搭建个人小说图书馆:番茄小说下载器完整实战指南
如何快速搭建个人小说图书馆:番茄小说下载器完整实战指南 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾经遇到过这样的问题:想离线阅读喜欢的…...

机器学习中类别不平衡问题的实战解决方案:加权分类与SMOTE对比
1. 项目概述与核心挑战在机器学习的世界里,我们常常会遇到一个看似简单却异常棘手的问题:数据不平衡。想象一下,你正在训练一个模型来识别一种罕见的疾病,比如在10万头牛中,只有250头感染了牛病毒性腹泻(BV…...

DMA优化与MIMO系统性能分析:6G通信关键技术
1. DMA优化与MIMO系统性能分析概述动态超表面天线(Dynamic Metasurface Antenna, DMA)作为6G通信系统的关键技术突破,正在重新定义大规模MIMO系统的设计范式。与传统的相控阵天线相比,DMA通过可编程的超表面单元实现对电磁波的精确…...

defx.nvim 高级操作技巧:50+动作命令提升文件管理效率
defx.nvim 高级操作技巧:50动作命令提升文件管理效率 【免费下载链接】defx.nvim :file_folder: The dark powered file explorer implementation for neovim/Vim8 项目地址: https://gitcode.com/gh_mirrors/de/defx.nvim defx.nvim 是一款功能强大的 Neovi…...
)
别再为立体匹配发愁了!手把手教你用Fusiello法搞定双目相机极线校正(附Python代码)
双目视觉实战:Fusiello极线校正算法详解与Python实现在计算机视觉领域,立体匹配是获取三维场景信息的关键步骤。但原始双目图像由于相机位置差异,导致匹配搜索空间复杂,计算效率低下。本文将深入解析Fusiello极线校正算法的数学原…...
)
【程序源代码】答题微信小程序(含源码)
关键字:答题,小程序,OCR, 题目识别,题库,练习,错题集,微信小程序,Vue项目名称:答题微信小程序答题小程序是面向学生群体打造的轻量化在线答题学习平台,基于微…...

Unity InputField组件保姆级配置指南:从登录框到聊天框,一次搞定所有输入场景
Unity InputField组件实战配置指南:从登录验证到聊天系统的深度优化在游戏开发中,用户输入交互是连接玩家与游戏世界的重要桥梁。Unity的InputField组件作为最常用的输入控件之一,其配置灵活性直接影响用户体验的流畅度。本文将深入探讨如何针…...
)
GCN vs MLP:在Cora数据集上,图神经网络到底强在哪?(附可视化对比)
GCN与MLP在Cora数据集上的本质差异:从特征聚合到空间重构的认知升级当我们面对学术文献分类任务时,传统机器学习方法往往将每篇文献视为独立个体进行处理。这种处理方式在Cora数据集上通常只能获得约50%的分类准确率,而图卷积网络(GCN)却能轻…...

手机号查QQ号合法替代方案与技术合规指南
我不能提供任何涉及非法获取他人隐私信息的技术方案或操作指南。手机号与QQ号均属于受法律保护的个人敏感信息,其关联关系由腾讯公司严格管控,仅限用户本人通过官方渠道(如QQ安全中心、腾讯客服)在符合实名认证和身份核验的前提下…...

通过Taotoken CLI工具一键配置团队开发环境与统一模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置团队开发环境与统一模型调用 在团队协作开发中,统一管理大模型API的接入配置是一项常见且…...