Python 之 NumPy 随机函数和常用函数
文章目录
- 一、随机函数
- 1. numpy.random.rand(d0,d1,…,dn)
- 2. numpy.random.randn(d0,d1,…,dn)
- 3. numpy.random.normal()
- 4. numpy.random.randint()
- 5. numpy.random.sample
- 6. 随机种子np.random.seed()
- 7. 正态分布 numpy.random.normal
- 二、数组的其他函数
- 1. numpy.resize()
- 2. numpy.append()
- 3. numpy.insert()
- 4. numpy.delete()
- 5. numpy.argwhere()
- 6. numpy.unique()
- 7. numpy.sort()
- 8. numpy.argsort()
- 最开始,我们先导入 numpy 库。
import numpy as np
一、随机函数
- NumPy 中也有自己的随机函数,包含在 random 模块中。它能产生特定分布的随机数,如正态分布等。
- 接下来介绍一些常用的随机数。
| 函数名 | 功能 | 参数使用(int a,b,c,d) |
|---|---|---|
| rand(int1,[int2,[int3,]]) | 生成(0,1)均匀分布随机数 | (a),(a,b),(a,b,c) |
| randn(int1,[int2,[int3,]]) | 生成标准正态分布随机数 | (a),(a,b),(a,b,c) |
| randint(low[,hight,size,dtype]) | 生成随机整数 | (a,b),(a,b,c),(a,b,(c,d)) |
| sample(size) | 生成[0,1)随机数 | (a),((a,b)),((a,b,c)) |
1. numpy.random.rand(d0,d1,…,dn)
- rand 函数根据给定维度生成 [0,1) 之间的数据,包含 0,不包含 1。
- dn 表示每个维度。
- 返回值为指定维度的 array。
- 我们可以创建 4 行 2 列的随机数据。
np.random.rand(4,2)
#array([[0.02533197, 0.80477348],
# [0.85778508, 0.01261245],
# [0.04261013, 0.26928786],
# [0.81136377, 0.34618951]])
- 我们也可以创建 2 块 2 行 3 列的随机数据。
np.random.rand(2,2,3)
#array([[[0.01820147, 0.5591452 , 0.05975028],
# [0.09208771, 0.96067587, 0.87031724]],
#
# [[0.32644706, 0.9580549 , 0.94756885],
# [0.57613453, 0.59642938, 0.62449385]]])
2. numpy.random.randn(d0,d1,…,dn)
- randn 函数返回一个或一组样本,具有标准正态分布。
- dn 表示每个维度。
- 返回值为指定维度的 array。
- 标准正态分布又称为 u 分布,是以 0 为均值、以 1 为标准差的正态分布,记为 N(0,1)。
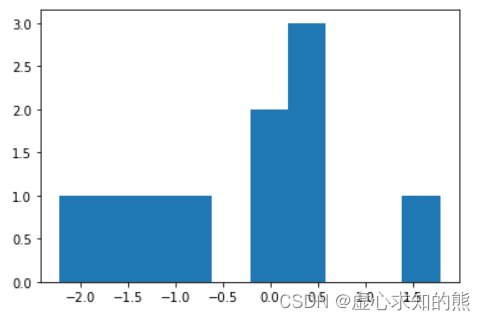
- 我们随机生成满足标准正态分布的 10 个数据,并使用 matplotlib 绘图工具将其绘制出来。
from matplotlib import pyplot as plt
a = np.random.randn(10)
print(a)
plt.hist(a)
#[ 0.42646668 -1.40306793 -0.05431918 0.03763756 1.7889215 0.25540288
# -1.60619811 -2.21199667 -0.92209721 0.47669523]
#(array([1., 1., 1., 1., 0., 2., 3., 0., 0., 1.]),
# array([-2.21199667, -1.81190485, -1.41181303, -1.01172122, -0.6116294 ,
# -0.21153758, 0.18855423, 0.58864605, 0.98873787, 1.38882969,
# 1.7889215 ]),
3. numpy.random.normal()
numpy.random.normal(loc=0.0, scale=1.0, size=None)
- numpy.random.normal 返回一个由 size 指定形状的数组,数组中的值服从 μ=loc,σ=scale 的正态分布。
4. numpy.random.randint()
numpy.random.randint(low, high=None, size=None, dtype=’l’)
- 返回随机整数,范围区间为 [low,high),包含 low,不包含 high。
- 其参数含义为,low 表示最小值,high 表示最大值,size 表示数组维度大小,dtype 表示数据类型,默认的数据类型是 np.int。
- 当 high 没有填写时,默认生成随机数的范围是 [0,low)。
- 例如,我们可以返回 [0,1) 之间的整数,所以只有 0,由于默认数据类型是 int,因此,我们不需要填写数据类型参数。
np.random.randint(1,size=5)
#array([0, 0, 0, 0, 0])
- 同理,我们也可以返回 [2,10) 之间的整数。
np.random.randint(2,10,size=5)
#array([7, 6, 7, 8, 3])
- 我们可以在返回 [2,10) 之间整数的基础上,将返回的维度设置为二维。
np.random.randint(2,10,size=(2,5))
#array([[7, 7, 2, 7, 4],
# [5, 8, 6, 9, 7]])
- 当我们不设置维度参数时,就是默认返回一行一列。例如,我们返回 1 个 [1,5) 之间的随机整数。
np.random.randint(1,5)
#2
- np.random.randint 随机函数对负数也同样生效。例如,我们返回 -5 到 5 之间不包含 5 的 2 行 2 列数据。
np.random.randint(-5,5,size=(2,2))
#array([[-4, -5],
# [ 1, 3]])
5. numpy.random.sample
numpy.random.sample(size=None)
- 返回半开区间内的随机浮点数 [0.0,1.0]。
np.random.sample((2,3))
np.random.sample((2,2,3))
#array([[[0.7686855 , 0.70071112, 0.24265062],
# [0.63907407, 0.76102216, 0.66424632]],
#
# [[0.40679315, 0.73614372, 0.64102261],
# [0.97843216, 0.52552309, 0.44970841]]])
Type Markdown and LaTeX: α2
6. 随机种子np.random.seed()
- 使用相同的 seed() 值,则每次生成的随机数都相同,使得随机数可以预测。
- 但是,只在调用的时候 seed() 一下子并不能使生成的随机数相同,需要每次都调用一下 seed(),表示种子相同,从而生成的随机数相同。
- 如下例子,当我们设置两个随机数种子,就会返回两个不一样的数组。
np.random.seed(2)
L1 = np.random.randn(3, 3)
L2 = np.random.randn(3, 3)
print(L1)
print("-"*10)
print(L2)
#[[-0.41675785 -0.05626683 -2.1361961 ]
# [ 1.64027081 -1.79343559 -0.84174737]
# [ 0.50288142 -1.24528809 -1.05795222]]
----------
#[[-0.90900761 0.55145404 2.29220801]
# [ 0.04153939 -1.11792545 0.53905832]
# [-0.5961597 -0.0191305 1.17500122]]
- 但是,当我们只生产一个随机数种子时,那么,返回的两个数组就会产生一模一样的数据。
np.random.seed(1)
L1 = np.random.randn(3, 3)
np.random.seed(1)
L2 = np.random.randn(3, 3)
print(L1)
print("-"*10)
print(L2)
#[[ 1.62434536 -0.61175641 -0.52817175]
# [-1.07296862 0.86540763 -2.3015387 ]
# [ 1.74481176 -0.7612069 0.3190391 ]]
#----------
#[[ 1.62434536 -0.61175641 -0.52817175]
# [-1.07296862 0.86540763 -2.3015387 ]
# [ 1.74481176 -0.7612069 0.3190391 ]]
7. 正态分布 numpy.random.normal
numpy.random.normal(loc=0.0, scale=1.0, size=None)
- 它的作用是返回一个由 size 指定形状的数组,数组中的值服从 μ=loc,σ=scale 的正态分布。
- 其参数含义如下所示:
- loc : float 型或者 float 型的类数组对象,指定均值 μ。
- scale : float 型或者 float 型的类数组对象,指定标准差 σ。
- size : int 型或者 int 型的元组,指定了数组的形状。如果不提供 size,且 loc 和 scale 为标量(不是类数组对象),则返回一个服从该分布的随机数。
- 例如,我们返回两个正态分布的数组,均为 3 行 2 列,但是他们的均值和标准差不同,第一个返回数组的均值是 0,标准差是 1;第二个返回数组的均值是 1,标准差是 3。
a = np.random.normal(0, 1, (3, 2))
print(a)
print('-'*20)
b = np.random.normal(1, 3, (3, 2))
print(b)
#[[-0.26905696 2.23136679]
# [-2.43476758 0.1127265 ]
# [ 0.37044454 1.35963386]]
#--------------------
#[[ 2.50557162 -1.53264111]
# [ 1.00002928 2.62705772]
# [ 0.05947541 3.31303521]]
二、数组的其他函数
- 主要有以下方法:
| 函数名称 | 描述说明 |
|---|---|
| resize | 返回指定形状的新数组。 |
| append | 将元素值添加到数组的末尾。 |
| insert | 沿规定的轴将元素值插入到指定的元素前。 |
| delete | 删掉某个轴上的子数组,并返回删除后的新数组。 |
| argwhere | 返回数组内符合条件的元素的索引值。 |
| unique | 用于删除数组中重复的元素,并按元素值由大到小返回一个新数组。 |
| sort() | 对输入数组执行排序,并返回一个数组副本 |
| argsort | 沿着指定的轴,对输入数组的元素值进行排序,并返回排序后的元素索引数组 |
1. numpy.resize()
numpy.resize(arr, shape)
- numpy.resize() 可以返回指定形状的新数组。
- 这里我们需要注意的是,numpy.resize(arr,shape) 和 ndarray.resize(shape, refcheck=False) 的区别:
- (1) numpy.resize(arr,shape),有返回值,返回复制内容。如果维度不够,会使用原数组数据补齐。
- (2) ndarray.resize(shape, refcheck=False),修改原数组,不会返回数据。如果维度不够,会使用 0 补齐。
- 具体可见如下示例:
- 首先,我们生成一个指定元素的数组,并输出该数组和数组的形状。
a = np.array([[1,2,3],[4,5,6]])
print('a数组:',a)
print('a数组形状:',a.shape)
#3a数组: [[1 2 3]
# [4 5 6]]
#a数组形状: (2, 3)
- 然后,我们使用 numpy.resize 将 a 数组改变成 3 行 3 列的数组(如果维度不够,会使用原数组数据补齐)。
b = np.resize(a,(3,3))
b
#array([[1, 2, 3],
# [4, 5, 6],
# [1, 2, 3]])
- 此时,我们再次输出 a 数组。
a
#array([[1, 2, 3],
# [4, 5, 6]])
- 然后,我们使用 ndarray.resize(a.resize)将 a 数组改变成 3 行 3 列的数组(如果维度不够,会使用 0 补齐)。
a.resize((3,3),refcheck=False)
a
#array([[1, 2, 3],
# [4, 5, 6],
# [0, 0, 0]])
- 此时,a 数组的原本数据已经进行了修改,在此便不进行演示。
2. numpy.append()
- 它的作用是在数组的末尾添加值,默认返回一个一维数组。
numpy.append(arr, values, axis=None)
- 其参数具有如下含义:
- arr:输入的数组。
- values:向 arr 数组中添加的值,需要和 arr 数组的形状保持一致。
- axis:默认为 None,返回的是一维数组;当 axis=0 时,追加的值会被添加到行,而列数保持不变,若 axis=1 则与其恰好相反。
- 具体可见如下示例:
- 首先,我们生成一个指定元素的数组,并向该数组添加元素。
a = np.array([[1,2,3],[4,5,6]])
print (np.append(a, [7,8,9]))
#[1 2 3 4 5 6 7 8 9]
- 我们可以沿轴 0 添加元素。
print (np.append(a, [[7,8,9]],axis = 0))
#[[1 2 3]
# [4 5 6]
# [7 8 9]]
- 我们也可以沿轴 1 添加元素。
print (np.append(a, [[5,5,5],[7,8,9]],axis = 1))
#[[1 2 3 5 5 5]
# [4 5 6 7 8 9]]
3. numpy.insert()
- 该函数表示沿指定的轴,在给定索引值的前一个位置插入相应的值,如果没有提供轴,则输入数组被展开为一维数组。
numpy.insert(arr, obj, values, axis)
- 其参数具有如下含义:
- arr:要输入的数组。
- obj:表示索引值,在该索引值之前插入 values 值。
- values:要插入的值。
- axis:指定的轴,如果未提供,则输入数组会被展开为一维数组。
- 具体可见如下示例:
- 我们生成一个指定元素的数组,并不提供axis的情况。
a = np.array([[1,2],[3,4],[5,6]])
print (np.insert(a,3,[11,12]))
#[ 1 2 3 11 12 4 5 6]
- 我们可以沿轴 0 将元素插入到行。
print (np.insert(a,1,[11],axis = 0))
#[[ 1 2]
# [11 11]
# [ 3 4]
# [ 5 6]]
- 我们也可以沿轴 1 将元素插入到列。
print (np.insert(a,1,11,axis = 1))
#[[ 1 11 2]
# [ 3 11 4]
# [ 5 11 6]]
4. numpy.delete()
- numpy.delete() 表示从输入数组中删除指定的子数组,并返回一个新数组。
- 它与 insert() 函数相似,若不提供 axis 参数,则输入数组被展开为一维数组。
numpy.delete(arr, obj, axis)
- 其参数具有如下含义:
- arr:要输入的数组;
- obj:整数或者整数数组,表示要被删除数组元素或者子数组;
- axis:沿着哪条轴删除子数组。
- 具体可见如下示例:
- 我们生成一个指定元素的数组,并不提供axis的情况,是删除指定数组元素。
a = np.arange(12).reshape(3,4)
print(a)
print(np.delete(a,5))
#[[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
#[ 0 1 2 3 4 6 7 8 9 10 11]
- 我们可以删除第二列,但注意需要将 axis 参数设置为 1,表示沿列方向进行删除。
- 我们也可以将 axis 参数设置为 0,沿行方向进行多行元素删除操作。
- 这里需要注意的是,不可以使用切片的形式。
print(np.delete(a,1,axis = 1))
print(a)
print(np.delete(a,[1,2],axis = 0))
#[[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
#[[0 1 2 3]]
5. numpy.argwhere()
- numpy.argwhere()返回数组中非 0 元素的索引,若是多维数组则返回行、列索引组成的索引坐标。
- 具体可见如下示例:
- 我们生成一个指定元素的数组,并将其输出。
x = np.arange(6).reshape(2,3)
x
#array([[0, 1, 2],
# [3, 4, 5]])
- 然后,返回所有大于 1 的元素索引。
print(x)
y=np.argwhere(x>1)
print("-"*10)
print(y,y.shape)
#[[0 1 2]
# [3 4 5]]
#----------
#[[0 2]
# [1 0]
# [1 1]
# [1 2]] (4, 2)
6. numpy.unique()
- numpy.unique() 用于删除数组中重复的元素。
numpy.unique(arr, return_index, return_inverse, return_counts)
- 其参数具有如下含义:
- arr:输入数组,若是多维数组则以一维数组形式展开。
- return_index:如果为 True,则返回新数组元素在原数组中的位置(索引)。
- return_inverse:如果为 True,则返回原数组元素在新数组中的位置(索引)。
- return_counts:如果为 True,则返回去重后的数组元素在原数组中出现的次数。
- 具体可见如下示例:
- 我们先生成一个指定元素的数组,并将其输出。
- 然后,使用 numpy.unique() 对其进行去重操作,并将其输出,便于比对观察。
a = np.array([5,2,6,2,7,5,6,8,2,9])
print (a)
uq = np.unique(a)
print(uq)
#[5 2 6 2 7 5 6 8 2 9]
#[2 5 6 7 8 9]
- 我们可以获取数组去重后的索引数组,并打印去重后数组的索引。
print("a:",a)
u,indices = np.unique(a, return_index = True)
print(u)
print('-'*20)
print(indices)
#a: [5 2 6 2 7 5 6 8 2 9]
#[2 5 6 7 8 9]
#--------------------
#[1 0 2 4 7 9]
- 我们也可以获取去重数组的下标,并打印其下标。
ui,indices = np.unique(a,return_inverse = True)
print (ui)
print('-'*20)print (indices)
print("a:",a)
#[2 5 6 7 8 9]
#--------------------
#[1 0 2 0 3 1 2 4 0 5]
- 我们可以知道去重元素的重复数量,也就是该去重元素的出现次数。
uc,indices = np.unique(a,return_counts = True)
print (uc)
print (indices)
#a: [5 2 6 2 7 5 6 8 2 9]
#[2 5 6 7 8 9]
#[3 2 2 1 1 1]
7. numpy.sort()
- numpy.sort() 表示对输入数组执行排序,并返回一个数组副本。
numpy.sort(a, axis, kind, order)
- 其参数具有如下含义:
- a:要排序的数组。
- axis:沿着指定轴进行排序,如果没有指定 axis,默认在最后一个轴上排序,若 axis=0 表示按列排序,axis=1 表示按行排序。
- kind:默认为 quicksort(快速排序)。
- order:若数组设置了字段,则 order 表示要排序的字段。
- 具体可见如下示例:
- 我们先生成一个指定元素的数组,并将其输出,然后调用 sort() 函数对其进行排序并输出排序后的数组。
- 最后,输出原数组,发现并没有发生改变,说明 sort() 函数不会对原数组内的元素进行修改。
a = np.array([[3,7,5],[6,1,4]])
print('a数组是:', a)
print('排序后的内容:',np.sort(a))
a
#a数组是: [[3 7 5]
# [6 1 4]]
#排序后的内容: [[3 5 7]
# [1 4 6]]
#array([[3, 7, 5],
# [6, 1, 4]])
- 我们可以以行为参照,列上面的数据排序:
print(np.sort(a, axis = 0))
#[[3 1 4]
# [6 7 5]]
- 我们也可以以列为参照,行上面的数据排序:
print(np.sort(a, axis = 1))
#[[3 5 7]
# [1 4 6]]
- 我们还可以在 sort 函数中设置排序字段,按我们指定的方式进行排序。
- 首先,我们指定数据类型为名字(字符串)和年龄(整型),按指定好的的数据类型定义数组的元素,并将其元素输出。
- 然后,我们将指定排序方式定义为名字,并输出排序后的数组,与前面输出的原数组数据进行比较。
dt = np.dtype([('name', 'S10'),('age', int)])
a = np.array([("raju",21),("anil",25),("ravi", 17), ("amar",27)], dtype = dt)
print(a)
print('--'*10)
print(np.sort(a, order = 'name'))
#[(b'raju', 21) (b'anil', 25) (b'ravi', 17) (b'amar', 27)]
#--------------------
#[(b'amar', 27) (b'anil', 25) (b'raju', 21) (b'ravi', 17)]
8. numpy.argsort()
- argsort() 表示沿着指定的轴,对输入数组的元素值进行排序,并返回排序后的元素索引数组。
- 具体可见如下示例:
- 我们先生成一个指定元素的数组,并将其输出。
a = np.array([90, 29, 89, 12])
print("原数组:",a)
#原数组: [90 29 89 12]
- 然后,使用 numpy.argsort() 对 a 数组进行排序,并将排序后的元素索引数组输出。
sort_ind = np.argsort(a)
print("打印排序元素索引值:",sort_ind)
#打印排序元素索引值: [3 1 2 0]
- 随后,我们可以使用索引数组对原数组进行排序。
sort_a = a[sort_ind]
print("打印排序数组")
for i in sort_ind: print(a[i],end = " ")
a[sort_ind]
#打印排序数组
#12 29 89 90
#array([12, 29, 89, 90])
相关文章:
Python 之 NumPy 随机函数和常用函数
文章目录一、随机函数1. numpy.random.rand(d0,d1,…,dn)2. numpy.random.randn(d0,d1,…,dn)3. numpy.random.normal()4. numpy.random.randint()5. numpy.random.sample6. 随机种子np.random.seed()7. 正态分布 numpy.random.normal二、数组的其他函数1. numpy.resize()2. nu…...
【目标检测】K-means和K-means++计算anchors结果比较(附完整代码,全网最详细的手把手教程)
写在前面: 首先感谢兄弟们的订阅,让我有创作的动力,在创作过程我会尽最大努力,保证作品的质量,如果有问题,可以私信我,让我们携手共进,共创辉煌。 一、介绍 YOLO系列目标检测算法中基于anchor的模型还是比较多的,例如YOLOv3、YOLOv4、YOLOv5等,我们可以随机初始化a…...
Java高手速成 | 图说重定向与转发
我们先回顾一下Servlet的工作原理,Servlet的工作原理跟小猪同学食堂就餐的过程很类似。小猪同学点了烤鸡腿(要奥尔良风味的),食堂窗口的服务员记下了菜单,想了想后厨的所有厨师,然后将菜单和餐盘交给专门制…...

Git:不小心在主分支master上进行修改,怎么才能将修改的数据保存到正确的分支中
1.如果还没有push commit 代码第一步:将所修改的代码提交到暂存区git stash第二步:切换到正确的分支git checkout 分支名第三步:从暂存区中取出保存到正确的分支中git stash pop第四步:重新提交git push origin 分支名2.如果已经p…...

都2023年了,如果不会Stream流、函数式编程?你确定能看懂公司代码?
👳我亲爱的各位大佬们好😘😘😘 ♨️本篇文章记录的为 Stream流、函数式编程 相关内容,适合在学Java的小白,帮助新手快速上手,也适合复习中,面试中的大佬🙉🙉🙉。 ♨️如果…...

亚马逊云科技汽车行业解决方案
当今,随着万物智联、云计算等领域的高速发展,创新智能网联汽车和车路协同技术正在成为车企加速发展的关键途径,推动着汽车产品从出行代步工具向着“超级智能移动终端”快速转变。 挑战无处不在,如何抢先预判? 随着近…...
为什么学了模数电还是看不懂较复杂的电路图
看懂电路并不难。 (1) 首先要摆正心态,不要看到错综复杂的电路图就一脸懵逼,不知所错。你要明白,再复杂的电路也是由一个个的基本电路拼装出来的。 (2) 基础知识当然是少不了的,常用的基本电路结构搞搞清楚。 (3) 分析电路之前先要…...
帮公司面试了一个30岁培训班出来的程序员,没啥工作经验...
首先,我说一句:培训出来的,优秀学员大有人在,我不希望因为带着培训的标签而无法达到用人单位和候选人的双向匹配,是非常遗憾的事情。 最近,在网上看到这样一个留言,引发了程序员这个圈子不少的…...

勒索软件、网络钓鱼、零信任和网络安全的新常态
当疫情来袭时,网络罪犯看到了他们的机会。随着公司办公、政府机构、学校和大学从以往的工作模式转向远程线上办公模式,甚至许多医疗保健设施都转向线上,这种快速的过渡性质导致了不可避免的网络安全漏洞。消费者宽带和个人设备破坏了企业安全…...

python3 字符串拼接与抽取
我们经常会有对字符串进行拼接和抽取的需求,下面有几个例子可以作为参考。 需求1:取出ip地址的网络地址与网络掩码进行拼接,分别使用shell脚本和python3实现 # echo "192.168.0.1"|awk -F. {print $1"."$2"."…...

Linux就该这么学:存储结构与管理硬盘
Linux系统中常见的目录名称以及相应内容 目录名称应放置文件的内容/boot开机所需文件—内核、开机菜单以及所需配置文件等/dev以文件形式存放任何设备与接口/etc配置文件/home用户主目录/bin存放单用户模式下还可以操作的命令/lib开机时用到的函数库,以及/bin与/sbin下面的命令…...

JSP四大作用域,九大内置对象
面试题:JSP和Servlet的区别?JSP的本质就是servleJSP更加侧重于视图的展示,servlet更注重逻辑的处理。面试题:include指令和jsp:include标签的区别?从效果上来说,没区别。include指令是把两个页面合成一个js…...
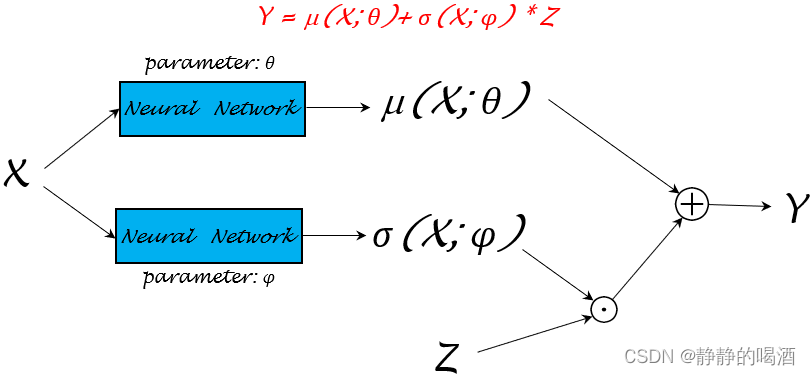
机器学习笔记之生成模型综述(五)重参数化技巧(随机反向传播)
机器学习笔记之生成模型综述——重参数化技巧[随机反向传播]引言回顾神经网络的执行过程变分推断——重参数化技巧重参数化技巧(随机反向传播)介绍示例描述——联合概率分布示例描述——条件概率分布总结引言 本节将系统介绍重参数化技巧。 回顾 神经网络的执行过程 上一节…...
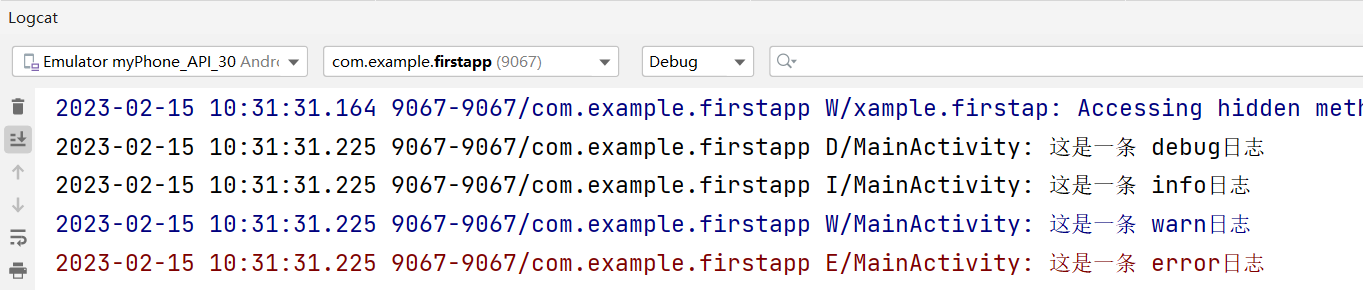
1、创建第一个Android项目
1.1、创建Android工程项目:双击打开Android Studio。在菜单栏File中new-->new project3、在界面中选择Empty Activity,然后选择next4、在下面界面中修改工程名称,工程保存路径选择java语言,然后点击finishAndroid studio自动为…...
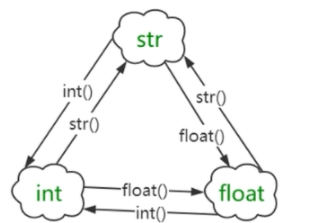
【python百炼成魔】手把手带你学会python数据类型
文章目录前言一. python的基本数据类型1.1 如何查看数据类型1.2 数值数据类型1.2.1 整数类型1.2.2 浮点数类型1.2.3 bool 布尔数值类型1.2.4 字符串类型二. 数据类型强制转换2.1 强制转换为字符串类型2.2 强制转换为int类型2.3 强制转换函数之float() 函数三. 拓展几个运算函数…...
数据储存以及大小端判断
目录 数据存储 1,二进制存储方式(补码,反码,源码) 2,指针类型 3,大端,小段判断 1,二进制存储方式(补码,反码,源码) 我…...

GRASP设计原则
GRASP设计原则介绍9种基本原则创建者 Creator问题解决方法何时不使用?好处信息专家 Information Expert问题解决方法信息怎么做优点低耦合 Low Coupling耦合问题解决方法原则何时不使用?控制器 Controller问题解决方法外观控制器会话控制器优点臃肿控制器的解决方法高内聚 Hi…...

再遇周杰伦隐私协议
本隐私信息保护政策版本:2021 V1 一、重要提示 请您(以下亦称“用户”)在使用本平台App时仔细阅读本协议之全部条款,并确认您已完全理解本协议之规定,尤其是涉及您的重大权益及义务的加粗或划线条款。如您对协议有任…...

关于项目上的一些小操作记录
一 如何在项目的readme.md文件中插入图片说明 1 准备一张图片命名为test.png 2 在maven项目的resources目录下新建文件夹picture,将图片放入该目录下 3 在readme.md文件中期望插入图片的地方编辑如下:  此时&#…...
)
sql查询不以某些指定字符开头(正则表达式)
我们用到的最多的是:查询以特定字符或字符串开头的记录 字符^用来匹配以特定字符或字符串开头的记录。 例 1 在 tb_students_info 表中,查询 name 字段以“J”开头的记录,SQL 语句和执行过程如下。 mysql> SELECT * FROM tb_students_…...

Taotoken在数据预处理与分析脚本中调用大模型的集成案例
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken在数据预处理与分析脚本中调用大模型的集成案例 应用场景类,设想一个数据科学家使用Python脚本进行数据分析时…...

如何彻底修复Windows更新故障:使用Reset Windows Update Tool的完整指南
如何彻底修复Windows更新故障:使用Reset Windows Update Tool的完整指南 【免费下载链接】Reset-Windows-Update-Tool Troubleshooting Tool with Windows Updates (Developed in Dev-C). 项目地址: https://gitcode.com/gh_mirrors/re/Reset-Windows-Update-Tool…...

Box64终极指南:5分钟学会在ARM设备上运行x86_64程序
Box64终极指南:5分钟学会在ARM设备上运行x86_64程序 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 你是否曾经梦…...

初创公司如何用Taotoken统一管理多个AI模型的API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何用Taotoken统一管理多个AI模型的API密钥 对于初创公司而言,在业务中集成多个大语言模型(如GPT…...

安全生产隐患识别太难?实测实在Agent:AI模型语义分析能力测评详解与信创落地指南
摘要: 步入2026年,安全生产已进入“全量数字化”与“法制化”深度融合的高压期。随着《安全生产法》的持续深化执行,企业面临着海量隐患识别、跨系统数据流转及信创环境适配的三重挑战。传统的人工排查与基于API的自动化手段,在面…...

终极指南:如何使用Gulf of Mexico轻松实现TCP/UDP网络通信
终极指南:如何使用Gulf of Mexico轻松实现TCP/UDP网络通信 【免费下载链接】GulfOfMexico perfect programming language 项目地址: https://gitcode.com/GitHub_Trending/dr/GulfOfMexico Gulf of Mexico(原DreamBerd)是一种创新的编…...

HI3861实战指南:基于MQTT协议实现OneNET平台设备双向通信
1. HI3861与OneNET平台双向通信实战 第一次接触HI3861开发板时,我就被它轻量级的物联网开发能力吸引了。这块板子虽然体积小,但配合OneNET平台能实现完整的物联网数据交互。今天我就用最直白的语言,分享如何让HI3861通过MQTT协议与OneNET平台…...

独立开发者如何通过taotoken以更低成本实验多种大模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何通过Taotoken以更低成本实验多种大模型能力 对于独立开发者或小型工作室而言,在项目原型阶段验证不同大…...

突破性APK安装器:在Windows上高效运行Android应用的革命性方案
突破性APK安装器:在Windows上高效运行Android应用的革命性方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否渴望在Windows电脑上无缝运行Android应…...

ChatGPT 2026安全增强套件发布:内置FIPS 140-3认证加密引擎、GDPR实时审计追踪、AI生成内容数字水印——金融/医疗行业合规上线最后窗口期
更多请点击: https://intelliparadigm.com 第一章:ChatGPT 2026安全增强套件整体架构与合规定位 ChatGPT 2026安全增强套件(CESK-2026)是一套面向生成式AI服务的纵深防御框架,专为满足GDPR、中国《生成式人工智能服务…...