Numpy基础与实例——人工智能基础
文章目录
- 一、Numpy概述
- 1. 优势
- 2. numpy历史
- 3. Numpy的核心:多维数组
- 4. 内存中的ndarray对象
- 4.1 元数据(metadata)
- 4.2 实际数据
- 二、numpy基础
- 1. ndarray数组
- 2. arange、zeros、ones、zeros_like
- 3. ndarray对象属性的基本操作
- 3.1 修改数组维度
- 3.2 修改数组元素类型
- 3.3 数组的size
- 4. 数组元素索引
- 5. Numpy内部基本数据类型
- 5.1 基本数据类型简写的应用案例
- 5.2 将列表强转为数组
- 方式1 通过字符串的方式指定dtype(不常用)
- 方式2:通过列表套元组(不常用)
- 方式3:通过字典的固定键设置dtype
- 5.3 datetime64
- 6. ndarray数组维度操作
- 6.1 视图变维(数据共享):reshape()与ravel()
- 6.2 赋值变维(数据独立)
- 6.3 就地变维:直接改变原数组的维度,不返回新数组
- 7. ndarray数组切片操作
- 7.1 一维数组切片
- 7.2 多维数组切片
- 7.3 ndarray数组的掩码操作
- 布尔掩码
- 布尔掩码操作案例:求100以内3的倍数的数字
- 标签掩码:掩码数组中为索引值
- 7.4 多维数组的组合与拆分
- stack and split
- concatenate
- 长度不等的数组组合
- 简单一维数组组合方案
- ndarray类的其他属性
一、Numpy概述
1. 优势
- Numpy(Nummerical Python),补充了Python语言所欠缺的数值计算能力;
- Numpy是其它数据分析及机器学习库的底层库;
- Numpy完全标准的C语言实现,运行效率充分优化(Python 1989年出现,1991年发布);
- Numpy开源免费。
2. numpy历史
- 1995年,Numeric,Python语言数值计算扩充;
- 2001年,Scipy->Numarray,多维数组运算;
- 2005年,Numeric+Numarray->Numpy。
- 2006年,Numpy脱离Scipy成为独立的项目。
3. Numpy的核心:多维数组
- 代码简洁:减少Python代码中的循环
- 底层实现: 厚内核©+薄接口(Python),保证性能.
4. 内存中的ndarray对象
4.1 元数据(metadata)
存储对目标数组的描述信息,如: ndim、shape、dtype、data等.
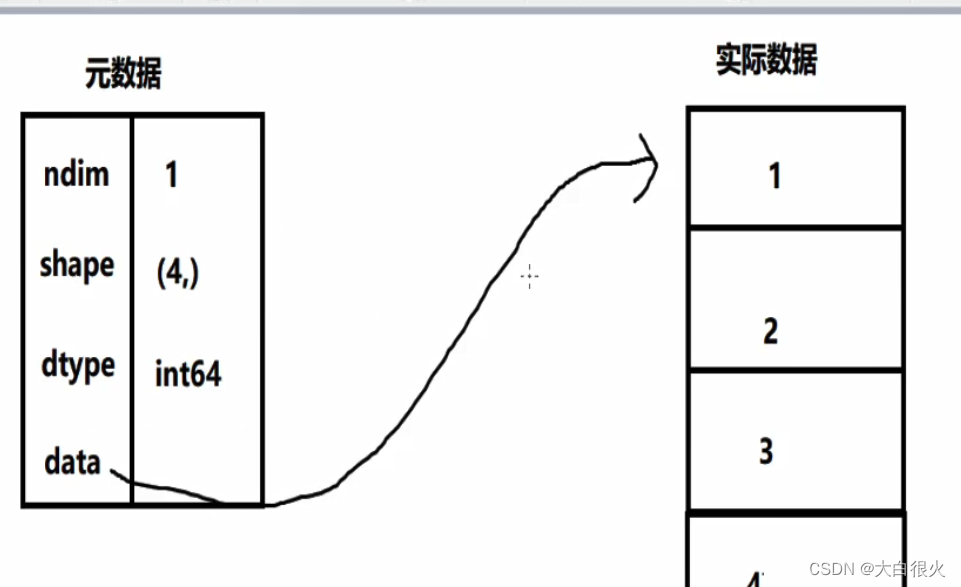
4.2 实际数据
完整的数组数据
将实际数据与元数据分开存放,一方面提高了内存空间的使用效率另一方面减少对实际数据的访问频率,提高性能。
ndarray数组对象的特点
- Numpy数组是同质数组,即所有元素的数据类型必须相同
- Numpy数组的下标从0开始,最后一个元素的下标为数组长度减1
ndarray数组对象的特点 - Numpy数组是同质数组,即所有元素的数据类型必须相同
- Numpy数组的下标从0开始,最后一个元素的下标为数组长度-1
二、numpy基础
1. ndarray数组
import numpy as np# 通过array创建ndarray
ary = np.array([1, 2, 3 , 4, 5])
print(ary)
print(type(ary))# 数组与元素的运算是数组与每个元素分别运算
print(ary+2)
print(ary*2)
print(ary == 3)# 数组与数组之间的运算 是 对应位置对应计算,数组不等不能计算
print(ary + ary)
print(ary * ary)# 输出:
# [1 2 3 4 5]
# <class 'numpy.ndarray'>
# [3 4 5 6 7]
# [ 2 4 6 8 10]
# [False False True False False]
#[ 2 4 6 8 10]
#[ 1 4 9 16 25]
数组与元素的运算是数组与每个元素分别运算;
数组与数组之间的运算是对应位置对应计算
数组长度不等不能计算
2. arange、zeros、ones、zeros_like
import numpy as npary = np.array([1, 2, 3 , 4, 5])
print(ary)print(ary + ary)
print(ary * ary)
aryrange = np.arange(1,3)
print(aryrange)
aryrange = np.arange(1,3,0.1)
print(aryrange)ary = np.zeros(10) # 生成0数组
print(ary)
ary = np.zeros(10, dtype='int64') # 设置数据类型
print(ary)ary = np.zeros((2 ,2)) # 生成2*2的矩阵
print(ary)
print(ary.shape)ary = np.array([1, 2, 3 , 4, 5]) # 拿到一个数组,用0填充
print(np.zeros_like(ary))# 输出
# [1 2 3 4 5]
# [ 2 4 6 8 10]
# [ 1 4 9 16 25]
# [1 2]
# [1. 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2. 2.1 2.2 2.3 2.4 2.5 2.6 2.7
# 2.8 2.9]# [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
# [0 0 0 0 0 0 0 0 0 0]# [[0. 0.]
# [0. 0.]]# (2, 2)# [1 2 3 4 5]
# [0 0 0 0 0]
python的range只能生成整数,而arange可生成浮点数
zeros_like拿到一个数组,用0填充
ones_like用法类似
3. ndarray对象属性的基本操作
3.1 修改数组维度
import numpy as npary = np.arange(1, 9)
print(ary)# 直接修改原始数据的维度
ary.shape = (2, 4)
print(ary)
print(ary.shape)# 修改为3维数据
ary.shape = (2, 2, 2)
print(ary)
print(ary.shape)# [1 2 3 4 5 6 7 8]# [[1 2 3 4]
# [5 6 7 8]]
# (2, 4)# [1 2 3 4 5 6 7 8]
# [[[1 2]
# [3 4]]
#
# [[5 6]
# [7 8]]]
# (2, 2, 2)
可
直接使用shape修改数组的形状
3.2 修改数组元素类型
ary = np.arange(1, 9)
ary.dtype = "float64" # 只能修改解析方式,修改数据类型只能用astype
print(ary)ary = np.arange(1, 9)
c = ary.astype(float) # 不会修改原始数据,可用一个变量去接收
print(c)# 输出
# [4.24399158e-314 8.48798317e-314 1.27319747e-313 1.69759663e-313]
# [1. 2. 3. 4. 5. 6. 7. 8.]
修改数组类型时不可使用dtype,此方式只能修改解析方式,会得到一个错误的值
可使用astype()去修改,此方式不会修改原始数据,可用一个新变量去接收
3.3 数组的size
import numpy as npary = np.arange(1, 9)
print(ary)print(ary.shape)
print(ary.size)
print(len(ary))
ary.shape = (2, 4)
print(ary.shape)
print(ary.size)
print(len(ary))# 输出
# [1 2 3 4 5 6 7 8]
# (8,)
# 8
# 8
# (2, 4)
# 8
# 2
size是指数组元素的个数,一维数组的len和size是一样的,二多维数组则不一样,在二维数组时,size是指二维数组中第二维度的个数。
4. 数组元素索引
import numpy as npary = np.arange(1, 9)
ary.shape = (2, 2, 2)
print(ary)print(ary[0]) # 访问三维数组的第一个二维数组
print(ary[0][0]) # 访问二维数组的第一一维数组
print(ary[0][0][0]) # 访问一维数组的第一个元素print(ary[0,0,0]) # numpy的全新写法# 输出# [[[1 2]
# [3 4]]
#
# [[5 6]
# [7 8]]]# [[1 2]
# [3 4]]# [1 2]# 1# 1
5. Numpy内部基本数据类型

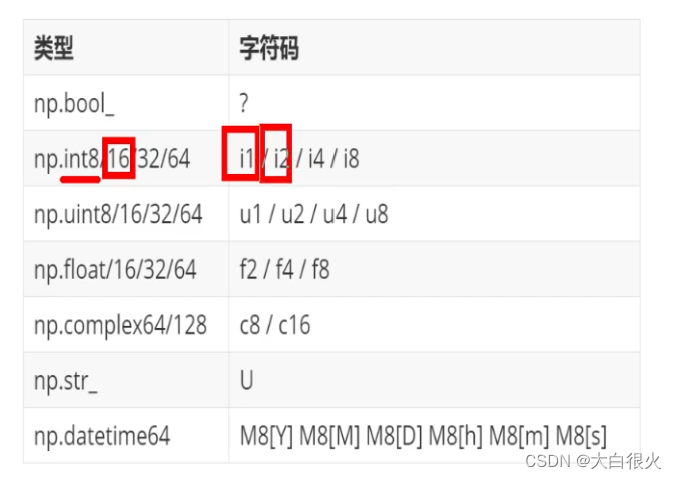
5.1 基本数据类型简写的应用案例
import numpy as npdata = [('zs', [100, 90, 95], 18),('ls', [100, 95, 93], 22),('ww', [98, 98, 98], 20)]print(data)ary = np.array(data)
print(ary)ary = np.array(data, dtype='U2, 3int8, int8')
print(ary)
5.2 将列表强转为数组
方式1 通过字符串的方式指定dtype(不常用)
import numpy as npdata = [('zs', [100, 90, 95], 18),('ls', [100, 95, 93], 22),('ww', [98, 98, 98], 20)]ary = np.array(data, dtype='U2, 3int8, int8')sum = 0
for i in data:sum = i[2]+sum
print(sum/3)print(ary['f2'].mean())
以上代码使用2种方式求年龄的平均值
方式2:通过列表套元组(不常用)
import numpy as np
import warnings
warnings.filterwarnings('ignore')data = [('zs', [100, 90, 95], 18),('ls', [100, 95, 93], 22),('ww', [98, 98, 98], 20)]# print(data)ary = np.array(data)
# print(ary)ary = np.array(data, dtype=[('name', 'str', 2),('score', 'int32', 3),('age', 'int32', 1)])
print(ary['score'].mean())
# 输出
# 20
方式3:通过字典的固定键设置dtype
import numpy as np
import warnings
warnings.filterwarnings('ignore')data = [('zs', [100, 90, 95], 18),('ls', [100, 95, 93], 22),('ww', [98, 98, 98], 20)]# print(data)ary = np.array(data)
# print(ary)ary = np.array(data, dtype={'names': ['name', 'score', 'age'], 'formats': ['U2', '3int32', 'int32']})print(ary['age'])
# 输出
# [18 22 20]5.3 datetime64
import numpy as np
import warnings
warnings.filterwarnings('ignore')data = np.array(['2011', '2012-12-12', '2023-02-13 08:08:08'])# 将字符串转成时间日期(精确到日)类型
pretty_data = data.astype("datetime64[D]")
print(pretty_data)# 转成整形
res = pretty_data.astype('int64')
print(res) # 返回距1970年1月1日的天数# 将字符串转成时间日期(精确到秒)类型
pretty_data = data.astype("datetime64[s]")
print(pretty_data)# 转成整形
res = pretty_data.astype('int64')
print(res) # 返回距1970年1月1日的秒数# 输出# ['2011-01-01' '2012-12-12' '2023-02-13']# [14975 15686 19401]# ['2011-01-01T00:00:00' '2012-12-12T00:00:00' '2023-02-13T08:08:08']# [1293840000 1355270400 1676275688]
numpy的日期格式要求严格
字符串的格式不能形如2021-1-1也不能形如2021/01/01
6. ndarray数组维度操作
容器:酒瓶 元素:酒
赋值拷贝:酒瓶装旧酒
浅拷贝:新瓶装旧酒
深拷贝:新瓶装新酒
6.1 视图变维(数据共享):reshape()与ravel()
import numpy as np
import warnings
warnings.filterwarnings('ignore')ary = np.arange(1, 9)
print(ary)
# 视图变维
bry = ary.reshape(2, 4)
print(bry)
print(ary)
ary[0] = 123
print("修改后的ary:", ary)
print("bry:", bry)
# 输出
# [1 2 3 4 5 6 7 8]
# [[1 2 3 4]
# [5 6 7 8]]
# [1 2 3 4 5 6 7 8]
# 修改后的ary: [123 2 3 4 5 6 7 8]
# bry: [[123 2 3 4]
# [ 5 6 7 8]]
只是形状发生了改变,修改了原始数据,变维后的数据跟着变,这就是所谓的
数据共享
变维后的数据虽然在形状上发生了变化,但不影响变维前的数据
ravel将数组(不管几维)拉伸为1维
6.2 赋值变维(数据独立)
import numpy as np
import warnings
warnings.filterwarnings('ignore')ary = np.arange(1, 9).reshape(2, 4)
print(ary)bry = ary.flatten()
print(bry)ary[0] = 666
print(ary)print(bry)# 输出
# [[1 2 3 4]# [5 6 7 8]]# [1 2 3 4 5 6 7 8]# [[666 666 666 666]
# [ 5 6 7 8]]# [1 2 3 4 5 6 7 8]
6.3 就地变维:直接改变原数组的维度,不返回新数组
import numpy as np
import warnings
warnings.filterwarnings('ignore')ary = np.arange(1, 9)
ary.resize(2, 2, 2)
print(ary)ary = np.arange(1, 9)
ary.resize(2, 2, 2)
print(ary)
7. ndarray数组切片操作
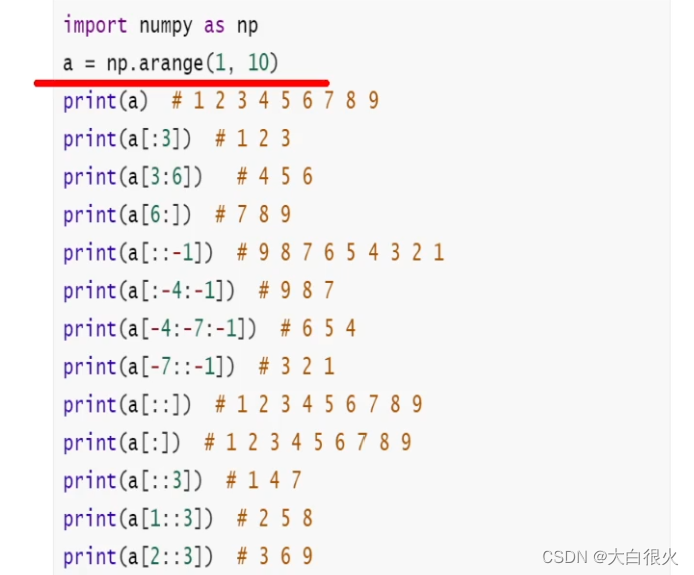
7.1 一维数组切片
数组对象切片的参数设置与列表切片参数类似
步长+:默认切从首到尾
步长-:默认切从尾到头
数组对象[起始位置:终止位置:步长,…]
默认步长:1
7.2 多维数组切片
import numpy as np
import warnings
warnings.filterwarnings('ignore')ary = np.arange(1, 9)
ary.resize(3,3)
print(ary)
print(ary[:2]) # 前两行
print(ary[:2, :2]) # 前两行的前两列
print(ary[::2, ::2]) # 1 3行,1 3列# 输出
# [[1 2 3]
# [4 5 6]
# [7 8 0]]
# [[1 2 3]
# [4 5 6]]
# [[1 2]
# [4 5]]
# [[1 3]
# [7 0]]import numpy as np
import warnings
warnings.filterwarnings('ignore')ary =np.arange(1, 101).reshape(20, 5)
print(ary)
# 所有行不要最后一列
print("所有行不要最后一列")
print(ary[:, :-1])
# 所有行只要最后一列
print(ary[:, -1])
7.3 ndarray数组的掩码操作
布尔掩码
import numpy as np
import warnings
warnings.filterwarnings('ignore')ary = np.arange(1, 10)
mask = [True, False, True, True, False, True, True, True, False]
res = ary[mask]
print(res)# 输出
# [1 3 4 6 7 8]
布尔掩码操作案例:求100以内3的倍数的数字
import numpy as np
import warnings
warnings.filterwarnings('ignore')ary = np.arange(1, 101)
print(ary[ary % 3 == 0])标签掩码:掩码数组中为索引值
import numpy as np
import warnings
warnings.filterwarnings('ignore')car = np.array(['bwm', 'benzi', 'audi', 'hongqi'])
mask = [0, 2, 1, 3]
res = car[mask]
print(res)
mask = [0, 0, 0, 0, 0, 2, 1, 1, 1, 1, 1, 1, 3]
res = car[mask]
print(res)# 输出
# ['bwm' 'audi' 'benzi' 'hongqi']
# ['bwm' 'bwm' 'bwm' 'bwm' 'bwm' 'audi' 'benzi' 'benzi' 'benzi' 'benzi' 'benzi' 'benzi' 'hongqi']
7.4 多维数组的组合与拆分
stack and split
垂直方向 vstack vsplit
水平方向 hstack hsplit
深度方向 dstack dsplit
import numpy as npary = np.arange(1, 7).reshape(2, 3)
bry = np.arange(7, 13).reshape(2, 3)
res = np.dstack((ary, bry))
print(ary)
print(bry)
print(res)
print(res.shape)print("-"*30)ary, bry = np.dsplit(res, 2)
print(ary)
print(bry)# 输出
[[1 2 3][4 5 6]]
[[ 7 8 9][10 11 12]]
[[[ 1 7][ 2 8][ 3 9]][[ 4 10][ 5 11][ 6 12]]]
(2, 3, 2)
------------------------------
[[[1][2][3]][[4][5][6]]]
[[[ 7][ 8][ 9]][[10][11][12]]]
三维数组拆分后依然是3维数组,想变成2维只能采用变维的方式。
concatenate
若待组合的数组都是二维数组:
0:垂直方向组合
1:水平方向组合
若待组合的数组都是三维数组:
0:垂直方向组合
1:水平方向组合
2:深度方向组合
np.concatenate((a,b),axis=0)
通过给出的数组与要拆分的份数,按照某个方向进行拆分,axis的取值同上
np.split(c,2,axis=0)
长度不等的数组组合
先填充,再组合
简单一维数组组合方案
a = np.arange(1,9)
b = np.arange(9,17)#把两个数组摞在一起成两行
c = np.row_stack((a,b))
print(c)#把两个数组组合在一起成两列
d = np.column_stack((a,b))
print(d)
ndarray类的其他属性
- shape-维度
- dtype-元素类型
- size-元素数量
- ndim-维数,len(shape)
- itemsize-元素字节数
- nbytes -总字节数= size x itemsize
- real-复数数组的实部数组
- imag-复数数组的虚部数组
- T-数组对象的转置视图
- flat-扁平选代器
相关文章:
Numpy基础与实例——人工智能基础
文章目录一、Numpy概述1. 优势2. numpy历史3. Numpy的核心:多维数组4. 内存中的ndarray对象4.1 元数据(metadata)4.2 实际数据二、numpy基础1. ndarray数组2. arange、zeros、ones、zeros_like3. ndarray对象属性的基本操作3.1 修改数组维度3…...

MQTT的工作原理
介绍MQTT协议的消息模型,消息传输过程,消息发布和订阅。 一、介绍MQTT协议的消息模型 MQTT协议的消息模型被称为“主题”模型。在这种模型中,服务器接收到的消息将通过主题进行分类。客户端可以通过订阅一个或多个主题来接收所需的消息。 1.1 消息主题 1.2 消息内容 1.…...

iOS开发:UINavigationController自定义返回按钮,系统导航支持侧滑返回
当你使用系统导航想拦截用户返回事件时,无法拦截侧滑返回 当你自定义导航或者隐藏导航后,iOS系统导航的侧滑返回就失效了,那么用户体验将大打折扣 网上大部分自定义导航的解决方案是:给页面添加全局的轻扫手势,那么又区别于原生系统,改变了用户的操作习惯 在开发过程中,…...
【Kafka进阶】-- unclean.leader.election.enable参数的内涵
一、背景近期,我们的kafka 消息队列集群(1.x版本)经过了一次事故。某节点意外宕机,导致 log 文件损坏,重启 kafka 失败,最后导致某个 topic 的分区不可用,本文对此做了简单的分析、解决和复现参考,以此为记…...
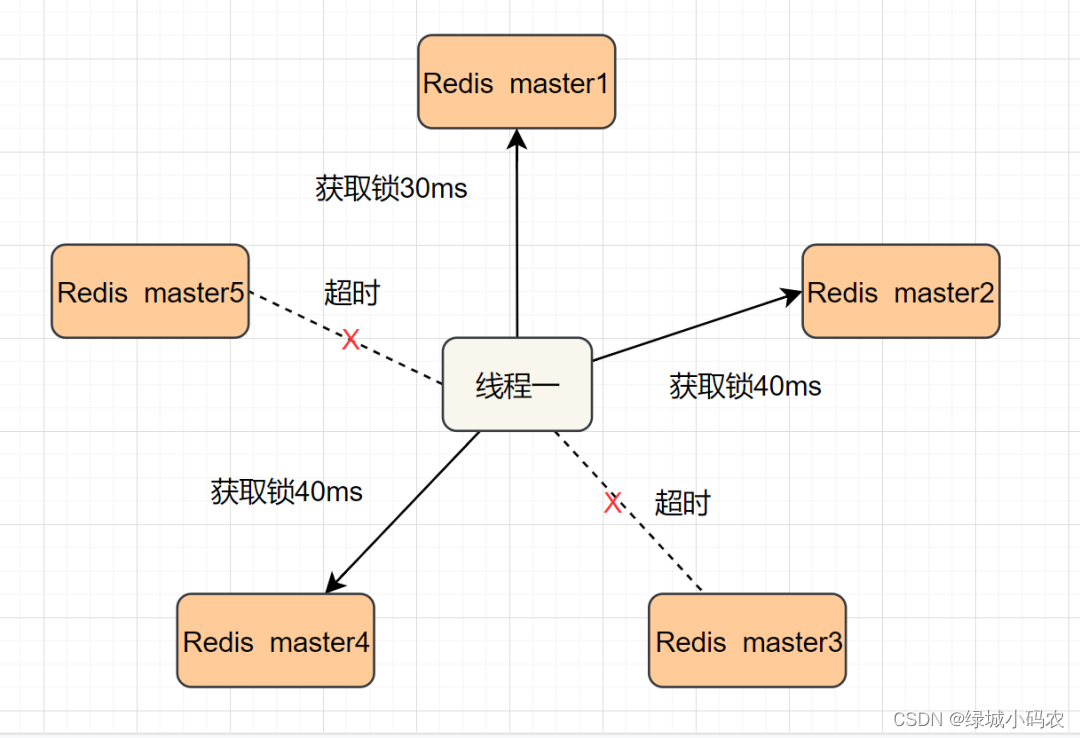
基于redis实现分布式锁
前言 我们的系统都是分布式部署的,日常开发中,秒杀下单、抢购商品等等业务场景,为了防⽌库存超卖,都需要用到分布式锁。 分布式锁其实就是,控制分布式系统不同进程共同访问共享资源的一种锁的实现。如果不同的系统或…...

C#开发的OpenRA动态加载插件DLL里的类实现
C#开发的OpenRA动态加载插件DLL里的类实现 由于这款游戏的设计是为了开源设计, 并且可以让不同个人或团体实现自己的游戏, 那么每个人实现的代码是不一样的,算法也是不一样的。 并且可能也拿不到代码一起编译生成一套运行的代码。 这时候,就要考虑使用动态加载类的功能。 意…...

网站代理是什么?有什么需要注意的?
如今,网站代理已经成为一种不可或缺的经营方式。无论是企业还是个人,都需要通过代理来获得更多的流量和市场份额。 一、网站代理的优势 网站代理的优势在于能够为您提供更加专业、周到的服务。这些优势包括:1.丰富的内容资源,能…...

动态库和静态库的区别
什么是库文件 一般来说,一个程序,通常都会包含目标文件和若干个库文件。经过汇编得到的目标文件再经过和库文件的链接,就能构成可执行文件。库文件像是一个代码仓库或代码组件的集合,为目标文件提供可直接使用的变量、函数、类等…...

C/C++路径去除前缀
在做一些日志输出的工作时,想要获取当前文件名,而不是冗长的文件路径。路径获取往往和各家os底层函数优化。C/C标准中定义了一些预处理宏,可以帮助我们获取文件路径。我们希望能够在编译期而不是在运行期做这个事情,避免额外的性能…...

Vue2之Vue-cli应用及组件基础认识
Vue2之Vue-cli应用及组件基础认识一、Vue-cli1、单页面应用程序2、vue-cli介绍3、安装和使用4、创建项目4.1 输入创建项目4.2 选择第三项,进行自主配置,按回车键即可4.3 选择自己需要的库4.4 选择Vue的版本4.5 选择CSS选择器4.6 选择Babel、ESLint、etc等…...

C 学习笔记 —— 声明、定义、初始化
文章目录声明定义初始化定义和初始化的区别静态变量初始化自动变量初始化声明 说明符表达式列表 int a; char j, k l;定义 一般的情况下,我们把建立空间的声明称之为定义,而把不需要建立存储空间的声明称之为声明。 int tern 1; //定义int main() {…...
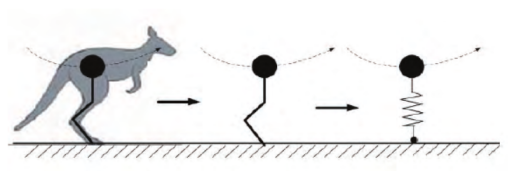
机械狗控制算法
一. MIT Cheetah特点 1.驱动器 Cheetah 2采用了定制的本体感受驱动器设计,具有高冲击缓解、力控制和位置控制能力。这种设计使其能够自主跳过障碍物,并以6m/s的高速跳跃,但其运动范围有限,只能进行矢状面运动。 Cheetah 3采用高扭…...
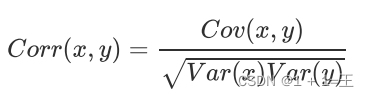
向量与矩阵 导数和偏导数 特征值与特征向量 概率分布 期望方差 相关系数
文章目录向量与矩阵标量、向量、矩阵、张量向量范数和矩阵的范数导数和偏导数特征值和特征向量概率分布伯努利分布正态分布(高斯分布)指数分布期望、⽅差、协⽅差、相关系数期望方差协⽅差相关系数向量与矩阵 标量、向量、矩阵、张量 标量(…...

记录--前端实现登录拼图验证
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前言 不知各位朋友现在在web端进行登录的时候有没有注意一个变化,以前登录的时候是直接账号密码通过就可以直接登录,再后来图形验证码,数字结果运算验证,…...
)
【Go语言基础】Go语言中的map集合详细使用(附带源码)
文章目录Go语言中的map集合1-1 定义1-2 map遍历1-3 map集合删除1-4 map是引用类型Go语言中的map集合 Go 语言提供了内置类型 map集合,它将一个值与一个键关联起来,可以使用相应的键检索值。 map是一种集合,可以像遍历数组或切片那样去遍历它…...
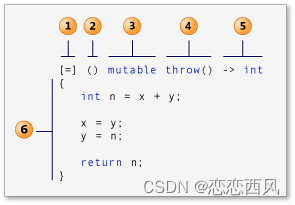
C++11 lambda
Lambda 介绍 Lambda 函数也叫匿名函数, 是C 11中新增的特性; 1. Lambda函数的好处 如果你的代码里面存在大量的小函数,而这些函数一般只被调用一次,那么将他们重构成 lambda 表达式。 Lambda函数使代码变得更加紧凑、更加结构化和更富有表现…...
)
【新】华为OD机试 - 分苹果(Python)
分苹果 题目 AB两个人把苹果分为两堆 A希望按照他的计算规则等分苹果 他的计算规则是按照二级制加法计算 并且不计算进位12+5=9(1100+0101=9), B的计算规则是十进制加法, 包括正常进位,B希望在满足A的情况下获取苹果重量最多 输入苹果的数量和每个苹果重量 输出满足A的情况下…...

Python 模块
Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句。 模块让你能够有逻辑地组织你的 Python 代码段。 把相关的代码分配到一个模块里能让你的代码更好用,更易懂。 模块能定义函数&#…...

gdb调试功能从零到会(Linux详解)
目录 👀 1.安装gdb 👀2.判断是否安装成功 👀3.改成debug方式发布。 👀 4.gdb功能简介 前言 gdb是Linux 下功能全面的调试工具。gdb支持断点、单步执行、打印变量、观察变量、查看寄存器、查看堆栈等调试手段。在Linux环境软件…...
【C语言学习笔记】:数组、指针相关面试题
无特殊说明情况下,下面所有题s目都是linux下的32位C程序。 「1、计算以下sizeof的值。」 char str1[] {a, b, c, d, e}; char str2[] "abcde";char *ptr "abcde";char book[][80]{"计算机应用基础","C语言","C程…...

动态电源路径管理技术解析与工程实践
1. 动态电源路径管理技术解析在便携式电子设备设计中,电源管理系统如同人体的血液循环系统,需要精确调控能量分配。动态电源路径管理(DPPM)技术的核心在于实现三个关键目标:优先保障系统负载供电、动态调节充电电流、最…...

开源首发:DocCenter — AI 时代的 HTML工作台深度解析
Tags:Python aiohttp 开源项目 AI工具 前端工程 工具分享 Claude ChatGPT 专栏:「工具开源」/「DocCenter」 一、痛点:AI 时代的文档散落病 过去一年,我每天被 AI 生成的 HTML 文件淹没。 Claude artifacts 一天 20 个、ChatGPT…...
)
别再熬夜改答辩 PPT 了!okbiye AI PPT,4 步搞定学术演示稿(附保姆级操作指南)
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPTAI PPT制作 - Okbiye智能写作https://www.okbiye.com/ppt 作为一名被毕业答辩 PPT 折磨过两次的过来人,我太懂那种痛苦了:对着几万字的论文,不知道怎么浓缩成十几页 …...

智能算法车队换道决策与轨迹规划【附仿真】
✨ 长期致力于车队换道、支持向量机、决策树、换道决策、多目标优化研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)NGSIM数据清洗与特征重构…...

基于AutoHotkey v2的Cursor AI编程效率工具:CapsLock快捷键方案详解
1. 项目概述:当CapsLock键成为你的AI编程副驾如果你是一名Windows用户,同时又是Cursor编辑器的深度使用者,那么你很可能和我一样,每天都在重复着一些机械操作:选中代码、复制、切换到AI聊天框、粘贴、再敲入一段提示词…...

Sutton《苦涩的教训》早已预言:一切**人工精巧设计的专用智能系统**,终将被算力与数据驱动的通用范式无情取代
《The Bitter Lesson》《苦涩的教训》3条极简核心背诵版 人类总爱把领域知识、手工设计、精巧架构塞进AI,短期有用,长远全没用。AI 历史规律:通用规模化(算力数据大模型)永远碾压 人工定制智能小系统。未来趋势&#x…...

深度解析Deep3D:专业级实时2D转3D视频转换技术实战指南
深度解析Deep3D:专业级实时2D转3D视频转换技术实战指南 【免费下载链接】Deep3D Real-Time end-to-end 2D-to-3D Video Conversion, based on deep learning. 项目地址: https://gitcode.com/gh_mirrors/dee/Deep3D Deep3D是一款基于深度学习的开源2D转3D视频…...

一滴血预警眼底病变!NFL 全程评估糖尿病视网膜病变
核心结论:本研究通过眼内液与血浆多组学联合分析,证实神经丝轻链(NFL)是可通过血浆微创检测、覆盖糖尿病视网膜病变全病程的保守生物标志物,能有效预测发病及糖尿病血管并发症风险。一、研究概况该研究发表于糖尿病领域…...

私域团队如何用企业微信 API 提升客户维护效率?
一、 场景描述:为什么你的团队每天都在“瞎忙”? 很多私域团队看似忙碌,实则效率低下。典型的现象包括: • 重复回答:每天 70% 的时间在复制粘贴相同的话术(如:发货时间、优惠券怎么领ÿ…...

量子退火在锂离子电池材料优化中的应用与原理
1. 量子退火技术原理与材料优化应用概述量子退火(Quantum Annealing)是一种基于量子力学原理的优化算法,它通过模拟量子系统的绝热演化过程来寻找复杂问题的全局最优解。与传统模拟退火算法相比,量子退火利用量子隧穿效应而非热涨…...