自然语言处理实战项目8- BERT模型的搭建,训练BERT实现实体抽取识别的任务
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目8- BERT模型的搭建,训练BERT实现实体抽取识别的任务。BERT模型是一种用于自然语言处理的深度学习模型,它可以通过训练来理解单词之间的上下文关系,从而为下游任务提供高质量的语言表示。它的结构是由多个Transformer编码器组成的,而Transformer编码器是由多个自注意力机制组成的。在训练中,模型通过预测遮盖的单词和判断两个句子之间的关系来提高语言表示的准确性。在实体识别任务中,BERT模型可以作为特征提取器使用,将每个单词的上下文相关的向量表示输入到分类器中完成实体识别。
一、BERT模型的框架
BERT的基础结构是多层的Transformer编码器架构。Transformer是一种自注意力机制,允许模型在不同的词语之间捕获重要的关系。具体而言,BERT使用自注意力头为文本序列中的每个单词生成一个向量表示,同时捕捉了整个句子的上下文信息。这些向量表示可以从底层到更高层进行组合,从而允许模型学习更加复杂的语义结构。
BERT模型有两种主要的预训练模型:
1.BERT-Base:包含12层(Encoder layers)、12个自注意力头(Attention heads)和768个隐藏层大小(Hidden size),总共有约 110M 个参数。
2.BERT-Large:包含 24层(Encoder layers)、16个自注意力头(Attention heads)和1024个隐藏层大小(Hidden size),总共约340M个参数。
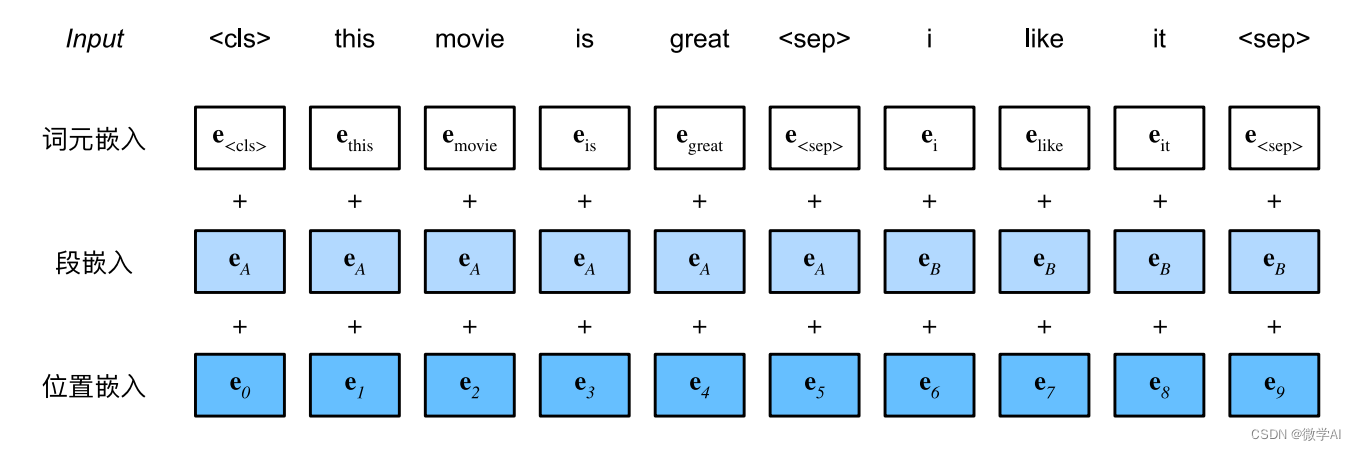 二、BERT的预训练
二、BERT的预训练
BERT的预训练主要分为两个阶段:预训练和微调。
2.1 预训练:
在预训练阶段,BERT的创新之举是利用大量无标注文本进行双向训练。在这个阶段,BERT引入了两个预训练任务:掩码语言建模(MLM) 和 下一句预测(NSP)。
掩码语言建模(MLM):在训练过程中,输入句子中的一部分单词被随机替换为一个特殊的掩码符号(MASK)。模型的目标是根据句子其他部分的上下文信息,预测被掩码的单词。这种训练方式使模型能够学习双向的语义信息。
下一句预测(NSP):这个任务旨在让模型学习理解句子之间的关系。给定一对句子,模型需要预测第二个句子是否紧跟在第一个句子之后。这个任务有助于BERT更好地应对需要理解多个句子关系的任务,如问答和自然语言推理等。
2.2 微调:
在预训练阶段完成后,BERT模型已经学会了丰富的语义表示。然后,在实际的NLP任务中,我们需要对预训练的BERT进行微调。微调阶段只需较少的标注数据就能使模型针对具体任务进行优化。
在微调过程中,通常在BERT模型的顶部添加一个任务相关的神经网络层,如全连接层、卷积层等。然后连同BERT整个模型进行端到端的微调训练。在训练时,利用带标签的数据计算损失,利用梯度下降进行参数更新。经过微调后,BERT能够根据特定任务生成更有针对性的结果。
三、训练BERT实现实体抽取识别的任务
以下是一个使用PyTorch和Hugging Face Transformers库的BERT模型进行中文命名实体识别任务的完整代码,第三方库载入,数据样例导入。
import torch
from torch.utils.data import Dataset, DataLoader
from transformers import BertTokenizer, BertForTokenClassification, AdamW
from sklearn.model_selection import train_test_split
from tqdm import tqdmdef load_data_from_txt(file_path):with open(file_path, "r", encoding="utf-8") as f:lines = f.readlines()data = []for line in lines:line = line.strip()if not line:continuetoken, label = line.split()data.append((token, label))return datafile_path = 'ner_data.txt'
data = load_data_from_txt(file_path)
print(data)ner_data.txt文件数据样例:
李 B-PER
华 I-PER
山 I-PER
是 O
一 O
个 O
优 O
秀 O
的 O
程 O
序 O
员 O
。 O
阿 B-ORG
里 I-ORG
巴 I-ORG
巴 I-ORG
是 O
一 O
家 O
著 O
名 O
的 O
中 B-LOC
国 I-LOC
公 O
司 O
。 O
陈 B-PER
明 I-PER
在 O
北 B-LOC
京 I-LOC
上 O
了 O
一 O
所 O
大 O
学 O
。 O模型加载与训练:
# 预处理
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
label_map = {"B-PER": 0, "I-PER": 1, "B-ORG": 2, "I-ORG": 3, "B-EDU":4,"I-EDU":5, "B-LOC":6,"I-LOC":7,"O": 8}
inverse_label_map = {v: k for k, v in label_map.items()}class NERDataset(Dataset):def __init__(self, data, tokenizer, label_map):self.data = dataself.tokenizer = tokenizerself.label_map = label_mapdef __len__(self):return len(self.data)def __getitem__(self, idx):token, label = self.data[idx]input_ids = tokenizer.encode(token, add_special_tokens=False)label_id = self.label_map[label]return torch.tensor(input_ids, dtype=torch.long), torch.tensor(label_id, dtype=torch.long)dataset = NERDataset(data, tokenizer, label_map)
train_data, val_data = train_test_split(dataset, test_size=0.2, random_state=42)
train_loader = DataLoader(train_data, batch_size=1, shuffle=True)
val_loader = DataLoader(val_data, batch_size=1, shuffle=False)# 模型
model = BertForTokenClassification.from_pretrained("bert-base-chinese", num_labels=len(label_map))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)# 优化器
optimizer = AdamW(model.parameters(), lr=5e-5)# 训练
num_epochs = 8
for epoch in range(num_epochs):model.train()total_loss = 0total_correct = 0total_count = 0for batch in tqdm(train_loader):input_ids, labels = batchinput_ids = input_ids.to(device)labels = labels.to(device)optimizer.zero_grad()outputs = model(input_ids, labels=labels)loss = outputs.lossloss.backward()optimizer.step()total_loss += loss.item()total_correct += (outputs.logits.argmax(-1) == labels).sum().item()total_count += labels.size(0)avg_loss = total_loss / total_countaccuracy = total_correct / total_countprint(f"Epoch {epoch + 1}/{num_epochs}, Loss: {avg_loss:.4f}, Accuracy: {accuracy:.4f}")运行结果:
100%|██████████| 97/97 [00:39<00:00, 2.47it/s]0%| | 0/97 [00:00<?, ?it/s]Epoch 1/10, Loss: 1.4691, Accuracy: 0.5979
100%|██████████| 97/97 [00:40<00:00, 2.42it/s]
Epoch 2/10, Loss: 1.3695, Accuracy: 0.6598
100%|██████████| 97/97 [00:39<00:00, 2.48it/s]
Epoch 3/10, Loss: 1.2924, Accuracy: 0.5979
100%|██████████| 97/97 [00:39<00:00, 2.48it/s]0%| | 0/97 [00:00<?, ?it/s]Epoch 4/10, Loss: 1.3100, Accuracy: 0.6701
100%|██████████| 97/97 [00:37<00:00, 2.59it/s]
Epoch 5/10, Loss: 1.2179, Accuracy: 0.6598
100%|██████████| 97/97 [00:40<00:00, 2.39it/s]0%| | 0/97 [00:00<?, ?it/s]Epoch 6/10, Loss: 0.9726, Accuracy: 0.6495
100%|██████████| 97/97 [00:39<00:00, 2.46it/s]0%| | 0/97 [00:00<?, ?it/s]Epoch 7/10, Loss: 1.0536, Accuracy: 0.6186
100%|██████████| 97/97 [00:40<00:00, 2.42it/s]
Epoch 8/10, Loss: 0.9458, Accuracy: 0.6907相关文章:
自然语言处理实战项目8- BERT模型的搭建,训练BERT实现实体抽取识别的任务
大家好,我是微学AI,今天给大家介绍一下自然语言处理实战项目8- BERT模型的搭建,训练BERT实现实体抽取识别的任务。BERT模型是一种用于自然语言处理的深度学习模型,它可以通过训练来理解单词之间的上下文关系,从而为下游…...
pdf怎么合并在一起?软件操作更高效
PDF格式已经成为了许多文档和表格的首选格式。然而,当你需要合并多个PDF文件时,可能会遇到一些麻烦,在本篇文章中,我们将向您介绍一种简单易用的方法来合并PDF文件。 以下是可以用来合并PDF文件的软件: - PDF转换器&a…...
Junit常见用法
一.Junit的含义 Junit是一种Java编程语言的单元测试框架。它提供了一些用于编写和运行测试的注释和断言方法,并且可以方便地执行测试并生成测试报告。Junit是开源的,也是广泛使用的单元测试框架之一 二.Junit项目的创建 (1)先创…...

c++—内存管理、智能指针、内存池
1. 内存分析诊断工具:valgrind; 2. 内存管理的两种方式: ①用户管理:自己申请的,自己用,自己回收;效率高,但容易导致内存泄漏; ②系统管理:系统自动回收垃圾…...

JAVA使用HTTP代码示例
以下是使用Java发送HTTP请求的示例代码: java import java.io.BufferedReader; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; public class HttpExample { public static void main(String[] args) { try { …...
【网络协议详解】——电子邮件系统协议(学习笔记)
目录 🕒 1. 电子邮件系统概述🕒 2. 简单邮件传送协议SMTP🕒 3. SMTP协议的命令和响应🕘 3.1 命令🕤 3.1.1 HELO🕤 3.1.2 MAIL FROM🕤 3.1.3 RCPT TO🕤 3.1.4 DATA🕤 3.1.…...
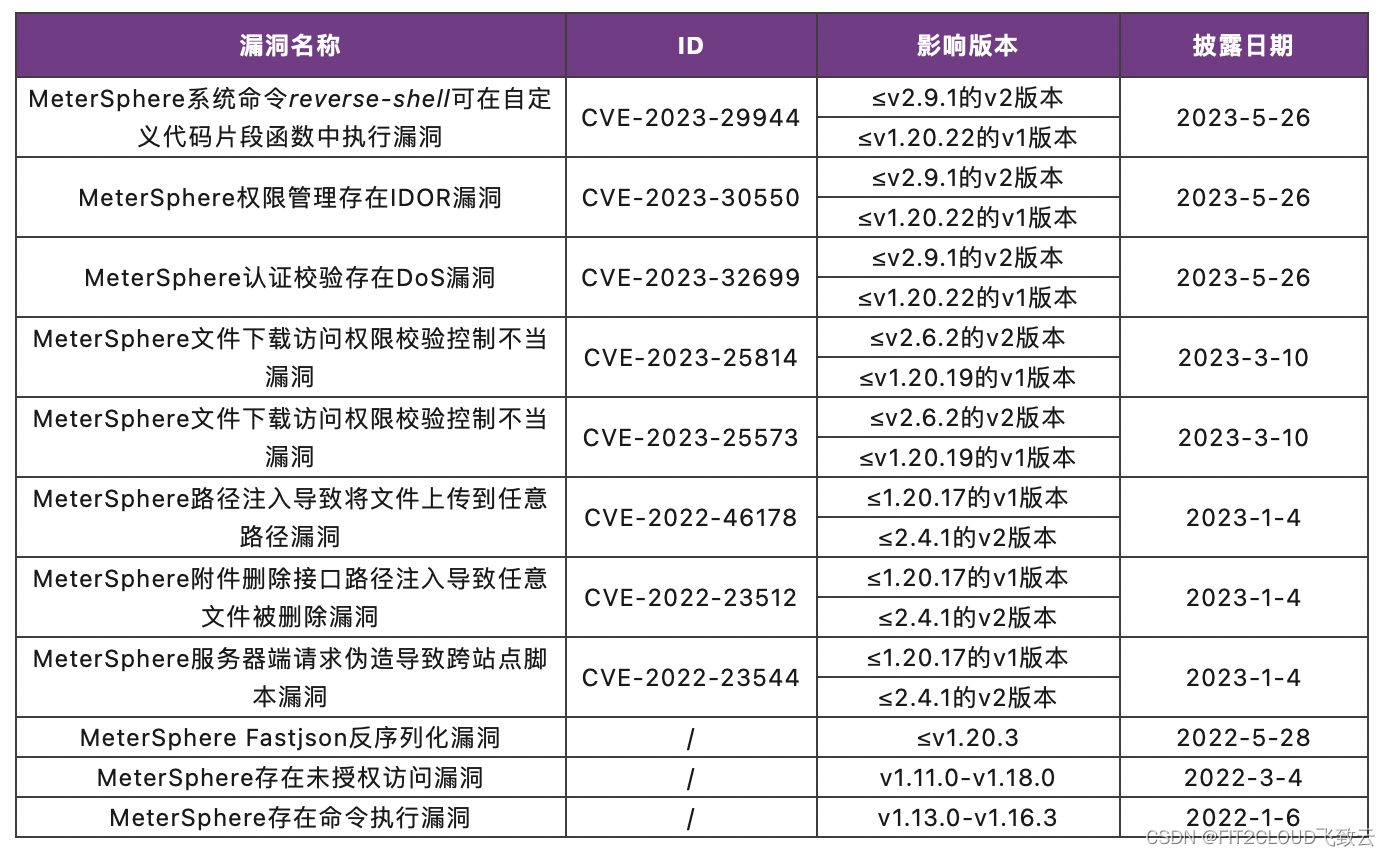
年度发布 | MeterSphere一站式开源持续测试平台发布v2.10 LTS版本
2023年5月25日,MeterSphere一站式开源持续测试平台正式发布v2.10 LTS版本。这是继2022年5月发布v1.20 LTS版本后,MeterSphere开源项目发布的第三个LTS(Long Term Support)版本。MeterSphere开源项目组将对MeterSphere v2.10 LTS版…...
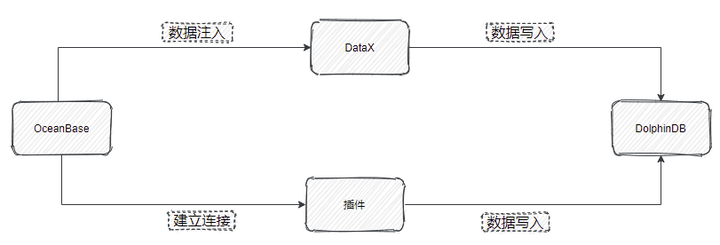
从 OceanBase 迁移数据到 DolphinDB
OceanBase 是一款金融级分布式关系数据库,具有数据强一致、高可用、高性能、在线扩展、高度兼容 SQL标准和主流关系数据库、低成本等特点,但是其学习成本较高,且缺乏金融计算函数以及流式增量计算的功能。 DolphinDB 是一款国产的高性能分布…...

淘宝商品列表数据接口(支持价格、销量排序)
淘宝商品列表数据接口是淘宝提供的一种可以获取淘宝商品信息的接口。通过该接口,可以获取到具有一定规则的商品信息,例如按照价格排序、按照销量排序等。接口返回的数据格式为JSON格式,可以方便地处理数据。 我们可以通过调用淘宝提供的API&…...

Android 11 版本变更总览
Android 11 版本 Android 11 总览重大隐私权变更行为变更:所有应用行为变更:以 Android 11 为目标平台的应用功能和 API 概览Intent系统广播 intent(API 级别 30)通用应用 intent(API 级别 30) Android 11 …...

传染病学模型 | Matlab实现基于SIS传染病模型模拟城市内人口的互相感染及城市人口流动所造成的传染
文章目录 效果一览基本描述模型介绍程序设计参考资料效果一览 基本描述 传染病学模型 | Matlab实现基于SIS传染病模型模拟城市内人口的互相感染及城市人口流动所造成的传染 模型介绍 SIS模型是一种基本的传染病学模型,用于描述一个人群中某种传染病的传播情况。SIS模型假设每个…...

物联网技术如何改变我们的生活:一位资深物联网专家的见解
物联网(IoT)是指通过网络互联的物理设备、车辆、建筑物以及其他物品,这些物品都内置了传感器、执行器、软件和网络连接器,使它们能够收集和交换数据。物联网技术已经在各个领域产生了深远的影响,包括家庭、医疗、交通、…...
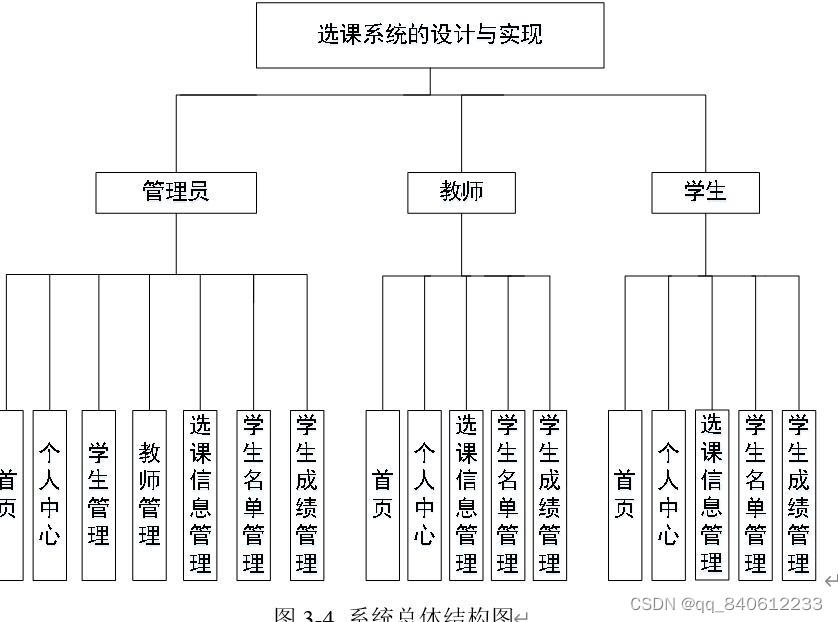
node.js+vue.js大学生在线选课系统的设计与实现93pul
本次设计任务是要设计一个选课系统的设计与实现,通过这个系统能够满足用户对选课信息的需求。系统的主要功能包括:个人中心、学生管理、教师管理、选课信息管理等功能。 管理员可以根据系统给定的账号进行登录,登录后可以进入选课系统的设计与…...

华为OD机试真题 Java 实现【寻找符合要求的最长子串】【2023Q1 200分】
一、题目描述 给定一个字符串 s ,找出这样一个子串: 该子串中的任意一个字符最多出现2次;该子串不包含指定某个字符;请你找出满足该条件的最长子串的长度。 二、输入描述 第一行为要求不包含的指定字符,为单个字符,取值范围[0-9a-zA-Z]。 第二行为字符串s,每个字符范…...
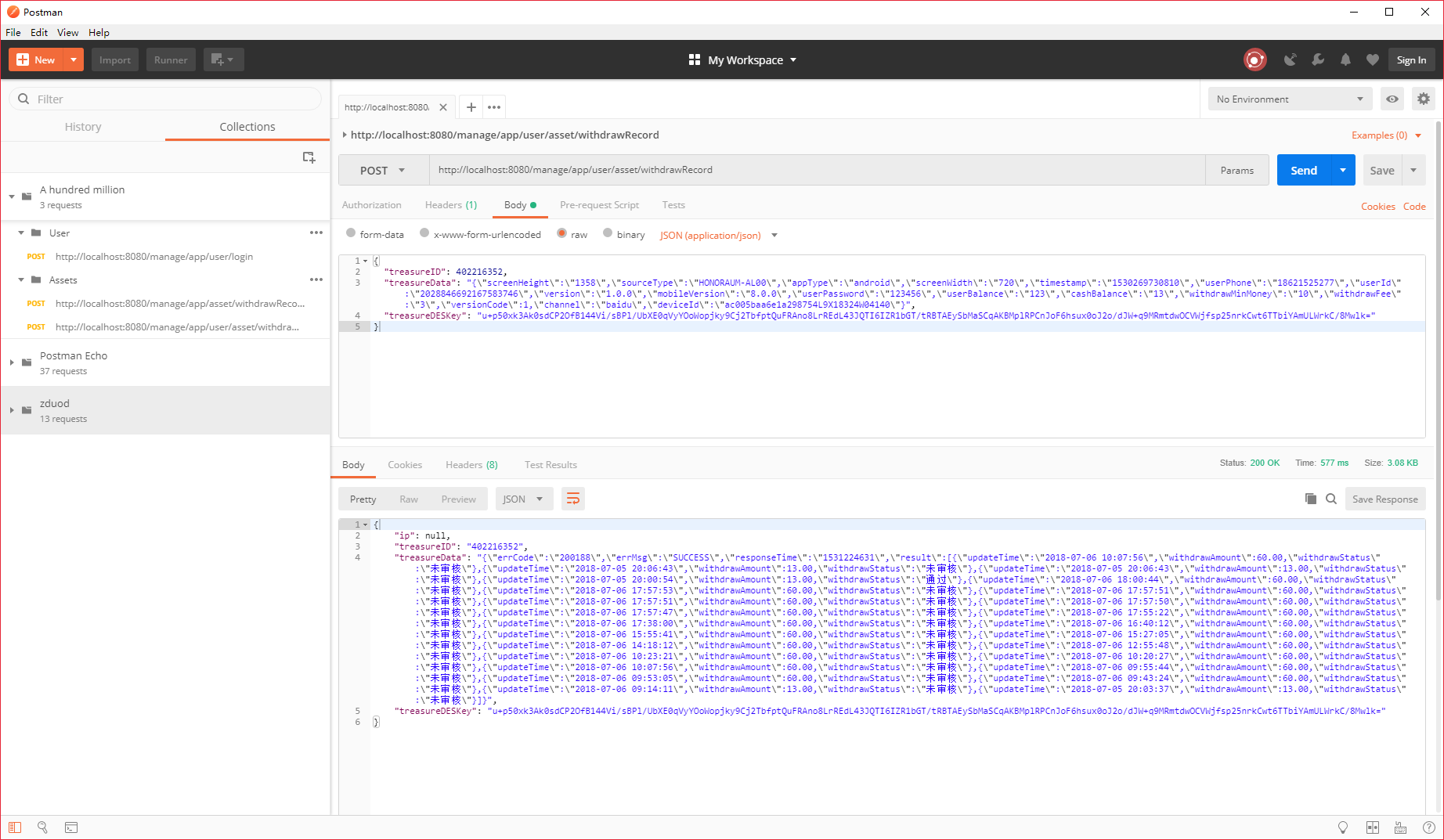
接口测试工具Postman接口测试图文教程
目录 一、前言 二、Postman安装和使用 三、请求方式 四、资金记录接口实例演示 一、前言 在前后端分离开发时,后端工作人员完成系统接口开发后,需要与前端人员对接,测试调试接口,验证接口的正确性可用性。而这要求前端开发进…...
视频编辑软件:迅捷视频工具箱
这是一款功能强大、易于使用的视频编辑工具,支持视频剪辑、视频转换、音频转换、视频压缩、视频水印、字幕贴图等实用功能,可以帮助你制作出高质量的视频作品。(传送门:https://www.xunjiepdf.com/xjspgjx) 功能简介 …...
网络知识点之-HTTP协议
超文本传输协议(Hyper Text Transfer Protocol,HTTP)是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。请求和响应消息的头以ASCII形式给出;而消息内…...

K类函数和KL类函数
Class K \mathcal{K} K function- K \mathcal{K} K类函数 Definition: A continuous function α : [ 0 , a ) → [ 0 , ∞ ) \alpha:[0,a)\rightarrow[0,\infin) α:[0,a)→[0,∞) is said belong to class K \mathcal{K} K if it strictly increasing and α ( 0 ) 0 …...
华为OD机试之完美走位(Java源码)
完美走位 题目描述 在第一人称射击游戏中,玩家通过键盘的A、S、D、W四个按键控制游戏人物分别向左、向后、向右、向前进行移动,从而完成走位。 假设玩家每按动一次键盘,游戏任务会向某个方向移动一步,如果玩家在操作一定次数的键…...
或特别的视频组件具体实现方法)
Vue 原始(传统)或特别的视频组件具体实现方法
一、原始的播放器组件(传统的视频播放组件) 参考链接 1. Vue2视频播放(Video) 二、自定义视频播放组件,自播放,无控制模式 简单点的理解,就是没有点击就会暂停播放视频,还有忽略…...

电池阻抗测量技术:伪随机序列与信号处理应用
1. 电池阻抗测量技术概述电池阻抗测量作为电化学系统状态监测的核心手段,其原理基于对电池施加特定激励信号并测量响应信号,通过分析两者的幅值和相位关系来获取阻抗谱。这种频域分析方法能够反映电池内部电荷转移、扩散过程等动力学特性,为电…...

去偏机器学习在交通行为因果推断中的应用:从关联分析到因果效应评估
1. 项目概述:当交通研究遇上因果推断在交通工程与城市规划领域,我们常常面临一个核心挑战:如何从海量的观测数据中,剥离出某个特定因素(比如一项新政策、一种交通管控措施)对人们行为的“真实”影响&#x…...

云原生数据库管理:在Kubernetes上运行数据库的完整指南
云原生数据库管理:在Kubernetes上运行数据库的完整指南 引言 在云原生环境中,数据库管理是一个复杂但至关重要的任务。与传统的数据库部署方式不同,在Kubernetes上运行数据库需要考虑容器化、高可用性、数据持久化等多个方面。 作为一名资深的…...

《Java 基础必学:ArrayList、HashMap 和泛型详解》
一、引言 1.为什么这些是 Java 基础的重点? ArrayList、HashMap 和泛型是Java集合框架的核心组成部分,广泛应用于实际开发中。 ArrayList:基于动态数组实现,支持快速随机访问,适合频繁查询和遍历的场景。HashMap&…...

书匠策AI降重降AIGC实测:论文圈的“消音器“到底有多猛?官网www.shujiangce.com深度拆解
各位还在论文泥潭里挣扎的宝子们,今天这期内容可能会让你少熬三个通宵。 我最近收到最多的私信就是:"博主,我查重42%,AIGC检测28%,导师说再改不过就延毕,怎么办?"说实话,…...

宏裕塑胶长玻纤RTP材料技术创新与应用实践
导读:在工程塑料领域,长玻纤增强热塑性材料(LFRT)正成为高端制造转型的核心驱动力。宏裕塑胶长玻纤RTP材料技术创新与应用实践,通过整合国际顶尖资源与自主改性技术,为汽车轻量化、新能源装备等场景提供高性…...

体验 Taotoken 官方价折扣与活动价带来的实际成本优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验 Taotoken 官方价折扣与活动价带来的实际成本优势 对于需要频繁调用大模型 API 的开发者和团队而言,成本控制是一个…...

今天不建Lovable ML平台,明天就被团队弃用!2025年AI工程团队留存率预警下的4步速建法
更多请点击: https://kaifayun.com 第一章:Lovable ML平台搭建 构建一个真正“可亲、可用、可信赖”的机器学习平台,核心不在于堆砌尖端框架,而在于以开发者体验(DX)和数据科学家工作流为设计原点。Lovab…...

AR眼镜主板与光机定制:从核心需求到量产落地的硬件开发指南
1. 项目概述:从一块主板到一副眼镜的蜕变最近几年,AR(增强现实)智能眼镜从科幻概念逐渐走进现实,无论是工业巡检、远程协作,还是消费娱乐,都能看到它的身影。但很多人可能不知道,决定…...

WorldArena榜单第一名Pelican-Unify 1.0:迈向具身智能统一范式的新里程碑
北京人形机器人创新中心团队发布首个统一理解、推理、想象与行动的具身基础模型 2026年5月 | 技术解读 图1 Pelican-Unify 1.0 统一具身智能模型概览:理解、推理、想象与行动的闭环融合 一、具身智能的范式演进:从模块化到统一化 具身智能(…...