2023 年的 Web Worker 项目实践
目录
前言
引入 Web Worker
Worker 实践
Worker 到底有多难用
类库调研
有类库加持的 worker 现状
向着舒适无感的 worker 编写前进
1. 抽取依赖,管理编译和更新:
2. 定义公共调用函数,引入所打包的依赖并串联流程:
3. 优化语法支持
4. 其他问题
总结
参考资料
前言
Web Workers 是 2009 年就已经提案的老技术,但是在很多项目中的应用相对较少,常见一些文章讨论如何写 demo ,但很少有工程化和项目级别的实践,本文会结合 Web Workers 在京东羚珑的程序化设计项目中的实践,分享一下在当下的 2023 年,关于 worker 融入项目的一些思考和具体的实现方式,涉及到的 demo 已经放在 github 上附在文末,可供参考。
先简单介绍下 Web Workers,它是一种可以运行在 Web 应用程序后台线程,独立于主线程之外的技术。众所周知,JavaScript 语言是单线程模型的,而通过使用 Web Workers,我们可以创造多线程环境,从而可以发挥现代计算机的多核 CPU 能力,在应对规模越来越大的 Web 程序时也有较多收益。
Web Workers 宏观语义上包含了三种不同的 Worker:DedicatedWorker(专有worker)、 SharedWorker(共享Worker)、 ServiceWorker,本文讨论的是第一种,其他两种大家可以自行研究一下。
引入 Web Worker
当引入新技术时,通常我们会考虑的问题有:
1、兼容性如何?
2、使用场景在哪?
问题 1,Web Workers 是 2009 年的提案,2012 年各大浏览器已经基本支持,11 年过去了,现在使用已经完全没有问题啦

问题 2,主要考虑了以下 3 点:
-
·Worker API的局限性:同源限制、无 DOM 对象、异步通信,因此适合不涉及 DOM 操作的任务 -
·Worker的使用成本:创建时间 + 数据传输时间;考虑到可以预创建,可以忽略创建时间,只考虑数据传输成本,这里可参考 19 年的一个测试 Is postMessage slow[1] ,简要结论是比较乐观的,大部分设备和数据情况下速度不是瓶颈 -
·任务特点:需要是可并行的多任务,为了充分利用多核能力,可并行的任务数越接近 CPU 数量,收益会越高。多线程场景的收益计算,可以参考
Amdahl公式,其中F是初始化所需比例,N是可并行数:
综上结论是,可并行的计算密集型任务适合用 Worker 来做。
不过 github 上我搜罗了一圈,也发现有一些不局限于此,颇有创意的项目,供大家打开思路:
-
·redux 挪到了 worker 内[2]
-
·dom 挪到了 worker 内[3]
-
·可使用多核能力的框架[4]
Worker 实践
介绍完 worker ,一个问题出现了:为什么一个兼容性良好,能够发挥并发能力的技术(听起来很有诱惑力),到现在还没有大规模使用呢?
我理解有 2 个原因:一是暂无匹配度完美的使用场景,因此引入被搁置了;二是 worker api 设计得太难用,参考很多 demo 看,限制多配置还麻烦,让人望而却步。本文会主要着力于第二点,希望给大家的 worker 实践提供一些成熟的工程化思路。
至于第一点理由,在如此卷的前端领域,当你手中已经有了一把好用的锤子,还找不到那颗需要砸的钉子吗?
Worker 到底有多难用
下面是一个原始 worker 的调用示例,上面是主线程文件,下面是 worker 文件:
// index.js
const worker = new Worker('./worker.js')
worker.onmessage = function (messageEvent) {console.log(messageEvent)
}
// worker.js
importScripts('constant.js')
function a() {console.log('test')
}
其中问题有:
-
·postMessage传递消息的方式不适合现代编程模式,当出现多个事件时就涉及分拆解析和解决耦合问题,因此需要改造 -
·新建
worker需要单独文件,因此项目内需要处理打包拆分逻辑,独立出worker文件 -
·worker内可支持定义函数,可通过importScript方式引入依赖文件,但是都独立于主线程文件,依赖和函数的复用都需要改造 -
·多线程环境必然涉及同步运行多个
worker,多worker的启动、复用和管理都需要自行处理
看完这么多问题,有没有感觉头很大,一个设计这样原始的 api,如何舒服的使用呢?
类库调研
首先可以想到的就是借助成熟类库的力量,下面表格是较为常见的几款 worker 类库,其中我们可能会关注的关键能力有:
-
·通信是否有包装成更好用的方式,比如
promise化或者rpc化 -
·是否可以动态创建函数——可以增加
worker灵活性 -
·是否包含多
worker的管理能力,也就是线程池 -
·考虑
node的使用场景,是否可以跨端运行

比较之下,workerpool[5] 胜出,它也是个年纪很大的库了,最早的代码提交在 6 年前,不过实践下来没有大问题,下文都会在使用它的基础上继续讨论。
有类库加持的 worker 现状
通过使用 workerpool,我们可以在主线程文件内新建 worker;它自动处理多 worker 的管理;可以执行 worker 内定义好的函数 a;可以动态创建一个函数并传入参数,让 worker 来执行。
// index.js
import workerpool from 'workerpool'
const pool = workerpool.pool('./worker.js')
// 执行一个 worker 内定义好的函数
pool.exec('a', [1, 2]).then((res) => {console.log(res)
})
// 执行一个自定义函数
pool.exec((x, y) => {return x + y}, // 自定义函数体[1, 2], // 自定义函数参数).then((res) => {console.log(res)})
// worker.js
importScripts('constant.js')
function a() {console.log('test')
}
但是这样还不够,为了可以舒适的写代码,我们需要进一步改造。
向着舒适无感的 worker 编写前进
我们期望的目标是:
-
·足够灵活:可以随意编写函数,今天我想计算
1+1,明天我想计算1+2,这些都可以动态编写,最好它可以直接写在主线程我自己的文件里,不需要我跑到worker文件里去改写; -
·足够强大:我可以使用公共依赖,比如
lodash或者是项目里已经定义好的某些公共函数。
考虑到 workerpool 具备了动态创建函数的能力,第一点已经可以实现;而第二点关于依赖的管理,则需要自行搭建,接下来介绍搭建步骤。
1. 抽取依赖,管理编译和更新:
新增一个依赖管理文件worker-depts.js,可按照路径作为 key 名构建一个聚合依赖对象,然后在 worker 文件内引入这份依赖
// worker-depts.js
import * as _ from 'lodash-es'
import * as math from '../math'const workerDepts = {_,'util/math': math,
}export default workerDepts
// worker.js
import workerDepts from '../util/worker/worker-depts'
2. 定义公共调用函数,引入所打包的依赖并串联流程:
worker 内定义一个公共调用函数,注入 worker-depts 依赖,并注册在 workerpool 的方法内
// worker.js
import workerDepts from '../util/worker/worker-depts'function runWithDepts(fn: any, ...args: any) {var f = new Function('return (' + fn + ').apply(null, arguments);')return f.apply(f, [workerDepts].concat(args))
}workerpool.worker({runWithDepts,
})
主线程文件内定义相应的调用方法,入参是自定义函数体和该函数的参数列表
// index.js
import workerpool from 'workerpool'
export async function workerDraw(fn, ...args) {const pool = workerpool.pool('./worker.js')return pool.exec('runWithDepts', [String(fn)].concat(args))
}
完成以上步骤,就可以在项目任意需要调用 worker 的位置,像下面这样。自定义函数内容,引用所需依赖(已注入在函数第一个参数),进行使用了。
这里我们引用了一个项目内的公共函数 fibonacci,也引用了一个 lodash 的 map 方法,都可以在depts 对象上取到
// 项目内需使用worker时
const res = await workerDraw((depts, m, n) => {const { map } = depts['_']const { fibonacci } = depts['util/math']return map([m, n], (num) => fibonacci(num))},input1,input2,
)
3. 优化语法支持
没有语法支持的依赖管理是很难用的,通过对 workerDraw 进行 ts 语法包装,可以实现在使用时的依赖提示:
import workerpool from 'workerpool'
import type TDepts from './worker-depts'export async function workerDraw<T extends any[], R>(fn: (depts: typeof TDepts, ...args: T) => Promise<R> | R, ...args: T) {const pool = workerpool.pool('./worker.js')return pool.exec('runWithDepts', [String(fn)].concat(args))
}
然后就可以在使用时获取依赖提示:

4. 其他问题
新增了 worker 以后,出现了 window和 worker 两种运行环境,如果你恰好和我一样需要兼容 node 端运行,那么运行环境就是三种,原本我们通常判断 window 环境使用的也许是 typeof window === 'object'这样,现在不够用了,这里可以改为 globalThis 对象,它是三套环境内都存在的一个对象,通过判断globalThis.constructor.name的值,值分别是'Window' / 'DedicatedWorker'/ 'Object',从而实现环境的区分
总结
通过使用 workerpool,添加依赖管理和构建公共 worker 调用函数,我们实现了一套按需调用,灵活强大的 worker 使用方式。
在京东羚珑的程序化设计项目中,通过把 skia 图形绘制部分逐步改造为 worker内调用,我们实现了整体服务耗时降低 75% 的效果,收益还是非常不错的。
文中涉及的代码示例都已放在 github[6] 上,内有 vite 和 webpack 两个完整实现版本,感兴趣的小伙伴可以 clone 下来参照着看~
参考资料
[1] Is postMessage slow: https://dassur.ma/things/is-postmessage-slow/
[2] redux 挪到了 worker 内: https://blog.axlight.com/posts/off-main-thread-react-redux-with-performance
[3] dom 挪到了 worker 内: https://github.com/ampproject/worker-dom
[4] 可使用多核能力的框架: https://github.com/neomjs/neo
[5] workerpool: https://github.com/josdejong/workerpool
[6] github: https://github.com/Silencesnow/worker-demo-2022
[7] MDN Web Workers API: https://developer.mozilla.org/zh-CN/docs/Web/API/Web_Workers_API
[8] workerpool: https://github.com/josdejong/workerpool
[9] 前端项目上 Web Worker 实践: https://www.youtube.com/watch?v=AEpG-3XXrjk
[10] Web Worker 文献综述: https://juejin.cn/post/6854573213297410062
相关文章:
2023 年的 Web Worker 项目实践
目录 前言 引入 Web Worker Worker 实践 Worker 到底有多难用 类库调研 有类库加持的 worker 现状 向着舒适无感的 worker 编写前进 1. 抽取依赖,管理编译和更新: 2. 定义公共调用函数,引入所打包的依赖并串联流程: 3. …...
C++的最后一道坎 | 百万年薪的程序员
| 导语 C 的起源可以追溯到 40 年前,但它仍然是当今使用最广泛的编程语言之一,C发明人Bjarne Stroustrup 一开始没想到 C 会获得如此大的成功,他说:“C 的成功显然令人惊讶。我认为它的成功取决于其最初的设计目标,就是…...

Unity的OnOpenAsset:深入解析与实用案例
Unity OnOpenAsset 在Unity中,OnOpenAsset是一个非常有用的回调函数,它可以在用户双击资源文件时自动打开一个编辑器窗口。这个回调函数可以用于自定义资源编辑,提高工作效率。本文将介绍OnOpenAsset的使用方法,并提供三个使用例…...
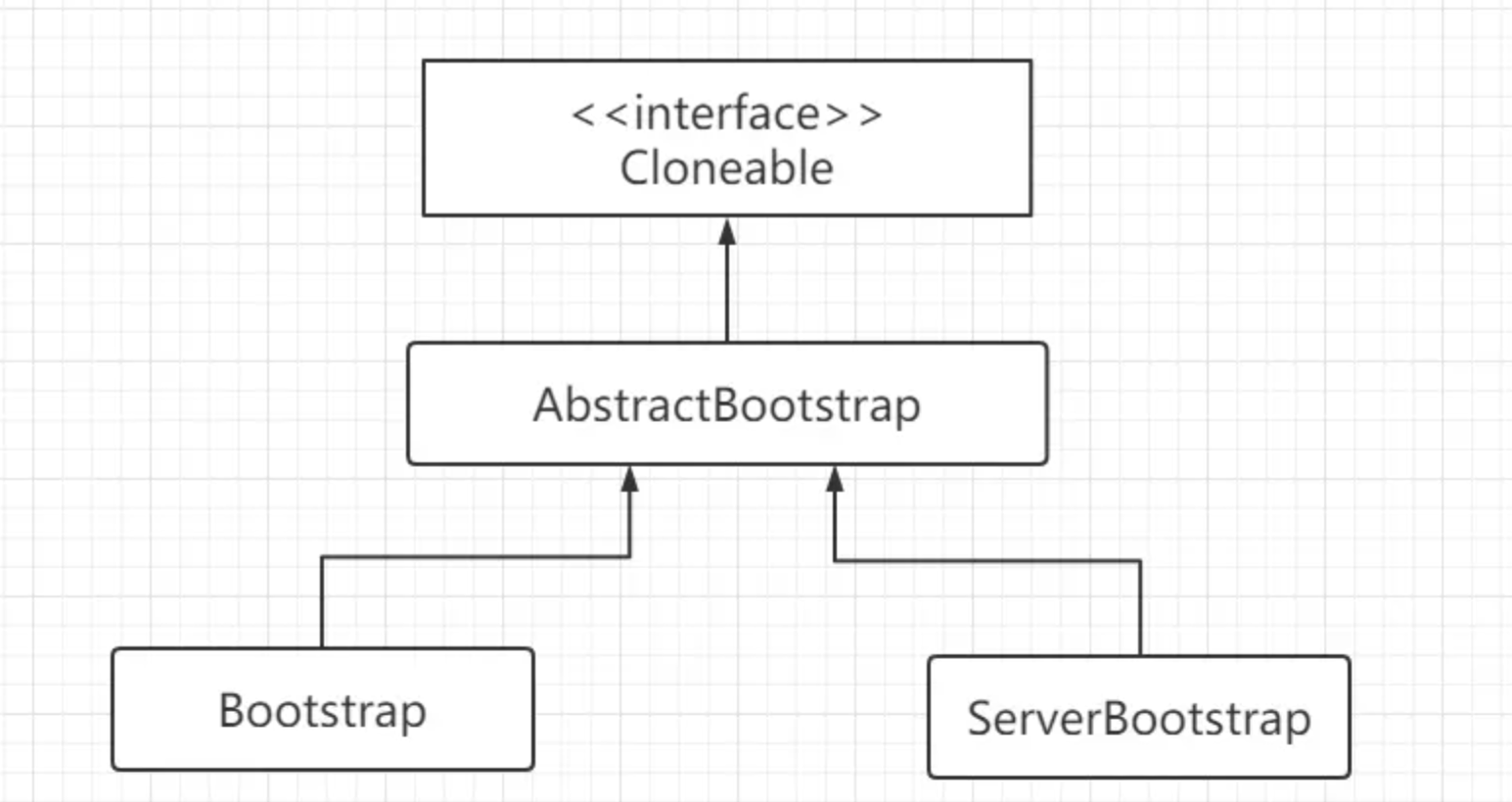
【Netty】Netty 程序引导类(九)
文章目录 前言一、引导程序类二、AbstractBootStrap 抽象类三、Bootstrap 类四、ServerBootstrap 类五、引导服务器5.1、 实例化引导程序类5.2、设置 EventLoopGroup5.3、指定 Channel 类型5.4、指定 ChannelHandler5.5、设置 Channel 选项5.6、绑定端口启动服务 六、引导客户端…...

如何使用进行MQ中间件接口测试
进行MQ中间件接口测试时,需要按以下步骤进行: 1.配置测试环境 搭建MQ服务器环境,并确保连接配置正确,以及客户端SDK等相关依赖库和组件已安装并配置正确。 2.制定测试计划 测试人员需要根据具体业务场景和测试目的,制…...

Zebec生态进展迅速,频被BitFlow、Matryx DAO等蹭热度碰瓷
进入到 2023 年以来, Zebec 生态的整体发展突飞猛进,除了流支付协议 Zebec Protocol 不断通过收购来扩大自身流支付业务、与万事达等合作推出 Zebec Card 等在支付业务上,实现进展外,其社区驱动的Layer3 模块化链 Nautilus Chain …...
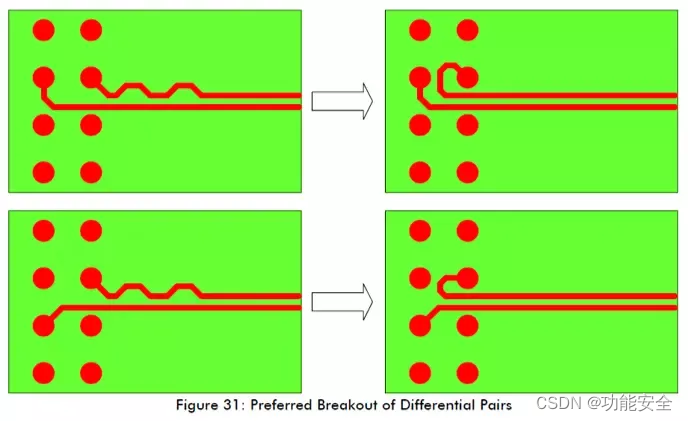
7种PCB走线方式
01电源布局布线相关 数字电路很多时候需要的电流是不连续的,所以对一些高速器件就会产生浪涌电流。 如果电源走线很长,则由于浪涌电流的存在进而会导致高频噪声,而此高频噪声会引入到其他信号中去。 而在高速电路中必然会存在寄生电感和寄…...

Rabbit SpringBoot高级用法
Rabbit高级用法 一、Rabbit Springboot集成1.1 引入依赖1.2 添加配置1.3 添加Config1.4 编写Consumer1.5 发送消息 二、Rabbit 高级用法2.1 消息发送前置处理器2.2 消息发送确认机制2.3 消息接收后处理器2.4 事务消息 一、Rabbit Springboot集成 1.1 引入依赖 <dependency…...

找不到vcruntime140.dll,无法继续执行代码?多种解决方法解析
找不到vcruntime140.dll,无法继续执行代码?当你在尝试运行某个程序时,突然弹出一条错误提示框,告诉你无法继续执行代码,因为找不到vcruntime140.dll。这个问题很常见,但是它可能会让你感到困惑和疑惑。这篇文章将详细介…...
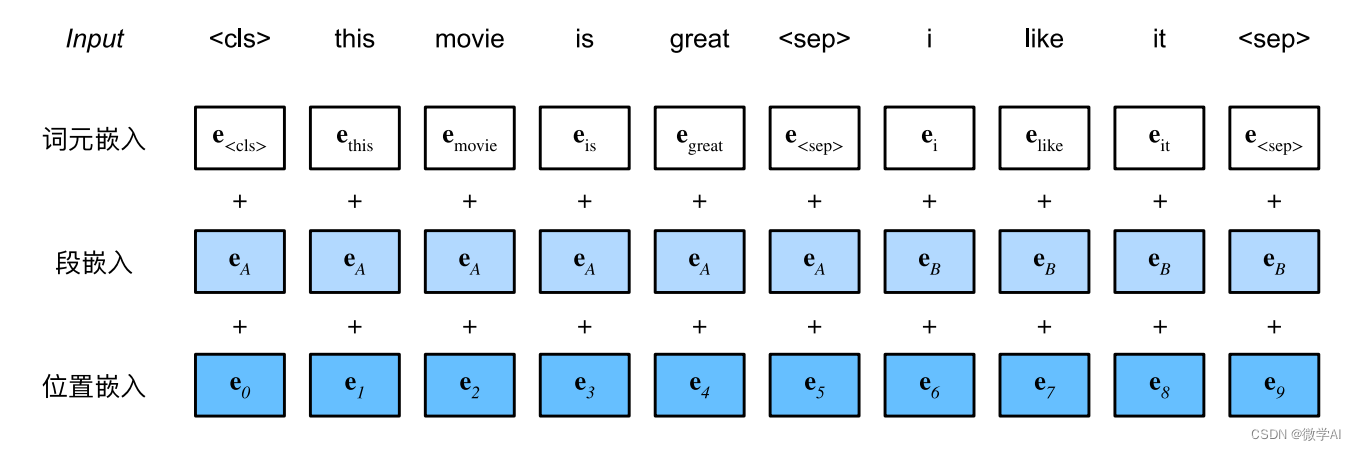
自然语言处理实战项目8- BERT模型的搭建,训练BERT实现实体抽取识别的任务
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目8- BERT模型的搭建,训练BERT实现实体抽取识别的任务。BERT模型是一种用于自然语言处理的深度学习模型,它可以通过训练来理解单词之间的上下文关系,从而为下游…...
pdf怎么合并在一起?软件操作更高效
PDF格式已经成为了许多文档和表格的首选格式。然而,当你需要合并多个PDF文件时,可能会遇到一些麻烦,在本篇文章中,我们将向您介绍一种简单易用的方法来合并PDF文件。 以下是可以用来合并PDF文件的软件: - PDF转换器&a…...
Junit常见用法
一.Junit的含义 Junit是一种Java编程语言的单元测试框架。它提供了一些用于编写和运行测试的注释和断言方法,并且可以方便地执行测试并生成测试报告。Junit是开源的,也是广泛使用的单元测试框架之一 二.Junit项目的创建 (1)先创…...

c++—内存管理、智能指针、内存池
1. 内存分析诊断工具:valgrind; 2. 内存管理的两种方式: ①用户管理:自己申请的,自己用,自己回收;效率高,但容易导致内存泄漏; ②系统管理:系统自动回收垃圾…...

JAVA使用HTTP代码示例
以下是使用Java发送HTTP请求的示例代码: java import java.io.BufferedReader; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; public class HttpExample { public static void main(String[] args) { try { …...
【网络协议详解】——电子邮件系统协议(学习笔记)
目录 🕒 1. 电子邮件系统概述🕒 2. 简单邮件传送协议SMTP🕒 3. SMTP协议的命令和响应🕘 3.1 命令🕤 3.1.1 HELO🕤 3.1.2 MAIL FROM🕤 3.1.3 RCPT TO🕤 3.1.4 DATA🕤 3.1.…...
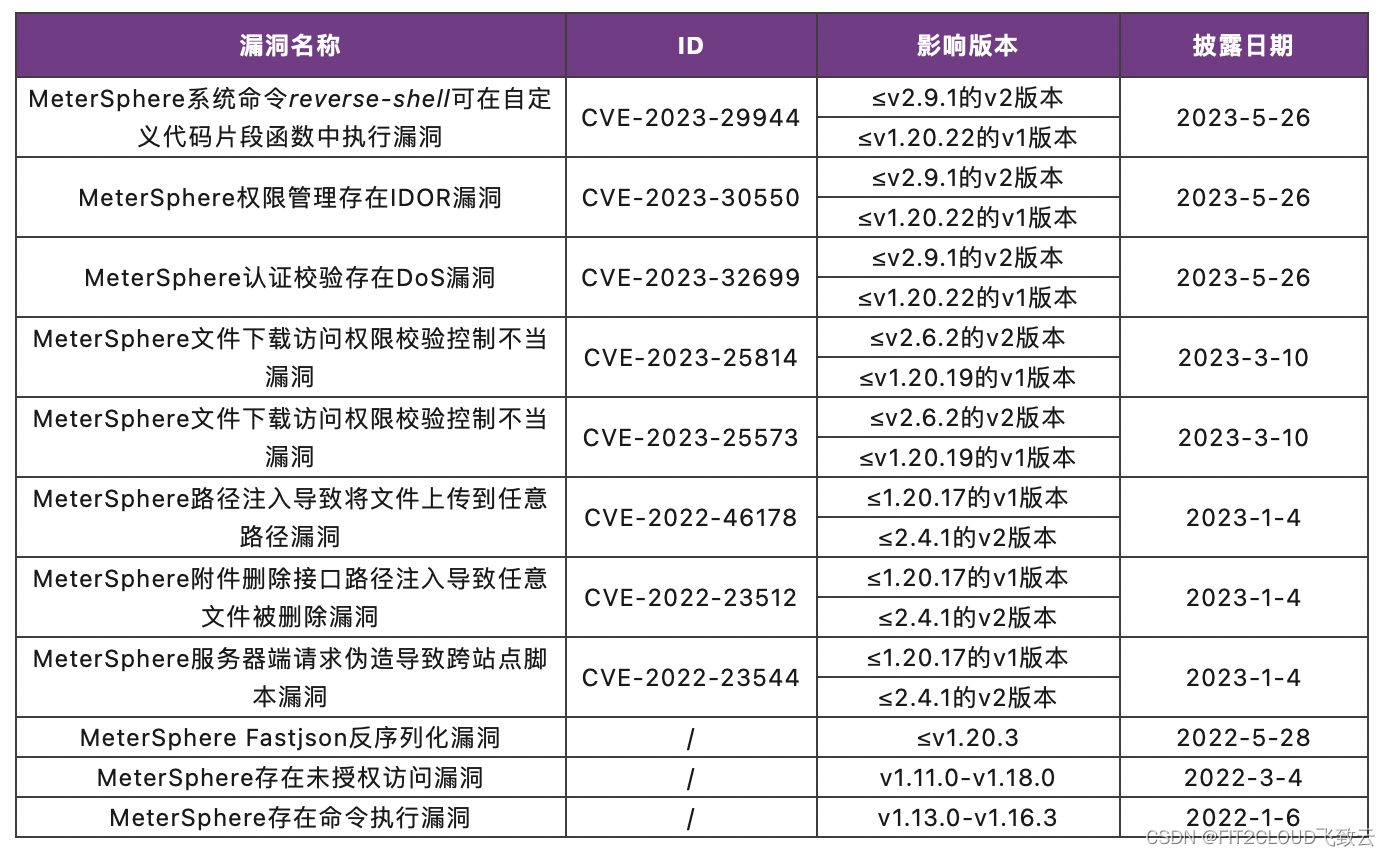
年度发布 | MeterSphere一站式开源持续测试平台发布v2.10 LTS版本
2023年5月25日,MeterSphere一站式开源持续测试平台正式发布v2.10 LTS版本。这是继2022年5月发布v1.20 LTS版本后,MeterSphere开源项目发布的第三个LTS(Long Term Support)版本。MeterSphere开源项目组将对MeterSphere v2.10 LTS版…...
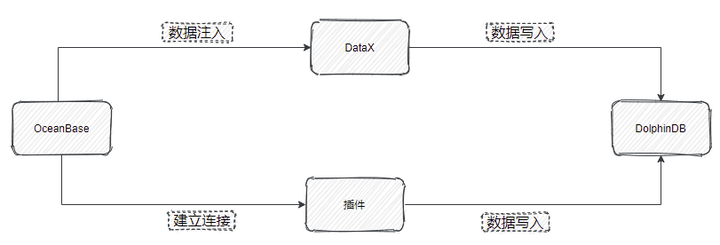
从 OceanBase 迁移数据到 DolphinDB
OceanBase 是一款金融级分布式关系数据库,具有数据强一致、高可用、高性能、在线扩展、高度兼容 SQL标准和主流关系数据库、低成本等特点,但是其学习成本较高,且缺乏金融计算函数以及流式增量计算的功能。 DolphinDB 是一款国产的高性能分布…...

淘宝商品列表数据接口(支持价格、销量排序)
淘宝商品列表数据接口是淘宝提供的一种可以获取淘宝商品信息的接口。通过该接口,可以获取到具有一定规则的商品信息,例如按照价格排序、按照销量排序等。接口返回的数据格式为JSON格式,可以方便地处理数据。 我们可以通过调用淘宝提供的API&…...

Android 11 版本变更总览
Android 11 版本 Android 11 总览重大隐私权变更行为变更:所有应用行为变更:以 Android 11 为目标平台的应用功能和 API 概览Intent系统广播 intent(API 级别 30)通用应用 intent(API 级别 30) Android 11 …...

传染病学模型 | Matlab实现基于SIS传染病模型模拟城市内人口的互相感染及城市人口流动所造成的传染
文章目录 效果一览基本描述模型介绍程序设计参考资料效果一览 基本描述 传染病学模型 | Matlab实现基于SIS传染病模型模拟城市内人口的互相感染及城市人口流动所造成的传染 模型介绍 SIS模型是一种基本的传染病学模型,用于描述一个人群中某种传染病的传播情况。SIS模型假设每个…...

基于流形学习的无人机起降场风场实时估计方法
1. 项目概述与核心挑战在无人机(UAV)起降场,特别是城市楼顶的垂直起降场(Vertiport),风场环境极其复杂。建筑物干扰会产生分离、再附、涡旋等非定常流动结构,对无人机的姿态稳定、轨迹控制和着陆…...

你的Linux启动慢?可能是UEFI这七个阶段在“摸鱼”!性能调优实战指南
Linux启动慢?UEFI七阶段性能调优实战指南当你的Linux系统启动速度像蜗牛爬行时,问题可能隐藏在UEFI启动的七个关键阶段中。本文将带你深入UEFI启动流程的每个环节,揭示可能导致延迟的"摸鱼"行为,并提供针对性的优化方案…...

PlayAI在特殊教育中的突破性应用:自闭症儿童社交训练响应率提升4.8倍的神经反馈模型首次公开
更多请点击: https://kaifayun.com 第一章:PlayAI教育领域应用案例 PlayAI 是一个面向教育场景的轻量级AI交互平台,支持教师快速构建可对话、可评估、可追踪的学习代理。其核心优势在于无需深度学习背景即可配置多轮问答逻辑、知识图谱链接…...

模块化AI:从大脑启示到工程实践,构建高效智能系统的核心范式
1. 引言:为什么我们需要重新审视“模块化”?在人工智能领域,我们正处在一个看似矛盾的时代。一方面,以大型语言模型(LLM)和深度神经网络(DNN)为代表的“单体巨兽”展现出了前所未有的…...
)
手把手教你用Python+OpenBMI复现运动想象BCI实验(附完整代码与数据集)
Python实战:从OpenBMI到运动想象脑机接口的全流程复现指南在认知科学与脑机接口(BCI)研究领域,运动想象(Motor Imagery)实验一直是经典范式。传统上,这类实验多依赖Matlab生态完成,但随着Python在科学计算领域的崛起,越…...

AI 开发工具选择指南:Qoder、Qwen 与开发者使用策略
AI 开发工具选择指南:Qoder、Qwen 与开发者使用策略 引言 在 AI 技术快速发展的今天,越来越多的 AI 工具涌现出来,帮助开发者提高工作效率。但对于许多开发者来说,面对众多的 AI 产品和服务,往往感到困惑:这…...

降AI率天花板!AI率92%暴降至5%!实测10款降AIGC平台!免费额度狂薅攻略
2026 年各大高校和期刊平台的 AI 检测系统又升级了,知网 AIGC、维普 AI、万方智能检测三大平台的算法迭代速度越来越快,上个月能蒙混过关的改写方式,这个月直接就会被标红预警。单纯的同义词替换、语序调整早就不管用了,想要有效降…...

告别调参噩梦:用nnU-Net自动搞定医学影像分割,新手也能发顶会论文
告别调参噩梦:用nnU-Net自动搞定医学影像分割,新手也能发顶会论文 医学影像分割一直是深度学习领域的热门研究方向,但对于大多数临床医生和科研新手来说,复杂的模型调参过程往往成为难以跨越的技术鸿沟。想象一下,当你…...
)
紧急!2024年Q2最新:Claude 3.5 Sonnet对LaTeX/Markdown混合文档的支持边界实测报告(附绕过限制的3种军工级方案)
更多请点击: https://kaifayun.com 第一章:Claude 3.5 Sonnet对LaTeX/Markdown混合文档的原生支持能力全景评估 Claude 3.5 Sonnet 在处理 LaTeX 与 Markdown 混合文档时展现出显著增强的解析鲁棒性与语义理解深度,尤其在数学公式嵌入、交叉…...

AI答案优化效果可以靠哪些第三方数据验证?
先给结论:AI答案优化效果要做三层交叉验证AI 答案优化、GEO 服务的效果,不应只听服务商自述,也不适合只靠单张 AI 回答截图判断。更稳妥的做法,是用三层数据交叉验证:AI回答层数据:看品牌是否被提及、位置是…...