如何运维多集群数据库?58 同城 NebulaGraph Database 运维实践
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SktQW2qn-1676450580889)(https://www-cdn.nebula-graph.com.cn/nebula-website-5.0/images/blogs/58.%20Com%20Inc/58%E5%90%8C%E5%9F%8E_%E7%94%BB%E6%9D%BF%201.jpg)]
图计算业务背景介绍
我们为什么选择 NebulaGraph?
在公司各个业务线中,有不少部门都有着关系分析等图探索场景,随着业务发展,相关的需求越来越多。大量需求使用多模数据库来实现,开发成本和管理成本相对较高。
随着图数据库的发展,相关系统应用越来越成熟,于是引入专业图数据库来满足这部分业务需求的事务也提上日程。接下来要考虑的问题就是图数据库选型了。
首先,NebulaGraph 有大量互联网大厂应用案例,说明 NebulaGraph 可以应对海量数据的图探索场景。另外,目前 NebulaGraph 在 DB-Engines 在图数据库领域排名 14,而且增长势头强劲。排名靠前的图数据库,部分不开源或者单机版开源,场景受限。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zLDII3nP-1676450580891)(https://www-cdn.nebula-graph.com.cn/nebula-website-5.0/images/blogs/58.%20Com%20Inc/58-1.png)]
NebulaGraph 实际测试表现如何
在导入性能上,数据量小的时候 NebulaGraph 的导入效率稍慢于 neo4j,但在大数据量的时候 NebulaGraph 的导入明显优于其他两款图数据库。在 3 种查询场景下,NebulaGraph 的效率都明显高于 neo4j,与 HugeGraph 相比也有一定的优势。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wji9VUMP-1676450580892)(https://www-cdn.nebula-graph.com.cn/nebula-website-5.0/images/blogs/58.%20Com%20Inc/58-2.png)]
适用场景有哪些
公司有多种线上业务,工程复杂度和架构复杂度都较高,各个业务部门都需要专门的图数据库来实现对实体关系数据的处理和探索。
通过图数据库实现对任务依赖的运行时间进行监控,及时获取延迟任务、销售激励平台任务血缘关系处理、分析应用内部的类/方法级调用关系、业务风险数据分析、记录企业高管、法人、股东关系,用于签单业务等场景。
资源申请和集群管理方式
为了更好的管理和维护,图数据库在运维部门集中运维管理。用户按需在工单平台中提交申请即可,工单中填写详细的资源需求数据和性能需求指标,由运维同学统一审核交付集群资源。
公司目前服务器环境是自建机房,采用高配物理机,单机多实例混部数据库服务。为了实现规模化管理和维护,需要提前制定好实例标准和规则。
集群规模
得益于 NebulaGraph 良好的图计算能力,我们已经持续交付集群接近 20 套,目前还有业务部门在持续申请相关集群服务资源。
NebulaGraph 规范和架构设计
由于需要满足大量业务需求,未来会有大量的集群需要交付和维护。为了高效管理和运维规模化的集群,需要提前规划和制定规范。
版本规范
目前使用版本为 2.0.1
路径规范
- 程序路径为
/opt/soft/nebula201,该路径下有 bin、scripts、share 等,作为公共的服务依赖路径,从服务路径中抽离出来
同样,升级为 3.X 版本,只需要将程序路径抽离出来作为公共的服务依赖路径即可。
- 服务路径为
/work/nebulagraph+graph 端口,该路径下有 data、etc、logs、pids
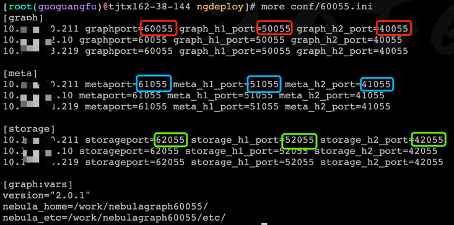
端口规范
- 集群之间端口递增 5,因为 storage 副本需要端口通信,通常是 storage 端口 -1,例如两套集群 graph 端口分别是 60000 和 60005;
- 每种服务端口和 http、http2 端口之间步长为 10000,例如 graph 端口是 60000,ws_http_port 就是 50000,ws_h2_port 就是 40000;
- 三种服务端口之间相差 1000,例如 graph 端口是 60000,meta 端口就是 61000,storage 端口就是 62000;
- 60000 graph 端口;50000 ws_http_port;40000 ws_h2_port
- 61000 meta 端口;51000 ws_http_port;41000 ws_h2_port
- 62000 storage 端口;52000 ws_http_port;42000 ws_h2_port
运维规范
第一,创建 space 需用 ngdb_ 左前缀,分片默认是节点数的 2 倍,副本数默认为 2,参考 CREATE SPACE ngdb_demo (partition_num=6,replica_factor=2,charset=utf8,collate=utf8_bin,vid_type=FIXED_STRING(128),atomic_edge=false) ON default;
第二,授予业务账号 DBA 角色:GRANT ROLE DBA ON ngdb_demo TO demo_wr;
第三,搭建一套 NebulaGraph 集群后,将内置账号 root 的密码重置,之后将 /work/nebulagraph+graph 端口 路径打包生成 rpm,作为标准安装包
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ArawDTB3-1676450580893)(https://www-cdn.nebula-graph.com.cn/nebula-website-5.0/images/blogs/58.%20Com%20Inc/58-3.png)]
服务请求直接通过 DNS 和网关服务到 Graph,方便计算和存储服务直接交互,由于是通过 DNS 访问,不对外暴露 Meta 节点信息,可以更灵活的运维,较少服务绑定 Meta 节点 ip 带来的运维代价。
这种架构限制了 Java 等驱动的访问,需要用其他驱动替代。
第四,基础集群套餐是 3 个 Graph 节点、3 个 Meta 节点、3 个 Storage 节点,在保证高可用的同时也能保证足够的处理能力。
基础集群分布在 3 台物理机上,存储和计算不需要过多的网络交互。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Rnk2HMGS-1676450580893)(https://www-cdn.nebula-graph.com.cn/nebula-website-5.0/images/blogs/58.%20Com%20Inc/58-4.png)]
集群部署自动化实现
为了能够一键部署服务,集中式管理服务,我们需要借助远程管理工具 Ansible,能帮我们做到快速部署。依据三种角色服务的端口规范,生成 Ansible 的配置文件。
- 由于将版本信息写到了配置文件中,在兼容多版本场景下,只需要在
bootstrap.yml文件中增加相应判断即可,主程序兼容多版本成本非常有限。
部署实例时,根据 graph 角色分发文件,也可以每个节点单独分发文件。
- 依据三种角色,分别分发配置文件到目的路径下,并且按照文件命名规则生成最终配置文件。
more bootstrap.yml
- hosts: graphbecome: yesremote_user: roottasks:- name: init elasticsearch file on datacommand: cp -r /opt/soft/nebulagraph201 {{ nebula_home }}
- hosts: graphbecome: yesremote_user: roottasks:- name: init config graphfile on master {{ version }}template: src=/opt/soft/ngdeploy/conf/templates/201graph dest="{{ nebula_etc }}nggraphd.conf" owner=root group=root mode=0755
- hosts: metabecome: yesremote_user: roottasks:- name: init config metafile on master {{ version }}template: src=/opt/soft/ngdeploy/conf/templates/201meta dest="{{ nebula_etc }}ngmetad.conf" owner=root group=root mode=0755
- hosts: storagebecome: yesremote_user: roottasks:- name: init config storagefile on master {{ version }}template: src=/opt/soft/ngdeploy/conf/templates/201storage dest="{{ nebula_etc }}ngstoraged.conf" owner=root group=root mode=0755
配置文件的分发最为关键,有较多变量需要处理,这些变量需要提前在 Ansible 的配置文件中定义,nebulagraphd 路径规范和服务端口需要使用 graphport、meta_server_addrs 需要用到 for 循环语法实现。
more templates/201graph
########## basics ##########
--daemonize=true
--pid_file=/work/nebulagraph{{ graphport }}/pids/nebula-graphd.pid
--enable_optimizer=true
########## logging ##########
--log_dir=/work/nebulagraph{{ graphport }}/logs
--minloglevel=0
--v=0
--logbufsecs=0
--redirect_stdout=true
--stdout_log_file=graphd-stdout.log
--stderr_log_file=graphd-stderr.log
--stderrthreshold=2########## query ##########
--accept_partial_success=false########## networking ##########
--meta_server_addrs={% for host in groups.graph%}{%if loop.last%}{{ hostvars[host].inventory_hostname }}:{{ hostvars[host].metaport }}{%else%}{{hostvars[host].inventory_hostname }}:{{hostvars[host].metaport}}
,{%endif%}{% endfor %}--local_ip={{inventory_hostname}}
--listen_netdev=any
--port={{ graphport }}
--reuse_port=false
--listen_backlog=1024
--client_idle_timeout_secs=0
--session_idle_timeout_secs=0
--num_accept_threads=1
--num_netio_threads=0
--num_worker_threads=0
--ws_ip={{inventory_hostname}}
--ws_http_port={{ graph_h1_port }}
--ws_h2_port={{ graph_h2_port }}
--default_charset=utf8
--default_collate=utf8_bin########## authorization ##########
--enable_authorize=true########## Authentication ##########
--auth_type=password
同样,nebulametad 服务配置文件路径规范和服务端口需要使用 metahport、meta_server_addrs 需要用到 for 循环语法实现。
more templates/201meta
########## basics ##########
--daemonize=true
--pid_file=/work/nebulagraph{{graphport}}/pids/nebula-metad.pid
########## logging ##########
--log_dir=/work/nebulagraph{{graphport}}/logs
--minloglevel=0
--v=0
--logbufsecs=0
--redirect_stdout=true
--stdout_log_file=metad-stdout.log
--stderr_log_file=metad-stderr.log
--stderrthreshold=2########## networking ##########
--meta_server_addrs={% for host in groups.graph%}{%if loop.last%}{{ hostvars[host].inventory_hostname }}:{{ hostvars[host].metaport }}{%else%}{{hostvars[host].inventory_hostname }}:{{hostvars[host].metaport}}
,{%endif%}{% endfor %}--local_ip={{inventory_hostname}}
--port={{metaport}}
--ws_ip={{inventory_hostname}}
--ws_http_port={{meta_h1_port}}
--ws_h2_port={{meta_h2_port}}
########## storage ##########
--data_path=/work/nebulagraph{{graphport}}/data/meta########## Misc #########
--default_parts_num=100
--default_replica_factor=1
--heartbeat_interval_secs=10
--timezone_name=CST-8
同样,nebulastoraged 服务配置文件路径规范和服务端口需要使用 storageport、meta_server_addrs 需要用到 for 循环语法实现。
more templates/201graph
########## basics ##########
--daemonize=true
--pid_file=/work/nebulagraph{{ graphport }}/pids/nebula-graphd.pid
--enable_optimizer=true
########## logging ##########
--log_dir=/work/nebulagraph{{ graphport }}/logs
--minloglevel=0
--v=0
--logbufsecs=0
--redirect_stdout=true
--stdout_log_file=graphd-stdout.log
--stderr_log_file=graphd-stderr.log
--stderrthreshold=2########## query ##########
--accept_partial_success=false########## networking ##########
--meta_server_addrs={% for host in groups.graph%}{%if loop.last%}{{ hostvars[host].inventory_hostname }}:{{ hostvars[host].metaport }}{%else%}{{hostvars[host].inventory_hostname }}:{{hostvars[host].metaport}}
,{%endif%}{% endfor %}--local_ip={{inventory_hostname}}
--listen_netdev=any
--port={{ graphport }}
--reuse_port=false
--listen_backlog=1024
--client_idle_timeout_secs=0
--session_idle_timeout_secs=0
--num_accept_threads=1
--num_netio_threads=0
--num_worker_threads=0
--ws_ip={{inventory_hostname}}
--ws_http_port={{ graph_h1_port }}
--ws_h2_port={{ graph_h2_port }}
--default_charset=utf8
--default_collate=utf8_bin########## authorization ##########
--enable_authorize=true########## Authentication ##########
--auth_type=password
需要部署新集群时,需要按照规则和目的服务器信息生成 Ansible 的配置文件,然后调用 ansible-playbook,按照 bootstrap.yml 定义的行为执行即可。
部署完毕之后,需要按照服务角色依次启动 start.yml 的脚本文件提前定义好三种服务的启动命令和配置文件。
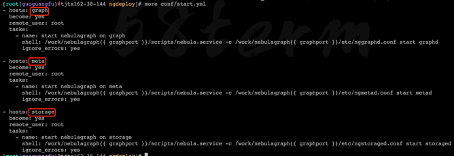
调用 ansible-playbook,根据 start.yml 的脚本文件依次执行三种服务的启动命令即可。

可视化图探索平台
有赖于将目标 host 前置于 Web 平台的设置,我们只需要对多个项目的开发提供一套公共的 Web 平台即可,减少了 NebulaGraph 集群的组件数量,有别于 ELK 的标准架构。
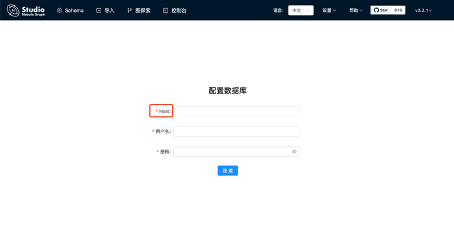
开发可以通过 NebulaGraph Studio 实现可视化管理数据,轻松实现数据导入和导出,便于用户探索数据关系。直接呈现出点边关系,使探索图数据之间的关系更为直观。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m103e1Go-1676450580913)(https://www-cdn.nebula-graph.com.cn/nebula-website-5.0/images/blogs/58.%20Com%20Inc/58-13.png)]
以上是我们在规模化管理维护 NebulaGraph 集群过程中的一些经验,希望对大家有些帮助。
交流图数据库技术?加入 NebulaGraph 交流群请先填写下你的 NebulaGraph 名片,NebulaGraph 小助手会拉你进群~~
NebulaGraph 的开源地址:https://github.com/vesoft-inc/nebula 如果你觉得使用体验还不错的话,给我们的 GitHub 点个 ❤️ 鼓励下开源路上的我们呢~
相关文章:
如何运维多集群数据库?58 同城 NebulaGraph Database 运维实践
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SktQW2qn-1676450580889)(https://www-cdn.nebula-graph.com.cn/nebula-website-5.0/images/blogs/58.%20Com%20Inc/58%E5%90%8C%E5%9F%8E_%E7%94%BB%E6%9D%BF%201.jpg)] 图计算业务背景介绍 我们为什…...
尚医通(十四)Spring Cloud GateWay网关 | 跨域 | 权限认证
目录一、网关基本概念1、API网关介绍2、Spring Cloud Gateway3、Spring Cloud Gateway核心概念二、创建service_gateway模块(网关服务)1、创建service_gateway模块2、在pom.xml引入依赖3、编写application.properties配置文件4、编写启动类5、前端端口号…...

PO模式在Selenium中简单实践
初识PO模式 PO(PageObject)是一种设计模式。简单来说就是把一些繁琐的定位方法、元素操作方式等封装到类中,通过类与类之间的调用完成特定操作。 PO被认为是自动化测试项目开发实践的最佳设计模式之一。 在学习PO模式前,可以先…...
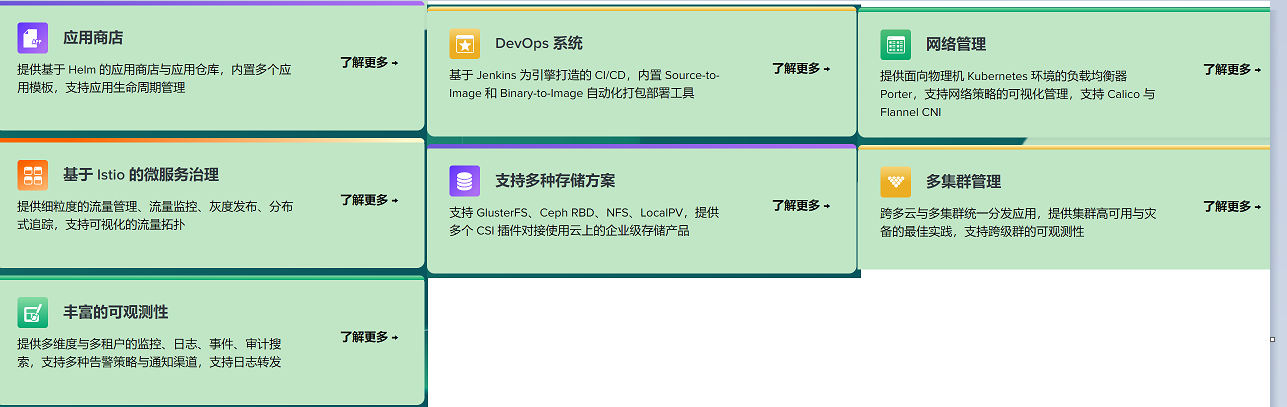
KubeSphere
文章目录一、概述二、最小化安装 KubeSphere2.1 前提2.2 安装 nfs 服务器一、概述 KubeSphere是在Kubernetes之上构建的以应用为中心的企业级分布式容器平台,提供简单易用的操作界面以及向导式操作方式,在降低用户使用容器调度平台学习成本的同时&#…...
必备)
JAVA基础阶段面试题(关键点)必备
1、简述什么是 JDK、JRE 和 JVM? JDK : 开发工具包JRE : 运行时环境JVM : java虚拟机2、写出Java的四类八种基本数据类?整数 byte short int long小数(浮点) float double布尔 boolean字符 char3、& 和 && 的区别 ?& 符号的左右两边,无…...
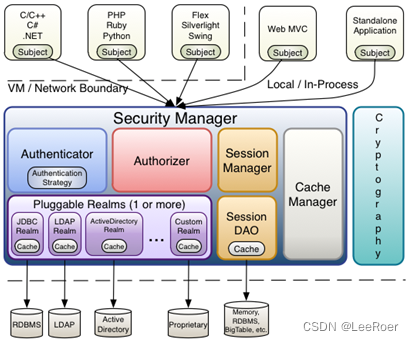
Shiro简介
介绍 ApacheShiro 是一个功能强大且易于使用的 Java 安全(权限)框架。Shiro 可以完成:认证、授权、加密、会话管理、与 Web集成、缓存等。借助Shiro 您可以快速轻松地保护任何应用程序一一从最小的移动应用程序到最大的 Web 和企业应用程序。 1.2:为什么要用 shiro 自2003年以…...

cmu 445 poject 3笔记
2022年的任务 https://15445.courses.cs.cmu.edu/fall2022/project3/ task1, 从磁盘读取数据的算子 task2, 聚合和join算子 task3, sort,limit,topn算子,以及sortlimit->TopN优化 leaderboard没做 本文不写代码,只记录遇到的一些思维盲点 Task1 scan…...

CHAPTER 2 Zabbix界面操作
Zabbix界面操作2.1 Zabbix界面操作1.zabbix的web界面安装2.添加监控信息3.查看监控内容4.查看图像2.2 自定义监控与监控报警1.自定义监控1.1 说明1.2 预备知识2.实现自定义监控2.1 自定义语法2.2 agent注册2.3 在server端注册(web操作)2.4 查看监控图形2.3 监控报警1.第三方报警…...

keep-alive的使用-及遇到的问题
被keep-alive包括的的组件,当组件切换是不是走销毁流程,而是缓存起来 keep-alive有三个参数include匹配name名被缓存,exclude匹配name名不会被缓存,max被缓存组件数量 不写,组件默认全部缓存 <keep-alive ><…...
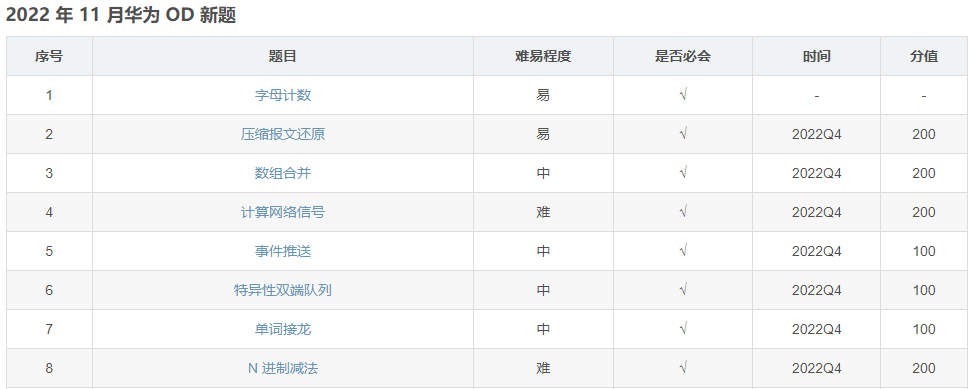
华为OD面试经验分享,尤其注意机试题部分
文章目录招聘流程和背景介绍面试准备机试题目类型和解答技巧在算法部分在操作系统部分面试官提问和答题技巧面试总结和建议推荐一些华为 od 常见的机试题题目:两数之和题目:二叉树的遍历题目:链表反转题目:最大子序和招聘流程和背…...

【Java】String、StringBuffer、StringBuilder的区别
一、String 由 char[] 数组构成,使用了 final 修饰,String的值是不可变的,这就导致每次对String的操作都会生成新的String对象,然后把指针指向新的引用对象,不仅效率低下,而且浪费大量优先的内存空间。 二…...

iOS开发:对Block使用的一次研究总结
在开发中Block是经常使用的,那我们就得知其然,知其所以然。 Block是什么? Block可以封装一个匿名函数为对象,并捕获上下文所需的数据,并传给目标对象在适当的时候回调。我们使用Block的目的其实就是回调传值,那我们去看看Block的底层,再深入了解一下Block。 Block的底…...

Spark 3.1.1 shuffle fetch 导致shuffle错位的问题
背景 最近从数据仓库小组那边反馈了一个问题,一个SQL任务出来的结果不正确,重新运行一次之后就没问题了,具体的SQL如下: select col1,count(1) as cnt from table1 where dt 20230202 group by col1 having count(1) > 1这个问题是偶发…...
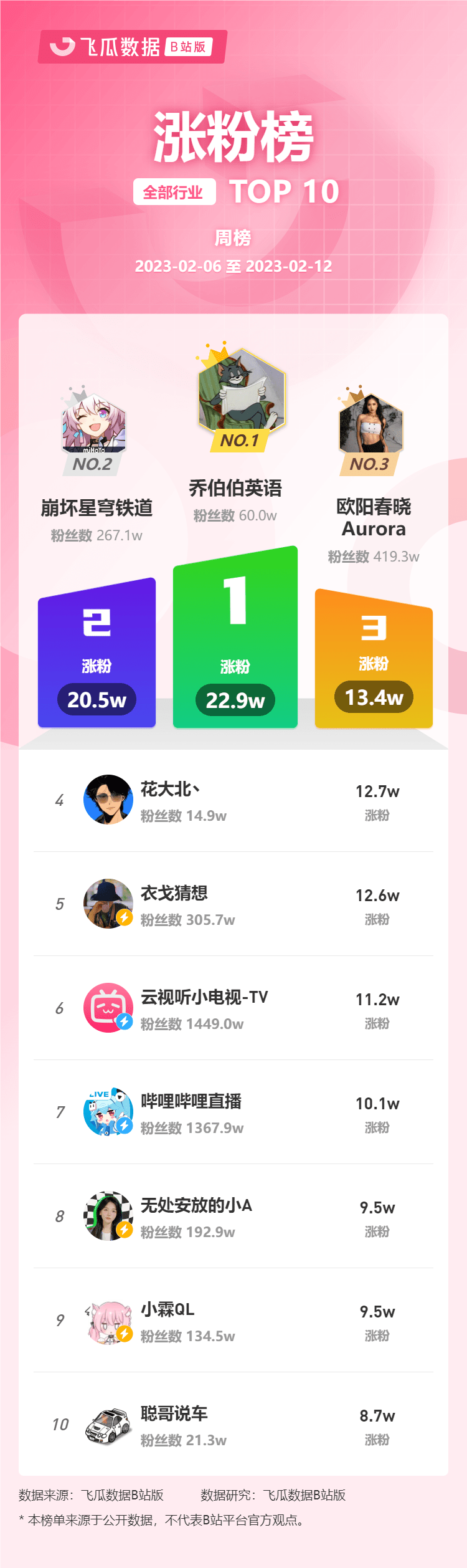
2月第2周榜单丨飞瓜数据B站UP主排行榜(哔哩哔哩平台)发布!
飞瓜轻数发布2023年2月6日-2月12日飞瓜数据UP主排行榜(B站平台),通过充电数、涨粉数、成长指数三个维度来体现UP主账号成长的情况,为用户提供B站号综合价值的数据参考,根据UP主成长情况用户能够快速找到运营能力强的B站…...
Jdk19 动态编译 Java源码为 Class 文件
动态编译 Java 源码为 Class一.背景1.Jdk 版本2.需求二.Java 源码动态编译实现1.Maven 依赖2.源码包装类3.Java 文件对象封装类4.文件管理器封装类5.类加载器6.类编译器三.动态编译测试1.普通测试类2.接口实现类3.测试四.用动态编译 Class 替换 SpringBoot 的 Bean(…...
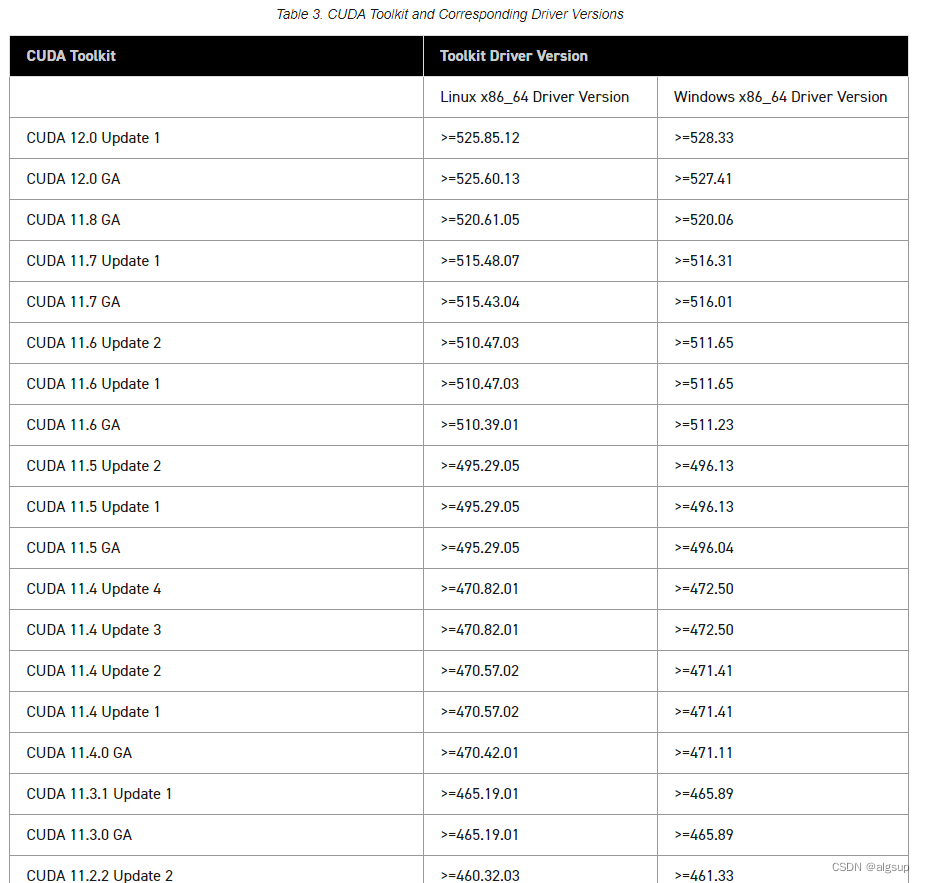
安装 GPU 版本的 tensorflow 完整版本
前言: 之前安装的 CPU 版本的 tensorflow 一直出问题,索性就直接安装 GPU 版本的 tensorflow 了(有了GPU 就不能浪费)。 安装过程: 1)看自己有无 GPU,找到对应 GPU 的版本:任务管理…...

BOM编程-设置地址栏上的URL
<!DOCTYPE html> <html> <head> <meta charset"utf-8"> <title>设置地址栏上的URL</title> </head> <body> <script> function go(){ // 获…...
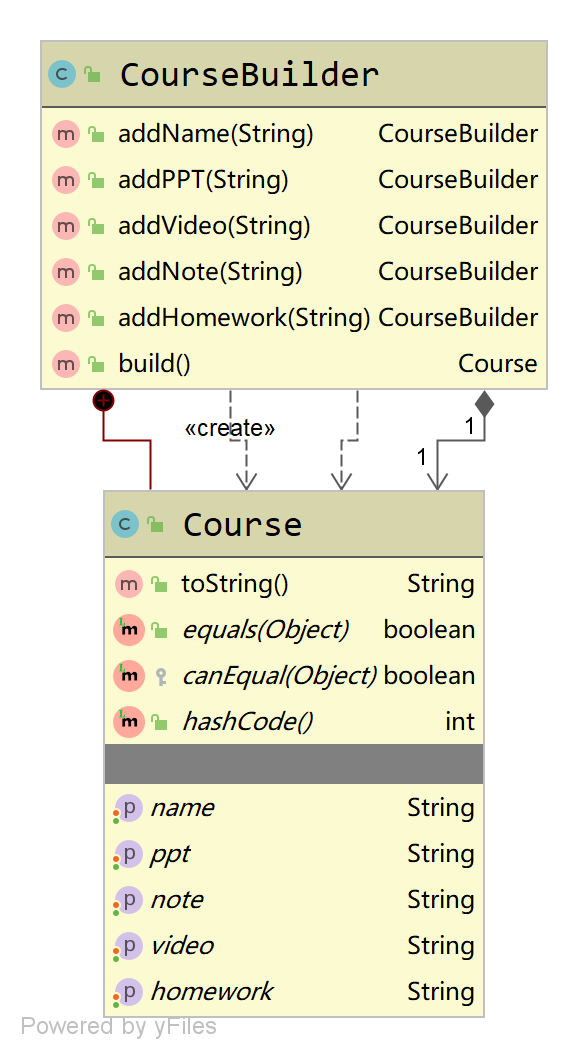
设计模式之原型模式与建造者模式详解和应用
目录1 原型模式1.1 原型模式定义1.2 原型模式的应用场景1.3 原型模式的通用写法(浅拷贝)1.4 使用序列化实现深度克隆1.5 克隆破坏单例模式1.6 原型模式在源码中的应用1.7 原型模式的优缺点1.8 总结2 建造者模式2.1 建造者模式定义2.2 建造者模式的应用场…...

C语言(函数和递归)
函数是完成特定任务的独立程序代码单元。 目录 一.函数 1.创建一个简单的函数 2.定义带形式参数的函数 3.使用return从函数中返回值 二.递归 一.函数 1.创建一个简单的函数 #include <stdio.h> void print(void); //函数原型 int main(){ print(); //函…...

快乐的shell命令行
快乐的shell命令行 PART1——基础 1.权限 #超级用户权限$普通用户 2.复制粘贴 复制:鼠标左键沿着文本拖动高亮的文本被复制到X管理的缓冲区(或者双击一个单词)粘贴:鼠标中键 3.简单命令 时间和日期date当前月份的日历cal磁…...

从DataOperation接口到QuickSort实现:探究适配器模式在算法整合中的应用
1. 适配器模式:解决接口不兼容的桥梁 想象一下你从国外带回来一个三脚插头的电器,但家里的插座都是两孔的。这时候你会怎么做?大多数人会选择买一个转换插头。在编程世界里,适配器模式就是这个万能的"转换插头"。 最近我…...

手把手教你用Simulink搭建BUCK电路:从主电路到PID整定的保姆级流程
手把手教你用Simulink搭建BUCK电路:从主电路到PID整定的保姆级流程 电力电子技术作为现代能源转换的核心,BUCK电路因其高效的降压特性被广泛应用于电源设计领域。对于初学者而言,理论知识与实际仿真之间往往存在一道难以跨越的鸿沟——明明理…...
)
AI大模型选型生死线(2026企业级部署避坑指南)
更多请点击: https://intelliparadigm.com 第一章:AI大模型选型生死线(2026企业级部署避坑指南) 企业在2026年落地AI大模型时,选型失误的代价已远超算力采购成本——模型架构错配、上下文长度硬伤、商用许可证模糊、推…...

STM32F103C8T6驱动5V LCD1602,开漏输出+上拉电阻的硬件连接与代码避坑指南
STM32F103C8T6驱动5V LCD1602的硬件设计与代码实战指南 当3.3V的STM32遇到5V供电的LCD1602模块时,电平不匹配问题常常让初学者头疼不已。本文将深入解析开漏输出配合上拉电阻的解决方案,通过硬件原理分析、示波器实测对比和完整代码示例,带你…...

CSS 混合模式完全指南
CSS 混合模式完全指南 引言 CSS 混合模式(Blend Modes)是一种强大的视觉效果工具,它允许你控制多个元素或图层如何混合在一起。本文将深入探讨各种混合模式的用法和高级技巧。 混合模式类型 基础混合模式 模式效果描述normal默认模式…...

S32K144开发板调试实战:除了点灯,如何用S32DS的调试窗口快速排查变量异常问题?
S32K144开发板调试实战:变量异常排查与高效调试技巧 调试嵌入式系统时,最令人头疼的莫过于程序看似正常运行,但某些变量值却莫名其妙地偏离预期。作为一名长期使用S32 Design Studio(S32DS)进行S32K144开发的工程师&a…...

PyTorch数据集加载进阶:除了CIFAR10,你的自定义数据该怎么准备?
PyTorch数据集加载进阶:从CIFAR10到自定义数据的深度实践 在深度学习项目中,数据准备往往比模型构建更耗时。许多开发者能熟练使用torchvision.datasets加载标准数据集,却对自定义数据束手无策。本文将带你深入PyTorch数据加载机制ÿ…...

从入门到精通:Systrace性能分析实战指南
1. Systrace入门:认识Android性能分析利器 第一次打开Systrace报告时,我完全被那些彩色线条和条形图搞懵了。这玩意儿看起来就像地铁线路图一样复杂,但别担心,它其实是Android开发者最得力的性能分析助手。Systrace是Android SDK自…...

pcb设计-器件:二极管
一、二极管的介绍 伏安特性曲线 二、二极管的整流功能 由于二极管存在导通压降以及反向截止的特性,对于交流电压,反向电压全部被截止,正向电压的最大值会距离峰值会有0.7v的压降。 在交流电路中,二极管限制了电容不能放电…...

Zotero Connector进阶指南:解锁知乎内容完整抓取与Snapshot模式精准切换
1. 为什么你的知乎内容总是只保存快照? 很多初次使用Zotero Connector抓取知乎内容的朋友都会遇到一个头疼的问题:明明想保存完整的文章内容,结果在Zotero里只能看到一个网页快照。这个问题其实和Zotero Connector的默认设置有关。Zotero Co…...