Hadoop集群配置
一、系统文件配置
集群部署规划
NameNode和SecondaryNameNode不要安装在同一台服务器
ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode放在同一台机器上。
这里装了四台机器,ant151,ant152,ant153,ant154。
ant151 | ant152 | ant153 | ant154 |
NameNode | NameNode | ||
DataNode | DataNode | DataNode | DataNode |
NodeManager | NodeManager | NodeManager | NodeManager |
ResourceManager | ResourceManager | ||
JournalNode | JournalNode | JournalNode | |
DFSZKFController | DFSZKFController | ||
zk0 | zk1 | zk2 |
配置文件说明
Hadoop配置文件分为默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件。
core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml四个配置文件放在$HADOOP_HOME/etc/hadoop路径下。
3.配置集群
core-site.xml
<property><name>fs.defaultFS</name><value>hdfs://gky</value><description>逻辑名称,必须与hdfs-site.xml中的dfs.nameservices值保持一致</description></property><property><name>hadoop.tmp.dir</name><value>/opt/soft/hadoop313/tmpdata</value><description>namenode上本地的hadoop临时文件夹</description></property><property><name>hadoop.http.staticuser.user</name><value>root</value><description>默认用户</description></property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value><description></description></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value><description></description></property><property><name>io.file.buffer.size</name><value>131072</value><description>读写文件的buffer大小为:128K</description></property><property><name>ha.zookeeper.quorum</name><value>ant151:2181,ant152:2181,ant153:2181</value><description></description></property><property><name>ha.zookeeper.session-timeout.ms</name><value>10000</value><description>hadoop链接zookeeper的超时时长设置为10s</description></property>hdfs-site.xml
<property><name>dfs.replication</name><value>3</value><description>Hadoop中每一个block的备份数</description></property><property><name>dfs.namenode.name.dir</name><value>/opt/soft/hadoop313/data/dfs/name</value><description>namenode上存储hdfs名字空间元数据目录</description></property><property><name>dfs.datanode.data.dir</name><value>/opt/soft/hadoop313/data/dfs/data</value><description>datanode上数据块的物理存储位置</description></property><property><name>dfs.namenode.secondary.http-address</name><value>ant151:9869</value><description></description></property><property><name>dfs.nameservices</name><value>gky</value><description>指定hdfs的nameservice,需要和core-site.xml中保持一致</description></property><property><name>dfs.ha.namenodes.gky</name><value>nn1,nn2</value><description>gky为集群的逻辑名称,映射两个namenode逻辑名</description></property><property><name>dfs.namenode.rpc-address.gky.nn1</name><value>ant151:9000</value><description>namenode1的RPC通信地址</description></property><property><name>dfs.namenode.http-address.gky.nn1</name><value>ant151:9870</value><description>namenode1的http通信地址</description></property><property><name>dfs.namenode.rpc-address.gky.nn2</name><value>ant152:9000</value><description>namenode2的RPC通信地址</description></property><property><name>dfs.namenode.http-address.gky.nn2</name><value>ant152:9870</value><description>namenode2的http通信地址</description></property><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://ant151:8485;ant152:8485;ant153:8485/gky</value><description>指定NameNode的edits元数据的共享存储位置(JournalNode列表)</description></property><property><name>dfs.journalnode.edits.dir</name><value>/opt/soft/hadoop313/data/journaldata</value><description>指定JournalNode在本地磁盘存放数据的位置</description></property> <!-- 容错 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value><description>开启NameNode故障自动切换</description></property><property><name>dfs.client.failover.proxy.provider.gky</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value><description>失败后自动切换的实现方式</description></property><property><name>dfs.ha.fencing.methods</name><value>sshfence</value><description>防止脑裂的处理</description></property><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value><description>使用sshfence隔离机制时,需要ssh免密登陆</description></property> <property><name>dfs.permissions.enabled</name><value>false</value><description>关闭HDFS操作权限验证</description></property><property><name>dfs.image.transfer.bandwidthPerSec</name><value>1048576</value><description></description></property> <property><name>dfs.block.scanner.volume.bytes.per.second</name><value>1048576</value><description></description></property>mapred-site.xml
<property><name>mapreduce.framework.name</name><value>yarn</value><description>job执行框架: local, classic or yarn</description><final>true</final></property><property><name>mapreduce.application.classpath</name><value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/hadoop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/opt/soft/hadoop313/share/hadoop/yarn/lib/*</value></property><property><name>mapreduce.jobhistory.address</name><value>ant151:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>ant151:19888</value></property><property><name>mapreduce.map.memory.mb</name><value>1024</value><description>map阶段的task工作内存</description></property><property><name>mapreduce.reduce.memory.mb</name><value>2048</value><description>reduce阶段的task工作内存</description></property>yarn-site.xml
<property><name>yarn.resourcemanager.ha.enabled</name><value>true</value><description>开启resourcemanager高可用</description></property><property><name>yarn.resourcemanager.cluster-id</name><value>yrcabc</value><description>指定yarn集群中的id</description></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value><description>指定resourcemanager的名字</description></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>ant153</value><description>设置rm1的名字</description></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>ant154</value><description>设置rm2的名字</description></property><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>ant153:8088</value><description></description></property><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>ant154:8088</value><description></description></property> <property><name>yarn.resourcemanager.zk-address</name><value>ant151:2181,ant152:2181,ant153:2181</value><description>指定zk集群地址</description></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>运行mapreduce程序必须配置的附属服务</description></property><property><name>yarn.nodemanager.local-dirs</name><value>/opt/soft/hadoop313/tmpdata/yarn/local</value><description>nodemanager本地存储目录</description></property><property><name>yarn.nodemanager.log-dirs</name><value>/opt/soft/hadoop313/tmpdata/yarn/log</value><description>nodemanager本地日志目录</description></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>2048</value><description>resource进程的工作内存</description></property><property><name>yarn.nodemanager.resource.cpu-vcores</name><value>2</value><description>resource工作中所能使用机器的内核数</description></property><property><name>yarn.scheduler.minimum-allocation-mb</name><value>256</value><description></description></property><property><name>yarn.log-aggregation-enable</name><value>true</value><description></description></property><property><name>yarn.log-aggregation.retain-seconds</name><value>86400</value><description>日志保留多少秒</description></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value><description></description></property><property><name>yarn.application.classpath</name><value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/hadoop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/opt/soft/hadoop313/share/hadoop/yarn/lib/*</value><description></description></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value><description></description></property>hadoop-env.sh
export JAVA_HOME=/opt/soft/jdk180
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
workers
ant151
ant152
ant153
ant154二、集群首次启动
启动zk集群
可以直接运行脚本文件
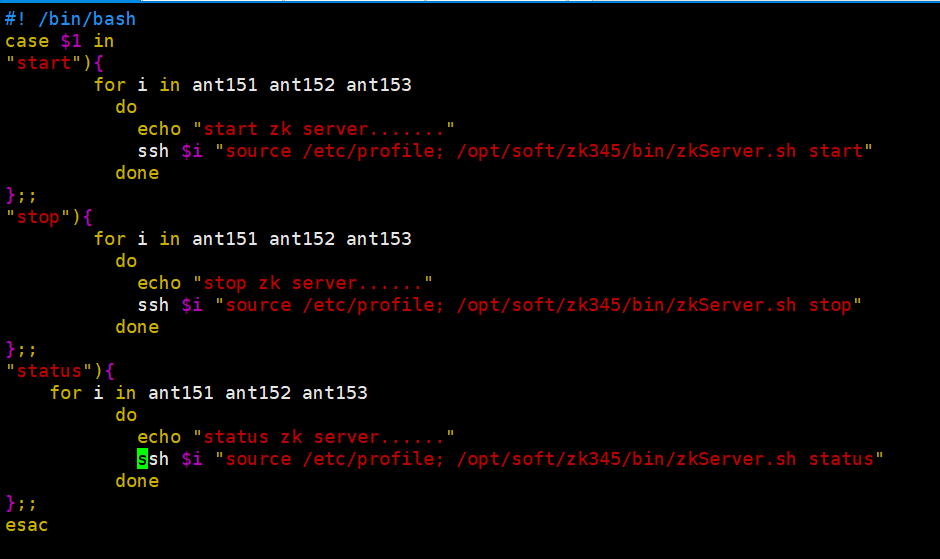
代码:
[root@ant151 shell]# ./zkop.sh start 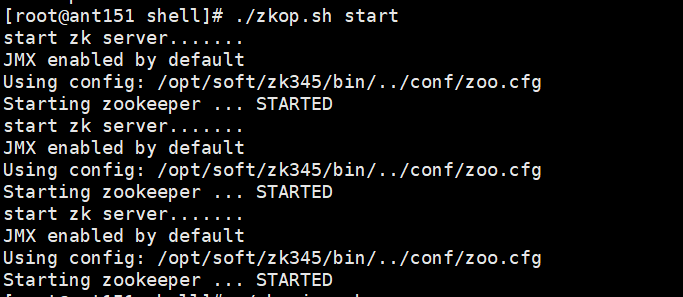
启动ant151,ant152,ant153的journalnode服务:
[root@ant151 shell]# hdfs --daemon start journalnode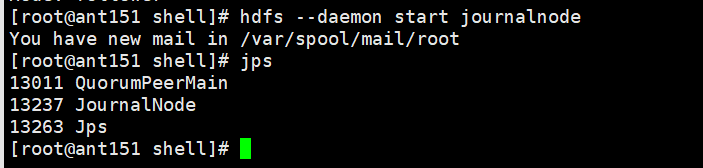
在ant151格式化hfds namenode:
[root@ant151 shell]# hdfs namenode -format在ant151启动namenode服务:hdfs --daemon start namenode
[root@ant151 shell]# hdfs --daemon start namenode
在ant152机器上同步namenode信息
[root@ant151 shell]# hdfs namenode -bootstrapStandby
在ant152启动namenode服务:hdfs --daemon start namenode
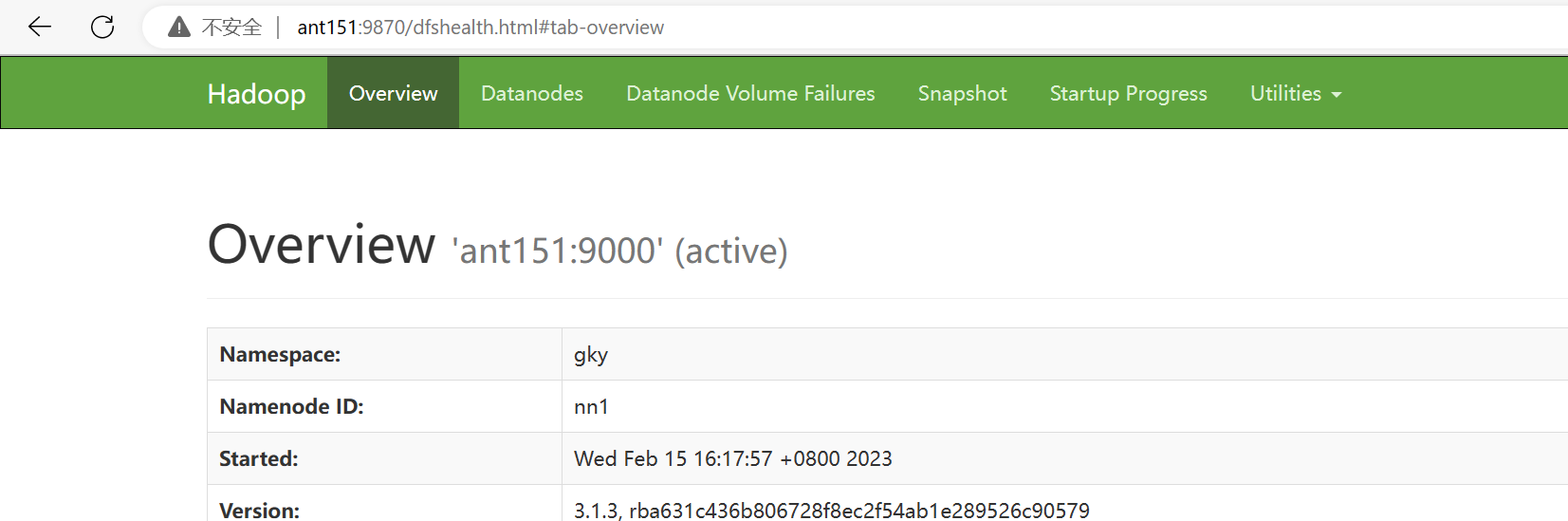
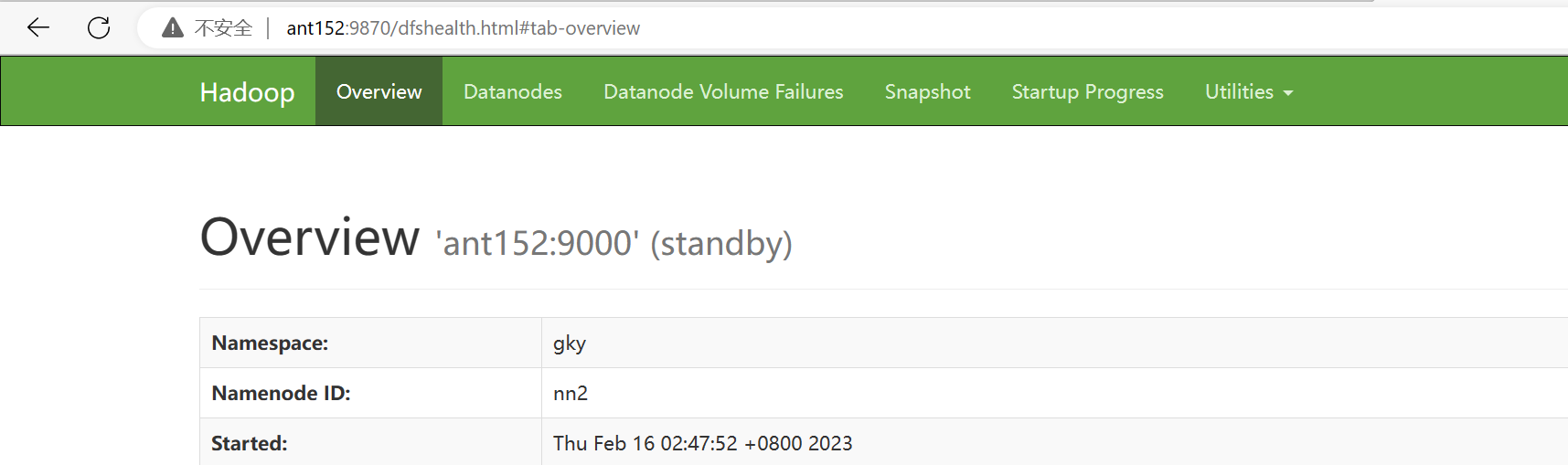
[root@ant152 soft]# hdfs --daemon start namenode查看namenode节点状态:hdfs haadmin -getServiceState nn1|nn2
[root@ant152 soft]# hdfs haadmin -getServiceState nn1
关闭所有dfs有关的服务
[root@ant151 soft]# stop-dfs.sh
格式化zk
[root@ant151 soft]# hdfs zkfc -formatZK
启动dfs
[root@ant151 soft]# start-dfs.sh
启动yarn: [root@ant151 soft]# start-yarn.sh
[root@ant151 soft]# start-yarn.sh
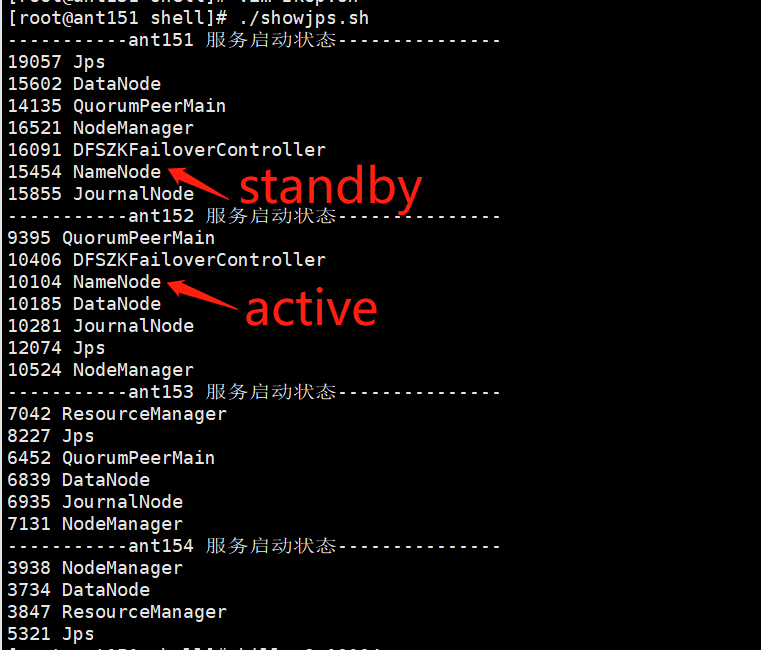
查看resourcemanager节点状态
[root@ant151 soft]# yarn rmadmin -getServiceState rm1
rm1状态:standby

rm2状态:active
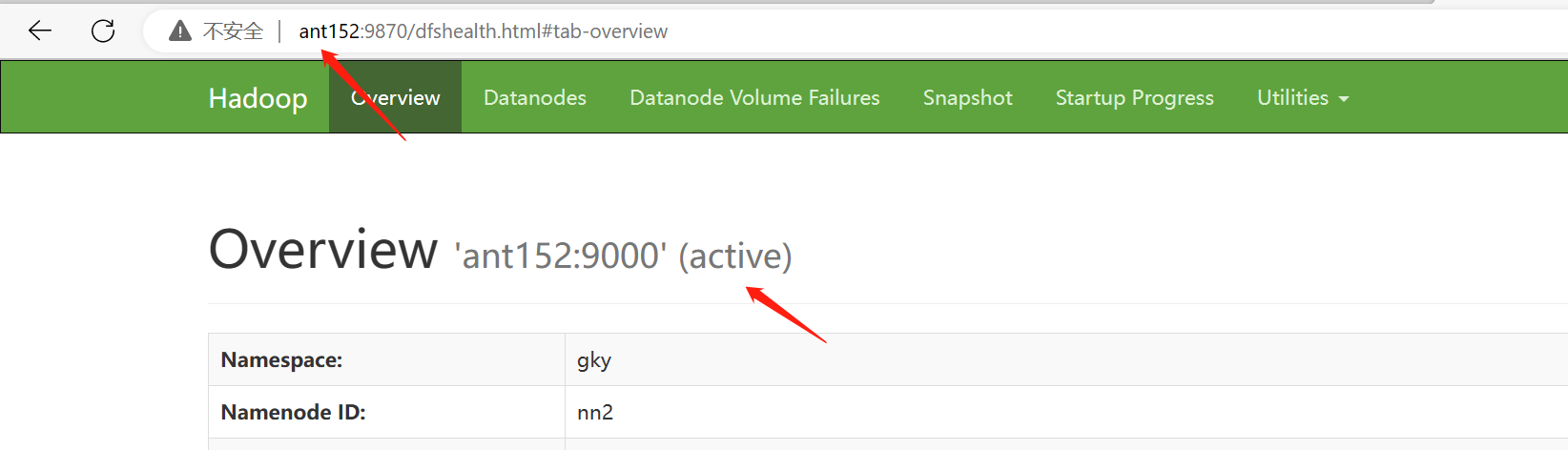
当前进程状态:
kill掉active进程

尝试访问,无法链接

恢复ant152的namenode进程

相关文章:
Hadoop集群配置
一、系统文件配置集群部署规划NameNode和SecondaryNameNode不要安装在同一台服务器ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode放在同一台机器上。这里装了四台机器,ant151,ant152,ant153,ant154。ant151ant152ant153ant154NameNode…...
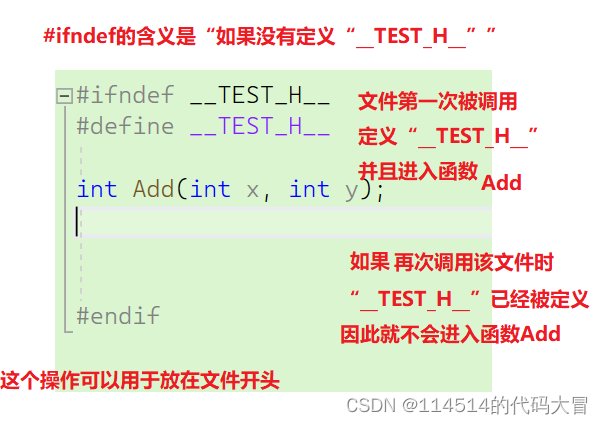
【C语言】程序环境和预处理|预处理详解|定义宏(下)
主页:114514的代码大冒 qq:2188956112(欢迎小伙伴呀hi✿(。◕ᴗ◕。)✿ ) Gitee:庄嘉豪 (zhuang-jiahaoxxx) - Gitee.com 文章目录 目录 文章目录 前言 2.5带副作用的宏参数 2.6宏和函数的对比 3#undef 编辑 4 命令行定义…...
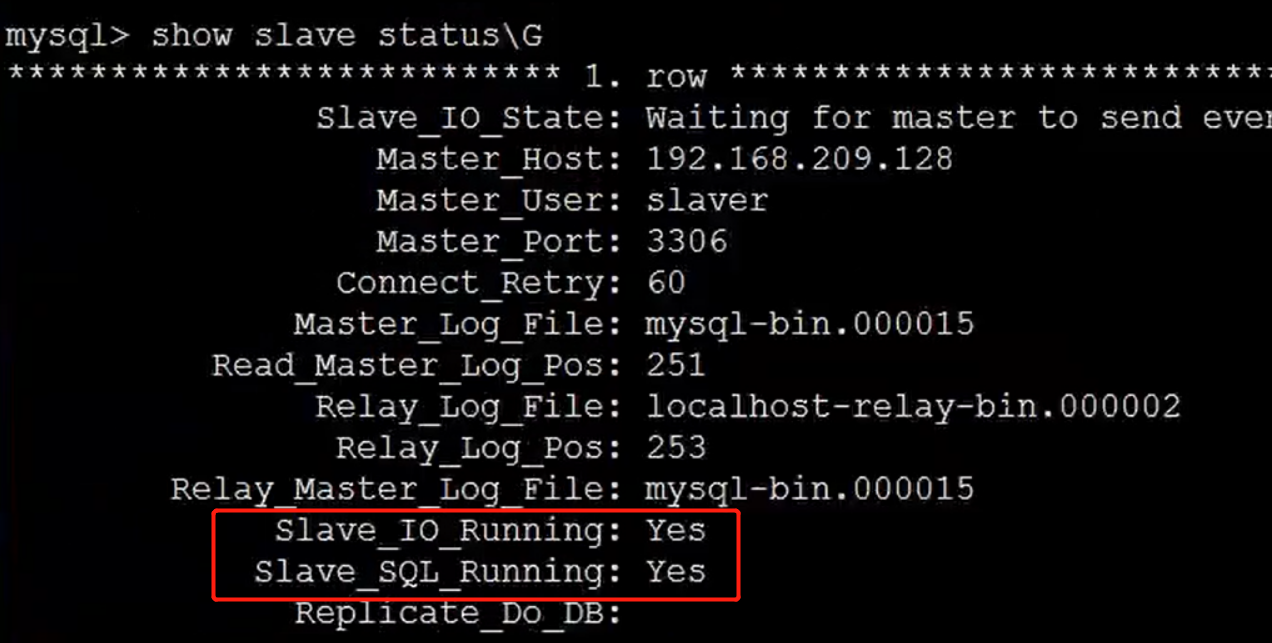
MySQL主从复制
操作流程准备两个服务器主服务器配置1>修改主配置文件 /etc/my.cnf[mysald] log-binmysql-bin //[必须]启用二进制日志server-id12>重启 mysql 服务3>创建mysql用户并授权mysql> GRANT REPLICATION SLAVE ON ** to slaver% identified by 123456;4>查看当前主服…...

做自媒体视频变现的三大要素!
大家都知道做自媒体可以赚钱,做得好的话收入会远超自己的工资! 但有些关键点你真的知道吗?有几点是新手很容易忽略的! 1、内容价值 我们所创作的内容是否是用户所需要的?用户是不是有强烈的需求?这一点你…...

软件测试如何获得高薪?
软件测试如何获得高薪? 目录:导读 测试基础理论/测试设计能力 业务知识 行业技术知识 数据库 掌握编程语言 搞定自动化测试 质量流程管理 下面谈谈不同level的测试工程师应具备的基本能力 第一个:我们称之为测试员/测试工程师 第二…...
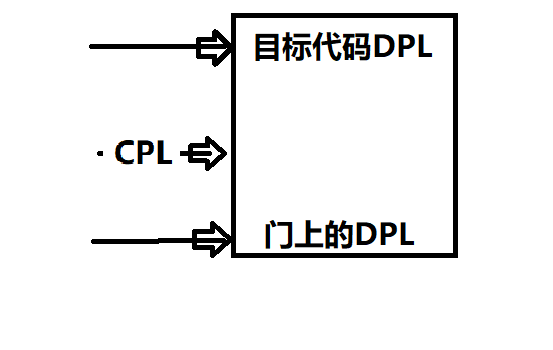
《真象还原》读书笔记——第五章 保护模式进阶,向内核迈进(特权级,更新)
5.4 特权级深入浅出 5.4.1 特权级哪点事 计算机 访问 可分为访问者和被访问者。 建立特权机制为了通过特权来检查合法性。 0、1、2、3级,数字越小,权力越大。 0特权级是系统内核特权级。 用户程序是3特权级,被设计为“有需求就找操作系统”…...

艾德卡EDEKA EDI 需求分析
艾德卡Edeka 是德国最大的食品零售商,因其采用“指纹付款”的方式进行结算,成为德国超市付款方式改革的先驱。2022年8月,入选2022年《财富》世界500强排行榜,位列第256位。 艾德卡EDEKA EDI需求分析 传输协议 在传输协议层面&a…...

python如何使用最简单的方式将PDF转换成Word?
由于PDF的文件大多都是只读文件,有时候为了满足可以编辑的需要通常可以将PDF文件直接转换成Word文件进行操作。 看了网络上面的python转换PDF文件为Word的相关文章感觉都比较复杂,并且关于一些图表的使用还要进行特殊的处理。 本篇文章主要讲解关于如何…...
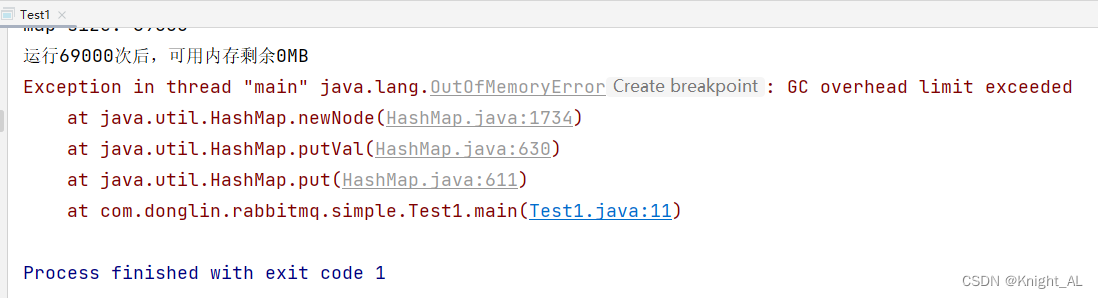
HashMap如何避免内存泄露问题
HashMap对于Java开发人员来说,应该是一种非常非常熟悉的数据结构了,应用场景相当广泛。 本文重点不在于介绍如何使用HashMap,而是关注在使用HashMap过程中,可能会导致内存泄露的情况,下面将以示例的形式展开具体介绍。…...

crontab -e定时任务
大家好,我是空空star,本篇带你了解下crontab -e定时任务。 文章目录前言一、crontab介绍二、crontab文件的含义四、crontab用法1.每隔5分钟执行一次命令2.每个小时的第5分执行一次命令3.每天9:05执行一次命令4.每隔9小时在第5分执行一次命令5.每月5号9号…...
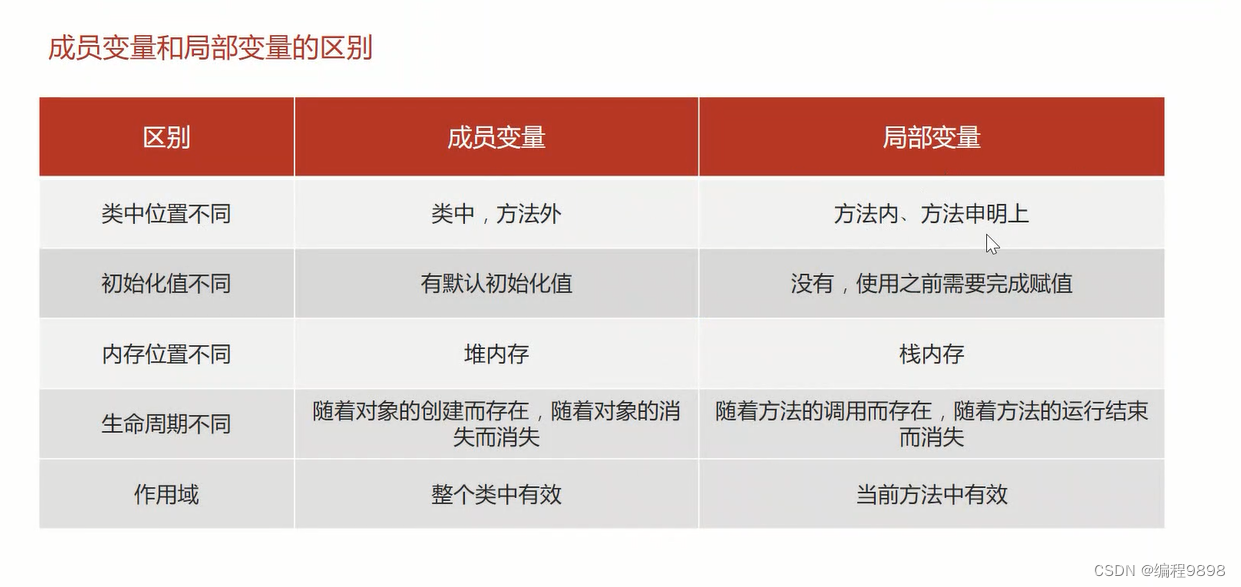
JavaSE学习day7_01 面向对象
1. 类和对象 1.1 类和对象的理解 客观存在的事物皆为对象 ,所以我们也常常说万物皆对象。即各个对象的总称,比如学生是一个类,但是学生有很多个,每一个称之为对象。 类 类的理解 类是对现实生活中一类具有共同属性和行为的事物的…...

有趣的HTML实例(十二) 早安、晚安动画(css+js)
这话在我心里已经复习了几千遍。我深恨发明不来一个新鲜飘忽的说法,只有我可以说只有你可以听,我说过,我听过,这说法就飞了,过去、现在和未来没有第二个男人好对第二个女人这样说。 ——《围城》 目录 一、前言 二、…...

入行测试已经4年了 ,进华为后迷茫了3个月,做完这个项目我决定离职....
转行测试 我是大专非计科,我转行之前从事的工作是商场管理,努力了4年左右的时间才做到楼层经理,但是工资太低并且事情太多,薪资才6K。 更多的是坚定了自己的想法,我要改变自己 恰好有几个大学同学在互联网公司工作&a…...
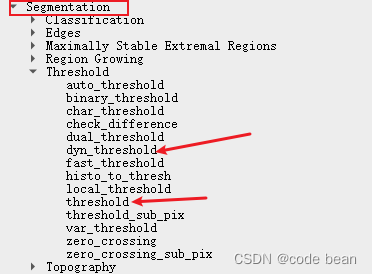
【halcon】灰度直方图直观理解与应用
灰度直方图 横坐标:是 0~255 表示灰度值的范围 纵坐标:是在不同灰度值下像素的个数! 那么灰度直方图的本质就是统计不同灰度下像素的个数! 它的直观目的,就是查看灰度的分布情况! 与之相关的函数ÿ…...

Android笔记:动画
文章目录1.View Animation(视图动画)1.1 Tween Animation(补间动画)Animation 继承属性透明度alpha缩放scale移动translate旋转rotateset标签Animation父类共有函数1.2Frame Animation (逐帧动画)2.Propert…...
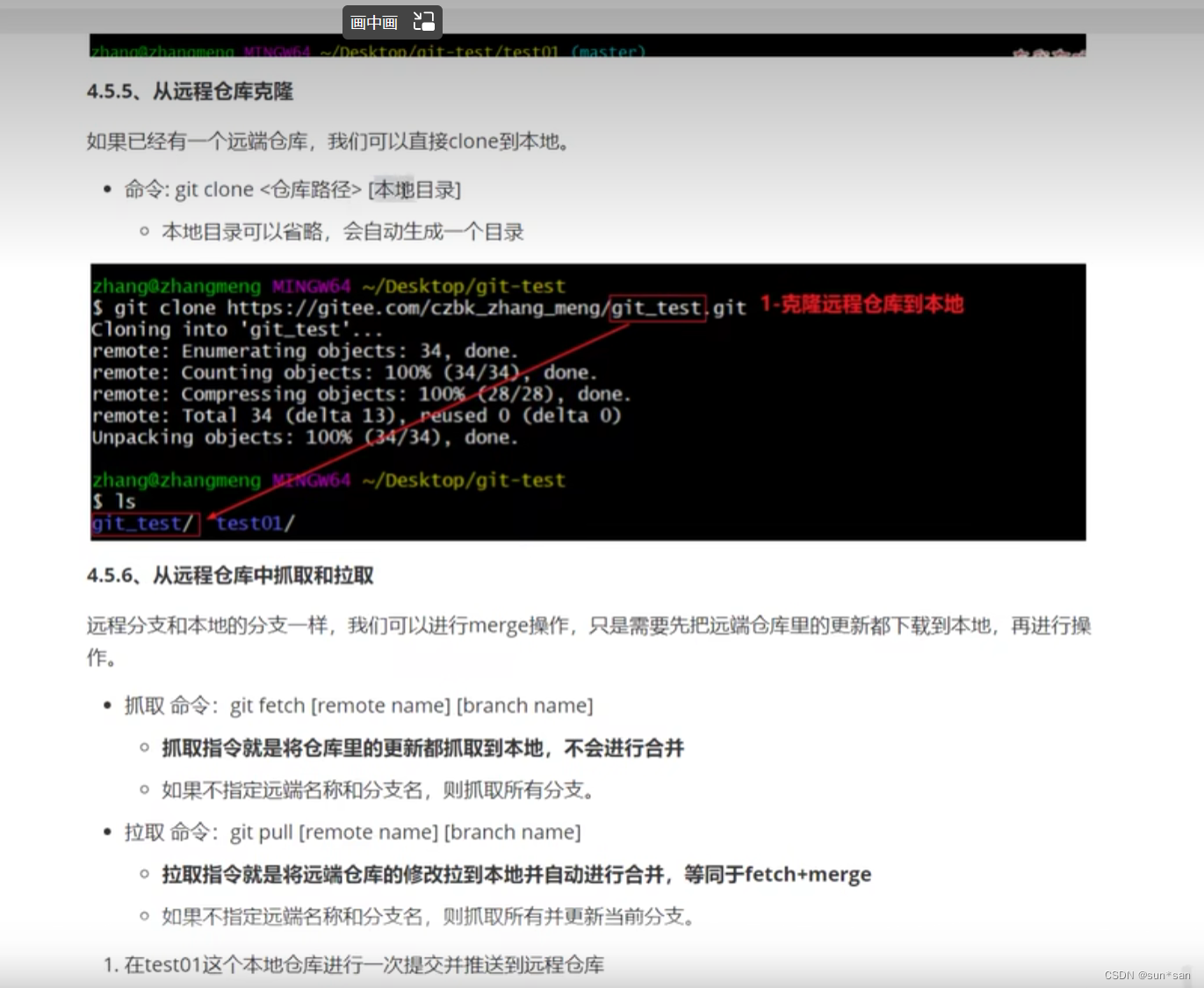
Git学习总结
目录 Git工作的基本流程图 git基本配置 配置SSH公钥 查看提交日志(log) 版本回退 为常用指令配置别名 添加文件至忽略列表 Git操作的基本指令 编辑 Git远程仓库的操作 把黑马的Git视频看完了黑马程序员Git全套教程,完整的git项目管…...

第四天笔记
1. 简述自定义转换器的使用过程? 第一步:定义一个类,实现 Converter 接口,该接口有两个泛型。 第二步:在 spring配置文件中配置类型转换器。 Spring配置类型转换器的机制是 将自定义的转换器注册到类型转换服务中去…...

《MySQL学习》 全局锁和表锁
一.MySQL锁的分类 二.全局锁 全局锁对整个数据库加锁,可以执行如下命令,整个数据库都将处于只读状态。 Flush tables with read lock ;我们可以执行 unlock table进行解锁 unlock table ;读操作 非读操作(阻塞) 全局锁的典型使…...
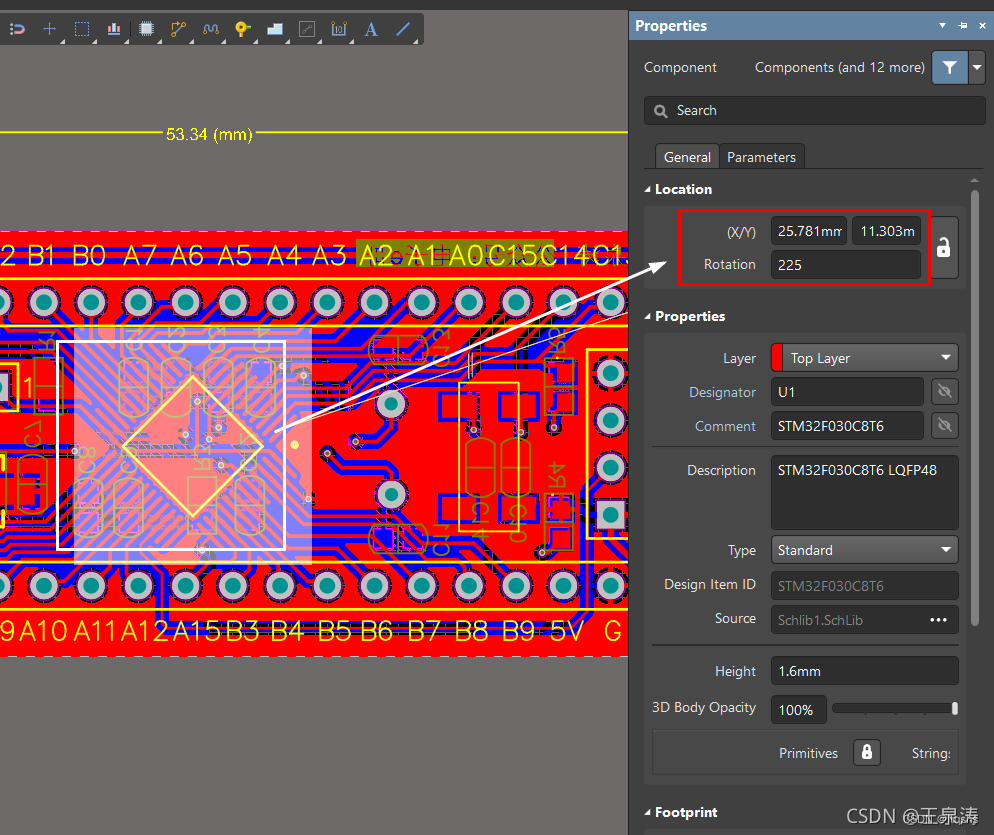
Altium Designer输出生产文件Gerber、IPC、NC Drill、坐标文件--AD
AD软件版本:22.2.1 gerber文件输出共有两部分: 1、Gerber Files:铜皮 和 外形分别导出 2、Nc Drill Files 分3次导出 一、Gerber Files 导出2次 设定原点 ** Edit->Origin->Set** 一般板边左下角为原点,可以根据自己板子形状确定 导…...
用VSCode搭建Vue.js开发环境及Vue.js第一个应用
目录 一、VSCode安装 二、VSCode简单配置 三、Vue.js的下载和引入 四、Vue.js第一个应用 一、VSCode安装 Visual Studio Code是一个轻量级但功能强大的源代码编辑器,可在您的桌面上运行,可用于Windows,macOS和Linux。它内置了对JavaScrip…...

Arm GIC虚拟中断控制器架构与寄存器详解
1. Arm GIC虚拟中断控制器架构概述 中断控制器是现代处理器架构中的关键组件,负责协调和管理来自各种外设的中断请求。在虚拟化环境中,传统的中断控制器面临新的挑战:如何高效处理来自多个虚拟机的中断请求,同时保持隔离性和性能。…...

性能测试指标选不对,报告全白费!从一次线上故障复盘TPS、RT与吞吐量的关系
性能指标迷局:当高QPS掩盖了系统瓶颈的真相 那天凌晨三点,我被一阵急促的电话铃声惊醒。电商大促系统监控面板上QPS曲线依然漂亮,但业务方反馈用户下单延迟高达15秒——这个看似矛盾的场景,揭开了性能指标认知中最危险的陷阱。我…...
)
别再死记硬背了!手把手带你用Vivado SDK调试ZYNQ FSBL源码(附常见启动失败排查)
深入实战:用Vivado SDK调试ZYNQ FSBL源码的完整指南 在嵌入式系统开发中,理解启动流程是掌握整个系统运行机制的关键。对于Xilinx ZYNQ平台而言,First Stage Boot Loader(FSBL)作为系统启动的第一环,其重要…...

八大网盘直链解析神器:彻底告别下载限速烦恼的终极指南
八大网盘直链解析神器:彻底告别下载限速烦恼的终极指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...

Let‘s Encrypt证书有效期缩短至90天后,如何实现自动续期
Let’s Encrypt证书有效期缩短至90天后,如何实现自动续期 打开网站突然发现浏览器地址栏一把红色小锁,提示"您的连接不是专用连接"——SSL证书过期了。这可能是站长最不想看到的画面之一:用户无法正常访问、搜索引擎排名下降、甚至…...

从NeoClaw项目看嵌入式开发:HAL设计、OTA与低功耗实战
1. 项目概述:从“NeoClaw”看现代嵌入式开发的新范式最近在GitHub上看到一个挺有意思的项目,叫“Atum246/NeoClaw”。光看这个名字,你可能会有点摸不着头脑——“NeoClaw”是什么?新爪子?机械爪?还是某种新…...

应对AIGC检测算法:论文初稿怎么做结构级优化?附实测工具避坑指南
写文章现在最怕什么?查重?不,现在的风向变了——最怕的是AI率太高。 现在越来越多学校开始严查aigc报告,只要被判定AI率过重,直接打回重写甚至影响答辩资格。很多同学为了降低ai率,四处寻找各种免费降ai率…...

Arm架构DCU寄存器解析与安全调试实践
1. Arm生命周期管理器DCU寄存器深度解析 在Arm架构的嵌入式系统开发中,生命周期管理器(Lifecycle Manager, LCM)扮演着关键角色,而其中的调试控制单元(Debug Control Unit, DCU)寄存器组则是开发人员必须掌…...

抖音内容高效采集实战:5个提升工作效率的开源方案
抖音内容高效采集实战:5个提升工作效率的开源方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. …...

2026年小程序多少钱对比:精选5大权威推荐帮你选对平台
小程序开发方案的选择直接影响功能匹配度与成本效益,2026年主流服务商主要分为模板化与定制化两类路径。本文将从开发费用构成、五大平台核心方案及选择策略三方面展开分析,帮助您快速定位适合自身业务阶段与预算的选项。内容涵盖基础功能解析、价格对比…...