使用Actor-Critic的DDPG强化学习算法控制双关节机械臂
在本文中,我们将介绍在 Reacher 环境中训练智能代理控制双关节机械臂,这是一种使用 Unity ML-Agents 工具包开发的基于 Unity 的模拟程序。 我们的目标是高精度的到达目标位置,所以这里我们可以使用专为连续状态和动作空间设计的最先进的Deep Deterministic Policy Gradient (DDPG) 算法。

现实世界的应用程序
机械臂在制造业、生产设施、空间探索和搜救行动中发挥着关键作用。控制机械臂的高精度和灵活性是非常重要的。通过采用强化学习技术,可以使这些机器人系统实时学习和调整其行为,从而提高性能和灵活性。强化学习的进步不仅有助于我们对人工智能的理解,而且有可能彻底改变行业并对社会产生有意义的影响。
而Reacher是一种机械臂模拟器,常用于控制算法的开发和测试。它提供了一个虚拟环境,模拟了机械臂的物理特性和运动规律,使得开发者可以在不需要实际硬件的情况下进行控制算法的研究和实验。
Reacher的环境主要由以下几个部分组成:
- 机械臂:Reacher模拟了一个双关节机械臂,包括一个固定基座和两个可动关节。开发者可以通过控制机械臂的两个关节来改变机械臂的姿态和位置。
- 目标点:在机械臂的运动范围内,Reacher提供了一个目标点,目标点的位置是随机生成的。开发者的任务是控制机械臂,使得机械臂的末端能够接触到目标点。
- 物理引擎:Reacher使用物理引擎来模拟机械臂的物理特性和运动规律。开发者可以通过调整物理引擎的参数来模拟不同的物理环境。
- 视觉界面:Reacher提供了一个可视化的界面,可以显示机械臂和目标点的位置,以及机械臂的姿态和运动轨迹。开发者可以通过视觉界面来调试和优化控制算法。
Reacher模拟器是一个非常实用的工具,可以帮助开发者在不需要实际硬件的情况下,快速测试和优化控制算法。
模拟环境
Reacher 使用 Unity ML-Agents 工具包构建,我们的代理可以控制双关节机械臂。 目标是引导手臂朝向目标位置并尽可能长时间地保持其在目标区域内的位置。 该环境具有 20 个同步代理,每个代理独立运行,这有助于在训练期间有效地收集经验。

状态和动作空间
了解状态和动作空间对于设计有效的强化学习算法至关重要。 在 Reacher 环境中,状态空间由 33 个连续变量组成,这些变量提供有关机械臂的信息,例如其位置、旋转、速度和角速度。 动作空间也是连续的,四个变量对应于施加在机械臂两个关节上的扭矩。 每个动作变量都是一个介于 -1 和 1 之间的实数。
任务类型和成功标准
Reacher 任务被认为是片段式的,每个片段都包含固定数量的时间步长。 代理的目标是在这些步骤中最大化其总奖励。 手臂末端执行器保持在目标位置的每一步都会获得 +0.1 的奖励。 当代理在连续 100 次操作中的平均得分达到 30 分或以上时,就认为成功。
了解了环境,下面我们将探讨 DDPG 算法、它的实现,以及它如何有效地解决这种环境中的连续控制问题。
连续控制的算法选择:DDPG
当涉及到像Reacher问题这样的连续控制任务时,算法的选择对于实现最佳性能至关重要。在这个项目中,我们选择了DDPG算法,因为这是一种专门设计用于处理连续状态和动作空间的actor-critic方法。
DDPG算法通过结合两个神经网络,结合了基于策略和基于值的方法的优势:行动者网络(Actor network)决定给定当前状态下的最佳行为,批评家网络(Critic network)估计状态-行为值函数(Q-function)。这两种网络都有目标网络,通过在更新过程中提供一个固定的目标来稳定学习过程。
通过使用Critic网络估计q函数,使用Actor网络确定最优行为,DDPG算法有效地融合了策略梯度方法和DQN的优点。这种混合方法允许代理在连续控制环境中有效地学习。
import random
from collections import deque
import torch
import torch.nn as nn
import numpy as npfrom actor_critic import Actor, Criticclass ReplayBuffer:def __init__(self, buffer_size, batch_size):self.memory = deque(maxlen=buffer_size)self.batch_size = batch_sizedef add(self, state, action, reward, next_state, done):self.memory.append((state, action, reward, next_state, done))def sample(self):batch = random.sample(self.memory, self.batch_size)states, actions, rewards, next_states, dones = zip(*batch)return states, actions, rewards, next_states, donesdef __len__(self):return len(self.memory)class DDPG:def __init__(self, state_dim, action_dim, hidden_dim, buffer_size, batch_size, actor_lr, critic_lr, tau, gamma):self.actor = Actor(state_dim, hidden_dim, action_dim, actor_lr)self.actor_target = Actor(state_dim, hidden_dim, action_dim, actor_lr)self.critic = Critic(state_dim, action_dim, hidden_dim, critic_lr)self.critic_target = Critic(state_dim, action_dim, hidden_dim, critic_lr)self.memory = ReplayBuffer(buffer_size, batch_size)self.batch_size = batch_sizeself.tau = tauself.gamma = gammaself._update_target_networks(tau=1) # initialize target networksdef act(self, state, noise=0.0):state = torch.tensor(state, dtype=torch.float32).unsqueeze(0)action = self.actor(state).detach().numpy()[0]return np.clip(action + noise, -1, 1)def store_transition(self, state, action, reward, next_state, done):self.memory.add(state, action, reward, next_state, done)def learn(self):if len(self.memory) < self.batch_size:returnstates, actions, rewards, next_states, dones = self.memory.sample()states = torch.tensor(states, dtype=torch.float32)actions = torch.tensor(actions, dtype=torch.float32)rewards = torch.tensor(rewards, dtype=torch.float32).unsqueeze(1)next_states = torch.tensor(next_states, dtype=torch.float32)dones = torch.tensor(dones, dtype=torch.float32).unsqueeze(1)# Update Criticself.critic.optimizer.zero_grad()with torch.no_grad():next_actions = self.actor_target(next_states)target_q_values = self.critic_target(next_states, next_actions)target_q_values = rewards + (1 - dones) * self.gamma * target_q_valuescurrent_q_values = self.critic(states, actions)critic_loss = nn.MSELoss()(current_q_values, target_q_values)critic_loss.backward()self.critic.optimizer.step()# Update Actorself.actor.optimizer.zero_grad()actor_loss = -self.critic(states, self.actor(states)).mean()actor_loss.backward()self.actor.optimizer.step()# Update target networksself._update_target_networks()def _update_target_networks(self, tau=None):if tau is None:tau = self.taufor target_param, param in zip(self.actor_target.parameters(), self.actor.parameters()):target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data)for target_param, param in zip(self.critic_target.parameters(), self.critic.parameters()):target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data)
上面的代码还使用了Replay Buffer,这可以提高学习效率和稳定性。Replay Buffer本质上是一种存储固定数量的过去经验或过渡的内存数据结构,由状态、动作、奖励、下一状态和完成信息组成。使用它的主要优点是使代理能够打破连续经验之间的相关性,从而减少有害的时间相关性的影响。
通过从缓冲区中抽取随机的小批量经验,代理可以从一组不同的转换中学习,这有助于稳定和概括学习过程。 Replay Buffer还可以让代理多次重用过去的经验,从而提高数据效率并促进从与环境的有限交互中更有效地学习。
DDPG算法是一个很好的选择,因为它能够有效地处理连续的动作空间,这是这个环境的一个关键方面。该算法的设计允许有效地利用多个代理收集的并行经验,从而实现更快的学习和更好的收敛。就像上面介绍的Reacher 可以同时运行20个代理,所以我们可以使用这20个代理进行分享经验,集体学习,提高学习速度。
完成了算法,下面我们将介绍、超参数选择和训练过程。
DDPG算法在Reacher 环境中工作
为了更好地理解算法在环境中的有效性,我们需要仔细研究学习过程中涉及的关键组件和步骤。
网络架构
DDPG算法采用两个神经网络,Actor 和Critic。两个网络都包含两个隐藏层,每个隐藏层包含400个节点。隐藏层使用ReLU (Rectified Linear Unit)激活函数,而Actor网络的输出层使用tanh激活函数产生范围为-1到1的动作。Critic网络的输出层没有激活函数,因为它直接估计q函数。
以下是网络的代码:
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optimclass Actor(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim, learning_rate=1e-4):super(Actor, self).__init__()self.fc1 = nn.Linear(input_dim, hidden_dim)self.fc2 = nn.Linear(hidden_dim, hidden_dim)self.fc3 = nn.Linear(hidden_dim, output_dim)self.tanh = nn.Tanh()self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)def forward(self, state):x = torch.relu(self.fc1(state))x = torch.relu(self.fc2(x))x = self.tanh(self.fc3(x))return xclass Critic(nn.Module):def __init__(self, state_dim, action_dim, hidden_dim, learning_rate=1e-4):super(Critic, self).__init__()self.fc1 = nn.Linear(state_dim, hidden_dim)self.fc2 = nn.Linear(hidden_dim + action_dim, hidden_dim)self.fc3 = nn.Linear(hidden_dim, 1)self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)def forward(self, state, action):x = torch.relu(self.fc1(state))x = torch.relu(self.fc2(torch.cat([x, action], dim=1)))x = self.fc3(x)return x
超参数选择
选择的超参数对于高效学习至关重要。在这个项目中,我们的Replay Buffer大小为200,000,批大小为256。演员Actor的学习率为5e-4,Critic的学习率为1e-3,soft update参数(tau)为5e-3,gamma为0.995。最后还加入了动作噪声,初始噪声标度为0.5,噪声衰减率为0.998。
训练过程
训练过程涉及两个网络之间的持续交互,并且20个平行代理共享相同的网络,模型会从所有代理收集的经验中集体学习。这种设置加快了学习过程,提高了效率。
from collections import deque
import numpy as np
import torchfrom ddpg import DDPGdef train_ddpg(env, agent, episodes, max_steps, num_agents, noise_scale=0.1, noise_decay=0.99):scores_window = deque(maxlen=100)scores = []for episode in range(1, episodes + 1):env_info = env.reset(train_mode=True)[brain_name]states = env_info.vector_observationsagent_scores = np.zeros(num_agents)for step in range(max_steps):actions = agent.act(states, noise_scale)env_info = env.step(actions)[brain_name]next_states = env_info.vector_observationsrewards = env_info.rewardsdones = env_info.local_donefor i in range(num_agents):agent.store_transition(states[i], actions[i], rewards[i], next_states[i], dones[i])agent.learn()states = next_statesagent_scores += rewardsnoise_scale *= noise_decayif np.any(dones):breakavg_score = np.mean(agent_scores)scores_window.append(avg_score)scores.append(avg_score)if episode % 10 == 0:print(f"Episode: {episode}, Score: {avg_score:.2f}, Avg Score: {np.mean(scores_window):.2f}")# Saving trained Networkstorch.save(agent.actor.state_dict(), "actor_final.pth")torch.save(agent.critic.state_dict(), "critic_final.pth")return scoresif __name__ == "__main__":env = UnityEnvironment(file_name='Reacher_20.app')brain_name = env.brain_names[0]brain = env.brains[brain_name]state_dim = 33action_dim = brain.vector_action_space_sizenum_agents = 20# Hyperparameter suggestionshidden_dim = 400batch_size = 256actor_lr = 5e-4critic_lr = 1e-3tau = 5e-3gamma = 0.995noise_scale = 0.5noise_decay = 0.998agent = DDPG(state_dim, action_dim, hidden_dim=hidden_dim, buffer_size=200000, batch_size=batch_size,actor_lr=actor_lr, critic_lr=critic_lr, tau=tau, gamma=gamma)episodes = 200max_steps = 1000scores = train_ddpg(env, agent, episodes, max_steps, num_agents, noise_scale=0.2, noise_decay=0.995)
训练过程中的关键步骤如下所示:
初始化网络:代理使用随机权重初始化共享的 Actor 和 Critic 网络及其各自的目标网络。 目标网络在更新期间提供稳定的学习目标。
- 与环境交互:每个代理使用共享的 Actor 网络,通过根据其当前状态选择动作来与环境交互。 为了鼓励探索,在训练的初始阶段还将噪声项添加到动作中。 采取行动后,每个代理都会观察由此产生的奖励和下一个状态。
- 存储经验:每个代理将观察到的经验(状态、动作、奖励、next_state)存储在共享重放缓冲区中。 该缓冲区包含固定数量的近期经验,这样每个代理能够从所有代理收集的各种转换中学习。
- 从经验中学习:定期从共享重放缓冲区中抽取一批经验。 通过最小化预测 Q 值和目标 Q 值之间的均方误差,使用采样经验来更新共享 Critic 网络。
- 更新 Actor 网络:共享 Actor 网络使用策略梯度进行更新,策略梯度是通过采用共享 Critic 网络关于所选动作的输出梯度来计算的。 共享 Actor 网络学习选择最大化预期 Q 值的动作。
- 更新目标网络:共享的 Actor 和 Critic 目标网络使用当前和目标网络权重的混合进行软更新。 这确保了稳定的学习过程。
结果展示
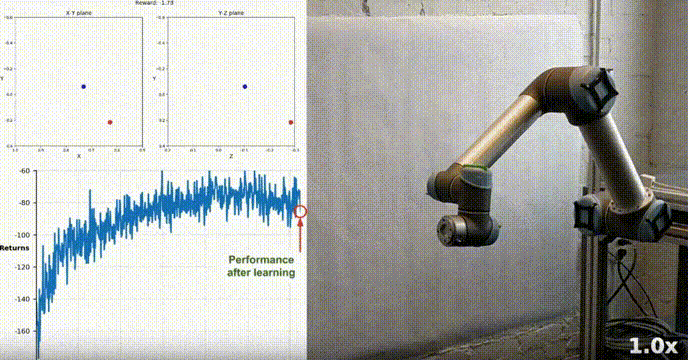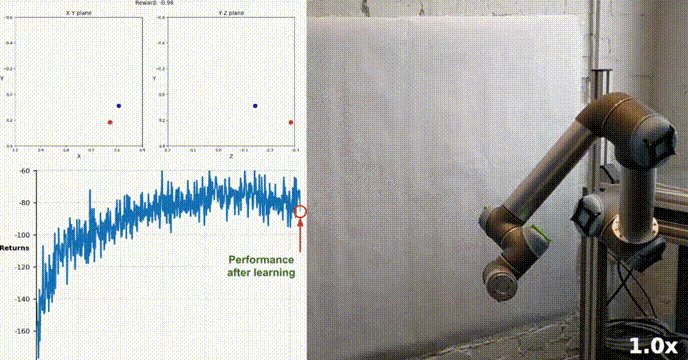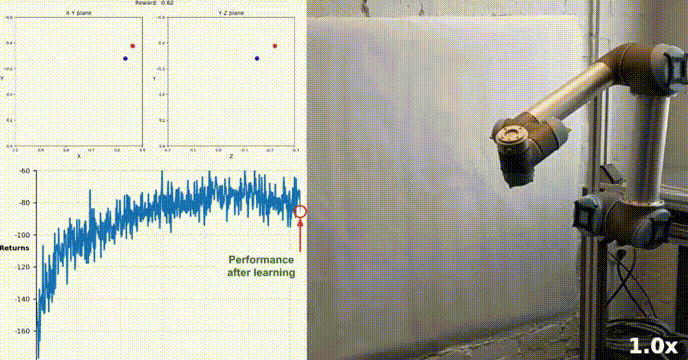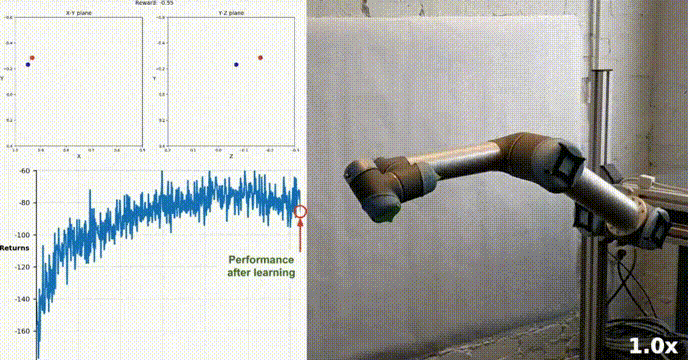
我们的agent使用DDPG算法成功地学会了在Racher环境下控制双关节机械臂。在整个训练过程中,我们根据所有20个代理的平均得分来监控代理的表现。随着智能体探索环境和收集经验,其预测奖励最大化最佳行为的能力显著提高。
可以看到代理在任务中表现出了显著的熟练程度,平均得分超过了解决环境所需的阈值(30+),虽然代理的表现在整个训练过程中有所不同,但总体趋势呈上升趋势,表明学习过程是成功的。
该图显示了20个代理的平均得分:
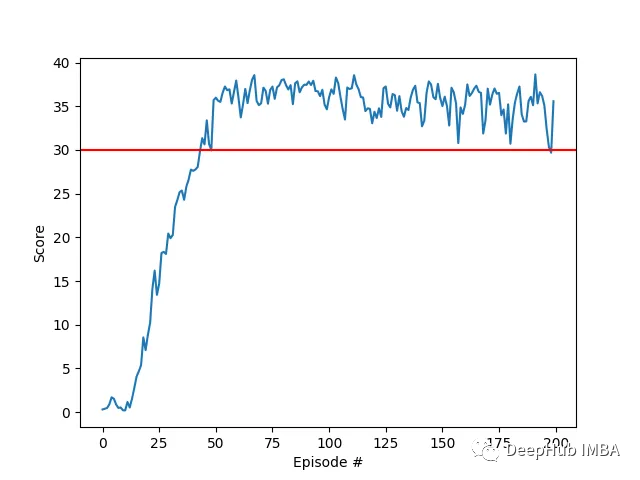
可以看到我们实现的DDPG算法,有效地解决了Racher环境的问题。代理能够调整自己的行为,并在任务中达到预期的性能。
下一步工作
本项目中的超参数是根据文献和实证测试的建议组合选择的。还可以通过系统超参数调优的进一步优化可能会带来更好的性能。
多agent并行训练:在这个项目中,我们使用20个agent同时收集经验。使用更多代理对整个学习过程的影响可能会导致更快的收敛或提高性能。
批归一化:为了进一步增强学习过程,在神经网络架构中实现批归一化是值得探索的。通过在训练过程中对每一层的输入特征进行归一化,批归一化可以帮助减少内部协变量移位,加速学习,并潜在地提高泛化。将批处理归一化加入到Actor和Critic网络可能会导致更稳定和有效的训练,但是这个需要进一步测试。
本文完整代码:
https://avoid.overfit.cn/post/54829204a5c74f0bb2b3a686c5fe079f
引用:
- Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., Silver, D., & Wierstra, D. (2015). Continuous control with deep reinforcement learning.
- Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction. MIT press.
- Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., … & Hassabis, D. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529–533.
- Udacity Deep Reinforcement Learning Nanodegree.
- Barth-Maron, G., Hoffman, M. W., Budden, D., Dabney, W., Horgan, D., TB, D., & Lillicrap, T. (2018). Distributed Distributional Deterministic Policy Gradients. arXiv preprint arXiv:1804.08617.
作者:Gabriel Cassimiro
相关文章:
使用Actor-Critic的DDPG强化学习算法控制双关节机械臂
在本文中,我们将介绍在 Reacher 环境中训练智能代理控制双关节机械臂,这是一种使用 Unity ML-Agents 工具包开发的基于 Unity 的模拟程序。 我们的目标是高精度的到达目标位置,所以这里我们可以使用专为连续状态和动作空间设计的最先进的Deep…...

黑马学生入职B站1年,晒出21K月薪:我想跳槽华为
现在的Z时代,嘴上说着不要,身体却很诚实。 前两天,黑马发布了《2022年度互联网平均薪资出炉!高到离谱!》,信息传输、软件和信息技术服务业薪资遥遥领先!Z时代举头望着天花板,故作潇…...

一文看懂GPT风口,都有哪些创业机会?
新时代的淘金者,低附加价值的创业要谨慎,高附加价值、低技术门槛创业也要谨慎,主干道边上的创业也要谨慎。不少朋友看完不淡定了,干什么都谨慎,回家躺平好了,我有个朋友,靠ChatGPT,半…...

chatgpt赋能python:Python中的不确定尾数问题
Python中的不确定尾数问题 Python作为一种高级编程语言,被广泛应用于数据科学、机器学习、Web开发等众多领域。然而,Python在处理浮点数时会出现一些不确定尾数的问题,给程序员和数据分析员带来不少麻烦。本篇文章将介绍Python中不确定尾数的…...
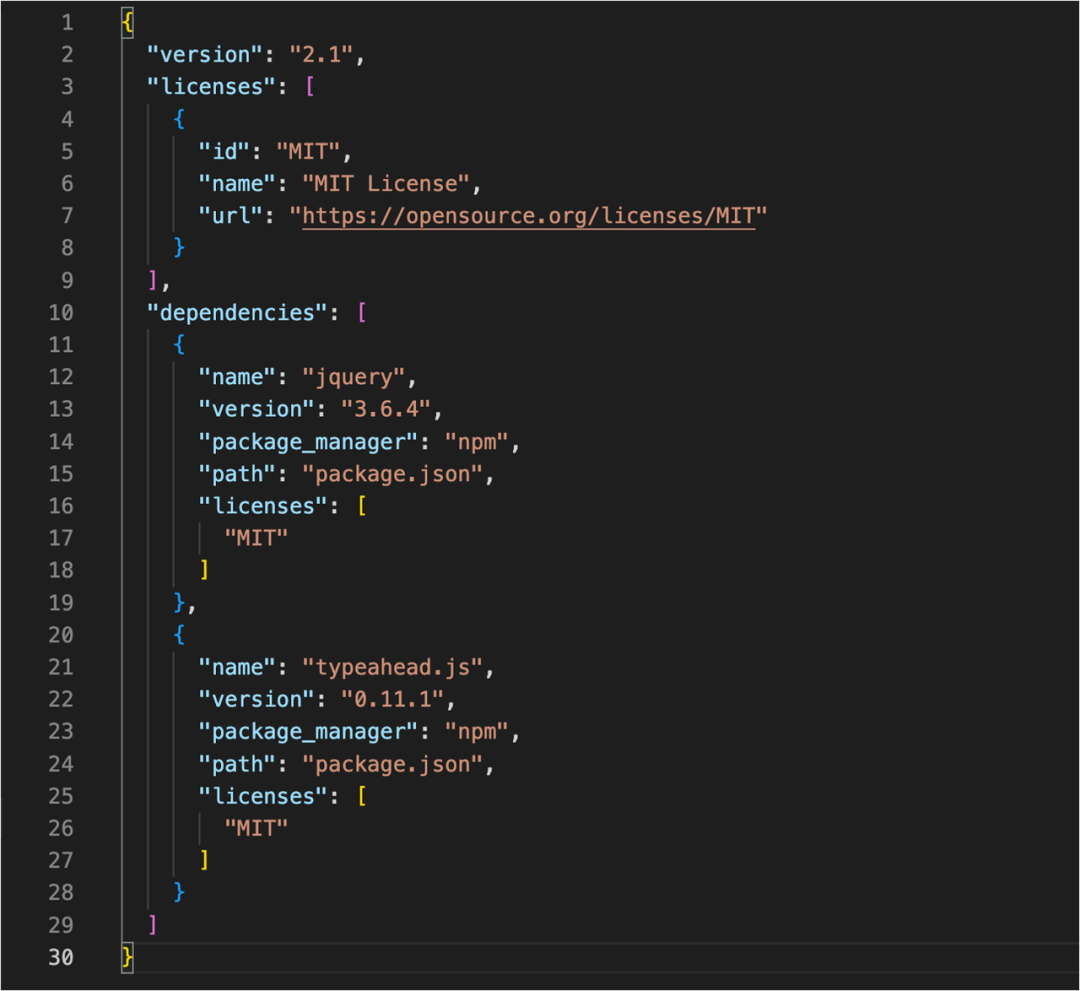
杜绝开源依赖风险,许可证扫描让高效合规「两不误」
目录 开源许可证及其常见类型 开源许可证扫描是软件研发过程中,不可或缺的工具 极狐GitLab 开源许可证扫描的优势与应用 Step 1:启用及设置许可证策略 Step 2:自动创建策略文件存放项目 Step 3:查看许可证合规情况 Step 4&…...
【sop】含储能及sop的多时段配网优化模型
目录 1 主要内容 2 部分代码 3 程序结果 4 下载链接 1 主要内容 之前分享了含sop的配电网优化模型,链接含sop的配电网优化,很多同学在咨询如何增加储能约束,并进行多时段的优化,本次拓展该部分功能,在原代码的基础上增加储能模…...

nodjs使用阿里云镜像安装
要使用阿里云镜像来安装 npm 包,你需要按照以下步骤进行操作: 首先,确保你已经安装了 Node.js 和 npm。你可以在终端(或命令提示符)中输入以下命令来验证它们的安装: node -v npm -v如果显示了 Node.js 和…...
C++ Primer Plus 第二章习题
目录 复习题 1.C程序的模块叫什么? 2.#include 预处理器编译指令的用处? 3.using namespace std; 该语句是干什么用的? 4.什么语句可以打印一个语句"hello,world",然后重新换行? 5.什么语句可以用来创…...

两分钟学会 制作自己的浏览器 —— 并将 ChatGPT 接入
前期回顾 分享24个强大的HTML属性 —— 建议每位前端工程师都应该掌握_0.活在风浪里的博客-CSDN博客2分享4个HTML5 属性,开发必备https://blog.csdn.net/m0_57904695/article/details/130465836?spm1001.2014.3001.5501 👍 本文专栏:开发…...

HEVC中,mvd怎么写进码流的?
文章目录 Motion vector difference syntax 标准文档描述语义解释设计意义 Motion vector difference syntax 标准文档描述 语义解释 MvdL1[ x0 ][ y0 ][ compIdx ] L1列表的mvd x0,y0 表示亮度快左上角坐标 compIdx 0表示水平 compIdx 0表示垂直 mvd_l1_zero_flag:…...

隐形黑客潜入美国和关岛关键基础设施而未被发现
微软和“五眼联盟”国家周三表示,一个隐秘的组织成功地在美国和关岛的关键基础设施组织中建立了一个持久的立足点,而没有被发现。 这家科技巨头的威胁情报团队正在以伏特台风(Volt Typhoon)的名义跟踪这些活动,包括入侵后的凭证访问和网络系…...
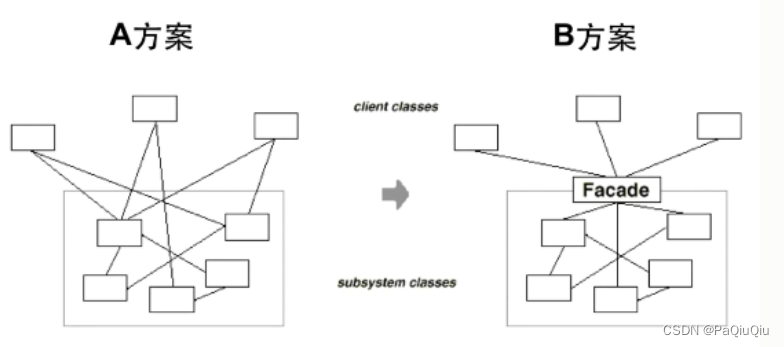
设计模式—“接口隔离”
在组件构建过程中,某些接口之间直接的依赖常常会带来很多问题、甚至根本无法实现。采样添加一层间接(稳定)接口,来隔离本来互相紧密关联的接口是一种常见的解决方案。 典型模式有:Fascade、Proxy、Adapter、Mediator 一、Fascade 动机 上述A方案的问题在于组件的客户和…...
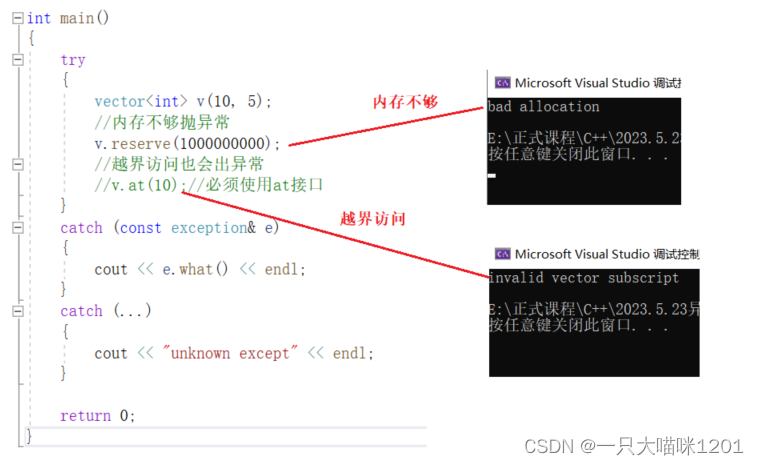
【C++学习】异常
🐱作者:一只大喵咪1201 🐱专栏:《C学习》 🔥格言:你只管努力,剩下的交给时间! 异常 🥮异常🍢自定义异常体系🍢C标准库的异常体系🍢异…...

如何理解TCP是面向字节流协议?
传输层是网络协议中的重要层次之一,主要负责向两个主机中的进程之间的通信提供服务。传输层的主要功能包括复用和分用、流量控制、分段/重组和差错控制。传输层在终端用户之间提供透明的数据传输,向上层提供可靠的数据传输服务。 传输层的复用和分用功能…...
机器学习期末复习 线性模型
1.线性回归,对数几率回归,线性判别分析是分类还是回归任务?是有监督的学习还是无监督的学习? 有监督学习和无监督学习 解释: 线性模型要做的有两类任务:分类任务、回归任务 分类的核心就是求出一条直线w…...

Worker及XMLHttpRequest简单使用说明
Worker 一、作用及使用场景 在Web应用程序中创建多线程环境,可以运行独立于主线程的脚本,从而提高Web应用的性能和响应速度。 Worker.js主要应用场景包括: 数据处理:在数据量较大的情况下,使用Worker可以将数据分成…...

零基础如何入门网络安全?2023年专业学习路线看这篇就够了
前景 很多零基础朋友开始将网络安全作为发展的大方向,的确,现如今网络安全已经成为了一个新的就业风口,不仅大学里开设相关学科,连市场上也开始大量招人。 那么网络安全到底前景如何?大致从市场规模、政策扶持、就业…...

《操作系统》by李治军 | 实验5.pre - switch_to 汇编代码详解
目录 【前言】 一、栈帧的处理 1. 什么是栈帧 2. 为什么要处理栈帧 3. 执行 switch_to 前的内核栈 4. 栈帧处理代码分析 二、PCB 的比较 1. 根据 PCB 判断进程切换与否 2. PCB 比较代码分析 三、PCB 的切换 1. 什么是 PCB 的切换 2. PCB 切换代码分析 四、TSS 内核…...

c++11基础
文章目录: c11简介统一的列表初始化{}初始化std::initializer_list 声明autodecltypenullptr 范围for循环STL中的一些变化arrayforward_listunordered_map和unordered_set 字符串转换函数 c11简介 在2003年C标准委员会曾经提交了一份技术勘误表(简称TC1)࿰…...
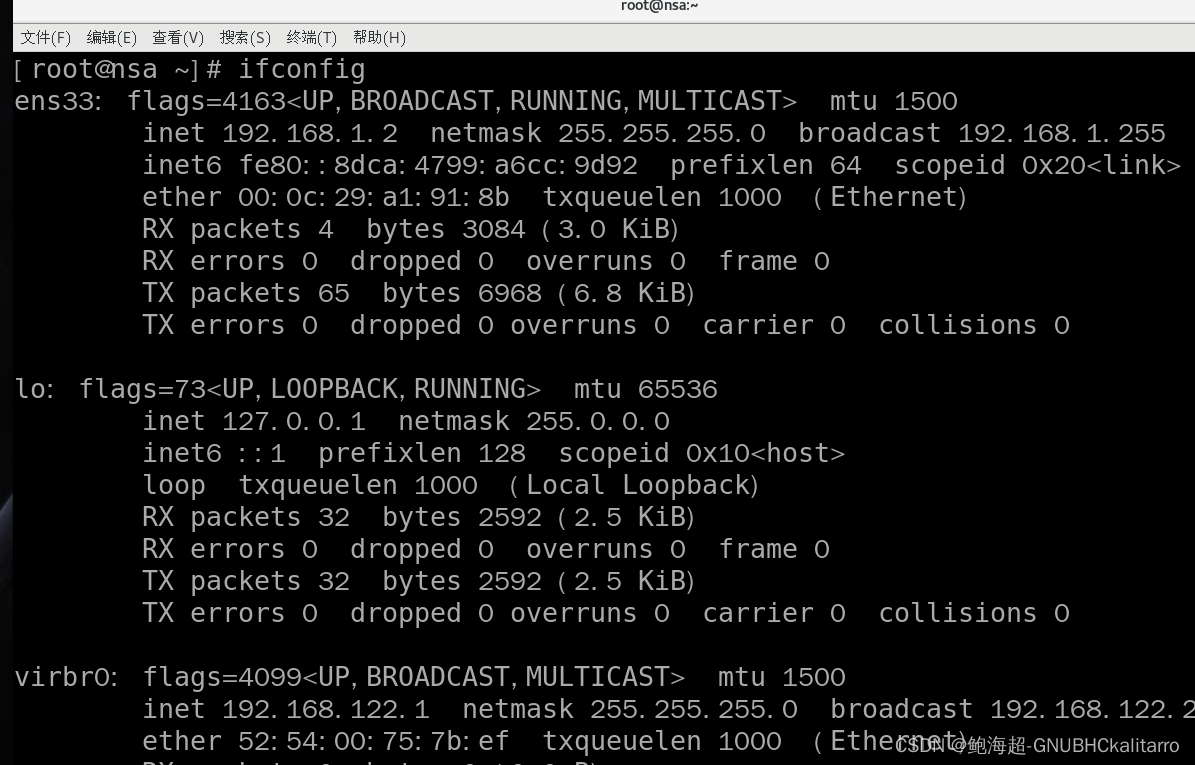
Linux:centos:修改临时ip永久ip
使用 ifconfig 查看网卡信息以及ip 临时配置ip 找到要修改ip的网卡的名称(我这里使用名称为:ens33网卡) # ifconfig 网卡名 ip /子网掩码 ifconfig ens33 192.168.1.2/24 配置永久ip 去配置网卡文件 vi /vim 或 nano vim /etc/s…...

别再只懂ls -l了!手把手教你用getfattr/setfattr玩转Linux文件隐藏属性
别再只懂ls -l了!手把手教你用getfattr/setfattr玩转Linux文件隐藏属性 在Linux系统中,文件权限和属性管理是每个开发者和管理员的必修课。大多数人熟悉 ls -l 展示的基础权限,但很少有人深入探索文件系统中那些不为人知的"隐藏技能&q…...

双系统硬盘告急?手把手教你用Ubuntu Live U盘和gparted无损调整/home分区大小
双系统用户必看:Ubuntu分区扩容实战指南你是否也遇到过这样的尴尬——当初安装双系统时随手给Ubuntu的分区分配空间,结果用着用着发现/home目录快被塞爆了,而根目录/却还有大量闲置空间?这种"旱的旱死,涝的涝死&q…...

集团首都公报:武汉市放飞炬人产业引导基金有限责任公司财政处批准 《武汉市放飞炬人产业引导基金有限责任公司财政处现金顾问制条令》
集团首都公报:武汉市放飞炬人产业引导基金有限责任公司财政处批准 《武汉市放飞炬人产业引导基金有限责任公司财政处现金顾问制条令》...
)
AI编程新纪元已来(Claude 3.5 Sonnet代码能力压测报告:GitHub Copilot vs Cursor vs 原生Claude)
更多请点击: https://intelliparadigm.com 第一章:AI编程新纪元已来(Claude 3.5 Sonnet代码能力压测报告:GitHub Copilot vs Cursor vs 原生Claude) AI编程工具正经历一场静默而深刻的范式迁移——Claude 3.5 Sonnet …...

昇腾CANN cmake:CANN 项目的 CMake 构建模块实战
从 ops-nn 到 cann-recipes-*,几乎所有 CANN 开源仓库都用 CMake 做构建系统。cann-cmake 仓库提供一套标准的 CMake 模块——FindCANN.cmake(找到 CANN 安装路径)、AscendCCore.cmake(Ascend C 编译规则)、AscendKern…...

Python异步编程深度解析:从asyncio到实战应用
Python异步编程深度解析:从asyncio到实战应用 引言 异步编程是现代Python后端开发中不可或缺的技能。作为从Python转向Rust的后端开发者,我发现Python的异步生态非常成熟,尤其是asyncio库提供了强大的异步编程能力。本文将深入探讨Python异步…...

安全打底・能力拉满:我的 OpenClaw 龙虾生态 Skill 清单
2026开年AI圈两大热词:龙虾(OpenClaw)、Skill插件。龙虾是短期流量话题,热度来得快去得快;而Skill插件可一次部署、长期复用,真正落地到日常办公、协作、社交场景。 市面多数Skill推荐内容堆砌命令、实用性…...

AI写论文真给力!4款AI论文生成工具,开启高效论文写作模式!
AI论文写作工具评测 还在为撰写期刊论文、毕业论文或职称论文而感到烦恼吗?在人工写作的过程中,面对那海量的文献资料,犹如在茫茫大海中捞针,而那些繁琐的格式要求更是让我们无从下手,不断的修改反复消耗我们的耐心&a…...

RAG大模型落地必杀技:解决幻觉、私有数据三大痛点,提升回答可信度!
本文深入解析了检索增强生成(RAG)技术,旨在解决大模型应用中的知识过时、幻觉和私有数据使用难题。文章详细阐述了RAG的三大核心模块——知识库、检索和生成,并系统讲解了索引、检索、生成的具体实施流程和优化策略。此外…...

Claude Code 用户如何通过 Taotoken 解决访问不稳定与 Token 不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 用户如何通过 Taotoken 解决访问不稳定与 Token 不足问题 对于依赖 Claude Code 进行开发的用户而言,服务…...