2000万的行数在2023年仍然是 MySQL 表的有效软限制吗?

谣言
互联网上有传言说我们应该避免在单个 MySQL 表中有超过 2000 万行。否则,表的性能会下降,当它超过软限制时,你会发现 SQL 查询比平时慢得多。这些判断是在多年前使用HDD硬盘存储时做出的。我想知道在2023年对于基于SSD的MySQL数据库来说,这是否仍然成立,如果成立,原因是什么?
环境
· 数据库
MySQL 版本:8.0.25
实例类型:AWS db.r5.large (2vCPUs, 16GiB RAM)
EBS 存储类型:通用 SSD (gp2)
· 测试客户端
Linux 内核版本:6.1
实例类型:AWS t2.micro (1 vCPU,1GiB 内存)
实验设计
创建具有相同模式但大小不同的表。我创建了9个表,分别包含10万、20万、50万、100万、200万、500万、1000万、2000万、3000万、5000万和6000万行。
1.创建几个具有相同模式的表:
CREATE TABLE row_test(`id` int NOT NULL AUTO_INCREMENT,`person_id` int NOT NULL,`person_name` VARCHAR(200),`insert_time` int,`update_time` int,PRIMARY KEY (`id`),KEY `query_by_update_time` (`update_time`),KEY `query_by_insert_time` (`insert_time`)
);
2. 插入不同行的表格。我使用测试客户端和复制来创建这些表。脚本可以在这里找到。
# test client
INSERT INTO {table} (person_id, person_name, insert_time, update_time) VALUES ({person_id}, {person_name}, {insert_time}, {update_time})# copy
create table <new-table> like <table>
insert into (`person_id`, `person_name`, `insert_time`, `update_time`)
select `person_id`, `person_name`, `insert_time`, `update_time` from
person_id、person_name、insert_time 和 update_time 的值是随机的。
3.使用测试客户端执行以下sql查询来测试性能。脚本可以在这里找到。
select count(*) from <table> -- full table scan
select count(*) from <table> where id = 12345 -- query by primary key
select count(*) from <table> where insert_time = 12345 -- query by index
select * from <table> where insert_time = 12345 -- query by index, but cause 2-times index tree lookup
4.查看innodb缓冲池状态
SHOW ENGINE INNODB STATUS
SHOW STATUS LIKE 'innodb_buffer_pool_page%'
5.每次在表上测试完一定要重启数据库!刷新 innodb 缓冲池以避免读取旧缓存并得到错误结果!
结果
查询 1:select count(*) from <table>

这种查询会造成全表扫描,这是MySQL不擅长的。
No-cache round:(第一轮)当缓冲池中没有缓存数据时,第一次执行查询。
Cache round:(Other round)当缓冲池中已经有数据缓存时执行查询,通常在第一次执行之后。
几个观察:
1.第一次执行的查询运行时间比后面的要长
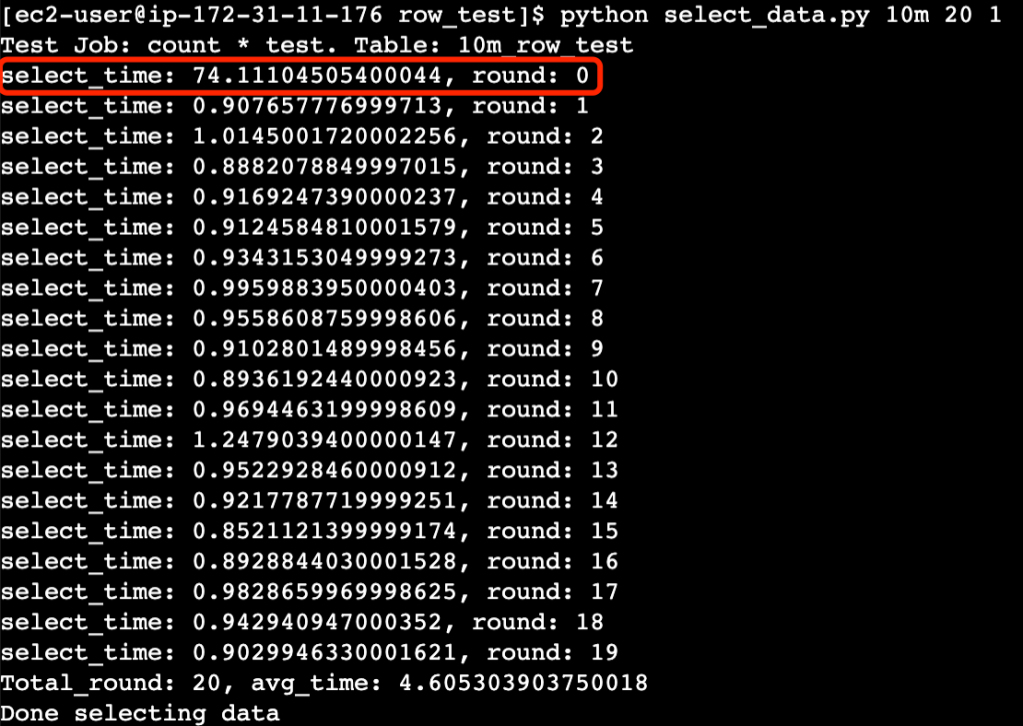
原因是MySQL使用了innodb_buffer_pool来缓存数据页。在第一次执行之前,缓冲池是空的,它必须进行大量的磁盘 I/O 才能从 .idb 文件加载表。但第一次执行后,数据存储在缓冲池中,后续执行可以通过内存计算得到结果,避免磁盘I/O,速度更快。该过程称为MySQL 缓冲池预热。
2.select count(*) from <table>将尝试将整个表加载到缓冲池
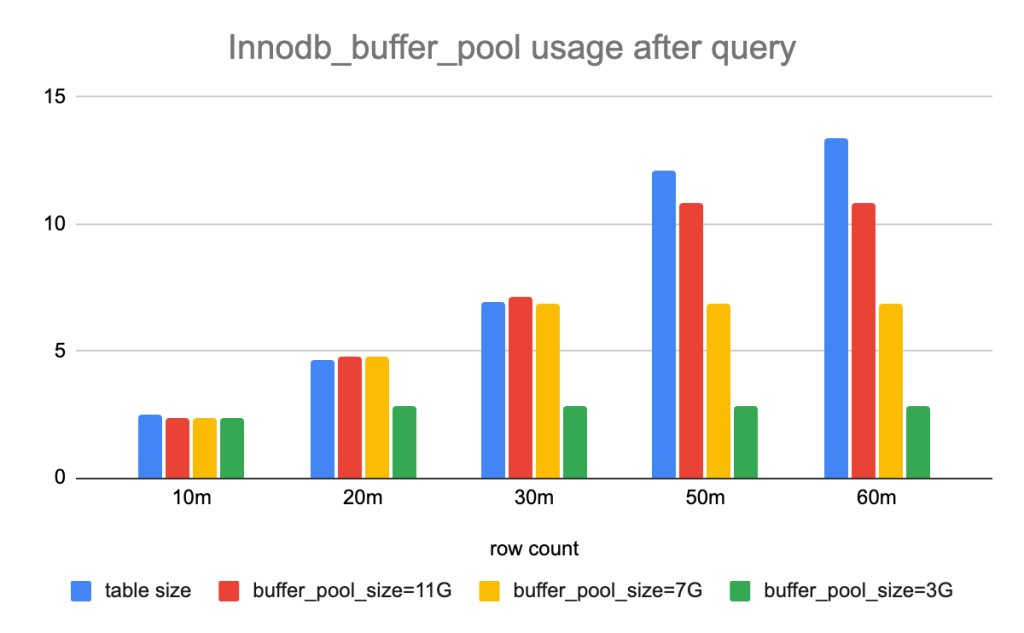
我比较了实验前后的 innodb_buffer_pool 统计数据。运行查询后,如果缓冲池足够大,缓冲池使用变化等于表大小。否则只有部分表会缓存在缓冲池中。原因是查询select count(*) from table会做全表扫描,一行一行地统计行数。如果没有缓存,这需要将完整表加载到内存中。为什么?因为 Innodb 支持事务,它不能保证事务在不同时间看到同一张表。全表扫描是获得准确行数的唯一安全方法。
3.如果缓冲池不能容纳全表,查询延迟会爆发
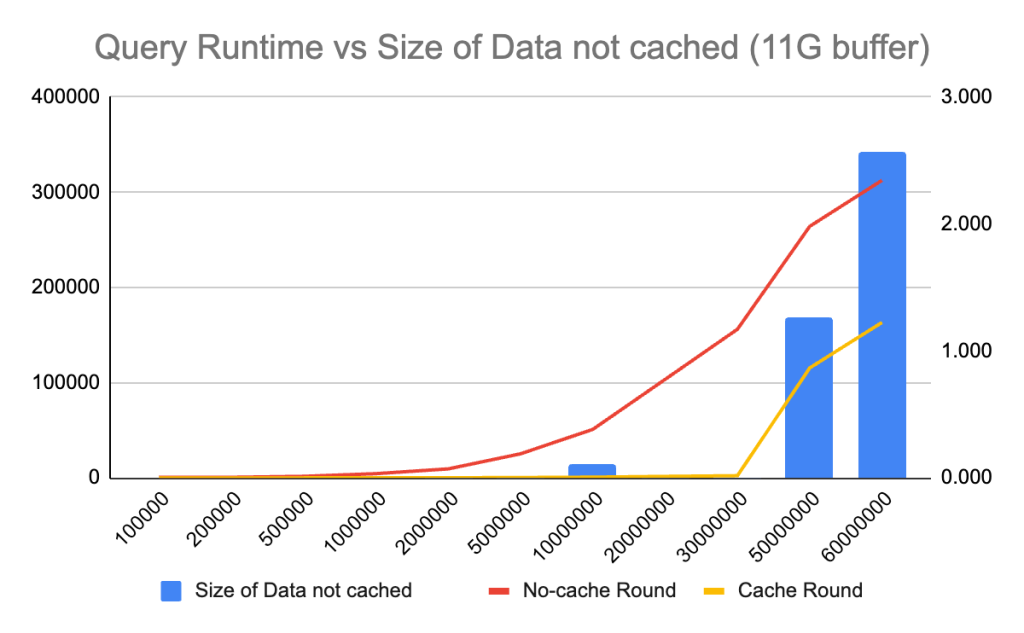
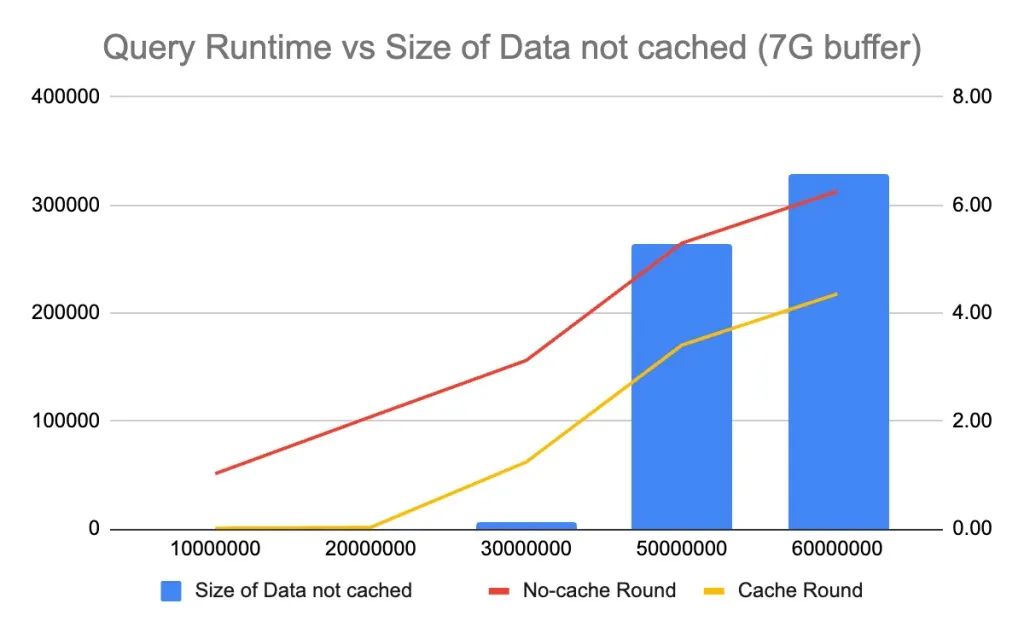
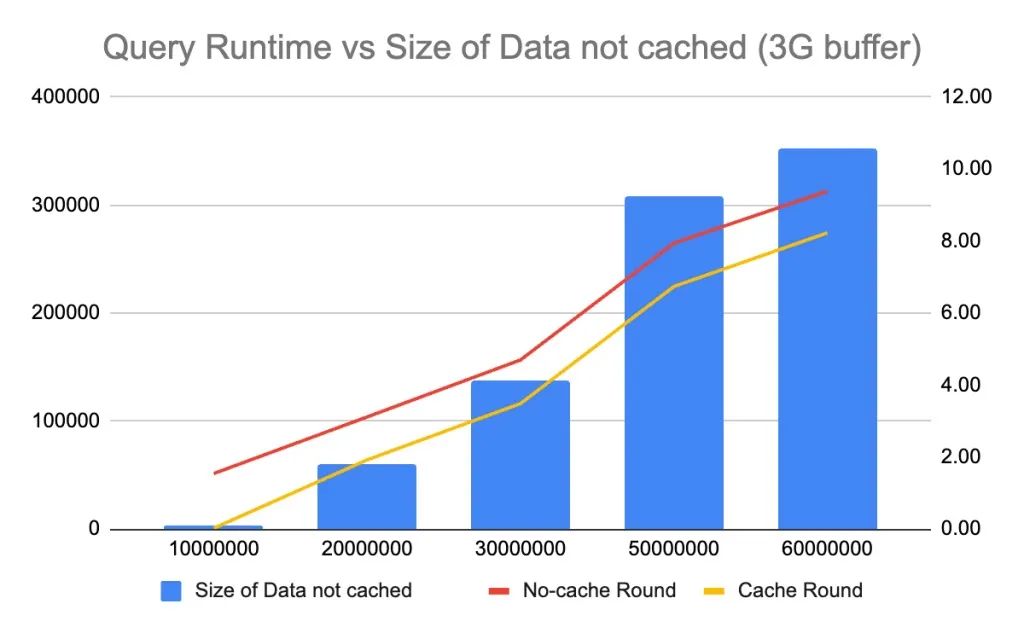
我注意到 innodb_buffer_pool 大小会对查询性能产生很大影响,因此我尝试在不同的配置下运行查询。当使用 11G 的缓冲池时,查询延迟的突增发生在表大小达到 50M 时。然后将缓冲池大小减小为 7G,查询延迟的突增发生在表大小为 30M 时。最后将缓冲池大小减小到 3G,查询运行时间的突增发生在表大小为 20M 时。很明显,如果表中的数据无法被缓存到缓冲池中,执行select count(*) from <table>就需要进行昂贵的磁盘 I/O 操作来加载数据,从而导致查询运行时间的突增。
4. 在不缓存的情况下,查询运行时间与表大小呈线性关系,与缓冲池大小无关。
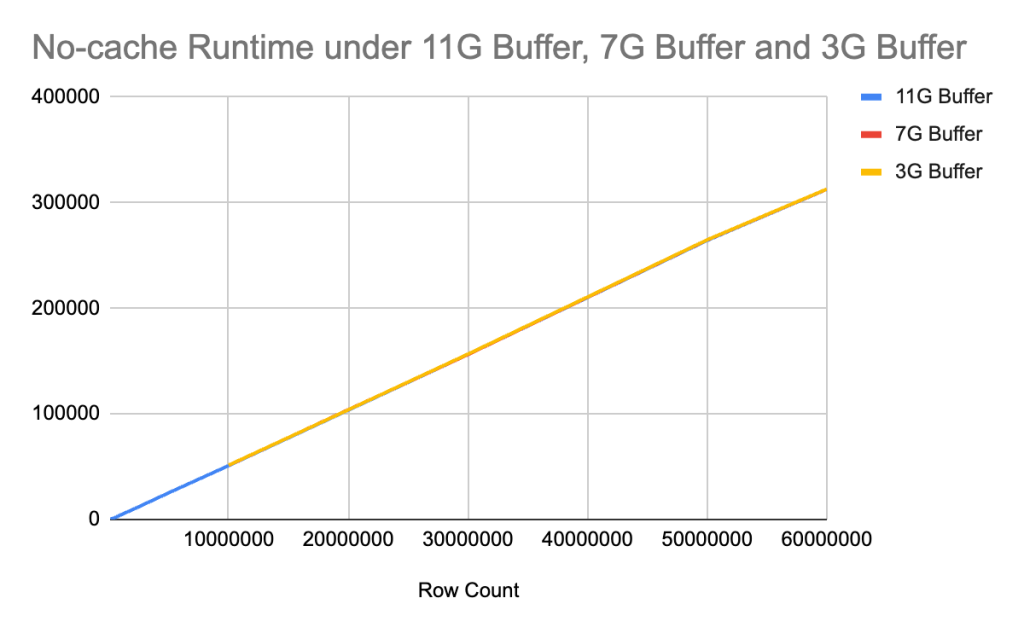
无缓存循环运行时间由磁盘 I/O 决定,与缓冲池大小无关。select count(*)使用相同 IOPS 的存储磁盘预热缓冲池没有区别。
5. 如果表无法完全缓存在缓冲池中,那么无缓存轮和有缓存轮之间的查询运行时间差是恒定的。
同时注意到,尽管如果表无法完全缓存在缓冲池中会导致查询运行时间的突增,但运行时间是可预测的。无缓存轮运行时间和有缓存轮运行时间之间的差值是恒定的,无论表的大小如何。原因是表的部分数据被缓存在缓冲池中,这个差值表示了从缓冲池而不是磁盘进行查询所节省的时间。
查询 2、3:select count(*) from <table> where <index_column> = 12345
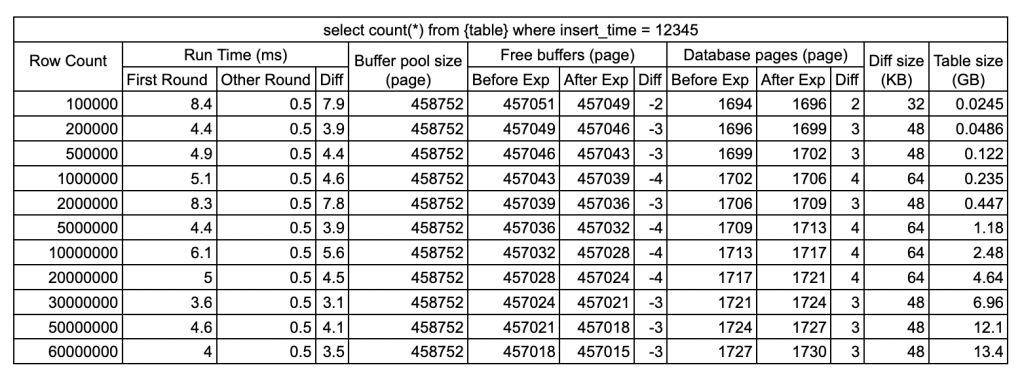
此查询使用索引。由于不是范围查询,只需要在B+树的路径中从上到下查找页面,并将这些页面缓存到innodb缓冲池中即可。
我创建的表的 B+ 树的深度都是 3,导致 3-4 次 I/O 来预热缓冲区,平均耗时 4-6ms。之后,如果我再次运行相同的查询,它会直接从内存中查找结果,即 0.5ms,等于网络 RTT。如果缓存页面长时间未命中并从缓冲池中逐出,则必须再次从磁盘加载该页面,这最多需要 4 次磁盘 I/O。
查询 4:select * from <table> where <index_column> = 12345
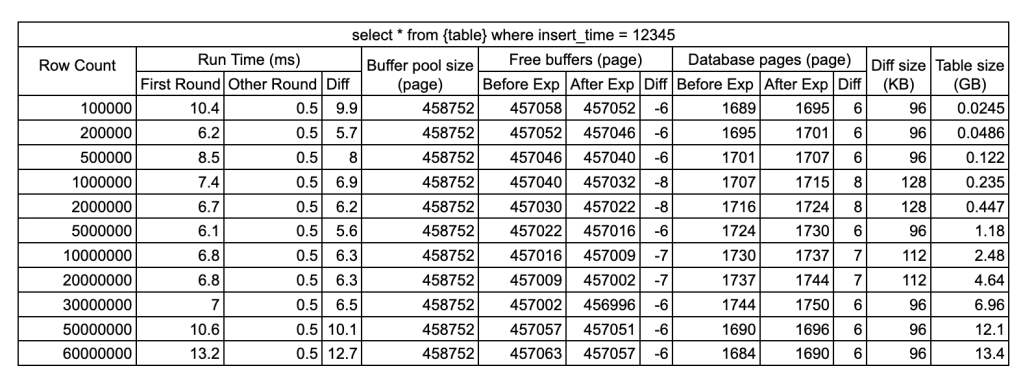
此查询导致 2 次索引查找。由于select *需要查询获取不包含在索引中的person_name, person_id,因此在查询执行期间数据库引擎必须查找 2 个 B+ 树。它首先查找insert_timeB+ 树以获取目标行的主键,然后查找主键 B+ 树以获取该行的完整数据,如下图所示:
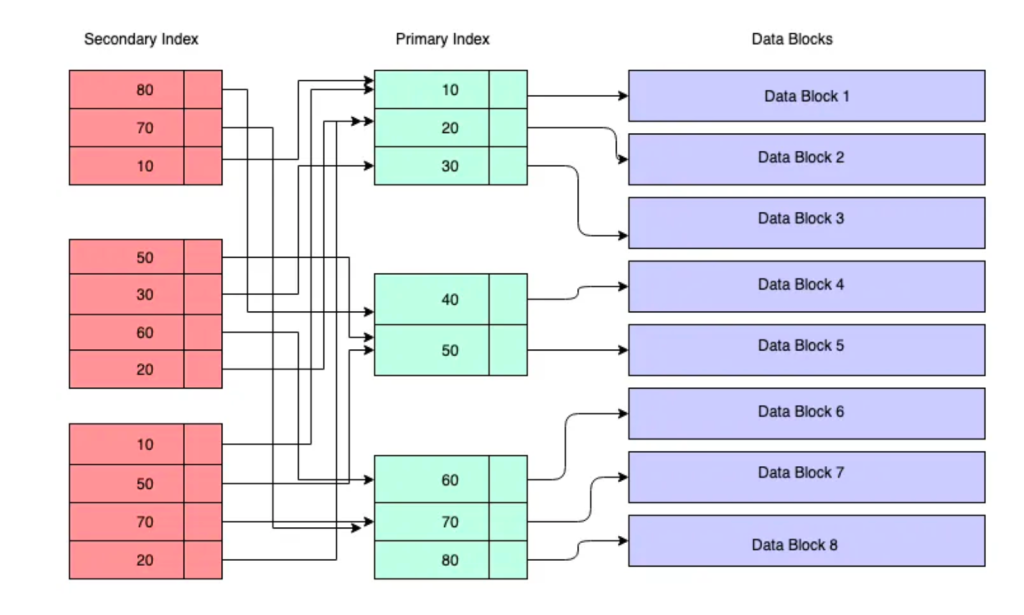
这就是我们在生产中应该避免的原因select *。并且在实验中,数据证实此查询加载的页面块比查询 2 或 3 多 2 倍,最多为 8。平均查询运行时间为 6-10 毫秒,也是查询 2 或 3 的 1.5 到 2 倍。
谣言是怎么来的

首先我们需要知道innodb索引页的物理结构。默认页面大小为 16k,由页眉、系统记录、用户记录、页面导向器和尾部组成。将只剩下 15-14k 来存储免费数据。
假设您使用 INT 作为主键(4 字节),每行 1KB 的有效负载。每个叶页可以存储 15 行,它将是 4+8=12 字节,使其成为指向该页的指针。因此,每个非叶页最多可以容纳 15k / 12 字节 = 1280 个指针。如果你有一个 4 层的 B+ 树,它最多可以容纳 1280*1280*15 = 24.6M 行数据。
回到 HDD 占据市场主导地位且 SSD 对于数据库而言过于昂贵的时代,4 次随机 I/O 可能是我们可以容忍的最坏情况,而使用 2 次索引树查找的查询甚至会使情况变得更糟。当时的工程师想要控制索引树的深度,不希望它们长得太深。现在SSD越来越流行,随机I/O比以前便宜了,我们可以回顾一下10年前的规则。
顺便说一句,5层B+树可以容纳1280*1280*1280*15 = 31.4B行数据,超过了INT所能容纳的最大数量。对每行大小的不同假设将导致不同的软限制,小于或大于 20M。例如,在我的实验中,每行大约 816 字节(我使用utf8mb4字符集,所以每个字符占用 4 个字节),4 层 B+ 树可以容纳的软限制是 29.5M。
结论
-
Innodb_buffer_pool 大小/表大小决定是否会出现性能下降。
-
一个更有意义的指标来判断是否需要拆分MySQL表是查询运行时间与缓冲池命中率的比值。如果查询总是命中缓冲池,就不会有性能问题。2000万行只是基于经验的一个值。
-
除了拆表,增加InnoDB缓冲池大小或数据库内存也是一个选择。
-
在生产环境中,如果可能的话,尽量避免使用
select *,因为在最坏的情况下会导致索引树的两次查找。 -
(个人观点)考虑到SSD现在的普及,2000万行并不是MySQL表的一个非常有效的软限制。
来源:Yisheng's blog
更多技术干货请关注公号“云原生数据库”
squids.cn,基于公有云基础资源,提供云上 RDS,云备份,云迁移,SQL 窗口门户企业功能,
帮助企业快速构建云上数据库融合生态。
相关文章:
2000万的行数在2023年仍然是 MySQL 表的有效软限制吗?
谣言 互联网上有传言说我们应该避免在单个 MySQL 表中有超过 2000 万行。否则,表的性能会下降,当它超过软限制时,你会发现 SQL 查询比平时慢得多。这些判断是在多年前使用HDD硬盘存储时做出的。我想知道在2023年对于基于SSD的MySQL数据库来说…...

jvm问题排查
常用工具 命令查询资源信息 top:显示系统整体资源使用情况 vmstat:监控内存和 CPU iostat:监控 IO 使用 netstat:监控网络使用 查看java进程 jps 查看运行时信息 jinfo pid gc工具 jstat: 查看jvm内存信息 GCViewer — 离线分析G…...

【Redis】浅谈Redis-集群(Cluster)
文章目录 前言1、集群实现1.1 创建cluster目录,并将redis.conf复制到该文件夹1.2 复制redis.conf,并进行配置1.3 启动redis,查看启动状态1.4 合成集群1.5 查看集群1.6 集群读写操作 2、SpringBoot整合redis集群2.1 引入包2.2 设置配置2.3 使用…...
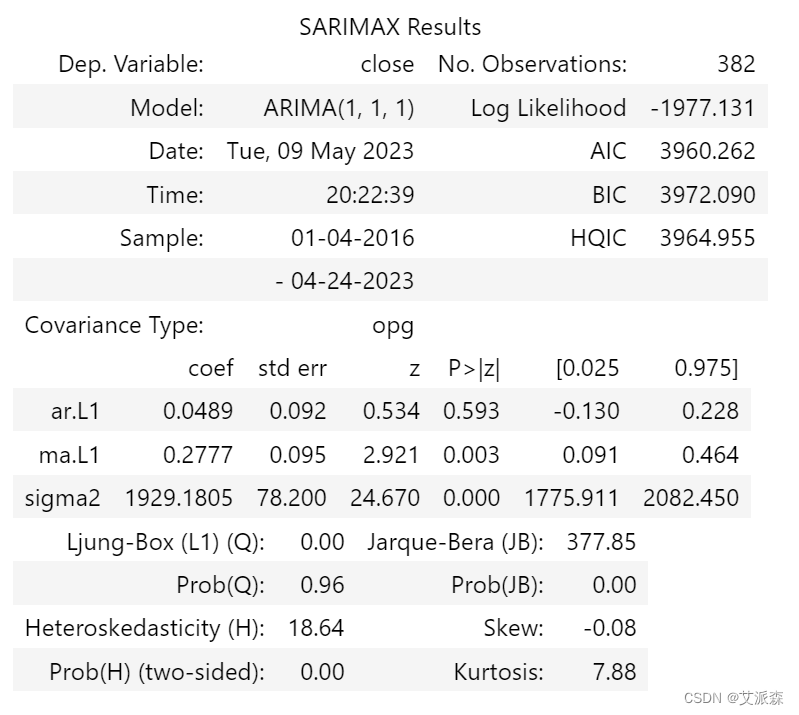
Python3实现基于ARIMA模型来预测茅台股票价格趋势
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...
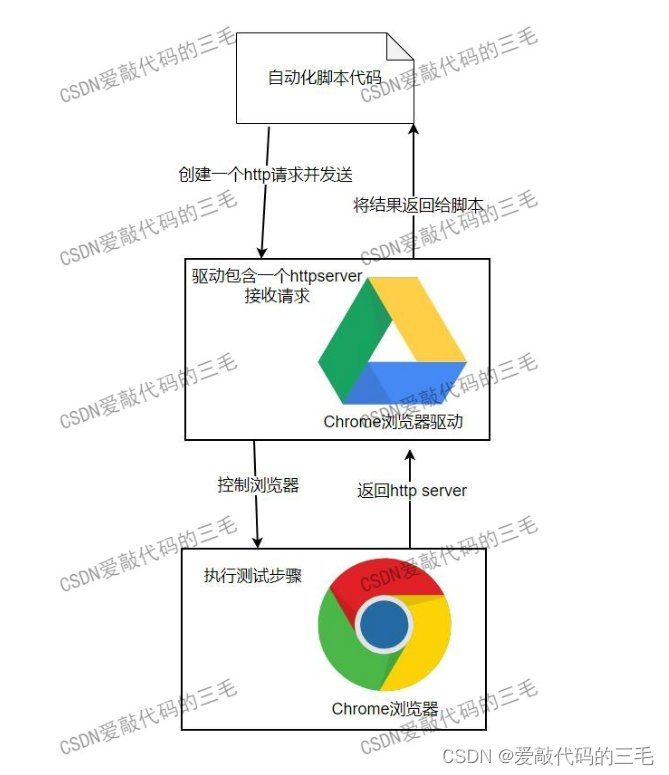
自动化测试selenium环境搭建
自动化测试工具selenium搭建 1. 自动化和selenium基本概念 1) 什么是自动化?为什么要做自动化? 自动化测试能够代替一部分的手工测试,自动化测试能够提高测试的效率。随着项目功能的增加,版本越来越多,版本的回归测试的压力也…...
SaaS系统平台,如何兼顾客户的个性化需求?
在当今数字化的商业环境中,SaaS系统已经成为企业运营的重要组成部分之一。 SaaS系统平台的好处是显而易见的,可以将业务流程数字化,从而帮助企业提高效率并节省成本。 但是,由于每个企业的业务都不尽相同,所以在选择Sa…...

QDir拼接路径解决各种斜杠问题
一般在项目中经常需要组合路径,与其他程序进行相互调用传递消息通信。 经常可能因为多加斜杠、少加斜杠等问题导致很多问题。 为了解决这些问题,我们可以使用QDir来完成路径的拼接,不直接拼接字符串。 QDir的静态方法QDir::cleanPath() 是为了规范化路径名的,在使用QDir组…...
mycat2主从配置实现读写分离
mycat2主从配置实现读写分离 在https://blog.csdn.net/zhangxue_wei/article/details/130840504基础上继续搭建 1.创建mycat数据源,可以在navcat里直接执行 1.1读数据源m1 /* mycat:createDataSource{"dbType":"mysql","idleTimeout&qu…...

如何在Centos7中安装Kubernetes
一、概述 Kubernetes([kubə’netis]),简称K8s,是用8代替名字中间的8个字符“ubernete”而成的缩写,它是一个由Google 开源的全新的分布式容器集群管理系统。 二、准备 IP角色内存192.168.1.130master4G192.168.1.1…...

Stream强化
使用stream求list的对象属性的和 假设有一个Student类,其中有一个属性是score,可以通过以下代码求出List<Student>中score的和: List<Student> students new ArrayList<>(); // 添加学生对象到List中 int sum student…...
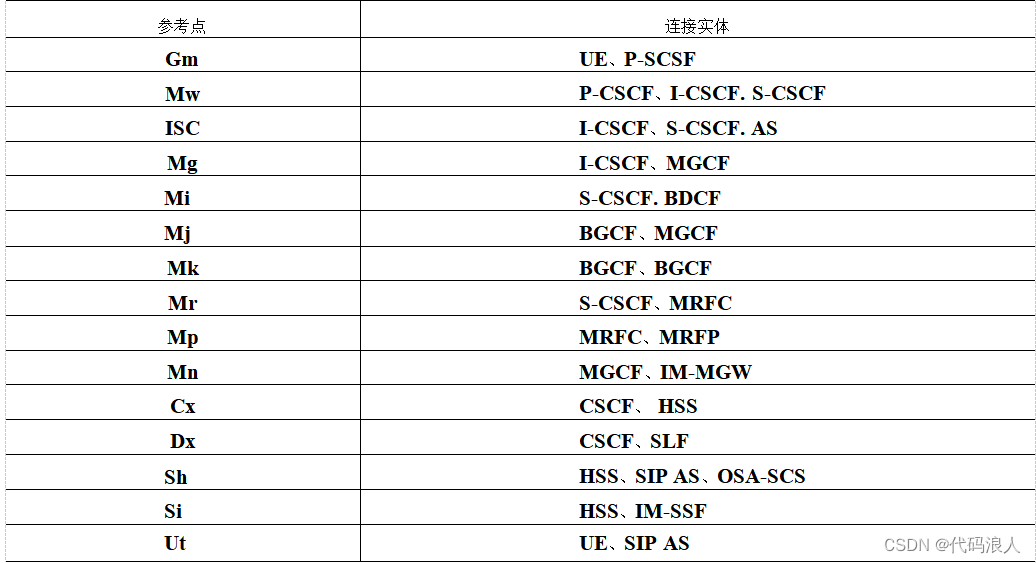
第一部分-基础篇-第一章:PSTN与VOIP(下篇)
文章目录 序言上一篇文章:1.6 电路交换与分组交换1.6.1 电路交换1.6.2 分组交换 1.7 VoIP1.8 IMS1.8.1 什么是IMS1.8.2 IMS的特点1.8.3 IMS核心网元(1 ) CSCF(2 ) MGCF(3 ) IM-MGW(5…...
《汇编语言》- 读书笔记 - 第4章-第一个程序
《汇编语言》- 读书笔记 - 第4章-第一个程序 4.1 一个源程序从写出到执行的过程4.2 源程序程序 4.11. 伪指令1.1 segment ends 声明段1.2 end 结束标记1.3 assume 关联 2. 源程序中的“程序”3. 标号4. 程序的结构5. 程序返回6. 语法错误和逻辑错误 4.3 编辑源程序4.4 编译4.5 …...
AI工具 ChatGPT-4 vs Google Bard , PostgreSQL 开发者会pick谁?
在人工智能 (AI) 进步的快节奏世界中,开发人员正在寻找最高效和突破性的解决方案来加快和提高他们的工作质量。对于 PostgreSQL 开发人员来说,选择理想的 AI 支持的工具以最专业的方式解决他们的查询至关重要。 近年来,人工智能工具的普及率…...

【网络】基础知识1
目录 网络发展 独立模式 网络互联 局域网LAN 广域网WAN 什么是协议 初识网络协议 协议分层 OSI七层模型 TCP/IP四层(或五层)模型 OSI和TCP/IP对比 网络传输流程 什么是报头 局域网通信原理 同网段的主机通讯 跨网段的主机通讯 数据包封装…...

chatgpt赋能python:Python倒序range的完整指南
Python倒序range的完整指南 Python是一种高级编程语言,很多人认为它非常容易学习和使用。其中一个非常有用的功能是range()函数,可以生成数字序列。然而,有时候我们需要以相反的顺序生成这个数字序列,这时候倒序range()函数就派上…...

工作笔记!
搭建tomcat Tomcat详细使用教程 tomcat配置用戶名和密碼 tomcat设置外网能访问_tomcat让别人通过网络访问 如何在windows开端口_windows开放端口命令 tomcat进Manager 403 Access Denied You are not authorized to view this page_tomcat报错you are not_ferry_cai 关于依…...

java设计模式之享元设计模式的前世今生
享元设计模式是什么? 享元设计模式是一种结构型设计模式,它的目的是在大规模重复使用相似对象时提高内存利用率和性能。它通过共享对象的公共部分来减少所需要的内存,从而在系统中同时存在更多的对象。 享元设计模式通过将对象分为可共享的内…...

RESTful:理解REST架构风格、RESTful API
一、REST架构风格 REST(英文Representational State Transfer)是一种基于客户端和服务器的架构风格,用于构建可伸缩、可维护的Web服务。REST的核心思想是,将Web应用程序的功能作为资源来表示,使用统一的标识符&#x…...
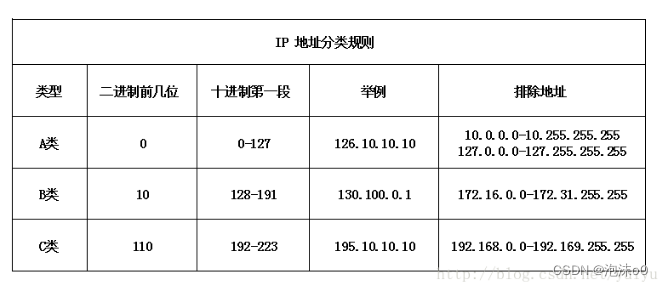
网络面试题:什么是 TCP/IP?
目录标题 什么是 TCP/IP?1) 网络接口层:2) 网络层:3) 传输层:4) 应用层: 2.数据包3.网络接口层4.网络层1) IP:2)地址解析协议 ARP3)子网 5 传输层1)UDP:2)TCP: 6 应用层运行在TCP协议上的协议:运行在UDP协议上的协议&…...

毫米波雷达模块在自动驾驶系统中的关键功能
随着自动驾驶技术的快速发展,毫米波雷达模块作为一项关键技术,为自动驾驶系统提供了重要的感知和决策能力。毫米波雷达模块通过实时探测和跟踪周围环境中的车辆、行人和障碍物,提供精确的距离和速度信息,帮助自动驾驶车辆做出准确…...

关于内卷,几个值得深想的洞察
首先声明:这篇不劝躺平,也不教内卷——只是想说清楚,你到底在一个什么样的游戏里。 你以为内卷是“资源不足”,其实是“分配方式” 很多人对内卷有个本质上的认知错误:以为内卷是因为资源不够,大家为了抢资…...

SuperCom串口调试工具终极指南:快速解决嵌入式开发中的通信难题
SuperCom串口调试工具终极指南:快速解决嵌入式开发中的通信难题 【免费下载链接】SuperCom SuperCom 是一款串口调试工具 项目地址: https://gitcode.com/gh_mirrors/su/SuperCom 想象一下这样的场景:你正在调试一个嵌入式设备,需要同…...

eqMac终极指南:macOS系统级音频均衡器免费使用教程
eqMac终极指南:macOS系统级音频均衡器免费使用教程 【免费下载链接】eqMac macOS System-wide Audio Equalizer & Volume Mixer 🎧 项目地址: https://gitcode.com/gh_mirrors/eq/eqMac 你是否曾经觉得Mac电脑的音质不够理想?想要…...

3PEAK思瑞浦 TPA6532-VS1R MSOP8 运算放大器
特性 供电电压:1.75伏至5.5伏 偏移电压:土1.5mV(最大) 通用峰值电压:300kHz,斜率:0.15V/us 轨到轨输入和输出 0.1Hz至10Hz电压噪声:1Vpp 开机和关机电流期间无明显输出抖动 低功耗:每通道最大25安培工作温度范围:-40C至125C...

长期使用Taotoken Token Plan套餐带来的成本节约感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐带来的成本节约感受 1. 项目背景与成本挑战 我们团队负责一个持续进行文本分析与内容生成的内部…...

九大网盘直链解析工具:如何让文件传输效率提升300%以上
九大网盘直链解析工具:如何让文件传输效率提升300%以上 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...

深入解析AlienFX Tools:从硬件直连到个性化灯光控制的完整技术方案
深入解析AlienFX Tools:从硬件直连到个性化灯光控制的完整技术方案 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 在Alienware设备生态中&…...

STM32F407 ADC采样值跳得厉害?HAL库时钟配置与软件滤波避坑指南
STM32F407 ADC采样值跳得厉害?HAL库时钟配置与软件滤波避坑指南 在嵌入式系统开发中,ADC(模数转换器)的稳定性直接关系到整个系统的测量精度。特别是对于STM32F407这类高性能MCU,当应用于电源监控、医疗设备或工业传感…...

3步实现网易云音乐插件管理,让你的音乐体验焕然一新
3步实现网易云音乐插件管理,让你的音乐体验焕然一新 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在为网易云音乐功能单一而烦恼吗?是否曾想过让音乐播放器…...

抖音批量下载终极指南:如何高效自动化获取用户主页全作品
抖音批量下载终极指南:如何高效自动化获取用户主页全作品 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...