【MySQL进阶】SQL优化
😊😊作者简介😊😊 : 大家好,我是南瓜籽,一个在校大二学生,我将会持续分享Java相关知识。
🎉🎉个人主页🎉🎉 : 南瓜籽的主页
✨✨座右铭✨✨ : 坚持到底,决不放弃,是成功的保证,只要你不放弃,你就有机会,只要放弃的人,他肯定是不会成功的人。
🍎🍎插入数据🍎🍎
如果我们需要一次性往数据库表中插入多条记录,可以从以下三个方面进行优化。
方案一:
批量插入数据
Insert into tb_user values(1,'Tom'),(2,'Cat'),(3,'Jerry');
方案二:
手动控制事务
start transaction;
insert into tb_user values(1,'Tom'),(2,'Cat'),(3,'Jerry');
insert into tb_user values(4,'Tom'),(5,'Cat'),(6,'Jerry');
insert into tb_user values(7,'Tom'),(8,'Cat'),(9,'Jerry');
commit;
方案三:
主键顺序插入,性能要高于乱序插入。
主键乱序插入 : 3 1 5 2
主键顺序插入 : 1 2 3 5
🍎🍎大批量插入数据🍎🍎
如果一次性需要插入大批量数据(比如:
几百万的记录),使用insert语句插入性能较低,此时可以使用MySQL数据库提供的load指令进行插入。
操作方法如下:
-- 客户端连接服务端时,加上参数 -–local-infile
mysql –-local-infile -u root -p
-- 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile = 1;
-- 执行load指令将准备好的数据,加载到表结构中
load data local infile '/root/sql.sql' into table tb_user fields
terminated by ',' lines terminated by '\n' ;
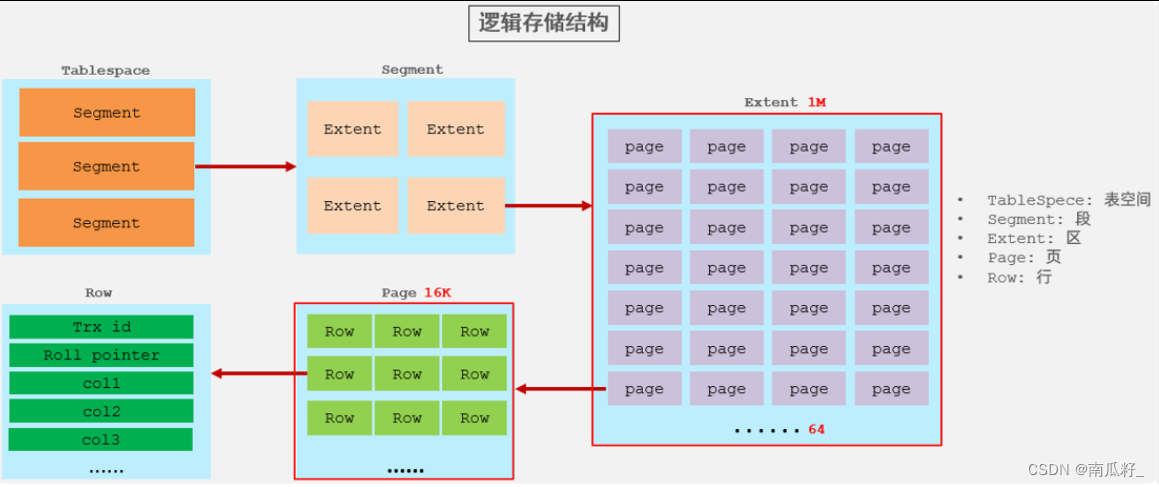
🍉🍉主键优化🍉🍉
🍉🍉数据组织方式🍉🍉
在
InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table IOT)。
行数据,都是存储在聚集索引 (默认为主键索引)的叶子节点上的。
在InnoDB引擎中,数据行是记录在逻辑结构 page 页中的,而每一个页的大小是固定的,默认16K。
那也就意味着, 一个页中所存储的行也是有限的,如果插入的数据行row在该页存储不小,将会存储到下一个页中,页与页之间会通过指针连接。
🍉🍉页分裂🍉🍉
页可以为空,也可以填充一半,也可以填充100%。每个页包含了2-N行数据(如果一行数据过大,会行溢出),根据主键排列。
1. 主键顺序插入效果

1. 主键乱序插入效果
一 : 第一、二页已经写满了数据
二 : 我们的需求是再插入一条主键为50的数据,
1、MySQL 进行判断发现一、二页已经满了。
2、此时会开辟一个新的页 3# page,但是并不会直接将50存入3#页,而是会将1#页后一半的数据,移动到3#页,然后在3#页,插入50。3、 移动数据,并插入id为50的数据之后,那么此时,这三个页之间的数据顺序是有问题的。 1#的下一个页,应该是3#, 3#的下一个页是2#。 所以,此时,需要重新设置链表指针


tips: 上述的这种现象,称之为 “页分裂”,是比较耗费性能的操作。
🍉🍉页合并🍉🍉
当我们对已有数据进行删除时,具体的效果如下:
1、当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记(flaged)为删除并且它的空间变得允许被其他记录声明使用。
2、当页中删除的记录达到 MERGE_THRESHOLD(默认为页的50%),InnoDB会开始寻找最靠近的页(前或后)看看是否可以将两个页合并以优化空间使用。
删除数据,并将页合并之后,再次插入新的数据21,则直接插入3#页
tips: MERGE_THRESHOLD:合并页的阈值,可以自己设置,在创建表或者创建索引时指定。


- 为表设置MERGE_THRESHOLD
CREATE TABLE table1 (id INT PRIMARY KEY AUTO_INCREMENT,name VARCHAR(32) NOT NULL,) COMMENT='MERGE_THRESHOLD=45';
- 为单个索引设置MERGE_THRESHOLD
CREATE INDEX idx_id ON table1 (id) COMMENT 'MERGE_THRESHOLD=40';
🍉🍉索引设计原则🍉🍉
1. 满足业务需求的情况下,尽量降低主键的长度。
2. 插入数据时,尽量选择顺序插入,选择使用AUTO_INCREMENT自增主键。
3. 尽量不要使用UUID做主键或者是其他自然主键,如身份证号。
4. 业务操作时,避免对主键的修改。
🍓🍓ORDER BY优化🍓🍓
MySQL的排序,有两种方式:
- Using filesort : 通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sortbuffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序。
- Using index : 通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高。
- 总结对于以上的两种排序方式,
Using index的性能高,而Using filesort的性能低,我们在优化排序操作时,尽量要优化为 Using index。
ORDER BY优化原则:
- 根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则。
- 尽量使用覆盖索引。
- 多字段排序, 一个升序一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC)。
- 如果不可避免的出现filesort,大数据量排序时,可以适当增大排序缓冲区大小sort_buffer_size(默认256k)。
🍇🍇GROUP BY优化🍇🍇
在分组操作中,我们需要通过以下两点进行优化,以提升性能:
- 在分组操作时,可以通过索引来提高效率。
- 分组操作时,索引的使用也是满足最左前缀法则的。
🍒🍒LIMIT优化🍒🍒
优化思路: 一般分页查询时,通过创建 覆盖索引 能够比较好地提高性能,可以通过覆盖索引加子查询形式进行优化
explain select * from tb_user t , (select id from tb_user order by id
limit 2000000,10) a where t.id = a.id;
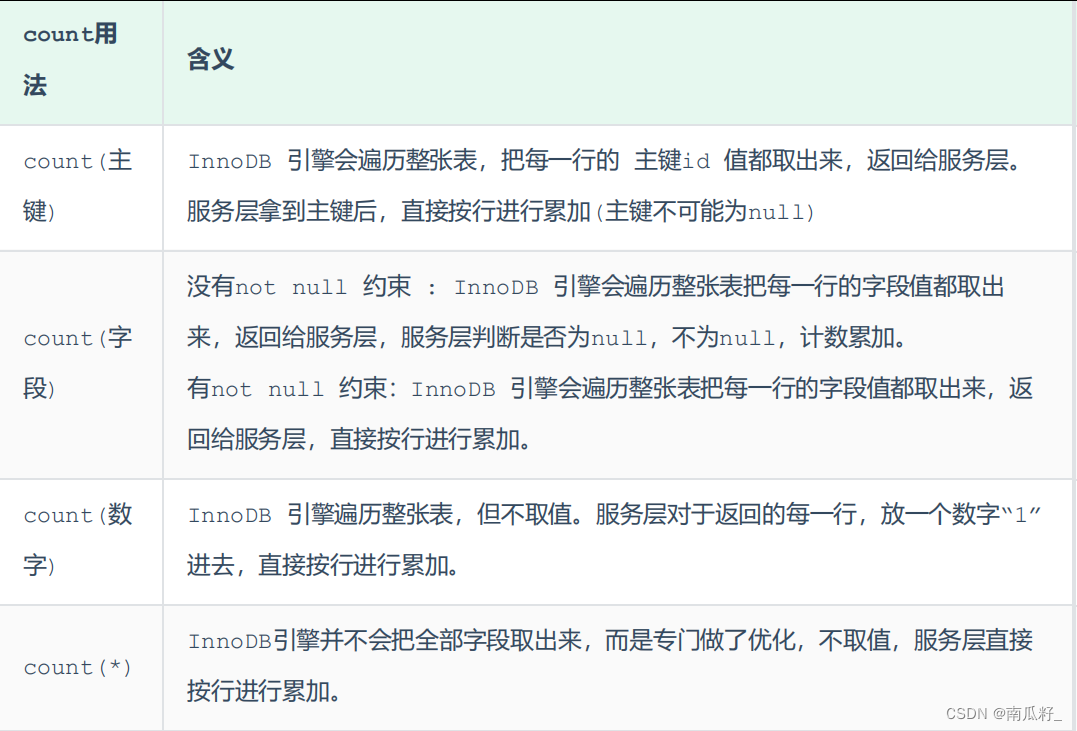
🍍🍍COUNT优化🍍🍍
- MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个数,效率很高; 但是如果是带条件的count,MyISAM也慢。
- InnoDB 引擎就麻烦了,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
主要的优化思路:自己计数(可以借助于redis这样的数据库进行,但是如果是带条件的count又比较麻烦了)
🍍🍍COUNT用法🍍🍍
count() 是一个聚合函数,对于返回的结果集,一行行地判断,如果 count 函数的参数不是NULL,累计值就加 1,否则不加,最后返回累计值。
效率从小到大排序: count(字段) < count(主键 id) < count(1) ≈ count(*)
🍊🍊UPDATE优化🍊🍊
我们主要需要注意一下update语句执行时的
注意事项。
update tb_user set name = '张三' where id = 1 ;
当我们在执行删除的SQL语句时,会锁定id为1这一行的数据(where关键字所起的作用),然后事务提交之后,行锁释放。
但是当我们在执行如下SQL时。
update tb_user set name = '王五' where name = '李四' ;
注意: 此时 name 字段是没有索引的,此时可以理解为索引失效,所以当执行上述SQL时,会将行锁升级为表锁,导致该update语句的性能大大降低!!!
InnoDB存储引擎的行锁是针对索引加的锁,不是针对记录加的锁 ,并且该索引不能失效,否则会从行锁升级为表锁
相关文章:
【MySQL进阶】SQL优化
😊😊作者简介😊😊 : 大家好,我是南瓜籽,一个在校大二学生,我将会持续分享Java相关知识。 🎉🎉个人主页🎉🎉 : 南瓜籽的主页…...
最新版海豚调度dolphinscheduler-3.1.3配置windows本地开发环境
0 说明 本文基于最新版海豚调度dolphinscheduler-3.1.3配置windows本地开发环境,并在windows本地进行调试和开发 1 准备 1.1 安装mysql 可以指定为windows本地mysql,也可以指定为其他环境mysql,若指定为其他环境mysql则可跳过此步。 我这…...

csv文件完整操作总结
csv文件完整操作总结 1.概述 csv 模块主要用于处理从电子数据表格Excel或数据库中导入到文本文件的数据,通常简称为 comma-separated value (CSV)格式因为逗号用于分离每条记录的各个字段。 2.读写操作 2.1.测试数据 创建一个test.csv文…...
时间序列预测--基于CNN的股价预测(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 👨💻4 Matlab代码 💥1 概述 时间序列预测有很多方法,如传统的时序建模方法ARIMA、周期因子法、深度学习网络等,本次实验采用最简单的…...
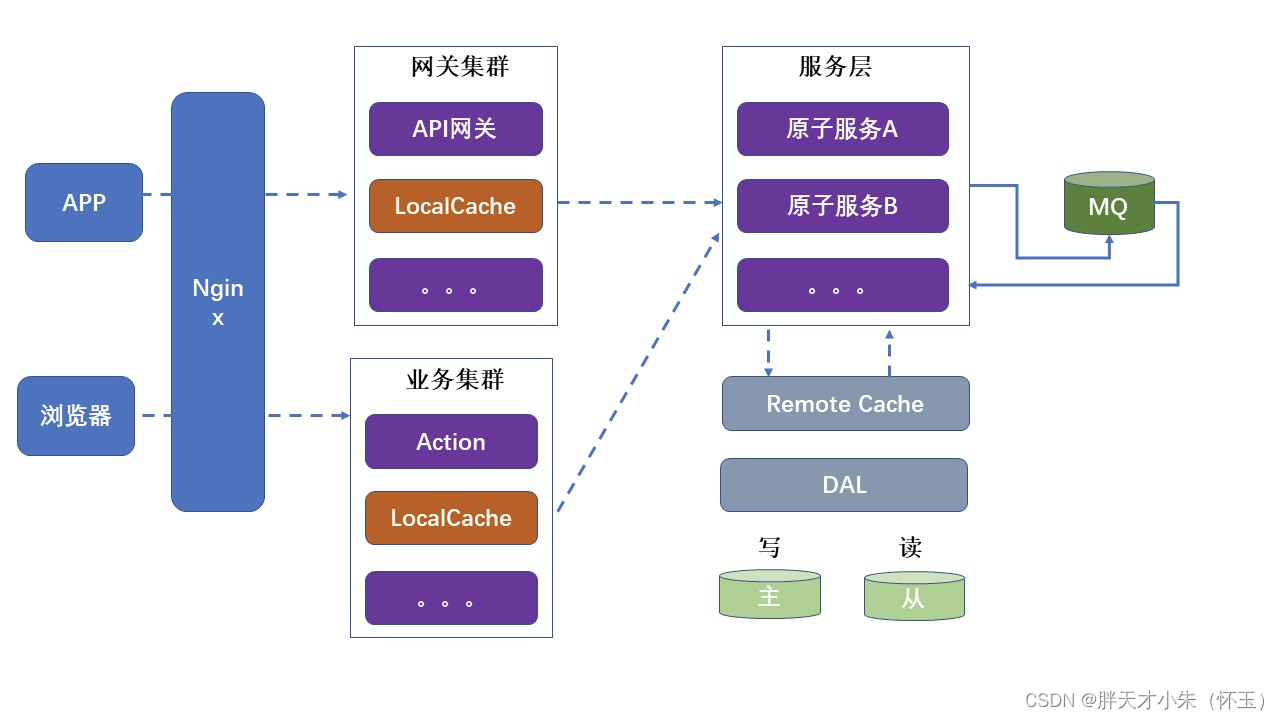
Dubbo与Spring Cloud优缺点分析(文档学习个人理解)
文章目录核心部件1、总体框架1.1 Dubbo 核心部件如下1.2 Spring Cloud 总体架构2、微服务架构核心要素3、通讯协议3.1 Dubbo3.2 Spring Cloud3.3 性能比较4、服务依赖方式4.1 Dubbo4.2 Spring Cloud5、组件运行流程5.1 Dubbo5.2 Dubbo 运行组件5.3 Spring Cloud5.4 Spring Clou…...

单元测试工具——JUnit的使用
⭐️前言⭐️ 本篇文章主要介绍单元测试工具JUnit的使用。 🍉欢迎点赞 👍 收藏 ⭐留言评论 📝私信必回哟😁 🍉博主将持续更新学习记录收获,友友们有任何问题可以在评论区留言 🍉博客中涉及源码…...

Linux_基本权限
Linux入门第二篇已送达! Linux_基本权限shell外壳权限Linux的用户分类角色划分Linux的文件文件类型查看权限目录的权限默认权限粘滞位shell外壳 为了保护操作系统,用户的指令不能由操作系统直接进行执行,需要一个中间者,比如Linu…...

3、JavaScript面试题
1, Js数据类型有哪些?数值、字符串、布尔、undefined、null、数组、对象、函数2, 引用类型和值类型的区别- 值类型存在于栈中, 存取速度快 引用类型存在于堆,存取速度慢- 值类型复制的是值本身 引用类型复制的是指向对象的指针- 值类型结构简单只包含基本数据, 引用…...

YUV图像
YUV的存储方式UV格式有两大类:planar和packed。对于planar的YUV格式,先连续存储所有像素点的Y,紧接着存储所有像素点的U,随后是所有像素点的V。对于packed的YUV格式,每个像素点的Y,U,V是连续交替存储的。YUV的采样主流…...
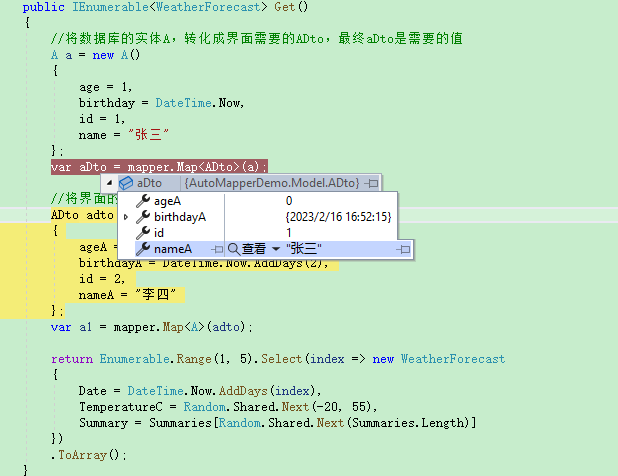
.net6API使用AutoMapper和DTO
AutoMapper,是一个转换工具,说到AutoMapper时,就不得不先说DTO,它叫做数据传输对象(Data Transfer Object)。 通俗的来说,DTO就是前端界面需要用的数据结构和类型,而我们经常使用的数据实体,是数…...
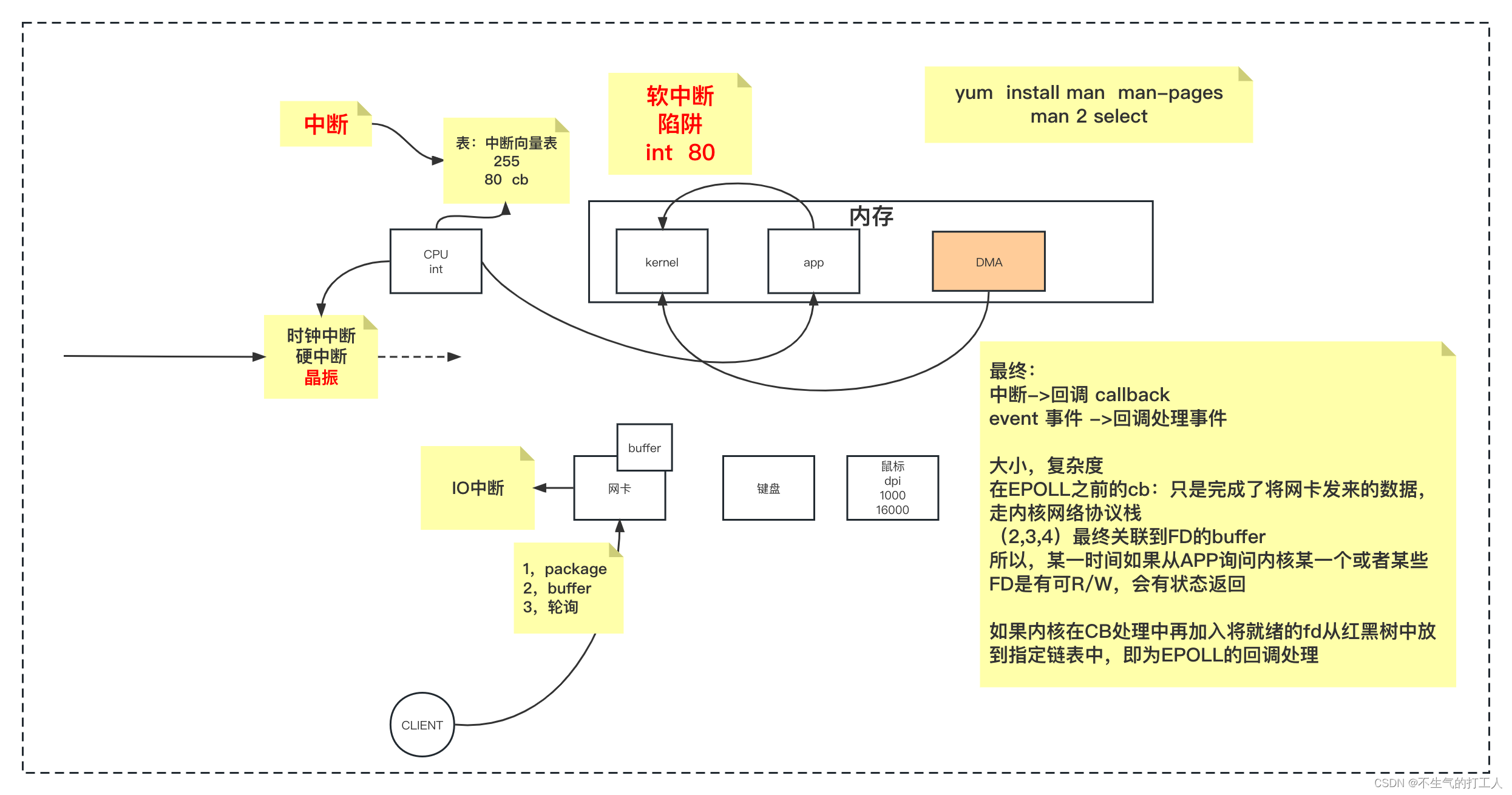
IO知识整理
IO 面向系统IO page cache 程序虚拟内存到物理内存的转换依靠cpu中的mmu映射 物理内存以page(4k)为单位做分配 多个程序访问磁盘上同一个文件,步骤 kernel将文件内容加载到pagecache多个程序读取同一份文件指向的同一个pagecache多个程…...
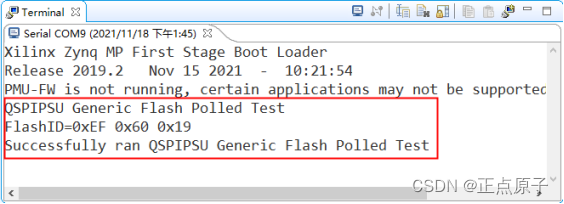
【正点原子FPGA连载】第十三章QSPI Flash读写测试实验 摘自【正点原子】DFZU2EG_4EV MPSoC之嵌入式Vitis开发指南
1)实验平台:正点原子MPSoC开发板 2)平台购买地址:https://detail.tmall.com/item.htm?id692450874670 3)全套实验源码手册视频下载地址: http://www.openedv.com/thread-340252-1-1.html 第十三章QSPI Fl…...
深入理解mysql的内核查询成本计算
MySql系列整体栏目 内容链接地址【一】深入理解mysql索引本质https://blog.csdn.net/zhenghuishengq/article/details/121027025【二】深入理解mysql索引优化以及explain关键字https://blog.csdn.net/zhenghuishengq/article/details/124552080【三】深入理解mysql的索引分类&a…...

LeetCode 141. 环形链表
原题链接 难度:easy\color{Green}{easy}easy 题目描述 给你一个链表的头节点 headheadhead ,判断链表中是否有环。 如果链表中有某个节点,可以通过连续跟踪 nextnextnext 指针再次到达,则链表中存在环。 为了表示给定链表中的…...
git提交
文章目录关于数据库:桌面/vue-admin/vue_shop_api 的 git 输入 打开 phpStudy ->mySQL管理器 导入文件同时输入密码,和文件名 node app.js 错误区: $ git branch // git branch 查看分支 只有一个main分支不见master解决: gi…...

Java中常见的编码集问题
收录于热门专栏Java基础教程系列(进阶篇) 一、遇到一个问题 1、读取CSV文件 package com.guor.demo.charset;import java.io.BufferedReader; import java.io.FileReader; import java.util.ArrayList; import java.util.HashMap; import java.util.L…...

数据结构与算法(Java版) | 就让我们来看看几个实际编程中遇到的问题吧!
上一讲,我给大家简单介绍了一下数据结构,以及数据结构与算法之间的关系,照理来说,接下来我就应该要给大家详细介绍线性结构和非线性结构了,但是在此之前,我决定还是先带着大家看几个实际编程中遇到的问题&a…...
【C++算法】dfs深度优先搜索(上) ——【全面深度剖析+经典例题展示】
💃🏼 本人简介:男 👶🏼 年龄:18 📕 ps:七八天没更新了欸,这几天刚搞完元宇宙,上午一直练🚗,下午背四级单词和刷题来着,还在忙一些学弟…...
总结高频率Vue面试题
目录 什么是三次握手? 什么是四次挥手?(close触发) 什么是VUEX? 什么是同源----跨域? 什么是Promise? 什么是fexl布局? 数据类型 什么是深浅拷贝? 什么是懒加载&…...
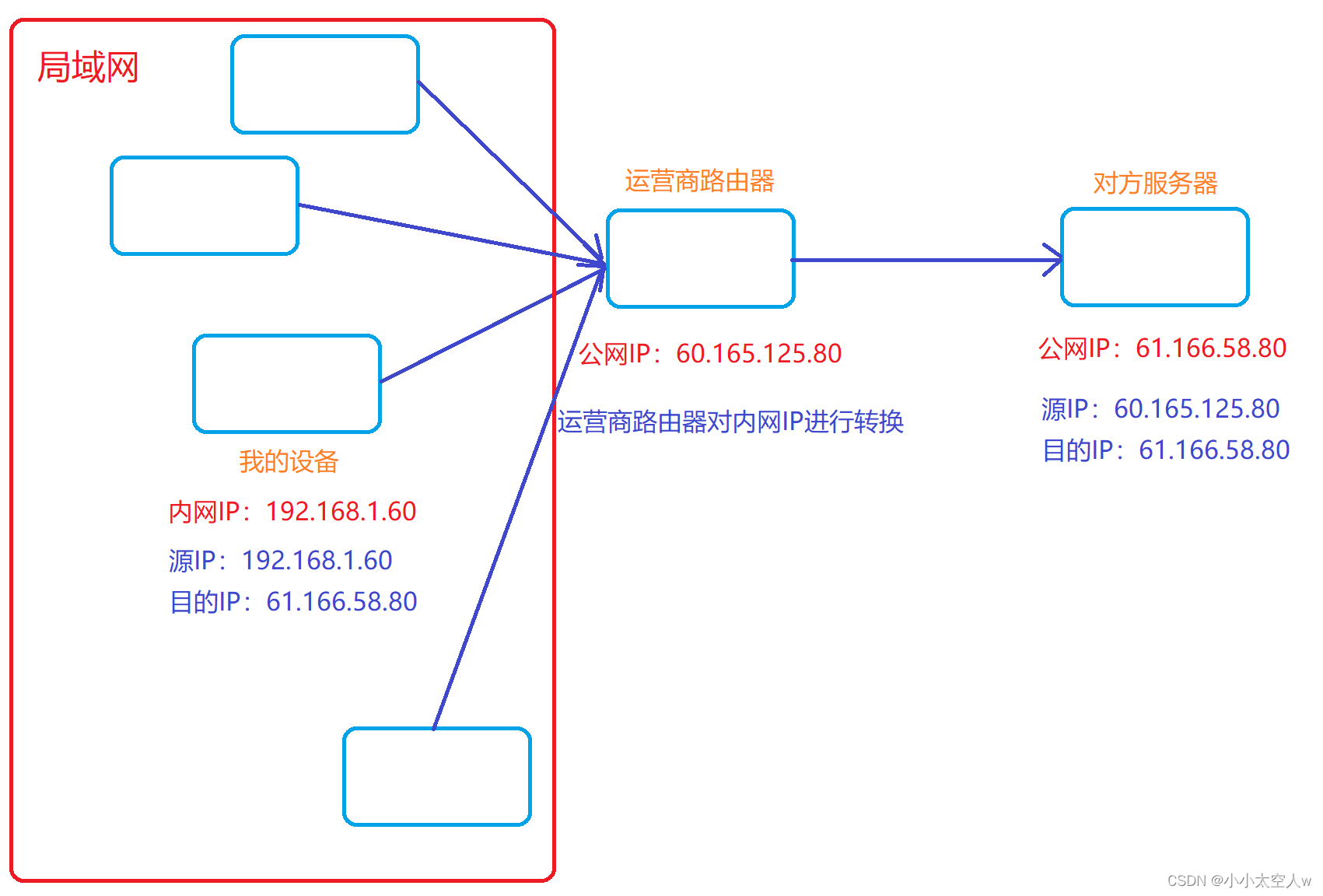
IP协议详解
目录 前言: IP协议 提出问题 解决方案 地址管理 子网掩码 路由选择 小结: 前言: IP协议作为网络层知名协议。当数据经过传输层使用TCP或者UDP对数据进行封装,然后当数据到达网络层,基于TCP或UDP数据包继续进行…...

粒子追踪模拟单透镜聚焦comsol ansys Fluent 二维三维模型 仿真模型,文献复现
粒子追踪模拟单透镜聚焦comsol ansys Fluent 二维三维模型 仿真模型,文献复现,热湿传递在实验室折腾粒子追踪仿真的时候,最让人上头的莫过于单透镜聚焦的场景搭建。COMSOL和ANSYS这对冤家各有各的脾气——前者把物理场耦合玩出花࿰…...

Sodaq_RN2483库详解:LoRaWAN Class A终端嵌入式实现
1. Sodaq_RN2483库深度解析:面向Class A LoRaWAN终端的嵌入式通信实现 1.1 库定位与工程价值 Sodaq_RN2483是一个专为Microchip RN2483 LoRaWAN模块设计的Arduino兼容C库,其核心目标是为资源受限的嵌入式系统提供稳定、可复用、符合LoRaWAN协议规范的无…...
与细胞治疗生产工具解析:Sexton产品应用综述【曼博生物官方代理Sexton】)
人血小板裂解液(hPL)与细胞治疗生产工具解析:Sexton产品应用综述【曼博生物官方代理Sexton】
摘要:人血小板裂解液(hPL)作为无动物源培养补充剂,正在逐步替代FBS应用于细胞与基因治疗(CGT)领域。本文结合相关产品体系,对hPL及细胞冻存与灌装系统进行系统梳理。 关键词:人血小板…...

不止于读写:在HC32F460上为FATFS和SDIO驱动添加调试信息与性能测试
HC32F460深度优化:FATFS与SDIO驱动的调试技巧与性能压测实战 当你的HC32F460开发板已经能够读取SD卡文件时,真正的挑战才刚刚开始。那些隐藏在初始化失败、数据错位、速度瓶颈背后的秘密,往往需要更精密的调试手段才能揭开。本文将带你超越基…...

OpenClaw多模型切换技巧:GLM-4.7-Flash与Qwen3-32B混合调用实战
OpenClaw多模型切换技巧:GLM-4.7-Flash与Qwen3-32B混合调用实战 1. 为什么需要多模型切换 去年冬天,当我第一次尝试用OpenClaw自动处理周报时,发现一个有趣的现象:用同一个模型处理文本摘要和代码片段时,效果差异很大…...

Qwen3.5-4B-Claude-Opus实际作品:正则表达式语法树构建与匹配逻辑推演
Qwen3.5-4B-Claude-Opus实际作品:正则表达式语法树构建与匹配逻辑推演 1. 模型能力概述 Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF是一个专注于逻辑推理和结构化分析的轻量级AI模型。作为Qwen3.5-4B的蒸馏版本,它在处理代码解释、算法分析…...

OpenClaw定时任务管理:ollama-QwQ-32B实现智能提醒系统
OpenClaw定时任务管理:ollama-QwQ-32B实现智能提醒系统 1. 为什么需要智能提醒系统 作为一个长期被各种截止日期折磨的技术从业者,我一直在寻找一个能够真正理解我需求的提醒工具。传统的日历应用虽然能设置固定时间的提醒,但缺乏灵活性——…...

基于Vue的沧交食堂食品监管系统[vue]-计算机毕业设计源码+LW文档
摘要:本文阐述了一个基于Vue框架开发的沧交食堂食品监管系统。该系统旨在借助现代Web技术,强化对沧交食堂食品安全的监管力度,提升监管效率与质量。系统涵盖了系统用户管理、新闻数据管理、食品相关业务管理以及评论管理等多方面功能。文章详…...

Repomix构建流程解析:TypeScript编译与打包的完整指南
Repomix构建流程解析:TypeScript编译与打包的完整指南 【免费下载链接】repomix 📦 Repomix (formerly Repopack) is a powerful tool that packs your entire repository into a single, AI-friendly file. Perfect for when you need to feed your cod…...

HP-Socket技术债务管理成熟度提升计划:行动项与时间表
HP-Socket技术债务管理成熟度提升计划:行动项与时间表 【免费下载链接】HP-Socket High Performance TCP/UDP/HTTP Communication Component 项目地址: https://gitcode.com/gh_mirrors/hp/HP-Socket HP-Socket作为高性能TCP/UDP/HTTP通信组件,随…...