ORACLE-SQL性能优化(3)
2. 给优化器更明确的命令
自动选择索引
如果表中有两个以上(包括两个)索引,其中有一个唯一性索引,而其他是非唯一性.
在这种情况下,ORACLE将使用唯一性索引而完全忽略非唯一性索引.
举例:
SELECT ENAME FROM EMP
WHERE EMPNO = 2326 AND DEPTNO = 20 ;
这里,只有EMPNO上的索引是唯一性的,所以EMPNO索引将用来检索记录.
TABLE ACCESS BY ROWID ON EMP
INDEX UNIQUE SCAN ON EMP_NO_IDX
至少要包含组合索引的第一列
如果索引是建立在多个列上, 只有在它的第一个列(leading column)被where子句引用时,优化器才会选择使用该索引.
SQL> create table multiindexusage ( inda number , indb number , descr varchar2(10));
Table created.
SQL> create index multindex on multiindexusage(inda,indb); Index created.
SQL> set autotrace traceonly
SQL> select * from multiindexusage where inda = 1; Execution Plan
----------------------------------------------------------
- SELECT STATEMENT Optimizer=CHOOSE
- 0 TABLE ACCESS (BY INDEX ROWID) OF 'MULTIINDEXUSAGE'
- 1 INDEX (RANGE SCAN) OF 'MULTINDEX' (NON-UNIQUE) SQL> select * from multiindexusage where indb = 1;
Execution Plan
----------------------------------------------------------
- SELECT STATEMENT Optimizer=CHOOSE
- 0 TABLE ACCESS (FULL) OF 'MULTIINDEXUSAGE'
很明显 当仅引用索引的第二个列时 优化器使用了全表扫描而忽略了索引
避免在索引列上使用函数
WHERE子句中,如果索引列是函数的一部分.优化器将不使用索引而使用全表扫描.
举例:
低效:
SELECT . FROM DEPT
WHERE SAL * 12 > 25000;
高效: SELECT .
FROM DEPT
WHERE SAL > 25000/12;
避免使用前置通配符
WHERE子句中, 如果索引列所对应的值的第一个字符由通配符(WILDCARD)开始, 索引将不被采用.
SELECT USER_NO,USER_NAME,ADDRESS FROM USER_FILES
WHERE USER_NO LIKE '%109204421';
在这种情况下,ORACLE将使用全表扫描.
避免在索引列上使用NOT
通常,我们要避免在索引列上使用NOT, NOT会产生在和在索引列上使用函数相同的影响. 当ORACLE”遇到”NOT,他
就
会停止使用索引转而执行全表扫描.举例:
低效: (这里,不使用索引) SELECT .
FROM DEPT
WHERE DEPT_CODE NOT = 0;
高效: (这里,使用了索引) SELECT .
FROM DEPT
WHERE DEPT_CODE > 0;
避免在索引列上使用 IS NULL和IS NOT NULL
避免在索引中使用任何可以为空的列,ORACLE将无法使用该索引 .对于单列索引,如果列包含空值,索引中将不存在此记录. 对于复合索引,如果每个列都为空,索引中同样不存在此
记录. 如果至少有一个列不为空,则记录存在于索引中.
如果唯一性索引建立在表的A列和B列上, 并且表中存在一条记录的A,B值为(123,null) , ORACLE将不接受下一条具有相同A,B值(123,null)的记录(插入). 然而如果所有的索引列都为空,ORACLE将认为整个键值为空而空不等于空. 因此你可以插入1000条具有相同键值的记录,当然它们都是空!
因为空值不存在于索引列中,所以WHERE子句中对索引列进行空值比较将使ORACLE停用该索引.
任何在where子句中使用is null或is not null的语句优化器是不允许使用索引的。
避免出现索引列自动转换
当比较不同数据类型的数据时, ORACLE自动对列进行简单的类型转换.
假设EMP_TYPE是一个字符类型的索引列.
SELECT USER_NO,USER_NAME,ADDRESS FROM USER_FILES
WHERE USER_NO = 109204421
这个语句被ORACLE转换为:
SELECT USER_NO,USER_NAME,ADDRESS FROM USER_FILES
WHERE TO_NUMBER(USER_NO) = 109204421
因为内部发生的类型转换, 这个索引将不会被用到!
在查询时尽量少用格式转换
如用 WHERE a.order_no = b.order_no
不用
WHERE TO_NUMBER (substr(a.order_no, instr(b.order_no, '.') - 1)
= TO_NUMBER (substr(a.order_no, instr(b.order_no, '.') - 1)
3.减少访问次数
减少访问数据库的次数
当执行每条SQL语句时, ORACLE在内部执行了许多工作:
解析SQL语句, 估算索引的利用率, 绑定变量 , 读数据块等等.
由此可见, 减少访问数据库的次数 , 就能实际上减少
ORACLE的工作量.
类比,工程实施
使用DECODE来减少处理时间
例如:
SELECT COUNT(*),SUM(SAL) FROM EMP
WHERE DEPT_NO = 0020
AND ENAME LIKE ‘SMITH%’;
SELECT COUNT(*),SUM(SAL) FROM EMP
WHERE DEPT_NO = 0030
AND ENAME LIKE ‘SMITH%’;
你可以用DECODE函数高效地得到相同结果
SELECT COUNT(DECODE(DEPT_NO,0020,’X’,NULL)) D0020_COUNT,
COUNT(DECODE(DEPT_NO,0030,’X’,NULL)) D0030_COUNT,
SUM(DECODE(DEPT_NO,0020,SAL,NULL)) D0020_SAL, SUM(DECODE(DEPT_NO,0030,SAL,NULL)) D0030_SAL
FROM EMP WHERE ENAME LIKE ‘SMITH%’;
减少对表的查询
在含有子查询的SQL语句中,要特别注意减少对表的查询.例如:
低效
SELECT TAB_NAME FROM TABLES
WHERE TAB_NAME = ( SELECT TAB_NAME
FROM TAB_COLUMNS WHERE VERSION = 604)
AND DB_VER= ( SELECT DB_VER FROM TAB_COLUMNS WHERE VERSION = 604)
高效
SELECT TAB_NAME FROM TABLES
WHERE (TAB_NAME,DB_VER) = ( SELECT TAB_NAME,DB_VER)
FROM TAB_COLUMNS WHERE VERSION = 604)
4. 细节上的影响
WHERE子句中的连接顺序
ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理, 当在WHERE子句中有多个表联接时,WHERE子句中排
在最后的表应当是返回行数可能最少的表,有过滤条件的子句应放在WHERE子句中的最后。
如:设从emp表查到的数据比较少或该表的过滤条件比较确定,能大大缩小查询范围,则将最具有选择性部分放在WHERE子句中的最后:
select * from emp e,dept d
where d.deptno >10 and e.deptno =30 ;
如果dept表返回的记录数较多的话,上面的查询语句会比下面的查询语句响应快得多。
select * from emp e,dept d
where e.deptno =30 and d.deptno >10 ;
WHERE子句 ——函数、表达式使用
最好不要在WHERE子句中使用函或表达式,如果要使用的话,最好统一使用相同的表达式或函数,这样便于以后使用合理的索引。
Order by语句
ORDER BY语句决定了Oracle如何将返回的查询结果排序。Order by语句对要排序的列没有什么特别的限制,也可以将函数加入列中(象联接或
者附加等)。任何在Order by语句的非索引项或者有计算表达式都将降低查询速度。
仔细检查order by语句以找出非索引项或者表达式,它们会降低性能。解决这个问题的办法就是
重写order by语句以使用索引,也可以为所使用的列建立另外一个索引,同时应绝对避免在order by子句中使用表达式。
联接列
对于有联接的列,即使最后的联接值为一个静态值,优化器是不会使用索引的。
select * from employss where
first_name||''||last_name ='Beill Cliton';
系统优化器对基于last_name创建的索引没有使用。
当采用下面这种SQL语句的编写,Oracle系统就可以采用基于last_name创建的索引。
select * from employee where
first_name ='Beill' and last_name ='Cliton';
带通配符(%)的like语句
通配符(%)在搜寻词首出现,Oracle系统不使用last_name的索引。
select * from employee where last_name like '%cliton%';
在很多情况下可能无法避免这种情况,但是一定要心中有底,通配符如此使用会降低查询速度。然而当通配符出现在字符串其他位置时,优化器就能利用索引。在下面的查询中索引得到了使用:
select * from employee where last_name like 'c%';
用Where子句替换HAVING子句
避免使用HAVING子句, HAVING 只会在检索出所有记录之后才对结果集进行过滤. 这个处理需要排序,总计等操作. 如果能通过WHERE子句限制记录的数目,那就能减少这方面的开销.
例如:
低效:
SELECT REGION,AVG(LOG_SIZE)
FROM LOCATION GROUP BY REGION
HAVING REGION REGION != ‘SYDNEY’ AND REGION != ‘PERTH’
高效
SELECT REGION,AVG(LOG_SIZE)
FROM LOCATION
WHERE REGION REGION != ‘SYDNEY’ AND REGION != ‘PERTH’
GROUP BY REGION
顺序
WHERE > GROUP > HAVING
用NOT EXISTS 替代 NOT IN
在子查询中,NOT IN子句将执行一个内部的排序和合并. 无论在哪种情况下,NOT IN都是最低效的 (因为它对子查询中的表执行了一个全表遍历).使用NOT EXISTS 子句可以有效地利用索引。尽可能使用NOT EXISTS来代替NOT IN,尽管二者都使用了NOT(不能使用索引而降低速度),NOT EXISTS要比NOT IN查询效率更高。
例如:
语句1
SELECT dname, deptno FROM dept WHERE deptno NOT IN (SELECT deptno FROM emp);
语句2
SELECT dname, deptno FROM dept WHERE NOT EXISTS
(SELECT deptno FROM emp WHERE dept.deptno = emp.deptno);
2要比1的执行性能好很多。
因为1中对emp进行了full table scan,这是很浪费时间的操作。而且1中没有用到emp的index, 因为没有where子句。而2中的语句对emp进行的是缩小范围的查询。
用索引提高效率
索引是表的一个概念部分,用来提高检索数据的效率,ORACLE使用了一个复杂的自平衡B-tree结构. 通常,通过索引查询数据比全表扫描要快. 当ORACLE找出执行查询和Update语句的最佳路径时, ORACLE优化器将使用索引. 同样在联结多个表时使用索引也可以提高效率. 另一个使用索引的好处是,它提供了主键(primary key)
的唯一性验证。
通常, 在大型表中使用索引特别有效. 当然,你也会发现, 在扫描小表时,使用索引同样能提高效率. 虽然使用索引能得到查询效率的提高,但是我们也必须注意到它的代价. 索引需要空间来存储,也需要定期维护, 每当有记录在表中增减或索引列被修改时, 索引本身也会被修改. 这意味着每条记录的INSERT , DELETE , UPDATE将为此多付出4 , 5 次的磁盘I/O . 因为索引需要额外的存储空间和处理,那些不必要的索引反而会使查询反应时间变慢.。定期的重构索引
是有必要的。
避免在索引列上使用计算
WHERE子句中,如果索引列是函数的一部分.优化器将不
使用索引而使用全表扫描.
低效:
SELECT . FROM DEPT WHERE SAL * 12 > 25000;
高效:
SELECT . FROM DEPT WHERE SAL > 25000/12;
用>= 替代 >
如果DEPTNO上有一个索引。
高效:
SELECT * FROM EMP
WHERE DEPTNO >=4
低效:
SELECT * FROM EMP
WHERE DEPTNO >3
通过使用>=、<=等,避免使用NOT命令
例子:
select * from employee where salary <> 3000;
对这个查询,可以改写为不使用NOT:
select * from employee where salary<3000 or salary>3000;
虽然这两种查询的结果一样,但是第二种查询方案会比第一种查询方案更快些。第二种查询允许Oracle对salary列使用索引,而第一种查询则不能使用索引。
如果有其它办法,不要使用子查询。
外部联接"+"的用法
外部联接"+"按其在"="的左边或右边分左联接和右联接。若不带"+"运算符的表中的一个行不直接匹配于带"+"预算符的表中的任何行,
则前者的行与后者中的一个空行相匹配并被返回。利用外部联接"+",可以替代效率十分低下的 not in 运算,大大提高运行速度。例如,下面这条命令执行起来很慢:
select a.empno from emp a where a.empno not in (select empno from emp1 where job='SALE');
利用外部联接,改写命令如下:
select a.empno from emp a ,emp1 b where a.empno=b.empno(+)
and b.empno is null and b.job='SALE';
这样运行速度明显提高.
尽量多使用COMMIT
事务是消耗资源的,大事务还容易引起死锁
COMMIT所释放的资源:
回滚段上用于恢复数据的信息. 被程序语句获得的锁
redo log buffer 中的空间
ORACLE为管理上述3种资源中的内部花费
用TRUNCATE替代DELETE
当删除表中的记录时,在通常情况下, 回滚段
(rollback
segments ) 用来存放可以被恢复的信息. 如果你没有
COMMIT事务,ORACLE会将数据恢复到删除之前的状态(准
确地说是恢复到执行删除命令之前的状况)
而当运用TRUNCATE时, 回滚段不再存放任何可被恢复的
信息.当命令运行后,数据不能被恢复.因此很少的资源被调用,
执行时间也会很短.
计算记录条数
和一般的观点相反, count(*) 比count(1)稍快 , 当然如果可
以通过索引检索,对索引列的计数仍旧是最快的.
例如
COUNT(EMPNO)
字符型字段的引号
比如有的表PHONE_NO字段是CHAR型,而且创建有索引,
但在WHERE条件中忘记了加引号,就不会用到索引。
WHERE PHONE_NO=‘13920202022’ WHERE PHONE_NO=13920202022
优化EXPORT和IMPORT
使用较大的BUFFER(比如10MB , 10,240,000)可以提高
EXPORT和IMPORT的速度; ORACLE将尽可能地获取你所指定的内
存大小,即使在内存
不满足,也不会报错.这个值至少要和表中最大的列相当,否则
列值会被截断;
相关文章:
)
ORACLE-SQL性能优化(3)
2. 给优化器更明确的命令 自动选择索引 如果表中有两个以上(包括两个)索引,其中有一个唯一性索引,而其他是非唯一性. 在这种情况下,ORACLE将使用唯一性索引而完全忽略非唯一性索引. 举例: SELEC…...

3年外包裸辞,面试阿里、字节全都一面挂,哭死.....
测试员可以先在外包积累经验,以后去大厂就很容易,基本不会被卡,事实果真如此吗?但是在我身上却是给了我很大一巴掌... 所谓今年今天履历只是不卡简历而已,如果面试答得稀烂,人家根本不会要你。况且要不是大…...
 -- 多线程(信号量与CountDownLatch))
JavaEE(系列16) -- 多线程(信号量与CountDownLatch)
目录 1. 信号量Semaphore 2. CountDownLatch 1. 信号量Semaphore 信号量, 用来表示 "可用资源的个数". 本质上就是一个计数器. 1.理解信号量 可以把信号量想象成是停车场的展示牌: 当前有车位 100 个. 表示有 100 个可用资源.当有车开进去的时候, 就相当于申请一个可…...
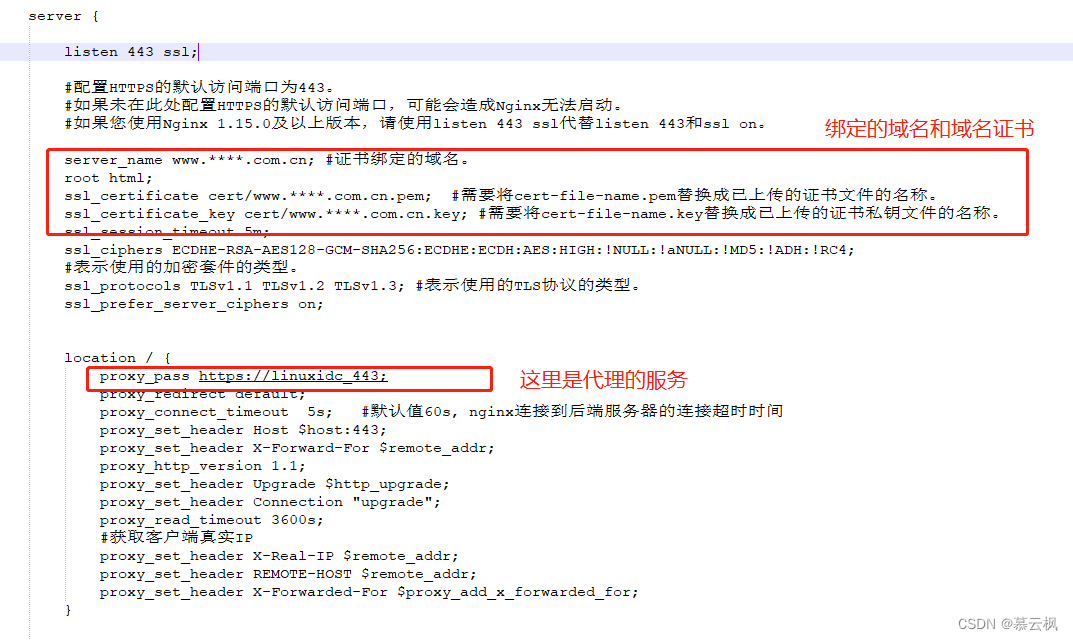
Tomcat配置https协议证书-阿里云,Nginx配置https协议证书-阿里云,Tomcat配置https证书pfx转jks
Tomcat/Nginx配置https协议证书 前言Tomcat配置https协议证书-阿里云方式一 pfx配置证书重启即可 方式二 jkspfx生成jks配置证书重启即可 Nginx配置https协议证书-阿里云实现方式重启即可 其他Tomcat相关配置例子如下nginx配置相关例子如下 前言 阿里云官网:https:…...

抖音定位基本原理
抖音是一款非常受欢迎的短视频分享应用程序,它允许用户创建和分享15秒到60秒的短视频。抖音的成功在很大程度上归功于其强大的定位技术,该技术可以根据用户的兴趣和位置提供个性化的内容。在本文中,我们将深入探讨抖音的定位技术,…...

【Hbase 05】Hbase表的设计原则与优化方案
这里说一下Hbase在使用过程中的表设计原则与优化方案,如果你是运维或者开发兼顾环境的工作,也许比较受用,话不多说,我们直接开始说优化的内容: 一、表设计原则 1.行键设计 行键在设计的时候要尽量的散列,例如可以考虑使用哈希、加密算法等使结果散列,这样能保证请求不会…...
行业报告 | 2022文化科技十大前沿应用趋势(上)
文 | BFT机器人 前言 Introduction 文化科技是文化科技融合过程中诞生的系列新技术成果,是文化强国和科技强国两大战略的交又领域。2012 年 8月,科技部会同中宣部、财政部、文化部、广电总局、新闻出版总署发布《文化科技创新工程纲要》,开启…...
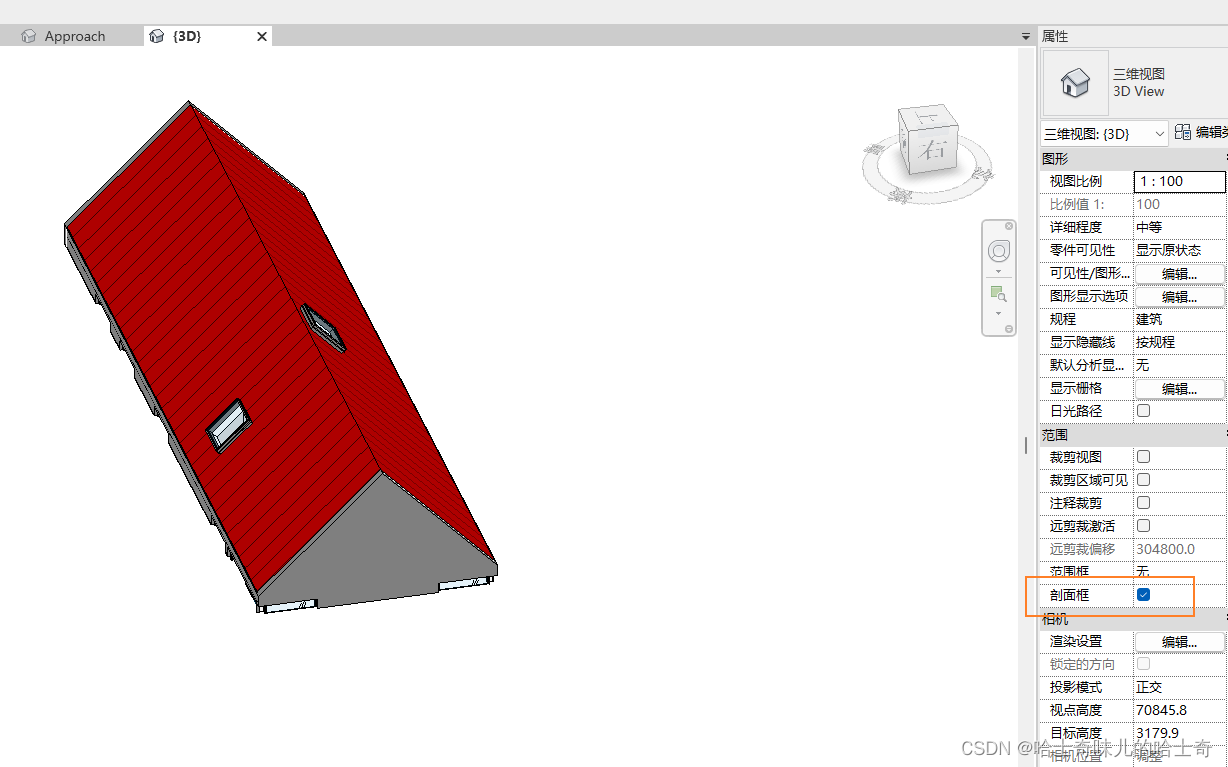
实现BIM的Revit软件学习资料
实现BIM的Revit软件学习资料 一、BIM与Revit的关系二、Revit使用方法总结(一)快捷键(二)一些技巧 一、BIM与Revit的关系 链接: BIM与Revit是什么关系?看完秒懂系列! REVIT是实现BIM理念的工具之一。 二、Revit使用方…...

09 集合框架2
集合元素的迭代方式有哪些? for循环,for-each循环(底层迭代器),迭代器 Iterator<String> it list.iterator(); while(it.hasNext()) {String ele it.next();System.out.println(ele); }并发修改集合元素异常是怎么造成的?怎么解决? 在迭代过程中使用List里面的增…...

相见恨晚的5款良心软件,每款都是经过时间检验的精品
今天来给大家推荐5款良心软件,每款都是经过时间检验的精品,用起来让你的工作效率提升飞快,各个都让你觉得相见恨晚! 1.颜色选择器——ColorPicker ColorPicker是一款用于在屏幕上选择颜色的工具。它可以让你快速地获取任意像素的颜色值,并复制到剪贴板…...
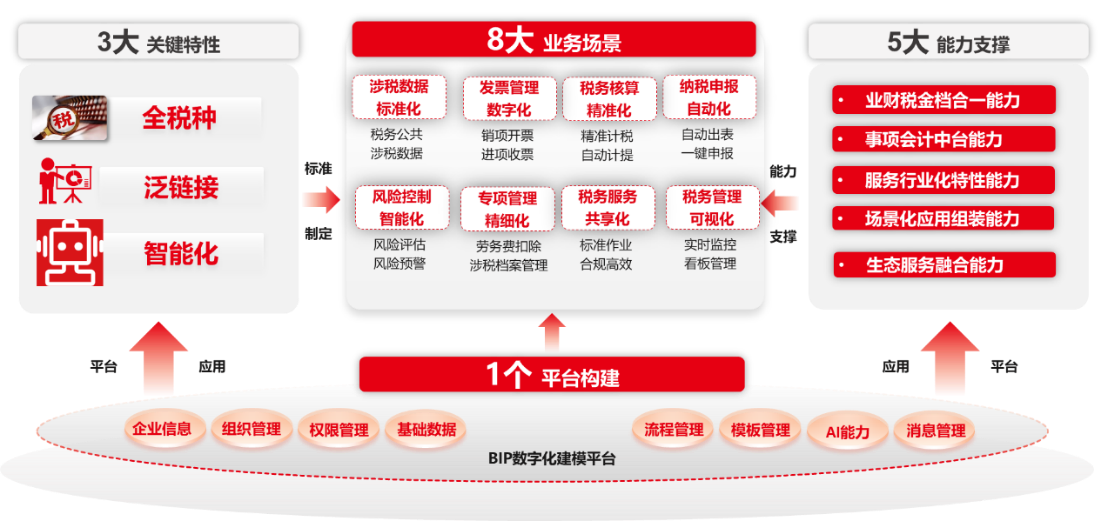
AI与税务管理:新技术带来的新机遇和新挑战
本文作者:王伊琳 人工智能(Artificial Intelligence,AI)是指由计算机系统或机器人模拟人类智能的过程和结果,包括感知、理解、学习、推理、决策等能力。近年来,随着计算机技术、互联网平台、大数据分析等的…...
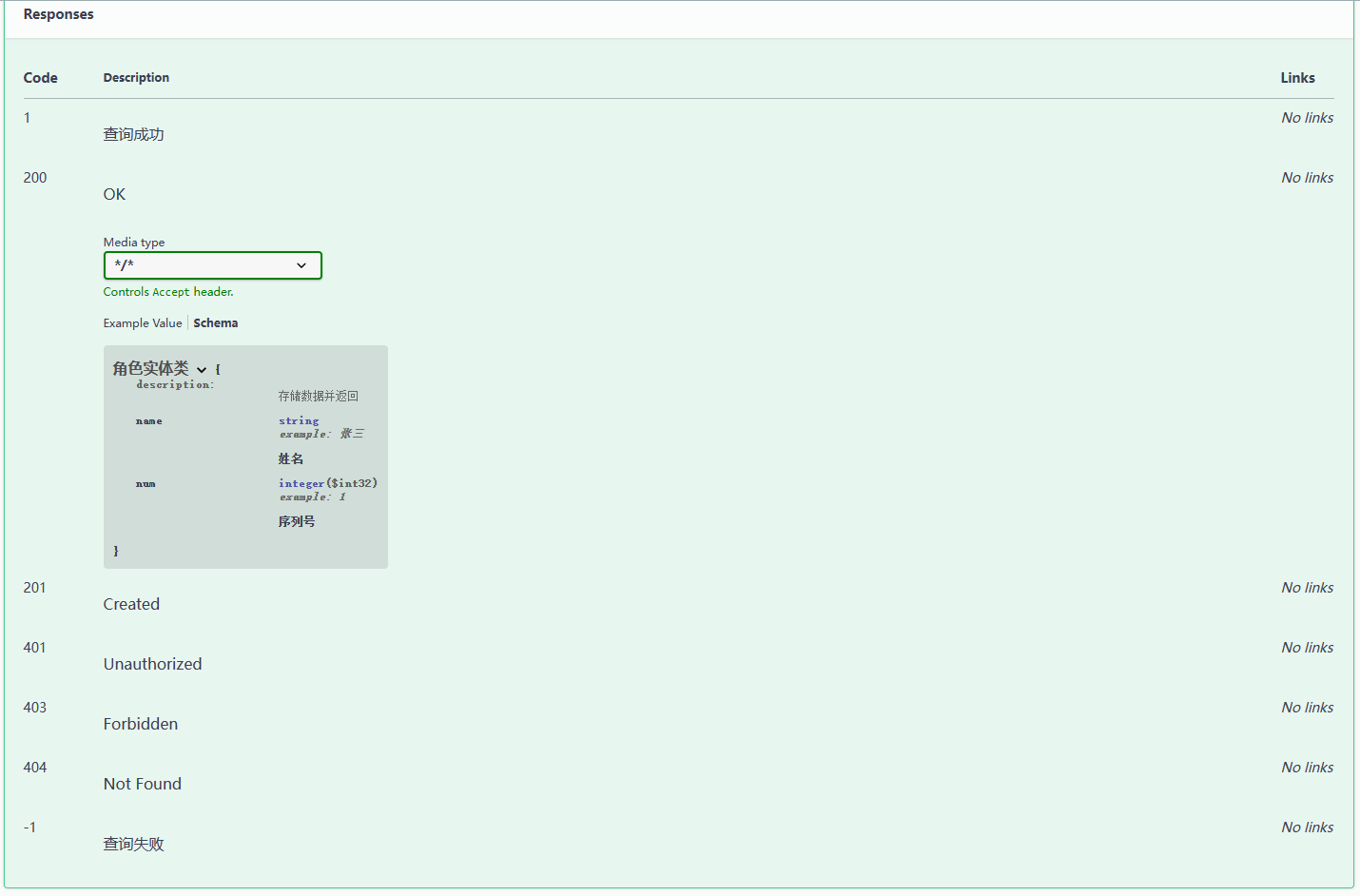
springboot 集成 Swagger3(速通)
→ springboot 集成 Swagger2 ← 目录 1. 案例2. info 配置3. Docket 配置1. 开关配置2. 扫描路径3. 路径匹配4. 分组管理 4. 常用注解1. 说明2. 案例 1. 案例 这次直接使用 2.5.6 的 spring-boot 。 依赖: <parent><groupId>org.springframework.…...
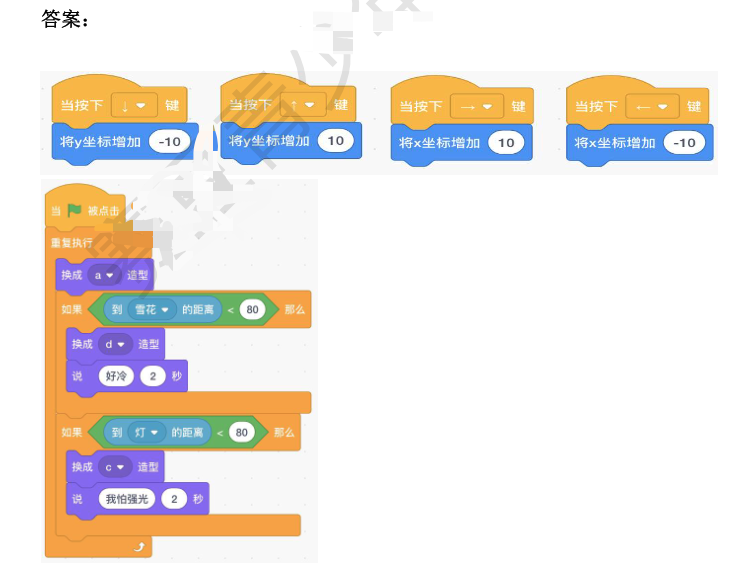
2023年NOC大赛创客智慧编程赛项图形化复赛模拟题二,包含答案解析
2023年NOC大赛创客智慧编程赛项图形化复赛模拟题二,包含答案解析 第一题: 在源程序“小蝙蝠”文件中,实现小蝙蝠遇到不同的角色会说不同的话,以及切换不同的造型要求: 1:游戏开始时,小蝙蝠角色是造型 a,并能够用键盘控制上、下、左、右移动; 2:移动小蝙蝠,距离角色雪…...

2023年NOC大赛创客智慧编程赛项Python 复赛模拟题(二)
题目来自:NOC 大赛创客智慧编程赛项Python 复赛模拟题(二) NOC大赛创客智慧编程赛项Python 复赛模拟题(二) 第一题: 编写一个成绩评价系统,当输入语文、数学和英语三门课程成绩时,输出三门课程总成绩及其等级。 (1)程序提示用户输入三个数字,数字分别表示语文、数学、…...

【SQL】MySQL的查询语句
文章目录 SELECT语句WHERE子句JOIN语句GROUP BY和HAVINGORDER BYLIMIT其他关键字 MySQL是一种广泛使用的关系型数据库管理系统,它被广泛地应用于各种应用程序和网站。学会使用MySQL的查询语句可以帮助我们更好地管理和分析数据,从而更好地利用数据库中的…...

测试的分类
1 按照开发阶段(软件开发周期) 单元测试是对软件的组成单元进行测试。其目的是检验软件基本组成单位的正确性。测试的对象是软件设计的最小单位——模块,故又称为模块测试。集成测试是将程序模块采用适当的集成策略组装起来,对系…...

【5.21】六、自动化测试—持续集成测试
目录 6.4 持续集成测试 6.4.1 持续集成的概念 6.4.2 持续集成测试框架设计 6.4 持续集成测试 持续集成(Continuous Integration,CI)是软件开发DevOps(DevelopmentOperations)中的一个概念,它强调的是软…...

【C++】 排列与组合算法详解(进阶篇)
文章目录 写在前面算法1:朴素算法思路缺点 算法2:递推预处理思路时间复杂度: O ( n 2 ) O(n^2) O(n2) 算法3:阶乘逆元思路时间复杂度: O ( n log n ) O(n \log n) O(nlogn)思考:读者也可以尝试写 O ( n…...

Godot引擎 4.0 文档 - 循序渐进教程 - 监听玩家输入
本文为Google Translate英译中结果,DrGraph在此基础上加了一些校正。英文原版页面: Listening to player input — Godot Engine (stable) documentation in English 监听玩家输入 在上一课创建您的第一个脚本的基础上,让我们看看任何游戏…...
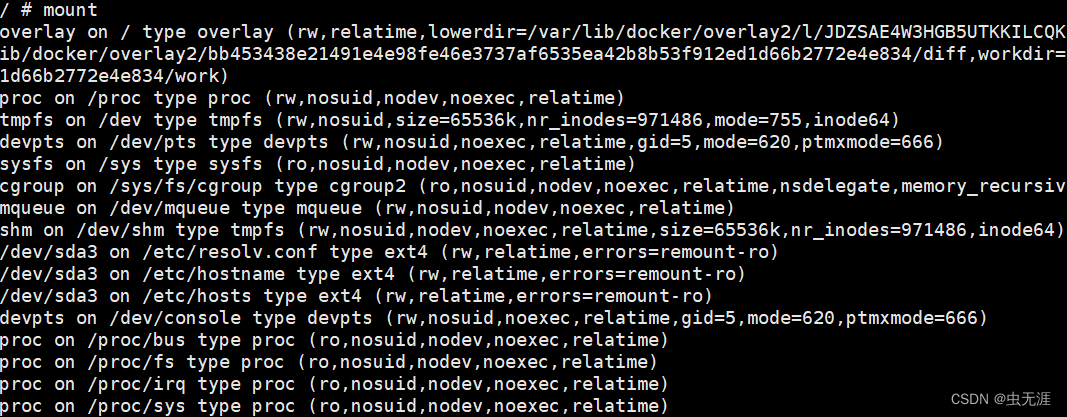
Docker笔记9 | Docker中网络功能知识梳理和了解
9 | Docker中网络功能知识梳理和了解 1 外部访问容器1.1 访问方式1.2 映射所有接口地址1.3 映射到指定地址的指定端口1.4 映射到指定地址的任意端口1.5 查看映射端口配置 2 容器互联2.1 新建网络2.2 连接容器 3 配置DNS 简单说:Docker 允许通过外部访问容器或容器互…...

Python安全自动化:构建可落地的渗透测试工作流
1. 这不是炫技工具箱,而是一套可落地的安全工作流“黑客的‘瑞士军刀’”这个说法在安全圈里被用滥了——很多人一听到就想到Kali Linux里那堆图标花哨、命令冗长、跑起来动不动就报错的GUI工具。但真正干过渗透测试的人心里都清楚:能稳定复现、可嵌入流…...

通达信ChanlunX缠论插件:5分钟完成专业缠论分析的终极免费工具
通达信ChanlunX缠论插件:5分钟完成专业缠论分析的终极免费工具 【免费下载链接】ChanlunX 缠中说禅炒股缠论可视化插件 项目地址: https://gitcode.com/gh_mirrors/ch/ChanlunX 你是不是经常盯着K线图却看不懂市场走势?想要掌握缠论分析技术&…...

NVIDIA Profile Inspector深度教程:解锁显卡隐藏设置的终极指南
NVIDIA Profile Inspector深度教程:解锁显卡隐藏设置的终极指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款功能强大的显卡性能调优工具,专为…...

HS2-HF Patch:你的HoneySelect2游戏体验终极解决方案
HS2-HF Patch:你的HoneySelect2游戏体验终极解决方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为HoneySelect2的语言障碍、MOD兼容性问题…...

Cursor Free VIP:AI编程助手Pro功能永久免费的技术解决方案
Cursor Free VIP:AI编程助手Pro功能永久免费的技术解决方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached you…...

学术写作新纪元!2026一站式AI论文写作工具推荐指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...

DLSS Swapper终极指南:如何一键管理游戏DLSS版本提升50%性能
DLSS Swapper终极指南:如何一键管理游戏DLSS版本提升50%性能 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 你是否曾经因为游戏自带的DLSS版本过时而感到困扰?当最新的DLSS 3.5版本发布&#x…...

AI Agent 在工具调用失败时,如何设计一个智能的降级策略?
这个问题挺关键的,工具调用失败在 AI Agent 系统里是常态,不是异常。核心思路是——先分类,再分级,最后兜底。 我之前做 Agent 编排系统的时候,工具调用成功率大概在 85% 左右,剩下 15% 都得靠降级策略兜住。如果没设计好,整个 Agent 就会频繁报错,用户体验很差。 第一步:错误…...

AMD Ryzen硬件调试神器:5分钟掌握SMU Debug Tool核心技巧
AMD Ryzen硬件调试神器:5分钟掌握SMU Debug Tool核心技巧 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:/…...

魔兽争霸3终极优化指南:5分钟解决画面拉伸、帧率限制与中文兼容问题
魔兽争霸3终极优化指南:5分钟解决画面拉伸、帧率限制与中文兼容问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为经典游戏魔兽争…...