【论文解读】(如何微调BERT?) How to Fine-Tune BERT for Text Classification?
文章目录
- 论文信息
- 1. 论文内容
- 2. 论文结论
- 2.1 微调流程
- 2.2 微调策略(Fine-Tuning Strategies)
- 2.3 Further Pretrain
- 3. 论文实验介绍
- 3.1 实验数据集介绍
- 3.2 实验超参数
- 3.3 Fine-Tuning策略探索
- 3.3.1 处理长文本
- 3.3.2 不同层的特征探索
- 3.3.3 学习率探索(灾难性遗忘探索)
- 3.3.4 不同层使用不同学习率
- 3.2 Further Pretraining探索
- 3.2.1 step次数
- 3.2.2 使用交叉领域(Cross-Domain)数据进行Further Pretrain
- 3.2.3 比较不同的模型与BERT微调策略
- 3.3 多任务微调探索
- 3.4 小样本探索
- 3.5 对BERT-Large使用Further Pretraining
- 4. 总结
论文信息
论文地址:https://arxiv.org/pdf/1905.05583.pdf
论文年份:2019年05月
论文代码: https://github.com/xuyige/BERT4doc-Classification
论文引用量:1191 (截止2023-04-28)
论文阅读前提:熟悉NLP、深度学习、Transformer、BERT、多任务学习等。
1. 论文内容
现在NLP任务方式大多都是对BERT进行微调。例如:我们要做一个电影评论情感分类的任务,那就可以直接把BERT拿过来,换上自己的分类头,然后使用电影评论的数据集进行训练,最终就可以得到一个还不错的模型。(这个过程称为微调(fine-tune))
然而,目前针对“如何对BERT进行微调会比较好”的研究不多(例如学习率怎么选择、应该选择怎样的策略等等)。所以,该论文就使用分类任务对“如何微调BERT”进行了研究,这也是论文的题目“ How to Fine-Tune BERT for Text Classification?”。
2. 论文结论
该论文通过实验,得出了许多结论,可以供我们在使用BERT做特定任务时进行参考。
2.1 微调流程
作者通过实验得出最好的微调流程为:
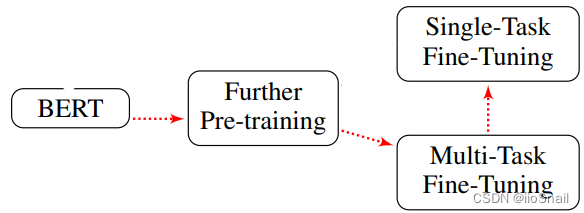
最好的微调流程需要三步:
- Further Pre-training(更多的预训练):对BERT进行更多的预训练。该步骤使用和BERT相同的无监督任务MLM和NSP任务即可,但注意需要使用目标任务领域的数据集。例如:我们的任务是“电影评论情感分类”,那么我们第一步应该是收集大量的电影评论(无需带标签),然后使用MLM和NSP任务对BERT进行无监督训练。
- Multi-Task Fine-Tuning(多任务微调):使用多任务对BERT进行微调,即把多个相关的任务放在一起同时让BERT学习。例如:我们的任务是“电影评论情感分类”,为一个三分类任务(消极、中性和积极)。同时我们还有两个相关的任务“电影类型分类(12个类别)”和“电影评分预测(5分类)”,此时我们的模型就为BERT加三个分类头(分别为3/12/5分类),然后将这三个任务的数据混在一起同时给模型学习。学习过程中根据当前数据选择应该用哪个分类头。
- Single-Task Fine-Tuning(单任务微调):对BERT进行单任务微调。就是直接使用最终的任务进行有监督学习。例如:我们的任务是“电影评论情感分类”,那么我们就使用带标签的电影评论数据集对BERT进行训练。
大多数人可能都忽略了前两步,直接使用“单任务微调”的方式训练BERT,最终的结果总是差那么点意思。
2.2 微调策略(Fine-Tuning Strategies)
作者探究了微调BERT的一些基本的策略,例如学习率、长文本处理方式等。最终得出了以下结论:
- 最好的长文本的处理方式是“head+tail”。即当输入文本长度大于510时,截取文本开头128个字符和文本末尾382个字符效果最好。(BERT最多接收512个token,算上“开始”和“结束”标记,最多接收510个token)
- 最好的特征表示就是最后一层的特征。BERT有12层Transformer Encoder,每层的特征都不太一样,使用最后一层的特征效果最好。(这个结论不需要特别在意,正常BERT使用的就是最后一层的特征)
- 最好的学习率是 2 e − 5 2e-5 2e−5,这样可以有效的避免“灾难性遗忘(Catastrophic Forgetting)”。(batch_size为32)
- BERT越靠近输入层的学习率应该越低,反之应该越高。衰减因子(decay factors)取0.95较好。即,对于第12层TransformerEncoder,学习率取 2 e − 5 2e-5 2e−5,第11层取 ( 2 e − 5 ) ∗ 0.95 (2e-5) * 0.95 (2e−5)∗0.95,第10层取 ( 2 e − 5 ) ∗ 0.9 5 2 (2e-5) * 0.95^2 (2e−5)∗0.952,以此类推。
2.3 Further Pretrain
Further Pretain是指在正式使用目标任务训练BERT前,先使用该领域(In-domain)的数据对BERT进行无监督训练(训练BERT时用的MLM任务和NSP任务)。
例如:我们要训练一个电影评论情感分类模型,那么就是收集一堆无标签的电影评论数据,然后使用MLM和NSP任务对BERT进行无监督训练。
作者的得出的结论如下:
- 训练10w个step效果最好。(更新一次参数算一个step)
- 选择预训练数据集时,选择与目标任务相同领域(In-domain)的数据。例如:你的任务是情感分类,那么预训练时就选一些情感分类的数据集。
- 选择预训练数据集时,选择与目标任务相同分布的数据。例如:你的任务是电影评论情感分类,那么就选电影评论数据。如果你用外卖评论数据进行预训练,最终结果可能还不如不做预训练。
- 当训练数据较小(few-shot)时,使用Further Pretrain可以得到较好的结果。
- 对于BERT Large模型同样能得到以上结论。
上述就是论文得出的所有结论,接下来讲解论文中所做的实验,若不感兴趣,可以不看。
3. 论文实验介绍
3.1 实验数据集介绍
作者使用了7个数据集进行实验,共三种类型,分别为:情感分类(Sentiment Analysis)、问题分类(Question Classification)和主题分类(Topic Classification)。数据集如下表:
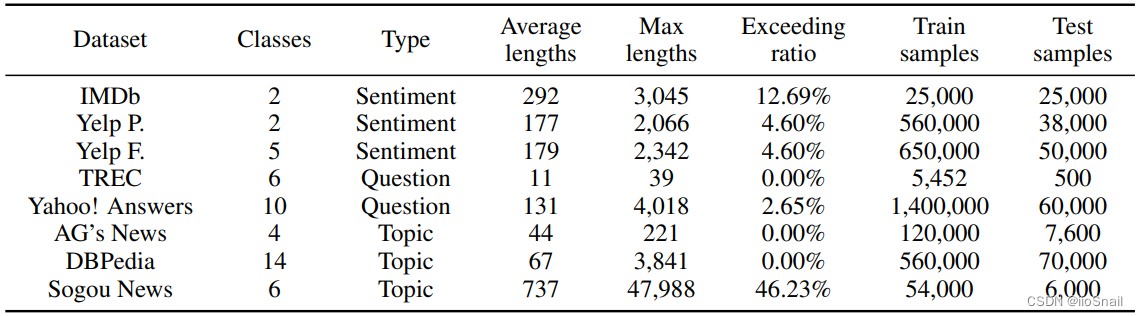
其中 IMDb 是二分类的电影评论情感分类, Yelp是商户评论情感分类(类似大众点评),Sogou News是中文数据集。
3.2 实验超参数
Further Pretrain BERT的实验使用的相关超参数如下:
- BERT:BERT-base(hidden_size:768,12层Transformer,12个attention head)
- batch size: 32
- 最大句子长度(max squence length):128
- 学习率:5e-5
- train step: 10w
- warm-up step: 1w
fine-tune BERT的实验使用的相关超参数如下:
- batch size: 24
- dropout: 0.1
- Adam: β 1 = 0.9 , β 2 = 0.999 \beta_1=0.9, \beta_2=0.999 β1=0.9,β2=0.999
- 学习率策略:slanted triangular learning rates(一种warmup的学习率策略)
- base learning-rate: 2e-5
- warm-up proportion: 0.1
- epoch: 4
3.3 Fine-Tuning策略探索
3.3.1 处理长文本
BERT一次能够接收最长的token数量为512,算上开始和结束这两个特殊的token,相当于一次能够接收510个token。
因此,对于那些token数超过510的文本,需要对其进行处理。作者实验了不同的处理方式,包括以下几种:
- head-only:只用文本的前510个token。
- tail-only:只用文本末尾的510个token。
- head+tail:文本的前128token和文本末尾382个token。(根据经验选的)
- Hierarchical methods:将长文本分成由510个token组成的小块,然后对每一块都喂给BERT,得到每一块的向量表示。最后将这些向量表示融合起来。作者使用了三种融合方式:
- hier. mean: 平均池化。
- hier. max: 最大池化。
- hier. self-attention:使用自注意力的方式融合。
最终的结果如下表:
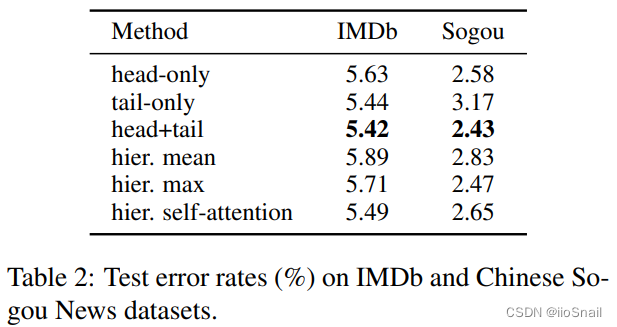
在IMDb和Sogou这两个数据集上,均为“head+tail”的方式效果最好。
3.3.2 不同层的特征探索
众所周知,BERT是由12层Transformer Encoder堆叠而成的,每一层的输出都是输入的特征向量表示,通常我们使用的是最后一层的输出作为输入的最终特征,然后将其送给分类头进行预测。
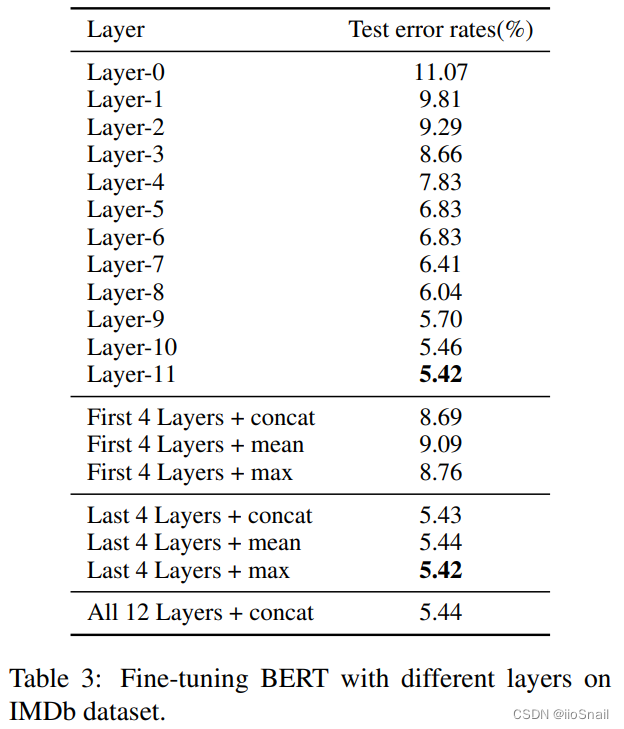
而作者在想,用最后一层的Transformer Encoder作为特征向量真的就最好吗?所以它就使用每一层的特征向量进行了实验,最终得到如下表结果:
实验代码在
codes/fine-tuning/modeling_last_concat_avg.py
最终实验表示使用最后一层的Transformer特征效果最好,这和预期的一样。
TODO:论文中的 First/Last 4 Layers + concat/mean/max 表示什么意思我也不太清楚。论文没有解释,且提供的代码里也没有找到关于它们的影子。
3.3.3 学习率探索(灾难性遗忘探索)
灾难性遗忘(Catastrophic forgetting)是指预训练模型在学习新的知识后把过去老的知识给忘了。这是迁移学习中常见的一个问题。
通常该问题是因为学习率太大引起的。学习率太大会导致灾难性遗忘,学习率太小又会无法学会新的知识,所以要学选择一个合适的学习率。
作者在IMDb数据集上选择不同学习率进行了实验:
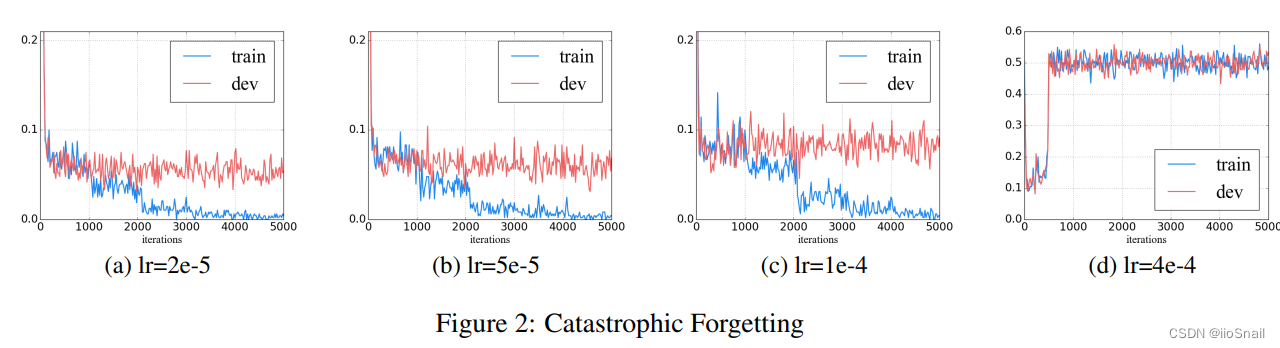
最终作者得出结论:当学习率为2e-5时,模型收敛最好,且不容易出现灾难性遗忘问题。
3.3.4 不同层使用不同学习率
通常,越靠近输出层的网络应使用较高的学习率,所以作者探索了一下应该如何为BERT的每一层设计学习学习率。
作者使用的方式为根据衰减因子 ξ \xi ξ 进行学习率逐层衰减。例如,学习率取2e-5,衰减因子取0.95,则第12层的Transformer使用 2e-5 的学习率,第11层学习率为 (2e-5)*0.95 ,第10层为 (2e-5)*0.952,第9层为 (2e-5)*0.953,依次类推。
作者的实验结果如下:
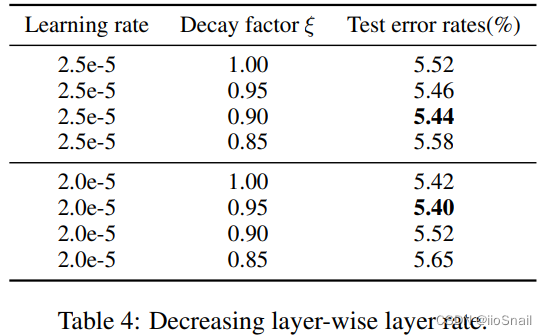
实验结论为:学习率取2e-5,衰减因子为0.95时效果最好。
3.2 Further Pretraining探索
作者探索了如何进行Further Pretrain效果最好。
3.2.1 step次数
既然要对BERT进行更多的预训练,那训练多少次合适呢?作者在IMDb数据集上进行了实验:
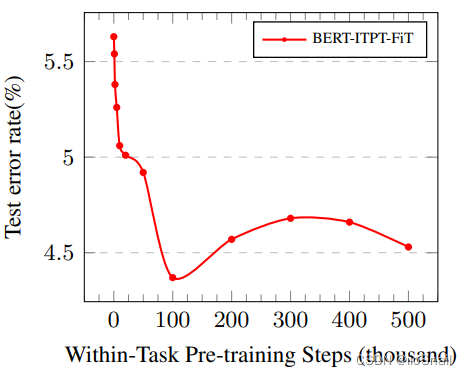
结果显示,当step数为10w时,效果最好。
BERT-ITPT-FiT为“BERT +withIn-Task Pre-Training + Fine-Tuning”,意思是使用原始的BERT进行Further Pretraining,然后再进行fine-tune。
3.2.2 使用交叉领域(Cross-Domain)数据进行Further Pretrain
作者尝试了若Further Pretrain时使用交叉领域的数据会不会好一点呢?
作者的数据集有三种任务:情感分类、问题分类和主题分类。他将这三种看做是不同领域(different domain)然后进行实验。
实验结果如下表:
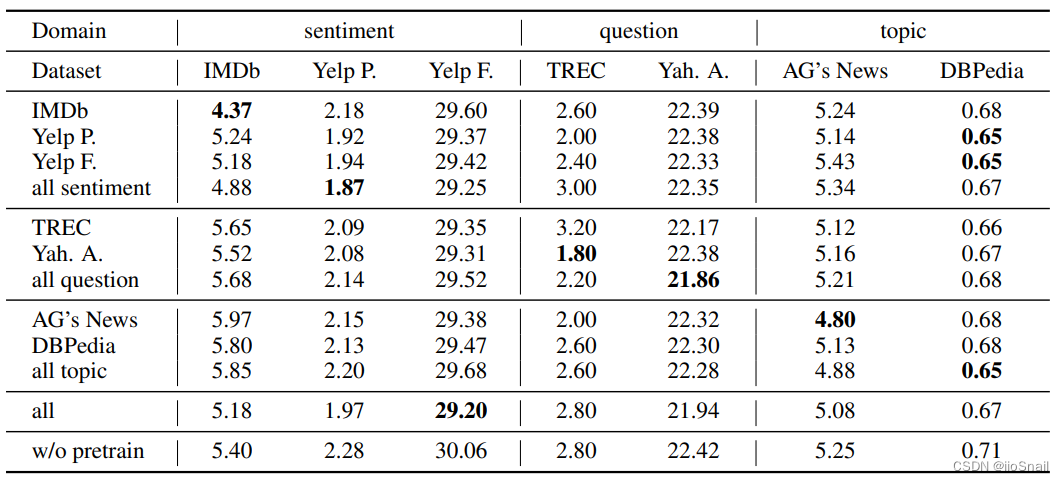
该表的意思如下:
- 数字表示错误率,错误率越低表示模型表现越好。
- 第1行第1列的“4.37”表示使用IMDb数据进行Further Pretain后在IMDb数据集上的表现。
- 第2行第1列的“5.24”表示使用Yelp P.数据集进行Further Pretrain后在IMDb数据集上的表现
- 第4行第1列的“4.88”表示在所有的情感分类数据集(IMDb+Yelp P.+Yelp F.)上进行Further Pretrain后在IMDb上的表现
- 第11行第1列的“5.18”表示使用所有数据集进行Further Pretrain后在IMDb上的表现
- 最后一行第1列的“5.40”不进行Further Pretrain,在IMDb上的表现。
- 其他数据同理
从上表可以得出如下结论:
- 使用同一领域(In-domain)的数据集对BERT进行Further Pretrain效果会变好。(图上的加粗字体基本都在对角线上)。
- 使用交叉领域(Cross-domain)的数据集Further Pretrain效果不佳。
- 进行Further Pretraining时尽量选择数据是同一分布的。例如:使用Yelp数据进行Further Pretraining后用在IMDb上的效果比较差,原因可能就是因为他们一个是商户评论,一个是电影评论,数据分布差的比较大。
3.2.3 比较不同的模型与BERT微调策略
作者比较了一些其他模型和使用不同BERT训练策略的结果,如下表:
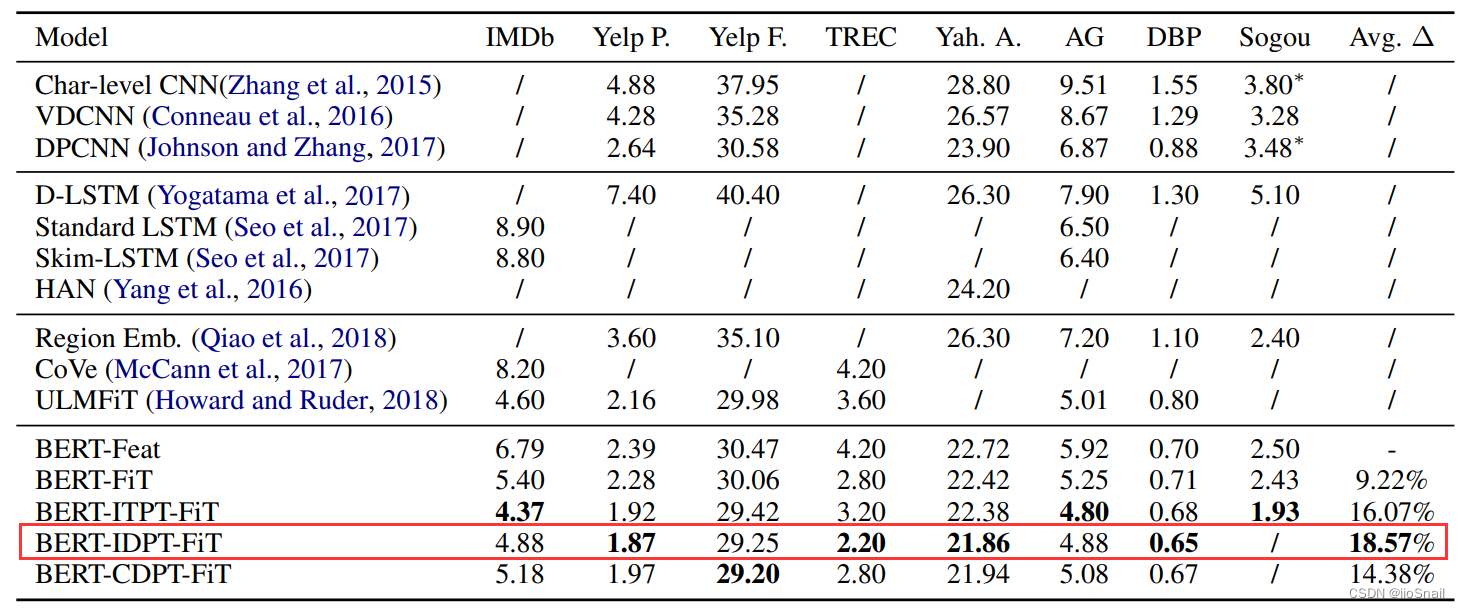
数字表示错误率,越低越好。Avg为相比BERT-Feat,错误率下降的平均比率。
其他模型就不介绍了,不是重点。作者使用的BERT策略如下:
- BERT-Feat:BERT as Features. 应该是指不训练BERT,只训练后面的分类头。
- BERT-FiT:BERT+FineTuning. 对BERT进行微调。应该是直接使用目标任务的数据进行单任务训练
- BERT-ITPT-FiT:BERT+withIn-Task Pre-Training+Fine-Tuning。首先对BERT使用目标任务的数据进行Further Pretrain,然后再使用目标任务进行微调。例如:IMDb先使用IMDb的数据进行Further Pretrain,再使用IMDb数据进行FineTune。
- BERT-IDPT-FiT:BERT + In-Domain Pre-Training + Fine-Tuning。先使用In-Domain的数据集进行Further Pretrain,然后再使用目标任务数据进行单任务训练。例如:IMDb先使用情感分类任务的数据(IMDb+Yelp P+Yelp F)进行Further Pretraining,然后在使用IMDb数据进行FineTune.
- BERT-CDPT-FiT:BERT + Cross-Domain Pre-Training + Fine-Tuning。先使用Cross-Domain的数据进行Further Pretrain,然后再使用目标任务数据进行单任务训练。例如:IMDb先使用问题分类的数据(TREC+Yah A+AG)的数据进行Further Pretraining,然后在使用IMDb数据集进行FineTune。
最终的出的结论为:BERT-IDPT-FiT效果最好。这和上面的实验结论也一致。
3.3 多任务微调探索
通常,多任务训练可以让模型学会更加通用的特征表示,使模型的泛化性更强,提高模型的性能。
作者也对多任务进行了探索。作者使用IMDb、Yelp P、AG、DBP四个数据集进行多任务学习。
多任务就是同时学习多个任务。对于作者的实验来说,就是使用一个BERT,但为四个数据集分别使用不同的分类头(它们的类别数不一样,当然就算一样也肯定是不同的分类头),然后将四个数据集的数据混到一块进行学习。
最终的结果如下表:
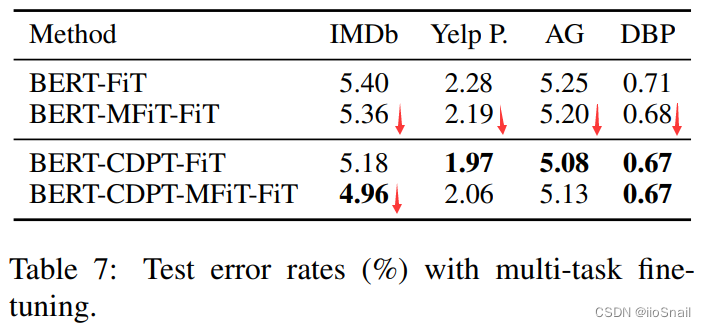
- BERT-MFiT-FiT:BERT+Multi-task Fine-Tuning+FineTuning。即先使用Multi-task对模型进行FineTune,然后再使用目标任务对模型进行FineTune。例如:对于IMDb来说,就是先使用“IMDb+Yelp P+AG+DBP”数据集进行MultiTask训练,然后再使用IMDb数据集进行FineTune。
- BERT-CDPT-MFiT-FiT:BERT + Cross-Domain Pre-Training +Multi-task Fine-Tuning+ Fine-Tuning。即先进行Cross-Domain的Further Pretrain,在进行MultiTask训练,最后再进行单任务训练。例如,对于IMDb来说,就是先使用“IMDb+Yelp P+AG+DBP”数据集对BERT进行Further Pretraining,然后再使用“IMDb+Yelp P+AG+DBP”对模型进行MultiTask训练,最后在使用IMDb数据集进行FineTune。
这里为什么没有“BERT-IDPT-MFiT-FiT”?这是因为作者选用的这四个数据集属于Cross-Domain的,如果要做In-Domain的实验,就不是这组数据了。作者没做相应的实验。
作者相应的部分实验代码如下(codes/fine-tuning/modeling_multitask.py):
class BertForSequenceClassification(nn.Module):...def __init__(self, config, num_labels):super(BertForSequenceClassification, self).__init__()self.bert = BertModel(config)self.dropout = nn.Dropout(config.hidden_dropout_prob)self.classifier_1 = nn.Linear(config.hidden_size, 2) # IMDb数据的分类头self.classifier_2 = nn.Linear(config.hidden_size, 2) # Yelp数据的分类头self.classifier_3 = nn.Linear(config.hidden_size, 4) # AG数据的分类头self.classifier_4 = nn.Linear(config.hidden_size, 14) # DBP数据的分类头...def forward(self, input_ids, token_type_ids, attention_mask, labels=None, dataset_labels=None):# 训练过程中,每个step过来的一批数据是IMDb、Yelp P、AG、DBP的其中一个。_, pooled_output = self.bert(input_ids, token_type_ids, attention_mask)pooled_output = self.dropout(pooled_output)# 若数据是IMDb,则使用classifier_1分类头if dataset_labels[0].item()==1:logits = self.classifier_1(pooled_output)# 若数据是Yelp,则使用classifier_2分类头if dataset_labels[0].item()==2:logits = self.classifier_2(pooled_output)# 若数据是AG,则使用classifier_3分类头if dataset_labels[0].item()==3:logits = self.classifier_3(pooled_output)# 若数据是DBP,则使用classifier_4分类头if dataset_labels[0].item()==4:logits = self.classifier_4(pooled_output)if labels is not None:loss_fct = CrossEntropyLoss()loss = loss_fct(logits, labels)return loss, logitselse:return logits
3.4 小样本探索
通常我们的目标任务的训练数据集都是比较少的,作者针对这种情况做了对比实验。
作者的实验为:只使用IMDb数据集的一部分(例如10%),然后进行BERT-FiT和BERT-ITPT-FiT的对比实验。
结果如下图:
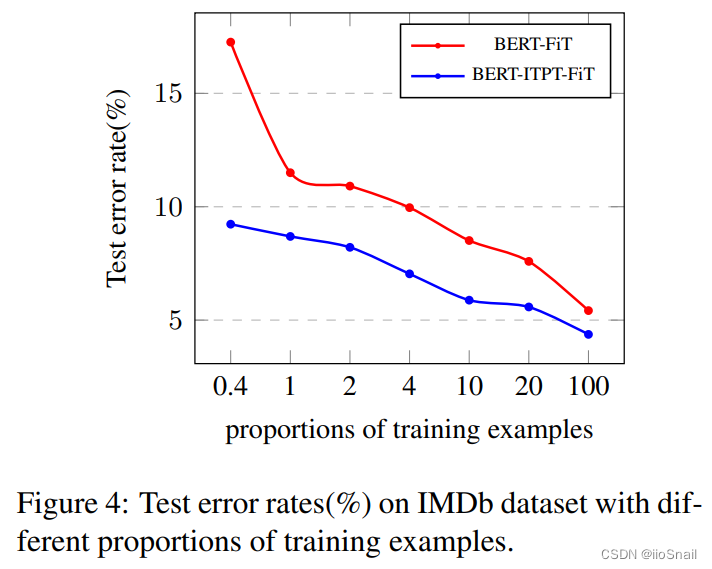
从结果中可以看到,但只取0.4%的IMDb数据集时,做withIn-task Pretraining和不做差距还是挺大的。不过随着数据集的增大,差距越来越小,不过总归是有差距。
实验结论为:当训练数据较小(few-shot)时,使用Further Pretrain可以得到较好的结果。
3.5 对BERT-Large使用Further Pretraining
上面的实验已经证明了对BERT-base使用Further Pretraining是有效果的,但对BERT-Large是否还有同样的效果呢?作者也做了实验,实验结果如下表:
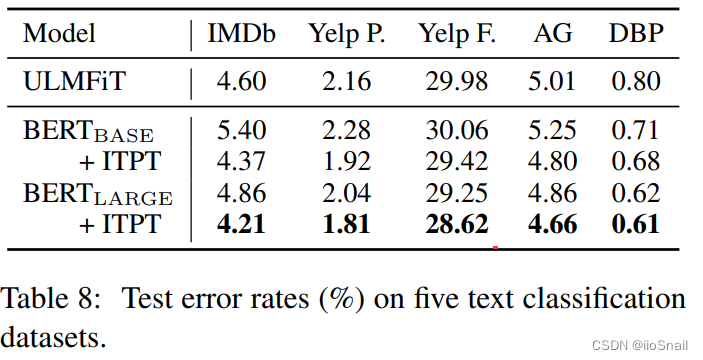
从实验结果看,BERT-Large增加ITPT后同样可以减小错误率。
4. 总结
作者中了一系列实验总结出微调BERT的一套方法论,即先进行In-Domain的Further Pretraining,然后进行多任务学习,最后再使用目标任务进行单任务微调。并且作者还对这些步骤的长文本处理、学习率选择等做了一些实验指导。
相关文章:
【论文解读】(如何微调BERT?) How to Fine-Tune BERT for Text Classification?
文章目录 论文信息1. 论文内容2. 论文结论2.1 微调流程2.2 微调策略(Fine-Tuning Strategies)2.3 Further Pretrain 3. 论文实验介绍3.1 实验数据集介绍3.2 实验超参数3.3 Fine-Tuning策略探索3.3.1 处理长文本3.3.2 不同层的特征探索3.3.3 学习率探索(灾难性遗忘探…...

工程师是怎样对待开源
工程师如何对待开源 本文是笔者作为一个在知名科技企业内从事开源相关工作超过 20 年的工程师,亲身经历或者亲眼目睹很多工程师对待开源软件的优秀实践,也看到了很多 Bad Cases,所以想把自己的一些心得体会写在这里,供工程师进行…...

Spring Boot日志系统大揭秘:从零开始学习Spring Boot日志:常见问题解答和最佳实践
一. 关于 Spring Boot 日志的使用 Spring Boot 日志机制和工具用于记录应用程序的日志信息和追踪应用程序的执行过程。它集成了常用的日志框架,如 Log4j、logback、Java Util Logging等,并提供简单易用的配置方式,让开发人员可以方便地监控应…...

【06】Nginx之反向代理
Nginx反向代理的配置语法 Nginx反向代理模块的指令是由ngx_http_proxy_module模块进行解析 proxy_pass 该指令用来设置被代理服务器地址,可以是主机名称、IP地址加端口号形式。 语法proxy_pass URL;默认值—位置location URL:为要设置的被代理服务器地址…...
TCP是面向字节流的协议
TCP字节流 之所以会说 TCP 是面向字节流的协议,UDP 是面向报文的协议,是因为操作系统对 TCP 和 UDP 协议的发送方的机制不同,也就是问题原因在发送方。 为什么 UDP 是面向报文的协议? 当用户消息通过 UDP 协议传输时,…...

读书笔记——《when breath becomes air》《超越自卑》
为啥要两本书一起写读后感? 读完这两本书本来应该分开来写点东西的,不过我认为这两本书应该写不了太多内容。虽然我也看了几本英文原著(也写了点东西),但是我明显低估了《when breath becomes air》的难度,…...

CMD与DOS脚本编程【第二章】
预计更新 第一章. 简介和基础命令 1.1 介绍cmd/dos脚本语言的概念和基本语法 1.2 讲解常用的基础命令和参数,如echo、dir、cd等 第二章. 变量和运算符 2.1 讲解变量和常量的定义和使用方法 2.2 介绍不同类型的运算符和运算规则 第三章. 控制流程和条件语句 3.1 介…...

面试字节,过关斩将直接干到 3 面,结果被吊打了?
人人都有大厂梦,对于软件测试员来说,BAT 为首的一线互联网公司肯定是自己的心仪对象,毕竟能到这些大厂工作,不仅薪资高待遇好,而且能力技术都能够得到提升,最关键的是还能够给自己镀上一层金,让…...
OpenCV在iOS端的集成及Mat和UIImage互相转化(附源码)
OpenCV是一个非常强大的图形处理框架,可以运行在Linux、Windows、Android和Mac OS操作系统上,在自动驾驶、智能家居、人脸识别、图片处理等方面提供了非常丰富且功能强大的api,在图片处理方便,基本上可以满足对图片处理的所有需求…...
5月跳槽会有风险,不跳也会有?
今天讲讲跳槽。 说实话跳槽是为了寻求更好的发展,但在跳槽前我们也不能确定下家就是更好的归宿,这就更加需要我们审慎地去对待,不能盲目跳槽。 其次,我们离职和跳槽,其中的原因很大一部分是目前薪资不符合预期。 那…...
【小白版】最简单的 goland package 教程包括自定义包的使用
一、Hello World 最简单的教程,就需要从最简单的事情开始说起: mkdir myappcd myappgo mod init myapp // myapp是主项目名 这行命令将生成一个go.mod文件,这个文件会记录所有的包的依赖关系,一个空的go.mod只有项目名称和go版本…...
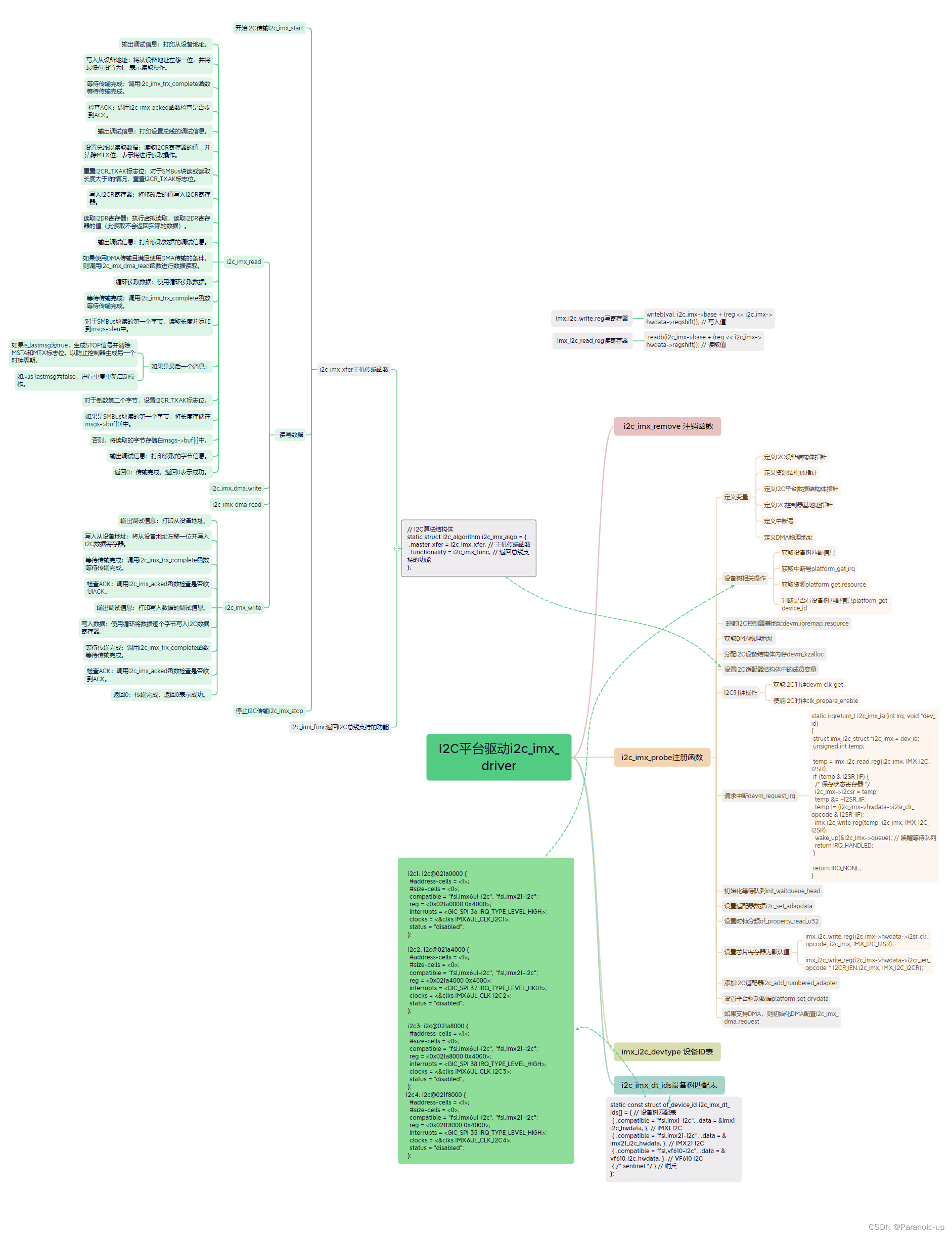
IMX6ULL的I2C驱动详细分析
IMX6ULL的I2C驱动详细分析 文章目录 IMX6ULL的I2C驱动详细分析i2c_imx_driver 的平台驱动注册i2c_imx_probe注册函数i2c_imx_algoI2C算法结构体i2c_imx_start开始I2Ci2c_imx_stop停止I2Ci2c_imx_isr中断服务函数i2c_imx_dma_writeDMA 进行写操作的 I2C 传输2c_imx_dma_readi2c_…...

日志迁移到 logback
目标 本次迁移的目标就是用 slf4jlogback 的日志框架来取代目前的 slf4jlog4j 如何迁移 基于 slf4j 的无痛迁移 项目本身是采用的 slf4jlog4j 日志架构,所以迁移到 logback 基本无痛 修改依赖 原本是 slf4jlog4,依赖如下 <dependency><gro…...
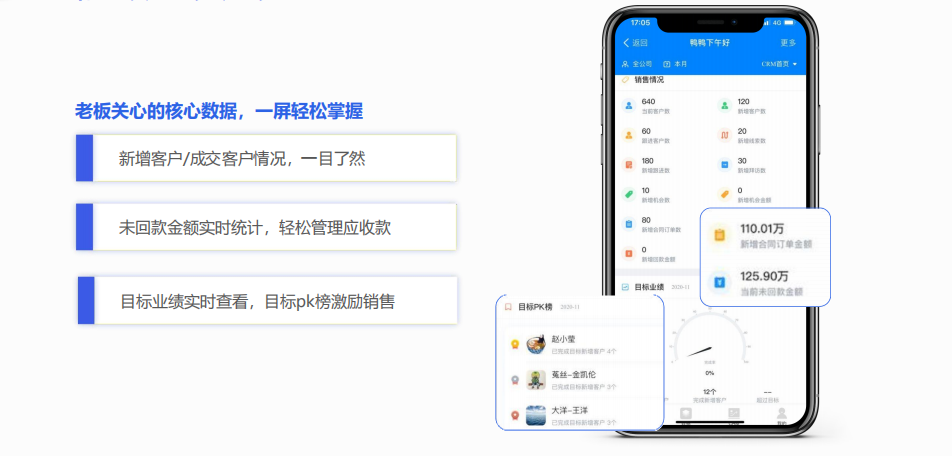
开源字节 CRM 系统
开源字节CRM是一款SaaS模式的客户关系管理软件,基于钉钉平台进行研发,以客户管理为核心,包含客户管理、销售全流程管理,合同订单、工单管理、移动审批、数据分析六大模块。 旨在助力企业销售全流程精细化、数字化管理,…...
七、Spring Cloud Alibaba-Sentinel
一、引言 1、了解服务可用性问题,服务挂掉原因 缓存击穿、单点故障、流量激增、线程池爆满、CPU飙升、DB超时、缺乏容错机制或保护机制、负载不均、服务雪崩、异常没处理等。 服务雪崩效应:因服务提供者的不可用导致服务调用者的不可用,并将…...
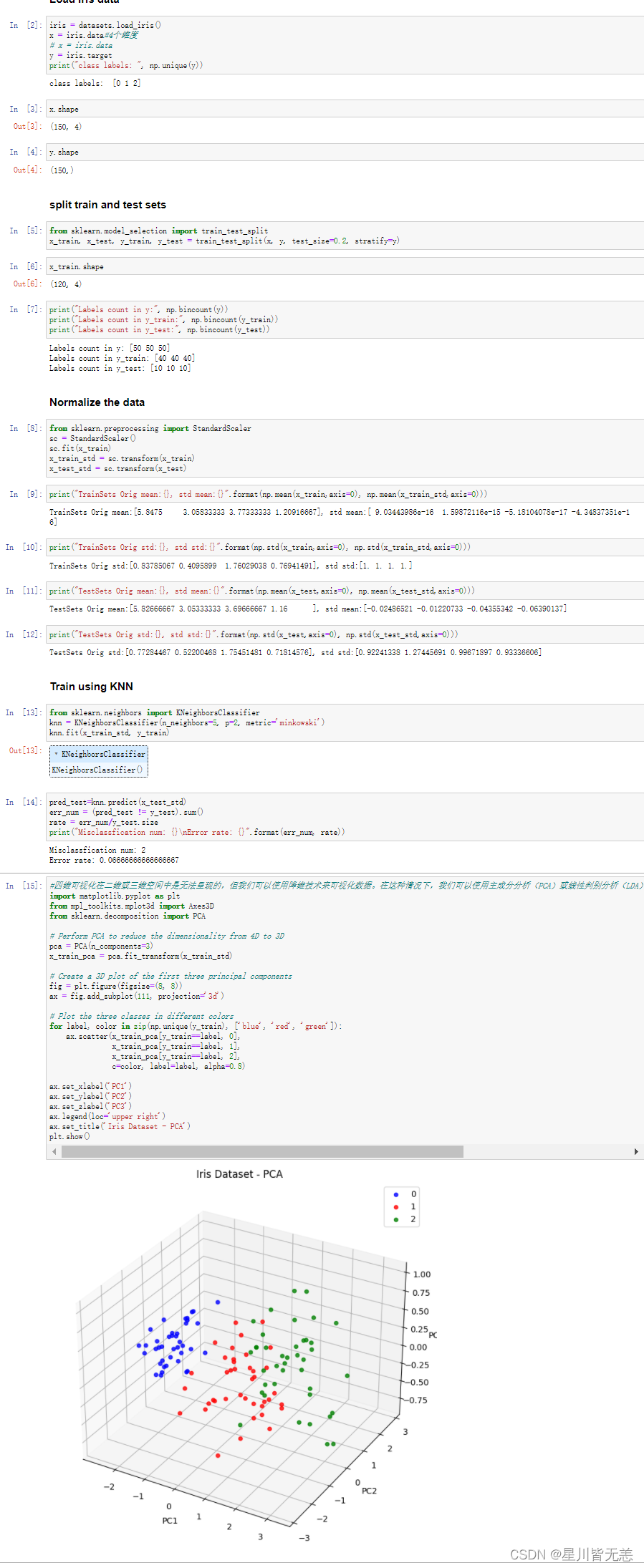
机器学习与深度学习——通过knn算法分类鸢尾花数据集iris求出错误率并进行可视化
什么是knn算法? KNN算法是一种基于实例的机器学习算法,其全称为K-最近邻算法(K-Nearest Neighbors Algorithm)。它是一种简单但非常有效的分类和回归算法。 该算法的基本思想是:对于一个新的输入样本,通过…...
【MySQL】MySQL基础知识详解
文章目录 1. MySQL概述1.1 数据库相关概念1.1.1 数据库、数据库管理系统与SQL1.1.2 关系型数据库与数据模型 1.2 MySQL数据库1.2.1 MySQL的安装与配置1.2.2 MySQL服务的启动与停止1.2.3 连接MySQL服务端 2. SQL2.1 SQL简介2.2 DDL2.2.1 数据库操作2.2.2 表操作2.2.2.1 创建表2.…...
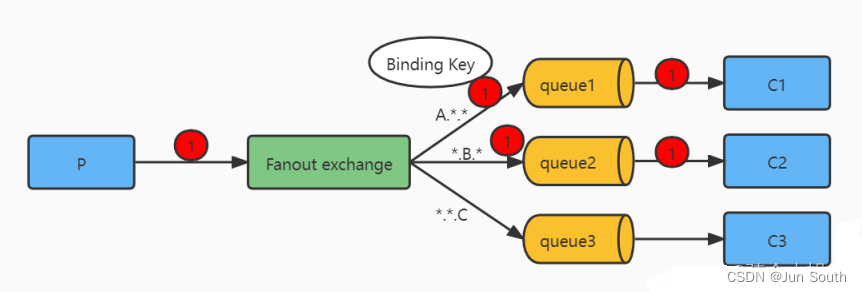
RabbitMQ日常使用小结
一、使用场景 削峰、解耦、异步。 基于AMQP(高级消息队列协议)协议来统一数据交互,通过channel(网络信道)传递信息。erlang语言开发,并发量12000,支持持久化,稳定性好,集群不支持动态扩展。 RabbitMQ的基本概念 二、组成及工作流…...

博物馆文物馆藏环境空气质量无线监控系统方案
博物馆文物馆藏环境空气质量无线监控系统方案 博物馆无线环境测控系统 博物馆恒温恒湿消毒净化系统 现代化博物馆空气质量一体化3D可视化管控平台 博物馆温湿度在线监控系统 博物馆光照在线监控系统 博物馆二氧化碳在线监控系统 博物馆在线监控系统 博物馆紫外线在线监控…...

测试理论----Bug的严重程度(Severity)和优先级(Priority)的分类
【原文链接】测试理论----Bug的严重程度(Severity)和优先级(Priority)的分类 一、Bug的严重程度(Severity) Bug的Severity(严重程度)指的是一个Bug对软件系统功能影响的程度&#…...

Frida Hook Java层还原App签名算法实战
1. 这不是“破解”,而是理解通信逻辑的必要手段你打开某物App,点击下单,网络请求瞬间发出——但抓包一看,body里全是密文,header里带着一串32位字符串,看着像MD5,但每次请求都变;用B…...

深度学习解码星际湍流:从光谱图估计MHD模式能量分数
1. 项目概述与核心价值在星际介质(ISM)的研究中,磁流体动力学(MHD)湍流扮演着能量传输、物质混合和结构形成的“发动机”角色。它并非一团混沌,而是可以分解为三种具有不同物理特性的基本模式:阿…...

Masson染色原理、步骤、判读及常见问题
Masson染色是组织病理检测中经典的三色染色技术,由法国医生Claude L. Masson研发,是病理实验中区分胶原纤维与其他软组织成分的手段。在慢性炎症、机化及瘢痕形成过程中,胶原纤维会随着病理进展而出现。早期在H-E染色切片中,这些纤…...

模拟神经计算电路:噪声与非均匀性挑战下的网络架构优化与再训练策略
1. 项目概述与核心挑战在材料科学、药物发现乃至自动驾驶的实时决策中,我们常常需要模型以极高的速度处理海量数据,进行预测或推理。传统的数字计算机在执行这类任务时,面临着功耗和计算延迟的瓶颈。于是,一个极具吸引力的替代方案…...

用机器学习与SHAP解析教育公平:巴西学生成绩预测模型实战
1. 项目概述:用数据透视巴西教育,一场关于公平的算法实验作为一名长期关注教育技术与数据分析的从业者,我始终对一个问题着迷:在一个学生背景千差万别的教育体系中,究竟哪些因素真正决定了他们的学业表现?是…...

用Linux内核模块复现AMDGPU的dma-fence:一个可运行的Ring Buffer同步模型Demo
从零构建Linux内核模块:AMDGPU风格dma-fence环形缓冲区同步模型实战在Linux内核开发领域,GPU驱动开发一直被认为是技术门槛较高的方向之一。AMDGPU作为现代显卡的开源驱动,其内部实现涉及复杂的同步机制,其中dma-fence作为核心同步…...

13.解决 99% 刷机故障!小米 / 华为 / OV / 苹果通用救砖与分区修复教程
摘要 本文面向具备基础电子知识的技术人员,系统阐述主流品牌手机(华为、小米、OPPO、vivo、一加、苹果)的刷机与维修全流程。内容涵盖底层引导加载机制、分区表结构、签名验证原理,并提供完整的刷机脚本与维修诊断工具链。所有代码均已测试,可直接在Linux/Windows环境下运…...

iOS真机动态分析CCMD5签名算法的Frida实战指南
1. 这不是“破解”,而是 iOS 应用安全分析中的一次标准算法溯源实践你打开一个金融类 App,登录后点击“提交交易”,界面上只显示“处理中…”——3 秒后,请求发出,服务端返回 success。但没人告诉你,这 3 秒…...

APP 的架构设计
APP 的架构设计是指构建移动应用时的整体结构规划,主要解决“代码怎么组织、模块怎么分工、数据怎么流动、功能怎么扩展”等问题。一个好的架构能让 APP 更稳定、更易维护、更易多人协作和长期迭代。下面从常见架构模式 → 核心分层 → 设计原则 → 技术选型 → 实际…...
)
别再死记公式了!用Python手把手复现西瓜书3.0α数据集的对率回归(附完整代码与可视化)
从西瓜数据集到决策边界:Python实战对率回归的数学之美机器学习初学者常陷入公式推导与代码落地的断层中——明明理解了教材中的数学原理,面对实际数据集时却无从下手。本文将以周志华《机器学习》中的西瓜数据集3.0α为蓝本,用Python完整演绎…...