C语言基础知识:位与位字段
目录
位与字节
位
比特
字节
对齐特性
位字段
位与字节
位
二进制数系统中,每个0或1就是一个位(bit),位是数据存储的最小单位。其中8 bit就称为一个字节(Byte)。计算机中的CPU位数指的是CPU一次能处理的最大位数,例如32位计算机的CPU一次最多能处理32位数据,计算机中的CPU位数也成为机器字长,和数据总线(CPU与内部存储器之间连接的用于传输数据的线的根数)的概念是统一的。
比特
1) 计算机专业术语,是信息量单位,是由英文BIT音译而来。二进制数的一位所包含的信息就是一比特,如二进制数0101就是4比特。
2)二进制数字中的位,信息量的度量单位,为信息量的最小单位。数字化音响中用电脉冲表达音频信号,“1”代表有脉冲,“0”代表脉冲间隔。如果波形上每个点的信息用四位一组的代码表示,则称4比特,比特数越高,表达模拟信号就越精确,对音频信号信号还原能力越强。
字节
1字节(byte) = 8 比特(bit)
注:这个字节与比特的关系是规定的,记住就好,通用于任何场景,容易混淆的是字长和字节,字长指的是cpu一次性能够运算的数据的位数,不同的计算机可能不一样,但是字节这个概念是恒久不变的。
对齐特性
对齐指的是如何安排对象在内存中的位置。
_Alignof运算符给出了一个类型的对齐要求,在关键字_Aligof后面的圆括号中写上类型名即可:
size_t d_align = _Alignof(float);
假定d_align的值是4,意思float类型对象的对齐要求是4。较大的对齐值被称为stricter或stronger,较小的值被称为weaker.
可以使用_Alignas说明符指定一个变量或类型的对齐值,但是不应该要求该值小于基本对齐值。
_Alignas(double) char c1;
_Alignas(8) char c2;
unsigned char _Alignas(long double) c_arr[sizeof(long double)];
注意:
位字段
位字段(bit filed)是C语言中一种存储结构,不同于一般结构体的是它在定义成员的时候需要指定成员所占的位数。位字段是一个signed int或unsigned int类型变量中一组相邻的位(C99和C11新增了Bool类型的位字段)。位字段通过一个结构声明来建立,该结构声明为每个字段提供标签,并确定该字段的宽度。例如,下面的声明建立了4个1位的字段:
struct {unsigned autfd : 1;unsigned bldfc : 1;unsigned undln : 1;unsigned itals : 1;
} prnt;根据该声明,prnt包含了4个1位的字段。现在,可以通过普通的结构成员运算符(.)单独给这些字段赋值:
prnt.itals=1;prnt.undln=0;prnt.bldfc=1;prnt.autfd=0;下面查看一下prnt的值:
char str[33];int* value=reinterpret_cast<int*>(&prnt);itoa(*value,str,2);printf("%d %d %d %d\n", prnt.autfd,prnt.bldfc,prnt.undln,prnt.itals);printf("sizeof(prnt) = %d\n",sizeof(prnt));printf("十进制: %d\n",prnt);printf("二进制: %032s\n",str);输出的结果为:
0 1 0 1
sizeof(prnt) = 4
十进制: 10
二进制: 0000 0000 0000 0000 0000 0000 0000 1010
可以看出,prnt的大小为4个字节(unsigned int 或 signed int),通过prnt的结构成员可以设置和访问某些bit位的值。
带有位字段的结构提供了一种记录设置的方便途径。许多设置(如,字体的粗体或斜体)就是简单的二进制一。例如,开或关、真或假。如果只需要使用1位,就不需要使用整个变量。内含位字段的结构允许在一个存储单元中存储多个设置。
有时,某些设置也有多个选择,因此需要多位来表示。例如,可以使用如下代码:
struct{unsigned code1 : 2;unsigned code2 : 2;unsigned code3 : 8;
}prcode;这里创建了两个2位的字段和一个8位的字段,可以这样赋值:
prcode.code1=0;prcode.code2=3;prcode.code3=102;但是要确保赋的值不超出字段可容纳的范围(下面会说明当超出范围时会发生什么事情)。
再次打印出prcode的内容
int* value_prcode=reinterpret_cast<int*>(&prcode);itoa(*value_prcode,str,2);printf("%d %d %d\n",prcode.code1,prcode.code2,prcode.code3);printf("sizeof(prcode) = %d\n",sizeof(prcode));printf("十进制: %d\n",prcode);printf("二进制: %032s\n",str);打印结果如下:
0 3 102
sizeof(prcode) = 4
十进制:1644
二进制:0000 0000 0000 0000 0000 0110 0110 1100
可以看出,prcode.code1对应于0-1比特位,数值为00,对应十进制为0;
prcode.code1对应于2-3比特位,数值为11,对应十进制为3;
prcode.code2对应于4-11比特位,数值为0110 0110,对应十进制为102。
因此,一个字段可以对应于多个比特位,且当使用结构字段赋值在可容纳的范围之内时,变量可以记录正确的值。
这里再讨论一些需要注意的问题。首先是,如果声明的总位数超过一个unsigned int类型的大小(4 bytes)时会发生什么事情?结果是会用到下一个unsigned int类型的存储位置。一个字段不允许跨越两个unsigned int之间的边界。编译器会自动移动跨界的字段,保持unsigned int的边界对齐。一旦发生这种情况,第1个unsigned int中会留下一个未命名的“洞”。例如:
struct{unsigned a : 4;unsigned b : 4;unsigned c : 4;unsigned d : 25;
}prlimit;上面定义的位字段大小共37个bits,超过了一个unsigned int的范围,给prlimit的各结构成员赋值,并使用下面代码打印出prlimit所存储的内容:
prlimit.a=0xF;prlimit.b=0;prlimit.c=0xF;prlimit.d=0x1FFFFFF;char str_1[33];char str_2[33];int* value_1=reinterpret_cast<int*>(&prlimit);int* value_2=reinterpret_cast<int*>(&prlimit)+1;itoa(*value_1,str_1,2);itoa(*value_2,str_2,2);printf("0x%x 0x%x 0x%x 0x%x \n",prlimit.a,prlimit.b,prlimit.c ,prlimit.d);printf("sizeof(prlimit) = %d\n",sizeof(prlimit));printf("二进制 0~31位: %032s\n",str_1);printf("二进制 32~63位: %032s\n",str_2);输出的结果如下:
0xf 0x0 0xf 0x1ffffff
sizeof(prlimit) = 8
二进制 0-31位:0000 0000 0000 0000 0000 1111 0000 1111
二进制 32-63位:0000 0001 1111 1111 1111 1111 1111 1111
从输出的结果可以看出,首先,prlimit的大小为8个字节;其次,编译器强制prlimit.d字段发生边界对齐,即prlimit.d位于第二个unsigned int上,prlimit.c与prlimit.d之间会填充未命名的“洞”。
实际上,我们也可以人为的在结构体当中设置未命名的字段宽度来进行填充。使用一个宽度为0的未命名的字段迫使下一个字段与下一个整数对齐:
struct {unsigned field1 : 1;unsigned : 2;unsigned field2 : 1;unsigned : 0;unsigned field3 : 4;
} stuff;使用下面的代码输出stuff的内容:
stuff.field1=1;stuff.field2=1;stuff.field3=0xf;char str_1[33];char str_2[33];int *value_1=reinterpret_cast<int*>(&stuff);int *value_2=reinterpret_cast<int*>(&stuff)+1;itoa(*value_1,str_1,2);itoa(*value_2,str_2,2);printf("sizeof(stuff) = %d\n",sizeof(stuff));printf("二进制 0-31位: %032s\n",str_1);printf("二进制 32-63位: %032s\n",str_2);输出的结果为:
sizeof(stuff) = 8
二进制 0-31位:0000 0000 0000 0000 0000 0000 0000 1001
二进制 32-63位: 0000 0000 0000 0000 0000 0000 0000 1111
也就是说,在这里,stuff.field1和stuff.field2之间,有一个2位的空隙;stuff.field3被强迫与下一个整数对齐,存储到下一个unsigned int中。stuff的大小为8个字节。
最后讨论一个当赋值超出字段可容纳范围的问题。
struct {unsigned t1 : 2;unsigned t2 : 3;unsigned t3 : 4;
} test;int main(){test.t1=3;test.t3=0;test.t2=11;printf("%d %d %d\n",test.t1,test.t2,test.t3);int *value=reinterpret_cast<int*>(&test);char str[50];itoa(*value,str,2);printf("二进制:%032s\n",str);return 0;}输出的结果为:
3 3 0
二进制:0000 0000 0000 0000 0000 0000 0000 1111
上述代码中,成员test.t2赋值的大小超出了容纳的范围。可以看到,t2赋值为11(二进制是1011),结果输出的值是3(二进制是011),即截断了超出的部分。同时也可以看到,超出的部分不会影响t3的值(不同平台不一样?网上有人说会覆盖超出的区域)。
最后需要说明的是,字段存储在一个int中的顺序取决于机器。在有些机器上,存储的顺序是从左往右的,而在另一些机器上,是从右往左的。另外,不同的机器中两个字段边界的位置也有区别。由于这些原因,位字段通常都不容易移植。尽管如此,有些情况却要用到这种不可移植的特性。例如,以特定硬件设备所用的形式存储数据。
相关文章:

C语言基础知识:位与位字段
目录 位与字节 位 比特 字节 对齐特性 位字段 位与字节 位 二进制数系统中,每个0或1就是一个位(bit),位是数据存储的最小单位。其中8 bit就称为一个字节(Byte)。计算机中的CPU位数指的是CPU一次能处理的最大位数࿰…...
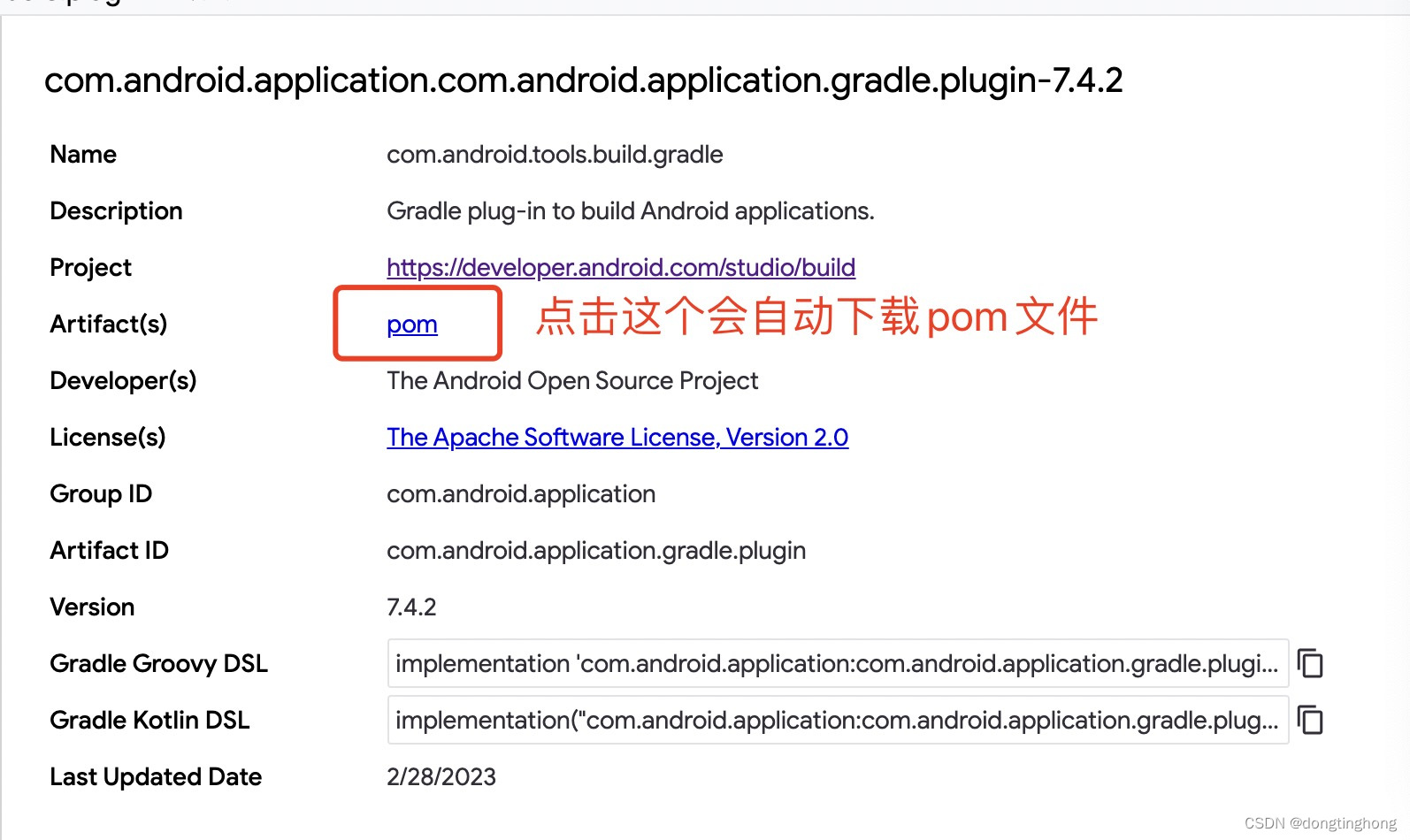
新版android studio gradle插件7.4.2.pom一直无法下载问题
android studio同步时候出现org.gradle.api.plugins.UnknownPluginException,Plugin [id: com.android.application, version: 7.4.2] was not found in any of the following sources: pom插件一直无法下载,搞了好几天,简直想砸电脑&#x…...

Shell——变量和引用
1.总结变量的类型及含义? 2.实现课堂案例计算长方形面积?(6种方式) 3.定义变量urlhttps://blog.csdn.net/weixin_45029822/article/details/103568815 (通过多种方法实现) 1)截取网站访问的协…...

实际开发中一些实用的JS数据处理方法
写在开头 JavaScript 是一种脚本语言,最初是为了网页提供交互式前端功能而设计的,而现在,通过 Node.js,JavaScript 还可以用于编写服务器端代码。 JavaScript 具有动态性、基于原型的面向对象特性、弱类型、多范式、支持闭包执行…...
10:00进去,10:05就出来了,这问的也太变态了···
从外包出来,没想到死在另一家厂子了。 自从加入这家公司,每天都在加班,钱倒是给的不少,所以也就忍了。没想到5月一纸通知,所有人不许加班,薪资直降30%,顿时有吃不起饭的赶脚。 好在有个兄弟内推…...

GPT时代,最令人担心的其实是“塔斯马尼亚效应”
目录 教育到底教什么? 过度依赖GPT可能导致文明退化 GPT可以帮助人类破解“学海无涯极限”悖论 春季学期伊始,全球各地的老师们如临大敌,因为学生们带着ChatGPT杀过来了。Study.com的调研显示,每10个学生中就有超过9个知道Chat…...

基于容器技术和服务发现的全新大数据平台弹性伸缩方法
随着科技的不断发展,各个行业都在不断地数字化和智能化。在这个过程中,大数据技术成为了许多行业的重要支撑。而随着大数据技术的普及,行业分类和设备装置的不断更新换代,弹性伸缩成为了一个不可避免的问题。本文将介绍基于服务发…...

php8 match
刚从 php7 升级到 php8 时 我在使用 switch 语句,结果出现了一个提示: "switch statement can be converted to match expression" 翻译过来就是: switch语句可以转换为match表达式 我当时在想,match 应该是php8 的…...
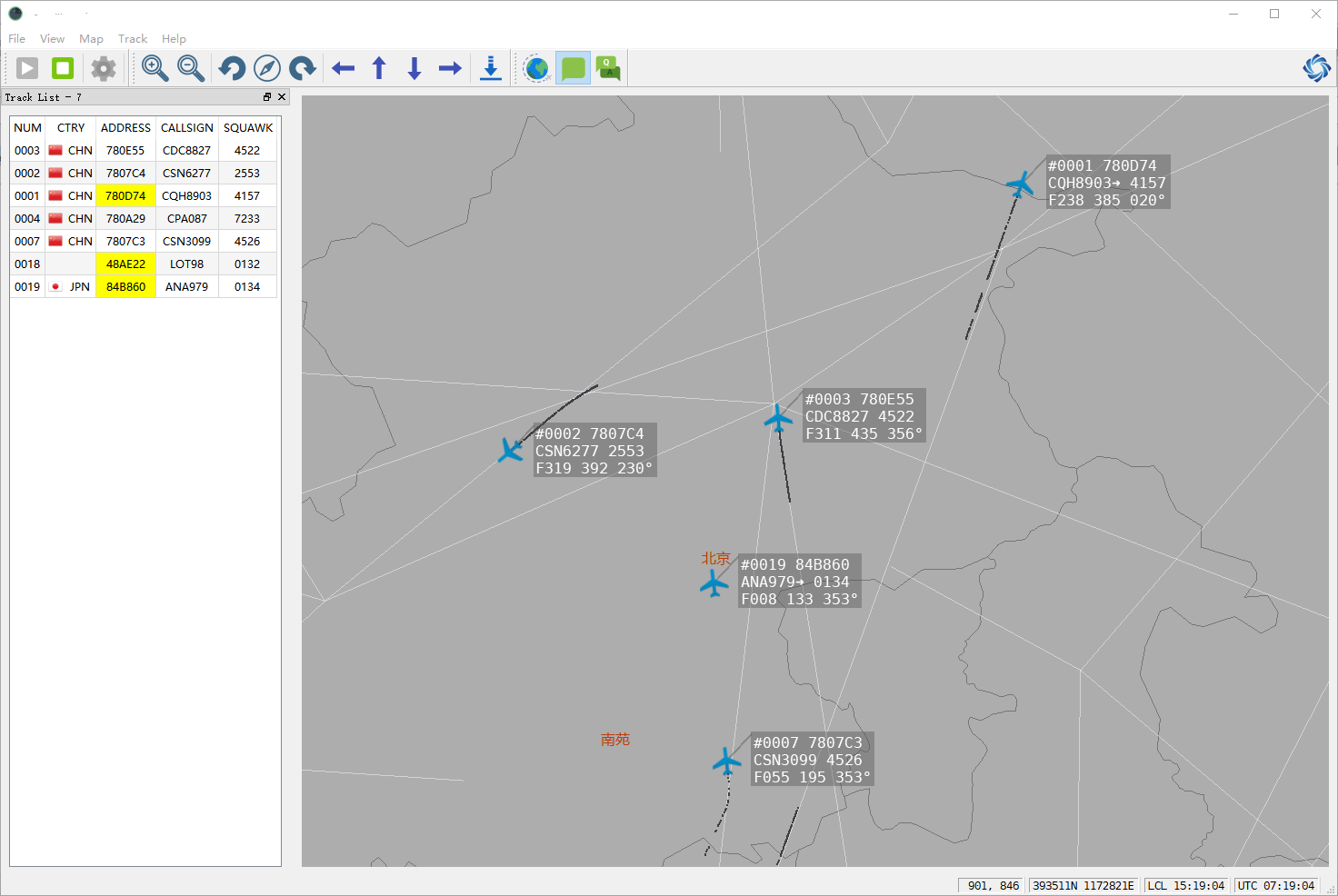
ADS-B接收机Radarcape
1.设备简介 Radarcape是一款便携、高性能、功能强大的ADS-B地面接收机。Radarcape的设备清单包含:ADS-B接收机主机,专业级ADS-B天线,GPS天线,电源线,网线。 2. 功能特点 Radarcape可以通过网口输出飞机的原始数据D…...

软件测评师2012年下半年考试真题<更新中。。。>
1.2012 年下半年全国计算机技术与软件专业技术资格(水平)考试日期是 11月4号。 2.在 CPU 中,控制器 不仅要保证指令的正确执行,还要能够处理异常事件。 3.循环冗余校验码(CRC) 利用生成多项式进行编码。设数据位为 k 位…...
ChatGPT 使用 拓展资料:开始构建你的优质Prompt
ChatGPT 使用 拓展资料:开始构建你的优质Prompt...
Hystrix原理
一.概述 在软件架构领域,容错特指容忍并防范局部错误,不让这种局部错误不断扩大。我们在识别风险领域,风险可以分为已知风险和未知风险,容错直接应对的就是已知风险,这就要求针对的场景是:系统之间调用延时…...

内网外网分离模式下,通过网关转发,来部署前后端分离的系统
前言 最近为某银行系统部署了一套商城系统,网络环境比较特别,思路记录下,其中商场系统使用前后端分离模式部署。 该银行网络环境: 外网服务器:外网可以访问到它,不能访问外网。 网关服务器:跟…...

基于 Amazon API Gatewy 的跨账号跨网络的私有 API 集成
一、背景介绍 本文主要讨论的问题是在使用 Amazon API Gateway,通过 Private Integration、Private API 来完成私有网络环境下的跨账号或跨网络的 API 集成。API 管理平台会被设计在单独的账号中(亚马逊云科技提供的是多租户的环境),因为客观上不同业务…...

SSH远程连接时报错kex_exchange_identification: Connection closed by remote host
简介 在SSH服务器上进行远程内容时,会经常出现kex_exchange_identification: Connection closed by remote host内容,主要是由于远程计算机登录节点的数量限制问题。 解释 在 SSH 服务器上,最大并发登录会话数是由 ‘MaxSessions’ 参数来…...

一、CNNs网络架构-基础网络架构
目录 1.LeNet 2.AlexNet 2.1 激活函数:ReLU 2.2 随机失活:Droupout 2.3 数据扩充:Data augmentation 2.4 局部响应归一化:LRN 2.5 多GPU训练 2.6 论文 3.ZFNet 3.1 网络架构 3.2 反卷积 3.3 卷积可视化 3.4 ZFNet改…...

[开发|C++] C++的基本运算符说明笔记
基本运算符说明 C是一种功能强大的编程语言,提供了多种运算符来执行各种基本操作。下面是一些常见的C基本运算符及其说明: 算术运算符: :加法运算符,用于执行两个操作数的相加操作。 -:减法运算符…...

抖音定位功能的作用
随着智能手机和社交网络的普及,人们日常生活中对于位置信息的需求也越来越高。而抖音作为一款以短视频为主的社交应用,其定位技术也备受关注。本文将就抖音的定位功能进行探究,介绍抖音如何获取、处理和利用用户的位置信息,并探讨…...

阿里 P9 推荐的 Spring 领域巅峰之作,直接颠覆了我对 Spring 的认知
写在前面 你第一次接触 spring 框架是在什么时候?相信很多人和我一样,第一次了解 spring 都不是做项目的时候用到,而是在网上看到或者是听到过一个叫做 spring 的框架,这个框架号称完爆之前的 structs 和 structs2,吸…...
R语言结构方程模型(SEM)在生态学领域中的实践应用
结构方程模型(Sructural Equation Model)是一种建立、估计和检验研究系统中多变量间因果关系的模型方法,它可以替代多元回归、因子分析、协方差分析等方法,利用图形化模型方式清晰展示研究系统中变量间的因果网络关系,…...

HexStrike AI v6.0:面向红队实战的多智能体渗透框架
1. 这不是又一个“AI安全”的概念玩具,而是一套能真正进红队作战包的智能体渗透框架我第一次在内部红队演练中把 HexStrike AI v6.0 推进真实靶场时,没敢直接叫它“AI渗透工具”——怕被老队员当场笑出声。毕竟过去三年里,我亲手试过七套标榜…...

好用还专业!2026 降AIGC平台测评:最新工具推荐与对比分析
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

量子机器学习在网络安全领域的算法演进与实践挑战
1. 量子机器学习:当算力革命遇见智能算法如果你关注过近几年的科技新闻,一定对“量子计算”这个词不陌生。它常常与“颠覆”、“革命”这样的词汇一同出现,听起来既神秘又遥远。但作为一名长期混迹在网络安全和算法优化一线的从业者ÿ…...

Arkime全流量分析平台企业级部署与深度调优实战
1. 这不是又一个SIEM,而是一台“网络时间机器”你有没有遇到过这样的场景:凌晨三点,安全告警平台突然炸出十几条“横向移动”高危告警,但日志里只有一行模糊的401 Unauthorized,源IP是内网段,目标端口是338…...

5分钟搞定Sunshine游戏串流:从安装到畅玩的完整指南
5分钟搞定Sunshine游戏串流:从安装到畅玩的完整指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否想过在卧室的平板上玩书房里的3A大作?或者用手机…...
)
DeepSeek监控告警设置实战指南(告警失效率下降92%的7个关键开关)
更多请点击: https://kaifayun.com 第一章:DeepSeek监控告警设置的核心价值与落地挑战 在大模型推理服务规模化部署的背景下,DeepSeek系列模型(如DeepSeek-V2、DeepSeek-Coder)对资源稳定性、延迟敏感性及异常响应时效…...

零基础玩转AI斗地主:DouZero_For_HappyDouDiZhu快速上手实战指南
零基础玩转AI斗地主:DouZero_For_HappyDouDiZhu快速上手实战指南 【免费下载链接】DouZero_For_HappyDouDiZhu 基于DouZero定制AI实战欢乐斗地主 项目地址: https://gitcode.com/gh_mirrors/do/DouZero_For_HappyDouDiZhu 想要在欢乐斗地主中体验AI智能辅助的…...

从岭回归到Lasso:正则化原理、稀疏性与ADMM算法实践
1. 项目概述:从岭回归到Lasso的深度解析在机器学习和统计建模的实践中,我们常常面临一个核心矛盾:模型在训练数据上表现优异,但在未见过的数据上却一塌糊涂,这就是所谓的“过拟合”。想象一下,你为了记住一…...

3大止损策略拯救你的交易:backtrader实战指南
3大止损策略拯救你的交易:backtrader实战指南 【免费下载链接】backtrader Python Backtesting library for trading strategies 项目地址: https://gitcode.com/gh_mirrors/ba/backtrader 作为一名量化交易者,你是否经常面临这样的困境ÿ…...

因果机器学习在制造业返工决策中的应用:以白光LED产线为例
1. 项目概述:当因果推断遇上产线返工在制造业,尤其是像白光LED芯片制造这样的精密流程工业里,每天都有成千上万个生产批次(Lot)在产线上流转。每个批次在经过磷光体转换(Color Conversion)这一关…...