基于zookeeper的Hadoop集群搭建详细步骤
目录
一、一些基本概念
二、集群配置图
三、Hadoop高可用集群配置步骤
1.在第一台虚拟机解压hadoop-3.1.3.tar.gz到/opt/soft/目录
2.修改文件名、属主和属组
3.配置windows四台虚拟机的ip映射
4.修改hadoop配置文件
(1)hadoop-env.sh
(2)workers
(3)crore-site.xml
(4)hdfs-site.xml
(5)mapred-site.xml
(6)yarn-site.xml
5.拷贝hadoop到其他三台虚拟机
6.分配环境变量
7.重启环境变量,检验四台虚拟机安装是否成功
四、首次启动hadoop集群
1.高可用启动之前要启动zookeeper
2.三台机器启动JournalNode
3.第一台机器格式化
4.第一台机器启动namenode
5.在第二台机器同步namenode信息
6.第二台机器启动namenode
7.每台机器查看namenode的状态都是standby
8.关闭所有的与dfs有关的服务
9.格式化zookeeper
10.zkCli.sh
11.启动dfs
12.查看namenode节点状态
13.打开网页登录查看
14.每台虚拟机下载主备切换工具
15.启动yarn
16.有resourcemanager的主机名登录8088端口
17.查看resourcemanager节点状态
18.关闭集群
zookeeper集群的安装步骤参考博文《搭建zookeeper高可用集群详细步骤》,注意主机名,这里换了主机名ant161=ant165;ant162=ant166;ant163=ant167;ant164=ant168
一、一些基本概念
JournalNode的作用
Hadoop集群中的DFSZKFailoverController进程的作用
二、集群配置图
| ant161 | ant162 | ant163 | ant164 |
| NameNode | NameNode | ||
| DataNode | DataNode | DataNode | DataNode |
| NodeManager | NodeManager | NodeManager | NodeManager |
| ResourceManager | ResourceManager | ||
| JournalNode监控NameNode是否同步 | JournalNode | JournalNode | |
| DFSZKFailoverController监控NameNode是否存活 | DFSZKFailoverController | ||
| zookeeper0 | zookeeper1 | zookeeper2 | |
| JobHistory |
三、Hadoop高可用集群配置步骤
1.在第一台虚拟机解压hadoop-3.1.3.tar.gz到/opt/soft/目录
[root@ant161 install]# tar -zxf ./hadoop-3.1.3.tar.gz -C /opt/soft/
2.修改文件名、属主和属组
[root@ant161 soft]# mv ./hadoop-3.1.3/ hadoop313[root@ant161 soft]# chown -R root:root ./hadoop313/
3.配置windows四台虚拟机的ip映射
C:\Windows\System32\drivers\etc目录下的host文件,添加以下的主机ip配置
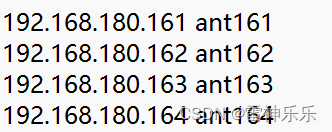
4.修改hadoop配置文件
(1)hadoop-env.sh
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/opt/soft/jdk180
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root(2)workers
输入四台虚拟机主机名
ant161
ant162
ant163
ant164
(3)crore-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://gky</value><description>逻辑名称,必须与hdfs-site.cml中的dfs.nameservices值保持一致</description></property><property><name>hadoop.tmp.dir</name><value>/opt/soft/hadoop313/tmpdata</value><description>namenode上本地的hadoop临时文件夹</description></property><property><name>hadoop.http.staticuser.user</name><value>root</value><description>默认用户</description></property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value><description></description></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value><description></description></property><property><name>io.file.buffer.size</name><value>131072</value><description>读写文件的buffer大小为:128K</description></property><property><name>ha.zookeeper.quorum</name><value>ant161:2181,ant162:2181,ant163:2181</value><description></description></property><property><name>ha.zookeeper.session-timeout.ms</name><value>10000</value><description>hadoop链接zookeeper的超时时长设置为10s</description></property>
</configuration>(4)hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>3</value><description>Hadoop中每一个block的备份数</description></property><property><name>dfs.namenode.name.dir</name><value>/opt/soft/hadoop313/data/dfs/name</value><description>namenode上存储hdfs名字空间元数据目录</description></property><property><name>dfs.datanode.data.dir</name><value>/opt/soft/hadoop313/data/dfs/data</value><description>datanode上数据块的物理存储位置</description></property><property><name>dfs.namenode.secondary.http-address</name><value>ant161:9869</value><description></description></property><property><name>dfs.nameservices</name><value>gky</value><description>指定hdfs的nameservice,需要和core-site.xml中保持一致</description></property><property><name>dfs.ha.namenodes.gky</name><value>nn1,nn2</value><description>gky为集群的逻辑名称,映射两个namenode逻辑名</description></property><property><name>dfs.namenode.rpc-address.gky.nn1</name><value>ant161:9000</value><description>namenode1的RPC通信地址</description></property><property><name>dfs.namenode.http-address.gky.nn1</name><value>ant161:9870</value><description>namenode1的http通信地址</description></property><property><name>dfs.namenode.rpc-address.gky.nn2</name><value>ant162:9000</value><description>namenode2的RPC通信地址</description></property><property><name>dfs.namenode.http-address.gky.nn2</name><value>ant162:9870</value><description>namenode2的http通信地址</description></property><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://ant161:8485;ant162:8485;ant163:8485/gky</value><description>指定NameNode的edits元数据的共享存储位置(JournalNode列表)</description></property><property><name>dfs.journalnode.edits.dir</name><value>/opt/soft/hadoop313/data/journaldata</value><description>指定JournalNode在本地磁盘存放数据的位置</description></property><!-- 容错 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value><description>启用NameNode故障自动切换</description></property><property><name>dfs.client.failover.proxy.provider.gky</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value><description>失败后自动切换的实现方式</description></property><property><name>dfs.ha.fencing.methods</name><value>sshfence</value><description>防止脑裂的处理</description></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value><description>使用sshfence隔离机制时需要ssh免登陆</description></property><property><name>dfs.permissions.enabled</name><value>false</value><description>关闭HDFS操作权限验证</description></property><property><name>dfs.image.transfer.bandwidthPerSec</name><value>1048576</value><description>1M</description></property><property><name>dfs.block.scanner.volume.bytes.per.second</name><value>1048576</value><description>如果该值为0,则DataNode的块扫描程序将被禁用。如果这是正数,则这是DataNode的块扫描程序将尝试从每个卷扫描的每秒字节数。</description></property>
</configuration>(5)mapred-site.xml
<property><name>mapreduce.framework.name</name><value>yarn</value><description>job执行框架: local, classic or yarn</description>
</property>
<property><name>mapreduce.application.classpath</name><value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/hadoop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/opt/soft/hadoop313/share/hadoop/yarn/lib/*</value><description></description>
</property>
<property><name>mapreduce.jobhistory.address</name><value>ant161:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>ant161:19888</value></property>
<property><name>mapreduce.map.memory.mb</name><value>1024</value><description>设置map阶段的task工作内存</description>
</property>
<property><name>mapreduce.reduce.memory.mb</name><value>2048</value><description>设置reduce阶段的task工作内存</description>
</property>(6)yarn-site.xml
<configuration><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value><description>开启resourcemanager高可用</description></property><property><name>yarn.resourcemanager.cluster-id</name><value>yrcabc</value><description>指定yarn集群中的id</description></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value><description>指定resourcemanager的名字</description></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>ant163</value><description>设置rm1的名字</description></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>ant164</value><description>设置rm2的名字</description></property><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>ant163:8088</value><description></description></property><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>ant164:8088</value><description></description></property><property><name>yarn.resourcemanager.zk-address</name><value>ant161:2181,ant162:2181,ant163:2181</value><description>指定zookeeper集群地址</description></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>运行mapreduce程序必须配置的附属服务</description></property><property><name>yarn.nodemanager.local-dirs</name><value>/opt/soft/hadoop313/tmpdata/yarn/local</value><description>nodemanager本地存储目录</description></property><property><name>yarn.nodemanager.log-dirs</name><value>/opt/soft/hadoop313/tmpdata/yarn/log</value><description>nodemanager本地日志目录</description></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>2048</value><description>resource进程的工作内存</description></property><property><name>yarn.nodemanager.resource.cpu-vcores</name><value>2</value><description>resource工作中所能使用机器的内核数</description></property><!--下面三个配置在公司要删除--><property><name>yarn.scheduler.minimum-allocation-mb</name><value>256</value><description></description></property><property><name>yarn.log-aggregation-enable</name><value>true</value><description></description></property><property><name>yarn.log-aggregation.retain-seconds</name><value>86400</value><description>日志保留多少秒</description></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value><description></description></property><property><name>yarn.application.classpath</name><value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/hadoop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/opt/soft/hadoop313/share/hadoop/yarn/lib/*</value></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property>
</configuration>5.拷贝hadoop到其他三台虚拟机
[root@ant161 soft]# scp -r ./hadoop313/ root@ant162:/opt/soft/
[root@ant161 soft]# scp -r ./hadoop313/ root@ant163:/opt/soft/
[root@ant161 soft]# scp -r ./hadoop313/ root@ant164:/opt/soft/
6.分配环境变量
[root@ant161 soft]# scp /etc/profile root@ant162:/etc/
profile 100% 2202 1.4MB/s 00:00
[root@ant161 soft]# scp /etc/profile root@ant163:/etc/
profile 100% 2202 1.4MB/s 00:00
[root@ant161 soft]# scp /etc/profile root@ant164:/etc/
profile 7.重启环境变量,检验四台虚拟机安装是否成功
source /etc/profilehadoop hadoop version四、首次启动hadoop集群
1.高可用启动之前要启动zookeeper
[root@ant161 soft]# /opt/shell/zkop.sh start
------------ ant161 zookeeper -----------
JMX enabled by default
Using config: /opt/soft/zk345/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
------------ ant162 zookeeper -----------
JMX enabled by default
Using config: /opt/soft/zk345/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
------------ ant163 zookeeper -----------
JMX enabled by default
Using config: /opt/soft/zk345/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED[root@ant161 soft]# /opt/shell/showjps.sh
---------------- ant161 服务启动状态 -----------------
2532 QuorumPeerMain
2582 Jps
---------------- ant162 服务启动状态 -----------------
2283 QuorumPeerMain
2335 Jps
---------------- ant163 服务启动状态 -----------------
2305 Jps
2259 QuorumPeerMain
---------------- ant164 服务启动状态 -----------------
2233 Jps[root@ant161 soft]# /opt/shell/zkop.sh status
------------ ant161 zookeeper -----------
JMX enabled by default
Using config: /opt/soft/zk345/bin/../conf/zoo.cfg
Mode: follower
------------ ant162 zookeeper -----------
JMX enabled by default
Using config: /opt/soft/zk345/bin/../conf/zoo.cfg
Mode: leader
------------ ant163 zookeeper -----------
JMX enabled by default
Using config: /opt/soft/zk345/bin/../conf/zoo.cfg
Mode: follower
2.三台机器启动JournalNode
[root@ant161 soft]# hdfs --daemon start journalnode
WARNING: /opt/soft/hadoop313/logs does not exist. Creating.[root@ant162 soft]# hdfs --daemon start journalnode
WARNING: /opt/soft/hadoop313/logs does not exist. Creating.[root@ant163 soft]# hdfs --daemon start journalnode
WARNING: /opt/soft/hadoop313/logs does not exist. Creating.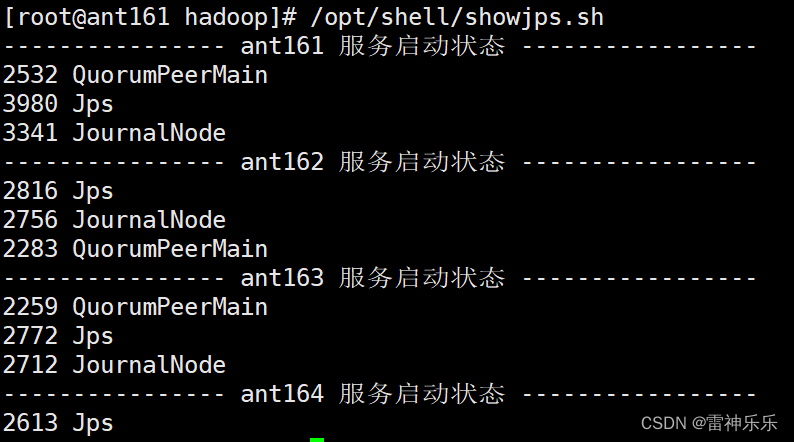
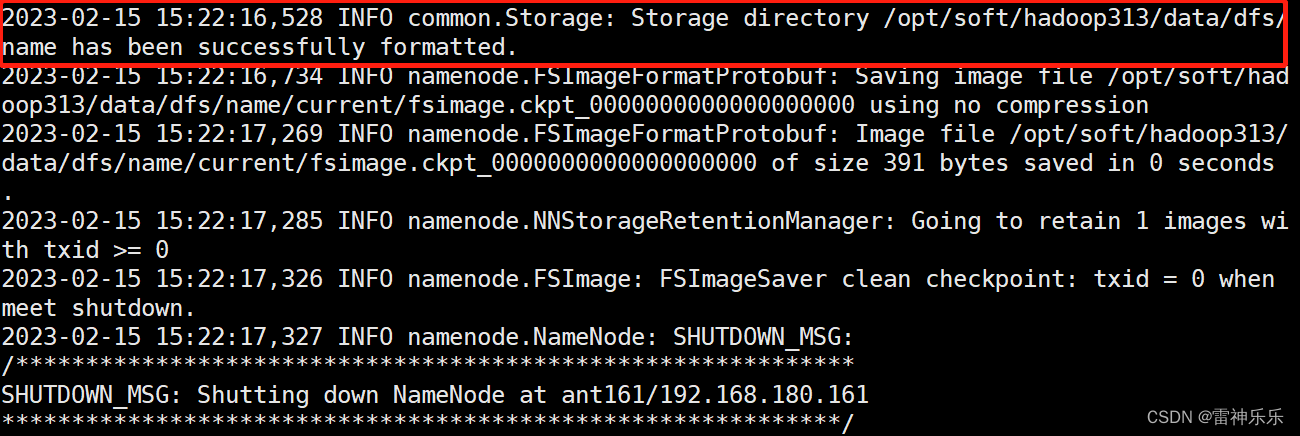
3.第一台机器格式化
[root@ant161 soft]# hdfs namenode -format
4.第一台机器启动namenode
[root@ant161 hadoop]# hdfs --daemon start namenode
5.在第二台机器同步namenode信息
[root @ant162 soft]# hdfs namenode -bootstrapStandby
6.第二台机器启动namenode
[root @ant162 soft]# hdfs --daemon start namenode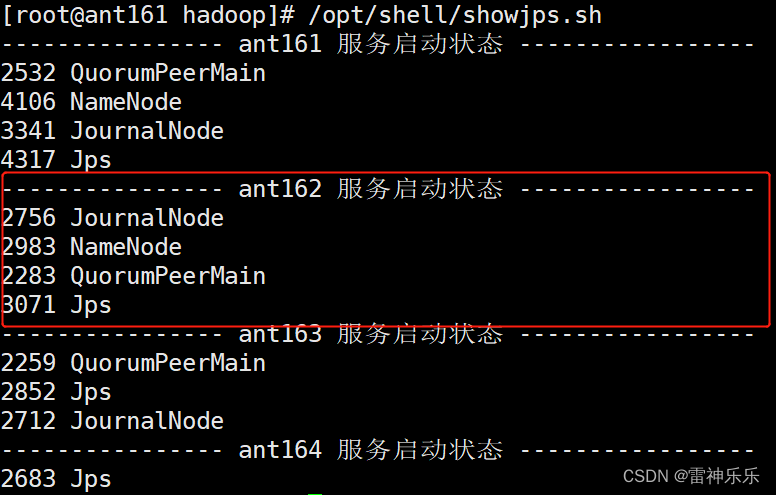
7.每台机器查看namenode的状态都是standby
[root @ant161 soft]# hdfs haadmin -getServiceState nn1
standby
[root @ant161 soft]# hdfs haadmin -getServiceState nn2
standby8.关闭所有的与dfs有关的服务
[root @ant161 soft]# stop-dfs.sh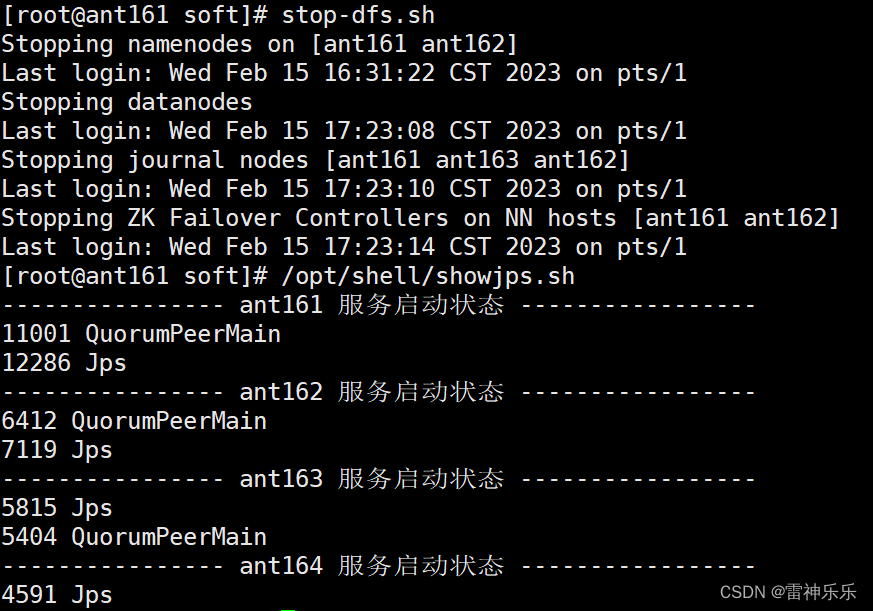
9.格式化zookeeper
[root @ant161 soft]# hdfs zkfc -formatZK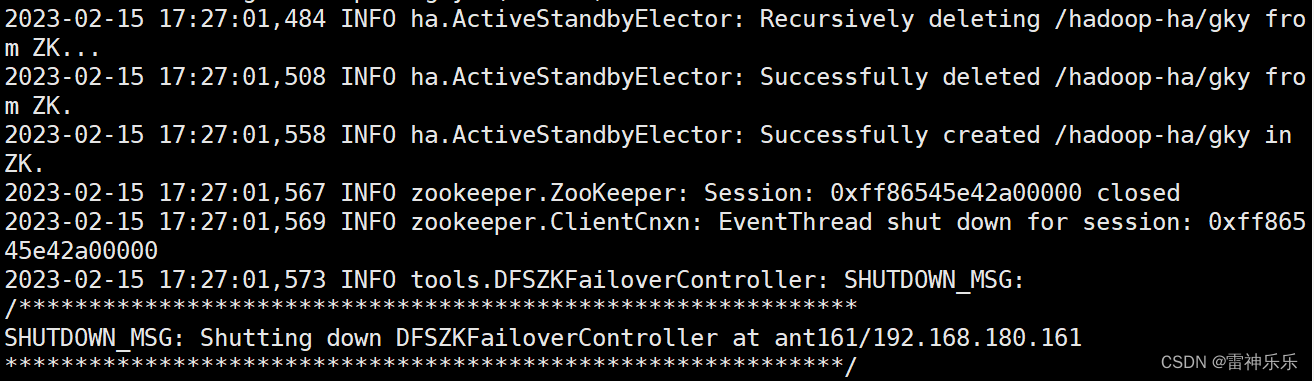
10.zkCli.sh
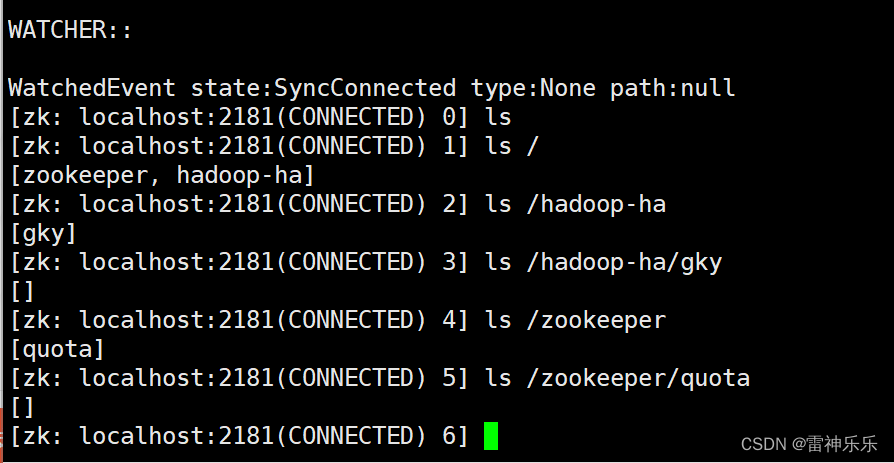
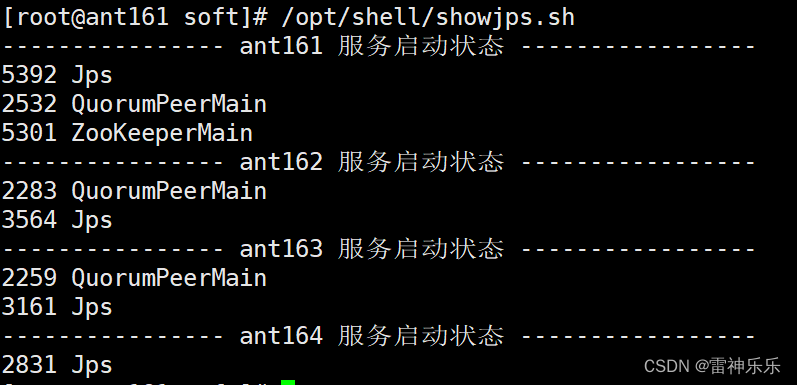
11.启动dfs
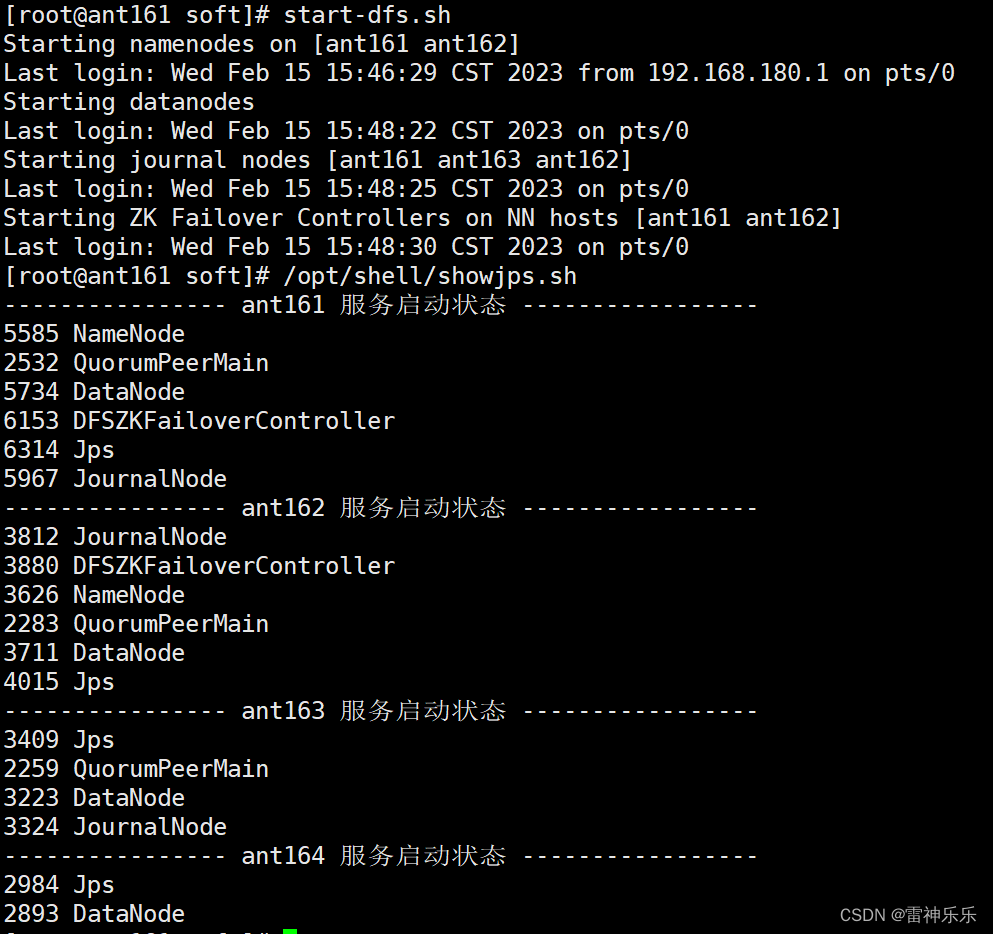
12.查看namenode节点状态
[root@ant161 soft]# hdfs haadmin -getServiceState nn1
standby
[root@ant161 soft]# hdfs haadmin -getServiceState nn2
active
13.打开网页登录查看
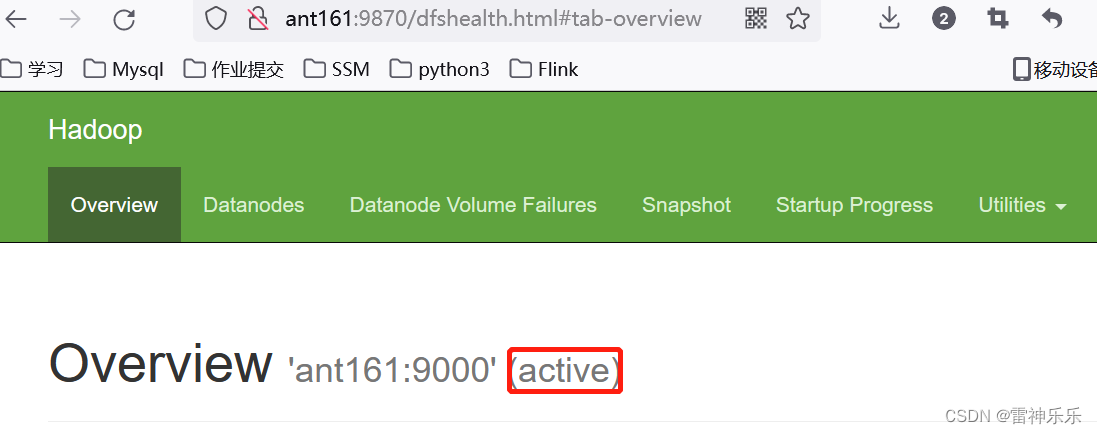
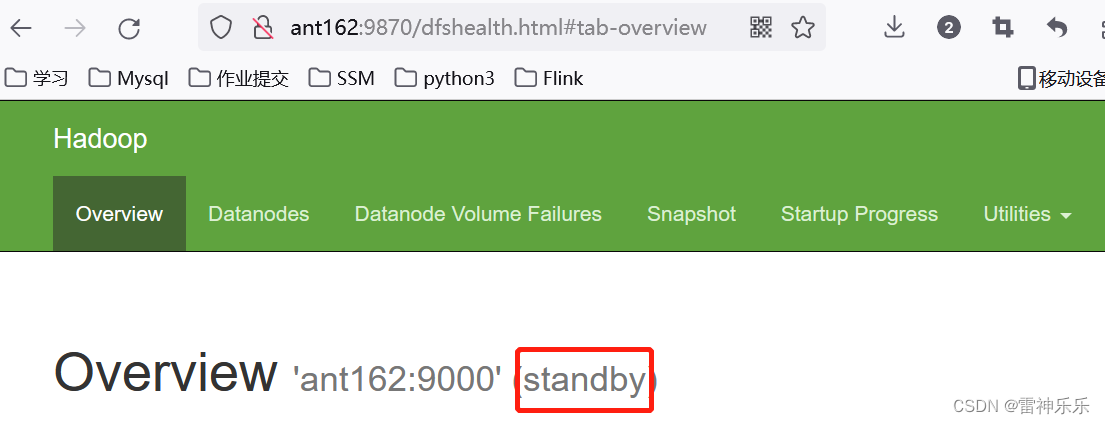
14.每台虚拟机下载主备切换工具
[root@ant161 soft]# yum install psmisc -y
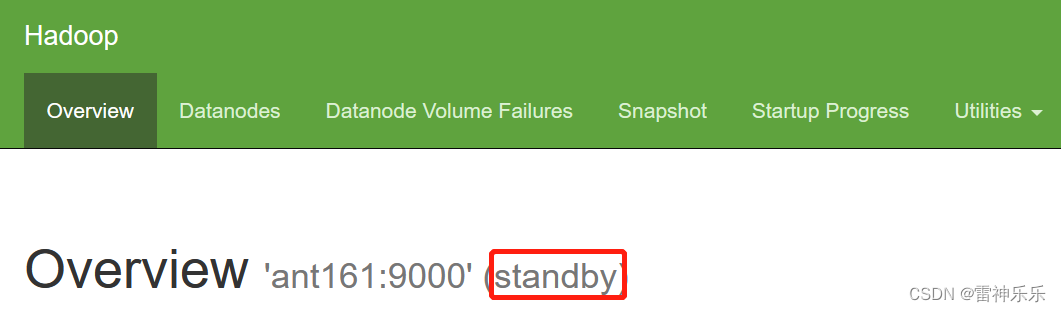
此时如果停止active那一台的namenode,7218是active那一台机器namenode的进程号
[root@ant162 soft]# kill -9 7218此时active那一台网页无法连接,另一台没有关闭namenode的机器的网页变为active
再重新启动关闭的namenode,网页端的两个网址刷新,就会发现刚刚变为active的那一台机器,还是active状态,而另一台重启的机器就编程了standby等待状态

15.启动yarn
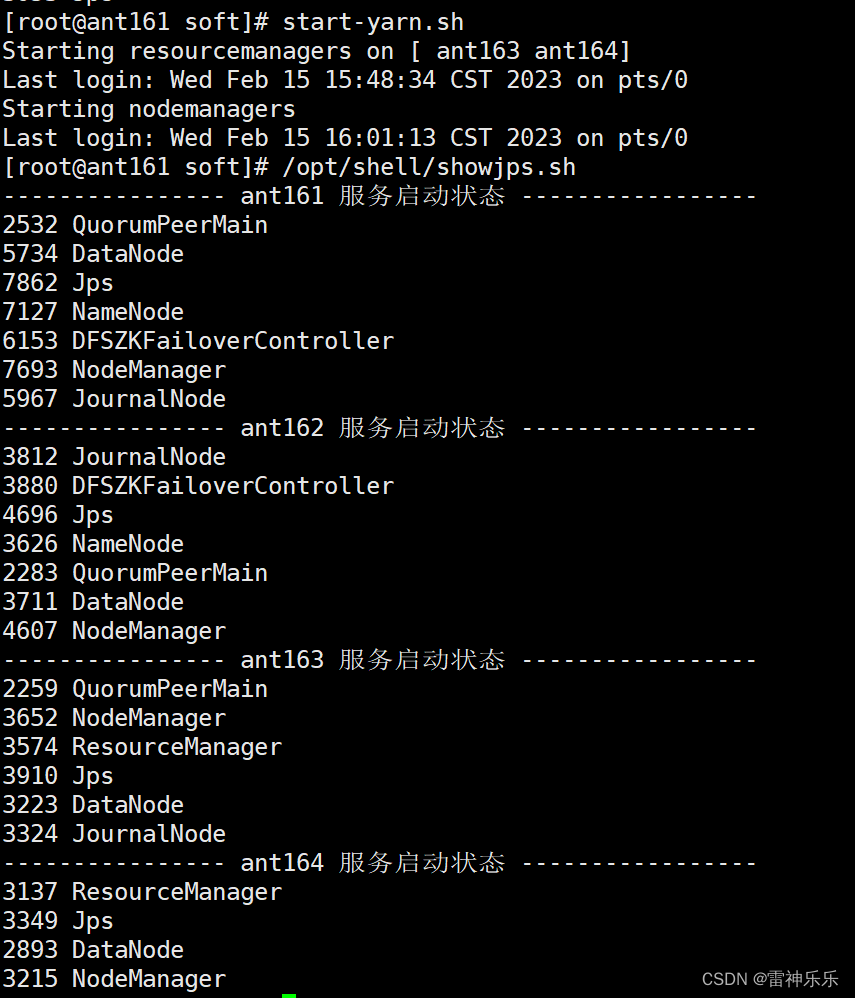
16.有resourcemanager的主机名登录8088端口
哪一台机器是active的状态,就会自动跳转到那一台机器的主机名
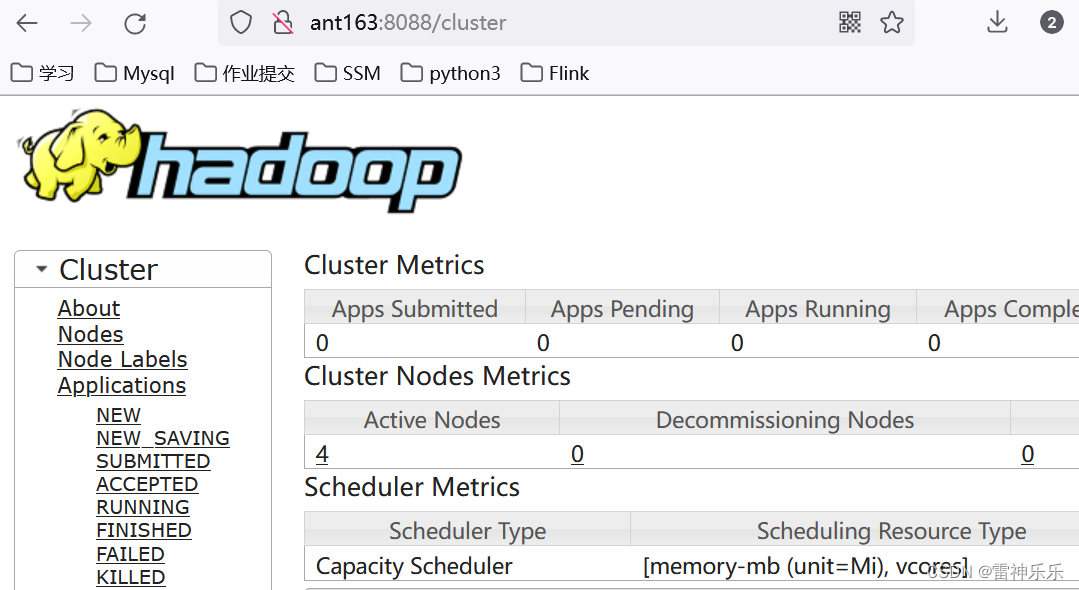
17.查看resourcemanager节点状态
[root@ant161 soft]# yarn rmadmin -getServiceState rm1
active
[root@ant161 soft]# yarn rmadmin -getServiceState rm2
standby
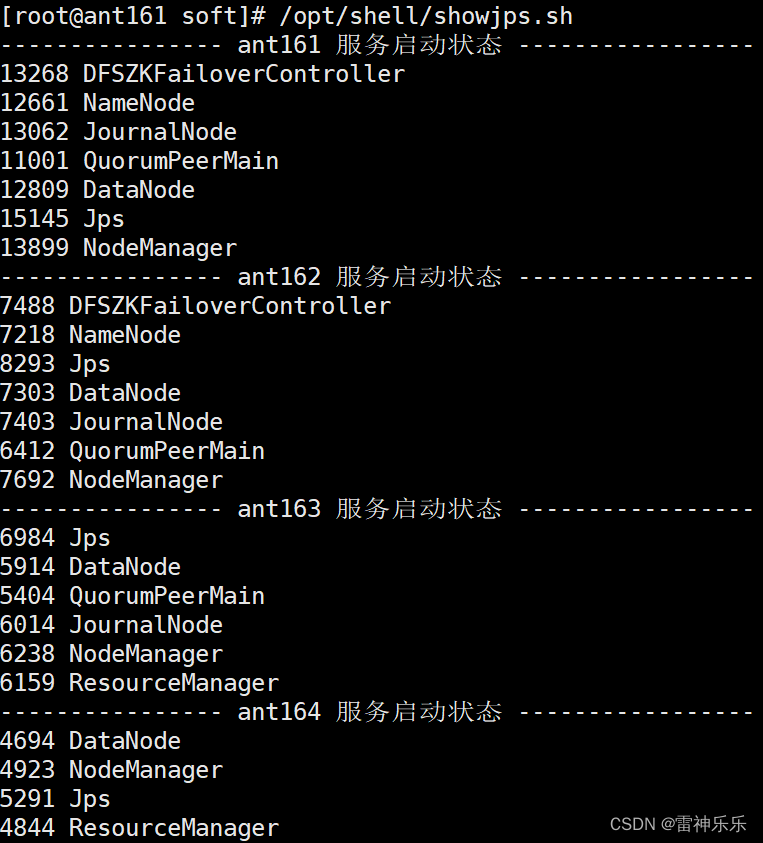
18.关闭集群
(1)关闭dfs
[root@ant161 soft]# stop-dfs.sh
(2)关闭yarn
[root@ant161 soft]# stop-yarn.sh
(3)关闭journalnode
[root@ant161 soft]# hdfs --daemon stop journalnode
(4)关闭zookeeper
[root@ant161 soft]# /opt/shell/zkop.sh stop
相关文章:
基于zookeeper的Hadoop集群搭建详细步骤
目录 一、一些基本概念 二、集群配置图 三、Hadoop高可用集群配置步骤 1.在第一台虚拟机解压hadoop-3.1.3.tar.gz到/opt/soft/目录 2.修改文件名、属主和属组 3.配置windows四台虚拟机的ip映射 4.修改hadoop配置文件 (1)hadoop-env.sh (2)workers (3)crore-site.xml …...

职称有哪些意义?如何提升职称?
每年我们会看到很多人都会努力地提升自己的职称,那么为什么大家都想要晋升职称?在这里余老师说说他的作用,您可以参考一下。 一、个人金钱方面的提升 工资。职称直接关联的就是涨工资了。正常情况下,职称和工资是一一对应的了,…...

mulesoft MCIA 破釜沉舟备考 2023.02.15.09
mulesoft MCIA 破釜沉舟备考 2023.02.15.09 1. According to MuleSoft, which deployment characteristic applies to a microservices application architecture?2. Refer to the exhibit.3. Mule application A receives a request Anypoint MQ message REQU with a payload…...

【项目实战】@ConditionalOnProperty注解让我少写了一些if判断
一、需求说明 本机启动含有XXL-job的工程,发现每次都会进行XXL-job的init的动作。这会导致本机每次启动都会把自己注册到XXL-job的服务端。但是我明明本地调试的功能不想要是编写定时任务,于是想了下,是否可以设计一个开关,让本机…...

SQL中的游标、异常处理、存储函数及总结
目录 一.游标 格式 操作 演示 二.异常处理—handler句柄 格式 演示 三.存储函数 格式 参数说明 演示 四.存储过程总结 一.游标 游标(cursor)是用来存储查询结果集的数据类型,在存储过程和函数中可以使用游标对结果集进行循环的处理。游标的使用包括游标的声明、OPEN、…...

Splashtop:支持M1/M2芯片 Mac 电脑的远程控制软件
M1和M1芯片的Mac电脑现在越来越多了。M1和M2的强大性能,让使用者们办公、娱乐如虎添翼。 M1 芯片于2020年11月11日推出,是Apple 首款专为Mac打造的芯片,拥有格外出色的性能、众多的功能,以及令人惊叹的能效表现。M1 也是Apple 首款…...

实验十三、阻容耦合共射放大电路的频率响应
一、题目 利用 Multism 从以下几个方面研究图1所示的阻容耦合共射放大电路的频率响应。图1阻容耦合共射放大电路图1\,\,阻容耦合共射放大电路图1阻容耦合共射放大电路(1)设 C1C210μFC_1C_210\,\textrm{μF}C1C210μF,分别测试它们所确定…...
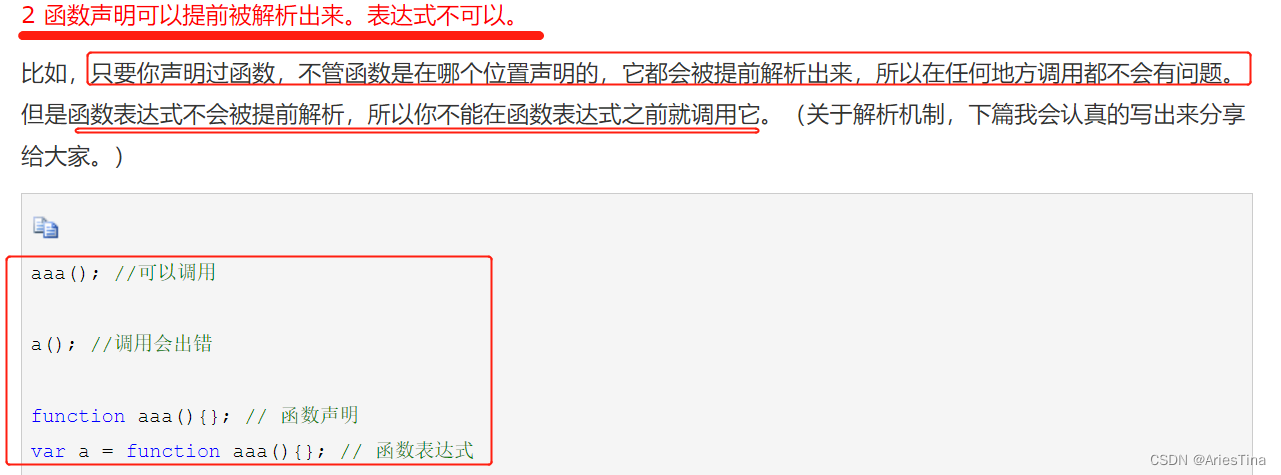
【每天进步一点点】函数表达式和函数声明
函数声明 function 函数名(){} 函数声明会被率先读取。 函数声明后不会立即执行,会在我们需要的时候调用到。 由于函数声明不是一个可执行语句,所以不以分号结束。 函数表达式 表达式赋值给了一个变量 const 变量名 functi…...

JavaScript void
文章目录JavaScript voidjavascript:void(0) 含义href"#"与href"javascript:void(0)"的区别JavaScript void javascript:void(0) 含义 我们经常会使用到 javascript:void(0) 这样的代码,那么在 JavaScript 中 javascript:void(0) 代表的是什么…...
笔记本电脑怎么连接无线网wifi?不同电脑系统的使用教程(2023最新)
现在越多人使用笔记本电脑,在我们的日常生活和工作中是很难离开它的。想要更快速地上网,我们都会选择连接无线网的wifi。有时笔记本电脑无法连接网络,你知道这是什么原因吗?笔记本电脑怎么连接无线网wifi?方法很简单&a…...
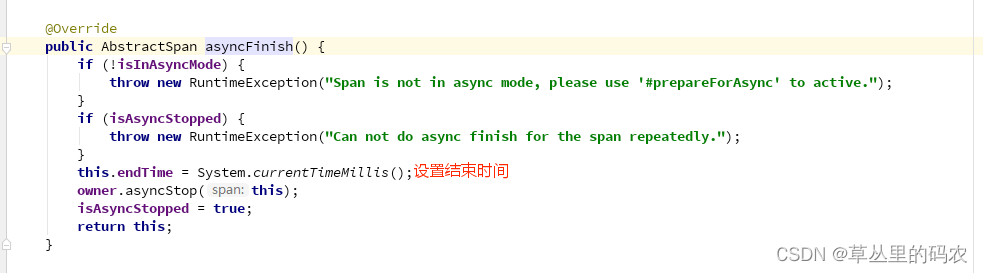
从lettcue插件看skywalking
lettcue 的写操作是异步的。io.lettuce.core.RedisChannelWriter.write进行写入,io.lettuce.core.protocol.RedisCommand进行异步读取数据 skywalking 插件大体逻辑 在方法执行前,通过ContextManager创建span创建span的同时,判断trace上下文…...

explain 每个列的含义
官网传送门:https://dev.mysql.com/doc/refman/5.7/en/explain-output.html 实例表 DROP TABLE IF EXISTS actor;CREATE TABLE actor (id int(11) NOT NULL,name varchar(45) DEFAULT NULL,update_time datetime DEFAULT NULL,PRIMARY KEY (id)) ENGINEInnoDB DEFA…...
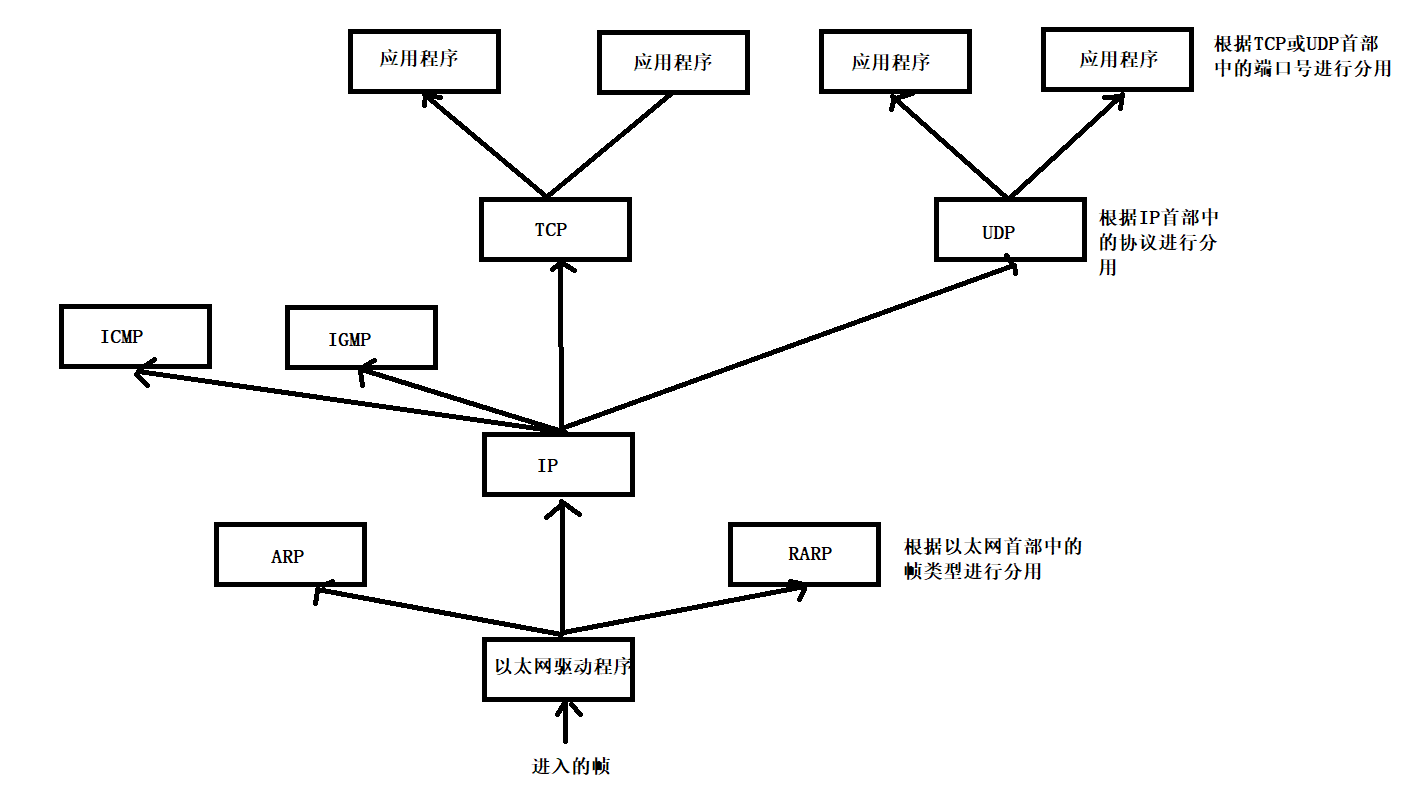
网络通信编程基础
1.IP地址 概念 IP地址主要用于标识网络主机、其他网络设备(如路由器)的网络地址。简单说,IP地址用于定位主机的网络地址。 就像我们发送快递一样,需要知道对方的收货地址,快递员才能将包裹送到目的地。 格式 IP地址…...

Linux网络编程
一、网络结构模式 1、C/S 结构 1)、简介 服务器 - 客户机,即 Client - Server(C/S)结构。C/S 结构通常采取两层结构。服务器负责数据的管理,客户机负责完成与用户的交互任务。客户机是因特网上访问别人信息的机器&a…...

***httpGet,httpPost,postman_http,httpClientSocket,httpSocketServer***
1:状态码_http 2:java访问(http):国家气象局 免费接口 3:httpClientSocket ~~~ httpSocketServer 4:httpGet ~ httpPost 1:状态码_http http请求的响应码一般分为五类 1xx 2xx 3xx 4xx 5xx 1xx 临时性的消息 101:当客户端问服务端支不支持http2.0的时候,如果支持服…...
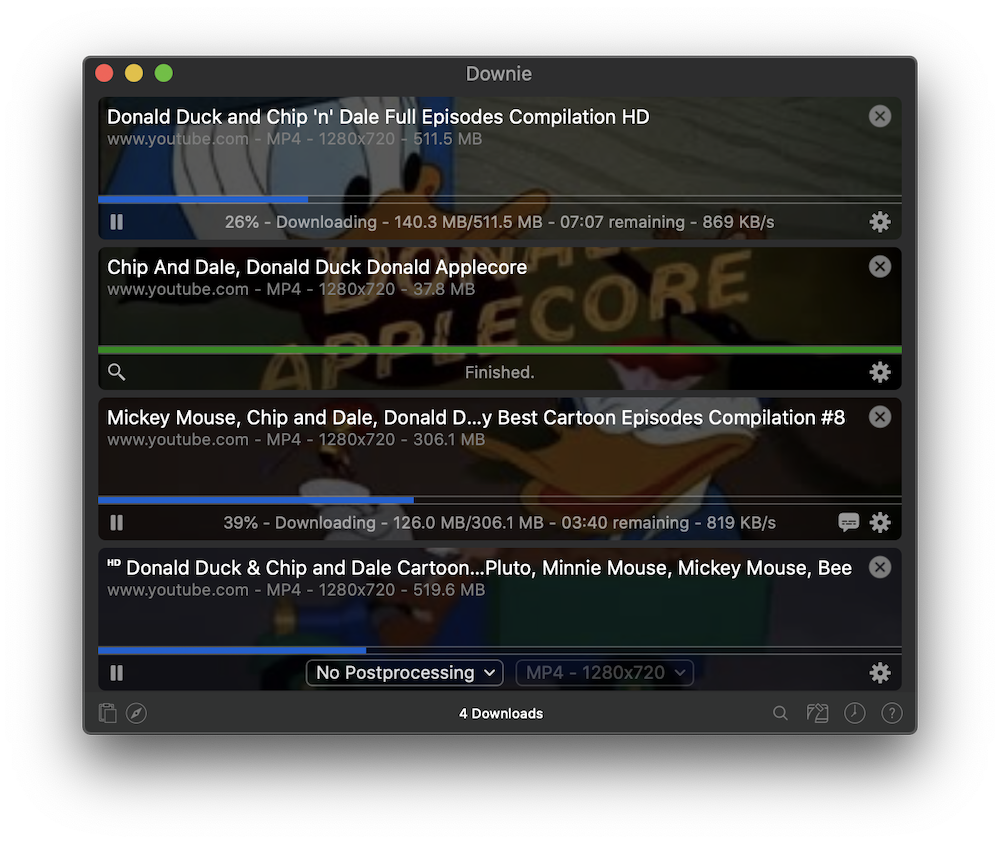
Downie4.6.7
Downie是Mac下一个简单的下载管理器,可以让您快速将不同的视频网站上的视频下载并保存到电脑磁盘里然后使用您的默认媒体播放器观看它们,文章末尾附下载地址。主要特点支持许多网站目前支持超过1,000个不同的网站(包括YouTube,Vim…...

重构是什么
重构 重构的主要目的是解决技术债务问题。它将混乱的代码转化为清晰的代码和简单的设计。 不错!但是“清晰的代码”具体是什么呢?以下是它的一些特征: 清晰的代码对其他程序员来说应该是一目了然的。 我不是在谈论超级复杂的算法。糟糕的…...
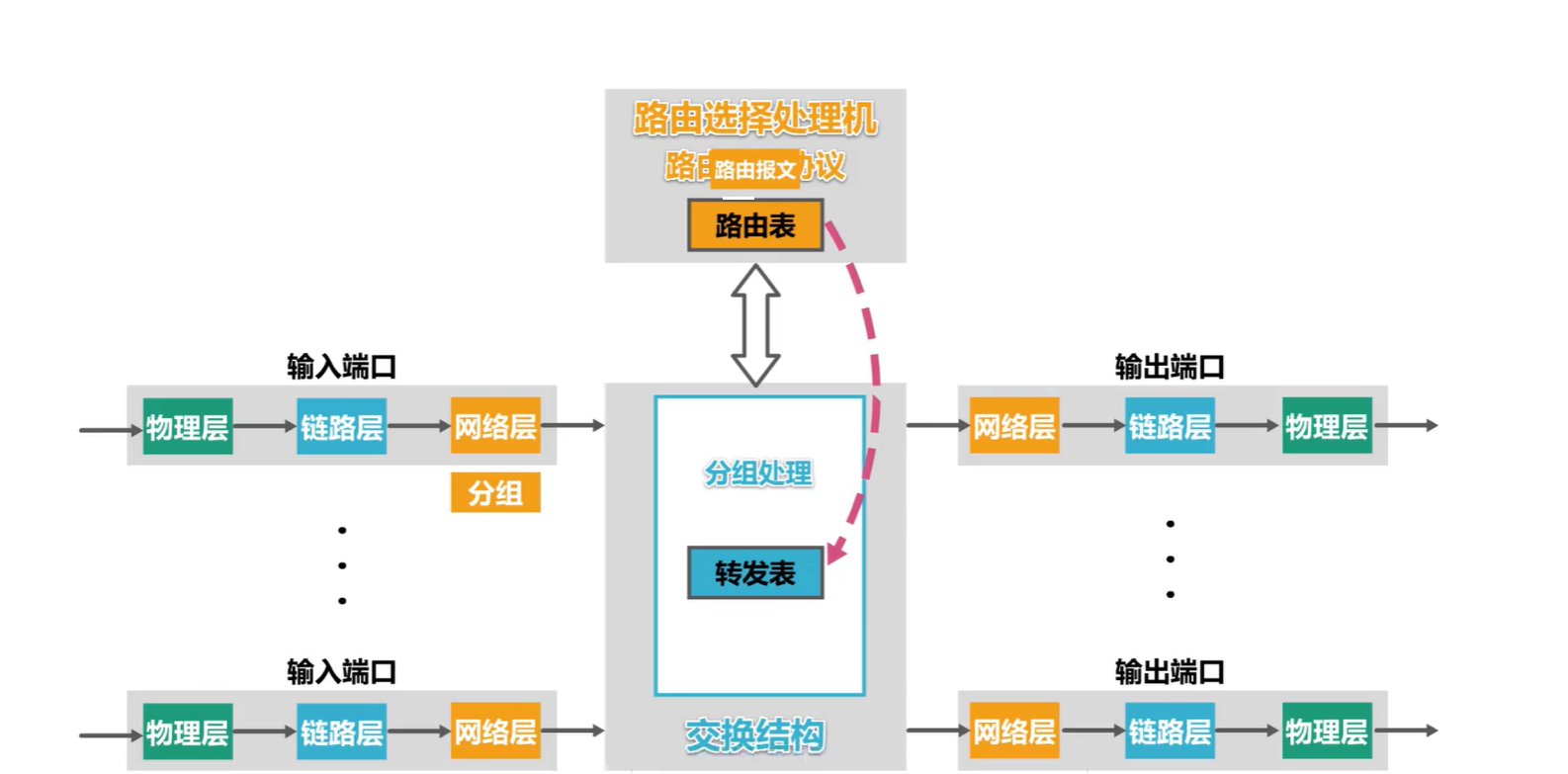
(考研湖科大教书匠计算机网络)第四章网络层-第六节1:路由选择协议概述
获取pdf:密码7281专栏目录首页:【专栏必读】考研湖科大教书匠计算机网络笔记导航 文章目录一:路由选择概述二:因特网采用的路由选择协议(1)特点(2)常见的路由选择协议三:…...
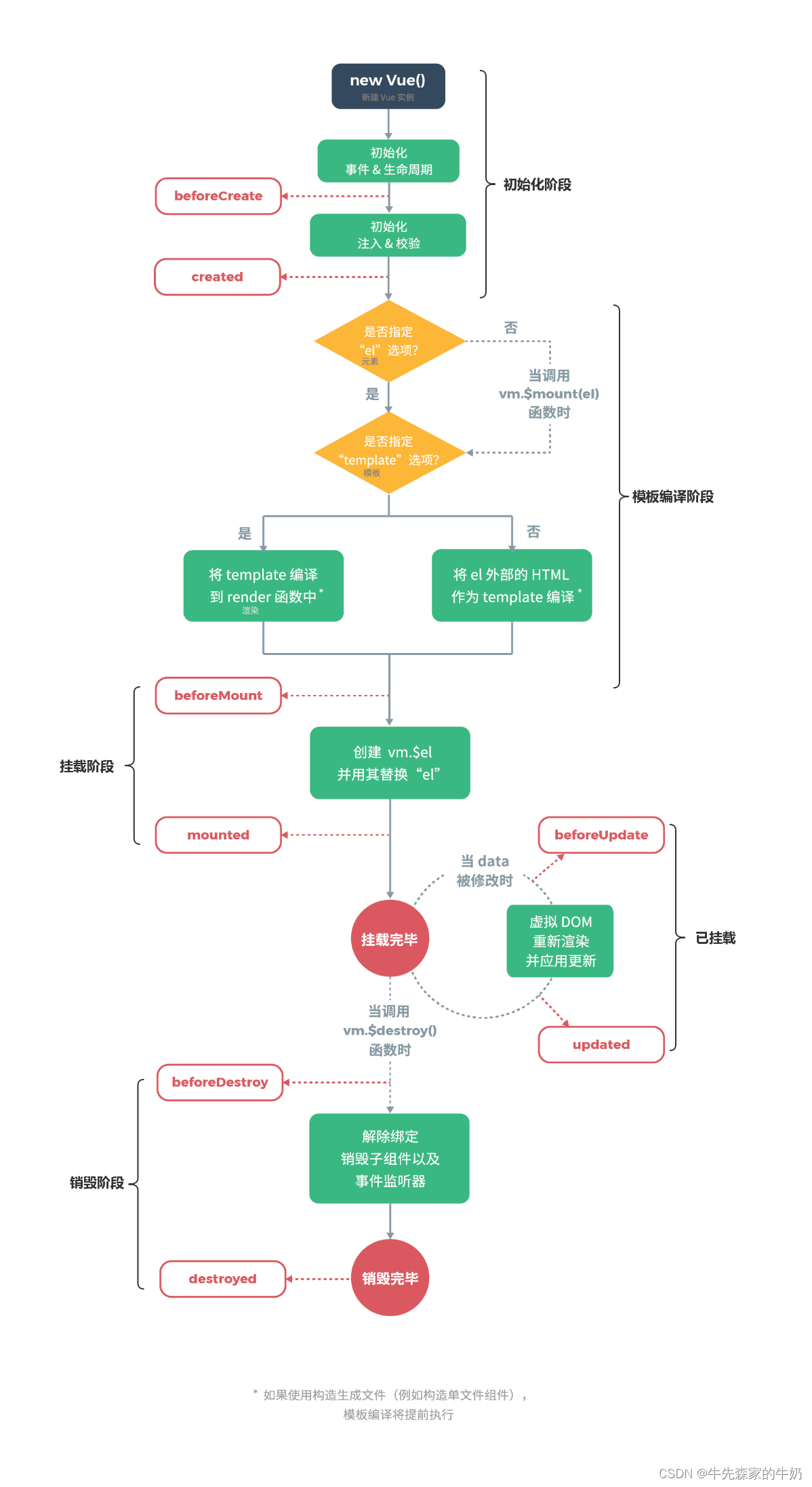
vue2源码之生命周期篇
vue2源码之生命周期篇vue2源码之生命周期篇生命周期流程图初始化阶段(new Vue)vue2源码之生命周期篇 生命周期流程图 从图中可以看到,Vue实例的生命周期大致可分为4个阶段: 初始化阶段:为Vue实例上初始化一些属性&am…...
:WebRTC中重要的API)
从零实现WebRTC(三):WebRTC中重要的API
文章目录一、createOffer二、createAnswer三、SetLocalDescription四、SetRemoteDescription五、addTrack六、addCandidate七、RTCPeerConnection重要事件一、createOffer aPromise myPeerConnection.createOffer(option) opeion { Audio True, Video True, iceReStart:f…...

如何用Rye与Docker打造无缝Python容器开发环境:完整实践指南
如何用Rye与Docker打造无缝Python容器开发环境:完整实践指南 【免费下载链接】rye a Hassle-Free Python Experience 项目地址: https://gitcode.com/gh_mirrors/ry/rye Rye是一款旨在提供无忧Python开发体验(a Hassle-Free Python Experience&am…...

MarkFlowy:基于智能感知的Markdown写作流工具设计与实现
1. 项目概述:一个为Markdown而生的高效写作流工具 如果你和我一样,每天的工作都离不开Markdown——写技术文档、整理项目笔记、构思博客文章,那你一定体会过那种在“专注写作”和“格式调整”之间反复横跳的痛苦。刚进入心流状态,…...

AI工作流自动化实践:Claude数据同步工具架构与实现
1. 项目概述与核心价值 最近在折腾AI应用集成的时候,发现一个挺有意思的项目,叫 cam901051/claude-sync 。乍一看这个标题,你可能会有点懵,这到底是干嘛的?简单来说,这是一个旨在实现Claude(…...

AI智能体开发工具栈全解析:从框架、可观测性到部署实战指南
1. 项目概述与核心价值如果你正在构建AI智能体应用,并且已经厌倦了在GitHub、Twitter和各种技术论坛里大海捞针般地寻找合适的开发工具,那么你很可能已经遇到了一个共同的痛点:生态碎片化。从让大语言模型(LLM)具备“记…...

别再到处问SQ01怎么用了!手把手教你从SQ03到SE93,搞定SAP Query自定义报表
SAP Query自定义报表实战:从零构建航班销售分析工具 每次月底做销售分析时,看着系统里那些标准报表总觉得差点意思——要么字段不全,要么格式不符合业务习惯。上周五下午,市场部的Lisa又急匆匆跑来问我:"能不能帮…...

如何快速掌握雀魂Mod Plus:解锁全角色皮肤的新手完全指南
如何快速掌握雀魂Mod Plus:解锁全角色皮肤的新手完全指南 【免费下载链接】majsoul_mod_plus 雀魂解锁全角色、皮肤、装扮等,支持全部服务器。 项目地址: https://gitcode.com/gh_mirrors/ma/majsoul_mod_plus 还在为无法获得心仪角色和皮肤而烦恼…...

文献阅读 260511-Wildfire damages and the cost-effective role of forest fuel treatments
Wildfire damages and the cost-effective role of forest fuel treatments 来自 <https://www.science.org/doi/10.1126/science.aea6463> ## Abstract: Gave the core question: Wildfires are among the most pressing environmental challenges of the 21st century,…...
)
【AI原生架构黄金法则】:SITS 2026现场实录的7条反直觉设计铁律(仅限首批参会专家内部流出)
AI原生应用架构设计:SITS 2026技术专家实战经验分享 更多请点击: https://intelliparadigm.com 第一章:SITS 2026现场共识与AI原生架构范式跃迁 在SITS 2026全球智能系统技术峰会上,来自37个国家的架构师、AI平台工程师与标准化组…...

FPGA上做图像压缩,别从零造轮子!聊聊DCT那些开源IP核与设计技巧
FPGA图像压缩实战:DCT开源IP核选型与架构优化指南 在嵌入式视觉系统开发中,JPEG图像压缩是FPGA工程师经常遇到的需求场景。当项目周期紧张且资源有限时,明智的开发者会优先考虑利用经过验证的开源IP核,而非从零开始实现离散余弦变…...

告别卡顿与臃肿:两种高效获取MATLAB Online账号的实战指南
1. 为什么你需要MATLAB Online? 如果你正在读这篇文章,大概率是因为你的电脑跑不动桌面版MATLAB了。我完全理解这种痛苦——当年我的老笔记本打开MATLAB要三分钟,运行个简单脚本风扇就狂转,更别提安装时那令人绝望的20GB硬盘占用…...